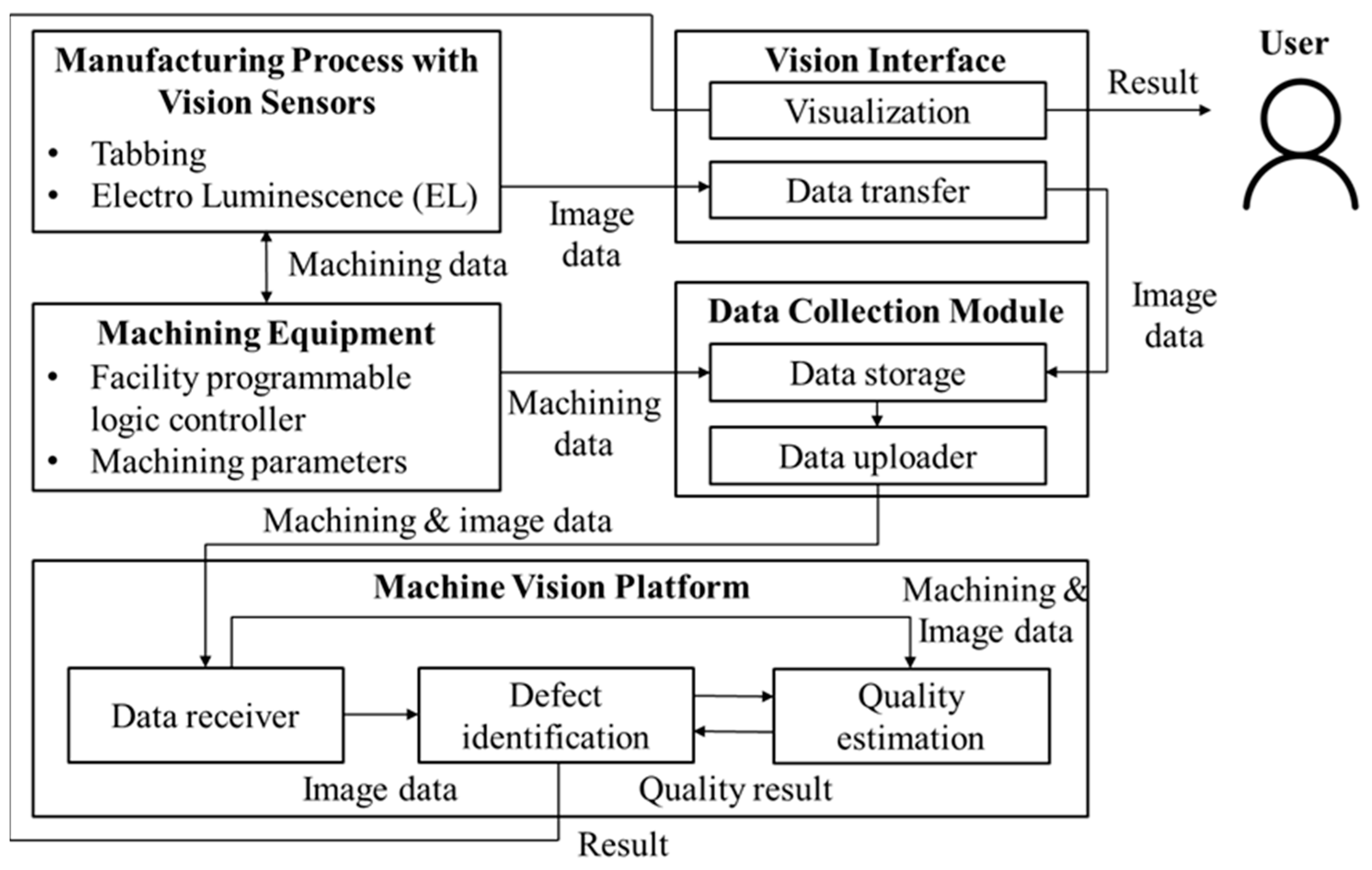
The PV module images collected by the vision sensors are transmitted to the data collection module through the interface and stored in the database for real-time defective product detection and judgment, subsequent artificial intelligence algorithm learning, and product quality management. During this process, the PV module manufacturing environment information (machining parameters and PLC control information) provided by the manufacturing equipment is also stored in the database. Image data acquired through the machine vision are transmitted to the data collection module in real time through IoT (Internet of Things). In particular, the IoT is developed as an appliance consisting of manufacturing analysis data collection and protocol standardization functions by utilizing the Edge box gateway. This appliance standardizes structured and unstructured data generated in the module manufacturing process and classifies them into a specific type of analysis dataset. In addition, it includes a middleware operating system for storing relational databases (RDBMSs), time series databases (TSDBs), and file systems (File DBs) depending on the data characteristics. The stored machining and image data are transferred to the machine vision platform, and in this process, the Quality Estimation and Defect Identification modules are responsible for extracting defective products using artificial intelligence. These modules analyze images to detect defective products with different patterns from existing products and make predictions about possible defective products. It utilizes the real-time inference function, which is a key function that can quickly discover the effects of introduction by applying artificial intelligence to the manufacturing site [
33]. By combining real-time process data and inspection (image) data, a big data-based learning model is created, and the convolutional neural network (CNN)-based inference engine functions to enable immediate anomaly detection and quality prediction in the manufacturing field (see
Section 2.3.1 and
Section 2.3.2 for details). This field data inference framework is used as a tool for rapid problem-solving by detecting various and complex causes of defects that interfere with production in advance. Ultimately, the machine vision platform has the function of checking the PV module components and detecting defective products by comparing their characteristics with normal products.
2.3.1. Defect Detection in the EL (Electroluminescence) Operation
In EL operation, a three-step machine learning model is applied to detect defects. First, in the pre-processing stage, an original image is subjected to geometric image transformation operations such as centering and data augmentation to ensure that only the regions with cells are selected. Second, the unsupervised anomaly segmentation technique is used to detect cells that are different from the normal PV cells [
34]. Third comes the classification of defected PV cells into four categories, such as crack, dark spot and dark area, and solder dark defects. The purpose of anomaly detection (or one-class learning) is to learn the distribution of normal samples so that when abnormal samples come in, they can be classified outside the learned distribution (i.e., outlier or anomaly detection) [
35]. One characteristic of this is that it can significantly improve classification performance by combining a small number of abnormal data during the model learning process. In order to learn about the characteristics of normal cells at position (
i,
j) in an image, let
be the set of embedding vectors for position (
i,
j) learned through
N normal cell images [
36]. If
follows a multivariate Gaussian distribution
with sample mean
and sample covariance
, the set of embedding vectors for location (
i,
j) can be summarized as shown in Equation (2). Notice that
serves as a normalization term to make
full rank and invertible.
Figure 5 represents the anomaly detection of a PV cell. If
, which is the Mahalanobis distance described in Equation (3), is greater than the threshold (θ), it is considered an outlier (i.e., abnormal PV cell).
In general, the Mahalanobis distance is an unsupervised method that is used to calculate the distance between two points, similar to the Euclidean distance, but it calculates it by finding the inverse matrix of the covariance calculated from collected data.
refers to the distance in the probability distribution of how far the observed value (
) is from the original mean (
) at (
i,
j). Since high scores on this map indicate anomalous areas, the final anomaly score for the entire image is the maximum value of the anomaly map, with defective components having high values.
Figure 6 shows the average distribution of grayscale image values for 84 normal product images and 74 defective product images collected in the EL process. It can be seen that the abnormal products have a larger observation probability value from 180 to 210 on average, showing a difference in distribution from the normal products. The Mahalanobis distance calculation result, according to Equation (3), shows that the defective product images have a value greater than 0.00022. Based on this threshold (θ = 0.00022), defective products can be differentiated from normal products.
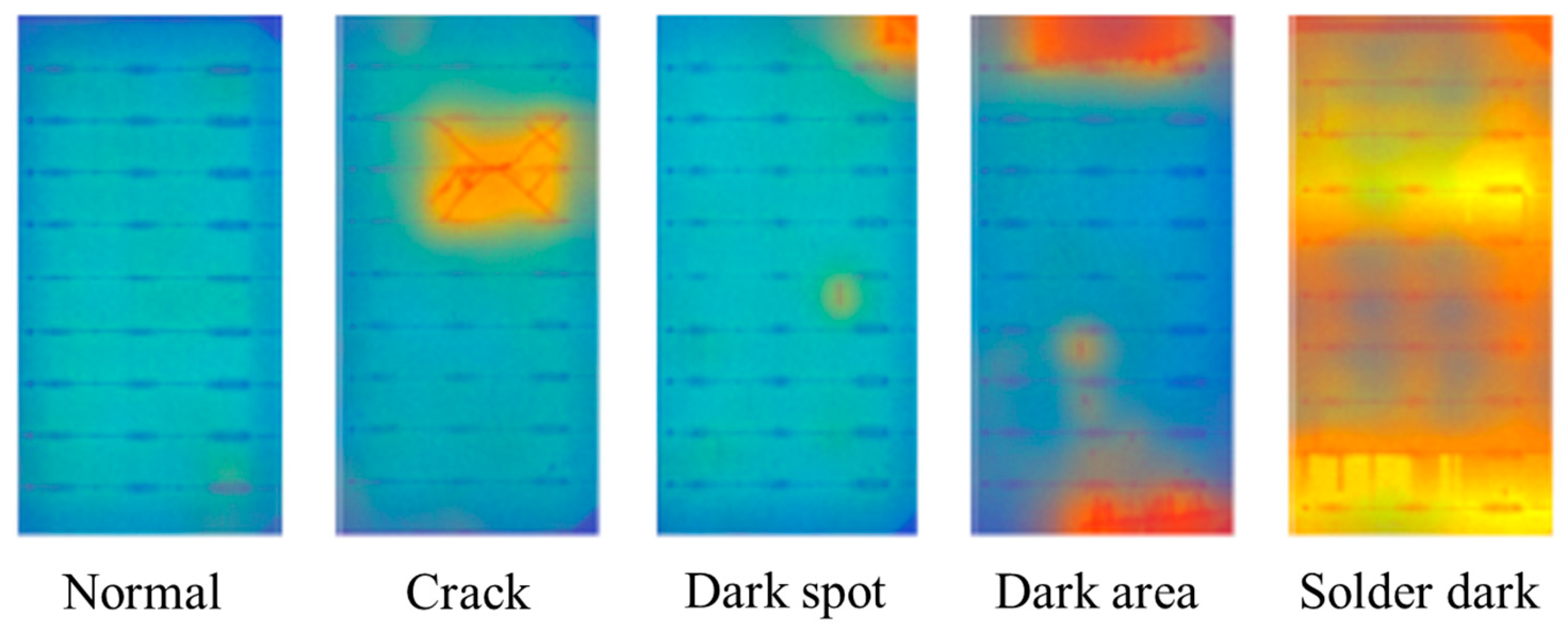
For the classification of abnormal PV cell images, ResNet50, which is a well-known deep learning model used in computer vision tasks [
34], is adopted. As shown in
Figure 7, defective components are classified into cracks, dark spots and dark areas, and solder dark defects. The sky blue color indicates a healthy part, while the orange color indicates where a defect has occurred in the part.
2.3.2. Defect Detection in the Tabbing Operation
Similar to the EL operation in
Section 2.3.1, in the pre-processing stage, geometric image transformation operations such as centering and data augmentation are applied to the original image so that only the region of interest (RoI) is extracted. Additionally, the wire shape and number of lines are extracted to conduct a rule-based defect classification. The rule-based classifier continuously receives new information and processes it according to features they have already learned; particularly, the deep neural network model enables them to efficiently conduct the classification [
37]. As shown in
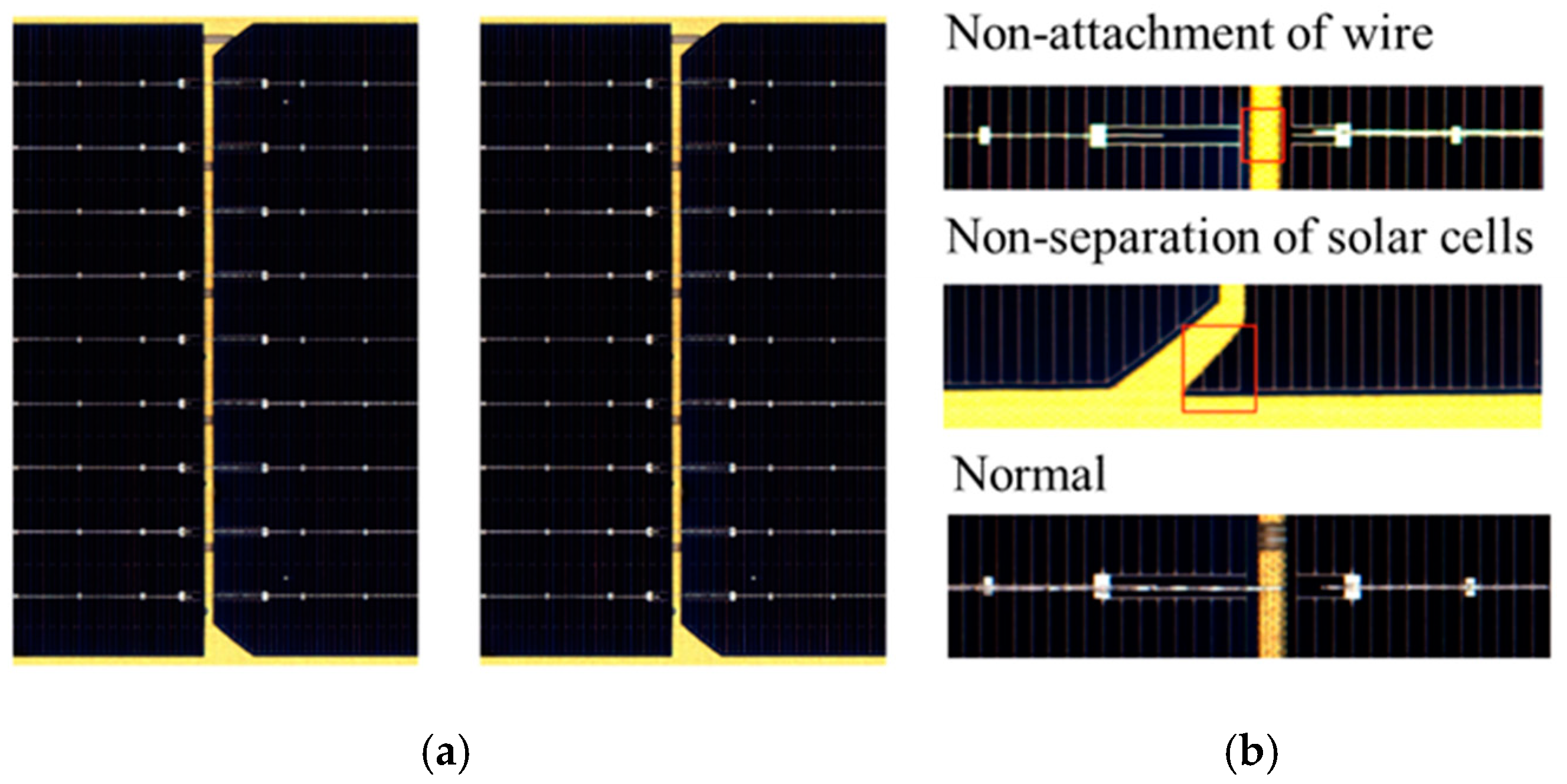
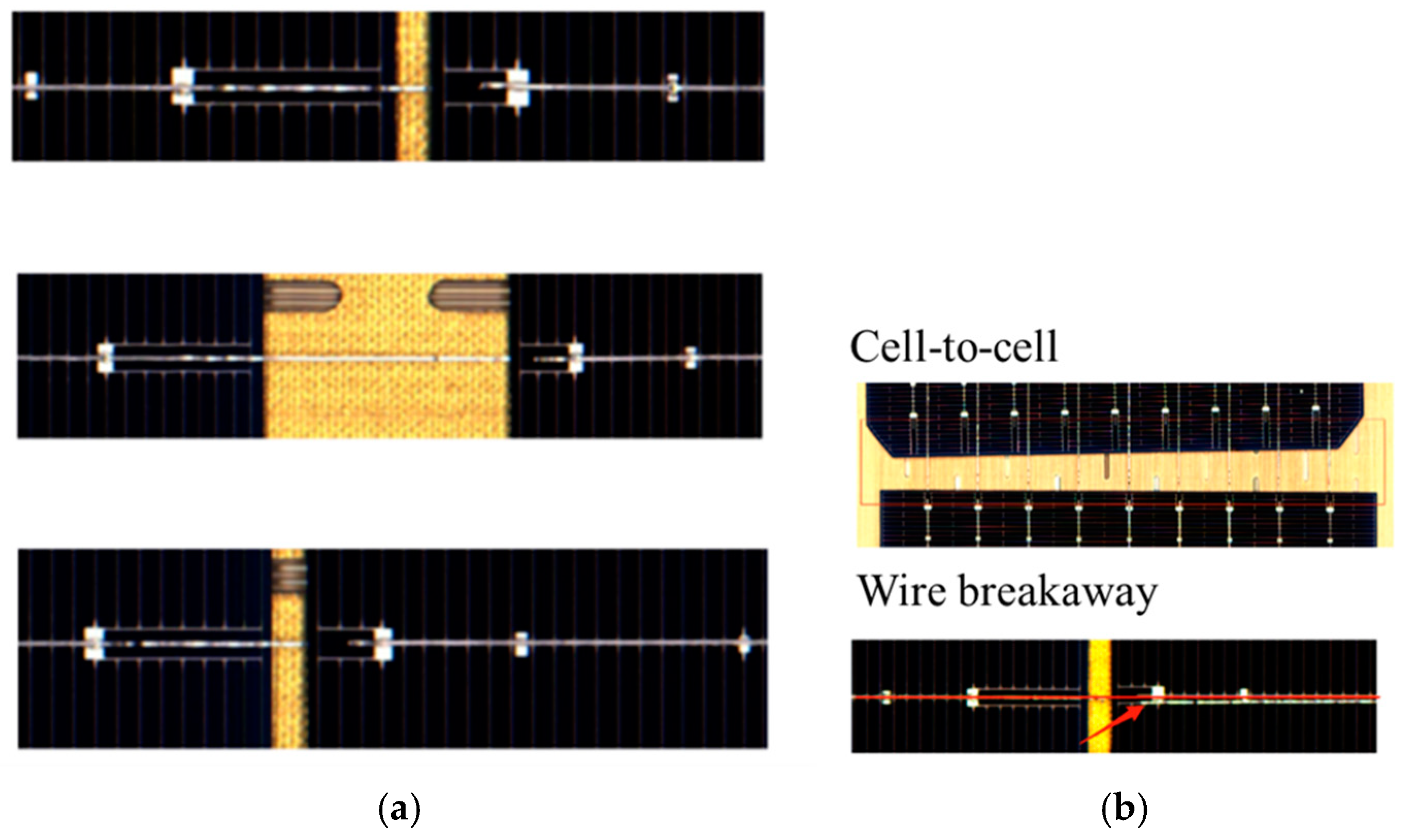
Figure 8, in the tabbing operation, the attachment of wires, separation of solar cells, and classification of normal PV panels are determined. The red box indicates the location where the defect is detected in
Figure 8.
For the anomaly detection, class-imbalance learning is conducted to consider cases with different numbers of data samples. In fact, most machine learning models are established on the assumption that the ratio of data volume between classes is similar. However, if the imbalance is large during model learning, the learning is biased toward the class with a large number of data samples. For example, in binary classification such as vision images, when there are 90% of samples in the good class and 10% of samples in the bad class, classification performance can be improved by learning by balancing the number of data between classes. The random oversampling technique [
38] is used with Equation (4) to add samples to the minority class by copying existing samples at random.
is the ratio of adding samples;
is the number of added samples;
is the number of images of normal products; and
is the number of images of abnormal products (i.e., defects). This cluster-based over-sampling (CBO) can deal with between-class and within-class imbalance simultaneously so that the detection performance for defective products can be improved even though the over-fitting issue may happen [
39].
Based on the balanced classes, the proposed machine vision platform performs the object detection using a convolutional neural network (CNN), which consists of an input layer, a hidden layer, and an output layer [
40]. In order to configure the model, the dataset was first divided into a training set and a test set. The ratio of the training set and the test set was 7:3. The total number of images used for the model train was 110, and the total number of test images was 48 (see
Table 2).
The image in the process has too large a pixel size; thus, if we use the image to construct a general CNN model, the computer memory will overflow. Therefore, the task of reducing the image size is performed first. The original size of the image is 5770 2912 pixels; however, the image was reduced to 600 300 pixels in order to train while maintaining the ratio of the image.
Next, the CNN structure was constructed. Keras was used as the deep learning library for constructing the CNN model. The model used a simple CNN model structure. First, three Conv2D layers were constructed, through which the image features were extracted without losing the spatial information of the image. Then, a max_pooling2d layer, which is a pooling layer, was added between each convolutional neural network, and the image features were reduced in size while being maintained. After this process, the multidimensional array was converted into a one-dimensional array through the flatten process, and classification was performed through the dense layer. The activation function used for the final classification is the sigmoid function.
Equation (5) has a value between 0 and 1. When the value learned in the proposed model is input, Equation (5) provides the value, which is the classification result. This model is classified into two types of labels: normal product and defective product. Therefore, according to the classification criteria, if the value is 0.5 or more, it is classified as label 1 (defective product), and if the value is less than 0.5, it is classified as label 0 (normal product).
The model is trained through a total of 60 iterations with parameters described in
Table 3. The optimizer uses Adaptive Moment Estimation (Adam), and the model loss is calculated using binary cross entropy (see Equation (6)). Binary cross entropy (
BCE) is a loss function specialized for binary classification problems, and it is a method that imposes a large penalty on the model for making incorrect predictions. The calculation is calculated as follows, where y is the actual label, and p is the predicted probability that the data point belongs to a specific label class. For reference, the model training time is 3 min and 36 s.
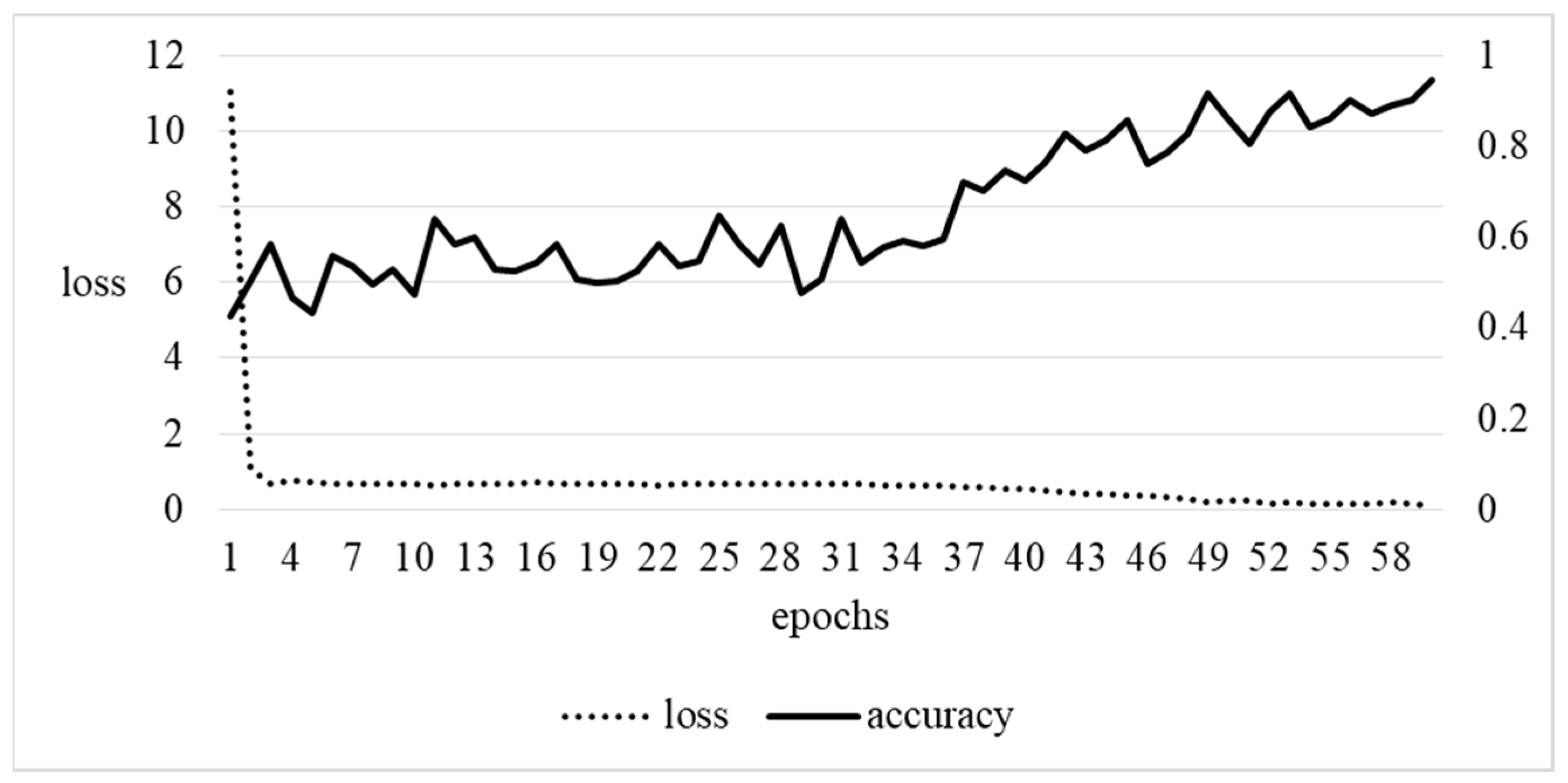
The learned model is used to make predictions on the test dataset. The test set consists of a total of 48 images, of which 25 images are normal data and 23 images are abnormal data. It takes less than 1 s to predict all 48 images. The accuracy and loss values according to learning are as shown in
Figure 9.
Accuracy increases from 42% at the beginning to 94% through 60 repetitions. Loss shows a value below 0.2 after 51 repetitions through 60 repetitions. The learning results are as described in
Table 4.
Based on the experimental results in
Table 4, the model is evaluated in terms of accuracy, precision, recall, and F1-score.
TP means true positive, which means that something that is actually True is predicted as True, FP means false positive, which means that something that is actually False is predicted as True, FN means false negative, which means that something that is actually True is predicted as False, and TN means true negative, which means that something that is actually False is predicted as False.
Accuracy is the ratio of correct answers predicted in the entire sample, and in this model, 40 out of 48 data were correct; therefore, the accuracy is 83%. Precision is the ratio of things that the model predicted as True to things that were actually True, and the precision of this model is 100%. Recall is the ratio of things that the classification model judged as True among the samples that were actually True, and the recall of this model is 76%. The f1 score calculated through the calculated precision and recall values is 86.17%. Meanwhile, these results show that performance improves when the threshold of the sigmoid function is changed. Looking at the prediction results, the function value of abnormal images ranges from a minimum of 0.11 to a maximum of 1, and the function value of normal images ranges from a maximum of 0.016. In other words, when the classification threshold is set to a value between 0.02 and 0.11, it can be confirmed that all 48 images are classified accurately. At this time, accuracy, precision, recall, and F1 score values are all 1.
Wire-unit RGB images (R/B channels: defect scores, G channel: original image) are generated through unsupervised anomaly detection (unsupervised anomaly segmentation).
Figure 10 represents example results of the unsupervised anomaly detection, respectively. The red box indicates the location where the defect is detected.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}