Abstract
Outlier detection is a critical task in the intelligent operation and maintenance (O&M) of transportation equipment, as it helps ensure the safety and reliability of systems like high-speed trains, aircraft, and intelligent vehicles. Nearest neighbor-based detectors generally offer good interpretability, but often struggle with complex data scenarios involving diverse data distributions and various types of outliers, including local, global, and cluster-based outliers. Moreover, these methods typically rely on predefined contamination, which is a critical parameter that directly determines detection accuracy and can significantly impact system reliability in O&M environments. In this paper, we propose a novel chain-based theory for outlier detection with the aim to provide an interpretable and transparent solution for fault detection. We introduce two methods based on this theory: Cascaded Chain Outlier Detection (CCOD) and Parallel Chain Outlier Detection (PCOD). Both methods identify outliers through sudden increases in chaining distances, with CCOD being more sensitive to local data distributions, while PCOD offers higher computational efficiency. Experimental results on synthetic and real-world datasets demonstrate the superior performance of our methods compared to existing state-of-the-art techniques, with average improvements of 11.3% for CCOD and 14.5% for PCOD.
1. Introduction
Outlier detection (OD) aims to identify data points that deviate from the general data distribution. It has been proven particularly valuable in the intelligent operation and maintenance (O&M) of transportation equipment, where identifying abnormal patterns in sensor data, operational parameters, and system behaviors is essential for ensuring safety and reliability [1,2,3].
In transportation equipment monitoring, outlier detection enables early identification of mechanical anomalies such as bearing degradation, gear wear, and structural fatigue through vibration analysis and multi-sensor data fusion [4,5]. The detection of such outliers in operational parameters—including temperature fluctuations, pressure variations, and rotational speed irregularities—indicates potential mechanical failures that require immediate attention to prevent catastrophic system breakdowns [6]. Beyond traditional condition monitoring, outlier detection has been successfully applied to assess component health in rotating machinery, where abnormal vibration signatures can reveal incipient faults in bearings, shafts, and gearboxes [7,8]. In transportation-specific applications, outlier detection serves to isolate anomalous operational patterns that indicate equipment degradation or performance deviation [9,10]. This capability has proven critical in railway systems for detecting wheel-rail interaction anomalies [11,12], in aviation for identifying engine performance deviations, and in automotive systems for monitoring drivetrain irregularities [13,14].
Despite widespread applications, existing outlier detection methods face significant challenges when applied to complex data scenarios commonly encountered in transportation O&M. First, such datasets typically contain multiple outlier types simultaneously—local outliers that deviate from their neighborhoods, global outliers that are distant from the entire dataset, and cluster outliers where small clusters comprise a few outliers [15,16,17,18]. Detection strategies optimized for different outlier types may conflict with each other, leading to suboptimal performance. Second, normal operational data often exhibits non-uniform distributions, where spatially close clusters may be distant in the underlying manifold space. Existing distance-based detectors that search for neighbors in ambient space fail to capture manifold similarity, causing points in sparse operational modes to include neighbors from nearby dense clusters, thereby disrupting the underlying data structure [19]. Third, most detectors require prior specification of contamination—the expected proportion of outliers—which directly determines detection accuracy and can significantly impact system reliability in O&M environments [20,21]. Estimating contamination in dynamic transportation systems is particularly challenging due to varying operational conditions and evolving fault patterns.
This paper extends our preliminary work with substantial improvements and comprehensive evaluations [22]. We present a chain-based theory with interpretable distance analysis and manifold-aware connectivity principles for complex data scenarios. Based on this theory, we propose two chaining methods: Cascaded Chain Outlier Detection (CCOD) and Parallel Chain Outlier Detection (PCOD). CCOD employs sequential chaining where each point has one predecessor and successor, providing higher sensitivity to local distributions and better manifold structure preservation, while PCOD allows multiple successors for parallel expansion, offering superior computational efficiency and scalability for large-scale transportation monitoring applications. Both methods identify outliers through sudden increases in chaining distances without requiring contamination parameters, making them particularly suitable for dynamic O&M environments.
The remainder of this paper is organized as follows: Section 2 reviews the related work on outlier detection and the evolution of the local outlier detectors. Section 3 presents the chain-based theory of outlier detection, as well as the proposed cascaded and parallel chaining methods. Section 4 demonstrates the superiority of the proposed model using synthetic and real-life data sets. In the end, concluding remarks are given in Section 5.
2. Related Work
Over the years, various outlier detection approaches have been proposed. In this section, we give an overview of the major outlier detection methods with particular emphasis on their interpretability characteristics. We choose seven state-of-the-art algorithms as the benchmarks for our experiments in Section 4.
2.1. Nearest Neighbor-Based Methods
Among various outlier detection paradigms, nearest neighbor-based methods demonstrate the strongest interpretability due to their intuitive underlying principles: they detect outliers by evaluating local density deviations between a point and its neighbors, providing clear explanations based on neighborhood relationships that are readily understandable by domain experts [23].
The concept of Local Outlier Factor (LOF) was first proposed by Breunig [24], and it has since become a widely adopted method for local outlier detection due to its interpretable scoring mechanism. The LOF assigns outlier scores based on the ratio of a point’s k-distance to its neighbors’ average k-distance, allowing practitioners to directly understand why a point is considered anomalous by examining its local density context. However, different types of outliers may conflict with each other, where larger k-neighborhoods can detect global outliers and cluster outliers, but reduce sensitivity to local outliers. Moreover, LOF fails to capture intrinsic manifold structure, causing misclassification for linearly distributed data.
The Connectivity-based Outlier Factor (COF) [25] attempts to improve manifold sensitivity by weighting neighborhoods based on shortest connective paths rather than Euclidean distances, providing interpretable explanations through connectivity patterns that reflect data topology. However, this approach incurs high computational costs in establishing connection paths. Some methods have explored more flexible neighborhood selections while maintaining interpretability. Huang et al. [26] restrict neighborhoods to mutual k-nearest neighbors, effectively handling non-uniform densities but failing to capture manifold curvature, though the mutual neighbor concept remains intuitive for practitioners. Jin et al. [27] expand neighborhoods via Influenced Outlierness (INFLO) to k-influence spaces containing both k-nearest neighbors and reverse k-nearest neighbors, providing bidirectional neighborhood insights, but this weakens local sensitivity.
Despite their interpretability advantages, the selection of appropriate local neighborhoods in nearest neighbor methods remains challenging. Insufficient neighborhoods fail to capture complex local distributions, while excessive neighborhoods result in reduced local sensitivity.
2.2. Clustering-Based Methods
Clustering-based methods use clustering as the local neighborhood rather than the k-nearest neighbors, but typically provide less intuitive explanations compared to nearest neighbor approaches since cluster formations may not directly correspond to abnormal patterns.
The Cluster-Based Local Outlier Factor (CBLOF) [28] categorizes clusters by size and calculates outlier scores based on distance to cluster centers or nearest large clusters. While this approach offers some interpretability through cluster membership, it provides less direct explanations than neighbor-based methods. However, CBLOF’s cluster size weighting overestimates scores for points in large clusters. The Local Density Cluster-Based Outlier Factor (LDCOF) [29] addresses this by using local density instead of cluster size. Using clusters as neighborhoods can enhance similarity among neighbors, but these methods still require contamination parameters and provide less transparent decision rationales.
Density-Based Spatial Clustering of Applications with Noise (DBSCAN) identifies outliers as points that do not belong to any cluster [30,31], offering binary interpretability (cluster member vs. noise). It avoids predefined contamination, but introduces complex parameter dependencies between the neighborhood radius and minimum points, making interpretations less straightforward compared to distance-based neighbor methods.
The effectiveness of clustering-based methods is limited by their reliance on clustering information [32], which is unavailable in outlier detection tasks, and their reduced interpretability compared to direct neighbor-based approaches.
2.3. Statistics-Based Methods
Statistics-based methods assume that the given data set follows a specific distribution and identify data points that deviate from it as outliers. However, these methods often provide the least interpretable results, as their explanations rely on complex statistical concepts that may not be intuitive to domain practitioners.
Gaussian mixture models [33] detect outliers through component deviations, while Local Outlier Probabilities (LoOP) [34] assumes half-Gaussian distributions for k-nearest neighbor distances. These methods are highly sensitive to contamination and provide probabilistic explanations that may be difficult to interpret in practical maintenance scenarios. Paladimitriou et al. [35] introduce the Multi-granularity DEviation Factor (MDEF) for measuring Local Correlation Integral (LOCI). LOCI avoids contamination by statistical significance testing and addresses k-dependency by dual neighborhoods, but incurs computational complexity while providing complex statistical explanations.
The Relative Density-based Outlier Score (RDOS) [36] uses kernel density estimation with three neighbor types to assess local density variations. The Kernel Density Estimation Based Outlier Detection (RKOF) [37] applies kernel functions for more refined local density assessment. The Copula-based Outlier Detection (COPOD) [38] utilizes empirical copulas to compute tail probabilities, leveraging negative log probabilities to effectively handle high-dimensional challenges. Similarly, the Empirical Cumulative Distribution-based Outlier Detection (ECOD) [39] ensembles empirical cumulative distributions per dimension. However, these advanced statistical methods, while mathematically sophisticated, provide explanations based on complex probability distributions that are challenging for maintenance personnel to interpret and act upon.
The effectiveness of statistics-based methods is constrained by their sensitivity to underlying manifold distributions and their limited interpretability in practical applications, which results in degraded usability when applied to complex data scenarios where clear explanations are crucial for decision-making.
3. The Proposed Methods
Empirical observations reveal that normal data points are typically concentrated in larger numbers and have sufficient neighbors within the cluster, whereas outlier data points do not conform to this pattern. To formalize this observation, we propose a chain-based theory that respects the intrinsic manifold structure of data by computing similarity via geodesic paths that approximate manifold distances. The chain distance method decomposes long distances into consecutive short paths, better adapting to the intrinsic geometric structure of the manifold. The following theorem establishes the theoretical advantage of chain distance.
Theorem 1.
Chain distance has a tighter error bound relative to k-distance. Suppose the dataset is distributed on an m-dimensional smooth manifold , with bounded sectional curvature, i.e., there exists a constant such that the absolute value of sectional curvature in any direction at any point does not exceed κ. When both methods find the same k-th nearest neighbor, the error bound of the chain method is smaller than that of the k-nearest neighbor method:
where , and is the k-th nearest neighbor of . represents the distance estimation of k-nearest neighbor, i.e., the Euclidean distance from to its k-th nearest neighbor ; represents the chain distance from to , i.e., the cumulative distance of piecewise paths for the set constructed by stepwise nearest neighbor linking; represents the geodesic distance between and .
Proof.
We will analyze the local error bounds for k-nearest neighbor distance and chain distance separately, and then compare them.
- Step 1. Local error bound for k-distance: For data point pairs p and q within the neighborhood, by the arc-chord estimation inequality in Riemannian geometry:Taking , , and denoting , we have:Therefore, the relative error of the k-distance satisfies:
- Step 2. Local error bound for chain distance: The chain distance decomposes long distances into multiple short segments, reaching the same through stepwise nearest neighbor linking. The distance between adjacent point pairs and in the chain is sufficiently small. Taking , , the error for local link sets in the chain path is:where . The total error of chain distance is:where . Therefore, the relative error of chain distance is:
- Step 3. Comparison of the two methods: When there exists at least one segment , the relative error upper bound of the chain method is strictly smaller than that of the k-nearest neighbor method:
□
The chain-based theory enables us to distinguish normal points from outliers based on their chaining behavior. It is assumed that for a normal data point, there should exist a sufficient number of points in its neighborhood such that a series of chaining distances starting from this point does not increase excessively. Conversely, for an outlier data point, the number of points in its neighborhood is insufficient to prevent excessive increases in chaining distances.
As shown in Figure 1, the chain-based theory aims to chain normal points (green dots) following the manifold structure, while leaving outliers unchained as they cause excessive increases in chaining distances. However, traditional density-based methods search for neighbors in ambient space, and outliers can be selected as neighbors due to their proximity in ambient distance.
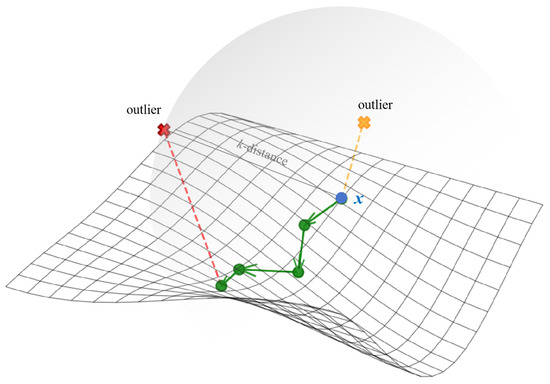
Figure 1.
An illustration of chain-based theory.
Therefore, we utilize the chaining distance as an estimator of data distribution, searching neighbors via consecutive short paths that approximate manifold distances. Points whose chaining distances exhibit excessive increases are identified as outliers, indicating significant separation from neighbors in manifold geometry. Conversely, chained data points with stable chaining distance are identified as the potential normal data. Based on this chain-based theory, two methods are proposed for outlier detection.
3.1. Cascaded Chain Outlier Detection
Suppose is the given data set, is the data set of normal points, and is the data set of outlier points. Use the Euclidean distance as the distance measure between any two points, i.e., , where , and , and calculate this distance only once. At the beginning of a chaining process in the search for outliers, select a random data point from as the start point and initialize the current chain as, i.e., with . It is the first point in the current chain, and any point can serve as a start point, provided it has not already been identified as normal or used as a start point. Thus, we define a data set of the remaining start points as . Then, the second data point to be included in the current chain is chosen from , which has the smallest distance to the start point . If there are multiple points with the minimum distance from the start point, only one is selected. The smallest distance between and is defined as a chaining distance , i.e., . It is the second point in the current chain, i.e., . For , select the -th data point from which has the smallest Euclidean distance to the j-th data point . The ratio of the chaining distance over the average chaining distance in the current chain is calculated as
For , if the satisfies
means that including in the series of chaining distances does not cause excessive increases, and is a potential normal data point that can be added to the current chain, i.e., , and let to chain the next point.
If and in the case of , consider the possible merging of two chains. Set the pre-chain data set , , and start a new chain from , , , . Once and satisfies the condition as follows:
these two chains have similar densities that can be combined as , , and let to chain the next point; If and Equation (11) is not satisfied, it means that the two chains have different densities and cannot be combined, thus the pre-chain is reset as and let to chain the next point.
If , it means that the chaining distances of increase excessively, and the current chain process ends at . In the case of , is not considered a normal cluster and is discarded. A new chaining process begins with from a random point in .
Note that the proposed method imposes stricter constraints in the case of , in which the upper constraint aims to prevent the chain from cascading to outliers or other clusters, while the lower constraint is to prevent the start point from being an outlier. If the start point is an outlier, the chaining distance of would increase excessively compared to that of . However, if , the start point must not be an outlier, because the proposed method considers chains containing more than K elements to be normal, making the lower bound constraint unnecessary.
For , if satisfies , it means that including in the series of chaining distances does not cause excessive increases, and is a potential normal data point that can be added to the current chain, i.e., , and let to chain the next point; If , it means that the chaining distances of increase excessively, and the current chain process ends at . , and the data set of start points is updated as . A new chaining process begins with from a random point in .
The search stops when no new clusters can be formed, i.e., . Finally, a point is considered normal if it belongs to and considered an outlier if it does not belong to , i.e., . In the proposed method, every chained point has only one predecessor and one successor, excluding the first and last. Hence, we refer to the method as outlier detection by cascaded chaining. The process of detecting the outliers by CCOD is summarized in Algorithm 1.
| Algorithm 1: Outlier detection by cascaded chaining |
|
To illustrate the process of how CCOD forms chains, we present an example of a two-dimensional data set in Figure 2. The parameters ARE and . Starting at the point , the second point in the chain is identified as , as it has the smallest distance from , i.e., . Next, the point is cascaded as the successor of , i.e., , because there are sufficient points in its neighborhood and the chaining distance condition is satisfied. Similarly, is cascaded as the successor of . The current chain is . Then, we focus on the nearest point to , which is and has a much shorter chain distance than before, i.e., and . At this point, we consider merging two chains. We copy the current chain into a pre-chain denoted as and a new current chain starts from . The search stops once , and the . The current chain and pre-chain can be combined because they have similar densities according to Equation (11), i.e., , and the order of the data points in is updated as . For , the is cascaded as the successor of , but as the nearest point of cannot be cascaded, because it would increase the chaining distance excessively, i.e., . At this point, the current chain is formed, as it cannot be extended any further. The current chain is considered a normal data set, as it contains more than k data points. However, fails to be chained as a successor and cannot form a normal data set as a start point, and thus would be considered an outlier.
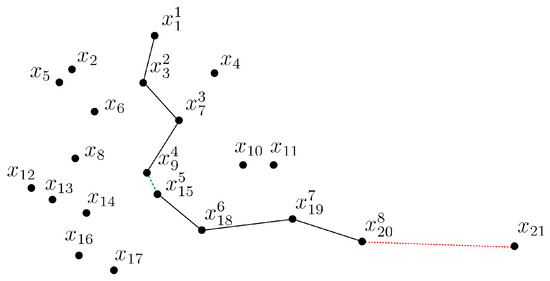
Figure 2.
CCOD in a 2D example.
It should be noted that in Figure 2, a substantial number of normal data points persist unchained even after undergoing a chaining process. These data points possess adequate neighbors but are restricted by the expansion direction of the current chain. Hence, we propose a variant approach that allows each point to have multiple successors. The CCOD approach is a special case of the deformation method, where the number of successor points is restricted to 1. While the two methods differ in detail, they share the same underlying concept of identifying outliers with excessive increases in chain distances and collecting the chained data points into a cluster of potential normal data when the chaining process exhibits no excessive distance change. Next, the potential normal data cluster would be defined as a normal data set if it contains more than data points.
3.2. Parallel Chain Outlier Detection
Suppose is the given data set, is the data set of normal points, and is the data set of outlier points. We still use the Euclidean distance as the distance measure between any two points. At the beginning of a chaining process, select a random data point from as the start point and initialize the current chain as with . It is the first point in the current chain, and any point can serve as a start point, provided it has not already been identified as normal or used as a start point. Thus, we define a data set of the remaining start points as . Then, the next batch of points is chosen from such that they have the first K smallest distances to the start point . If there are more than k following points for one data point, only the first k points are included. The distance between and is defined as a chaining distance , i.e., . Let represent the z-th batch. The first batch contains only a start point, i.e., , and the second batch is recorded as , i.e., where and . These two batches are included in the current chain, i.e., . For , the current points are selected from in ascending order of superscript, and the k nearest points to be included in the -th batch are selected from based on their k smallest Euclidean distances to the current point. The t-th nearest point to the current point is , where . The ratio of the chaining distance over the average chaining distance in the current chain is calculated as
Note that points with smaller distances to their predecessors have higher priority in selecting successors, since each successor can only be selected once within the same batch or cluster.
For , if any satisfies
it means that a series of chaining distances containing the does not increase excessively, and the is a potential normal data point that can be taken into the -th batch as one of the successor points of , i.e., , and let to chain the next point. Then, , and let to chain the next batch. The current chain process stops when there are no new points to be chained, i.e., . Then, the is a normal cluster if , such that , and the data set of start points is updated as . A new chaining process begins with from a random point in .
The search stops when no new clusters can be formed, i.e., . Finally, a point is considered normal if it belongs to ; Otherwise, it is considered an outlier, i.e., . In the proposed variant approach, except for the start point, each chain point has only one predecessor, but can have more than one successor. Hence, we refer to the method as outlier detection by parallel chaining. The process of detecting the outliers by PCOD is summarized in Algorithm 2.
To illustrate the process of how PCOD forms chains, we present an example of a two-dimensional data set in Figure 3. The parameters and . Starting at the point as the first batch , the second batch points in the chain are identified as and , as they have the k smallest distance from and , i.e., . The current chain is . Next, is chained as the successor of from , i.e., , and is chained as the successor of from , i.e., , as and . However, the other points in have no new successors, so the 3-rd batch has two elements, i.e., . The current chain is . Similarly, , and are chained as successors of from , and and are chained as successors of from . The 4-th batch is , and the current chain is . Continuing in the same way, is chained as the successors of , are chained as successors of , are chained as successors of , and are chained as successors of . The 5-th batch is , and the current chain is . The 6-th batch is , which only has one element as the successors of . However, fails to be chained as a successor and cannot form a normal data set as a start point, and thus would be considered an outlier.
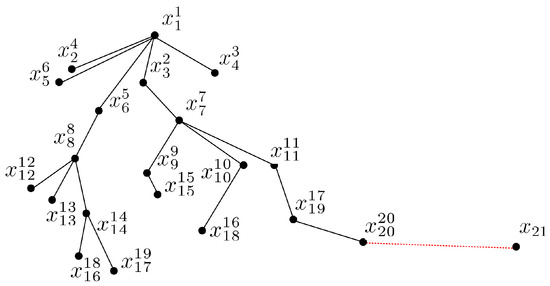
Figure 3.
PCOD in a 2-D example [22].
Both CCOD and PCOD have a theoretical time complexity of , but their practical performance differs due to chain formation strategies. CCOD requires a large number of small chains, providing higher sensitivity to local distributions but making it unsuitable for large data sets. PCOD divides observations into fewer chains with more points in each chain, offering superior computational efficiency by greatly reducing the time required to form new chains, though more time is spent processing each individual chain. Therefore, CCOD is more suitable for small data sets requiring precise local analysis, while PCOD is ideal for large data sets prioritizing computational efficiency.
| Algorithm 2: Outlier detection by parallel chaining |
|
4. Results
In this section, we compare the proposed models with seven state-of-the-art algorithms. To ensure a comprehensive comparison, we chose LOF [24] and its most-cited variants COF [25], LoOP [34], LOCI [35], NOF [26], RDOS [36], and ECOD [39] as representative local outlier detectors. Unlike existing methods requiring predefined contamination parameters, our approaches automatically identify outliers by detecting abrupt increases in chaining distances.
The performance metric employed in our study is the Area Under the Receiver Operating Characteristic Curve (AUC) and Precision (PRN). The AUC evaluates the trade-off between correctly identifying true outliers and minimizing false detections on normal points, where AUC = 1.00 indicates perfect detection performance to identify normal data and outliers. Unlike conventional detectors that produce continuous outlier scores and require a predefined contamination, the proposed methods output binary scores, assigning 1 to predicted normal points and 0 to predicted outliers. The PRN measures the proportion of correctly identified outliers among all predicted outliers, where PRN = 1.00 indicates that all predicted outliers are true outliers. All methods in our study achieved the highest AUC based on their respective parameters. All reported results are averaged over 5 independent runs.
Experiments are conducted on a 2.40 GHz Core i5-1135G7 CPU with 16 GB of RAM. The experiments are programmed in Python, and the software version is Python 3.8.
4.1. Detection Performance on Synthetic Data Sets
To illustrate the intuition behind the proposed methods, experiments are conducted on a variety of synthetic data sets. As shown in Figure 4a–c, Example_l, Example_c and Example_n are designed for different complex data scenarios. Example_l is constructed to evaluate the effectiveness of outlier detection algorithms in identifying both local and global outliers. The Example_c aims to evaluate the performance of detecting outlier clusters. Example_n investigates the ability of detectors to identify local and global outliers when two normal clusters with different densities are located near each other. As shown in Figure 4d–l, the Groups, Regressions, and Moons data sets are designed for various random distributions. For Groups data sets in Figure 4d–f, we generate Groups_e, Groups_u, and Groups_g subject to equidistant (_e), uniform (_u), and Gaussian (_g) as subtype distributions, respectively. The Regressions data sets in Figure 4g–i and Moons data sets in Figure 4j–l are generated in the same way. Each subtype includes three different random variations, and the experimental results are averaged across these variations. In addition, we add 3%, 5%, and 7% outliers to these distributions, respectively, in which outliers are subject to a uniform distribution. A list of characteristics of synthetic data sets can be found in Table 1.
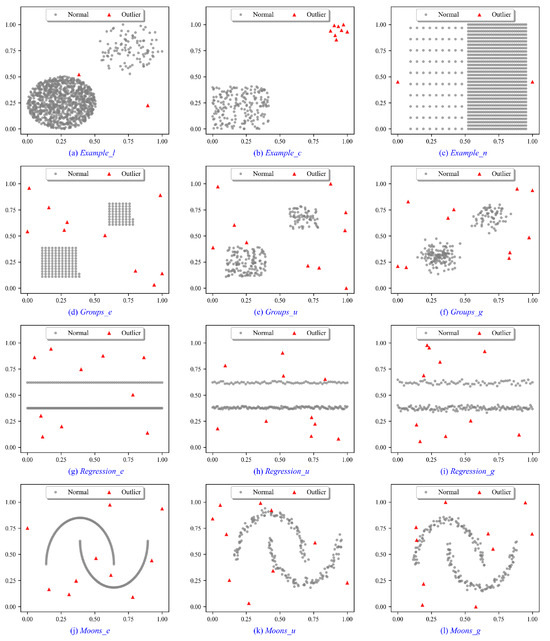
Figure 4.
Synthetic data sets for performance evaluation of outlier detection methods.

Table 1.
The characteristics of synthetic data sets.
The performance of each detector on the Example_l, Example_c, and Example_n data sets in terms of AUC and PRN is presented in Table 2 and Table 3, respectively. For the Example_l data set, the proposed methods and most algorithms achieve perfect AUC and PRN values of 1.000. whereas ECOD exhibits significant limitations in identifying outliers in this small-scale data set. For the Example_c data set, COF, LoOP, and ECOD achieve the AUC and PRN values consistently lower than average, indicating that these methods fail to accurately detect clustered outliers due to high similarity with normal clusters. For the Example_n data set, LOCI, NOF, and ECOD all fail in this case due to the low local density of the sparse cluster members located near the dense clusters, resulting in normal data being considered outliers. The experiments demonstrate that only the proposed methods and RDOS achieve perfect performance across various scenarios.
Table 2.
AUC of various outlier detection methods in Example_l, Example_c, and Example_n data sets.
Table 3.
PNR of various outlier detection methods in Example_l, Example_c, and Example_n data sets.
The performance of each detector on the Groups, Regressions, and Moons data sets in terms of AUC and PRN is presented in Table 4 and Table 5.
Table 4.
AUC of various outlier detection methods in Groups, Regressions and Moons data sets.
Table 5.
PNR of various outlier detection methods in synthetic data sets.
For the Groups data sets, most methods achieve perfect AUC and PRN values of on Group_e and Group_u when the contamination is and , except for NOF and ECOD. However, as the contamination increases to , only CCOD and PCOD maintain perfect AUC and PRN values of on Group_u, while on Group_e, PCOD achieves the highest AUC of . Particularly, on Group_e with contamination, PCOD outperforms LOF, COF, LoOP, LOCI, NOF, RDOS, and ECOD by , , , , , , and , respectively. For the more irregular Group_g data set with contamination, CCOD achieves an AUC of and PRN of , while PCOD obtains an AUC of and PRN of , demonstrating CCOD’s superior sensitivity to local distribution variations in terms of AUC.
On the Regressions data sets, LOF, LoOP, LOCI, and RDOS show relatively unstable AUC values and correspondingly lower PRN values on linearly distributed data, while COF consistently demonstrates strong performance through its shortest-path linkage mechanism. Specifically, under contamination in Regression_e, LOF and NOF achieve PRN values of only , ECOD obtains , whereas CCOD reaches . When the contamination increases to , CCOD and PCOD both achieve perfect scores with AUC and PRN of on Regression_e and Regression_u, indicating that the chaining theory effectively adapts to linear manifold structures. However, at contamination on the Gaussian-distributed Regression_g, the performance of both methods degrades to AUC values of and , with corresponding PRN values of and , respectively, suggesting room for improvement in scenarios with more complex density distributions.
For the Moons data sets, most methods show significant performance degradation due to difficulties in capturing the diverse data distribution structures. CCOD and PCOD maintain perfect AUC and PRN values of across all contamination levels on Moon_e, except that PCOD’s AUC drops to at contamination, and achieve the best AUC and PRN performance at and contaminations on Moon_u and Moon_g. Particularly, on Moon_g with contamination, CCOD outperforms LOF, LOCI, NOF, and ECOD by , , , and , respectively. Under contamination on Moon_g, CCOD achieves a PRN of while PCOD obtains , demonstrating its superior precision within complex distribution scenarios. The experiments demonstrate the superior robustness of CCOD and PCOD across complex data scenarios with varying contamination levels.
Furthermore, we investigate the parameter tuning and sensitivity analysis for CCOD and PCOD. The minimum cluster size is determined by , where the parameter is set to a fixed value of 0.2 in both CCOD and PCOD, whereas and k are tunable parameters. In the experiments on synthetic data sets, ranges from 1 to 5 with an interval of 0.2, and k ranges from 5 to 50 with an interval of 5. Empirically, when CCOD and PCOD achieve optimal AUC, the value of is approximately 3.6. Therefore, we recommend setting when prior statistical information is unavailable. Similarly, the optimal value of k is approximately 10 for CCOD and 15 for PCOD. It is recommended that k be increased moderately with growing data set size. Additionally, we evaluate the sensitivity of parameter . As shown in Figure 5, the values of that achieve optimal AUC in CCOD and PCOD are presented across varying values of k. It is observed that the correlation between and k is weak, with the variation in remaining insignificant as k increases from 5 to 50. In Figure 5d, the value of for both CCOD and PCOD consistently remains at 3.6 across all values of k.
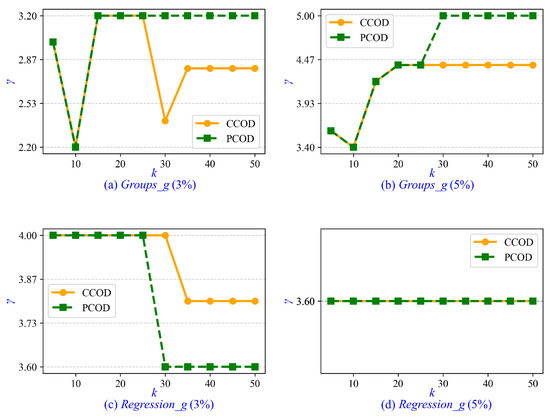
Figure 5.
Sensitivity of parameter to varying k in synthetic data sets.
4.2. Detection Performance on Real-Life Data Sets
To evaluate the predictive performance of different models in real-life scenarios, experiments are conducted on 20 real-life data sets with varying sample sizes, dimensionalities, and contamination. The data sets span diverse applications, including healthcare, sensor readings, handwriting, and tabular benchmarks [40,41]. In the medical domain, the breast cancer Wisconsin data set (abbr., BCancer) contains benign and malignant cases extracted from Fine Needle Aspirate (FNA) images of nuclei. By treating malignant cases as outliers, the performance of the detector is evaluated by identifying malignant cases. In pattern recognition, the pen-based recognition of the handwritten digits data set is a collection of data extracted from digitized handwritten images of different writers. Of these, the Pen-global treats digit 8 as normal and other digits as outliers, and Pen-local treats digit 4 forms an outlier cluster. In remote sensing, the Landsat satellite data set (abbr. Satellite) contains scenes extracted from satellite imagery, where semantic scenes corresponding to cotton crops and soil with vegetation stubble are selected as outliers. All numeric attributes are normalized before being used in our experiments. To mitigate the curse of dimensionality in high-dimensional data sets, we apply principal component analysis for dimensionality reduction while preserving at least 95% of the original variance to maintain detection capability and ensure fair comparison. Table 6 summarizes the comprehensive data set characteristics.
Table 6.
The characteristics of real-life data sets.
Table 7 and Table 8 present the AUC and PRN performance of each detector on 20 real-life data sets, with rankings shown in parentheses. Overall, PCOD achieves the highest average AUC of , while CCOD attains the highest average PRN of and the second-best AUC of .
Table 7.
AUC of various outlier detection methods in real-life data sets.
Table 8.
PNR of various outlier detection methods in real-life data sets.
For low contamination data sets (≤5%), we analyze 10 data sets with contamination ranging from to . In this case, PCOD demonstrates exceptional performance, achieving first rank in 7 out of 10 data sets, while CCOD consistently delivers competitive results. For the BCancer data set, PCOD and LOF achieve the highest AUC of with a PRN of , surpassing COF, LoOP, and LOCI by , NOF by , RDOS by , and ECOD by . For the Musk data set, PCOD achieves the best performance with an AUC of and PRN of , significantly outperforming LOF by . For the Pen-local data set, both CCOD and PCOD achieve a PRN of , while CCOD achieves the highest AUC of compared to PCOD’s , benefiting from its more refined cascaded local search mechanism that effectively identifies small outlier clusters. For the Shuttle and Optdigits data sets, PCOD achieves the highest AUC, and CCOD is the second highest performer. The superior performance is particularly notable on large-scale data sets, where PCOD achieves substantial improvements over other methods.
For medium contamination data sets (5–20%), we evaluate 5 data sets with contamination between and . In this case, PCOD ranks first in 3 out of 5 data sets, while CCOD consistently ranks in the top-4 across these data sets. For the Annthyroid data set, PCOD achieves the best performance with an AUC of and PRN of , its AUC outperforms LOF by , and significantly surpasses NOF and ECOD by . For the Pen-global data set, PCOD achieves the highest AUC of , demonstrating superior effectiveness over LOCI by and NOF by , showcasing excellent performance in pattern recognition tasks such as handwriting recognition. However, on the Letter data set, LoOP achieves the highest AUC of , with PCOD and CCOD at . This occurs because traditional methods can use exact contamination levels as prior knowledge, whereas CCOD and PCOD determine outliers based on chaining distances without prior contamination knowledge, which may reduce precision in some cases.
For high contamination data sets (), we test 5 challenging data sets with contamination from to . Despite the challenging conditions with dense outlier distributions, PCOD maintains first ranking in all 5 data sets, while CCOD maintains competitive performance. For the HeartDis data set with the highest contamination (), PCOD achieves the best AUC of and CCOD achieves , with PCOD obtaining a PRN of and CCOD achieving a PRN of , demonstrating strong performance. For the Spambase data set, PCOD attains the highest AUC of with a PRN of , with CCOD achieving the second-best AUC of and a PRN of , substantially outperforming traditional methods like LOF and COF. In contrast, traditional methods show significant performance degradation in high contamination scenarios. For instance, ECOD achieves only AUC with a PRN of on the Wine data set, while NOF obtains AUC values below with PRN values generally below on multiple high contamination data sets. Although COF and LOF maintain competitiveness on some data sets, their overall performance remains unstable. The ensemble method ECOD demonstrates poor performance on multiple data sets, highlighting the limitations of feature independence assumptions. In this case, contamination parameters have a significant impact on outlier detection performance, and even minor contamination variations can cause significant changes in results. However, the proposed methods remain effective when dealing with highly contaminated data.
We present the running time analysis on real-life data sets. Detectors ranked by average execution time are: ECOD (1.73s), LOF (1.80s), PCOD (2.68s), NOF (2.82s), CCOD (3.95s), RDOS (7.27s), LOCI (23.97s), LoOP (39.27s), and COF (51.67s). ECOD achieves linear complexity , while LOCI has cubic complexity . Other methods, including LOF, NOF, RDOS, LoOP, COF, and the proposed CCOD and PCOD, have quadratic complexity . Among the methods, LOF is computationally the most efficient, involving only distance calculations and simple density ratios. In contrast, NOF requires bidirectional verification of mutual k-nearest neighbors, RDOS and LoOP incur overhead from kernel density estimation and probabilistic computations, and COF suffers from expensive shortest path construction across connectivity patterns. Our CCOD and PCOD methods achieve practical efficiency comparable to LOF through streamlined contrastive computations, while delivering superior detection accuracy, effectively balancing cost and performance.
Experimental results demonstrate that our chain-based approaches consistently outperform state-of-the-art methods across both synthetic and real-life data sets, validating the effectiveness of chain-based theory in tackling complex outlier detection scenarios.
Furthermore, we investigate the parameter tuning and sensitivity analysis for CCOD and PCOD. The minimum cluster size is determined by , where the parameter is set to a fixed value of 0.2 in both CCOD and PCOD, whereas and k are tunable parameters. In the experiments on real-life data sets, ranges from 1 to 5 with an interval of 0.2, and k ranges from 5 to 50 with an interval of 5. Empirically, when CCOD and PCOD achieve optimal AUC, the value of is approximately 3.6. Therefore, we recommend setting when prior statistical information is unavailable. Similarly, the optimal value of k is approximately 15 for CCOD and 25 for PCOD. It is recommended that k be increased moderately with growing data set size. Additionally, we evaluate the sensitivity of parameter . As shown in Figure 6, the values of that achieve optimal AUC in CCOD and PCOD are presented across varying values of k. It is observed that the correlation between and k is weak, with the variation in remaining insignificant as k increases from 5 to 50. In Figure 6b, the value of for both CCOD and PCOD consistently remains at 3.6 across all values of k.
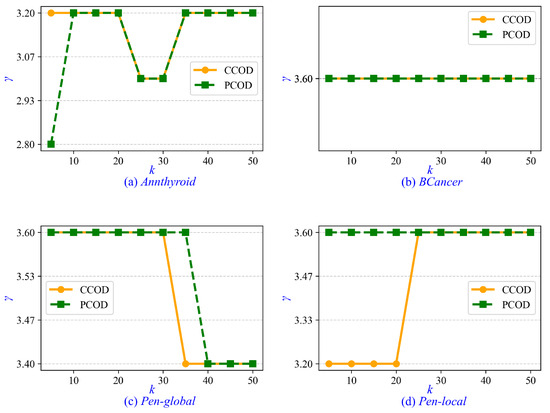
Figure 6.
Sensitivity of parameter to varying k in real-life data sets.
5. Conclusions
This paper proposes a novel chain-based theory for outlier detection that simultaneously addresses multiple challenges in complex data scenarios: handling different outlier types, adapting to varying cluster densities, and eliminating dependence on contamination parameters. We present CCOD and PCOD, two interpretable methods that utilize chaining distance as a manifold-aware data distribution estimator, identifying outliers through sudden distance increases in geodesic connectivity paths while providing intuitive explanations for detection decisions. Through extensive experiments with both synthetic data sets and real-life data sets, we demonstrate that performance is comparable or better to state-of-the-art methods, establishing chain-based theory as a promising solution for addressing complex data scenarios in outlier detection. The contamination-free design and computational efficiency make these methods particularly suitable for intelligent O&M applications where outlier proportions are unknown and large-scale monitoring is required. These results establish chain-based theory as a promising solution for addressing complex data scenarios in outlier detection.
Future work will extend our approach to real-time applications by developing online learning capabilities that can adapt to evolving operational conditions and integrate with existing maintenance decision support systems. We also aim to validate our methods across diverse transportation equipment types and develop comprehensive multi-modal sensor fusion frameworks that can provide holistic fault diagnosis for complex mechanical systems in dynamic operational environments.
Author Contributions
Conceptualization, H.D. and Q.-G.W.; methodology, H.D. and Q.-G.W.; validation, H.D., M.L. and S.W.; formal analysis, H.D. and Z.Z.; investigation, M.L. and S.W.; data curation, M.L. and S.W.; writing—original draft preparation, H.D.; writing—review and editing, H.D., M.L., S.W., Q.-G.W. and Z.Z.; visualization, H.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant number 62373060.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yao, Y.; Zhang, X.; Cui, W. A LOF-IDW based data cleaning method for quality assessment in intelligent compaction of soils. Transp. Geotech. 2023, 42, 101101. [Google Scholar] [CrossRef]
- Bałdyga, M.; Barański, K.; Belter, J.; Origlia, R.; Rossi, B. Anomaly detection in railway sensor data environments: State-of-the-art methods and empirical performance evaluation. Sensors 2024, 24, 2633. [Google Scholar] [CrossRef] [PubMed]
- Bianchi, G.; Fanelli, C.; Freddi, F.; Giuliani, F.; La Placa, A. Systematic review railway infrastructure monitoring: From classic techniques to predictive maintenance. Adv. Mech. Eng. 2025, 17, 16878132241285631. [Google Scholar] [CrossRef]
- Xing, Z.; Liu, Y.; Wang, Q.; Li, J. Multi-sensor signals with parallel attention convolutional neural network for bearing fault diagnosis. AIP Adv. 2022, 12, 075020. [Google Scholar] [CrossRef]
- Wang, X.; Mao, D.; Li, X. Bearing fault diagnosis based on vibro-acoustic data fusion and 1D-CNN network. Measurement 2021, 173, 108518. [Google Scholar] [CrossRef]
- Li, X.; Wang, Y.; Yao, J.; Zhang, H. Multi-sensor fusion fault diagnosis method of wind turbine bearing based on adaptive convergent viewable neural networks. Reliab. Eng. Syst. Saf. 2024, 245, 109980. [Google Scholar] [CrossRef]
- Wan, H.; Gu, X.; Yang, S.; Liu, P. A sound and vibration fusion method for fault diagnosis of rolling bearings under speed-varying conditions. Sensors 2023, 23, 3130. [Google Scholar] [CrossRef]
- Pacheco-Chérrez, J.; Fortoul-Diaz, J.A.; Cortés-Santacruz, F.; Aloso-Valerdi, L.M.; Ibarra-Zarate, D.I. Bearing fault detection with vibration and acoustic signals: Comparison among different machine leaning classification methods. Eng. Fail. Anal. 2022, 139, 106515. [Google Scholar] [CrossRef]
- Chen, S.; Wang, W.; van Zuylen, H. A comparison of outlier detection algorithms for ITS data. Expert Syst. Appl. 2010, 37, 1169–1178. [Google Scholar] [CrossRef]
- Ribeiro, R.P.; Pereira, P.; Gama, J. Sequential anomalies: A study in the railway industry. Mach. Learn. 2016, 105, 127–153. [Google Scholar] [CrossRef]
- Ghiasi, R.; Khan, M.A.; Sorrentino, D.; Friswell, M.I. An unsupervised anomaly detection framework for onboard monitoring of railway track geometrical defects using one-class support vector machine. Eng. Appl. Artif. Intell. 2024, 133, 108167. [Google Scholar] [CrossRef]
- Wan, T.H.; Tsang, C.W.; Hui, K.; Ho, I.W.H. Anomaly detection of train wheels utilizing short-time Fourier transform and unsupervised learning algorithms. Eng. Appl. Artif. Intell. 2023, 122, 106037. [Google Scholar] [CrossRef]
- Phusakulkajorn, W.; Núñez, A.; Wang, H.; Dollevoet, R. Artificial intelligence in railway infrastructure: Current research, challenges, and future opportunities. Intell. Transp. Infrastruct. 2023, 2, liad016. [Google Scholar] [CrossRef]
- Shaikh, M.Z.; Jatoi, S.; Baro, E.N.; Ahmed, A.; Memon, T.D. FaultSeg: A Dataset for Train Wheel Defect Detection. Sci. Data 2025, 12, 309. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, S.; Wu, Z. Outlier detection using local density and global structure. Pattern Recognit. 2025, 157, 110947. [Google Scholar] [CrossRef]
- Omar, M.; Sukthankar, G. Text-Defend: Detecting Adversarial Examples using Local Outlier Factor. In Proceedings of the IEEE International Conference on Semantic Computing, Laguna Hills, CA, USA, 27 February–1 March 2023; pp. 118–122. [Google Scholar]
- Ruff, L.; Kauffmann, J.R.; Vandermeulen, R.A.; Montavon, G.; Samek, W.; Kloft, M.; Dietterich, T.G.; Müller, K.R. A unifying review of deep and shallow anomaly detection. Proc. IEEE 2021, 109, 756–795. [Google Scholar] [CrossRef]
- Liu, B.; Tan, P.N.; Zhou, J. Unsupervised anomaly detection by robust density estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022; Volume 36, pp. 4101–4108. [Google Scholar]
- Romano, M.; Faiella, G.; Bifulco, P.; Cesarelli, M. Outliers detection and processing in CTG monitoring. In XIV Mediterranean Conference on Medical and Biological Engineering and Computing 2016; Springer: Cham, Switzerland, 2014; pp. 651–654. [Google Scholar]
- Perini, L.; Bürkner, P.C.; Klami, A. Estimating the contamination factor’s distribution in unsupervised anomaly detection. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 27668–27679. [Google Scholar]
- Pearson, R.K. Outliers in process modeling and identification. IEEE Trans. Control Syst. Technol. 2002, 10, 55–63. [Google Scholar] [CrossRef]
- Dong, H.; Wang, Q.G.; Ding, W. Chain-Based Outlier Detection for Complex Data Scenarios. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; pp. 504–509. [Google Scholar]
- Yang, J.; Zhou, K.; Li, Y.; Liu, Z. Generalized out-of-distribution detection: A survey. Int. J. Comput. Vis. 2024, 132, 5635–5662. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 93–104. [Google Scholar]
- Tang, J.; Chen, Z.; Fu, A.W.C.; Cheung, D.W. Enhancing effectiveness of outlier detections for low density patterns. In Advances in Knowledge Discovery and Data Mining; Chen, M.S., Yu, P.S., Liu, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 535–548. [Google Scholar]
- Huang, J.; Zhu, Q.; Yang, L.; Feng, J. A non-parameter outlier detection algorithm based on natural neighbor. Knowl.-Based Syst. 2016, 92, 71–77. [Google Scholar] [CrossRef]
- Jin, W.; Tung, A.K.H.; Han, J.; Wang, W. Ranking outliers using symmetric neighborhood relationship. In Advances in Knowledge Discovery and Data Mining; Ng, W.K., Kitsuregawa, M., Li, J., Chang, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 577–593. [Google Scholar]
- He, Z.; Xu, X.; Deng, S. Discovering cluster-based local outliers. Pattern Recognit. Lett. 2003, 24, 1641–1650. [Google Scholar] [CrossRef]
- Amer, M.; Goldstein, M. Nearest-neighbor and clustering based anomaly detection algorithms for RapidMiner. In Proceedings of the 3rd RapidMiner Community Meeting and Conference (RCOMM’12), Shenzhen, China, 9–11 May 2012; pp. 1–12. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Campello, R.J.G.B.; Moulavi, D.; Zimek, A.; Sander, J. Hierarchical Density Estimates for Data Clustering, Visualization, and Outlier Detection. ACM Trans. Knowl. Discov. Data 2015, 10, 1–51. [Google Scholar] [CrossRef]
- Du, H.; Zhao, S.; Zhang, D.; Wu, J. Novel clustering-based approach for local outlier detection. In Proceedings of the 2016 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), San Francisco, CA, USA, 10–14 April 2016; pp. 802–811. [Google Scholar]
- Yamanishi, K.; Takeuchi, J.I.; Williams, G.; Milne, P. On-line unsupervised outlier detection using finite mixtures with discounting learning algorithms. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 320–324. [Google Scholar]
- Kriegel, H.P.; Kröger, P.; Schubert, E.; Zimek, A. LoOP: Local outlier probabilities. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 1649–1652. [Google Scholar]
- Papadimitriou, S.; Kitagawa, H.; Gibbons, P.B.; Faloutsos, C. LOCI: Fast outlier detection using the local correlation integral. In Proceedings of the 19th International Conference on Data Engineering, Bangalore, India, 5–8 March 2003; pp. 315–326. [Google Scholar]
- Tang, B.; He, H. A local density-based approach for outlier detection. Neurocomputing 2017, 241, 171–180. [Google Scholar] [CrossRef]
- Qin, X.; Cao, L.; Rundensteiner, E.A.; Madden, S. Scalable kernel density estimation-based local outlier detection over large data streams. In Proceedings of the 22nd International Conference on Extending Database Technology (EDBT), Lisbon, Portugal, 26–29 March 2019. [Google Scholar]
- Li, Z.; Zhao, Y.; Botta, N.; Ionescu, C.; Hu, X. COPOD: Copula-Based Outlier Detection. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 1118–1123. [Google Scholar]
- Li, Z.; Zhao, Y.; Hu, X.; Botta, N.; Ionescu, C.; Chen, H.G. ECOD: Unsupervised Outlier Detection Using Empirical Cumulative Distribution Functions. IEEE Trans. Knowl. Data Eng. 2022, 14, 71–77. [Google Scholar] [CrossRef]
- Papers with Code. ODDS (Outlier Detection Data Sets). Available online: https://paperswithcode.com/dataset/odds (accessed on 3 June 2025).
- Campos, G.O.; Zimek, A.; Sander, J.; Campello, R.J.; Micenková, B.; Schubert, E.; Assent, I.; Houle, M.E. On the evaluation of unsupervised outlier detection: Measures, data sets, and an empirical study. Data Min. Knowl. Discov. 2016, 30, 891–927. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).