This section presents the incorporation of the extended disturbance estimator in the car-following control scheme. The purpose is to estimate the impact of the “equivalent disturbance” on the ACV’s car-following system. Subsequently, the estimator gains are adjusted through reinforcement learning.
4.1. Extended Disturbance Estimator Design
Let
indicate the positional difference between the safe space
xsafe, and
xveh is the length of the ego-vehicle and the real space of two neighboring vehicles. Let
indicate the velocity difference between the ego-vehicle and the leading vehicle. In this case, we selected a sliding surface as outlined below:
This formulation ensures that both position and velocity errors are considered in the control law, allowing for responsive adjustments that maintain safe following distances. The positive controller gain c1 balances the position and velocity terms to enhance stability.
The
si function’s derivative can be obtained through the following steps:
By replacing Equation (1) and
yi into Equation (3), we obtain the following result:
Explain
as an “equivalent disturbance”, and Equation (5) is represented as
Then, Equation (5) can be reformulated as the following:
By utilizing Equation (6), it is possible to indirectly determine the structure of di by measuring the earlier structure of
ui,
,
vi,
ai, and calculating
. This can be expressed as defining
z1 =
di and
z2 =
di, and rewriting the “equivalent disturbance” can be reformulated as the following:
Additionally, Equation (7) can be expressed in the following formula through the definition of
A = [0, 1; 0, 0],
B = [0, 1]
T, and
z = [
z1,
z2]
T.
Hence, System Equation (8) can be represented by Equation (6). By setting
C = [1, 0], the output equation is expressed as follows:
Given the observability of the pair (
A,
C), the disturbance estimator for an autonomous driving vehicle can be formulated based on the guidelines provided in [
30] by establishing
Theorem 1. Suppose we assume that the second derivative of equivalent disturbance di is confined and pleases for the system. The boundedness ofis reasonable in typical driving scenarios, as physical disturbances (like drag or road gradient) generally vary gradually. The parameter δ1 is chosen based on expected disturbance levels, ensuring robustness to realistic variations in traffic and road conditions. Considering Equations (8) and (9), EDE can be designed in the following formula:
Therefore, the error in estimating the disturbance, denoted as , can approach a region near the origin through the selection of suitable gains L = [l1, l2]T and an auxiliary variable p.
Equation (10) can be rewritten by substituting the second line into the derivative of the first line.
Rewriting Equations (6) and (9), and
in Equation (11) results in
Equation (8) subtracted by Equation (12) results in
Selecting suitable gains will result in
being Hurwitz due to the observability of the pair (
A,
C). Therefore, for any positive matrix
Q > 0, a distinct positive matrix
p > 0 exists.
Select a Lyapunov function.
The time derivative is obtained by taking the derivative of Equation (15) concerning Equations (13) and (14).
Consider
λp as the largest eigenvalue of matrix
P and
λq as the smallest eigenvalue of matrix
Q, resulting in
It can be shown that |.|, ||.||2, and ||.||F represent the utter value of a variable, the 2-norm of a vector, and the Frobenius norm of a matrix, correspondingly. It follows that . Subsequently, the reduction in V1 leads the system’s path towards a region where . Consequently, by selecting suitable gains L = [l1, l2]T, the system’s path will ultimately converge towards a limited origin.
Statement 1. Traditional EDE relies on manual adjustment of gains, which are determined through experience. However, due to the constantly changing nature of disturbances in transportation environments, the secure gain of EDE falls short in meeting the demands of complex transportation scenarios, ultimately leading to a decrease in the precision of disturbance estimates.
4.2. Estimator Gain Adjusted by Reinforcement Learning
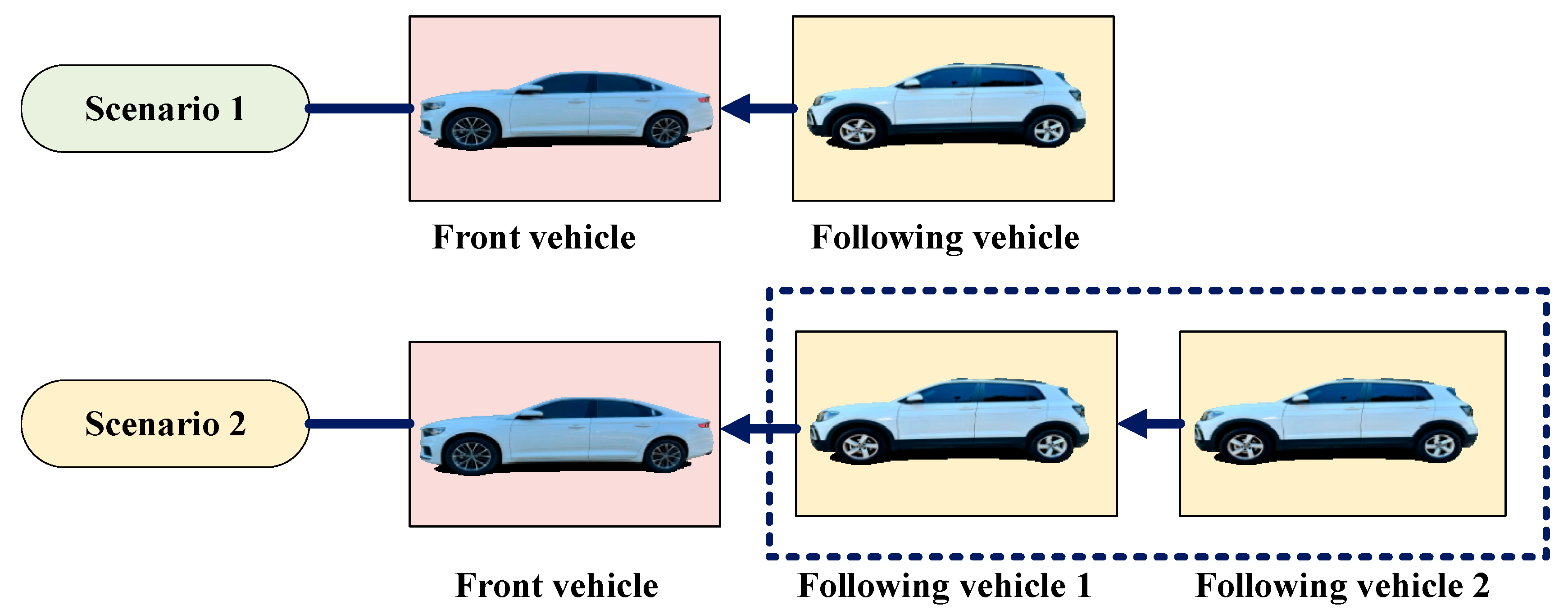
The EDE gain for the suggested car-following system is adjusted using reinforcement learning. This method allows for maximizing returns through trial and error to achieve an ideal approach. DDPG is a common reinforcement learning algorithm that is well-suited for continuous action spaces. Therefore, the DDPG algorithm from Algorithm 1 is utilized in this study to adjust EDE gains. Two car-following scenarios are selected for ease of reinforcement learning application, as depicted in
Figure 1.
| Algorithm 1: DDPG Algorithm |
- 1.
Initialize: Critic network Q(s,a∣θQ) and actor μ(s∣θμ) random weights θQ and θμ. Target networks Q′ and μ′ with weights θQ′←θQ. Replay buffer R.
- 2.
For episode = 1 to M do:
- 3.
For time step t = 1 to T do: Select action
according to the current policy and exploration noise. Execute action at and observe reward rt and new state st+1. Store transition (st, at, rt, st+1) in replay buffer R.
- 4.
Sample a random minibatch of N transitions (si, ai, ri, si+1) from R.
- 5.
Set target value for each sampled transition:
- 6.
Update critic by minimizing the loss:
- 7.
Update the actor policy using the sampled policy gradient:
- 8.
- 9.
End for
- 10.
End for
|
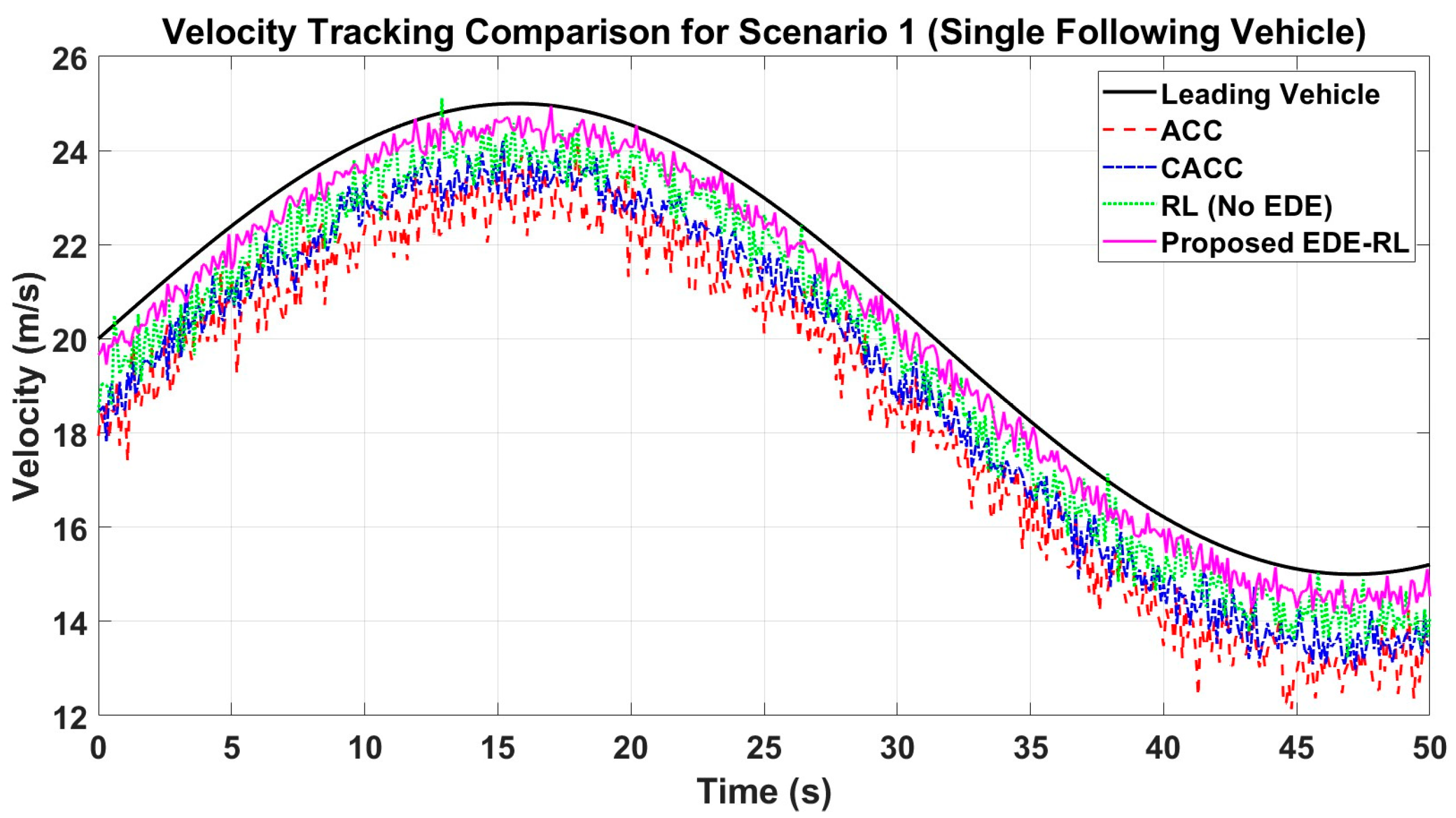
In Scenario 1, there is a single leading vehicle and a single following vehicle. The two vehicles exchange information regarding speed, position, and other relevant data through V2V communication. The vehicle highlighted in the blue box in
Figure 1 implements the car-following system outlined in this research, where the EDE gain is continuously simplified in the present using reinforcement learning.
The Markov decision process is initially modeled. The DDPG selects the action as the EDE gain of the subsequent vehicle. The state space is then selected as
The universe movement between the following vehicle and the front vehicle is calculated as , where xsafe represents the safe space and xveh represents the vehicle length. The velocity error between the following vehicle and the front vehicle is determined as Δvi = vi − v0, with vi and ai representing the velocity and acceleration of the following vehicle.
The selection of the compensation purpose is as follows:
In the equation, aik represents the acceleration of the i-th following vehicle at the k-th frame. Additionally, vmax, amax, and ΔT stand for maximum velocity, maximum acceleration, and time step, correspondingly. The theoretical absolute value of a variable is indicated by |.|, while positive coefficients ω1 and ω2 are also included in the equation.
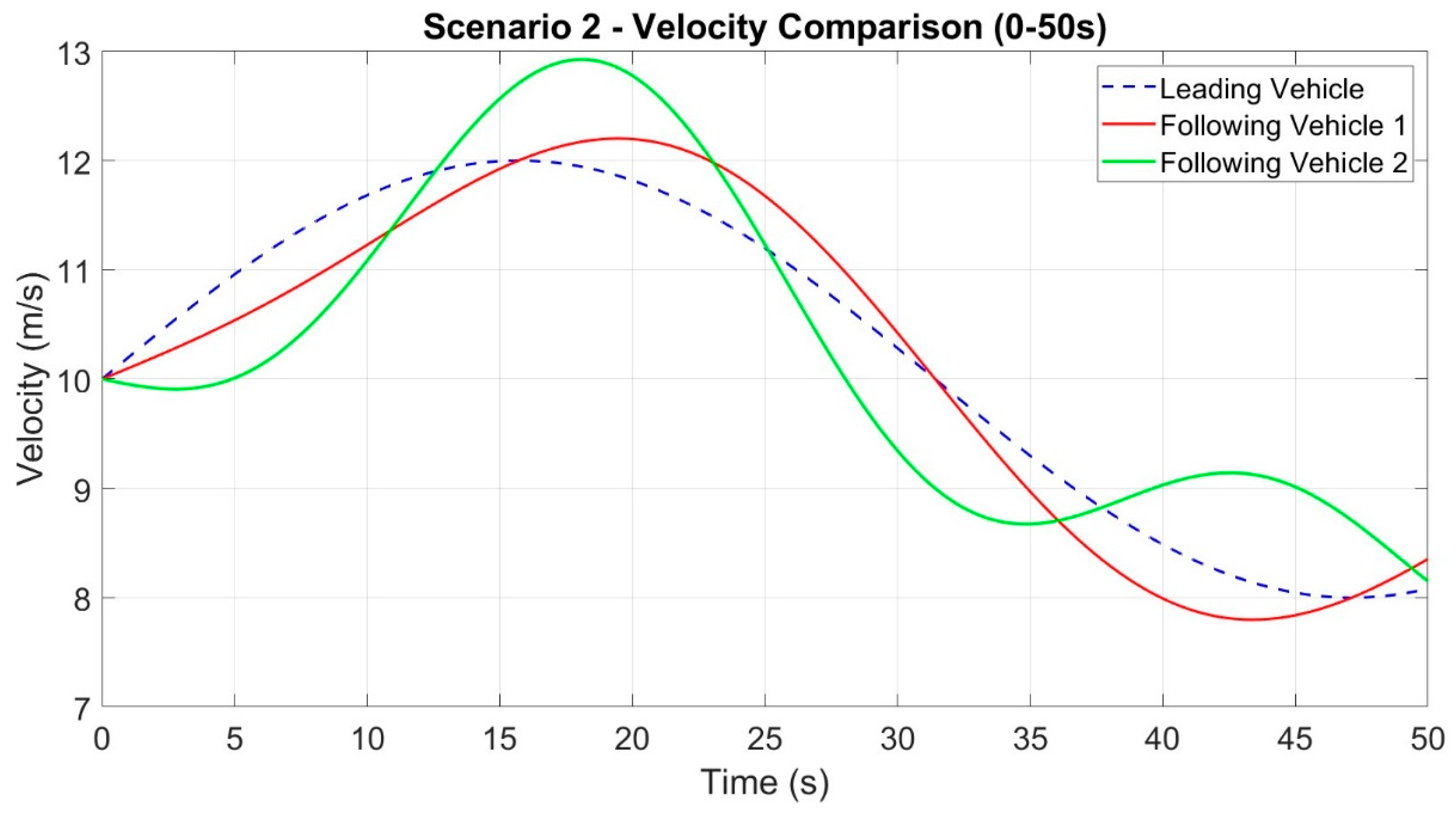
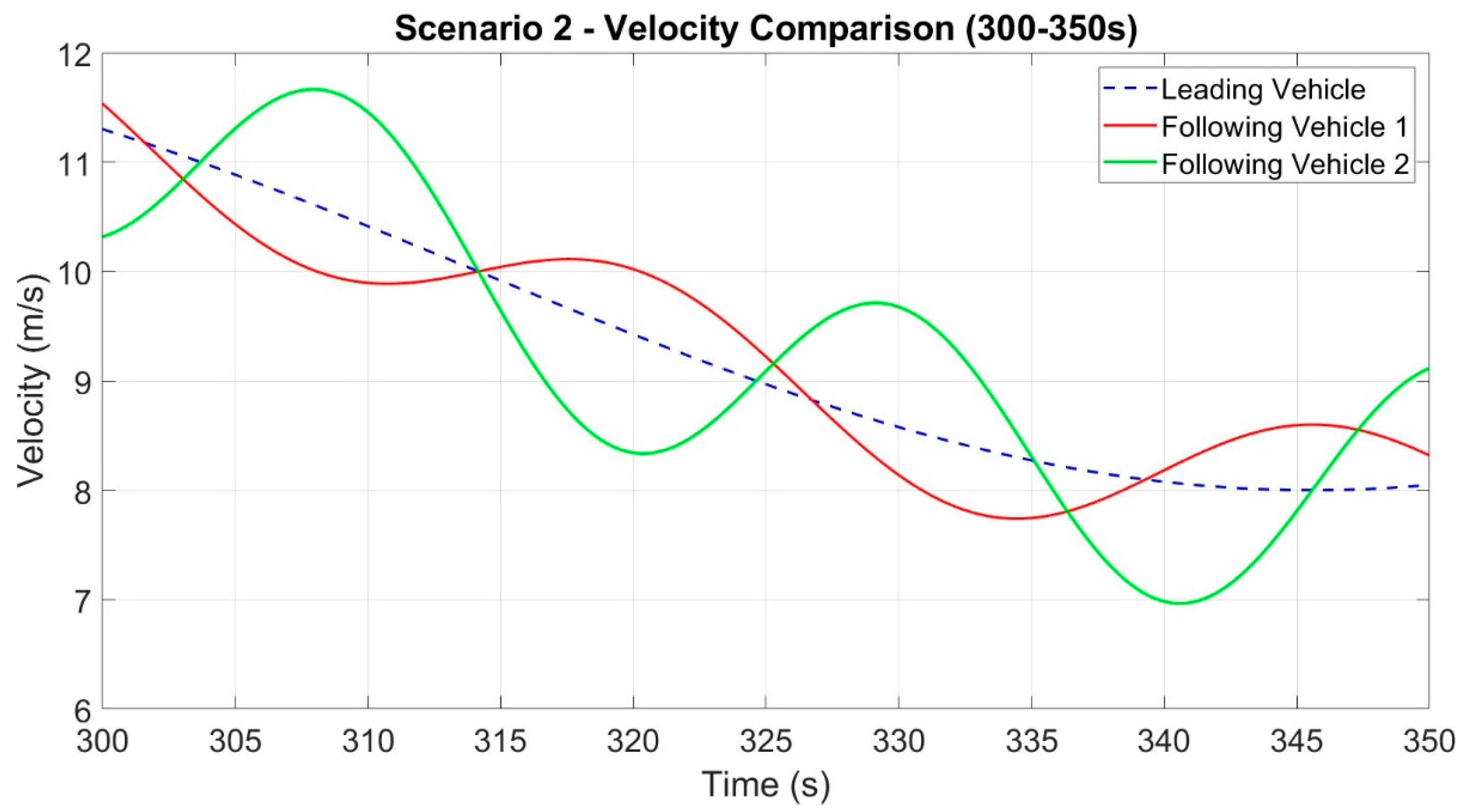
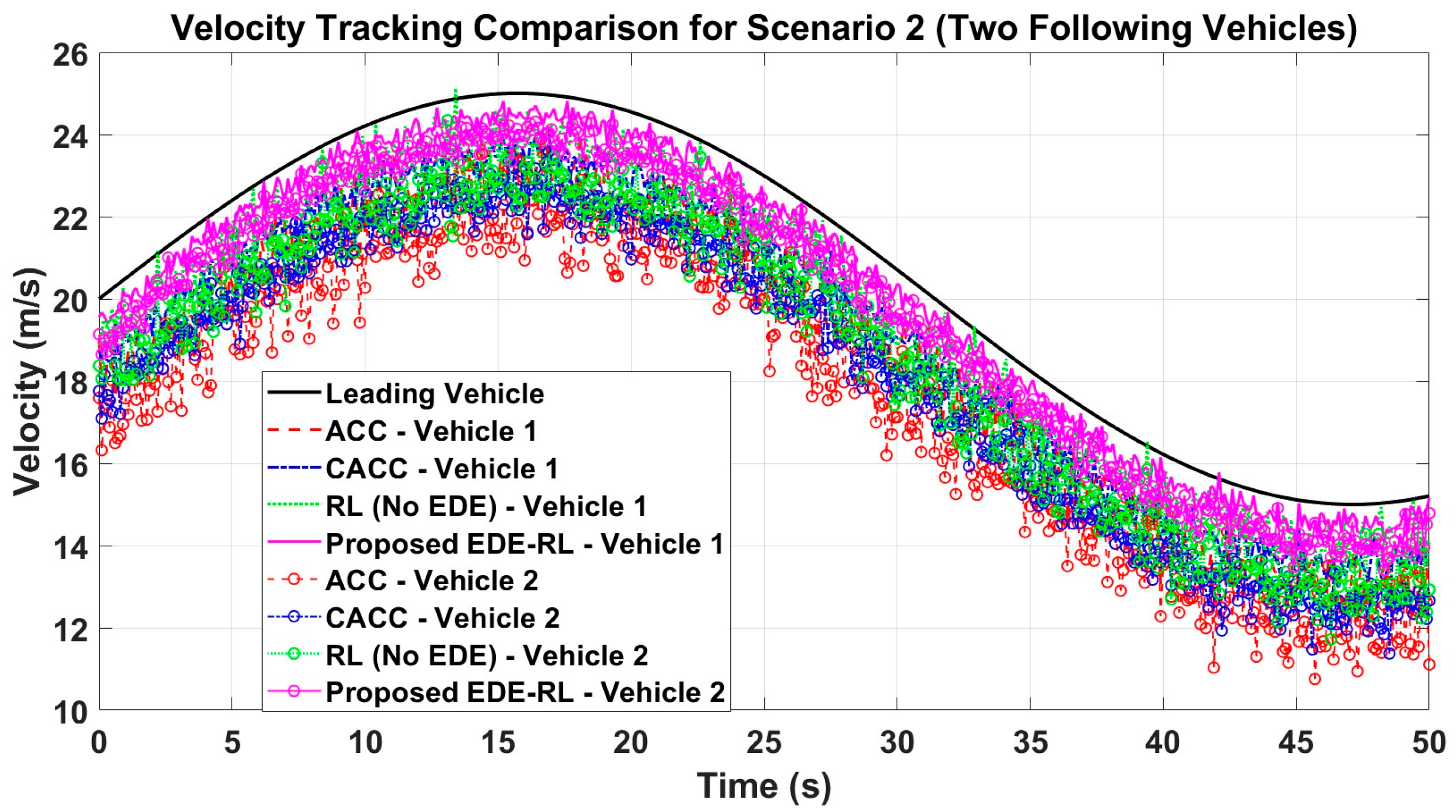
In Scenario 2, there is a front vehicle and two following vehicles. As depicted in
Figure 1, the car-following approach presented in this study is utilized by the following vehicles 1 and 2, with real-time updates of EDE gain through reinforcement learning.
We formulate a Markov decision method for Scenario 2, where the exploit of DDPG is selected as the EDE gain for two consecutive vehicles simultaneously. The state space is defined as follows:
The universe relative motion movement between following vehicle 1 and the front vehicle is given by , while the velocity error is represented by Δvi = vi − v0. On the other hand, the universe relative motion movement between following vehicle 2 and the front vehicle is denoted by yi+1 = xi+1 − x0 − 2(xveh − xsafe), and the velocity error is Δvi+1 = vi+1 − v0. The velocities of the following vehicles 1 and 2 are represented by vi and vi+1, respectively.
The incentive function in scenario 2 is calculated as the total of Equation (19) for subsequent vehicles 1 and 2 in the following manner:
Statement 2. In contrast to the conventional EDE method, which relies on experience to adjust gains, the gains of EDE in this research are fine-tuned using RL. RL involves continuous trial and error during training to achieve the strategy with the highest cumulative reward, ensuring accurate disturbance adaptive estimation in intricate traffic situations. Consequently, through reinforcement learning, EDE gains can be optimized to suit various state spaces, enhancing the precision of the disturbance estimate.
Statement 3. For more than three vehicles, the EDE gain will be adjusted by linking Scenarios 1 and 2. For instance, if there are four ACVs, Scenario 1 will be applied to vehicles 1 and 2, with vehicle 2 being manipulated by the suggested method. On the other hand, Scenario 2 will be applied to vehicles 2, 3, and 4, with vehicles 3 and 4 being operated by the suggested method. Due to the possibility of delay, the suggested car-following structure only takes into account V2V communication between both vehicles, making it suitable for limited platoons.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}