1. Introduction
The rail fastening system (hereinafter referred to as ‘fastener’), as a vital part of the track structure, serves to connect the rail and the underlying supporting structure. It performs functions such as fixing the rail position and providing elastic support to the rail, thus playing a crucial role in ensuring the stability and smoothness of the track structure as well as the safe operation of trains [
1,
2,
3].
The fastener is primarily composed of three categories of components: the spring clip, the bolt, and the rail pad, and its functions are achieved through the coordination among these individual parts, as depicted in
Figure 1. Under the long-term combined effects of cyclic train dynamic loads and complex and variable environmental loads, some typical damage and degradation issues have been exposed in fasteners currently in operation, e.g., fracture, missing and rotation of spring clips [
4,
5], protrusion and breakage of bolts [
6,
7], as well as aging and crushing of rail pads [
8], etc. Such issues will lead to the attenuation or loss of fastening pressure and elastic support performance, thereby reducing the integrity and stability of the track structure, causing local damage or even overall failure of the track structure, ultimately deteriorating ride quality and endangering running safety. Therefore, the detection of the service condition of fasteners has always been a research focus.
Traditional fastener defect detection methods heavily rely on manual periodic inspections and empirical judgments, resulting in temporal discontinuity, spatial gaps, and lack of rigor in diagnosis. In recent years, with the rapid development of computer technology, intelligent detection of fastener defects has become a current research hotspot. Wang et al. [
9] transformed the original image into HOG feature vectors and subsequently generated left–right and up–down symmetrical images, respectively, and finally achieved the detection of defective fasteners. The detection of missing fasteners was conducted through combining the stability of the fastener edge contours and template matching with curve feature projection [
10]. Hu et al. [
11] identified and located loose fasteners by utilizing a temporal Bayesian approach in conjunction with track vibration data. Fan et al. [
12] proposed an image recognition method optimized by an IFOA algorithm on the basis of an improved SVM model, which was subsequently applied to the abnormal monitoring of fasteners. Considerable progress has been made in the research of fastener defect detection using the aforementioned methods. Nevertheless, several pressing issues remain to be addressed. For instance, the recognition of numerous edge feature points on some fasteners results in a complex sorting and iteration process. Secondly, Bayesian algorithms can be sensitive to outliers and noise when processing vibration data, and the presence of significant interference or abnormalities in the data can lead to the accumulation of errors, thereby affecting the detection accuracy. Additionally, due to the diversity of shapes and backgrounds, it is challenging to manually design accurate and robust features for fastener components using SVM models, consequently hindering the improvement of detection precision.
Nowadays, research on fastener defect detection based on deep learning technologies has emerged continuously, with object detection methods serving as the primary representative. One type of method is based on the end-to-end one-stage algorithm, primarily represented by the YOLO series of models [
13]. For example, Hsieh et al. [
14] implemented the detection of missing and fracture of spring clips by applying the YOLOv4Tiny model. Li et al. [
15] proposed a novel method for detecting fastener defects by introducing the CBAM attention mechanism and a weighted bidirectional feature pyramid network on the basis of the YOLOv5s model. Meanwhile, Cai et al. [
16] presented the FSS-YOLO detection model by improving the YOLOv5n model, which combines the morphological characteristics of fastener bolts to achieve rapid detection of bolt defects. The aforementioned methods have demonstrated remarkable advantages in fastener defect detection owing to their fast detection speed and ease of implementation and deployment. However, due to the fact that these methods generally require only one forward propagation to complete detection, there may be certain limitations in terms of localization accuracy, particularly when dealing with clustered targets, where their performance still needs further enhancement and optimization.
Another type of method involves the two-stage algorithm based on target candidate regions [
17], which exhibits good robustness and high accuracy in complex scenarios. For instance, Bai et al. [
18] proposed an optimized detection method based on an improved Faster R-CNN model, achieving effective localization of fastener defects. Moreover, Shang et al. [
19] shifted the focus from qualitative analysis of fasteners to more accurate quantitative analysis by introducing an advanced image segmentation network model, namely Mask-FRCN. Nevertheless, it is noteworthy that due to the pixel-level segmentation processing involved in such two-stage algorithms, their computational complexity is relatively high, which to some extent limits the application in scenarios requiring high real-time object detection.
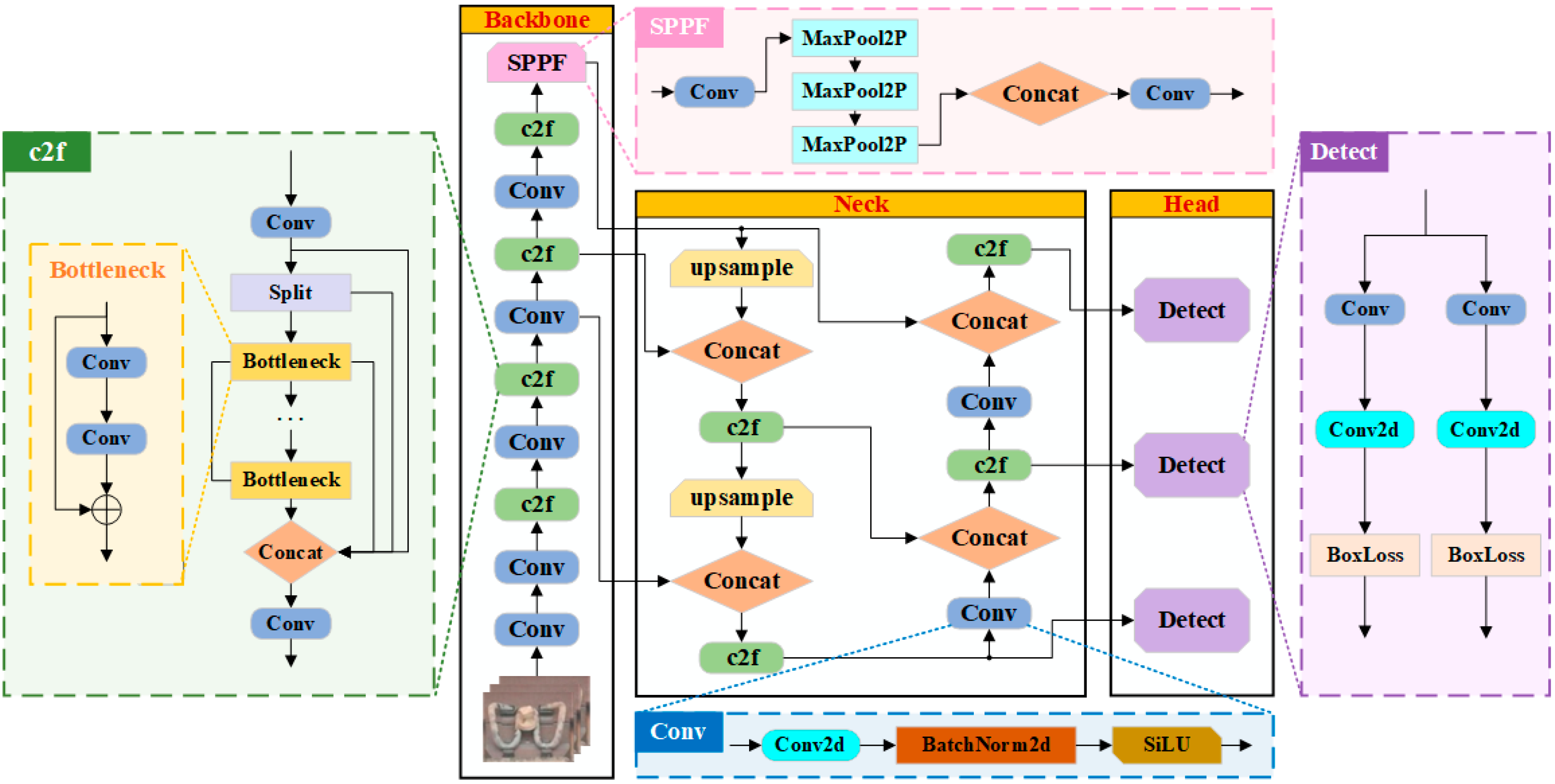
The YOLO series models have developed rapidly in the field of object detection [
20,
21]. Notably, the YOLOv8 [
22] model stands out as the primary representative of the current YOLO series due to its advanced training methodology, high training efficiency, and robust generalization capability. To address the object detection tasks in complex and diverse real-world scenarios, the YOLOv8 model has been devised with multiple size variants, spanning various scales including n, s, m, l, and x, catering to a wide range of requirements from lightweight to high-performance. Among them, the YOLOv8n model, with its relatively compact size, boasts not only high detection accuracy but also the fastest detection speed, making it particularly suitable for tasks that demand extreme real-time performance. In light of this, this study focuses on the real-time detection of fastener defects, and an improved model namely YOLOv8n-Fastener Defect Detection (YOLOv8n-FDD) is developed, which is derived from and tailored based on the original YOLOv8n model, aiming to achieve high-precision and efficient detection of multiple common types of fastener defects.
4. Experiments and Results
4.1. Experimental Environment and Parameter Setting
The hardware and software configurations related to the experiments conducted in this paper are shown in
Table 2.
To ensure a clear comparison with the original YOLOv8n model, the hyperparameter values of the proposed improved model YOLOv8n-FDD, are set to be largely consistent with the default settings of the YOLOv8n model, as detailed in
Table 3.
4.2. Evaluation Metrics
In this study, a comprehensive evaluation of the proposed model’s performance is systematically conducted across four key dimensions: object detection accuracy, inference speed, model memory foodprint, and computational complexity.
In terms of detection accuracy, evaluation metrics commonly used in the field of object detection are selected, including precision, recall, and mean Average Precision (mAP).
Precision, represented by
P, measures the proportion of samples predicted by the model as follows:
where
TP denotes the number of true positives, and
FP denotes the number of false positives.
Recall, represented by
R, measures the ability of the model to correctly identify positive samples, i.e., the proportion of instances that the model is able to identify as positive when they are truly positive, as defined in Equation (20):
where
FN denotes the number of false negatives.
mAP, considers the Average Precision (AP) at different recall levels to provide a more comprehensive reflection of the overall performance of the model. mAP is calculated by averaging the AP values of all categories at a fixed IoU threshold (notably, the IoU threshold is set to 0.5 in this paper), as shown in Equation (21):
where
ncat is the number of categories and
APi is the average precision for samples belonging to the
ith category.
Inference speed is commonly assessed using the frames-per-second (FPS) metric, which quantifies the rate at which a model can process sequential image frames within a one-second interval.
Model memory footprint is defined as the model size, evaluated by examining the storage requirements of the final trained model, representing the actual memory space needed for deployment.
Computational complexity is analyzed through Floating Point Operations (FLOPs), which approximate the theoretical arithmetic intensity by counting the number of multiply–accumulate operations required for a single inference pass.
4.3. Model Training and Performance Analysis
The preprocessed dataset is randomly divided into training, validation, and testing sets at a ratio of 8:1:1. Subsequently, both the YOLOv8n model and the improved YOLOv8n-FDD model proposed in this paper are trained on the training set for 300 epochs. The results of the training process are illustrated in
Figure 13.
Figure 13a compares the changes in loss values between the YOLOv8n model and the YOLOv8n-FDD model during the training process. It can be observed that as the number of epochs increases, the loss values of both models continuously decrease. In the first 25 epochs, the loss values of the two models are relatively close and both decrease rapidly. However, starting from the 26th epoch, the loss value of the YOLOv8n-FDD model gradually becomes smaller than that of the YOLOv8n model. After the 50th epoch, the loss values of both models tend to stabilize, and ultimately the YOLOv8n-FDD model stabilizes at 0.104.
Figure 13b compares the changes in mAP values during the training process between the YOLOv8n model and the YOLOv8n-FDD model. It can be seen that the mAP values increase consistently as the number of epochs progresses. For the first 35 epochs, the mAP values of both models are almost the same, while after the 35th epoch, the mAP value of the YOLOv8n-FDD model begins to surpass that of the YOLOv8n model. After the 100th epoch, the convergence rate of both models slows down until they stabilize. In the end, the YOLOv8n-FDD model achieves a peak mAP value of 0.961.
Figure 14 demonstrates the comparison of detection accuracy of the improved model, YOLOv8n-FDD, for different types of fastener defects on the test set. Firstly, it is evident that for the entire test set comprising samples from six fastener categories, the YOLOv8n-FDD model achieves 0.963, 0.941, and 0.961 in terms of P, R, and mAP, respectively. Furthermore, further observation reveals that for the normal categories, e-normal and w-normal, the P, R, and mAP values of the YOLOv8n-FDD model are slightly higher than the other four defect categories. Meanwhile, it is worth noting that the mAP values of the YOLOv8n-FDD model for each type of fastener reach more than 0.95, indicating that the YOLOv8n-FDD model fully meets the requirements for detecting fastener defects.
4.4. Comparative Experiments on Improvement Points
4.4.1. Attention Mechanisms
To analyze the impact of different attention mechanisms on the performance of the YOLOv8n model, MHSA [
41], CBAM [
42], and the CA mechanism modules are individually incorporated into the backbone structure of the YOLOv8n model. Four sets of comparative experiments are conducted under the same experimental conditions. The first group serves as the control group without adding any attention mechanism. The comparison results of model performance under different attention mechanism modules are presented in
Table 4.
As can be seen from
Table 4, the detection accuracy of the improved model with the addition of the CA mechanism shows a significant increase compared to the original YOLOv8n model. Furthermore, compared to the other two attention mechanism modules, the YOLOv8n + CA model still performs the best in detection accuracy, with mAP being 1.4% and 0.4% higher than the YOLOv8n+MHSA model and YOLOv8n + CBAM model, respectively. However, in terms of the FPS and model size, the values corresponding to the three attention mechanism modules remain the same. Certainly, the FLOPs value increases when the attention mechanism is incorporated. However, compared to the other two attention mechanisms, the FLOPs value remains the smallest when the CA mechanism is employed. Consequently, adding CA mechanism is more helpful in improving the accuracy of fastener defect detection.
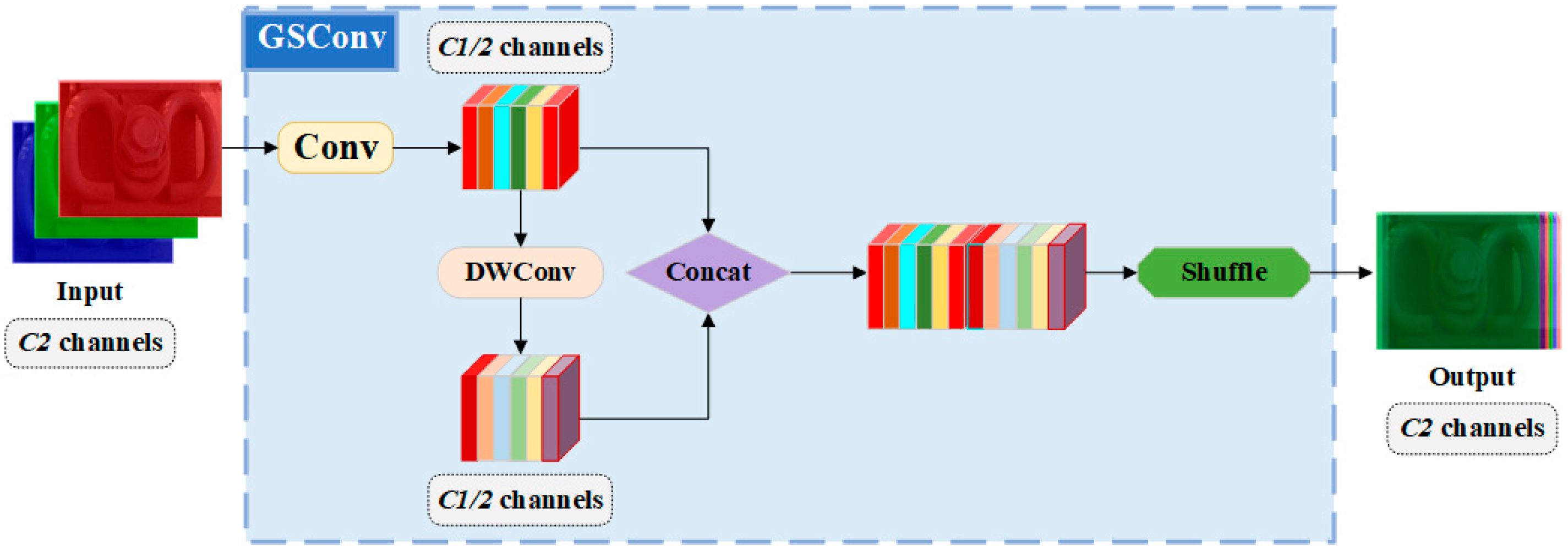
4.4.2. Model Lightweighting Modules
To investigate the effect of the model lightweighting modules introduced in
Section 2.2.2 of this paper on the performance of the YOLOv8n model, two sets of comparative experiments are carried out under same experimental conditions. The comparison results are shown in
Table 5.
From
Table 5, it is evident that compared to the original YOLOv8n model, the improved model with the addition of the lightweighting modules achieves a decrease in model size and FLOPs, subsequently resulting in an increase in detection speed. Specifically, the FPS increased by about 20%. Concurrently, the detection accuracy of the improved model is also enhanced, with the mAP value of the YOLOv8n + GSConv + VoVGSPCP model exceeding that of the YOLOv8n model by 1.5%. Thus, adding lightweighting modules has proven effective in improving the overall performance of fastener defect detection.
4.4.3. Bounding Box Loss Functions
To validate the effect of different bounding box loss functions on the performance of the YOLOv8n model, three widely used bounding box loss functions in the field of object detection, namely CIoU, DIoU [
43], and EIoU [
44], are adopted here and compared with the WIoU bounding box loss function introduced in
Section 2.2.3. The comparison results of model performance are presented in
Table 6.
It can be observed from
Table 6 that compared with the YOLOv8n + CIOU model, the detection accuracy of the YOLOv8n+WIoU model has been improved. In addition, the mAP value of the YOLOv8n + WIoU model is 0.7% and 0.2% higher than that of the YOLOv8n+DIoU and YOLOv8n + EIoU models, respectively, when compared to the other two bounding box loss functions. In terms of the FPS, model size, as well as FLOPs, the values corresponding to the three bounding box loss functions are the same. Hence, adopting the WIoU bounding box loss function is also more effective in enhancing the accuracy of fastener defect detection.
4.5. Comparative Experiments of Different Models
To further verify the superiority of the improved model proposed in this paper, based on the same software, hardware environment, and fastener defect dataset, the YOLOv8n-FDD model is compared with the existing mainstream object detection models, including SSD [
45], YOLOv3u [
22], YOLOv4 [
22], YOLOv6n [
22], and YOLOv8n. The detection performances of each model are presented in
Table 7.
As evident from
Table 7, in terms of detection accuracy, the mAP of the YOLOv8n-FDD model can reach 0.961, which represents a 2% improvement over YOLOv8n and 8.8%, 4.8%, 4%, and 2.8% improvements, respectively, over SSD, YOLOv3u, YOLOv4, and YOLOv6n models. In terms of detection speed, model size, and computational complexity, the YOLOv8n-FDD model demonstrates significant advantages. Specifically, the presented model achieves an FPS of 91, representing an increase of 8 compared to the baseline model YOLOv8n. Its model size is only 6.0 MB, which is 0.2 MB smaller than that of YOLOv8n. The FLOPs value of the model is 7.4, indicating a reduction of 0.7 compared to YOLOv8n. When compared to models such as SSD, YOLOv3u, YOLOv4, and YOLOv6n, the YOLOv8n-FDD model achieves varying degrees of optimization across these three metrics. Summarily, for the fastener defect dataset, compared with other object detection models, the improved model proposed in this paper performs better in detection accuracy, detection speed, model size, and computational complexity.
In addition, to demonstrate that the improved model proposed in this paper is not only applicable to the fastener defect dataset but also other data, a generalization experiment is conducted by comparing the YOLOv8n-FDD model with the YOLOv8n model on two classic public datasets in the field of object detection: VOC2007 [
46] and COCO128 [
25]. The performance comparison results are shown in
Table 8. It can be clearly seen that the detection performance of the YOLOv8n-FDD model is superior to that of the YOLOv8n model on both public datasets, indicating the universality of the proposed improvement scheme, which can be applied to detection tasks of diverse objects.
4.6. Visualization Results Analysis
To intuitively demonstrate the superiority of the improved model proposed in this paper in terms of detection performance, a visual comparison of the detection results between the original YOLOv8n model and the YOLOv8n-FDD model on the test set is presented here. The specific results are shown in
Figure 15, where the left and right images represent the detection results of the YOLOv8n model and the YOLOv8n-FDD model, respectively.
Specifically, it can be observed in
Figure 15a that when detecting w-normal fasteners, the YOLOv8n model exhibits false detections, mistakenly identifying a bolt located outside the fastener position as an e-normal fastener. Similarly, in
Figure 15b, the YOLOv8n model once again misclassifies a w-normal fastener as a w-missing fastener, revealing its limitations in distinguishing similar objects against complex backgrounds. In contrast, in
Figure 15c, when detecting w-missing fasteners, both models are able to achieve accurate recognition and localization, but the YOLOv8n-FDD model outputs a higher confidence level, demonstrating its superior detection certainty and robustness. Lastly, in
Figure 15d, when detecting a w-rotation fastener with rotated morphology, the YOLOv8n model again experiences a false detection, incorrectly identifying it as a w-fracture fastener. Conversely, the YOLOv8n-FDD model accurately recognizes the w-rotation fasteners, indicating its superior feature extraction and adaptability.
In summary, for the detection of different types of fastener defects, the proposed improved model YOLOv8n-FDD exhibits lower false detection rate, higher classification accuracy, and stronger robustness compared to the original YOLOv8n model.
5. Concluding Remarks
This paper focuses on the task of fastener defect detection. By selecting the current advanced object detection model, YOLOv8n, and improving upon it, a YOLOv8n-FDD model specifically designed for fastener defect detection is proposed and the high accuracy and real-time detection of various types of fastener defects is conducted.
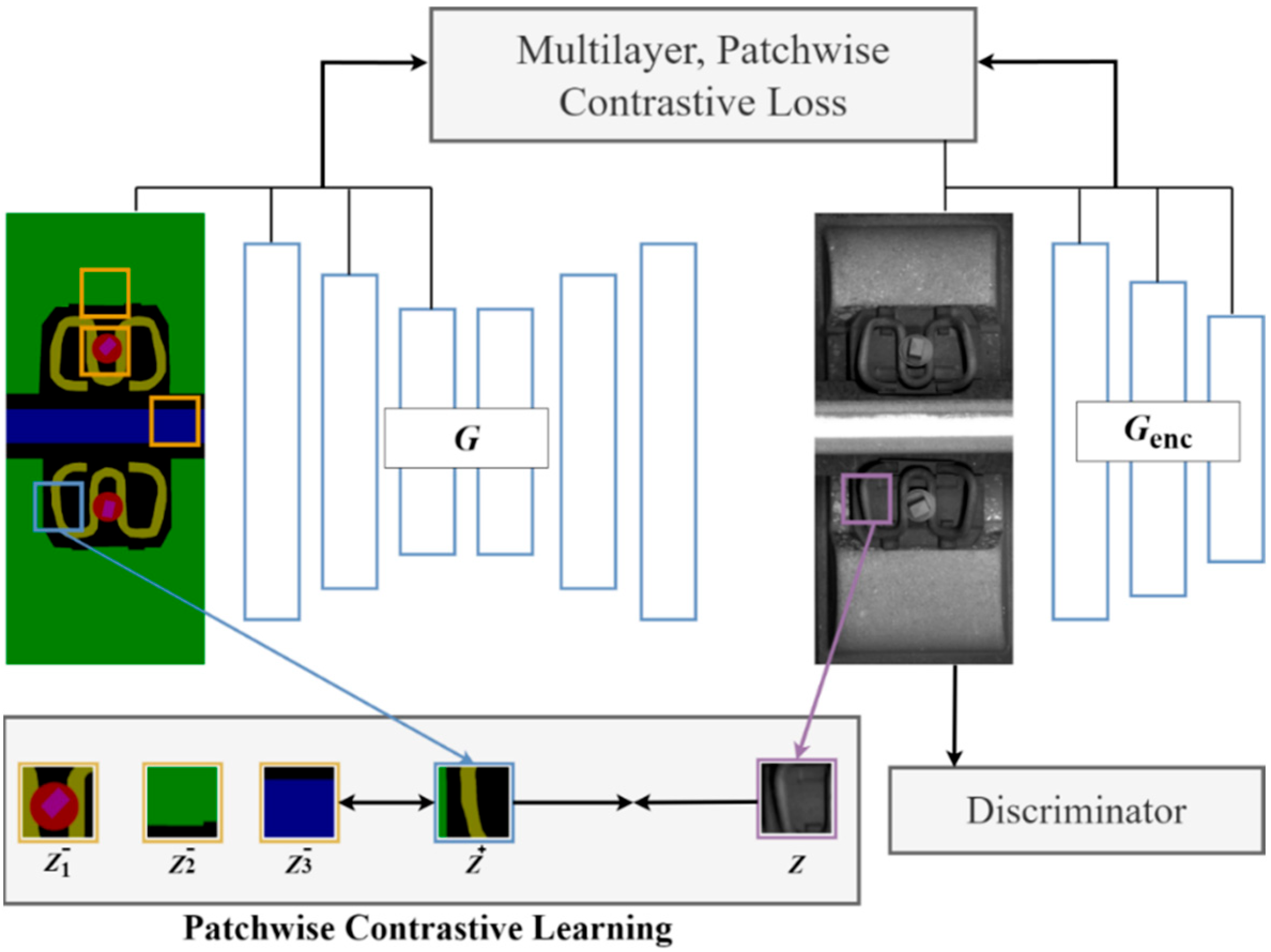
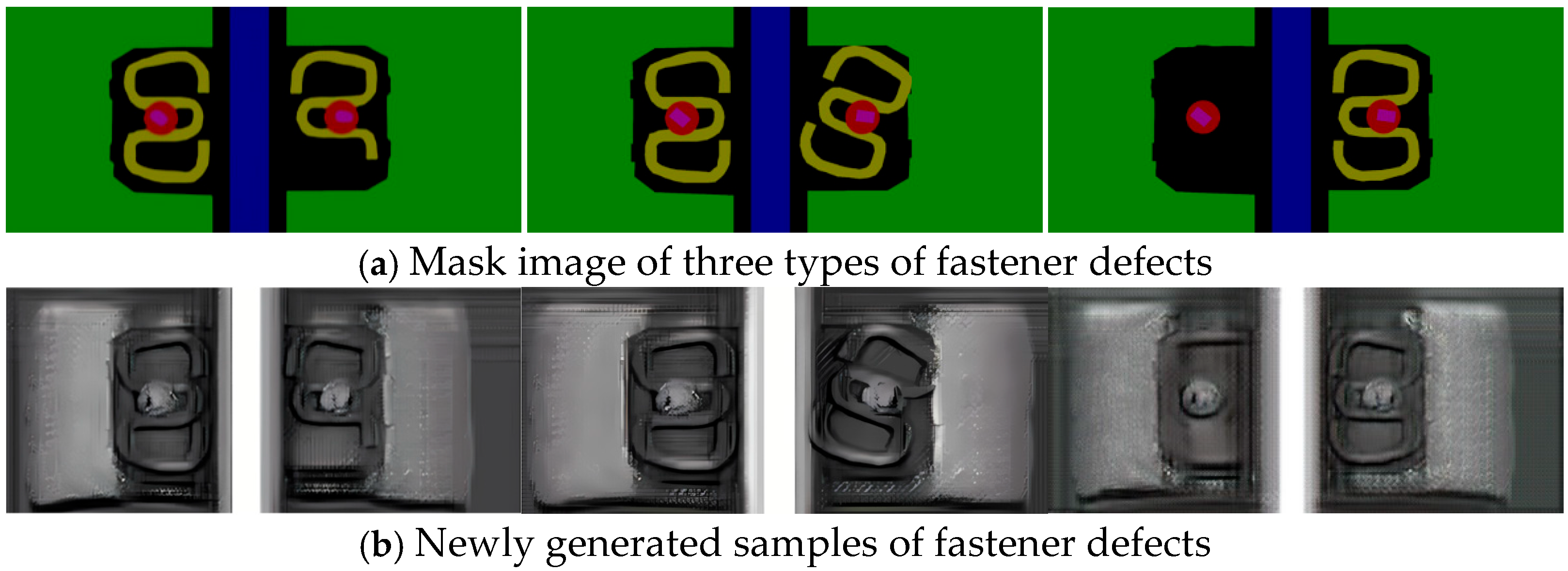
Firstly, to enhance detection accuracy, the CA mechanism is incorporated into the backbone structure of the original YOLOv8n model, thereby optimizing detection performance. Secondly, with respect to the detection efficiency, the traditional Conv module in the backbone structure and the c2f module in the neck structure of the YOLOv8n model are, respectively, replaced with the GSConv and VoVGSPCP modules, effectively reducing the computational complexity of the YOLOv8n-FDD model and achieving model lightweighting. Finally, by upgrading the bounding box loss function of the YOLOv8n model from CIoU to WIoU, the YOLOv8n-FDD model’s generalization ability and overall detection performance in handling complex scenarios are further improved. Additionally, a fastener dataset containing two types of normal fasteners and four types of defective fasteners is established and subsequently preprocessed by the fastener defect sample generation strategy based on the CUT style transfer model, effectively addressing the issue of imbalance distribution in sample categories.
Through comparative experimental validation, the addition of the CA mechanism and the selection of WIoU as the bounding box loss function both contribute to an improvement in detection accuracy compared to the YOLOv8n model. Meanwhile, the introduction of the GSConv and VoVGSPCP modules optimizes the detection speed while reducing both the model size and computational complexity. When benchmarked against other mainstream object detection models, the proposed improved model exhibits superior performance across key metrics. Specifically, the YOLOv8n-FDD model achieves a mAP of 96.1%, a throughput of 91 FPS, a model size of 6 MB, and a computational complexity of 7.4 billion FLOPs.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}