
Toward Competent Robot Apprentices: Enabling Proactive Troubleshooting in Collaborative Robots


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Background
2.1. Robot Self-Assessment
2.2. Action Selection with Human Interactions
2.3. Task and Performance Dialogues
H: Describe how to dance.
R: To dance, I raise my arms, I lower my arms, I look left, I look right, I look forward, I raise my arms, and I lower my arms.
H: What is the probability that you can dance?
R: The probability that I can dance is 0.9.
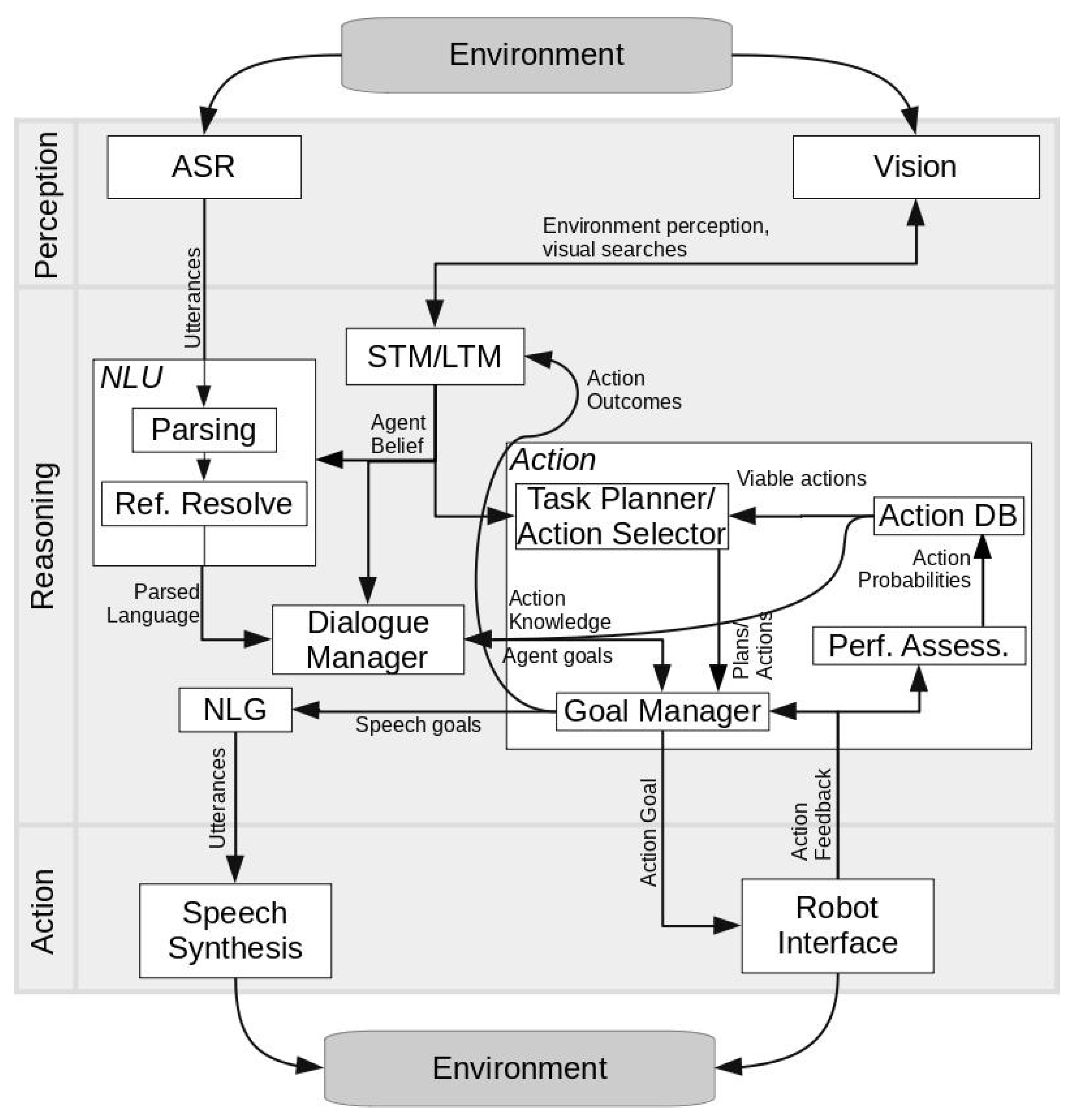
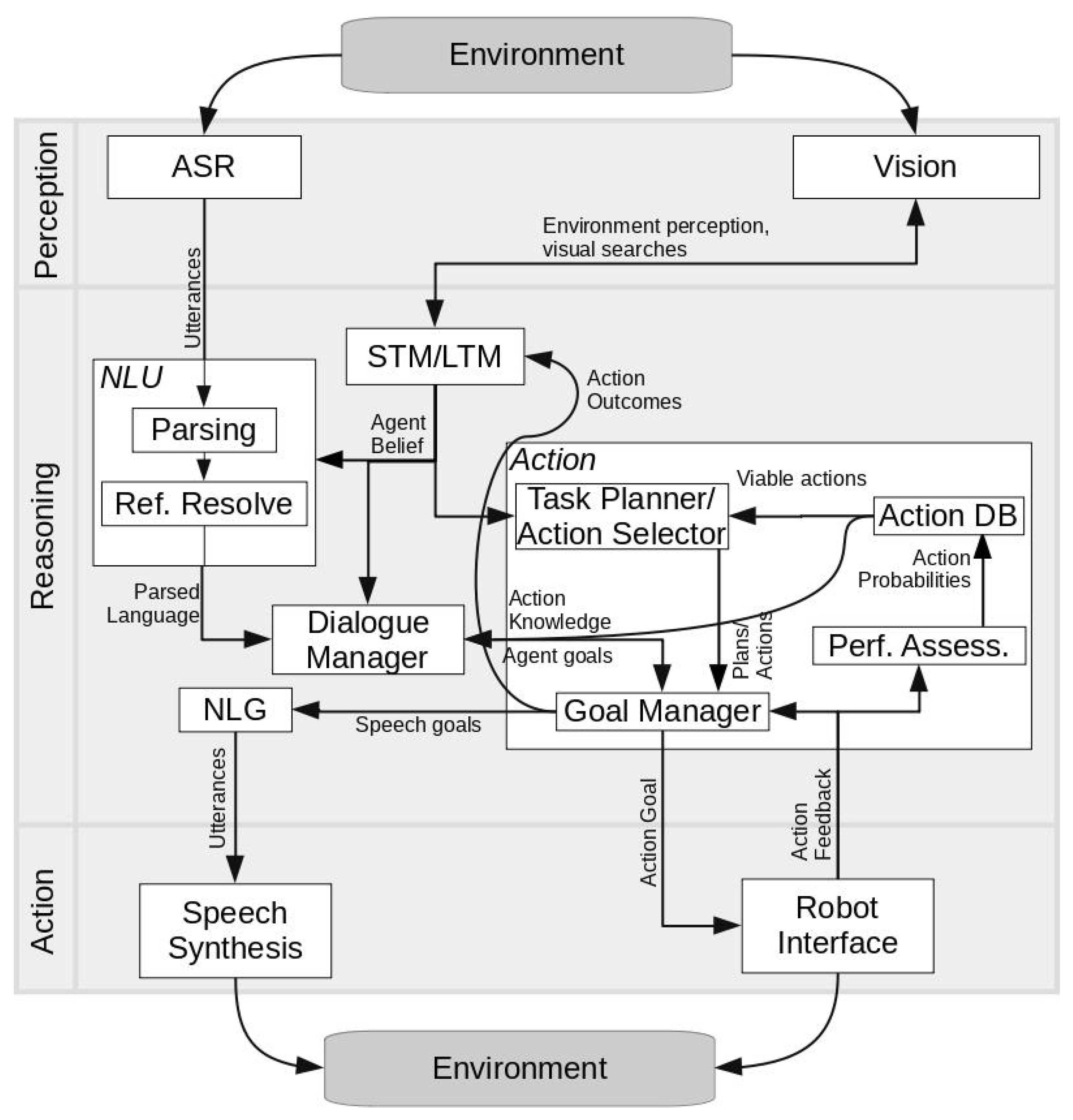
3. Technical Approach
3.1. Environment and Tasks
3.2. Sensing
3.3. Reasoning and Goal Management
3.4. Self-Assessments and Performance Analysis
3.5. A Problem-Solving Example
H: What is the probability that you can fetch the gearbox top?
R: The probability is 0.
H: Pick up the caddy.
R: I don’t think I can pick up, but I can scoop the caddy. [The robot scoops the caddy.]
4. Case Studies
4.1. Communicating the Current Context
H: Go to pose ‘Prepare’. [The robot arm moves over its head.]
H: Approach the caddy. [The robot drives towards the caddy.]
H: What is the probability that you can fetch the gearbox top?
R: The probability is 0.96.
H: What is the probability that you can approach the screw?
R: The probability is 1.0.
H: Go to pose ‘Prepare’. [The robot does not move.]
H: Grab the caddy. [The robot does not move.]
H: What is the probability that you can fetch the gearbox top?
R: The probability is 0.0.
4.2. Optimizing for Success
H: What is the probability that you can fetch the large gear?
R: The probability is 0.77.
H: What is the probability that you can fetch the small gear?
R: The probability is 0.83.
H: Pick a gear.
R: OK. [The robot grabs the small gear.]
4.3. Identifying Implications of Failure
H: What is the probability that you can approach the small gear?
R: The probability is 1.0.
H: What is the probability that you can grab the gearbox top?
R: The probability is 0.99.
H: Approach the caddy. [The robot approaches the caddy.]
H: Fetch the screw.
R: I cannot fetch the screw because grasping does not grasp.
H: What is the probability that you can approach the small gear?
R: The probability is 1.0.
H: What is the probability that you can grab the gearbox top?
R: The probability is 0.0.
4.4. Context-Dependent Action Outcomes
H: Grab the gearbox top. [The robot grabs the gearbox top.]
H: Grab the caddy. [The robot fails to grab the caddy.]
R: I cannot grab the caddy because ‘grasping’ does not grasp.
H: Pick a gear. [The robot grabs the larger of the two gears.]
5. User Study
5.1. Methods
R: OK. [The robot fails to grab the caddy.]
R: OK. [The robot fails to grab the caddy.]
R: I cannot pick up the caddy.
R: OK. [The robot fails to grab the caddy.]
R: I cannot pick up the caddy because my gripper is jammed.
R: I don’t think I can pick up.
H: Scoop the caddy.
R: OK. [The robot scoops the caddy.]
R: I don’t think I can pick up, but I can scoop the caddy. [The robot scoops the caddy.]
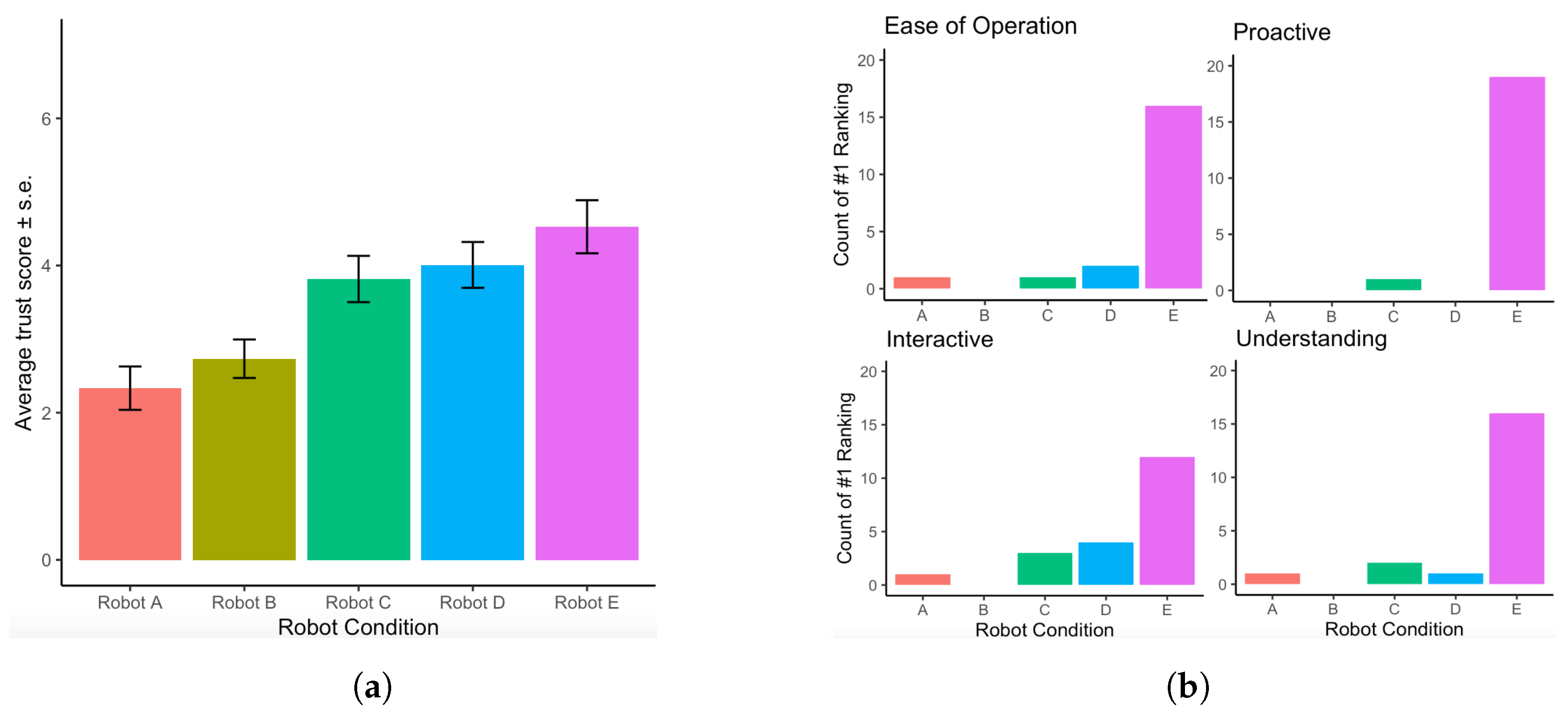
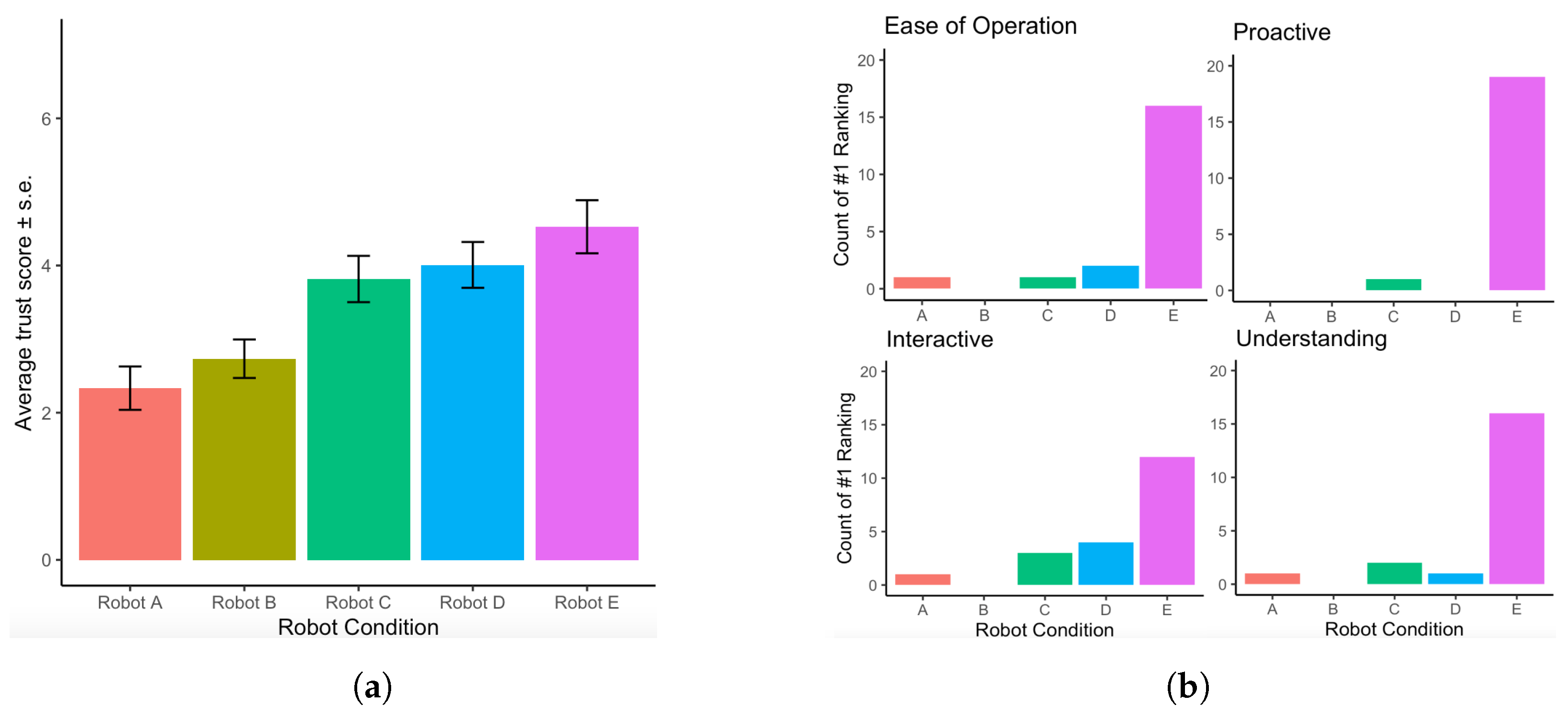
5.2. Results
6. Discussion and Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Valsiner, J.; Van der Veer, R. The Social Mind: Construction of the Idea; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Pezzulo, G.; Dindo, H. What should I do next? Using shared representations to solve interaction problems. Exp. Brain Res. 2011, 211, 613–630. [Google Scholar] [CrossRef] [PubMed]
- Cantrell, R.; Schermerhorn, P.; Scheutz, M. Learning actions from human-robot dialogues. In Proceedings of the 2011 RO-MAN, Atlanta, GA, USA, 31 July–3 August 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 125–130. [Google Scholar]
- Scheutz, M.; Schermerhorn, P.; Kramer, J.; Anderson, D.C. First steps toward natural human-like hri. Auton. Robot. 2006, 22, 411–423. [Google Scholar] [CrossRef]
- Huffman, S.B.; Laird, J.E. Flexibly instructable agents. J. Artif. Intell. Res. 1995, 3, 271–324. [Google Scholar] [CrossRef]
- Frasca, T.M.; Scheutz, M. A framework for robot self-assessment of expected task performance. IEEE Robot. Autom. Lett. 2022, 7, 12523–12530. [Google Scholar] [CrossRef]
- Majji, M.; Rai, R. Autonomous task assignment of multiple operators for human robot interaction. In Proceedings of the 2013 American Control Conference, Washington, DC, USA, 17–19 June 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 6454–6459. [Google Scholar]
- Xu, Y.; Dai, T.; Sycara, K.; Lewis, M. Service level differentiation in multi-robots control. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 2224–2230. [Google Scholar]
- Srivastava, V.; Surana, A.; Bullo, F. Adaptive attention allocation in human-robot systems. In Proceedings of the 2012 American Control Conference (ACC), Montreal, QC, Canada, 27-29 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 2767–2774. [Google Scholar]
- Chien, S.Y.; Lewis, M.; Mehrotra, S.; Brooks, N.; Sycara, K. Scheduling operator attention for multi-robot control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 473–479. [Google Scholar]
- Shi, H.; Xu, L.; Zhang, L.; Pan, W.; Xu, G. Research on self-adaptive decision-making mechanism for competition strategies in robot soccer. Front. Comput. Sci. 2015, 9, 485–494. [Google Scholar] [CrossRef]
- Dai, T.; Sycara, K.; Lewis, M. A game theoretic queueing approach to self-assessment in human-robot interaction systems. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 58–63. [Google Scholar]
- Lewis, M. Human interaction with multiple remote robots. Rev. Hum. Factors Ergon. 2013, 9, 131–174. [Google Scholar] [CrossRef]
- Ardón, P.; Pairet, E.; Petillot, Y.; Petrick, R.P.; Ramamoorthy, S.; Lohan, K.S. Self-assessment of grasp affordance transfer. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; IEEE: Piscataway, NJ, USA, 2020; pp. 9385–9392. [Google Scholar]
- Ardón, P.; Cabrera, M.E.; Pairet, E.; Petrick, R.P.; Ramamoorthy, S.; Lohan, K.S.; Cakmak, M. Affordance-aware handovers with human arm mobility constraints. IEEE Robot. Autom. Lett. 2021, 6, 3136–3143. [Google Scholar] [CrossRef]
- Chen, F.; Sekiyama, K.; Huang, J.; Sun, B.; Sasaki, H.; Fukuda, T. An assembly strategy scheduling method for human and robot coordinated cell manufacturing. Int. J. Intell. Comput. Cybern. 2011, 4, 487–510. [Google Scholar]
- Conlon, N.; Szafir, D.; Ahmed, N.R. Investigating the Effects of Robot Proficiency Self-Assessment on Trust and Performance. arXiv 2022, arXiv:2203.10407. [Google Scholar]
- Lefort, M.; Gepperth, A. Active learning of local predictable representations with artificial curiosity. In Proceedings of the 2015 Joint IEEE International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), Providence, RI, USA, 13–16 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 228–233. [Google Scholar]
- Shi, H.; Lin, Z.; Zhang, S.; Li, X.; Hwang, K.S. An adaptive decision-making method with fuzzy Bayesian reinforcement learning for robot soccer. Inf. Sci. 2018, 436, 268–281. [Google Scholar]
- Jauffret, A.; Grand, C.; Cuperlier, N.; Gaussier, P.; Tarroux, P. How can a robot evaluate its own behavior? A neural model for self-assessment. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–8. [Google Scholar]
- Alami, R.; Chatila, R.; Clodic, A.; Fleury, S.; Herrb, M.; Montreuil, V.; Sisbot, E.A. Towards human-aware cognitive robots. In Proceedings of the Fifth International Cognitive Robotics Workshop (the AAAI-06 Workshop on Cognitive Robotics), Boston, MA, USA, 16–17 July 2006. [Google Scholar]
- Alami, R.; Clodic, A.; Montreuil, V.; Sisbot, E.A.; Chatila, R. Toward Human-Aware Robot Task Planning. In Proceedings of the AAAI Spring Symposium: To Boldly Go Where No Human-Robot Team Has Gone Before, Stanford, CA, USA, 27–29 March 2006; pp. 39–46. [Google Scholar]
- Kwon, W.Y.; Suh, I.H. Planning of proactive behaviors for human–robot cooperative tasks under uncertainty. Knowl.-Based Syst. 2014, 72, 81–95. [Google Scholar]
- Koppula, H.S.; Jain, A.; Saxena, A. Anticipatory planning for human-robot teams. In Experimental Robotics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 453–470. [Google Scholar]
- Buisan, G.; Sarthou, G.; Alami, R. Human aware task planning using verbal communication feasibility and costs. In Proceedings of the International Conference on Social Robotics, Golden, CO, USA, 14–18 November 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 554–565. [Google Scholar]
- Liu, C.; Hamrick, J.B.; Fisac, J.F.; Dragan, A.D.; Hedrick, J.K.; Sastry, S.S.; Griffiths, T.L. Goal Inference Improves Objective and Perceived Performance in Human-Robot Collaboration. arXiv 2018, arXiv:1802.0178. [Google Scholar]
- Devin, S.; Clodic, A.; Alami, R. About decisions during human-robot shared plan achievement: Who should act and how? In Proceedings of the International Conference on Social Robotics, Tsukuba, Japan, 22–24 November 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 453–463. [Google Scholar]
- Hoffman, G.; Breazeal, C. Cost-based anticipatory action selection for human–robot fluency. IEEE Trans. Robot. 2007, 23, 952–961. [Google Scholar]
- Hoffman, G.; Breazeal, C. Effects of anticipatory action on human-robot teamwork efficiency, fluency, and perception of team. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction, Arlington, VA, USA, 8–11 March 2007; pp. 1–8. [Google Scholar]
- Kim, Y.; Yoon, W.C. Generating task-oriented interactions of service robots. IEEE Trans. Syst. Man, Cybern. Syst. 2014, 44, 981–994. [Google Scholar] [CrossRef]
- Wolfe, J.A.; Marthi, B.; Russell, S. Combined Task and Motion Planning for Mobile Manipulation. In Proceedings of the 20th International Conference on Automated Planning and Scheduling, ICAPS 2010, Toronto, ON, Canada, 12–16 May 2010. [Google Scholar]
- Foehn, P.; Romero, A.; Scaramuzza, D. Time-optimal planning for quadrotor waypoint flight. Sci. Robot. 2021, 6, 1221. [Google Scholar] [CrossRef]
- Canal, G.; Alenyà, G.; Torras, C. Adapting robot task planning to user preferences: An assistive shoe dressing example. Auton. Robot. 2019, 43, 1343–1356. [Google Scholar] [CrossRef]
- Kulkarni, A.; Zha, Y.; Chakraborti, T.; Vadlamudi, S.G.; Zhang, Y.; Kambhampati, S. Explicable Planning as Minimizing Distance from Expected Behavior. In Proceedings of the AAMAS Conference Proceedings, Montreal, QC, Canada, 13–17 May 2019; pp. 2075–2077. [Google Scholar]
- Forer, S.; Banisetty, S.B.; Yliniemi, L.; Nicolescu, M.; Feil-Seifer, D. Socially-aware navigation using non-linear multi-objective optimization. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–9. [Google Scholar]
- Nissim, R.; Brafman, R.I. Cost-Optimal Planning by Self-Interested Agents. In Proceedings of the Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013; pp. 732–738. [Google Scholar] [CrossRef]
- Lee, C.Y.; Shen, Y.X. Optimal planning of ground grid based on particle swam algorithm. Int. J. Eng. Sci. Technol. (IJEST) 2009, 3, 30–37. [Google Scholar]
- Khandelwal, P.; Yang, F.; Leonetti, M.; Lifschitz, V.; Stone, P. Planning in action language BC while learning action costs for mobile robots. In Proceedings of the Twenty-Fourth International Conference on Automated Planning and Scheduling, Portsmouth, NH, USA, 21–26 June 2014. [Google Scholar]
- Frasca, T.M.; Krause, E.A.; Thielstrom, R.; Scheutz, M. “Can you do this?” Self-Assessment Dialogues with Autonomous Robots Before, During, and After a Mission. arXiv 2020, arXiv:2005.01544. [Google Scholar]
- Norton, A.; Admoni, H.; Crandall, J.; Fitzgerald, T.; Gautam, A.; Goodrich, M.; Saretsky, A.; Scheutz, M.; Simmons, R.; Steinfeld, A.; et al. Metrics for robot proficiency self-assessment and communication of proficiency in human-robot teams. ACM Trans. Hum.-Robot Interact. (THRI) 2022, 11, 20. [Google Scholar]
- Baraglia, J.; Cakmak, M.; Nagai, Y.; Rao, R.P.; Asada, M. Efficient human-robot collaboration: When should a robot take initiative? Int. J. Robot. Res. 2017, 36, 563–579. [Google Scholar]
- Nikolaidis, S.; Kwon, M.; Forlizzi, J.; Srinivasa, S. Planning with verbal communication for human-robot collaboration. ACM Trans. Hum.-Robot Interact. (THRI) 2018, 7, 22. [Google Scholar] [CrossRef]
- St. Clair, A.; Mataric, M. How robot verbal feedback can improve team performance in human-robot task collaborations. In Proceedings of the Tenth Annual ACM/IEEE International Conference on Human-Robot Interaction, Portland, OR, USA, 2–5 March 2015; pp. 213–220. [Google Scholar]
- Unhelkar, V.V.; Li, S.; Shah, J.A. Decision-making for bidirectional communication in sequential human-robot collaborative tasks. In Proceedings of the 2020 15th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Cambridge, UK, 23–26 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 329–341. [Google Scholar]
- Beer, J.M.; Fisk, A.D.; Rogers, W.A. Toward a framework for levels of robot autonomy in human-robot interaction. J. Hum.-Robot Interact. 2014, 3, 74. [Google Scholar] [CrossRef] [PubMed]
- Fong, T.; Thorpe, C.; Baur, C. Collaboration, dialogue, human-robot interaction. In Robotics Research; Springer: Berlin/Heidelberg, Germany, 2003; pp. 255–266. [Google Scholar]
- Langley, P. Explainable agency in human-robot interaction. In Proceedings of the AAAI Fall Symposium Series, Arlington, VA, USA, 17–19 November 2016. [Google Scholar]
- Duffy, B. Robots social embodiment in autonomous mobile robotics. Int. J. Adv. Robot. Syst. 2004, 1, 17. [Google Scholar] [CrossRef]
- Wagner, A.R. Robots that stereotype: Creating and using categories of people for human-robot interaction. J. Hum.-Robot Interact. 2015, 4, 97. [Google Scholar] [CrossRef]
- Kaupp, T.; Makarenko, A.; Durrant-Whyte, H. Human–robot communication for collaborative decision making—A probabilistic approach. Robot. Auton. Syst. 2010, 58, 444–456. [Google Scholar] [CrossRef]
- Fetch Robotics, Inc. FetchIt! Challenge. Available online: https://opensource.fetchrobotics.com/competition (accessed on 1 December 2023).
- Wise, M.; Ferguson, M.; King, D.; Diehr, E.; Dymesich, D. Fetch and freight: Standard platforms for service robot applications. In Proceedings of the Workshop on Autonomous Mobile Service Robots, New York, NY, USA, 11 July 2016. [Google Scholar]
- Scheutz, M.; Williams, T.; Krause, E.; Oosterveld, B.; Sarathy, V.; Frasca, T. An overview of the distributed integrated cognition affect and reflection DIARC architecture. In Cognitive Architectures; Springer: Cham, Switzerland, 2019; pp. 165–193. [Google Scholar]
- Scheutz, M.; Thielstrom, R.; Abrams, M. Transparency through Explanations and Justifications in Human-Robot Task-Based Communications. Int. J.-Hum.-Comput. Interact. 2022, 38, 1739–1752. [Google Scholar] [CrossRef]
- Briggs, G.; Scheutz, M. Multi-modal belief updates in multi-robot human-robot dialogue interaction. In Proceedings of the 2012 Symposium on Linguistic and Cognitive Approaches to Dialogue Agents; University of Birmingham: Birmingham, UK, 2012; Volume 47. [Google Scholar]
- Walker, W.; Lamere, P.; Kwok, P.; Raj, B.; Singh, R.; Gouvea, E.; Wolf, P.; Woelfel, J. Sphinx-4: A Flexible Open Source Framework for Speech Recognition; Sun Microsystems, Inc.: Santa Clara, CA, USA, 2004. [Google Scholar]
- Lamere, P.; Kwok, P.; Gouvea, E.; Raj, B.; Singh, R.; Walker, W.; Warmuth, M.; Wolf, P. The CMU SPHINX-4 speech recognition system. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2003), Hong Kong, China, 6–10 April 2003; Volume 1, pp. 2–5. [Google Scholar]
- Thielstrom, R.; Roque, A.; Chita-Tegmark, M.; Scheutz, M. Generating Explanations of Action Failures in a Cognitive Robotic Architecture. In Proceedings of the 2nd Workshop on Interactive Natural Language Technology for Explainable Artificial Intelligence, Dublin, Ireland, 18 December 2020; pp. 67–72. [Google Scholar]
- Fox, M.; Long, D. PDDL2. 1: An extension to PDDL for expressing temporal planning domains. J. Artif. Intell. Res. 2003, 20, 61–124. [Google Scholar] [CrossRef]
- Thierauf, C.; Thielstrom, R.; Oosterveld, B.; Becker, W.; Scheutz, M. “Do This Instead”—Robots That Adequately Respond to Corrected Instructions; Association for Computing Machinery: New York, NY, USA, 22 September 2023. [Google Scholar] [CrossRef]
- Rossi, A.; Dautenhahn, K.; Koay, K.L.; Walters, M.L. The impact of peoples’ personal dispositions and personalities on their trust of robots in an emergency scenario. Paladyn J. Behav. Robot. 2018, 9, 137–154. [Google Scholar] [CrossRef]
- Lee, J.D.; See, K.A. Trust in automation: Designing for appropriate reliance. Hum. Factors 2004, 46, 50–80. [Google Scholar] [CrossRef]
- Freedy, A.; DeVisser, E.; Weltman, G.; Coeyman, N. Measurement of trust in human-robot collaboration. In Proceedings of the 2007 International Symposium on Collaborative Technologies and Systems, Orlando, FL, USA, 21–25 May 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 106–114. [Google Scholar]
- Lyons, J.B.; Guznov, S.Y. Individual differences in human–machine trust: A multi-study look at the perfect automation schema. Theor. Issues Ergon. Sci. 2019, 20, 440–458. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thierauf, C.; Law, T.; Frasca, T.; Scheutz, M. Toward Competent Robot Apprentices: Enabling Proactive Troubleshooting in Collaborative Robots. Machines 2024, 12, 73. https://doi.org/10.3390/machines12010073
Thierauf C, Law T, Frasca T, Scheutz M. Toward Competent Robot Apprentices: Enabling Proactive Troubleshooting in Collaborative Robots. Machines. 2024; 12(1):73. https://doi.org/10.3390/machines12010073
Chicago/Turabian StyleThierauf, Christopher, Theresa Law, Tyler Frasca, and Matthias Scheutz. 2024. "Toward Competent Robot Apprentices: Enabling Proactive Troubleshooting in Collaborative Robots" Machines 12, no. 1: 73. https://doi.org/10.3390/machines12010073
APA StyleThierauf, C., Law, T., Frasca, T., & Scheutz, M. (2024). Toward Competent Robot Apprentices: Enabling Proactive Troubleshooting in Collaborative Robots. Machines, 12(1), 73. https://doi.org/10.3390/machines12010073