
Visual–Tactile Fusion and SAC-Based Learning for Robot Peg-in-Hole Assembly in Uncertain Environments


Abstract
1. Introduction
- We propose a novel robot assembly framework that combines visual–tactile multimodal perception with reinforcement learning. This fusion enables the robot to perceive environmental uncertainties and object states more comprehensively, which is critical for robust peg-in-hole operations.
- We develop a multimodal feature fusion network based on the convolutional autoencoder; this network can effectively extract and fuse multimodal information (RGB image, depth map, force–torque signals, robot pose information). The fused features provide rich context for decision-making during assembly tasks.
- We integrate the Soft Actor–Critic (SAC) algorithm into the robot control pipeline for adaptive skill learning. By using fused sensory features as input, the SAC-based policy learns to generate precise control actions that are robust to pose deviations and variable contact conditions.
2. Materials and Methods
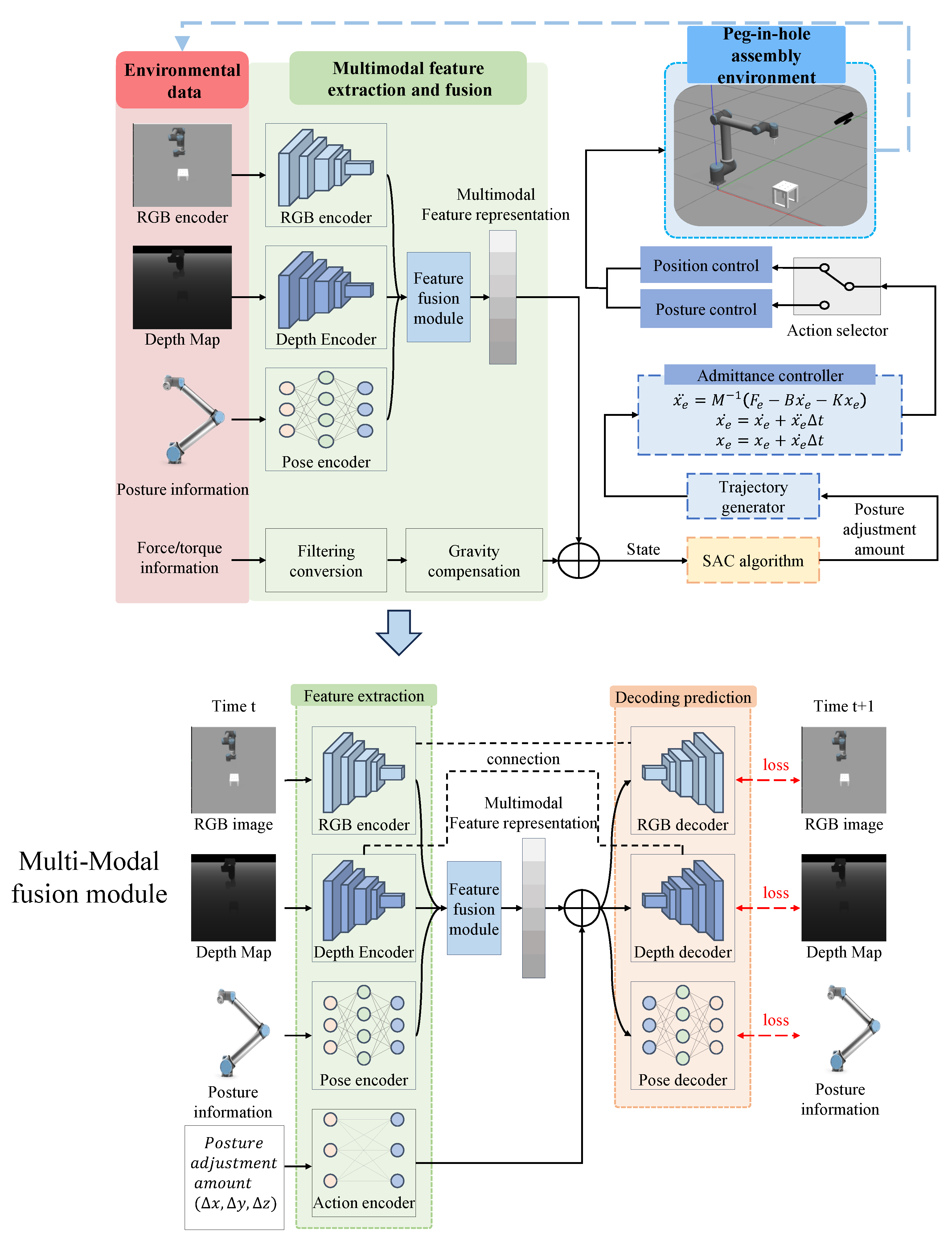
2.1. Visual–Tactile Fusion Network
2.2. Visual–Tactile Fusion Network
2.2.1. Multimodal Feature Extraction
2.2.2. Multimodal Feature Fusion Model
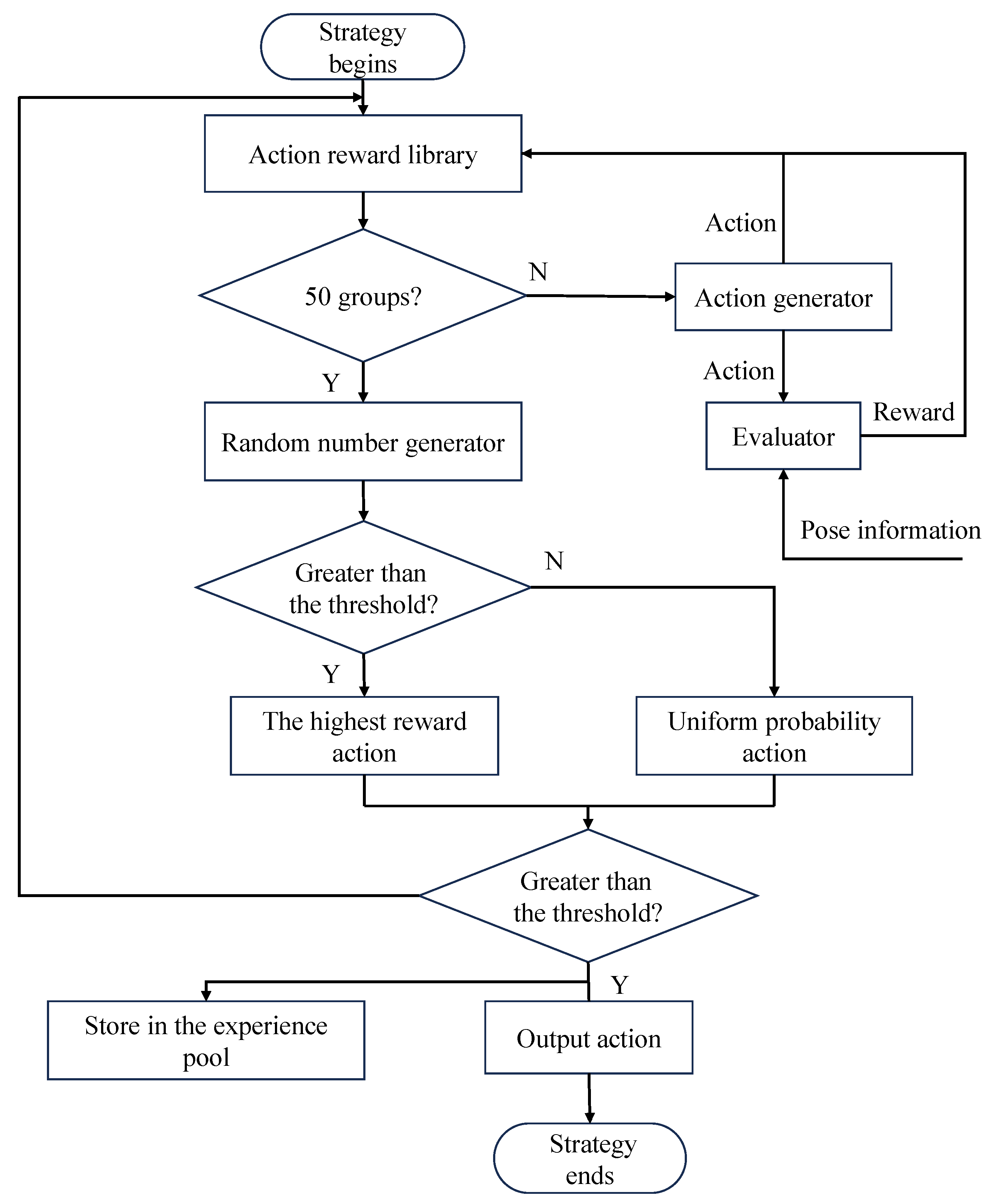
2.2.3. Multimodal Data Collection Strategy
2.3. Sac-Based Assembly Skill Learning
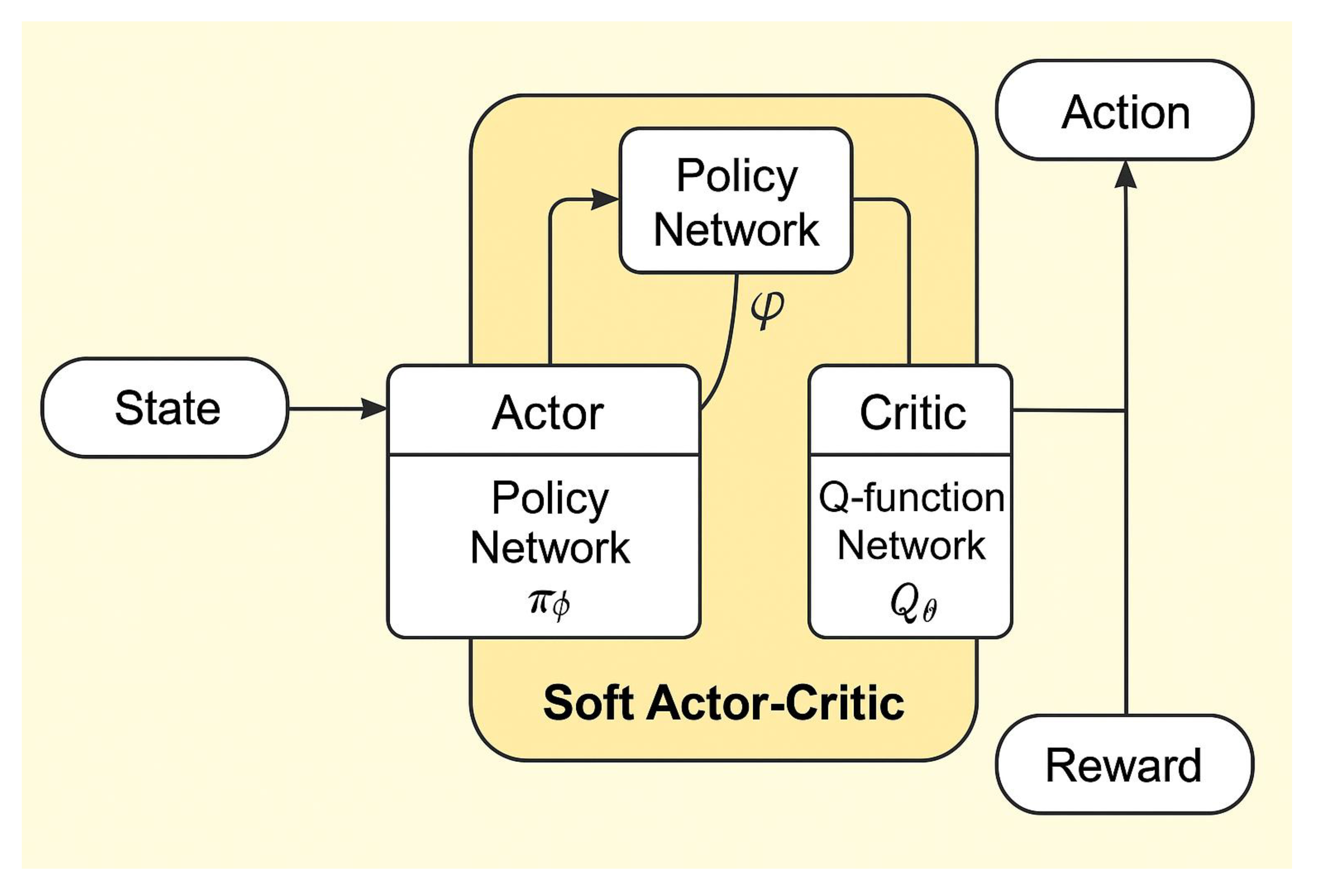
2.3.1. Soft Actor–Critic (SAC) Algorithm Overview
2.3.2. Learning Process with Multimodal Representations
2.3.3. Robot Controller Design
2.4. Integration of Visual–Tactile Fusion and SAC Learning
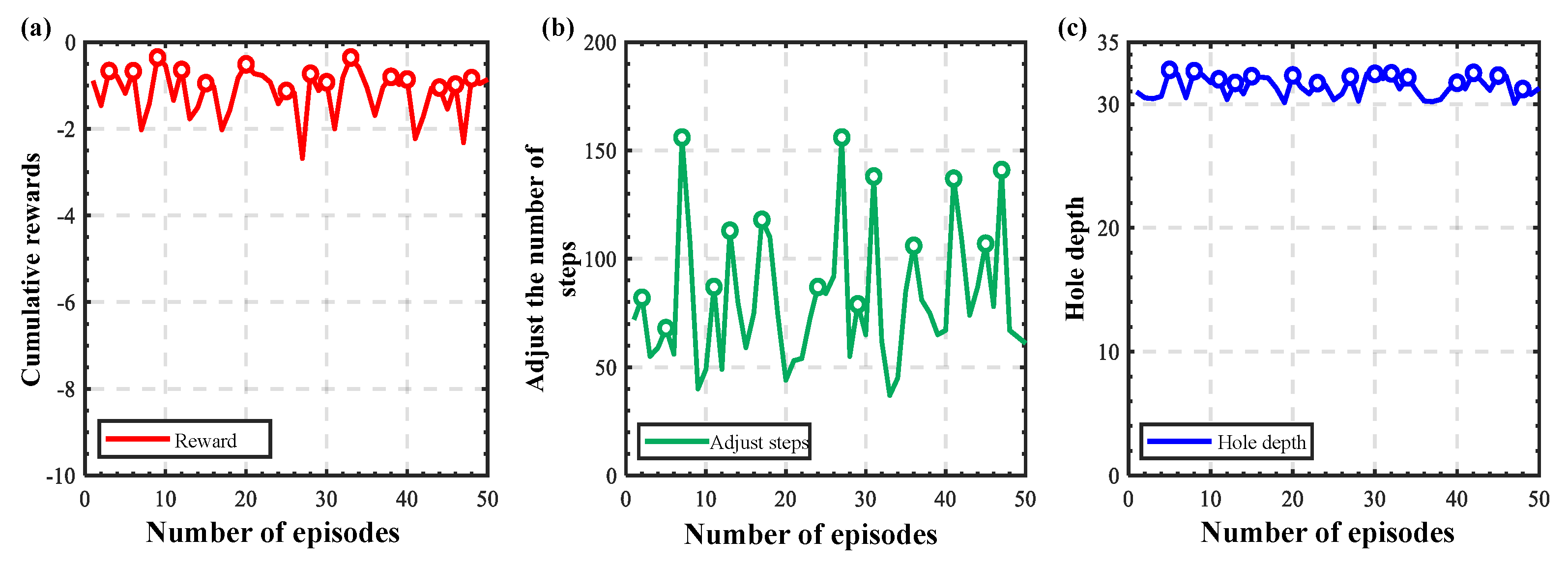
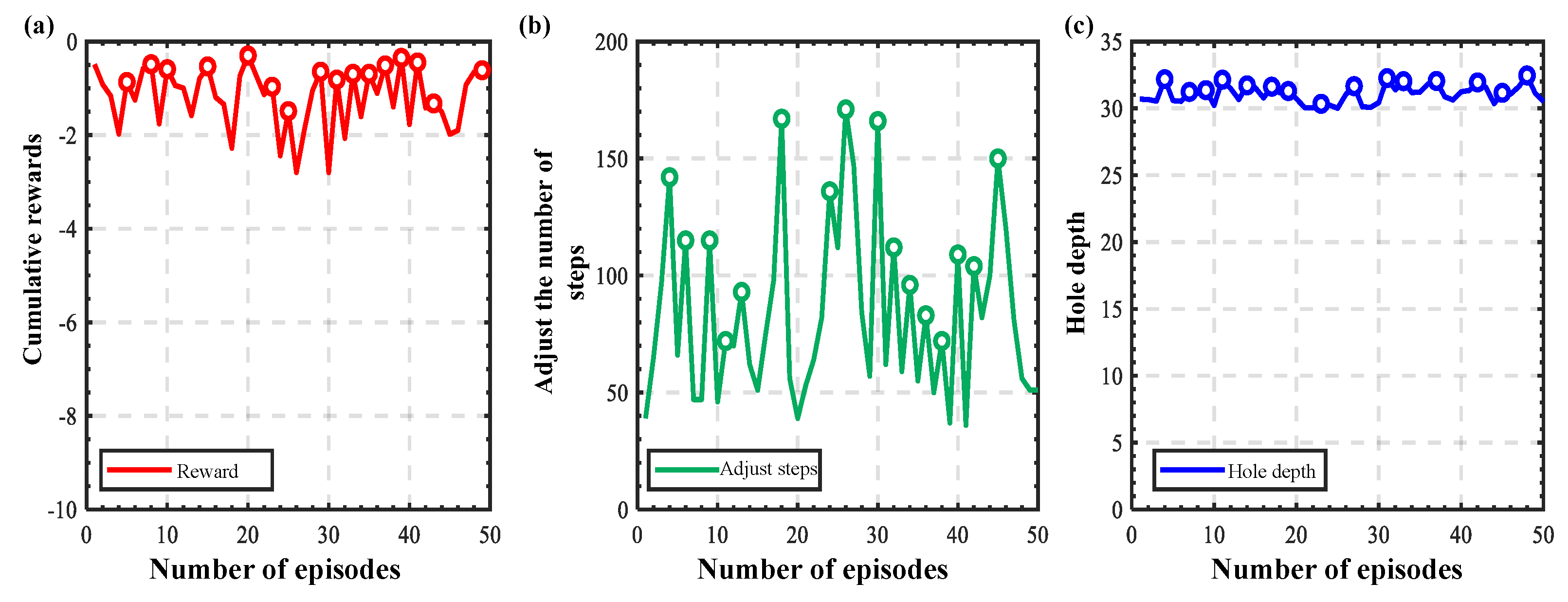
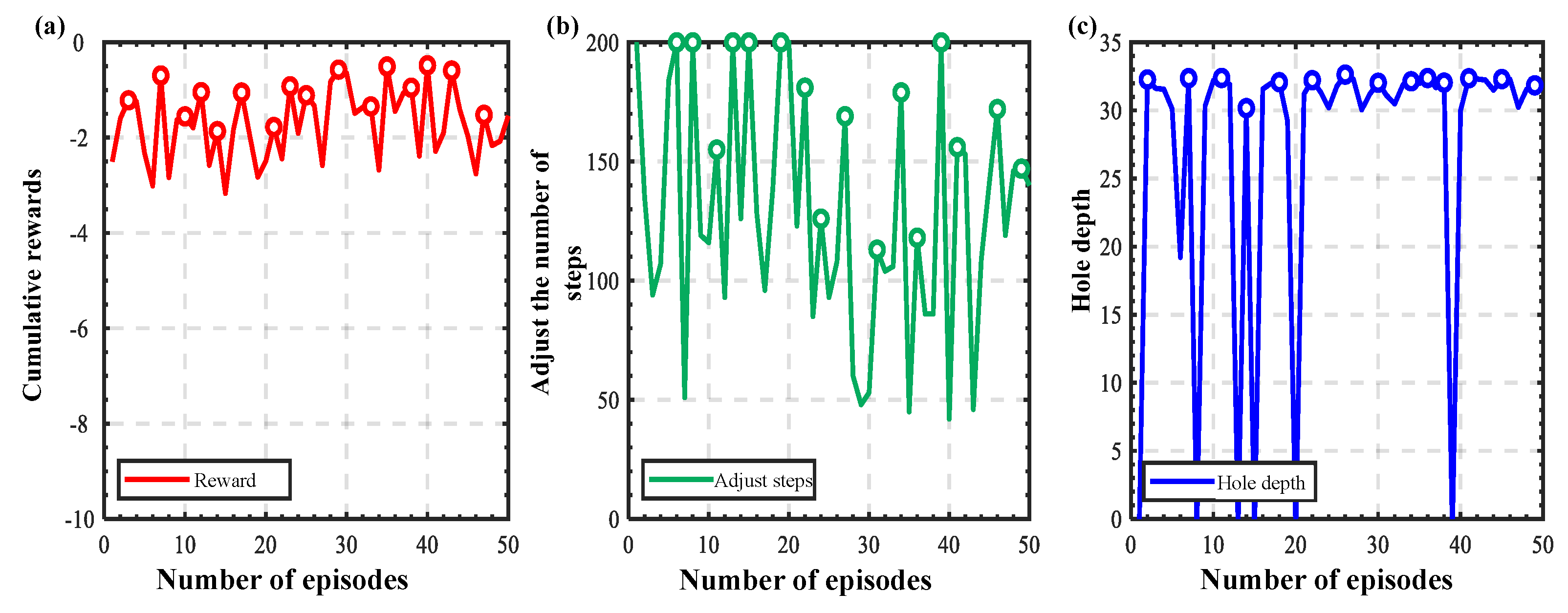
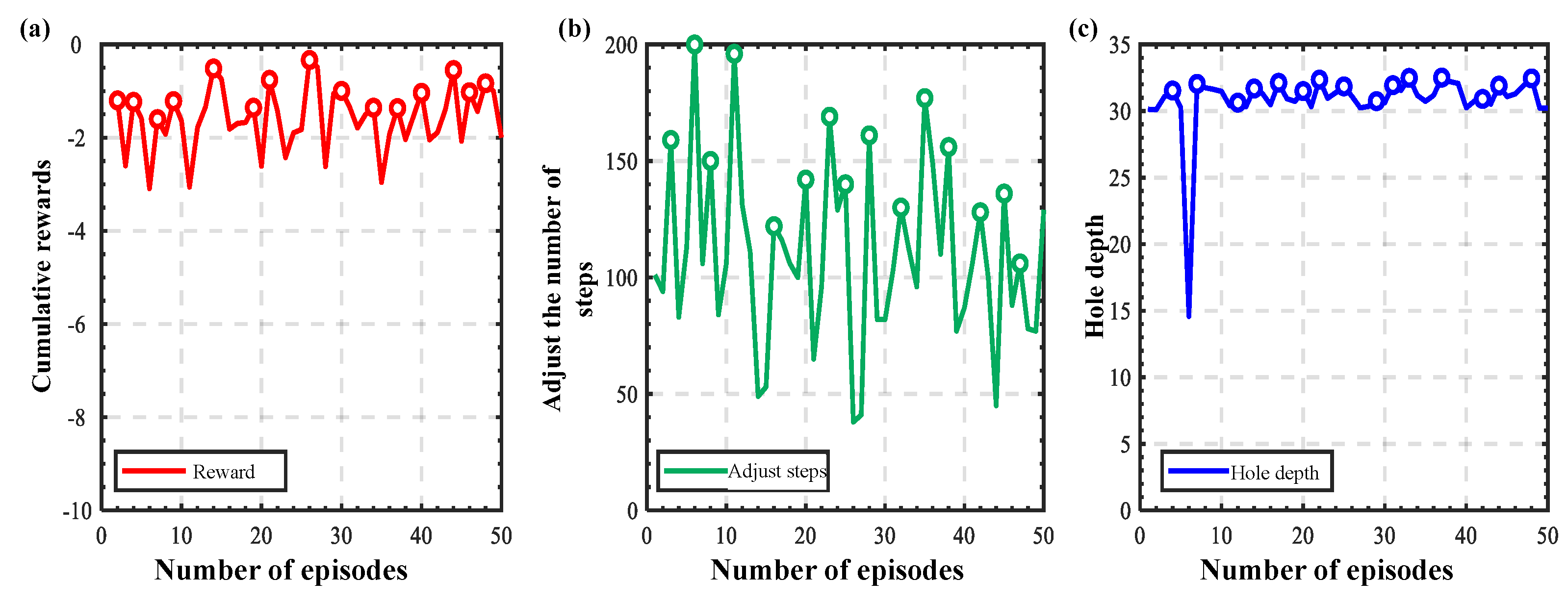
3. Results and Discussion
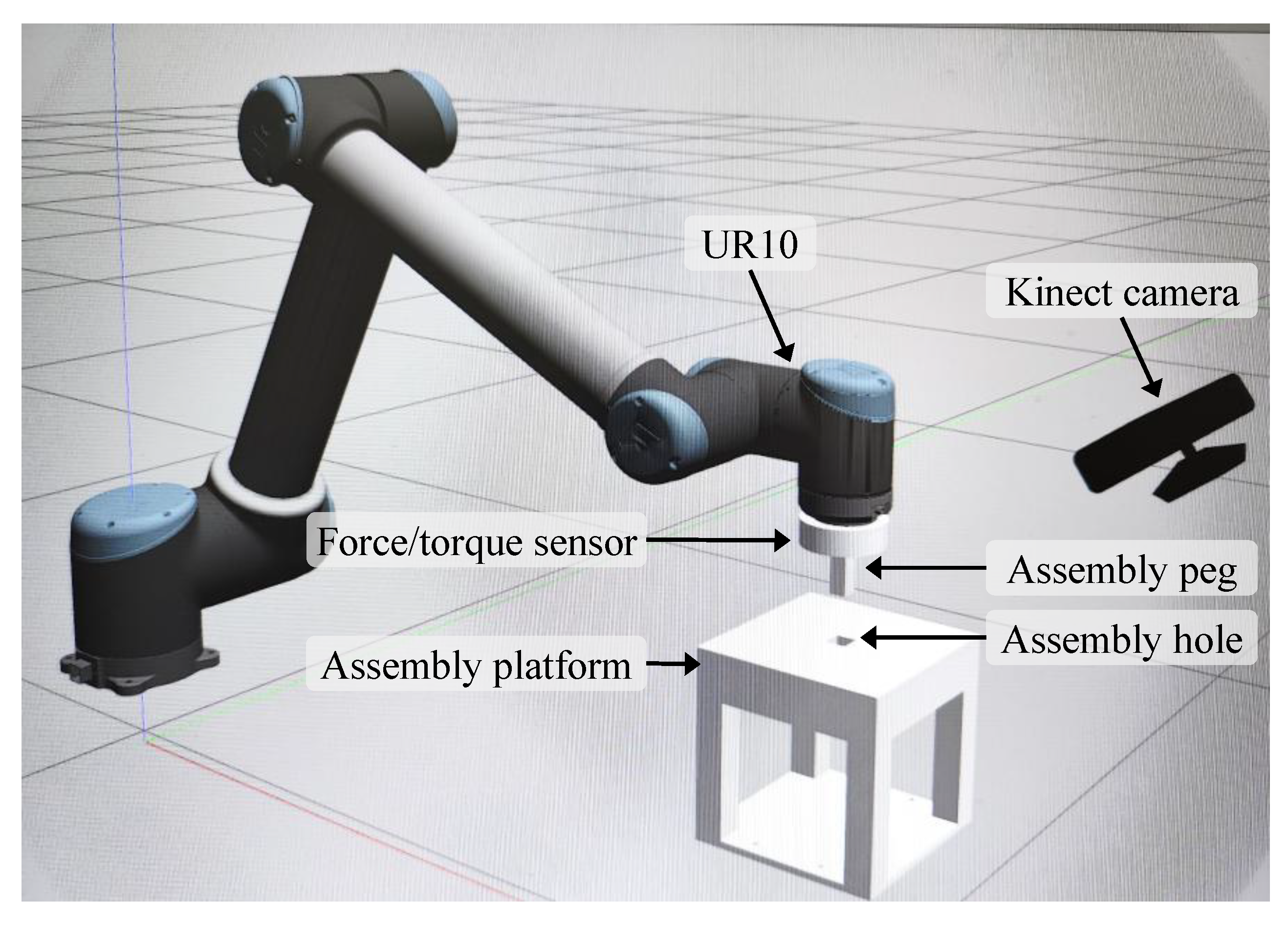
3.1. Experimental Setup
3.2. Experimental Verification
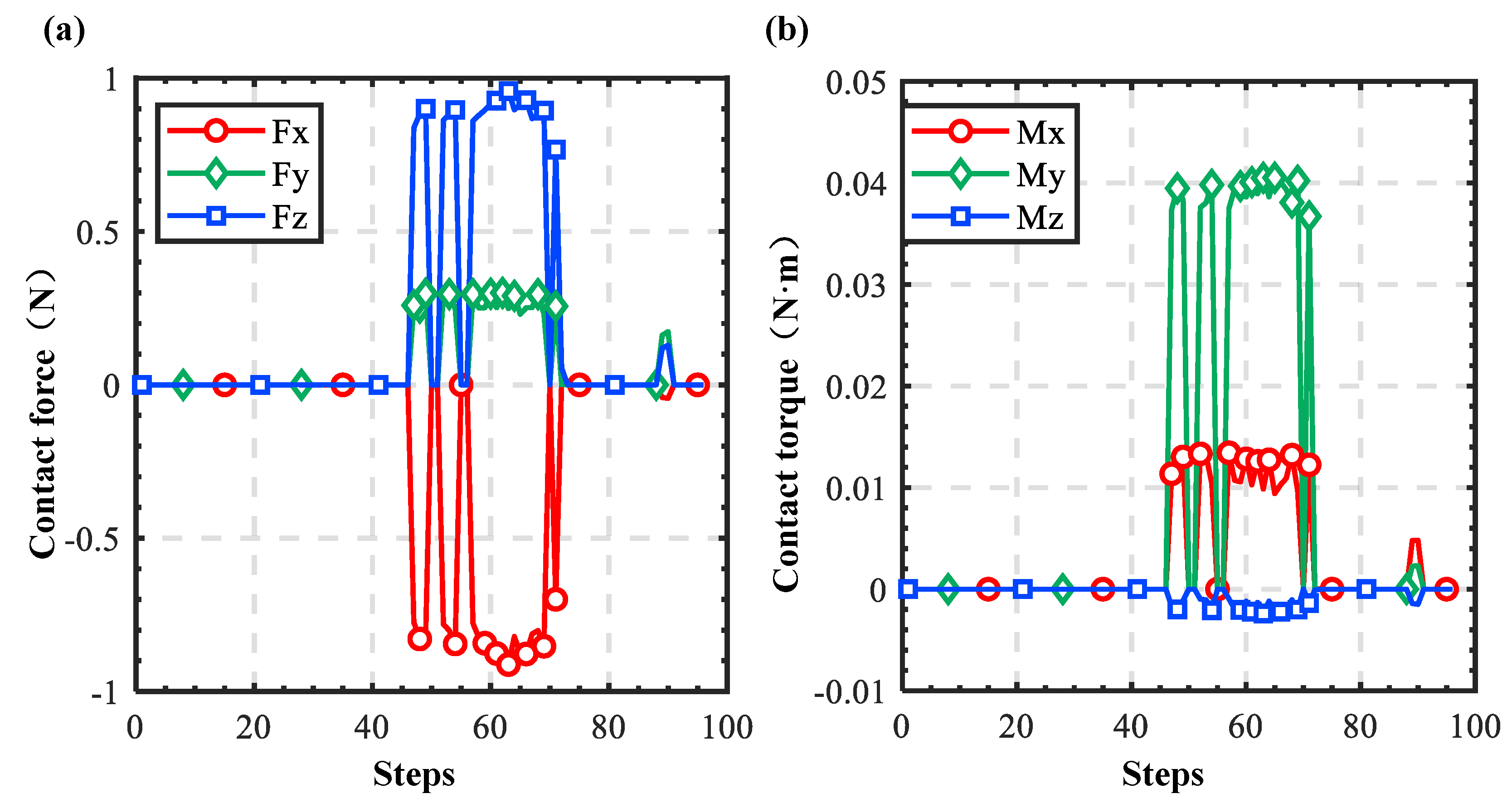
3.2.1. Experimental Verification of Deterministic Model
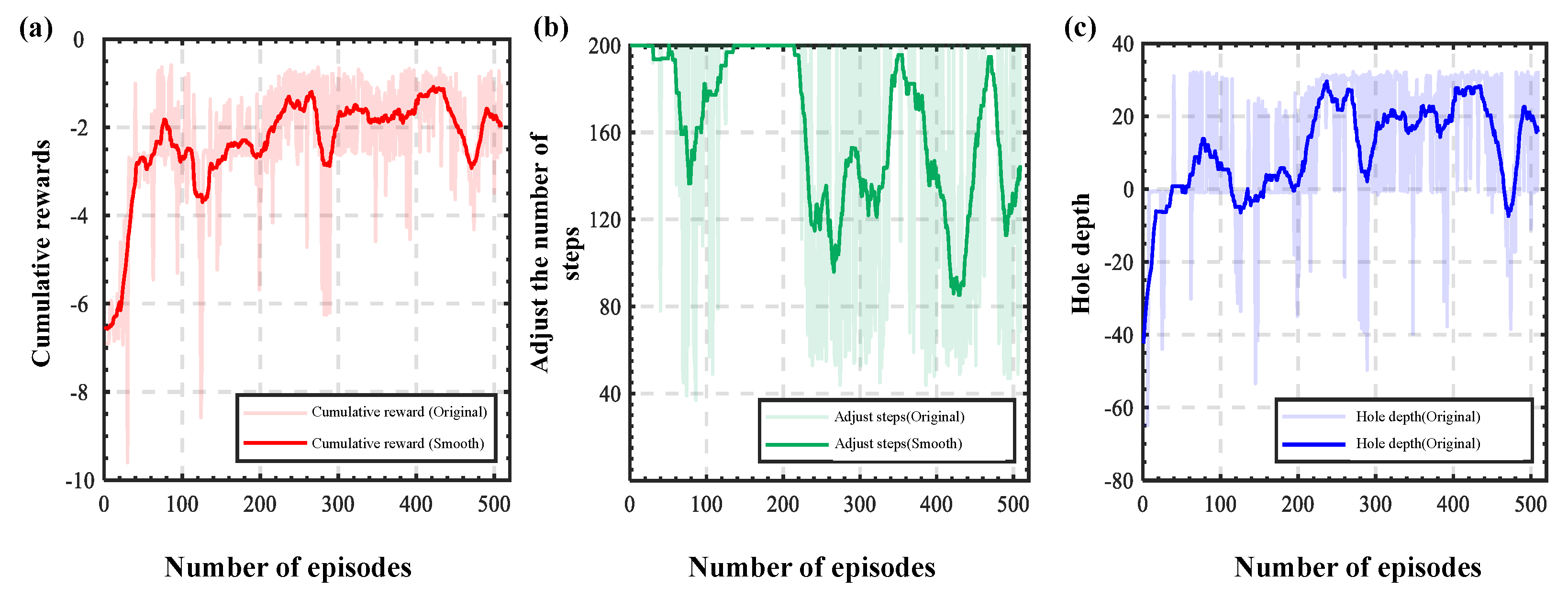
3.2.2. Training and Verification of Peg-in-Hole Strategies
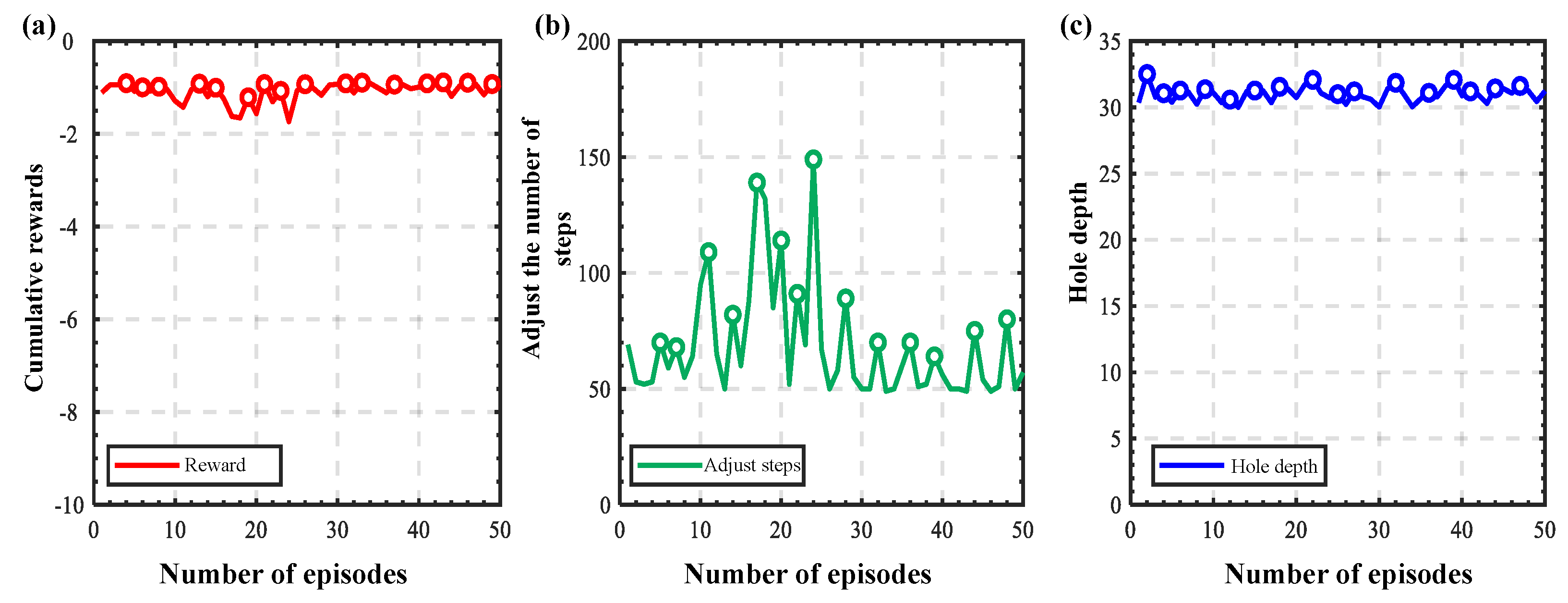
3.2.3. Generalization Experiments at Different Initial Positions
3.2.4. Generalization Experiments for Different Types of Holes
3.2.5. Comparison with Existing Approaches
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shen, L.; Su, J.; Zhang, X. Review on Peg-in-Hole Insertion Technology Based on Reinforcement Learning. In Proceedings of the 2023 China Automation Congress (CAC), Chongqing, China, 17–19 November 2023; pp. 6688–6695. [Google Scholar]
- Xu, J.; Hou, Z.; Liu, Z.; Qiao, H. Compare contact model-based control and contact model-free learning: A survey of robotic peg-in-hole assembly strategies. arXiv 2019, arXiv:1904.05240. [Google Scholar]
- Zhang, X.; Sun, L.; Kuang, Z.; Tomizuka, M. Learning Variable Impedance Control via Inverse Reinforcement Learning for Force-Related Tasks. IEEE Robot. Autom. Lett. 2021, 6, 2225–2232. [Google Scholar] [CrossRef]
- Jiang, J.; Huang, Z.; Bi, Z.; Ma, X.; Yu, G. State-of-the-art control strategies for robotic PiH assembly. Robot. Comput.-Integr. Manuf. 2020, 65, 101894. [Google Scholar] [CrossRef]
- Sun, T.; Liu, H. Adaptive force and velocity control based on intrinsic contact sensing during surface exploration of dynamic objects. Auton. Robot. 2020, 44, 773–790. [Google Scholar] [CrossRef]
- Yan, S.; Xu, D.; Tao, X. Hierarchical policy learning with demonstration learning for robotic multiple peg-in-hole assembly tasks. IEEE Trans. Ind. Inform. 2023, 10, 10254–10264. [Google Scholar] [CrossRef]
- Kim, B.; Choi, M.; Son, S.; Yun, D.; Yoon, S. Vision-force guided precise robotic assembly for 2.5D components in a semistructured environment. Assem. Autom. 2021, 41, 200–207. [Google Scholar] [CrossRef]
- Xu, J.; Liu, K.; Pei, Y.; Yang, C.; Cheng, Y.; Liu, Z. A Noncontact Control Strategy for Circular Peg-in-Hole Assembly Guided by the 6-DOF Robot Based on Hybrid Vision. IEEE Trans. Instrum. Meas. 2022, 71, 3509815. [Google Scholar] [CrossRef]
- Zou, P.; Zhu, Q.; Wu, J.; Xiong, R. Learning-based Optimization Algorithms Combining Force Control Strategies for Peg-in-Hole Assembly. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 7403–7410. [Google Scholar]
- Schoettler, G.; Nair, A.; Luo, J.; Bahl, S.; Ojea, J.A.; Solowjow, E.; Levine, S. Deep reinforcement learning for industrial insertion tasks with visual inputs and natural rewards. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 5548–5555. [Google Scholar]
- Dimeas, F.; Aspragathos, N. Reinforcement learning of variable admittance control for human-robot co-manipulation. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 1011–1016. [Google Scholar]
- Feng, Y.; Shi, C.; Du, J.; Yu, Y.; Sun, F.; Song, Y. Variable admittance interaction control of UAVs via deep reinforcement learning. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 1291–1297. [Google Scholar]
- Kumhar, H.S.; Kukshal, V. A review on reinforcement deep learning in robotics. In Proceedings of the 2022 Interdisciplinary Research in Technology and Management (IRTM), Kolkata, India, 24–26 February 2022; pp. 1–8. [Google Scholar]
- Singh, B.; Kumar, R.; Singh, V.P. Reinforcement learning in robotic applications: A comprehensive survey. Artif. Intell. Rev. 2022, 55, 945–990. [Google Scholar] [CrossRef]
- Elguea-Aguinaco, Í.; Serrano-Muñoz, A.; Chrysostomou, D.; Inziarte-Hidalgo, I.; Bøgh, S.; Arana-Arexolaleiba, N. A review on reinforcement learning for contact-rich robotic manipulation tasks. Robot. Comput.-Integr. Manuf. 2023, 81, 102517. [Google Scholar] [CrossRef]
- Spector, O.; Di Castro, D. InsertionNet: A Scalable Solution for Insertion. IEEE Robot. Autom. Lett. 2021, 6, 5509–5516. [Google Scholar] [CrossRef]
- Ma, Y.; Xie, Y.; Zhu, W.; Liu, S. An Efficient Robot Precision Assembly Skill Learning Framework Based on Several Demonstrations. IEEE Trans. Autom. Sci. Eng. 2023, 20, 124–136. [Google Scholar] [CrossRef]
- Hou, Z.; Fei, J.; Deng, Y.; Xu, J. Data-efficient hierarchical reinforcement learning for robotic assembly control applications. IEEE Trans. Ind. Electron. 2020, 68, 11565–11575. [Google Scholar] [CrossRef]
- Lee, M.A.; Zhu, Y.; Zachares, P.; Tan, M.; Srinivasan, K.; Savarese, S.; Fei-Fei, L.; Garg, A.; Bohg, J. Making sense of vision and touch: Learning multimodal representations for contact-rich tasks. IEEE Trans. Robot. 2020, 36, 582–596. [Google Scholar] [CrossRef]
- Jin, L.; Men, Y.; Song, R.; Li, F.; Li, Y.; Tian, X. Robot Skill Generalization: Feature-Selected Adaptation Transfer for Peg-in-Hole Assembly. IEEE Trans. Ind. Electron. 2024, 71, 2748–2757. [Google Scholar] [CrossRef]
- Hua, J.; Zeng, L.; Li, G.; Ju, Z. Learning for a robot: Deep reinforcement learning, imitation learning, transfer learning. Sensors 2021, 21, 1278. [Google Scholar] [CrossRef]
- Whitney, D.E.; Rourke, J.M. Mechanical behavior and design equations for elastomer shear pad remote center compliances. J. Dyn. Syst. Meas. Control 1986, 108, 223–232. [Google Scholar] [CrossRef]
- Asada, H.; Kakumoto, Y. The dynamic RCC hand for high-speed assembly. In Proceedings of the 1988 IEEE International Conference on Robotics and Automation, Philadelphia, PA, USA, 24–29 April 1988; pp. 120–125. [Google Scholar]
- Sturges, R.H.; Laowattana, S. Fine motion planning through constraint network analysis. In Proceedings of the IEEE International Symposium on Assembly and Task Planning, Pittsburgh, PA, USA, 10–11 August 1995; pp. 160–170. [Google Scholar]
- Zhang, Q.; Hu, Z.; Wan, W.; Harada, K. Compliant Peg-in-Hole Assembly Using a Very Soft Wrist. IEEE Robot. Autom. Lett. 2023, 9, 17–24. [Google Scholar] [CrossRef]
- Choi, S.; Kim, D.; Kim, Y.; Kang, Y.; Yoon, J.; Yun, D. A Novel Compliance Compensator Capable of Measuring Six-Axis Force/Torque and Displacement for a Robotic Assembly. IEEE/ASME Trans. Mechatron. 2023, 29, 29–40. [Google Scholar] [CrossRef]
- Xu, X.; Zhu, D.; Zhang, H.; Yan, S.; Ding, H. Application of novel force control strategies to enhance robotic abrasive belt grinding quality of aero-engine blades. Chin. J. Aeronaut. 2019, 32, 2368–2382. [Google Scholar] [CrossRef]
- Solanes, J.E.; Gracia, L.; Munoz-Benavent, P.; Esparza, A.; Miro, J.V.; Tornero, J. Adaptive robust control and admittance control for contact-driven robotic surface conditioning. Robot. Comput.-Integr. Manuf. 2018, 54, 115–132. [Google Scholar] [CrossRef]
- Lu, S.; Zhang, X.; Wu, C.; Wang, H. Kinematics and dynamics analysis of the 3PUS-PRU parallel mechanism module designed for a novel 6-DOF gantry hybrid machine tool. J. Mech. Sci. Technol. 2020, 34, 345–357. [Google Scholar] [CrossRef]
- Lu, S.; Zhang, X.; Wu, C.; Wang, H. Minimum-jerk trajectory planning pertaining to a translational 3-DOF parallel manipulator through piecewise quintic polynomials interpolation. Adv. Mech. Eng. 2020, 12, 168781402091366. [Google Scholar] [CrossRef]
- Chhatpar, S.R.; Branicky, M.S. Search strategies for peg-in-hole assemblies with position uncertainty. In Proceedings of the 2001 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Maui, HI, USA, 29 October–3 November 2001; pp. 1465–1470. [Google Scholar]
- Sharma, K.; Shirwalkar, V.; Pal, P.K. Intelligent and Environment-Independent Peg-In-Hole Search Strategies. In Proceedings of the 2013 International Conference on Control, Automation, Robotics and Embedded Systems (CARE-2013), Jabalpur, India, 16–18 December 2013. [Google Scholar]
- Newman, W.S.; Zhao, Y.H.; Pao, Y.H. Interpretation of force and moment signals for compliant peg-in-hole assembly. In Proceedings of the 2001 IEEE International Conference on Robotics and Automation, Seoul, Republis of Korea, 21–26 May 2001; pp. 571–576. [Google Scholar]
- Sharma, K.; Shirwalkar, V.; Pal, P.K. Peg-In-Hole search using convex optimization techniques. Ind. Robot. Int. J. 2017, 44, 618–628. [Google Scholar] [CrossRef]
- Chernyakhovskaya, L.B.; Simakov, D.A. Peg-on-hole: Mathematical investigation of motion of a peg and of forces of its interaction with a vertically fixed hole during their alignment with a three-point contact. Int. J. Adv. Manuf. Technol. 2020, 107, 689–704. [Google Scholar] [CrossRef]
- Wu, W.; Liu, K.; Wang, T. Robot assembly theory and simulation of circular-rectangular compound peg-in-hole. Robotica 2022, 40, 1–34. [Google Scholar] [CrossRef]
- Luo, Z.; Li, J.; Bai, J.; Wang, Y.; Liu, L. Adaptive hybrid impedance control algorithm based on subsystem dynamics model for robot polishing. In Proceedings of the 2019 Intelligent Robotics and Applications (ICIRA), Shenyang, China, 8–11 August 2019; Springer: Cham, Switzerlan, 2019; pp. 163–176. [Google Scholar]
- Jin, Z.; Qin, D.; Liu, A.; Zhang, W.; Yu, L. Model predictive variable impedance control of manipulators for adaptive precision-compliance tradeoff. IEEE/ASME Trans. Mechatron. 2022, 28, 1174–1186. [Google Scholar] [CrossRef]
- Gai, Y.; Guo, J.; Wu, D.; Chen, K. Feature-based compliance control for precise peg-in-hole assembly. IEEE Trans. Ind. Electron. 2021, 69, 9309–9319. [Google Scholar] [CrossRef]
- Huang, J.; Chen, S.; Zheng, W.; Su, P.; Li, J.; Zheng, J.; Liang, Y.; Xiao, H.; Peng, Y.; Huang, Z. Fuzzy Adaptive Compliance Control Method for Charging Manipulator. In Proceedings of the 2023 IEEE International Conference on Mechatronics and Automation (ICMA), Harbin, China, 6–9 August 2023; pp. 992–997. [Google Scholar]
- Lee, D.; Choi, M.; Park, H.; Jang, G.; Park, J.; Bae, J. Peg-in-Hole Assembly with Dual-Arm Robot and Dexterous Robot Hands. IEEE Robot. Autom. Lett. 2022, 7, 8566–8573. [Google Scholar] [CrossRef]
- Hao, P.; Lu, T.; Cui, S.; Wei, J.; Cai, Y.; Wang, S. Meta-Residual Policy Learning: Zero-Trial Robot Skill Adaptation via Knowledge Fusion. IEEE Robot. Autom. Lett. 2022, 7, 3656–3663. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
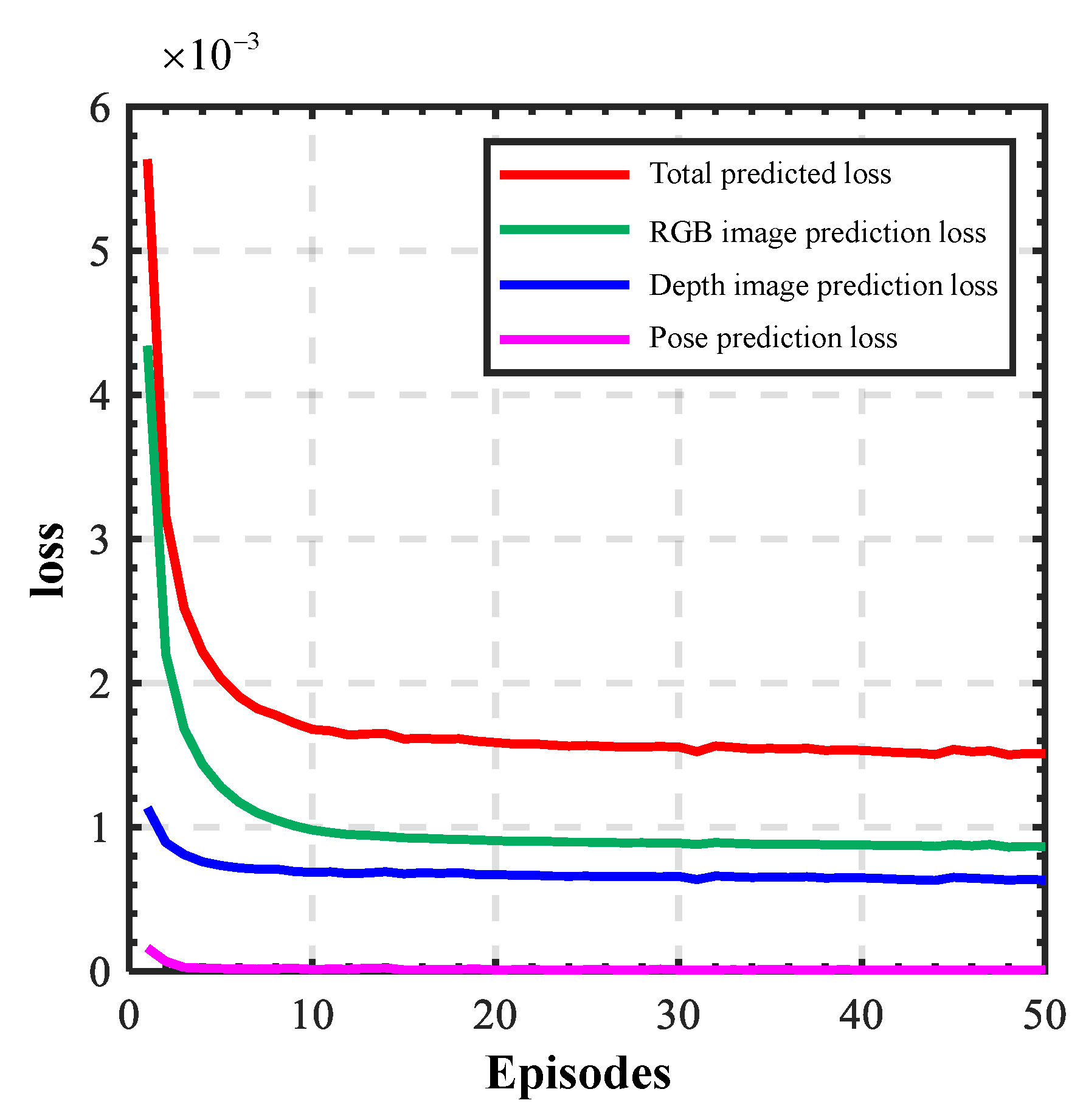
| Parameter | Loss Value |
|---|---|
| Total predicted loss | |
| RGB prediction loss | |
| Depth prediction loss | |
| Pose prediction loss |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, J.; Yuan, X.; Li, S. Visual–Tactile Fusion and SAC-Based Learning for Robot Peg-in-Hole Assembly in Uncertain Environments. Machines 2025, 13, 605. https://doi.org/10.3390/machines13070605
Tang J, Yuan X, Li S. Visual–Tactile Fusion and SAC-Based Learning for Robot Peg-in-Hole Assembly in Uncertain Environments. Machines. 2025; 13(7):605. https://doi.org/10.3390/machines13070605
Chicago/Turabian StyleTang, Jiaxian, Xiaogang Yuan, and Shaodong Li. 2025. "Visual–Tactile Fusion and SAC-Based Learning for Robot Peg-in-Hole Assembly in Uncertain Environments" Machines 13, no. 7: 605. https://doi.org/10.3390/machines13070605
APA StyleTang, J., Yuan, X., & Li, S. (2025). Visual–Tactile Fusion and SAC-Based Learning for Robot Peg-in-Hole Assembly in Uncertain Environments. Machines, 13(7), 605. https://doi.org/10.3390/machines13070605