Abstract
Lane detection based on semantic segmentation can achieve high accuracy, but, in recent years, it does not have a mobile-friendly cost, which is caused by the complex iteration and costly convolutions in convolutional neural networks (CNNs) and state-of-the-art (SOTA) models based on CNNs, such as spatial CNNs (SCNNs). Although the SCNN has shown its capacity to capture the spatial relationships of pixels across rows and columns of an image, the computational cost and memory requirement needed cannot be afforded with mobile lane detection. Inspired by the channel attention and self-attention machine, we propose an integrated coordinate attention (ICA) module to capture the spatial-wise relationships of pixels. Furthermore, due to the lack of enhancement in the channel dimension, we created an efficient network with a channel-enhanced coordinate attention block named CCA, composed of ICA and other channel attention modules, for all-dimension feature enhancement. As a result, by replacing many repeated or iterative convolutions with the attention mechanism, CCA reduces the computational complexity. Thus, our method achieves a balance of accuracy and speed and has better performance on two lane datasets—TuSimple and ILane. At less than a few tenths of the computational cost, our CCA achieves superior accuracy compared to the SCNN. These results show that the low cost and great performance of our design enable the use of the lane detection task in autopilot scenarios.
1. Introduction
Lane detection is closely related to the normal driving of self-driving cars and plays an important role in assisted driving systems [,,]. As a perception technique for autonomous driving, lane detection is the fundament of lane departure warning (LDW) systems and lane keeping assistance (LKA) systems []. Through subsequent decision-making algorithms, it makes the vehicle drive in the lane correctly and complies with the traffic rules stipulated for the lane []. In recent years, with the development of computer vision, many methods for detecting lanes have reached this goal []. However, how to deal with prior knowledge of lanes, confusion with other lines and environments, and severe occlusion from other cars still remain challenges [].
In the past several years, lane detection has been based on hand-crafted feature detectors, typically taking into account aspects such as image preprocessing, feature extraction, lane line model fitting, and straight-line tracking. In recent years, algorithms based on deep convolutional neural networks (CNNs) have developed rapidly, their advantages in image feature extraction have become more and more obvious, and their accuracy has obviously improved. Since then, CNN-based lane detection has become a popular research method. Nowadays, the popular methods are categorized into four groups, inspired, respectively, by semantic segmentation [], object detection [], keypoint [], and curve-fitting methods []. The approach based on semantic segmentation mostly predicts every pixel of the image with a binary label [], with an encoder to extract features and a decoder to upsample and recover them. The first method to consider the prior knowledge was the SCNN [], and it greatly enhanced the feature extraction of ordinary convolutional neural networks (CNNs []). The SCNN tries to dig out spatial features deeply with a spatial CNN, moving from deep layer-by-layer convolutions to slice-by-slice convolutions within feature maps. Based on the SCNN, a novel module named the recurrent feature-shift aggregator (RESA) [] has been developed to gather information vertically and horizontally by shifting the sliced feature map recurrently. These approaches mostly aim to figure out more and more about the intrinsic characters of lane lines, improving the accuracy of the task. However, due to the abundant floating point operations (FLOPs), the speed of the tasks performed on high-resolution inputs is far from the design requirements of the driver assistance system (DAS).
Along with the popularity of the attention mechanism and the creation of ViT [], the networks in computer vision have become simpler and lighter as a result of the replacement of recurrence and convolutions, without sacrificing accuracy. Inspired by ViT, we designed an efficient transformer-based module with fused kinds of attention, named integrated coordinate attention (ICA). Channel-enhanced coordinate attention (CCA) divides the feature matrices into the query (Q), key (K), and value (V), like multi-head attention [], and then has two branches in parallel. One is for catching deeper features, and the other uses ICA to gather the attentional importance between all features. The feature branch utilizes Inverted Residuals and ECANet [] after concatenating the Q, K, and V to output a detailed feature map. In contrast, the attention branch applies the ECANet to enhance the information of Q, K, and V, then, respectively, gather the relevance of the input features along the vertical and horizontal directions via Scaled Dot-Product Attention []. The combination of two branches makes our encoder accurately aggregate the spatial features of traffic lanes without a high computational cost. Several major advantages of CCA are as follows: (1) CCA applies global attention to gather information on feature maps, showing better segmentation performance. (2) Because it lacks complex spatial convolutions and recurrent spatial shifts, CCA avoids the burden of high computation for pixel-wise segmentation tasks. (3) CCA is light, simple, and convenient to transfer to other designs.
To achieve outstanding performance in the balance of speed and accuracy, we designed an upsampling module. To demonstrate it, we evaluated it on the dataset TuSimple []. The results in Figure 1 show that the CCA we designed performs better and consumes fewer resources than existing state-of-the-art networks of lane detection by semantic segmentation.
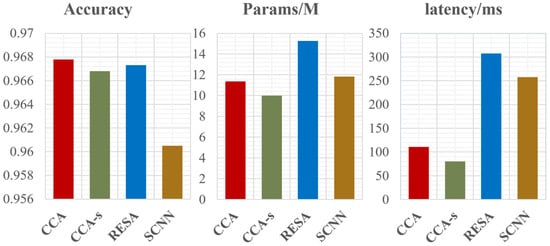
Figure 1.
Performance of different lane detection methods. The y-axis labels from left to right are accuracy, parameters, and latency, respectively. Our approach CCA not only significantly reduces the memory and time costs but also maintains the detection precision of RESA.
The core contributions we focus on are as follows:
(1) We propose CCA to capture a small amount of important lane information and discard redundant background information with the help of the attention mechanism. CCA, which includes feature extraction and enhancement as well as foreground and background segmentation, is simple yet useful and thus suitable for being applied to another network to achieve better overall performance. Additionally, we propose a simple dual-channel convolutional decoder (PDecoder), a new upsampling module adapted for the CCA which can achieve better performance.
(2) Our network achieves the best performance on the TuSimple dataset with minimum latency, demonstrating the potential to serve as a lightweight and efficient lane detection module for mobile devices.
(3) We have collected a new dataset to classify complex lane situations into seven categories, containing nearly 2000 images, to validate the excellent performance of our design.
2. Materials and Methods
2.1. Related Work
In recent years, the field of image recognition has undergone a tremendous transformation from traditional methods by hand-crafted feature to deep-learning-based methods. For the lane detection task, although many cleaver methods have emerged, the requirements of the application remain challenging. How to design a network with high detection accuracy and short detection time has always been a difficult problem. Semantic segmentation and the attention mechanism have shown excellent performance in various deep-learning tasks in recent years. As a pixel-level image processing technology, semantic segmentation can efficiently extract the details of the target, while the attention mechanism focuses on weights of features and obtaining the associations between information. Based on this, the author conducts relevant analysis and launches research and improvement on lane detection task.
2.1.1. Lane Detection by Semantic Segmentation
Since FCN [] pioneered the “sampling + aggregation” network for semantic segmentation, how to aggregate features has been the focus of research in this field. The classical aggregation methods are as follows: UNet [] fuses high-level and low-level features in a step-by-step manner, PSPNet [] utilizes “multi-scale image feature fusion + upsampling”, and DeepLab series [,,], inspired by the idea of multi-scale fusion, introduces the Dilated Convolution to increase the receptive field of the convolution. Cutting-edge algorithms include those proposed by SegFormer [] for the Transformer block and multi-scale fusion methods; K-Net [] which unifies semantic segmentation, instance segmentation, and panoramic segmentation; MaskFormer [] which only performs instance-level classification and eliminates pixel-level classification; Mask2Former [] which introduces a cross-attention mechanism; and segmentation anything model (SAM), proposed in 2023, which can automatically recognize all objects present in the image and is an extraordinary large-scale vision model.
Classical representative methods for lane detection such as SCNN and RESA propose spatial convolution of features based on CNN and utilize spatial iteration to pass information between neighboring rows or columns of the feature map, which is time-consuming and prone to losing dependencies between distant information. Our design is inspired by past research on the self-attention mechanism and channel attention [], to aggregate the dependencies between different information. Without the convolutional aggregator of SCNN and RESA, the design significantly saves computational resources and time costs, so is more suitable for mobile devices.
2.1.2. Feature Enhancement by Spatial Attention
In 2015, Bahdanau et al. proposed the self-attention mechanism [], an important technique for modeling sequence data, and Vaswani et al. proposed the Transformer [] in 2017, which has drawn widespread attention and found extensive applications. The self-attention mechanism compares each element of the input sequence with all other elements and then assigns weights based on the similarity between them. As shown in Figure 2, the author expands the input matrix to obtain Q, K, and V. V can be interpreted as a feature backup, while Q and K carry out the transformations to solve for the weights. In addition to its success in the field of natural language processing, the self-attention mechanism has also been widely used in the field of computer vision. Moreover, the ViT model applies the self-attention mechanism to the image classification task to achieve a performance that matches or even exceeds all traditional convolutional neural networks, which brings a new concept and methodology to the deep learning models in the image field. In short, regardless of the deep learning domain, the attention mechanism is an excellent tool for weight assignment.
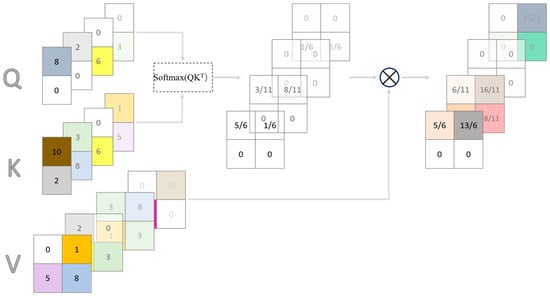
Figure 2.
The principle diagram of the self-attention mechanism. The matrix of query, key, and value are input, and the output is the matrix of weight. The grid represents the feature matrix, and every color’s grid with number represents feature of a pixel. By calculating the feature matrix, the weight distribution factor can be obtained with the self-attention mechanism.
In this thesis, the self-attention mechanism serves as the foundation of core component and is capable of effectively capturing the long-range dependencies among plane coordinates.
2.1.3. Feature Enhancement by Channel Attention
The most classic design in the field of channel attention research is SENet []; Jie Hu’s team from Momenta Enterprise (Momenta, Suzhou, China) pioneered squeeze-and-excitation attention, which makes channel attention a major research hotspot in mobile network design. On one hand, SENet directly sets the values on the two plane dimensions to 1, which causes significant and irreversible damage in terms of performance. Thus, ECA-Net [] emerged through the efforts of scholars in the field of machine learning represented by Wang and others. Only a small number of parameters are added to maintain performance without dimensionality reduction. On the other hand, SENet’s neglect of location information has become an aspect to be optimized. Therefore, Hou and other scientists from the National University of Singapore proposed coordinate attention (CA block) [], which focuses on the grasping of image location information.
These attention mechanisms are highly beneficial to the model’s performance. Considering the shape information of lane lines, we used scaled dot-product attention to obtain stronger associations between different information, as shown in Figure 3; the inspiration of the ICA module comes from SENet, CA and self-attention mechanism. By integrating channel and plane branches, an attention module for three-direction feature enhancement is created. Then, it is applied to the traditional semantic segmentation framework and can effectively capture the key features of lanes.
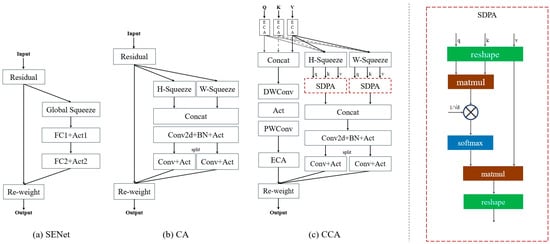
Figure 3.
The structure of a serials of channel attention: (a) SENet; (b) CA Block; and (c) CCA Block (ours).
2.2. Method
2.2.1. Architecture Design
We train a neural network for lane detection that comprises three components: encoder, CCA, and decoder. Firstly, we select ResNet as the encoder, which is utilized for extracting the information of raw images. It downsamples the size of input images to 1/8, retains better original features, and ensures a smoother and more stable training process. Secondly, CCA is the heart of our design, which combines long-range feature embedment in the spatial dimension and information enhancement in the channel dimension. Finally, the dual-channel convolutional decoder (PDecoder) consists of a plain channel and a detail channel. The main purpose of plain channel is to restore the size of the feature map, and the other aims to reduce feature loss due to upsampling. After that are the output branches, predicting the existence and probability of each lane and pixel.
2.2.2. Channel-Enhanced Coordinate Attention
The channel-enhanced coordinate attention (CCA) block can act as a mathematical module to analyze its principles for enhancing the representation of features. The output feature tensor of encoder is shown as . After the augmented representations, it can be transformed to an output tensor , whose size is same as . In this part, we will first revisit the self-attention machine and ECA-Net to give an articulate presentation of CCA.
- 1.
- Revisit ECANet.
ECANet, whose full name is efficient channel attention module, was proposed in 2019. In this paper, the researchers abolished the double-FC layer in SENet, since the double-FC layer hardly obtains the weights efficiently and thus keeps away from low costs. Instead of the unnecessary FC layers, the authors proposed an adaptive way to acquire cross-dimension interaction, achieving high-quality prediction of channel weights. The key point of ECANet is how to compute the convolution kernel adaptively.
where is the channel of input feature, and and are the parameters of the mapping function. After that, channel attention can be obtained by a convolution and a sigmoid function.
- 2.
- Revisit Attention Mechanisms.
Attention mechanisms have enhanced the existing best results with low computational costs and thus play an important role in our CCA. As demonstrated in [], we can obtain the weights with a simple softmax function when the input consists of queries, keys, and values. The attention output can be as follows:
where is a scaling factor, is the query matrix, is the key matrix, and is the value matrix. The multi-head attention first obtains the weights of information from representation subspaces at different positions and then concatenates the weights, instead of computing the weight after averaging the information, avoiding the discarding of detailed information.
- 3.
- Revisit Coordinate Attention (CA Block).
As described in [], the coordinate attention block can be decomposed into two steps: coordinate information embedding and attention generation, which are designed for channel relationship encoding and exploration of long-range dependencies with precise position. With the input , the embedding step for the channel at height and weight can be formulated as follows:
By the pair of equations above, the features from two different spatial directions are, respectively, aggregated, avoiding the loss of many details and such expensive computational costs.
The next step is to make full use of the expressive representations resulting from the embedding transformation. Refer to three criteria–mobile, ROI-highlighted, and relationships between channels: the author first concatenates and sends them to a convolutional transformation function , which is formulated as follows:
where means the concatenation operation, denotes activation function, and is the intermediate feature map. was split into two dimension-separate tensors and which were sent to another convolutional function and .
where is the sigmoid function. Finally, they multiplied inputs and weights, yielding the output of the module depicted as follows:
- 4.
- CCA Block.
The block we designed consists of two types of branches: the feature branch and the weight branch, as Figure 4.
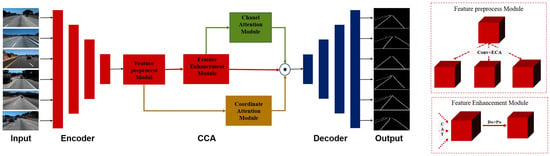
Figure 4.
Architecture design. Our design consists of five main parts: the encoder chooses the residual network; the feature preprocessing has two parts as shown on the right; the channel attention module is the ECA module; the coordinate attention module is ICA as in Figure 5; and the decoder as in Figure 6.
One is the feature branch, which combines the feature preprocess module and the following feature enhancement module. It is the main branch to extract more fine-detailed features. In the preprocess module, we split the feature matrix into , , and , facilitating the operation of the weight branch. Then, stacking the , , and in channel dimension in the enhancement module, and by the following part composed of a DWConv [], a ReLU, a PWConv [], and a ECANet, a new feature map can be output. The DWConv aims to capture more details, the PWConv changes the number of channels, and the ECANet enhances the channel-wise information by calculating the matrix. The output of feature branch can be as follows:
where denotes the ECA block, and denote the two kinds of convolutional functions, is hardsigmoid function, and denotes the concatenation operation.
The other one is the weight branch we call ICA as shown in Figure 5, and can be used to filter important spatial information in high resolution. ICA has two parts, the coordinate attention module and the channel attention module. Identical to the feature branch, the coordinate attention module also performs feature processing based on , , and . The attention branch is divided into two stages—coordinate information squeezing and spatial attention generation. However, the channel attention module is relatively easy to implement. The input of it is same as the feature enhancement module of the feature branch. Its composition is an ECANet.
- Coordinate Information Squeezing.
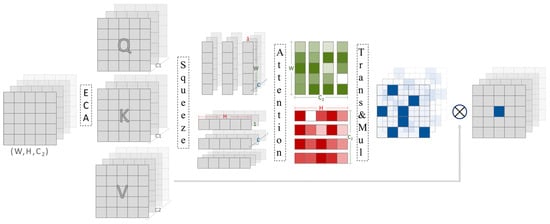
Figure 5.
Our implementation of the enhancement branch ICA.
In SENet and ECANet, global pooling was used to squeeze the spatial information. The shortcoming is obvious. Global averaging is too crude to preserve representative details. Thus, like the coordinate attention block, we apply the global pooling but squeeze the vectors in two respective spatial directions for , , and in the first step. The input in channel involves three feature matrixes , , and as shown:
where height and width are , , and the outputs can be depicted as similar equations:
For :
For :
For :
where is the output at weight and is the output at height. By pairs of equations above, height-dimension and weight-dimension vectors were squeezed, outputting six vectors of information as the input of the attention part. Aiming to dig out the more interesting importance of different spatial positions over long distances, we compute the weights for value, respectively, at the height and weight. The output of attention Functions are as follows:
and denote the information map with two-directions weight, embedding to the next transformation as inputs. On one hand, with the help of the attention mechanism, spatial coordinates in two different dimensions can be encoded efficiently, preserving as many representative details as possible. On the other hand, the scaled factor enables our module not to have such substantial computational costs to burden. By the attention, the key, query, and value were linked, yielding a feature tensor in each direction. In addition, we must stitch the coordinate information of different directions by concatenating them in the last step:
- Spatial Attention Generation.
Further on the basis of encoding global coordinate information is how to identify the interested region, so we need to clarify the relationships between coordinates. Few operations, in this part, are proposed that differ from the CA block. The first step is transforming by a convolutional transformation function and an activation function . The output is as follows:
where is the t_hardsigmoid function and , and r is the reduction ratio controlling the size of the CCA block. Then, after splitting along the height and width direction, the two tensors obtained are sent separately to customized convolutional functions and . Thus, the output of the enhancement branch can be written as follows:
denotes the spatial dimension height or width, is a no-linear activation function, and we choose softmax in the experiment. and , the results of the enhancement, act as the weights of the feature branch. So, we need the last operation, multiplying them:
2.2.3. Dual-Channel Convolutional Decoder
In this part, we need to design a decoder to upsample the feature map so that its resolution is the same as the input. The first requirement is to be lightweight, so we choose a simple and low-parameter decoder as the base, named PlainDecoder []. However, the 1 × 1 convolution in PlainDecoder transforms the information into an overly sketchy situation, ignoring details that should not be ignored. Aiming to overcome this drawback, the second step we take is to add another channel to focus on the details. Just a sum of the dual channel is sufficient to output a feature map. Without high cost, it can improve a lot.
In Figure 6, the UpSampleConv is a combination of a group convolution, a channel-enhanced block, and a 1 × 1 convolution. It is similar to the BottleNeck but with a reduction ratio of 2, not 6. The OutputConv and the PlainConv are both 1 × 1 convolution, and the difference between them is the number of input channels. The latter one has the same number of inputs, while the former one has one-eighth of it. We can describe the module as follows:
where is a no-linear activation function, is the OutputConv, is the UpSampleConv, is the PlainConv, and is Dropout, a strategy for suppressing overfitting.
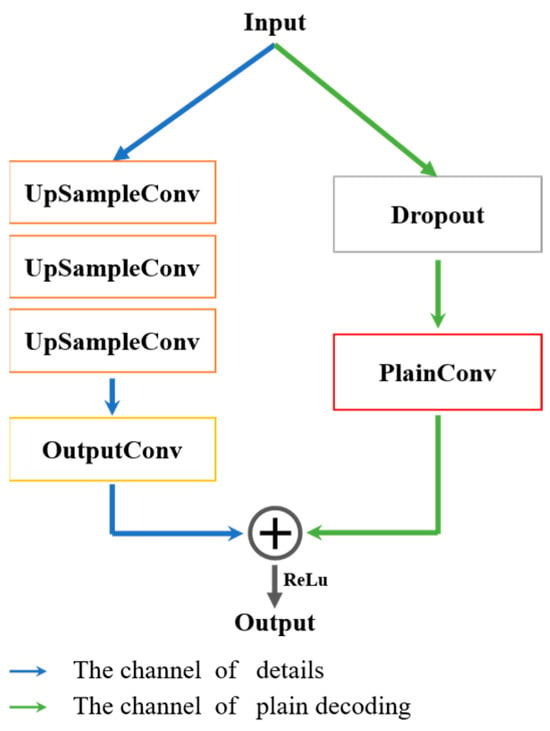
Figure 6.
Our implementation of Dual-Channel Convolutional Decoder PDecoder.
3. Results and Discussions
3.1. Experiment Implementation and Dataset
3.1.1. Dataset of Experiment
We conduct experiments on a widely used lane detection benchmark dataset: the Tusimple Lane detection benchmark. The dataset consists of 3626 training images and 2782 test images with stable lighting conditions in American highways. Considering the limitations of highway, we collect a new dataset, which is called Ilane, which includes several difficult roads such as country roads and environments such as night and snow. For the test dataset, we classify Ilane into a number of different categories. The detailed information is given in Figure 7.
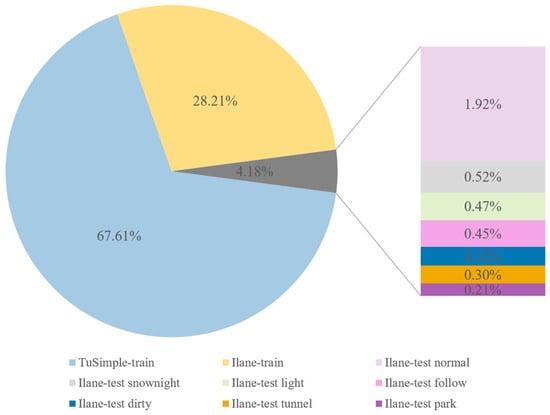
Figure 7.
Dataset description.
3.1.2. Evaluation Metrics of Experiment
The evaluation metrics are , , and , are depicted as follows:
where is the number of images, is the number of all point in lane, and is the number of the points with right prediction. and are the numbers of the points with wrong predictions, which are divided into missing correct values, creating incorrect values.
3.1.3. Implement Settings of Experiment
Our models are modified based on the RESA, and the initial weights of the backbone are copied from ResNet. In both tasks, we train the models using standard stochastic gradient descent (SGD) with batch size 4, base learning rate 0.02, momentum 0.9, and weight decay 0.0001. The loss function we choose is the sum of binary cross entropy (BCE) and existence cross entropy (CE), but we have also made a few setting modifications to fine-tune the configuration of the loss function. The original size of the images is 720 × 1280. For the default version, the images are cropped to the fixed size of 368 × 640. For the full-resolution version, the images are kept at the original size 720 × 1280. For the scaling-resolution version, we set the size to 720 × 640. All experiments were conducted on an NVIDIA GeForce RTX 4060 GPU.
3.2. Experimental Results and Discussions
3.2.1. Main Results
In this section, we extensively evaluate the performance of the proposed network CCA on different datasets and in real scenarios.
- 1.
- Qualitative Analysis.
In this part, we present the qualitative comparison results of CCA with two classical algorithms. We visualize the semantic segmentation results as shown in Figure 8; we can measure missed detections in terms of the density of points. In many details, such as long-distance lane markings, the RESA has a good detection effect. Although CCA is not as dense as the RESA at long-distance detection points, but it still performs better overall. Both are significantly better than the SCNN, which cannot even detect any point on the leftmost road. Due to the irregular shape of lane lines and complex road conditions, the detection performance of existing algorithms and the network is not ideal. It can be seen from the prediction results that the SCNN algorithm, which has the same detection time as CCA, has obvious limitations, with too many missing coordinate points of lane lines and sparse dots. For the better performance of the RESA, the prediction results of the RESA can segment lane lines well, but the issues of the detection time and cost need to be analyzed in the following chapters. The target edge predicted by our algorithm is very close to the real situation on the ground, showing high robustness and no false detection. Our algorithm outperforms other comparison methods in terms of detection and segmentation performance.
- 2.
- Quantitative Analysis.

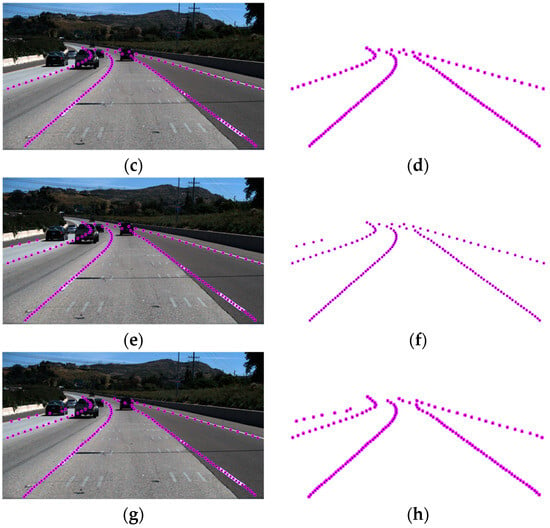
Figure 8.
A visualization comparison on the output images of CCA and SCNN: (a) the input image; (b) the ground-truth labels; (c) SCNN output features visualized on the input image; (d) binary image output by SCNN; (e) CCA output features visualized on the input image; (f) binary image output by CCA; (g) RESA output features visualized on the input image; and (h) binary image output by RESA.
The following will show the results of our network on different datasets and the comparison of the metrics of different networks. The first one is on the TuSimple dataset. We select some classical lane line recognition methods such as LaneNet, LaneATT, the RESA, and the SCNN. In addition, we consider two sets of “aggregator-free” networks, which are composed of two kinds of common backbones and a BUSD decoder from the RESA. The result is shown in Table 1. While the RESA outperforms all baselines in terms of accuracy, it does so at the expense of efficiency. In contrast, CCA optimizes latency to achieve the most balanced result. Under the condition that all backbones choose resnet34, the latency of our network is 392 ms, nearly half as fast as the RESA, and even much faster than Res34-BUSD without an aggregator. It has to be mentioned that, on the other hand, the accuracy rate is 96.81%, an increase of 0.28% on the basis of the SCNN and only 0.6% lower than the RESA. Taken together, the evaluation gives us a good indication of the adaptability of CCA on mobile devices.

Table 1.
Comparison with state-of-the-art results on TuSimple with image resolution (1, 3, 368, and 640).
On the dataset Ilane that we collected, we classified the images and compared the performance of the RESA, SCNN, and CCA under different adverse conditions. The result is shown in Table 2. In terms of the latency, our designed CCA can reach higher-rate levels. In some conditions such as curves, junctions, and old roads, the complexity of image features increases the processing difficulty and thus lengthens the latency of the task. However, it is reassuring to see that CCA still maintains a low latency. In terms of accuracy, the detection accuracy of CCA is superior to that of the SCNN in any case. In cases of bad light, tunnel, and others, the accuracy is even better than that of the RESA.
Table 2.
Comparison with state-of-the-art results on Ilane with image resolution (1, 3, 368, and 640).
The final output of our designed network is shown in Figure 9. The input picture of CCA is located in the first row. The network performs point recognition to output point coordinates, plotted in the input image as shown in the second row of images, plotted in the black background image as shown in the third row of images. It can be seen that our network can accurately identify the two adjacent lanes of a car and output dense point coordinates, which meets the requirements of intelligent transportation and autonomous driving for lane identification. In addition, on the side road and bypass road, there may be an inaccurate detection or poor detection effect. Therefore, how to accurately identify them is one of the key points we still continue to focus on and improve.

Figure 9.
The results images of our network in different environments.
3.2.2. Ablation Study
To elaborate on the advantages of our approach in more detail, we combine the channel-enhanced coordinate attention block and the PDecoder discussed in the Method chapter and attempt to analyze and confirm the necessity of each module in this section.
- 1.
- Loss of Each Module.
We first studied the processing efficiency of aggregators and the decoder. As a baseline, we chose ResNet-34 as the backbone. After extraction from the backbone network, the feature maps enter the aggregator, and the image feature weights are calculated for stacking. Finally, we use the decoder to upsample the feature maps by a factor of 8. We record the processing time for each module. To compare the aggregators, we replace the aggregator with the RESA and SCNN without changing the other modules. Similarly, to compare the decoder’s time consumption, we just replace the decoder with BUSD and PlainDecoder. We summarize the performance of each aggregator module in Table 3, and the performance of each decoder module in Table 4. It can be seen that both modules significantly improve the lane detection performance, which demonstrates the capability of the modules. In particular, in the aggregator part, the computation of our new design CCA is about 1/25 of the RESA and lower than 1/5 of the SCNN, while, in the decoder part, we do not simplify it blindly, so its computation is not too low but still lower than 1/20 of BUSD, which enables a balance of time loss while keeping the decoding a without loss of accuracy.
- 2.
- Effectiveness of Each Module.
Table 3.
Parameters and latency of three aggregators in different high resolutions of input images. Lat1 means the latency in 256 × 256, Lat2 means 512 × 512, and Lat3 means 1024 × 1024.
Table 4.
Parameters and latency of three decoders in different high resolutions of input images. Lat1 means the latency in 256 × 256, Lat2 means 512 × 512, and Lat3 means 1024 × 1024.
In this section, we explore the effect of different combinations of aggregators and decoders on the processing results. Theoretically, when the amount of computation increases, it means that the complexity of the operation increases, and more accurate features can be aggregated per feature map. However, this comes at the cost of processing time. The focus of the study is how to select the right combination of aggregator and decoder to achieve the perfect balance between accuracy and speed.
At the beginning of our design, we wanted to take advantages of the CCA block in terms of the time cost. However, when comparing the accuracy of the SCNN and RESA, we found that, whether it is paired with a complex BUSD or a simple PlainDecoder, it does not achieve the best result in terms of accuracy. Therefore, we designed PDecoder to simplify the operation of BUSD while retaining its idea. As shown in Table 5, although it takes a little more time compared with PlainDecoder, it shows a significant improvement in accuracy, and the increase in computational load on the entire network is insignificant. This is a trade-off between performance and computational resources. To strike a balance between the two, we choose “CCA + PDecoder” as our final choice.
Table 5.
Parameters and latency of three decoders in different high resolutions of input images. Lat1 means the latency in 256 × 256, Lat2 means 512 × 512, and Lat3 means 1024 × 1024. “↑” represents the increase in different metric and “↓” represents the decrease.
4. Conclusions
In this paper, we present two key components for lane detection: the channel-enhanced coordinate attention (CCA) and the simple upsampling decoder (PDecoder). The CCA block utilizes the superposition of multiple attention mechanisms to obtain local relationships between pixels in both the vertical and horizontal directions. In the foundation of acquiring the base plane feature weights in the vertical and horizontal directions, it uses channel attention to perform feature enhancement in the third dimension, and then aggregates the information from each pixel into global information. In addition, it can be easily integrated into other networks. The simple upsampling decoder simplifies some image convolution operations and fully connected structures, saving a significant amount of computing time while combining coarse-grained and fine-grained images. The most outstanding advantage is that the decoder can be combined with CCA to achieve the best performance. Our approach is evaluated on the lane detection benchmark dataset Tusimple to achieve the best balance among various metrics. Furthermore, considering that the TuSimple dataset has a single road condition, we collected a new dataset, ILane, which covers many rural roads with different road conditions for evaluation and testing. We conducted experiments on this dataset and found that the algorithms designed by us can maintain good results in terms of both accuracy and processing speed even under a few extreme conditions. We found that, even under the conditions of low light, extreme weather, and poor vehicle conditions, our algorithm still maintains good results in terms of both accuracy and latency, and it is expected to be embedded in existing autonomous driving systems. We are actively exploring suitable application scenarios and deploying solutions to promote the development of automotive intelligence.
Author Contributions
Conceptualization, K.X. and Z.H.; methodology, K.X.; software, K.X.; validation, K.X.; formal analysis, Z.H., M.Z. and J.W.; investigation, Z.H., M.Z. and J.W.; data curation, K.X.; writing—original draft preparation, K.X.; writing—review and editing, Z.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Science and Technology Bureau of Changchun, China, under grant number 2024GD03.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available upon request form the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Liu, L.; Chen, X.; Zhu, S.; Tan, P. CondLaneNet: A Top-to-down Lane Detection Framework Based on Conditional Convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Al-Rajab, M.; Loucif, S.; Kousi, O.; Irani, M. Smart Application for Every Car (SAEC). (AR Mobile Application). Alex. Eng. J. 2022, 61, 8573–8584. [Google Scholar] [CrossRef]
- Dong, B.; Lin, H.; Chang, C. Driver Fatigue and Distracted Driving Detection Using Random Forest and Convolutional Neural Network. Appl. Sci. 2022, 12, 8674. [Google Scholar] [CrossRef]
- Chen, W.; Wang, W.; Wang, K.; Li, Z.; Li, H.; Liu, S. Lane departure warning systems and lane line detection methods based on image processing and semantic segmentation: A review. J. Traffic Transp. Eng. 2020, 7, 748–774. [Google Scholar] [CrossRef]
- Zou, Q.; Jiang, H.; Dai, Q.; Yue, Y.; Chen, L.; Wang, Q. Robust Lane Detection From Continuous Driving Scenes Using Deep Neural Networks. IEEE Trans. Veh. Technol. 2020, 69, 41–54. [Google Scholar] [CrossRef]
- Kachhoria, R.; Jaiswal, S.; Lokhande, M.; Rodge, J. Chapter 7-Lane detection and path prediction in autonomous vehicle using deep learning. In Intelligent Edge Computing for Cyber Physical Applications, 2nd ed.; Hemanth, D., Gupta, B., Elhoseny, M., Shinde, S., Eds.; Academic Press: Cambridge, MA, USA, 2023; pp. 111–127. [Google Scholar]
- Guo, Y.; Zhou, J.; Dong, Q.; Bian, Y.; Li, Z.; Xiao, J. A lane-level localization method via the lateral displacement estimation model on expressway. Expert Syst. Appl. 2024, 243, 122848. [Google Scholar] [CrossRef]
- Lin, H.; Chang, C.; Tran, V. Lane detection networks based on deep neural networks and temporal information. Alex. Eng. J. 2024, 98, 10–18. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, Z.; Zhang, X.; Xue, J.; Liao, Q. Deep Learning in Lane Marking Detection: A Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 5976–5992. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the state-of-the-art technologies of semantic segmentation based on deep learning. Neurocomputing 2022, 493, 626–646. [Google Scholar] [CrossRef]
- Kaur, R.; Singh, S. A comprehensive review of object detection with deep learning. Digit. Signal Process. 2023, 132, 103812. [Google Scholar] [CrossRef]
- Hao, W. Review on lane detection and related methods. Cogn. Robot. 2023, 3, 135–141. [Google Scholar] [CrossRef]
- Parashar, A.; Rhu, M.; Mukkara, A.; Puglielli, A.; Venkatesan, R.; Khailany, B.; Emer, J.; Keckler, S.; Dally, W. SCNN: An accelerator for compressed-sparse convolutional neural networks. In Proceedings of the 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Zheng, T.; Fang, H.; Zhang, Y.; Tang, W.; Yang, Z.; Liu, H.; Cai, D. RESA: Recurrent Feature-Shift Aggregator for Lane Detection. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- TuSimple. Available online: https://paperswithcode.com/sota/lane-detection-on-tusimple (accessed on 20 October 2018).
- Jonathan, L.; Evan, S.; Trevor, D. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–15 June 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.P.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Álvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Proceedings of the Annual Conference on Neural Information Processing Systems 2021, Virtual Event, 6–14 December 2021. [Google Scholar]
- Zhang, W.; Pang, J.; Chen, K.; Loy, C.C. K-Net: Towards Unified Image Segmentation. In Proceedings of the Annual Conference on Neural Information Processing Systems 2021, Online, 6–14 December 2021. [Google Scholar]
- Cheng, B.; Schwing, A.G.; Kirillov, A. Per-Pixel Classification is Not All You Need for Semantic Segmentation. In Proceedings of the Annual Conference on Neural Information Processing Systems 2021, Online, 6–14 December 2021. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention Mask Transformer for Universal Image Segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Guo, Y.; Li, Y.; Feris, R.; Wang, L.; Rosing, T. Depthwise Convolution is All You Need for Learning Multiple Visual Domains. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence, Virtual Event, 22 February–1 March 2022. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).