

Digital Twin Data Management: Framework and Performance Metrics of Cloud-Based ETL System


Abstract
1. Introduction
2. Related Work
2.1. Big Data in Digital Twin
- Data Volume: Digital twins generate large volumes of data as they continuously collect information from various sensors and devices to create a real-time, dynamic representation of a physical object or system.
- Data Variety: The data associated with digital twins comes from a diverse range of sources, including IoT sensors, operational systems, and environmental data, encompassing a wide variety of formats.
- Real-Time Processing: Digital twins often require real-time or near-real-time data processing to accurately reflect the current state of the physical entity they represent. This demands efficient and robust big data processing capabilities.
- Complex Analytics: The use of digital twins involves complex analytics, including predictive modeling and simulation, to gain insights and make decisions based on the data collected. This requires sophisticated data processing and analysis techniques, which are hallmarks of big data applications.
- Integration Challenges: Like other big data applications, digital twins face challenges in integrating and harmonizing data from disparate sources, ensuring data quality, and managing the scale of data.
2.2. Current Approaches to ETL
- Service-oriented architecture (SOA);
- Web-based technologies (e.g., semantic web);
- Fault-tolerant algorithms;
- Structured Query Languages (SQL);
- Parallelization (e.g., MapReduce);
- Domain ontology;
- Multi-agent systems (MAS);
- Conceptual modeling (e.g., Unified Modeling Language (UML) and Business Process Modeling Notation (BPMN));
- Metadata repository [16].
2.3. Challenges and Limitations in Existing Systems
2.4. Overview of Existing Solutions: Apache Airflow and AWS Batch
2.5. Relevance to the Present Study
3. Data Processing Modalities in Digital Twin Systems
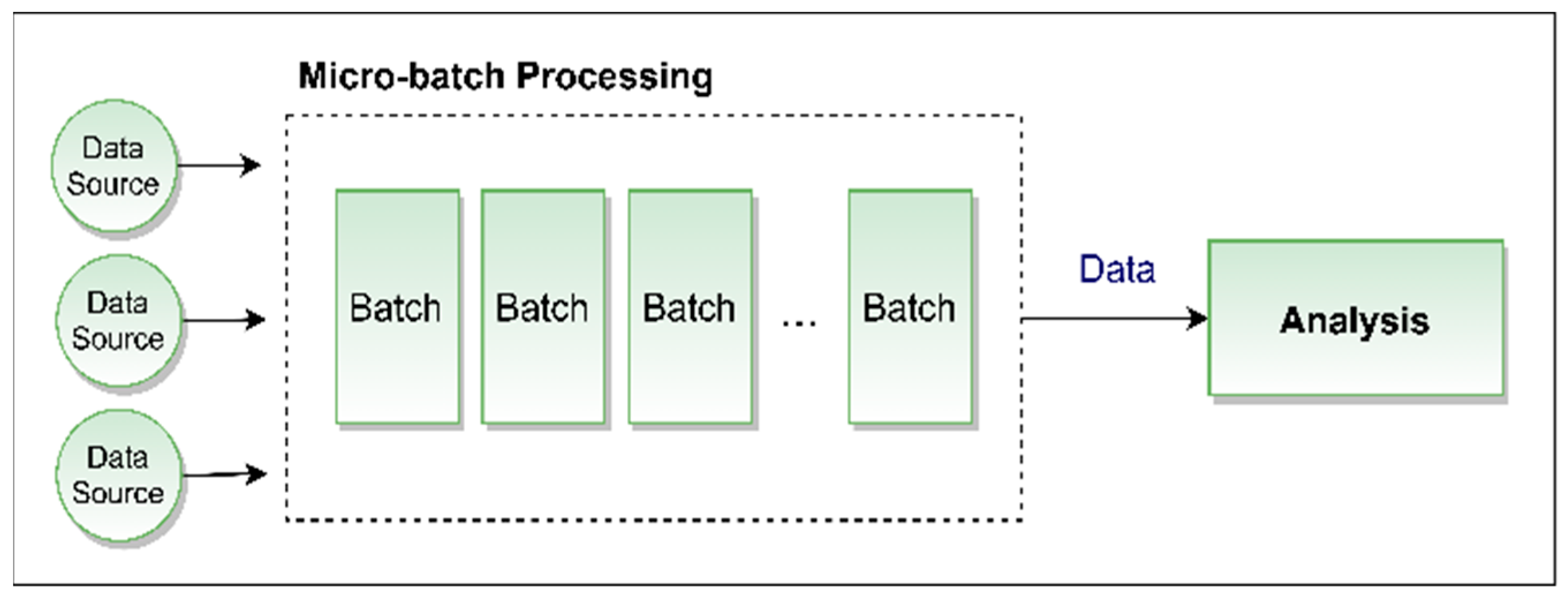
3.1. Micro-Batch Data Processing
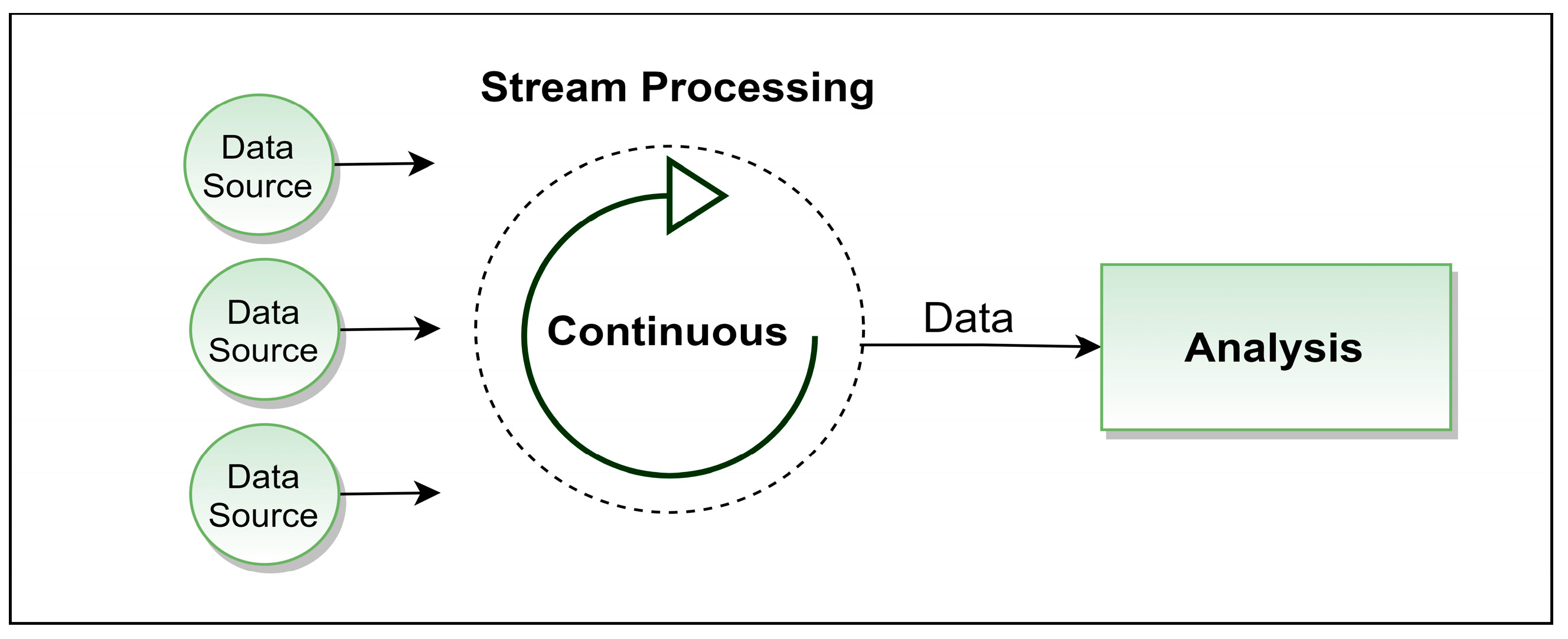
3.2. Stream Data Processing
3.3. Rationale behind Adopting Batch Processing
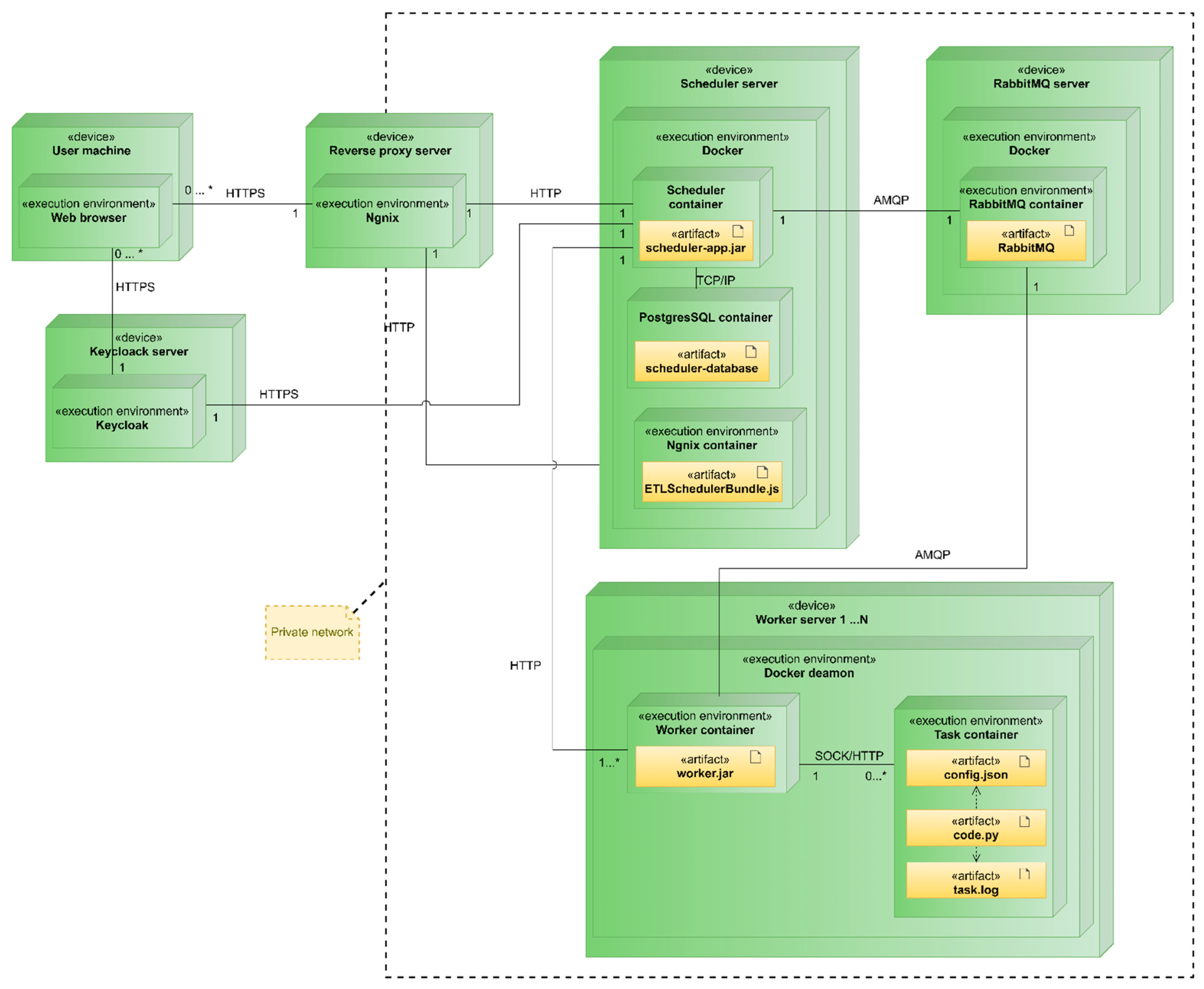
4. Architectural Framework of Docker-Integrated Task Management in the EA-SAS Cloud Scheduler
4.1. System Components and Topology
- Reverse Proxy Server: Functions as an intermediary for all external system access. It enhances traffic monitoring and keeps task executor servers secure from external access, forming a crucial part of the company’s infrastructure.
- Keycloak Server: Hosts the Keycloak authentication service, centralizing all system authentication processes. This server is a critical component of the infrastructure.
- Scheduler Server: Contains the scheduler, user interface components, and a PostgreSQL database. It is primarily responsible for task scheduling and storing execution histories.
- RabbitMQ Server: Hosts the RabbitMQ message-queuing service, facilitating a significant portion of the communication between the scheduler and task executor servers.
- Worker Server: Represents the task executor subsystem. The number of these servers is theoretically unlimited, though the centralized architecture might impose some constraints. Each server performs tasks within separate containers and maintains task logs.
4.2. Integration and Communication
4.2.1. Docker Execution Environment
4.2.2. Temporal Composition of a Task
- Scheduler Delay (t1): This interval commences with the scheduled time of task execution and culminates when the task is triggered. It encapsulates the delay between when a task is scheduled and its initiation.
- Queuing/Task Distribution Delay (t2): Post triggering, the task enters a queuing system. The duration represented by t2 captures the time taken from the task entry into this queue until the system identifies and designates a suitable worker for its execution.
- Config Fetching (t3): During this phase, the system retrieves the task metadata essential for determining the conditions under which the task will be executed.
- Data Fetching (Extract, t4): Here, specific datasets, as outlined in the previously fetched configuration, are acquired to facilitate task execution.
- Calculations (Transform, t5): This interval is central to the task’s purpose, wherein the actual computational operations are executed.
- Uploading/Saving Data (Load, t6): Upon computation completion, the results are transmitted and stored within the digital twin platform.
- Confirm Delay (t7): This final interval signifies the time lapse between task execution completion and its acknowledgment on the user interface.
5. Results
5.1. Objective Derivation and Hypothesis Formation
5.2. Experimental Setup and Methodology
- Task Design: We utilized a basic Python task to maintain consistency in our measurements, thereby removing any discrepancies that could result from intricate task executions or data retrieval processes.
- Test Configuration: Our testing procedure involved establishing a directed acyclic graph (DAG)/task flow with the aforementioned task. We meticulously recorded the interval from the task’s scheduling point to the confirmation of the DAG/task flow.
- Test Scope: The experiment spanned a wide range of task counts, from 1 to 1000 per minute, to thoroughly assess the performance of the schedulers under varying operational loads.
- Infrastructure: Both scheduling tools were assessed using the identical virtual private server (VPS) setup, ensuring a controlled environment. Executors were isolated on a separate server to preclude any potential disturbances to the scheduling assessment. The VPS’s specifications are detailed in Table 3.
5.3. Quantitative Metrics and Analytical Outcomes
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- EA-SAS Digital Twin. Available online: https://www.energyadvice.lt/en/products/ (accessed on 8 August 2022).
- Fuller, A.; Fan, Z.; Day, C.; Barlow, C. Digital Twin: Enabling Technologies, Challenges and Open Research. IEEE Access 2020, 8, 108952–108971. [Google Scholar] [CrossRef]
- Minerva, R.; Lee, G.M.; Crespi, N. Digital Twin in the IoT Context: A Survey on Technical Features, Scenarios, and Architectural Models. Proc. IEEE 2020, 108, 1785–1824. [Google Scholar] [CrossRef]
- Loaiza, J.H.; Cloutier, R.J. Analyzing the Implementation of a Digital Twin Manufacturing System: Using a Systems Thinking Approach. Systems 2022, 10, 22. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Kang, C.; Xia, Q. Clustering of Electricity Consumption Behavior Dynamics Toward Big Data Applications. IEEE Trans. Smart Grid 2016, 7, 2437–2447. [Google Scholar] [CrossRef]
- Wang, Y.; Kang, X.; Chen, Z. A survey of Digital Twin techniques in smart manufacturing and management of energy applications. Green Energy Intell. Transp. 2022, 1, 100014. [Google Scholar] [CrossRef]
- ISO 23247-1:2021; Automation Systems and Integration—Digital Twin Framework for Manufacturing—Part 1: Overview and General Principles. International Organization for Standardization: Geneva, Switzerland, 2021. Available online: https://www.iso.org/standard/75066.html (accessed on 18 January 2024).
- ISO 23247-2:2021; Automation Systems and Integration—Digital Twin Framework for Manufacturing—Part 2: Reference Architecture. International Organization for Standardization: Geneva, Switzerland, 2021. Available online: https://www.iso.org/standard/78743.html (accessed on 18 January 2024).
- ISO 23247-3:2021; Automation Systems and Integration—Digital Twin Framework for Manufacturing—Part 3: Digital Representation of Manufacturing Elements. International Organization for Standardization: Geneva, Switzerland, 2021. Available online: https://www.iso.org/standard/78744.html (accessed on 18 January 2024).
- ISO 23247-4:2021; Automation Systems and Integration—Digital Twin Framework for Manufacturing—Part 4: Information Exchange. International Organization for Standardization: Geneva, Switzerland, 2021. Available online: https://www.iso.org/standard/78745.html (accessed on 18 January 2024).
- Shao, G.; Frechette, S.; Srinivasan, V. An analysis of the new ISO 23247 series of standards on digital twin framework for manufacturing. In Proceedings of the ASME 2023 18th International Manufacturing Science and Engineering Conference, New Brunswick, NJ, USA, 12–16 June 2023. [Google Scholar]
- Hribernik, K.; Cabri, G.; Mandreoli, F.; Mentzas, G. Autonomous, context-aware, adaptive Digital Twins—State of the art and roadmap. Comput. Ind. 2021, 133, 103508. [Google Scholar] [CrossRef]
- Tao, F.; Cheng, Y.; Cheng, J.; Zhang, M.; Xu, W.; Qi, Q. Theories and technologies for cyber-physical fusion in digital twin shop-floor. Jisuanji Jicheng Zhizao Xitong/Comput. Integr. Manuf. Syst. CIMS 2017, 23, 1603–1611. [Google Scholar] [CrossRef]
- Zhou, G.; Zhang, C.; Li, Z.; Ding, K.; Wang, C. Knowledge-driven digital twin manufacturing cell towards intelligent manufacturing. Int. J. Prod. Res. 2020, 58, 1034–1051. [Google Scholar] [CrossRef]
- Zhang, R.; Wang, F.; Cai, J.; Wang, Y.; Guo, H.; Zheng, J. Digital twin and its applications: A survey. Int. J. Adv. Manuf. Technol. 2022, 123, 4123–4136. [Google Scholar] [CrossRef]
- Nwokeji, J.; Aqlan, F.; Anugu, A.; Olagunju, A. Big data etl implementation approaches: A systematic literature review. In Proceedings of the International Conference on Software Engineering and Knowledge Engineering, SEKE, San Francisco, CA, USA, 1–3 July 2018; pp. 714–715. [Google Scholar] [CrossRef]
- Ali, S.M.F.; Wrembel, R. From conceptual design to performance optimization of ETL workflows: Current state of research and open problems. VLDB J. 2017, 26, 777–801. [Google Scholar] [CrossRef]
- Hu, W.; Zhang, T.; Deng, X.; Liu, Z.; Tan, J. Digital twin: A state-of-the-art review of its enabling technologies, applications and challenges. J. Intell. Manuf. Spec. Equip. 2021, 2, 1–34. [Google Scholar] [CrossRef]
- Siddiqa, A.; Hashem, I.A.T.; Yaqoob, I.; Marjani, M.; Shamshirband, S.; Gani, A.; Nasaruddin, F. A survey of big data management: Taxonomy and state-of-the-art. J. Netw. Comput. Appl. 2016, 71, 151–166. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, M.; Nee, A.Y.C. Digital Twin and Big Data. In Digital Twin Driven Smart Manufacturing; Academic Press: Cambridge, MA, USA, 2019; pp. 183–202. [Google Scholar] [CrossRef]
- Sepasgozar, S.M.E. Differentiating Digital Twin from Digital Shadow: Elucidating a Paradigm Shift to Expedite a Smart, Sustainable Built Environment. Buildings 2021, 11, 151. [Google Scholar] [CrossRef]
- El Mokhtari, K.; Panushev, I.; McArthur, J.J. Development of a Cognitive Digital Twin for Building Management and Operations. Front. Built Environ. 2022, 8, 856873. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, M.; Nee, A.Y.C. Digital Twin and Cloud, Fog, Edge Computing. Digital Twin Driven Smart Manufacturing; Academic Press: Cambridge, MA, USA, 2019; pp. 171–181. [Google Scholar] [CrossRef]
- Al-Ali, A.R.; Gupta, R.; Batool, T.Z.; Landolsi, T.; Aloul, F.; Al Nabulsi, A. Digital Twin Conceptual Model within the Context of Internet of Things. Futur. Internet 2020, 12, 163. [Google Scholar] [CrossRef]
- Li, X.; Liu, H.; Wang, W.; Zheng, Y.; Lv, H.; Lv, Z. Big data analysis of the Internet of Things in the digital twins of smart city based on deep learning. Futur. Gener. Comput. Syst. 2022, 128, 167–177. [Google Scholar] [CrossRef]
- Wallner, B.; Zwölfer, B.; Trautner, T.; Bleicher, F. Digital Twin Development and Operation of a Flexible Manufacturing Cell using ISO 23247. Procedia CIRP 2023, 120, 1149–1154. [Google Scholar] [CrossRef]
- Lu, Y.; Liu, C.; Kevin, I.; Wang, K.; Huang, H.; Xu, X. Digital Twin-driven smart manufacturing: Connotation, reference model, applications and research issues. Robot. Comput. Integr. Manuf. 2020, 61, 101837. [Google Scholar] [CrossRef]
- Best Practices—Airflow Documentation. Available online: https://airflow.apache.org/docs/apache-airflow/stable/best-practices.html (accessed on 8 August 2022).
- Aquilanti, P.-Y.; Kendrex, S.; Koop, M. AWS Batch Dos and Don’ts: Best Practices in a Nutshell|AWS HPC Blog. Available online: https://aws.amazon.com/blogs/hpc/aws-batch-best-practices/ (accessed on 8 August 2022).
- Liston, B. Creating a Simple ‘Fetch & Run’ AWS Batch Job|AWS Compute Blog. Available online: https://aws.amazon.com/blogs/compute/creating-a-simple-fetch-and-run-aws-batch-job/ (accessed on 8 August 2022).
- VPS Serveriai—Interneto Vizija. Available online: https://www.iv.lt/vps-serveriai/#konteineriai (accessed on 10 August 2022).
- Amazon EC2 Pricing—Amazon Web Services. Available online: https://aws.amazon.com/ec2/pricing/ (accessed on 10 August 2022).
- Khalid, M.; Yousaf, M.M. A Comparative Analysis of Big Data Frameworks: An Adoption Perspective. Appl. Sci. 2021, 11, 11033. [Google Scholar] [CrossRef]
- Rovnyagin, M.M.; Shipugin, V.A.; Ovchinnikov, K.A.; Durachenko, S.V. Intelligent container orchestration techniques for batch and micro-batch processing and data transfer. Procedia Comput. Sci. 2021, 190, 684–689. [Google Scholar] [CrossRef]
- Pishgoo, B.; Azirani, A.A.; Raahemi, B. A hybrid distributed batch-stream processing approach for anomaly detection. Inf. Sci. 2020, 543, 309–327. [Google Scholar] [CrossRef]
- ISO/IEC TR 30172:2023; Internet of THINGS (loT)—Digital twin—Use Cases. International Organization for Standardization: Geneva, Switzerland, 2023. Available online: https://www.iso.org/standard/81578.html (accessed on 24 January 2024).
- ISO/IEC 30173:2023; Digital Twin—Concepts and Terminology. International Organization for Standardization: Geneva, Switzerland, 2023. Available online: https://www.iso.org/standard/81442.html (accessed on 24 January 2024).
- Wang, Z.; Gupta, R.; Han, K.; Wang, H.; Ganlath, A.; Ammar, N.; Tiwari, P. Mobility Digital Twin: Concept, Architecture, Case Study, and Future Challenges. IEEE Internet Things J. 2022, 9, 17452–17467. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Apache Airflow | AWS Batch | EA-SAS Cloud Scheduler |
|---|---|---|---|
| Open ID connect compatibility | Yes | No | Yes |
| Ability to launch tasks within 3 seconds (short task launch delay) | No | No | Yes |
| Task execution in isolated environments | With extension | Yes | Yes |
| Configuration of tasks via user interface | No | Yes | Yes |
| Real-time task status and reporting via user interface | Yes | Yes | Yes |
| Automatic retry of failed tasks | Yes | Yes | Conditional |
| Criteria | Micro-Batch Processing | Stream Processing |
|---|---|---|
| Data Collection | Data aggregated over defined short intervals. | Continuous data streaming. |
| Data Processing | Processing occurs subsequent to collection. | Data are processed incrementally. |
| Advantages | Enables comprehensive data analysis, simpler implementation, and increased applicability. | Offers swift processing and real-time analytics. |
| Disadvantages | It may introduce variable latency. | Presents implementation complexity and specific applicability challenges. |
| Suitability | Ideal for large datasets needing in-depth analysis. | Less preferred for projects requiring extensive data analysis or large data volumes. |
| Parameter | Characteristic |
|---|---|
| Processor | Intel Xeon (Skylake), 4 cores @ 2.6 GHz |
| RAM | 16 GB |
| Storage Media | SSD |
| Task Count per Minute | Task Execution Overhead, Seconds | |
|---|---|---|
| Apache Airflow | EA-SAS Cloud Scheduler | |
| 1 | 7.1 | 0.6 |
| 5 | 7.8 | 0.6 |
| 10 | 8.8 | 0.7 |
| 20 | 10.6 | 0.7 |
| 50 | 12.1 | 0.7 |
| 100 | 13.2 | 0.7 |
| 200 | 16.2 | 0.8 |
| 500 | 18.9 | 1.1 |
| 1000 | 23.4 | 1.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dapkute, A.; Siozinys, V.; Jonaitis, M.; Kaminickas, M.; Siozinys, M. Digital Twin Data Management: Framework and Performance Metrics of Cloud-Based ETL System. Machines 2024, 12, 130. https://doi.org/10.3390/machines12020130
Dapkute A, Siozinys V, Jonaitis M, Kaminickas M, Siozinys M. Digital Twin Data Management: Framework and Performance Metrics of Cloud-Based ETL System. Machines. 2024; 12(2):130. https://doi.org/10.3390/machines12020130
Chicago/Turabian StyleDapkute, Austeja, Vytautas Siozinys, Martynas Jonaitis, Mantas Kaminickas, and Milvydas Siozinys. 2024. "Digital Twin Data Management: Framework and Performance Metrics of Cloud-Based ETL System" Machines 12, no. 2: 130. https://doi.org/10.3390/machines12020130
APA StyleDapkute, A., Siozinys, V., Jonaitis, M., Kaminickas, M., & Siozinys, M. (2024). Digital Twin Data Management: Framework and Performance Metrics of Cloud-Based ETL System. Machines, 12(2), 130. https://doi.org/10.3390/machines12020130