1. Introduction
Quadruped robots are highly complex and versatile machines that replicate the movement of four-legged animals, such as dogs, cats, or horses. They are capable of autonomous walking, running, jumping, and even climbing in complex and changing environments [
1]. The design of these robots draws on knowledge from several disciplines, including mechanical engineering, electronic engineering, computer science, control theory, and bionics, to achieve efficient and stable locomotion. With the rapid advancement in automation and intelligent technologies, quadruped robots have attracted considerable attention for their stability and adaptability in challenging terrains. They exhibit distinct advantages in various applications, including disaster relief, military reconnaissance, and everyday service tasks [
2].
Since the 1990s, numerous experts and scholars have conducted research on bionic quadruped robots. To improve the mechanical structure performance of these robots, an innovative bionic actuator system was proposed in the literature [
3]. This system combines additive manufacturing and topology optimization techniques to effectively reduce redundant materials in the limb units, thereby significantly enhancing their dynamic performance. In addition, reference [
4] introduced a novel leg phase detection method for robots, which uses proprioceptive feedback to estimate the leg state, addressing the issue of inaccuracy when external equipment is unavailable. Furthermore, reference [
5] reported the development of a quadruped robot with soft–rigid hybrid legs, where the legs were designed using a multistage topology optimization method, providing a new solution to the traditional challenge of a limited bearing capacity in soft legs. In the context of adapting to complex environments, the bionic quadruped obstacle-crossing robot described in [
6] achieves high obstacle-crossing performance by storing energy in its hind limb structures. Similarly, ref. [
7] introduces a novel quadruped robot with a reconfigurable sprawl posture, enabling it to switch between different postures to navigate narrow spaces, obstacles, and inclined surfaces. As research on quadruped robots advances, alongside the optimization of mechanical structures, many advanced algorithms are gradually being integrated. These algorithms play a critical role in improving the robot’s performance, intelligence, and autonomy. In terms of control strategies, ref. [
8] introduces an end-to-end training framework that enables quadruped robots to learn various gaits through deep learning. Reference [
9] presents a comprehensive decision-making and control framework specifically addressing the issue of falls in quadruped robots, incorporating a model-free deep reinforcement learning method to achieve post-fall recovery. Furthermore, reference [
10] details a contextual meta-reinforcement learning method developed to formulate a fault-tolerant strategy that enhances the mobility of quadruped robots within unstructured environments. Reference [
11] introduces a Lyapunov model predictive control algorithm that incorporates sequential scaling to improve the tracking accuracy of these robots. Subsequently, reference [
12] implements a teacher–student policy architecture, which allows the robot to adjust its motion strategy based on environmental variables. Experiments performed on actual quadruped robots have confirmed the efficacy of these strategies in enabling high-speed motion and adaptation to complex terrains. The swift advancement in quadruped robot technology has not only achieved significant theoretical innovations but has also been substantiated by practical implementations, showcasing the substantial potential and value of these robots for future advancements in automation and intelligent systems.
However, the design of control systems for quadruped robots faces numerous challenges, particularly in achieving precise gait adjustments and maintaining balance in dynamic environments [
13]. In [
14], a deep reinforcement learning framework was developed to enable a quadruped robot to perform agile and dynamic locomotion tasks. Similarly, ref. [
15] employed neural networks to control a quadruped robot traversing challenging terrains, showcasing the effectiveness of neural network-based control in real-world robotic applications. These works highlight the potential of neural networks in enhancing the control capabilities of quadruped robots. Adaptive optimal control [
16] offers an effective solution by optimizing control strategies in real time to adapt to environmental changes, thereby enhancing the robot’s adaptability and stability.
Optimal control [
17] is a method used to determine the best control strategy under given constraints to maximize (or minimize) a system’s performance index. It plays a critical role in controller design, ensuring optimal system performance, improving the response speed and stability, and enhancing robot path planning. Key advantages of optimal control include performance optimization, precision, flexibility, robustness, and efficiency, which make it particularly suited for addressing control challenges in complex systems. As a result, it has been widely applied across various fields. Among the most commonly used approaches are reinforcement learning-based solutions [
18,
19]. Reinforcement learning is a method where an agent learns by interacting with its environment, accumulating experience, and optimizing its strategy through trial and error [
20]. One key advantage of reinforcement learning over traditional control techniques is its ability to autonomously learn control strategies through environmental interaction, even without precise system models. This feature offers greater flexibility and robustness, particularly when dealing with highly complex and dynamic environments, such as those encountered by quadruped robots, where it demonstrates significant advantages. With the continuous development of reinforcement learning, the idea of combining adaptive control and optimal control has recently emerged, commonly referred to as adaptive dynamic programming (ADP) [
21]. A common framework for studying reinforcement learning or ADP is the Markov Decision Process (MDP), in which the control process is typically stochastic and modeled in discrete time. However, there is a growing need to extend this approach to controlling deterministic systems in continuous time domains. In reference [
22], an online adaptive optimal control algorithm based on ADP is proposed to solve multiplayer nonzero-sum games (MP-NZSGs) for discrete time unknown nonlinear systems. In reference [
23], a robust optimal control design for a class of uncertain nonlinear systems is explored from the perspective of RADP [
24], aiming to address dynamic uncertainties or unmodeled dynamics. In reference [
25], an event-driven adaptive robust control method is developed for continuous time uncertain nonlinear systems using a neural dynamic programming (NPD) strategy. This method provides a novel approach to integrating self-learning control, event-triggered adaptive control, and robust control, advancing research on nonlinear adaptive robust feedback design in uncertain environments. While most of these algorithms focus on regulation problems, real-world scenarios often encounter tracking challenges. In quadruped robot control, tracking a desired trajectory under uncertain conditions is critical. Reference [
26] introduces a neural network-based control approach for quadruped robots to achieve precise trajectory tracking despite dynamic uncertainties. In reference [
27], a hierarchical autonomous control scheme based on a twin double deep deterministic policy gradient algorithm and model predictive control is proposed, achieving the precise tracking of pressure control targets and promoting the application of AI technology in underground construction. For the path tracking control of autonomous vehicles with uncertain dynamics, ref. [
28] presents an adaptive optimal control method with prescribed performance, introducing prescribed performance functions into ADP to constrain tracking errors within defined performance boundaries while optimizing control. Additionally, ref. [
29] develops an optimal neural control framework with prescribed performance constraints to solve the trajectory tracking control problem for hypersonic vehicles. In view of the dynamic uncertainty and the disturbance factors acting on the system, reference [
30] develops a novel online adaptive
control scheme for ACC systems. Furthermore, it possesses the unique capability of learning control and disturbance policies concurrently.
The design of the aforementioned controller addresses both the regulation and tracking problems in nonlinear systems, while disregarding the influence of modeling inaccuracy, particularly in models with a complex modeling process, such as those of quadruped robots. Although these systems can be calculated, they still take a lot of time. And they still need to be recalculated in the face of a new system. The complexity and accuracy of the calculation are difficult to guarantee. To overcome this issue, we propose a novel optimal tracking control method based on Generalized Policy Iteration (GPI), applied for the first time in quadruped robot control. Generalized Policy Iteration (GPI) is a reinforcement learning method that involves two interacting processes: policy evaluation and policy improvement. The strategy is always improved based on a specific value function, and the value function will always converge to the true value function corresponding to the specific strategy. This GPI-based approach eliminates the need for prior knowledge of the system’s drift function f(x), providing a partially model-free online solution that effectively resolves the foot-end displacement control problem in quadruped robots.
The main contributions of this paper are as follows:
A kinematic model of the parallel quadruped robot’s leg mechanism is established, and a novel algorithm based on Generalized Policy Iteration (GPI) is applied for the first time to the tracking control of this model.
Unlike the existing algorithm [
31], GPI avoids solving complex dynamic models. It will give an online model-free solution with any quadruped robot.
A co-simulation model for the parallel quadruped robot is developed, significantly improving the accuracy of the simulation process and addressing the limitations of the mathematical model. The simulation results are validated through experimental verification.
The structure of the remainder of the paper is as follows:
Section 2 presents the kinematic model of the parallel quadruped robot.
Section 3 describes the controller design.
Section 4 covers the simulation and experimental validation, and
Section 5 provides the conclusion.
2. Kinematic Model of Quadruped Robot’s Control System
Establishing a kinematic model is crucial to determining the relationship between the foot-end and the joints of the legs in terms of the position and orientation for legged robots. Kinematics forms the foundation for enabling effective motion control in robotics. By integrating the robot’s movements with mathematical modeling, further advanced research can be conducted in areas such as gait planning, trajectory planning, and posture control.
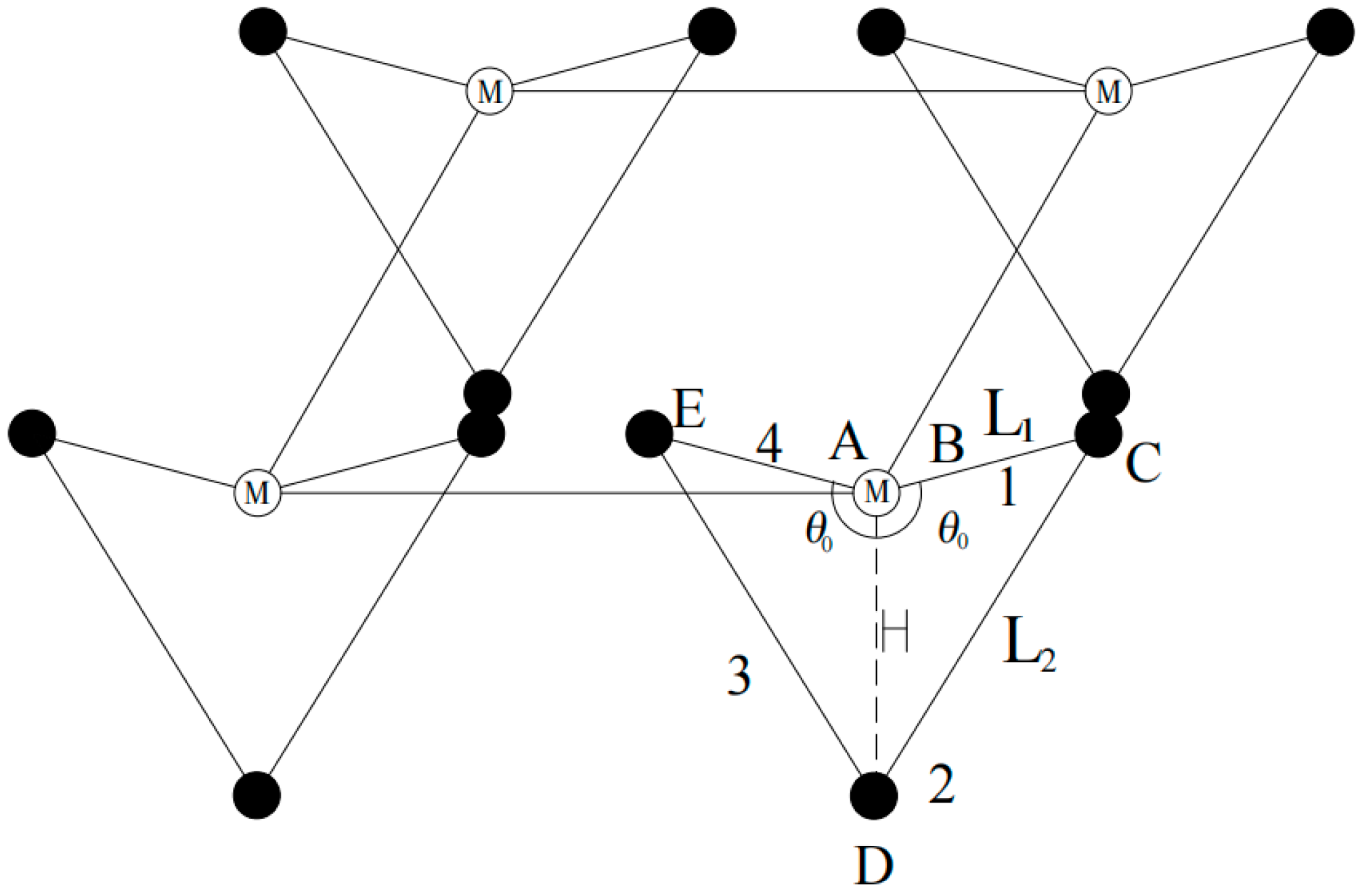
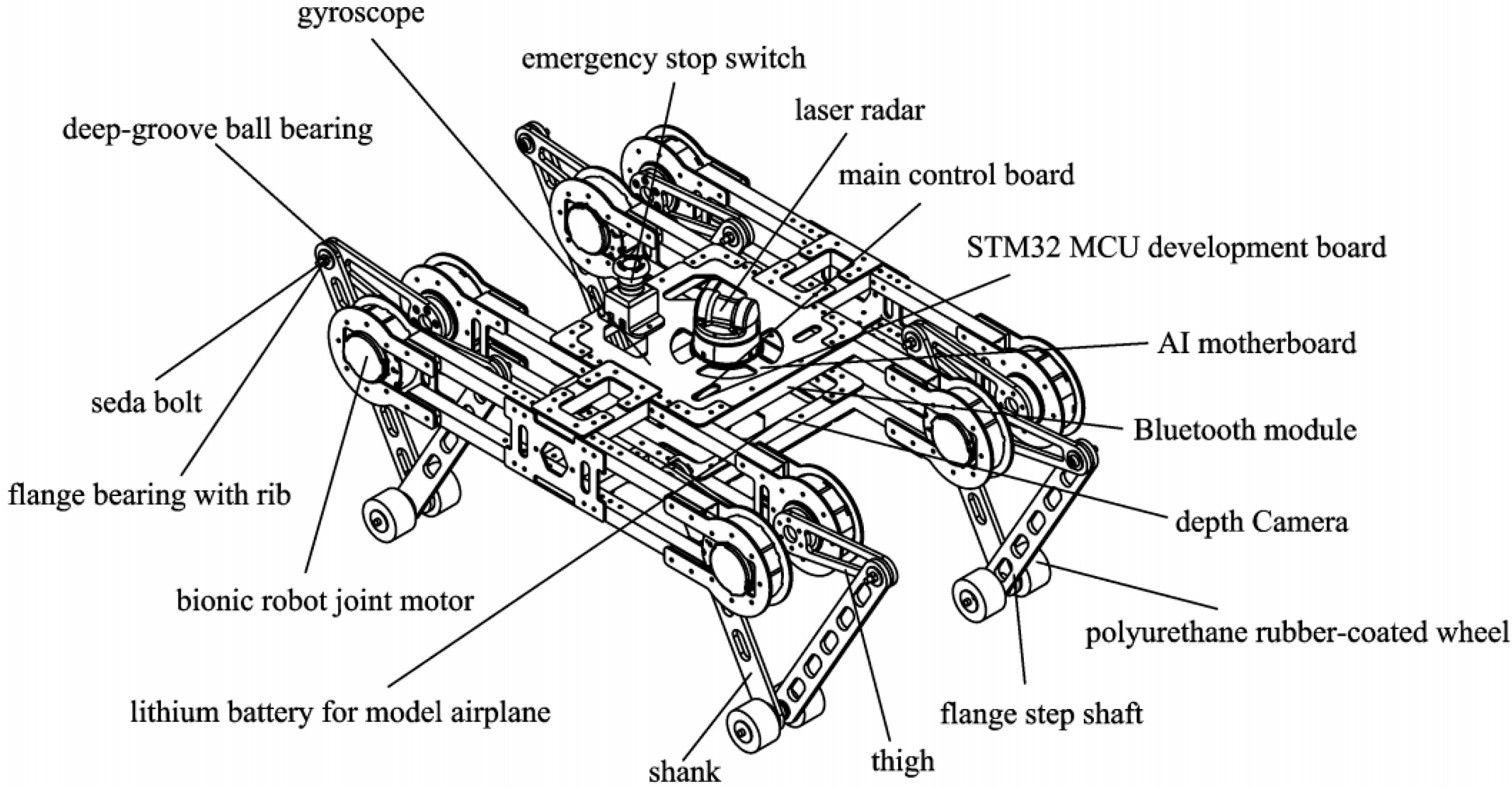
The mechanical structure of the quadruped robot was inspired by the physiological structure of mammals and consists of five parts. The legs are connected to the torso by four joints, with each joint having two degrees of freedom. Considering the balance between mechanical flexibility and complexity, the mechanical structure has been simplified. The simplified structure is shown in
Figure 1 and consists of five parts. The parameters and structure of the four legs are identical and symmetrically distributed around the center. The kinematic model in its initial state is shown in
Figure 2.
If the pose of the robot’s end-effector is given, the values of the other joints can be determined by performing inverse kinematics. There are two methods for solving inverse kinematics: The first is the analytical method, which is fast and accurate, utilizing algebraic calculation and geometric analysis for the solution. The second is the numerical method, which has a slower computation speed and unstable numerical iteration. Therefore, in this research, the geometric analysis approach from the analytical method was adopted to solve the inverse kinematics of the robot’s single leg.
The position inverse solution analysis involves determining the motor angles that achieve the desired foot-end trajectory, given the known lengths of the actuators AE and BC, as well as the lengths of the driven links ED and CD.
The continuous phase transition process of the foot-end of a single leg, from ground contact to liftoff, is referred to as the stance phase. The swing phase describes the continuous phase transition process in which the foot-end moves along the planned trajectory from liftoff to ground contact. During the stance phase, the leg supports the robot’s load and moves the torso in the target direction through phase transitions, shifting from the anterior extreme to the posterior extreme. Conversely, the swing phase shifts from the posterior extreme to the anterior extreme, determining the robot’s stride length and leg lift height when crossing obstacles. Therefore, research on the stance and swing phases is essential for deriving the torso trajectory of quadruped robots.
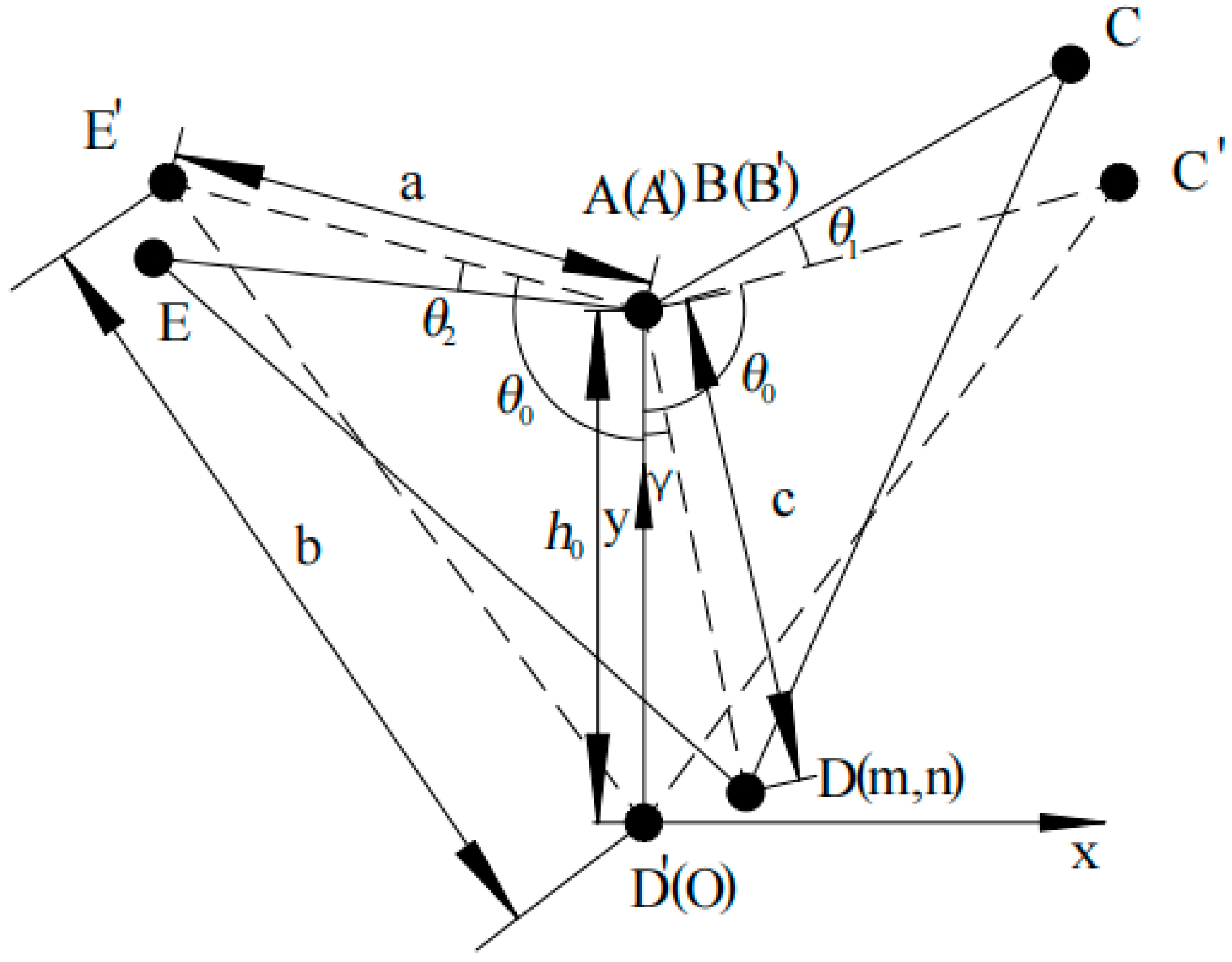
To study the stance phase of the right foreleg of the quadruped robot, we first assume that the parallel mechanism exhibits no lateral motion. The origin of the coordinate system is set at the center of the foot-end when the quadruped robot is in a static stance, with the forward direction aligned with the positive
X-axis and the vertical direction upward along the positive
Y-axis. The kinematic model under general conditions is shown in
Figure 3.
From the geometric relationships and the law of cosines, we derive
where
represents the distance between the motor center and the foot-end center during movement,
is the distance between the motor center and the foot-end center when stationary,
is the horizontal distance of the foot-end, and
is the vertical distance of the foot-end.
where
is the length of the thigh,
is the length of the calf, and
is the angle between the stationary shin and the vertical axis.
where
γ is the angle between the line connecting the motor center and the foot-end center and the vertical axis.
where
is the angle between the moving thigh and the stationary thigh at the front, which represents the internal motor rotation, and
is the angle between the moving thigh and the stationary thigh at the back, representing the external motor rotation.
From (3) and (4), the relationship between the two motor angles is derived as
From (4) and (6), the expression for motor angle
as a function of the foot-end position is
From (5) and (7), the expression for motor angle
as a function of the foot-end position is
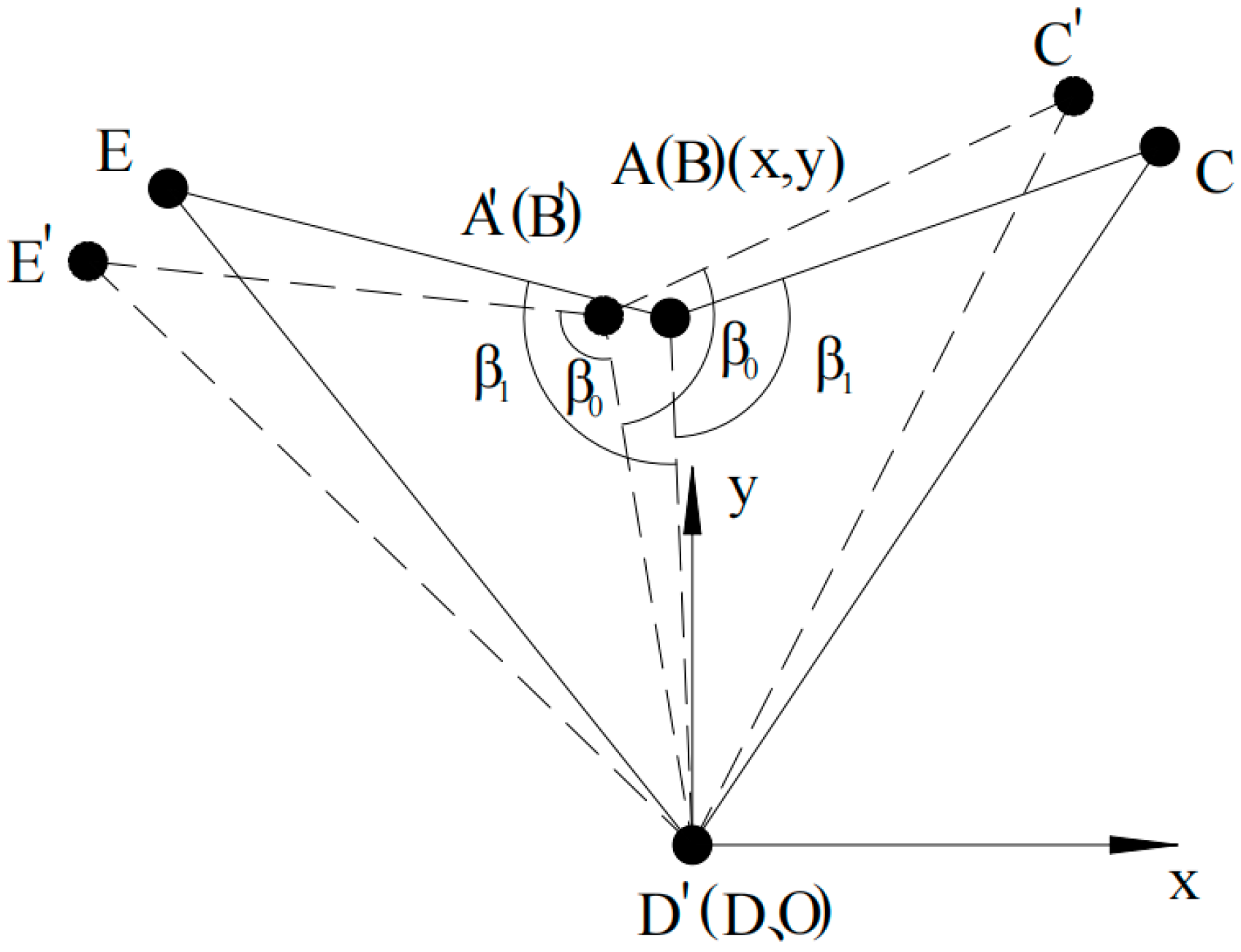
To investigate the stance phase of the quadruped robot’s right foreleg, it is assumed that the parallel mechanism does not undergo lateral motion. The foot-end center in the initial standing position during the stance phase is designated as the coordinate origin, with the forward direction aligned along the positive
X-axis and the vertical direction upward along the positive
Y-axis. The kinematic model under general conditions is illustrated in
Figure 4.
Based on geometric relationships and the law of cosines, it can be derived as
where
represents the initial distance between the motor and the foot-end, and
is the angle between the thigh and the line connecting the motor and foot-end at the initial moment.
represents the distance between the motor and the foot-end during motion, and
is the corresponding angle during movement.
where
denotes the step length.
where
and
represent the motor coordinates.
The relationship between the two motor angles is
where
denotes the inner motor angle and
denotes the outer motor angle.
From Equations (9)–(12), the relationship between motor angles
and
and the motor position is given by
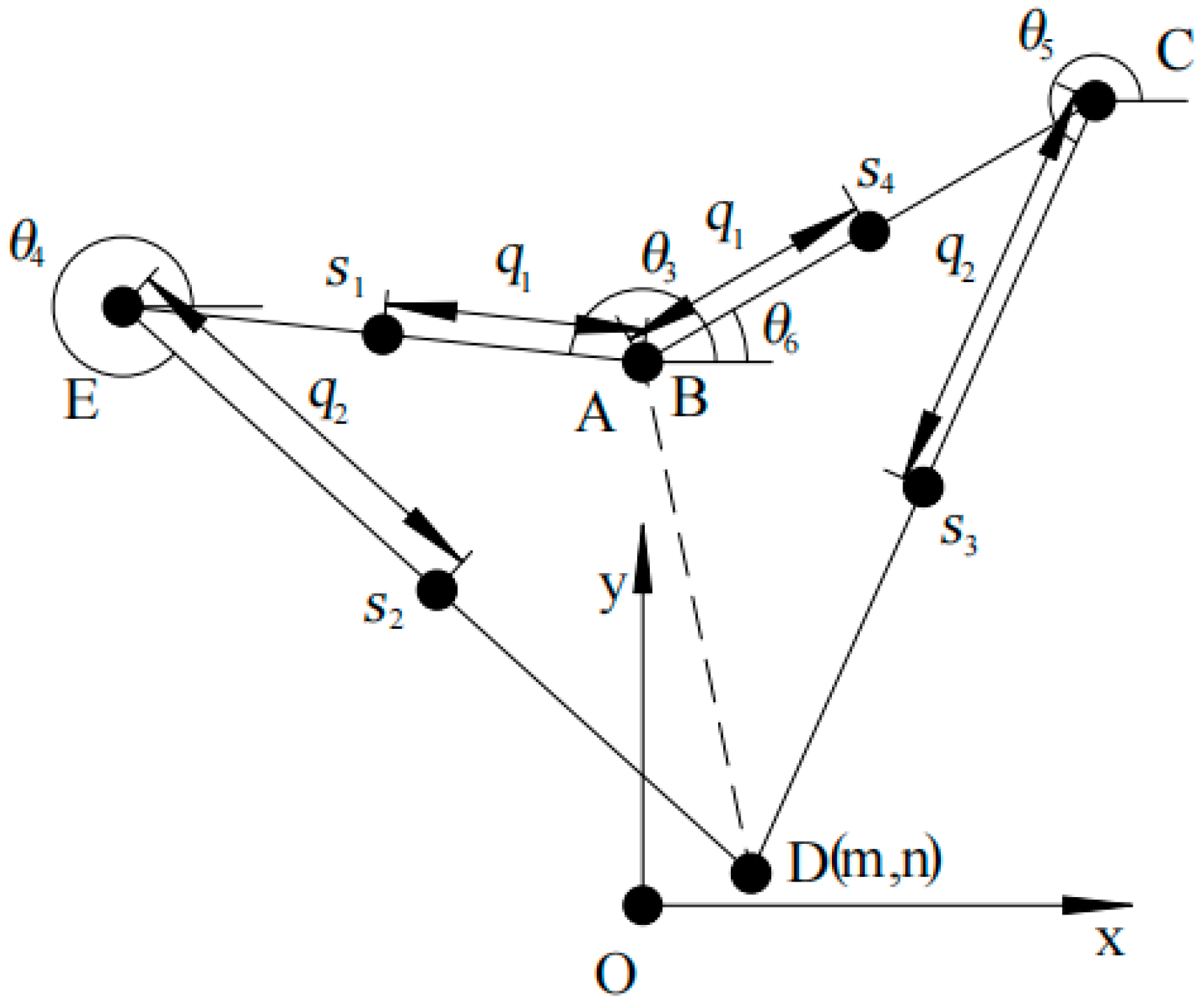
The commonly used methods for the dynamics study of parallel robots include the Lagrange method, the Kane method, and the Newton-Euler method. In this section, the Lagrange method is used to establish the dynamic equation of the parallel leg mechanism, and the expression of the driving torque is obtained by solving the equation. The schematic diagram of the parallel leg mechanism is shown in
Figure 5.
It is assumed that the position of the center of mass of each bar is on the common perpendicular of the adjacent joint axes. From the closed vector method and the projection relation, we can obtain
where
is the included angle between the left thigh and the positive direction of the
X axis,
is the included angle between the left crus and the positive direction of the
X axis,
is the included angle between the right thigh and the positive
X axis direction, and
is the included angle between the right crus and the positive
X axis direction. The center of mass of each member is located on the common perpendicular of the adjacent joint axes. Choose
and
as generalized coordinates. It can be seen from
Figure 3 and
Figure 5 that
It can be obtained from Formula (14) that
where
,
,
,
, and
.
Take the partial derivative of Equation (14) with respect to
and
, respectively, to obtain
By taking the derivative of both sides of Equation (14), we can obtain
Rewrite Equation (18) into a matrix form:
where
,
, and
.
The position of the center of mass of each rod can be obtained from
Figure 5 and the linear velocity of the center of mass of each rod can be obtained through time derivation.
The linear velocity of the center of mass of the right thigh center is
where
is the horizontal linear velocity of the centroid of the right thigh and
is the vertical linear velocity of the centroid of the right thigh.
is the distance between the thigh mass center and the motor center and
is the distance between the crus mass center and a joint connecting the thigh with the crus.
The linear velocity of the center of mass of the right lower leg is
where
is the linear velocity in the horizontal direction of the mass center of the right leg and
is the linear velocity in the vertical direction of the mass center of the right leg.
The linear velocity of the center of mass of the left lower leg is
where
is the horizontal linear velocity of the mass center of the left leg and
is the vertical linear velocity of the mass center of the left leg.
The linear velocity of the center of mass of the left thigh center is
where
is the horizontal linear velocity of the mass center of the left thigh and
is the vertical linear velocity of the mass center of the left thigh.
According to (16) and (19)–(23), the total kinetic energy of the system is expressed as
where the masses of the left thigh, left calf, right calf, and right thigh are
,
,
, and
, respectively, and the moments of inertia of the left thigh, left calf, right calf, and right thigh around the center of mass are
,
,
, and
, respectively, and
,
,
, and
. The coefficients
,
, and
are, respectively, expressed as
The total potential energy of the legs can be expressed as
where the height of the center of mass of the left thigh, the left leg, the right leg, and the right thigh from the ground is
,
,
, and
, respectively.
The driving moments
and
can be obtained from the Lagrangian equation
as follows:
In the gait cycle of a quadruped walking robot, the torso movement follows a regular pattern. Therefore, it is necessary to deduce the robot’s torso trajectory from the foot-end trajectory, specifically calculating the actual trajectory of the foot during single-leg movement.
To enhance the adaptability of quadruped robots to unstructured environments and ability to efficiently complete assigned tasks, the trot gait is generally used as the ideal state. In the trot gait, the duty cycle is 0.5, meaning that the robot’s diagonal legs move in sync, both either in the swing phase or in the stance phase.
The foot-end trajectory of the quadruped robot adopts the earliest composite cycloid trajectory. The stance phase and swing phase each occupy half of the total cycle. When the foot-end is in the swing phase, the trajectory equation of the quadruped robot’s foot-end relative to the torso is given by the following equation:
where
represents the lift height,
is the cycle, and
is the time.
The foot-end trajectory during the swing phase of the quadruped robot is corrected. Since the quadruped robot uses the trot gait, the foot-end trajectory should be the vector sum of the torso trajectory, which is derived from the inverse of the composite cycloid trajectory planned during the stance phase and the theoretical sine trajectory planned during the swing phase. The absolute trajectory equation of the foot-end during the swing phase is thus given by
Since the stance phase moves the robot’s torso by changing the leg phase to achieve movement in the target direction, the motor rotation pattern can be derived through the analysis of the stance phase. By taking the first derivative of (13) with respect to time, the expression for the motor’s angular velocity can be obtained:
By taking the second derivative of (13) with respect to time, the angular acceleration expression for motor rotation is obtained:
where
,
,
, and
.
Since the quadruped robot uses the trot gait with a duty cycle of 0.5, and the foot trajectory is planned using a composite cycloid curve, kinematic analysis reveals that the trajectory equations of the robot’s torso match those of the foot relative to the driving mechanism:
Using the state variables
from (34)–(36), we obtain
Through a forward kinematics analysis of the swing phase, setting
and
, the following geometric relationship is derived:
Next, we analyzed the stance phase. From [
32], the motor state equations can be described as
The state variables represent the motor’s position and angular velocity, is the inertia, and denotes the torque vector.
For the quadruped robot’s joint motors, let
,
, and
, leading to
Therefore, (40) can be expressed as
where
.
Let
, and the state variables of the quadruped robot are
, where
represents displacement and
represents velocity. Let
be denoted as
. Based on (37) and (39), the overall system equations of the quadruped robot can be expressed as
where
and
.
Let the tracking parameter
. Similarly to [
33], we constructed an augmented system:
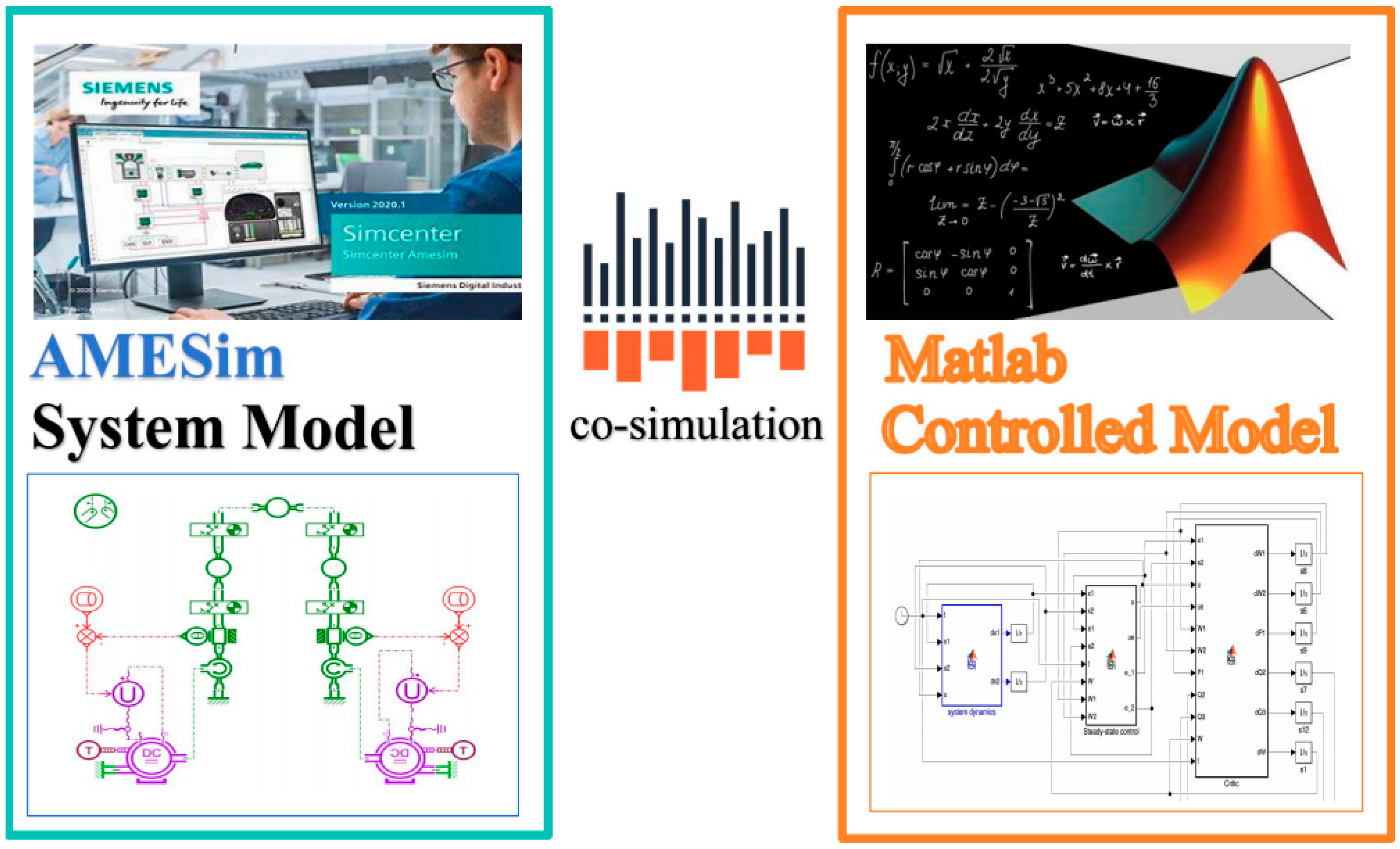
Remark 1. Due to the nonlinearity of the system, especially in the dynamics of robotic joint torque, direct linearization may lose some dynamic characteristics. However, it is difficult to obtain specific expressions of and without further simplification. In this paper, we opted to use AMESim and Simulink for co-simulation instead of manually building complex state equation models. AMESim accurately simulates the dynamic behavior, motion variations, and interaction characteristics of the multi-robot system, eliminating the need to manually construct detailed kinematic and mechanical coupling equations. This approach significantly simplifies the modeling process and enhances the accuracy of the simulation results. Simulink was employed to implement the control algorithm, and the proposed algorithm is model-free. This process will be explained in detail in Section 4.
3. Optimal Controller Design
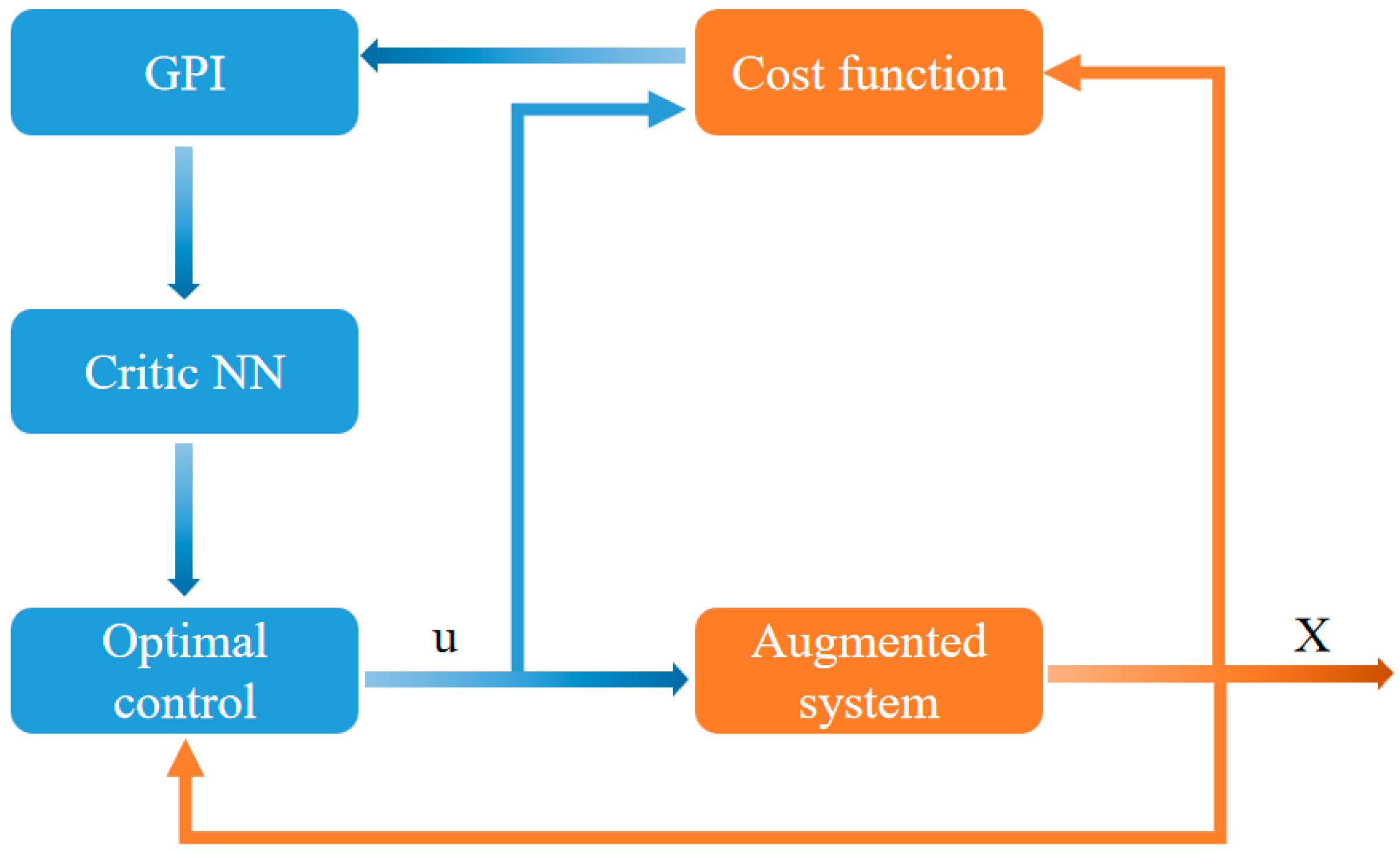
This section presents the general formula for the infinite horizon nonlinear optimal control problem in continuous time systems. The flow chart of the algorithm in this paper can be seen in
Figure 6.
In
Section 2, we defined the control system for the quadruped robot as follows:
where
represents the state vector,
is the control input or strategy, and
and
are the system and input gain functions, respectively. The value function
is defined as the infinite horizon cost:
where
with
is a positive definite matrix, and
.
Assumption 1. Assume that satisfies Lipschitz continuity on a compact set that contains the origin, and the system (46) is stable, meaning that the state converges to a stable control law .
The optimal control problem is solved by selecting the optimal stabilizing control
that minimizes the value function in (47). The optimal value function
is defined as
The partial differential equation of the optimal value function
can be expressed as a general solution to the nonlinear optimal control problem. We define the Hamiltonian for this problem as
where the gradient vector is
. The optimal value function
from (48) satisfies the Hamilton–Jacobi–Bellman (HJB) equation:
For the unconstrained control
, the optimal control
can be found by setting
, hence
Substituting the optimal control expression (51) into (50) yields the HJB equation based on
:
Given the nonlinearity of the HJB (50) and the requirement for an accurate understanding of the system dynamics and the input gain , solving the equation is typically challenging.
Remark 2. Policy iteration is a reinforcement learning method used to determine optimal values and control strategies. By alternating between policy evaluation and policy improvement, it incrementally converges towards the optimal policy. This approach has led to the development of various algorithms, as described in [34,35], which are designed to solve the HJB equation either in real time or in advance. In the discussion within this section, policy evaluation and improvement occur synchronously, as both the critic and actor are updated simultaneously. This process is considered an extreme form of Generalized Policy Iteration (GPI). In continuous time systems, policy evaluation can be achieved using adaptive critics, with the core involving the solution of a nonlinear Lyapunov equation (e.g., [
35,
36]). The derivation of such equations can be via Leibniz’s formula for differentiating the value function [
35]. Additionally, another approach for solving the Bellman equation is through Integral Reinforcement Learning (IRL) [
37].
Let the period
. This is a discrete time Bellman equation, similar to the integral form. Note that the system equation
and input gain
in the Lyapunov equation do not appear in the Bellman (53). For policy improvement, following [
38], the control is iteratively obtained by solving the value function
(53), as follows:
The system will converge to the optimal control from (51).
3.1. Value Function Approximation with Adaptive Critic
This section introduces a novel design for policy evaluation using an adaptive critic. We approximate the value function through a critic neural network:
where
in the activation vector with
hidden neurons, and
is the weight vector.
represents the approximation error of the neural network. By selecting appropriate activation functions, a complete set of independent bases can be constructed to ensure the accurate approximation of
. According to the Weierstrass higher order approximation theorem [
38], within a compact set
, as the number of neurons
, for a fixed
, the approximation error
and its gradient
approach zero, i.e.,
and
.
We applied the Bellman method to update the critic. Substituting the approximated value function (55) into the Bellman equation (53) gives
By using integral reinforcement
, the difference
, and the Bellman equation, the residual error
is bounded within the compact set
, ensuring that
remains within bounds. To design an adaptive law for the weight vector that guarantees the convergence of the value function approximation, we introduce the auxiliary variables
and
through the low-pass-filtered variables in (56):
Here, the filtering parameter
and the discount factor
are introduced to ensure exponential decay, effectively preventing unbounded growth in the values of
and
while maintaining stability.
and
are defined as follows:
Definition 1. (Persistency of excitation (PE) [
39]).
If there exists a strictly positive constant such that the following condition holds over the interval , the signal is said to be persistently excited, i.e.,
The PE condition [
39] is widely required in adaptive control to ensure parameter convergence.
Lemma 1. ([
40]).
If the signal is persistently excited for all , then the auxiliary variable defined in (57) is positive definite, i.e.,
, and the minimum eigenvalue , .
Proof. Detailed proof can be found in [
40].
The adaptive critic neural network can be expressed as
where
and
represent the current estimates of
and
, respectively. We now design an adaptive law to update
using a sliding mode technique, defined as follows:
is defined as
, and
is a positive adjustment gain to be determined in [
36]. This gain facilitates the adaptive learning process. □
Lemma 2. Considering the adaptive law (61), if the system state remains bounded under a given stable control, and if , , and the system state are persistently excited, then the estimation error satisfies the following conditions:
If the approximation error of the neural network is zero, the estimation error will converge to zero within a finite time .
If , the estimation error will converge to a compact set within a finite time .
Proof. We begin by examining the boundedness of . In Equation (58), when the states and are bounded, the matrix is positive and has an upper bound , such that . Due to the Bellman equation, the residual error is bounded. By introducing some constants and substituting into Equations (56)–(58), we find that is also bounded, where is given by . Thus, can be expressed as
Since
is persistently excited, from Lemma 1, we know that
is symmetric and positive definite, and thus invertible. Therefore, we have
. Here,
can be used to design a suitable Lyapunov function, as it includes both the estimation error
and
. We differentiate
as follows:
where
and
is bounded, meaning that
for some constants
. Note that
is bounded since
and
. Therefore, the upper and lower bounds for
can easily be derived as
and
. Consequently, we can easily find the lower and upper bounds for the two
-type functions in
[
41], which serve as the lower and upper bounds of the following modified Lyapunov function:
where
is a constant. The time derivative can be calculated as
where
is a positive constant for a properly chosen
with
. Based on [
42], we can conclude that
and
within a finite time
. Thus, we have the following results:
In the case where , we find that , , and , meaning that with , and will converge to zero within finite time .
In the case where , that is, when and , this implies that and , meaning that will be bounded after the finite time .
□
Remark 3. Based on Lemma 1, the minimum eigenvalue of can be monitored to verify whether the persistent excitation (PE) condition is satisfied in real time. To ensure that the PE condition is always satisfied, the methods proposed in the literature, such as those in [35,43], can be used. These methods introduce an appropriate level of noise into the system states or the controller design. Remark 4. The sliding mode term in the adaptive law (61) ensures finite time convergence and also prevents the potential chattering phenomenon caused by integral action, as discussed in [40]. 3.2. Adaptive Optimal Control Through GPI
In this section, we design an actor focused on policy improvement. By verifying the derivation in (54), if the estimated weight
converges to the unknown actual weight
, we successfully solve the Bellman equation (53). This allows us to directly use the adaptive critic (60) to determine the optimal control strategy. Therefore, the control output is defined as
Now, we summarize the first result of this paper as follows:
Theorem 1. Consider the continuous time nonlinear affine system given by Equation (46) and the infinite time value function defined in Equation (47). Under the adaptive critic neural network control structure specified in Equation (60) with an adaptive law (61) and actor (66), the adaptive optimal control achieves the following properties:
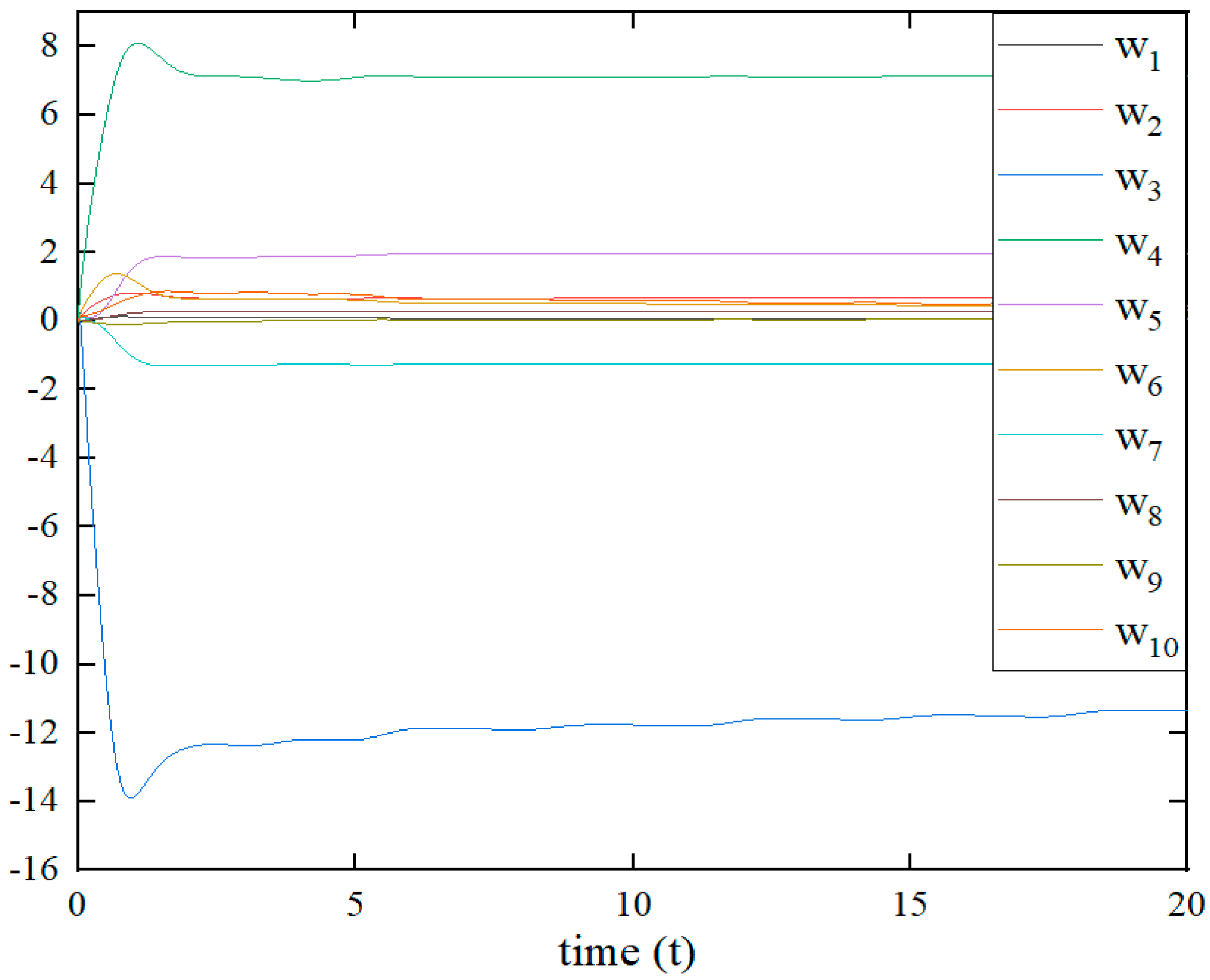
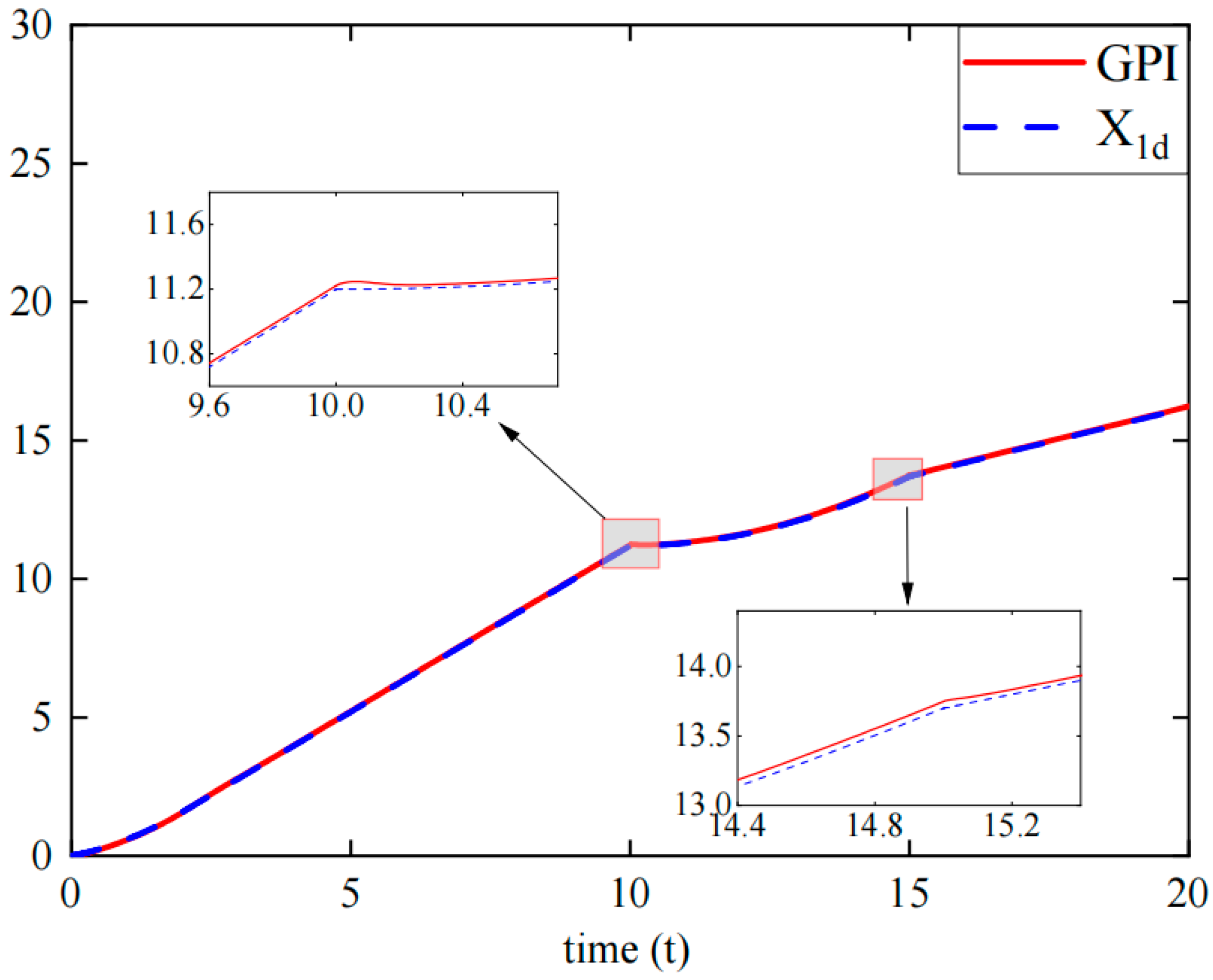
In the absence of an approximation error, the adaptive critic weight estimation error converges to zero in finite time , and the control input converges to the optimal solution .
In the presence of an approximation error, the adaptive critic weight estimation error converges within a finite time to a very small neighborhood around zero, and the control input converges to a small bounded neighborhood around the optimal solution .
Proof. We designed the Lyapunov function similarly to those in [
36,
37], as follows:
and
are positive constants.
. We analyzed the Lyapunov function
over a compact set. Assume that the elements
are located within
. Further, suppose that the initial conditions of
are uniformly positioned inside the
. Therefore, the initial trajectory has no effect on state
and control
for a duration in time
. In Equation (67), the term
involves
.
(50) can be defined as
By applying Young’s Inequality
and using the constant
, along with results from [
38,
42,
44], the derivative of
can be derived as
where
,
,
, and
are positive constants for a properly chosen
,
,
, and
with
,
,
, and
, respectively.
addresses the effect of the neural network approximation error.
Thus, the first four terms in the inequality (69) form a negative definite function within the set
, ensuring the existence of an ultimate bounded set
. The bound depends on the magnitude of
; as
decreases, the set
also becomes smaller. Assuming
is sufficiently large, this implies that
is small enough, such that
. Consequently, it follows that no trajectory can escape from
, indicating that it is an invariant set. This means that the state
remains bounded, and the function
stays within bounds. Similarly, the approximation errors
,
are bounded functions defined over the compact set. Based on the Lyapunov theorem and Lemma 2, both
and
will converge to a set of ultimate boundedness. Furthermore, according to Equations (54)–(66), the difference between the actor and the optimal control is bounded by
This occurs within a finite time , after which the bound holds. This establishes part b while part a can be easily deduced. □
Remark 5. In the absence of prior knowledge of system drift , the proposed GPI method (Theorem 1) is a partially model-free algorithm that can solve nonlinear optimal control problems in continuous time through online approximation. This approach further eliminates the need for the identifier of the dual approximation structure in [36]. Additionally, because the critic weights converge within finite time, the actor neural network used in [35] is not required. The adaptive critic and actor continuously update each other, effectively avoiding the mixed structure in [34] and eliminating the need for a stable initial control policy as required in [34,43]. 




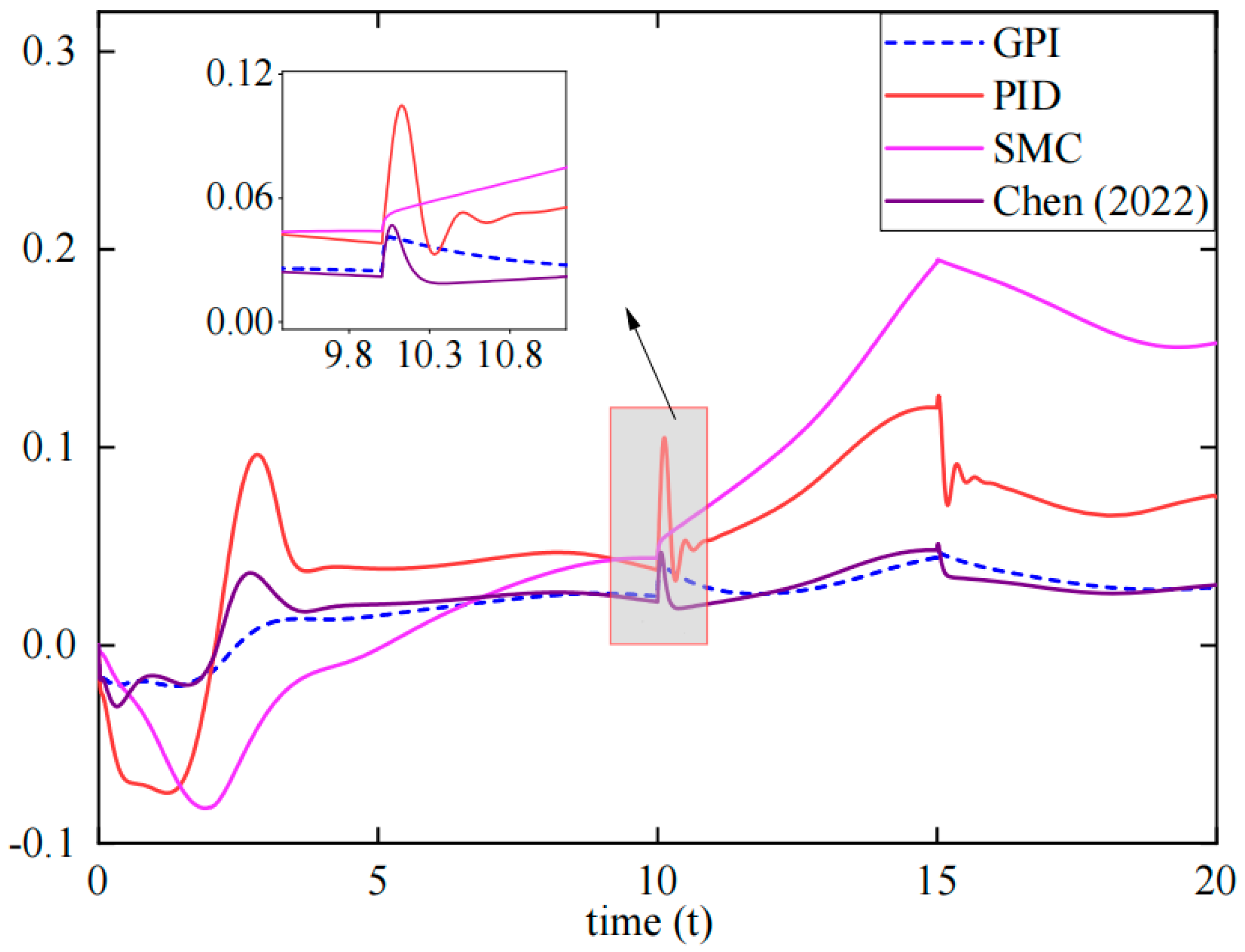
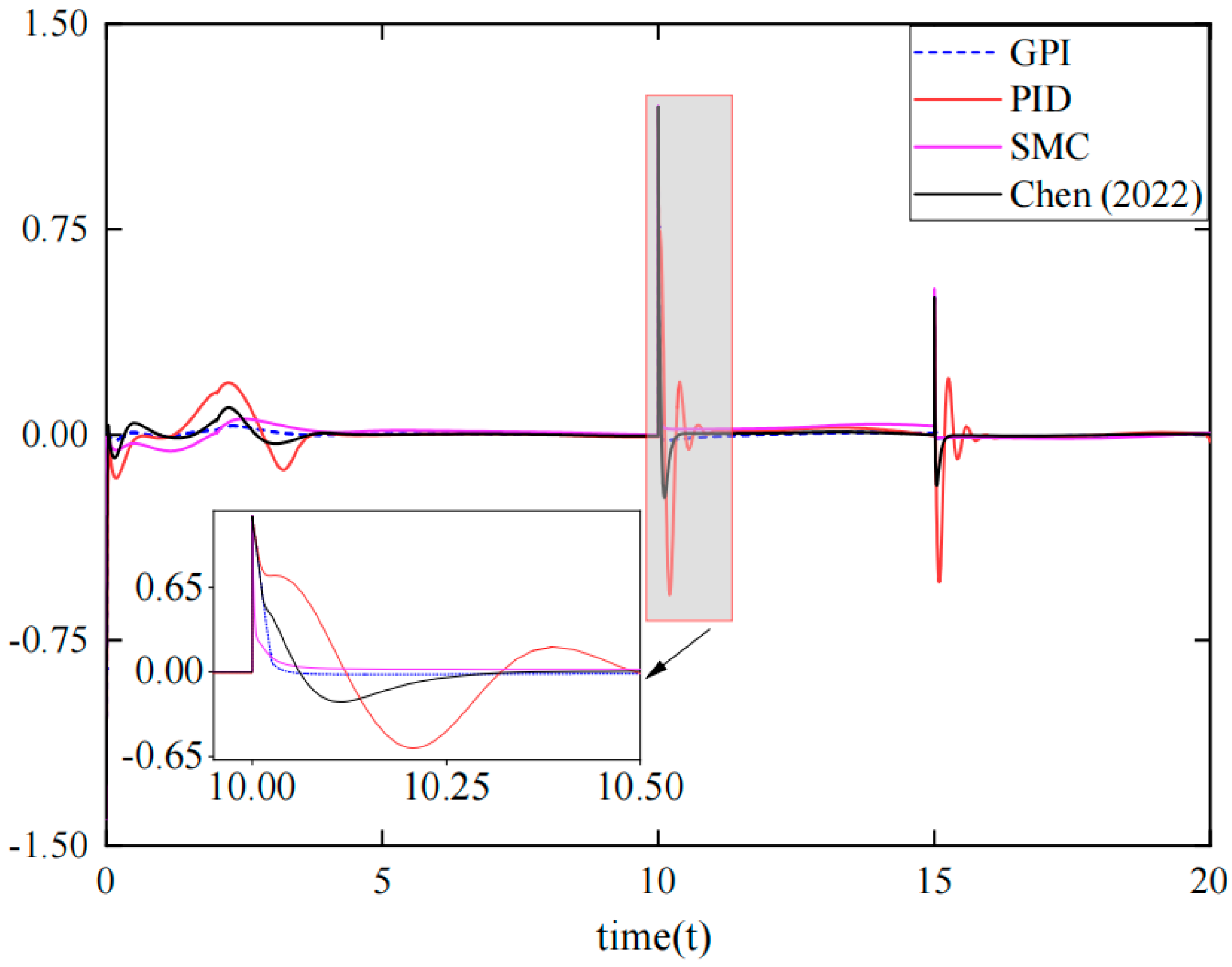
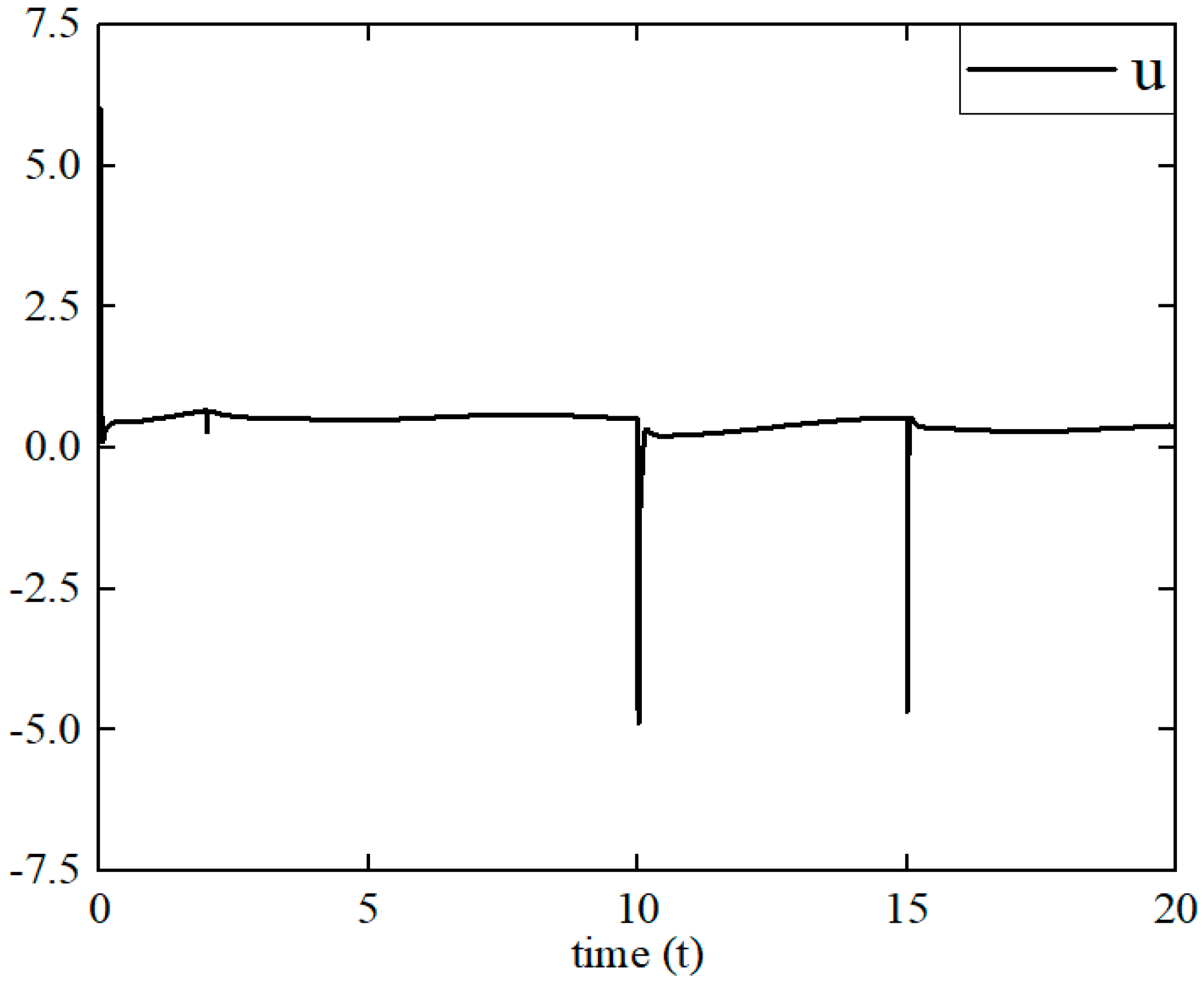
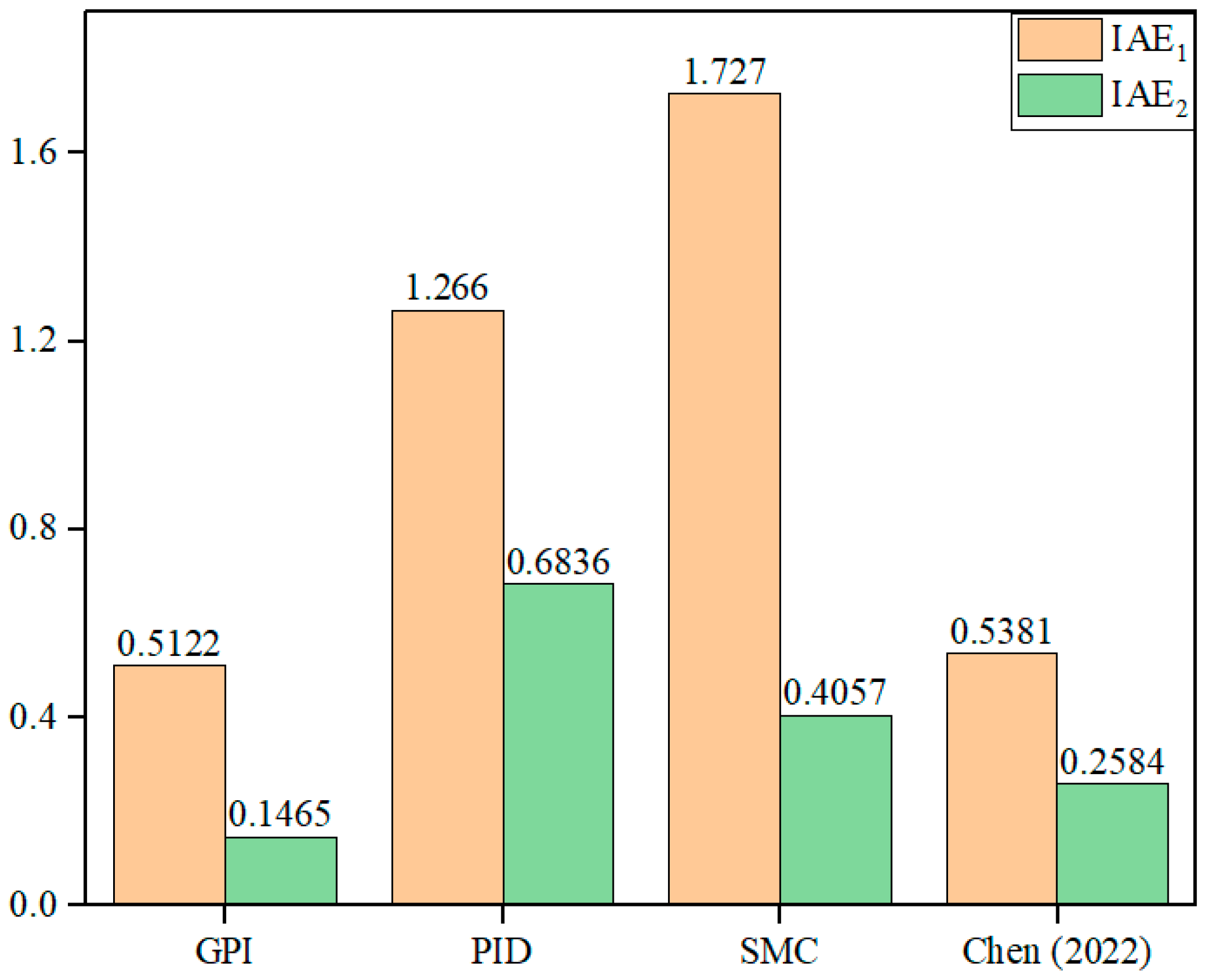



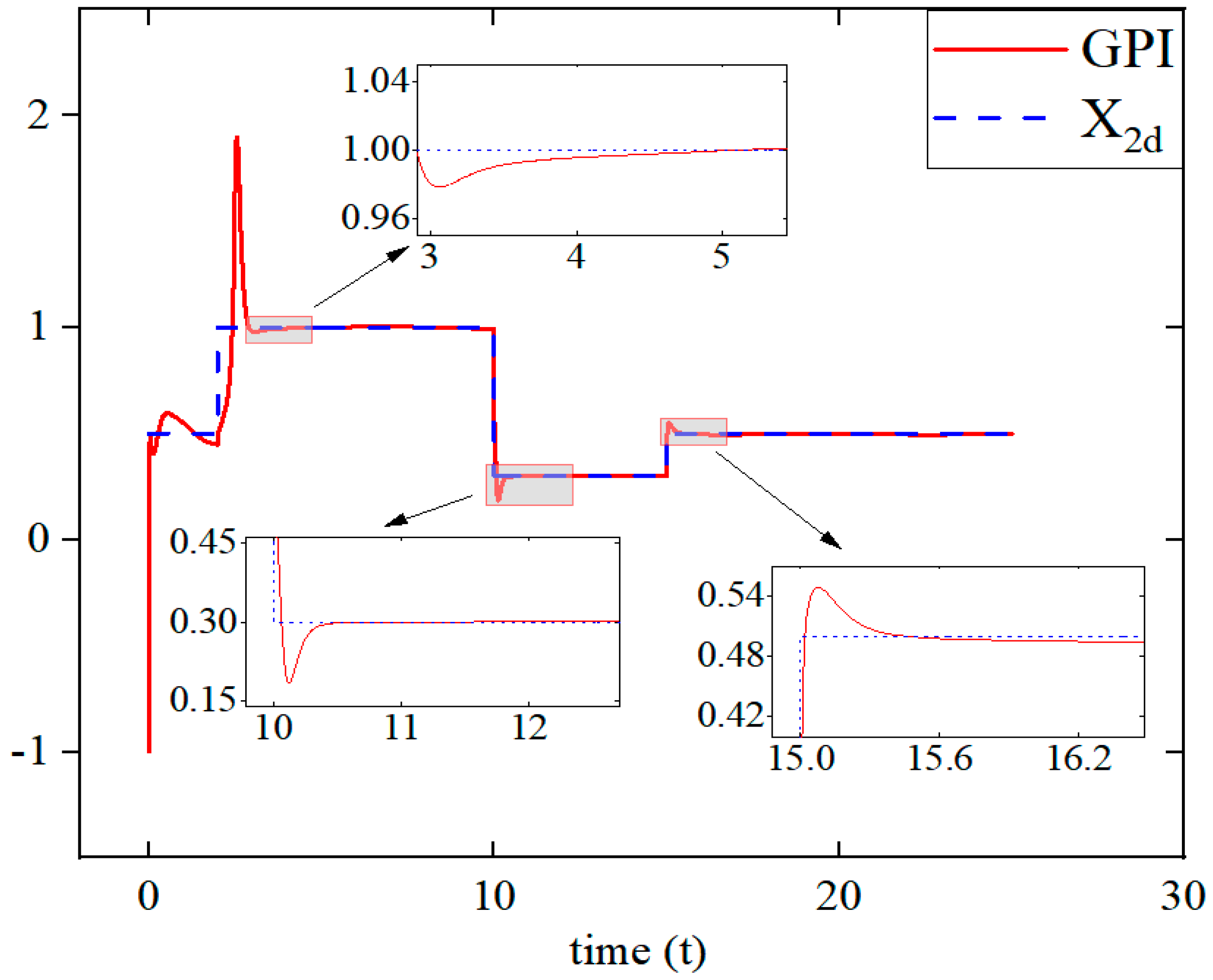

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}