
Research on the Remaining Life Prediction Method of Rolling Bearings Based on Optimized TPA-LSTM


Abstract
1. Introduction
2. Theoretical Analysis of the Rolling Bearing RUL Prediction Model
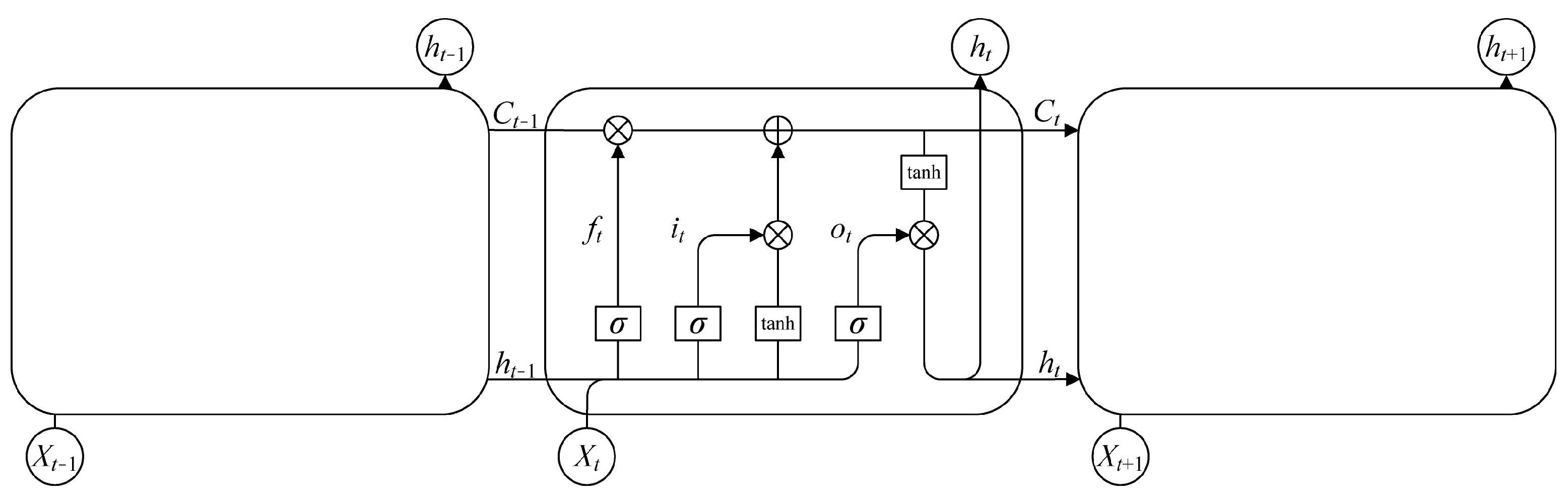
2.1. Basic Theory of LSTM
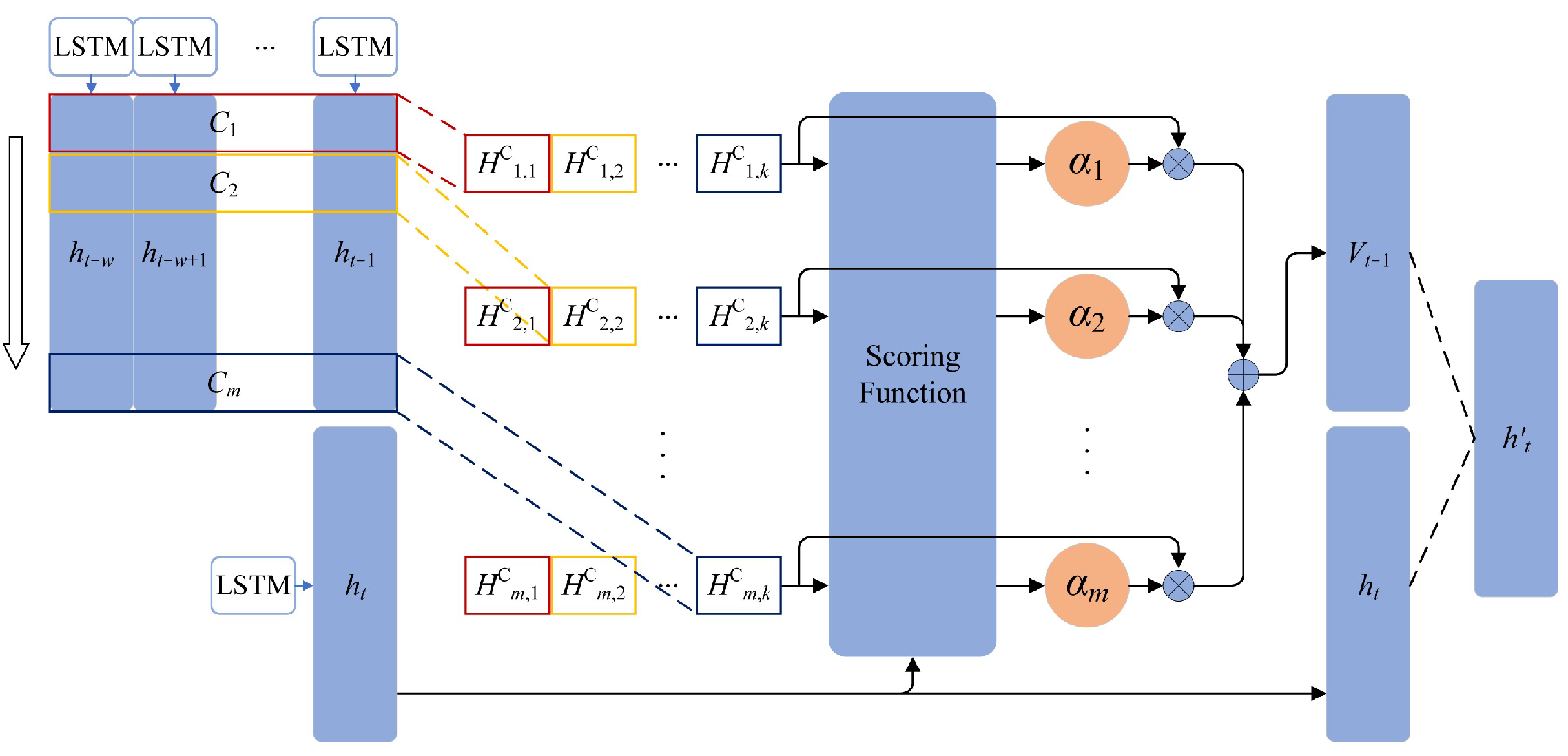
2.2. Basic Theory of TPA Mechanism
2.3. Basic Theory of GOA Algorithm
- (1)
- Random initialization of the population
- (2)
- Global search
- (3)
- Local search
- (4)
- Gazelle escape
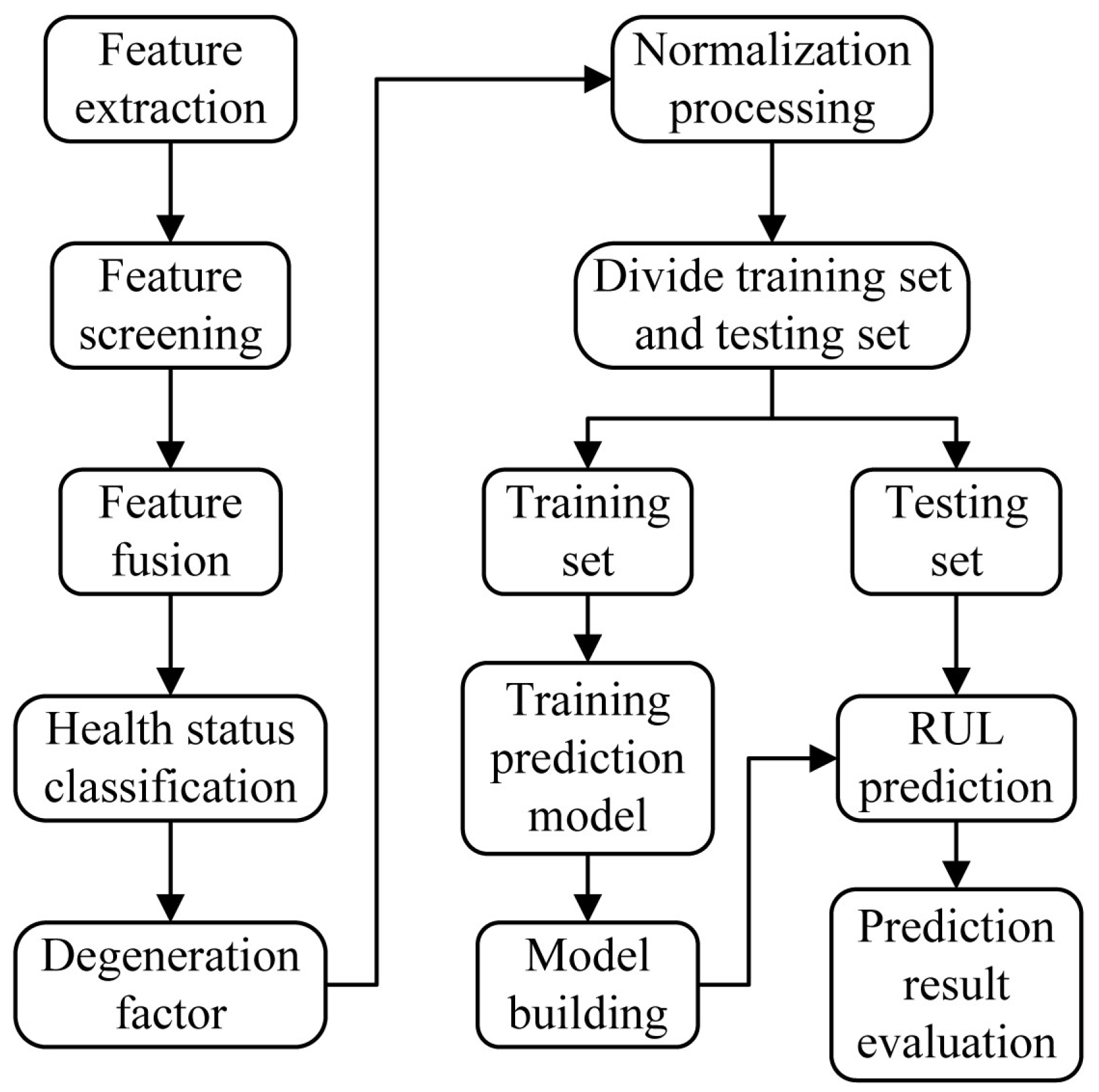
2.4. RUL Prediction of Rolling Bearing Based on GOA-TPA-LSTM
- (1)
- Extracting the degradation feature of rolling bearings from time domain, frequency domain, and time–frequency domain to build a feature set;
- (2)
- Screening feature sets based on monotonicity, time series correlation, and robustness;
- (3)
- Combining hierarchical clustering and PCA to fuse feature sets;
- (4)
- Using the top-down (TPD) algorithm to divide the fused features into health stage, degradation stage, and failure stage, and using the features of the degradation stage as degradation factors for subsequent prediction;
- (5)
- Normalize the degradation factor and divide the dataset into training and testing sets;
- (6)
- Using TPA-LSTM as the prediction model and optimizing its parameters through GOA, the training set is used as input to train the model;
- (7)
- Input the testing set into the trained prediction model for RUL prediction;
- (8)
- Evaluate the prediction results and verify the effectiveness of the method proposed in this paper.
3. Experimental Study
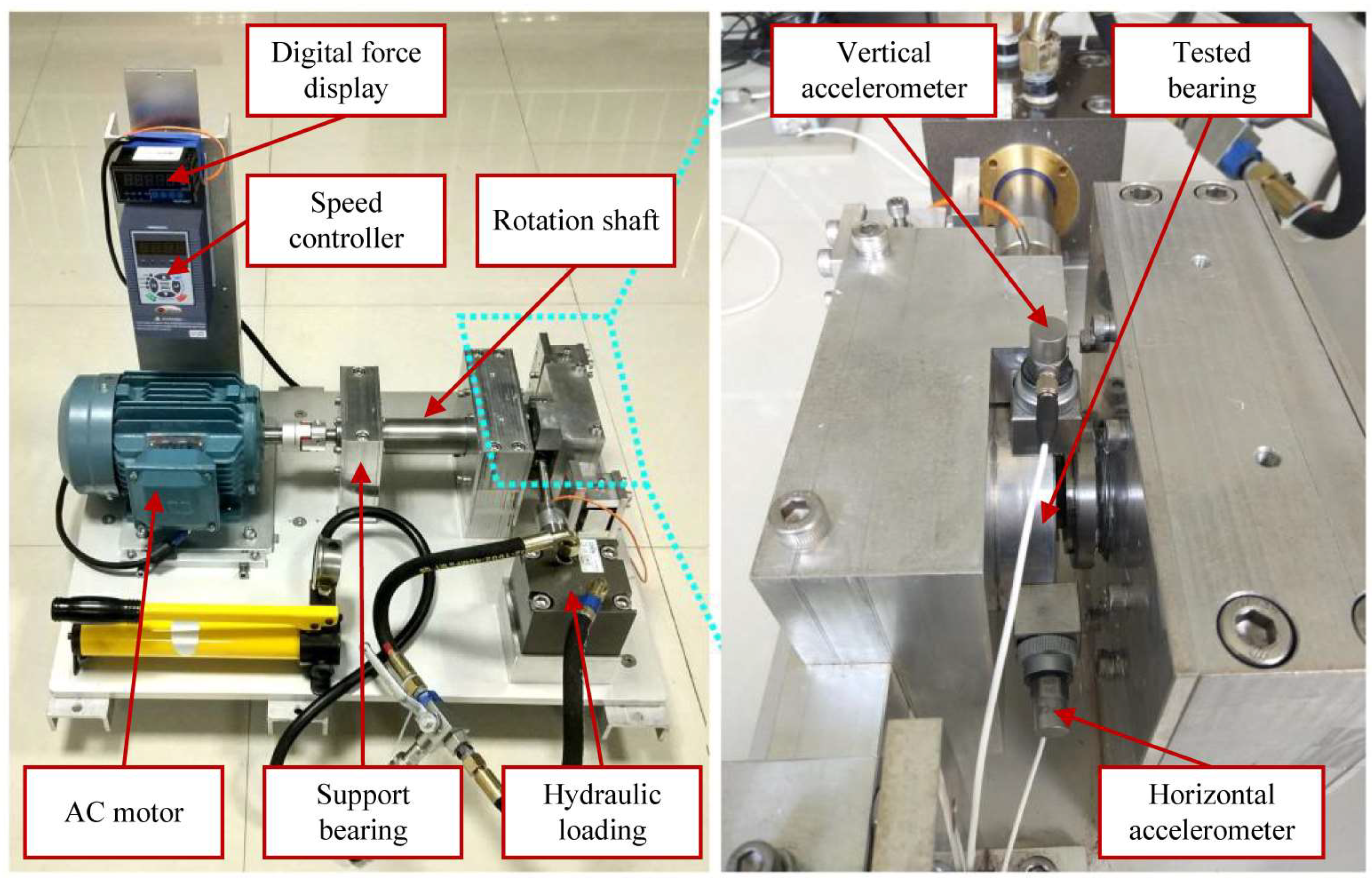
3.1. Introduction to Data Sets
3.2. Rolling Bearing HI Construction
3.2.1. Feature Extraction
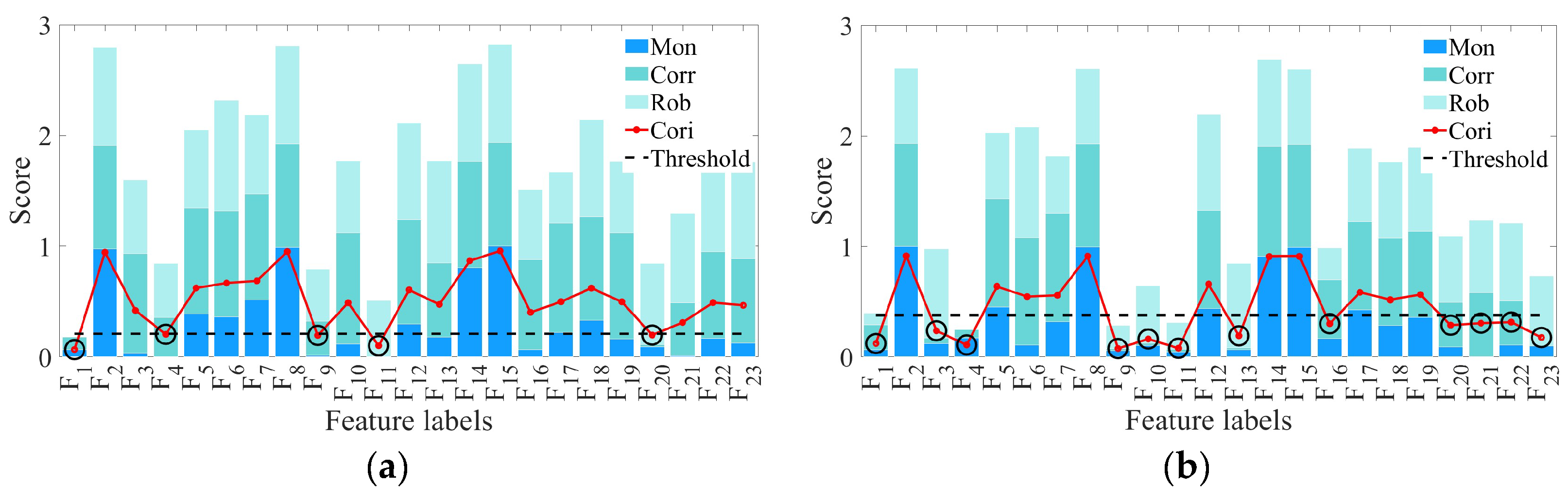
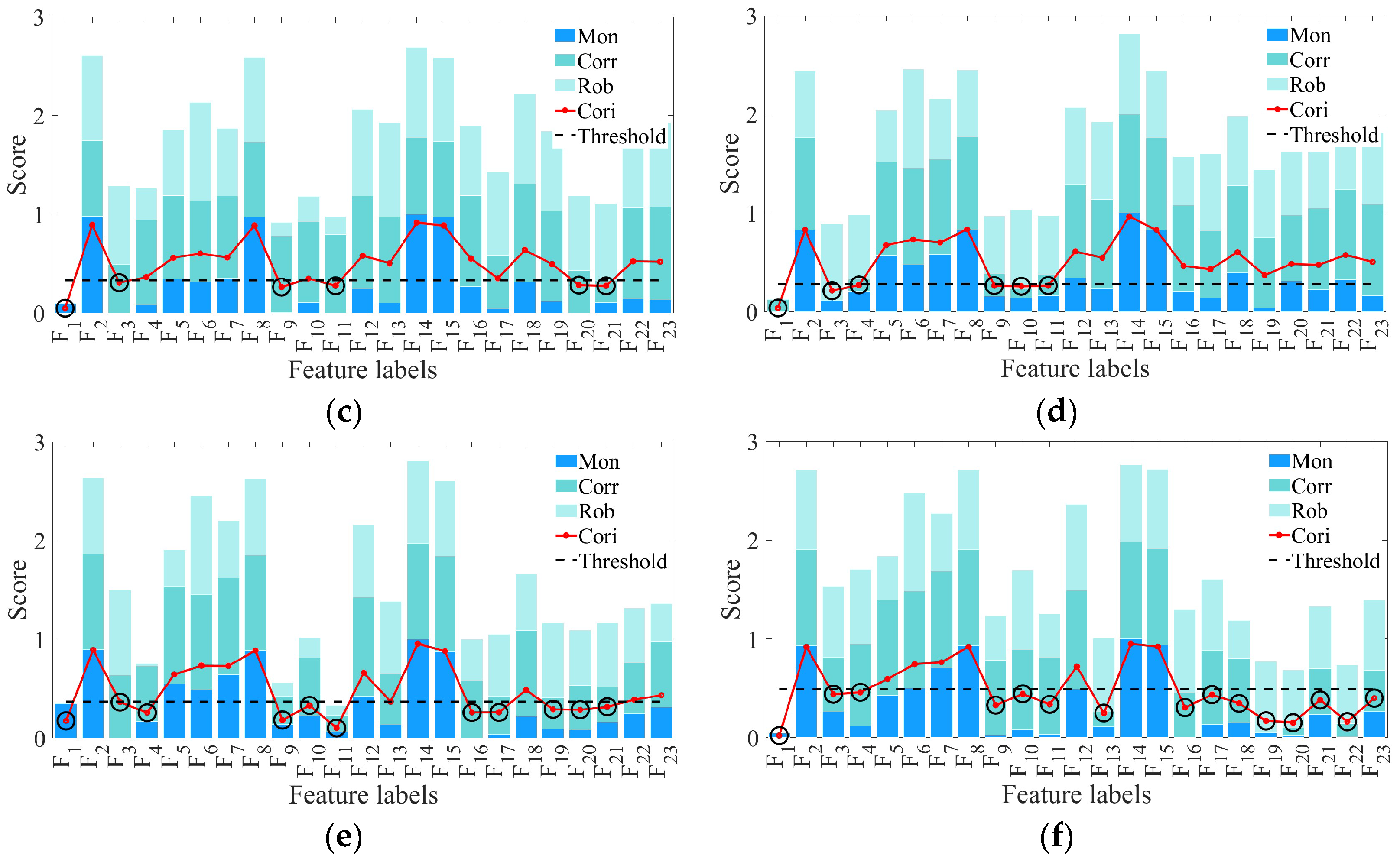
3.2.2. Screening of Rolling Bearing Feature Sets
3.2.3. Construction of a Rolling Bearing HI Based on Hierarchical Clustering and PCA Fusion
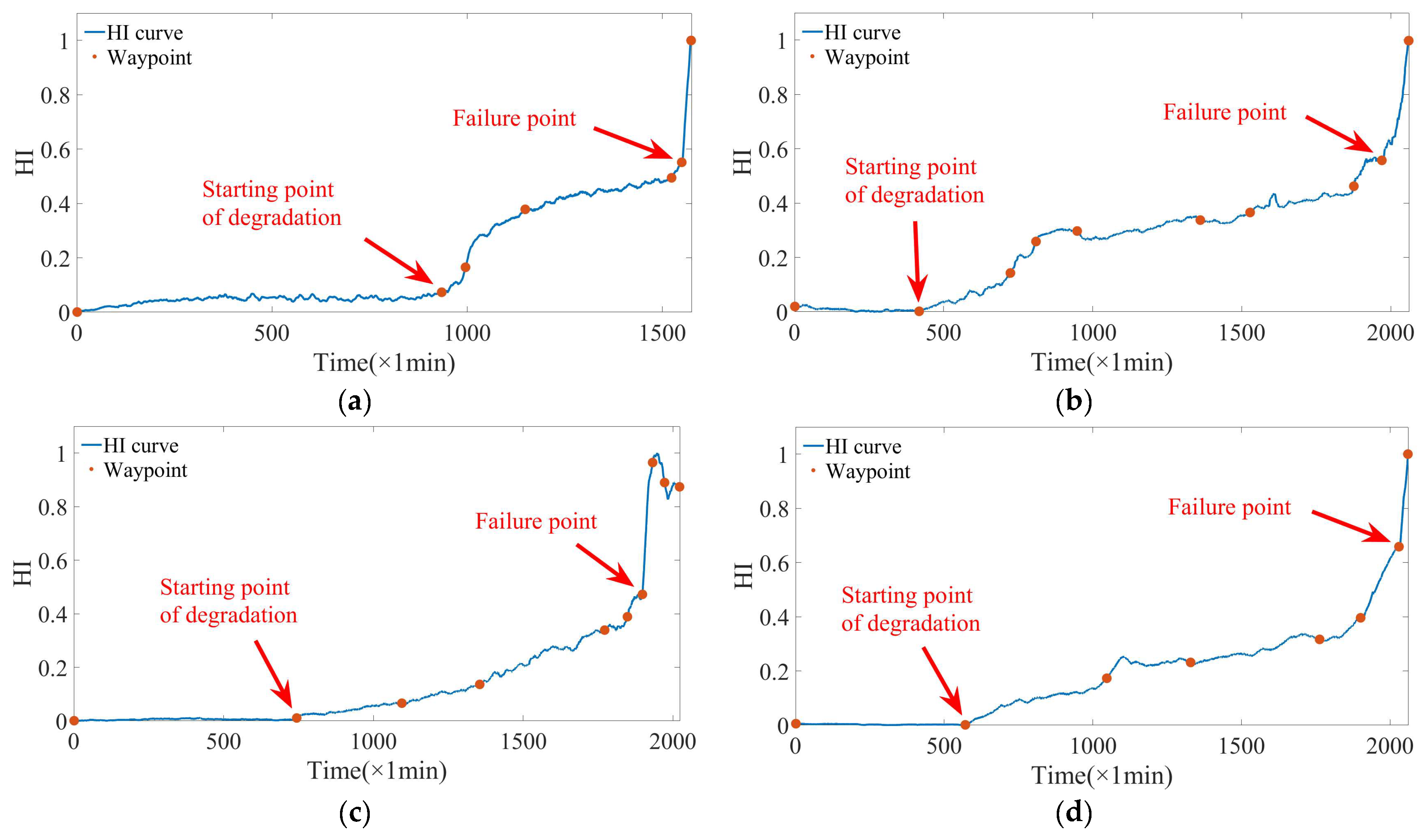
3.2.4. TPD-Based HI Health Status Classification of Rolling Bearings
3.3. Simulation Research
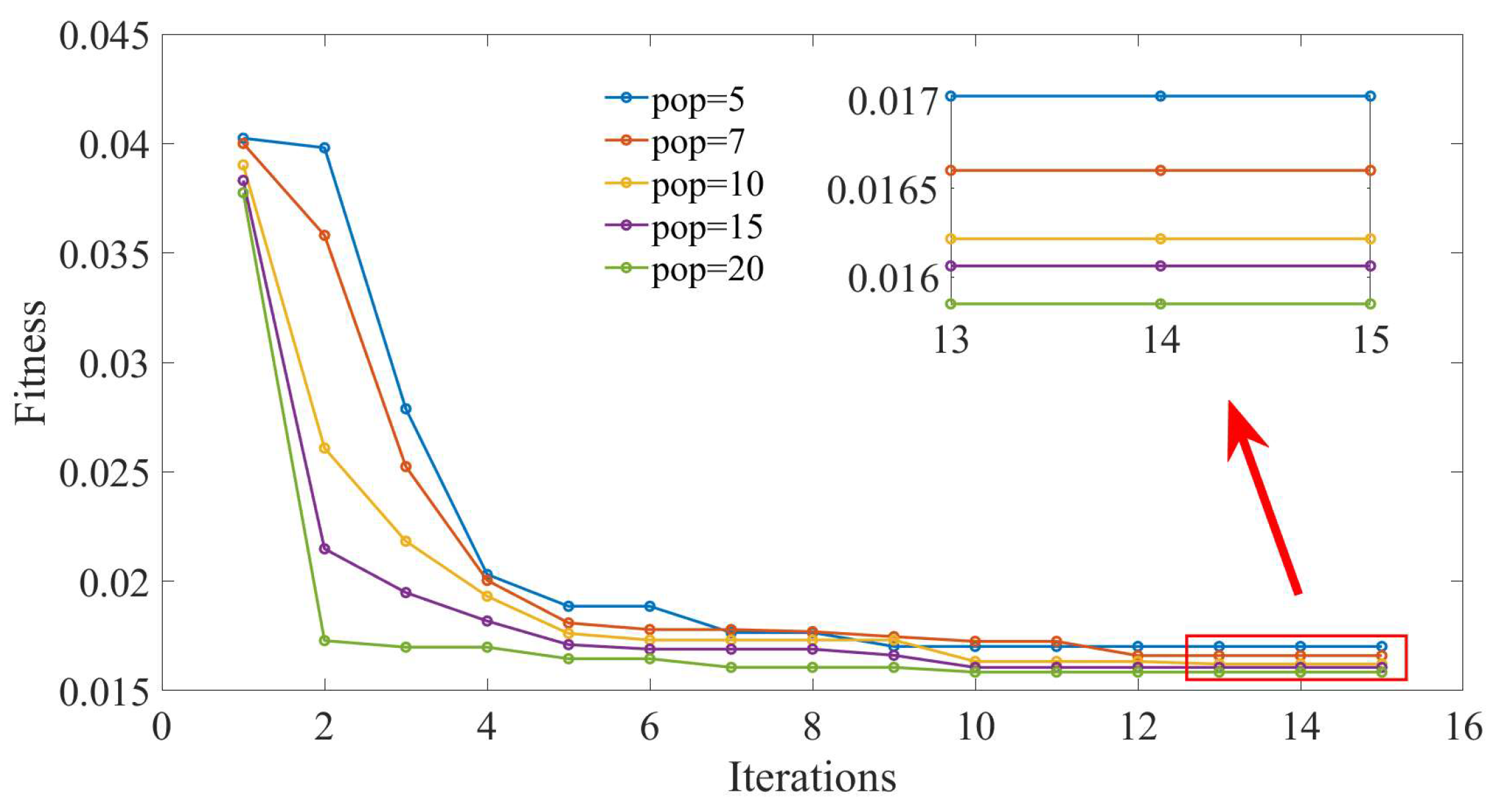
3.3.1. GOA Prediction Model Optimization Parameter Selection
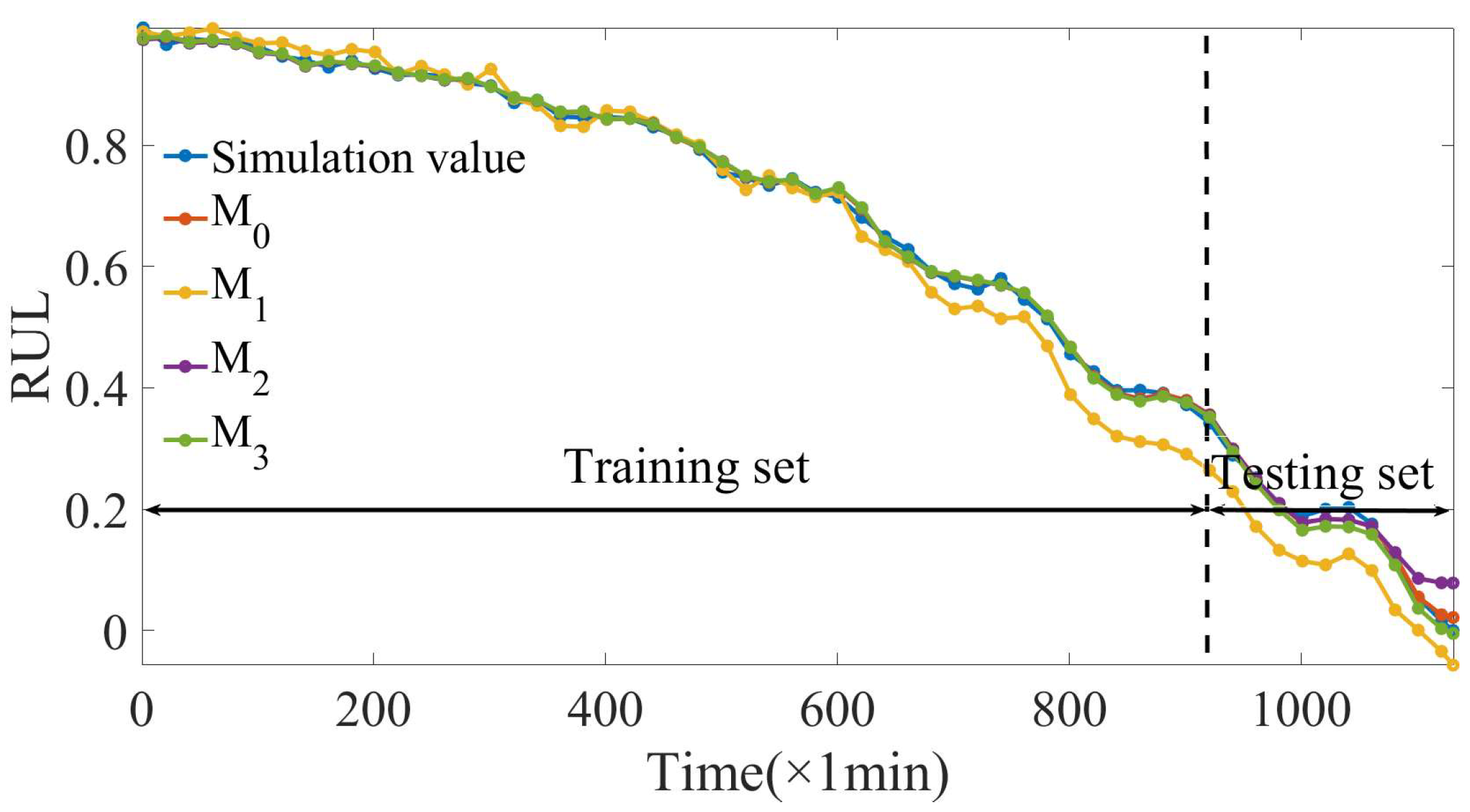
3.3.2. Simulation Data Prediction Results
3.4. Experimental Research
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rai, A.; Upadhyay, S.H. A review on signal processing techniques utilized in the fault diagnosis of rolling element bearings. Tribol. Int. 2016, 96, 289–306. [Google Scholar] [CrossRef]
- Wang, G.; He, Z.; Chen, X.; Lai, Y. Basic research on machinery fault diagnosis—What is the prescription. J. Mech. Eng. China 2013, 49, 63–72. [Google Scholar] [CrossRef]
- Peng, C.; Tseng, S. Mis-Specification Analysis of Linear Degradation Models. IEEE Trans. Reliab. 2009, 58, 444–455. [Google Scholar] [CrossRef]
- Feng, L.; Wang, H.; Si, X.; Zou, H. A State-Space-Based Prognostic Model for Hidden and Age-Dependent Nonlinear Degradation Process. IEEE Trans. Autom. Sci. Eng. 2013, 10, 1072–1086. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, Y.; Zi, Y. Switching State-Space Degradation Model With Recursive Filter/Smoother for Prognostics of Remaining Useful Life. IEEE Trans. Ind. Inform. 2019, 15, 822–832. [Google Scholar] [CrossRef]
- Pang, Z.; Si, X.; Hu, C.; Du, D.; Pei, H. A Bayesian Inference for Remaining Useful Life Estimation by Fusing Accelerated Degradation Data and Condition Monitoring Data. Reliab. Eng. Syst. Saf. 2021, 208, 107341. [Google Scholar] [CrossRef]
- Lei, Y. Intelligent Fault Diagnosis and Remaining Useful Life Prediction of Rotating Machinery; Butterworth-Heinemann: Amsterdam, The Netherlands, 2016; pp. 12–86. [Google Scholar] [CrossRef]
- Tang, Y.; Lin, F.; Zou, L. Research on the fault diagnosis method for reciprocating compressor based on LMD, MSE and LSSVM. Compress. Technol. China 2018, 2018, 1–7. [Google Scholar] [CrossRef]
- Wang, R.; Hou, Q.; Shi, R. Residual life prediction method of lithium battery based on variational mode decomposition and integration depth model. Chin. J. Sci. Instrum. 2021, 42, 111–120. [Google Scholar] [CrossRef]
- Deutsch, J.; He, D. Using Deep Learning-Based Approach to Predict Remaining Useful Life of Rotating Components. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 11–20. [Google Scholar] [CrossRef]
- Wang, F.; Liu, X.; Deng, G.; Yu, X.; Li, H.; Han, Q. Remaining Life Prediction Method for Rolling Bearing Based on the Long Short-Term Memory Network. Neural Process. Lett. 2019, 50, 2437–2454. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, L.; Xu, J. Degradation feature selection for remaining useful life prediction of rolling element bearings. Qual. Reliab. Eng. Int. 2016, 32, 547–554. [Google Scholar] [CrossRef]
- Tayade, A.; Patil, S.; Phalle, V.; Kazi, F.; Powar, S. Remaining useful life (RUL) prediction of bearing by using regression model and principal component analysis (PCA) technique. Vibroeng. Procedia 2019, 23, 30–36. [Google Scholar] [CrossRef]
- Mao, W.; He, J.; Tang, J.; Li, Y. Predicting remaining useful life of rolling bearings based on deep feature representation and long short-term memory neural network. Adv. Mech. Eng. 2018, 10, 1687814018817184. [Google Scholar] [CrossRef]
- Li, N.; Lei, Y.; Lin, J.; Ding, S.X. An Improved Exponential Model for Predicting Remaining Useful Life of Rolling Element Bearings. IEEE Trans. Ind. Electron. 2015, 62, 7762–7773. [Google Scholar] [CrossRef]
- Jin, X.; Sun, Y.; Que, Z.; Wang, Y.; Chow, T.W. Anomaly Detection and Fault Prognosis for Bearings. IEEE Trans. Instrum. Meas. 2016, 65, 2046–2054. [Google Scholar] [CrossRef]
- Wang, L.; Wu, Z.; Fu, Y.; Yang, G. Remaining life predictions of fan based on time series analysis and BP neural networks. In Proceedings of the 2016 IEEE Information Technology, Networking, Electronic and Automation Control Conference, Chongqing, China, 20–22 May 2016; pp. 607–611. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, L.; Zhao, W. Tool Life Prediction Model Based on GA-BP Neural Network, Materials Science Forum; Trans Tech Publications Ltd.: Wollerau, Switzerland, 2016; Volume 836–837, pp. 256–262. Available online: https://www.scientific.net/MSF.836-837.256 (accessed on 26 March 2024).
- Chen, X.; Xiao, H.; Guo, Y.; Kang, Q. A multivariate grey RBF hybrid model for residual useful life prediction of industrial equipment based on state data. Int. J. Wirel. Mob. Comput. 2016, 10, 90. [Google Scholar] [CrossRef]
- Wang, X.; Han, M. Online sequential extreme learning machine with kernels for nonstationary time series prediction. Neurocomputing 2014, 145, 90–97. [Google Scholar] [CrossRef]
- Miao, J.; Li, X.; Ye, J. Predicting research of mechanical gyroscope life based on wavelet support vector. In Proceedings of the 2015 First International Conference on Reliability Systems Engineering (ICRSE), Beijing, China, 21–23 October 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Babu, G.S.; Zhao, P.; Li, X. Deep Convolutional Neural Network Based Regression Approach for Estimation of Remaining Useful Life, Database Systems for Advanced Applications. In Proceedings of the 21st International Conference, DASFAA 2016, Dallas, TX, USA, 16–19 April 2016; Part 21; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 214–228. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, N.; Peng, W. Estimation of Bearing Remaining Useful Life Based on Multiscale Convolutional Neural Network. IEEE Trans. Ind. Electron. 2019, 66, 3208–3216. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q. Deep learning-based remaining useful life estimation of bearings using multi-scale feature extraction. Reliab. Eng. Syst. Saf. 2019, 182, 208–218. [Google Scholar] [CrossRef]
- Mo, R.; Li, T.; Si, X.; Zhu, X. Remaining useful life prediction for equipment using residual network and convolutional attention mechanism. J. Xi’an Jiaotong Univ. China 2022, 56, 1–9. [Google Scholar] [CrossRef]
- Heimes, F.O. Recurrent neural networks for remaining useful life estimation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; pp. 1–6. [Google Scholar] [CrossRef]
- Guo, L.; Li, N.; Jia, F.; Lei, Y. A recurrent neural network based health indicator for remaining useful life prediction of bearings. Neurocomputing 2017, 240, 98–109. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Yan, T.; Li, N.; Guo, L. Recurrent convolutional neural network: A new framework for remaining useful life prediction of machinery. Neurocomputing 2020, 379, 117–129. [Google Scholar] [CrossRef]
- Huang, C.; Huang, H.; Li, Y. A Bidirectional LSTM Prognostics Method Under Multiple Operational Conditions. IEEE Trans. Ind. Electron. 2019, 66, 8792–8802. [Google Scholar] [CrossRef]
- Ma, M.; Mao, Z. Deep-Convolution-Based LSTM Network for Remaining Useful Life Prediction. IEEE Trans. Ind. Inform. 2021, 17, 1658–1667. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar] [CrossRef]
- She, D.; Jia, M. A BiGRU method for remaining useful life prediction of machinery. Measurement 2021, 167, 108277. [Google Scholar] [CrossRef]
- Jiang, G.; Yang, J.; Cheng, T. Remaining useful life prediction of rolling bearings based on Bayesian neural network and uncertainty quantification. Qual. Reliab. Eng. Int. 2023, 39, 1756–1774. [Google Scholar] [CrossRef]
- Shih, S.; Sun, F.; Lee, H. Temporal pattern attention for multivariate time series forecasting. Mach. Learn. 2019, 108, 1421–1441. [Google Scholar] [CrossRef]
- Agushaka, J.O.; Ezugwu, A.E.; Abualigah, L. Gazelle optimization algorithm: A novel nature-inspired metaheuristic optimizer. Neural Comput. Appl. 2023, 35, 4099–4131. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Li, N. A Hybrid Prognostics Approach for Estimating Remaining Useful Life of Rolling Element Bearings. IEEE Trans. Reliab. 2020, 69, 401–412. [Google Scholar] [CrossRef]
- Wen, J.; Gao, H. A prediction method of bearing residual life based on UPF. J. Vib. Shock. 2018, 37, 208–213. [Google Scholar] [CrossRef]
- Eamonn, K.; Selina, C.; David, H.; Michael, P. Segmenting Time Series: A Survey and Novel Approach. In Data Mining in Time Series Databases; World Scientific: Singapore, 2004; pp. 1–21. [Google Scholar] [CrossRef]
- Ye, Z.-S.; Chen, N. The inverse gaussian process as a degradation model. Technometrics 2014, 56, 302–311. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Working Conditions | Rotating Speed/r·min−1 | Radial Force/kN |
|---|---|---|
| 1 | 2100 | 12 |
| 2 | 2250 | 11 |
| 3 | 2400 | 10 |
| Bearing Labels | Hierarchical Clustering Results | Contribution of Fused Feature | avh | |
|---|---|---|---|---|
| Cluster | Feature Labels | |||
| C1 | D1 | F2, F5, F6, F7, F8, F14, F15 | 99.63% | 0.1280 |
| D2 | F3, F12, F13, F16, F18, F21, F22, F23 | 95.40% | 0.2106 | |
| D3 | F10, F17, F19 | 97.26% | 0.3415 | |
| C2 | D1 | F2, F5, F6, F7, F8, F14, F15 | 98.54% | 0.1701 |
| D2 | F12, F18 | 98.51% | 0.3551 | |
| D3 | F17, F19 | 99.21% | 0.2892 | |
| C3 | D1 | F2, F5, F6, F7, F8, F14, F15 | 99.23% | 0.1500 |
| D2 | F4, F10 | 98.38% | 0.1729 | |
| D3 | F12, F13, F16, F17, F18, F19, F22, F23 | 95.34% | 0.2642 | |
| C4 | D1 | F2, F5, F6, F7, F8, F14, F15 | 98.42% | 0.1793 |
| D2 | F12, F13, F16, F17, F18, F19, F22, F23 | 95.51% | 0.2478 | |
| D3 | F20, F21 | 97.77% | 0.4021 | |
| C5 | D1 | F2, F5, F6, F7, F8, F14, F15 | 99.61% | 0.3883 |
| D2 | F12, F18 | 96.14% | 0.4845 | |
| D3 | F13, F22, F23 | 95.15% | 0.3999 | |
| C6 | D1 | F2, F5, F6, F7, F8, F15 | 99.99% | 0.2993 |
| D2 | F14 | 100% | 0.4214 | |
| D3 | F12 | 100% | 0.2893 | |
| Parameters to be Optimized | Initial Value | Optimization Boundary |
|---|---|---|
| LSTM layer units | 40 | [20, 200] |
| Dropout rate | 0.2 | [0.1, 0.4] |
| Training period | 100 | [30, 300] |
| Learning rate | 0.01 | [10 × 10−4, 0.1] |
| Index | Data Set | Prediction Model | |||
|---|---|---|---|---|---|
| M0 | M1 | M2 | M3 | ||
| RMSE | Training | 0.78 | 3.70 | 0.83 | 0.86 |
| Testing | 0.94 | 7.69 | 2.31 | 1.69 | |
| R2 | Training | 0.999 | 0.906 | 0.995 | 0.997 |
| Testing | 0.997 | 0.539 | 0.971 | 0.991 | |
| Bearing | Index | Prediction Model | |||
|---|---|---|---|---|---|
| M0 | M1 | M2 | M3 | ||
| C3 | RMSE | 2.390 | 6.505 | 6.166 | 6.084 |
| R2 | 0.993 | 0.950 | 0.955 | 0.956 | |
| PICP | 0.737 | 0.426 | 0.481 | 0.467 | |
| PINAW | 0.965 | 1.318 | 0.926 | 0.907 | |
| C6 | RMSE | 3.944 | 11.118 | 8.048 | 4.509 |
| R2 | 0.981 | 0.861 | 0.923 | 0.976 | |
| PICP | 0.435 | 0.122 | 0.157 | 0.524 | |
| PINAW | 0.943 | 0.737 | 0.906 | 0.925 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, N.; Tang, Y.; Li, A.; Jiang, P. Research on the Remaining Life Prediction Method of Rolling Bearings Based on Optimized TPA-LSTM. Machines 2024, 12, 224. https://doi.org/10.3390/machines12040224
Lei N, Tang Y, Li A, Jiang P. Research on the Remaining Life Prediction Method of Rolling Bearings Based on Optimized TPA-LSTM. Machines. 2024; 12(4):224. https://doi.org/10.3390/machines12040224
Chicago/Turabian StyleLei, Na, Youfu Tang, Ao Li, and Peichen Jiang. 2024. "Research on the Remaining Life Prediction Method of Rolling Bearings Based on Optimized TPA-LSTM" Machines 12, no. 4: 224. https://doi.org/10.3390/machines12040224
APA StyleLei, N., Tang, Y., Li, A., & Jiang, P. (2024). Research on the Remaining Life Prediction Method of Rolling Bearings Based on Optimized TPA-LSTM. Machines, 12(4), 224. https://doi.org/10.3390/machines12040224