
A Deep Learning Approach to Classify and Detect Defects in the Components Manufactured by Laser Directed Energy Deposition Process


Abstract
:1. Introduction
1.1. Imaging Defects
1.2. Classification and Detection of Defects
- To use laser-directed energy deposition process to manufacture horizontal wall structures, vertical wall structures and cuboid structures using different combinations of process parameters followed by cross-sectioning of the manufactured structures to capture images for a dataset.
- To prepare a dataset of horizontal wall structure, vertical wall structure and cuboid structure with three defective classes such as rough textures, flash formation, and voids, and one non-defective class.
- Identify a deep learning algorithm capable of classifying defective and non-defective components and detecting different defects in the components manufactured by the laser-directed energy deposition process.
- Investigate and compare the performance parameters of various deep learning models such as VGG16, AlexNet, GoogLeNet and ResNet used for classifying and detecting defects.
2. Materials and Methods
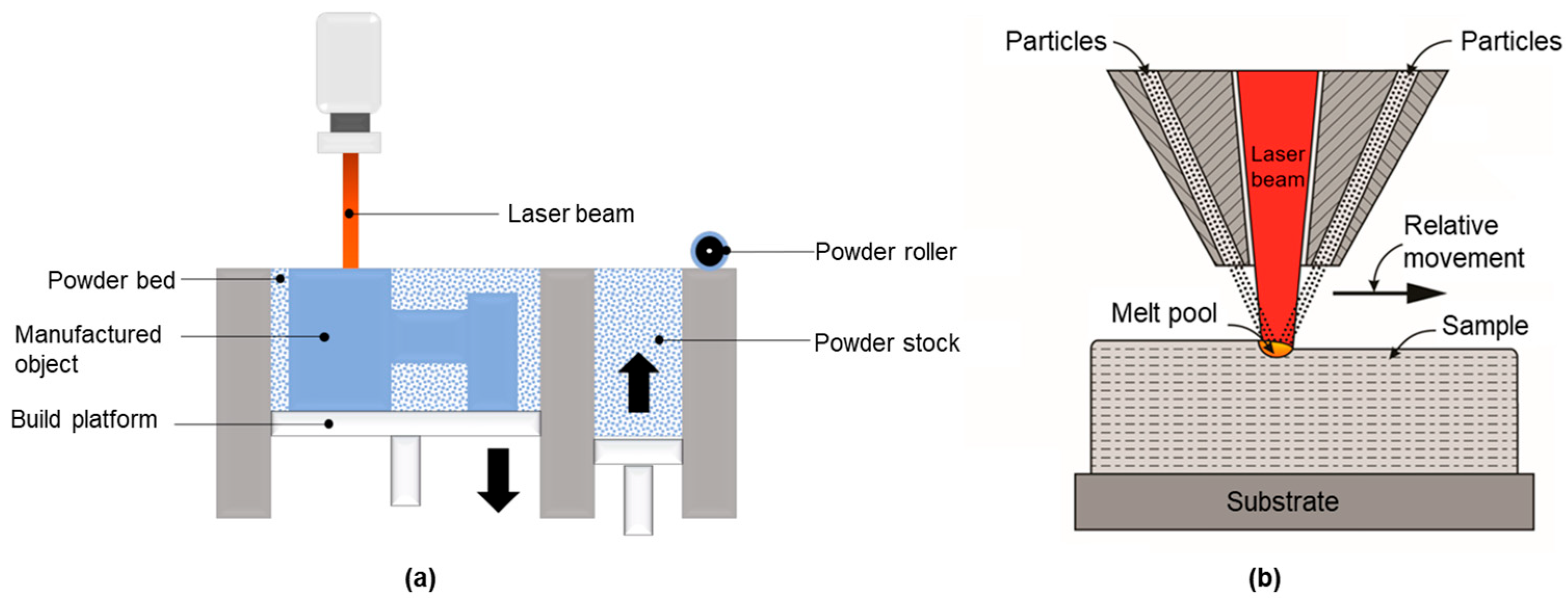
2.1. Experimental and Acquisition of Image
2.2. Dataset
- Conversion RGB to grayscale
- Gaussian filter applied to enhance image pixel intensity.
- Resize the image
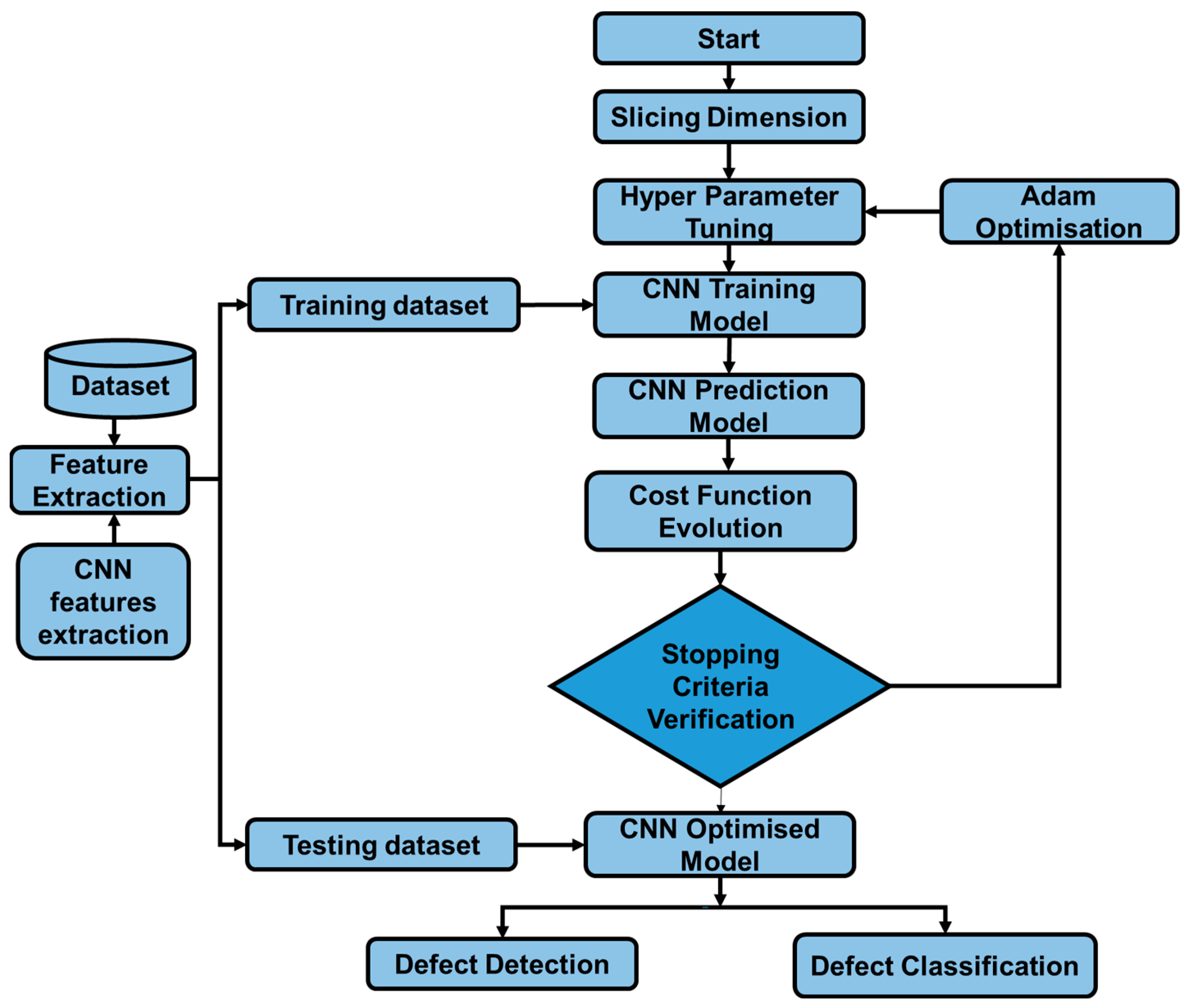
2.3. Deep Learning Model
- Computational analysis of images within the dataset
- Defect classification and detection model.
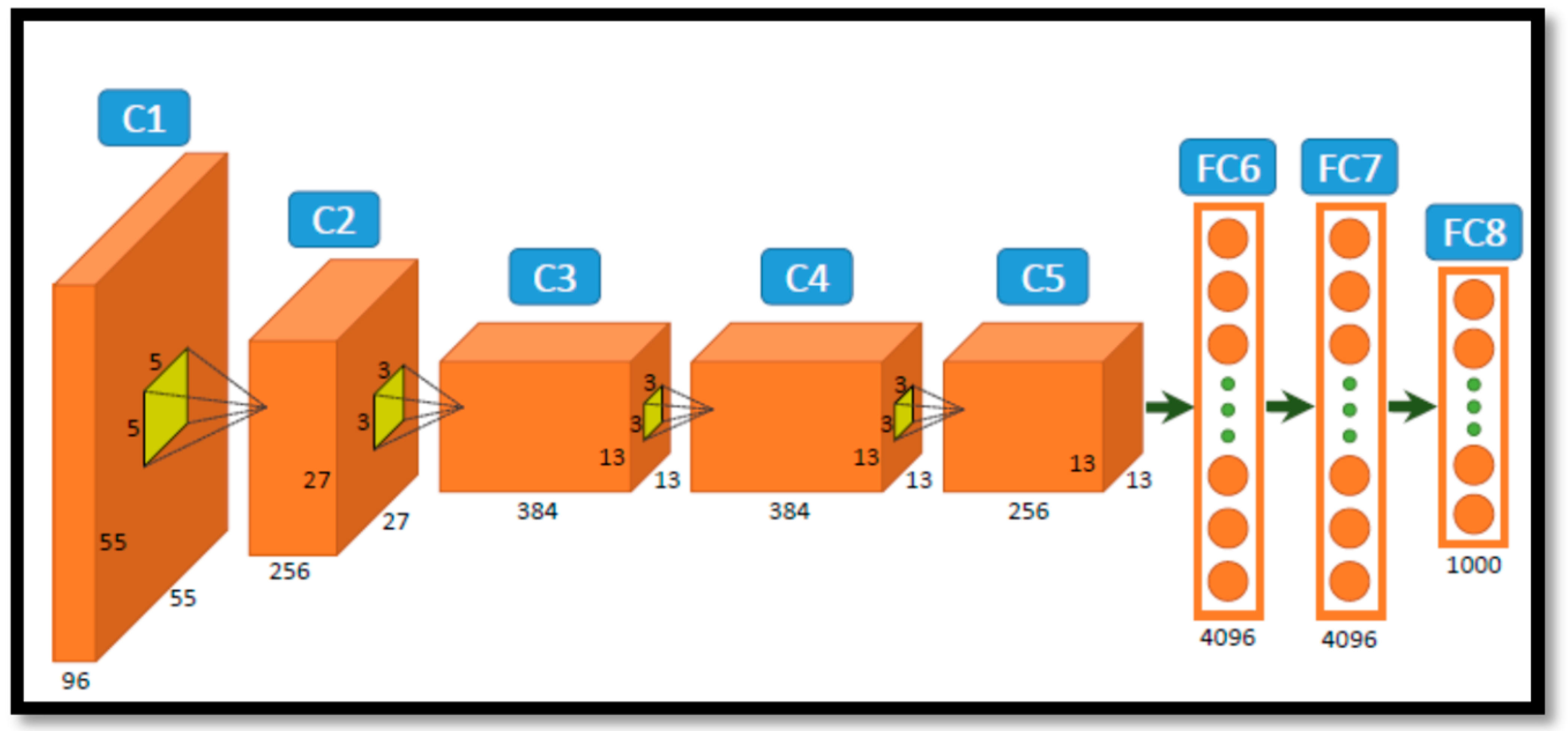
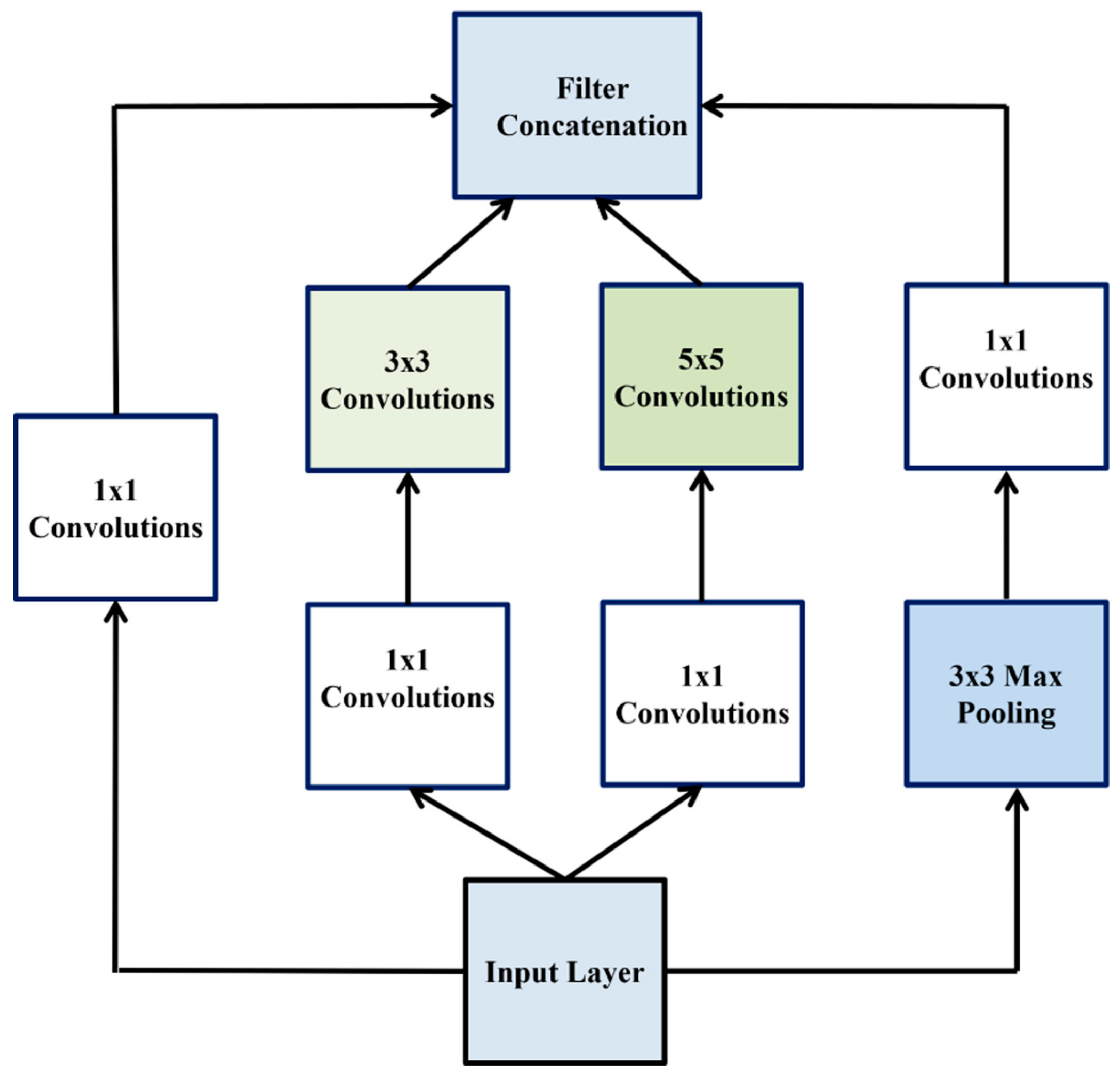
2.3.1. Convolutional Neural Network and Architectures Used in This Work
2.3.2. Transfer Learning
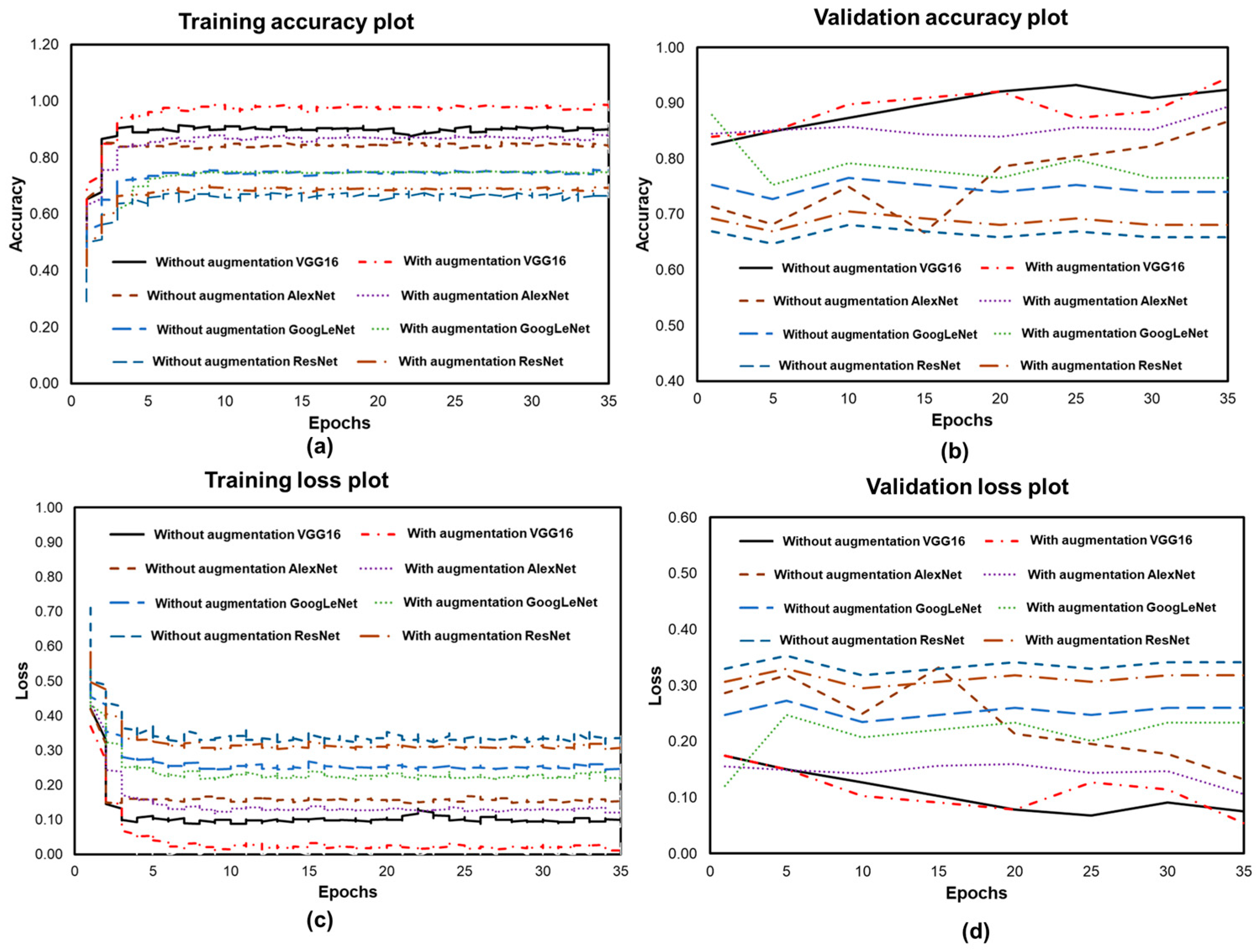
3. Results and Discussion
3.1. Defects Classification
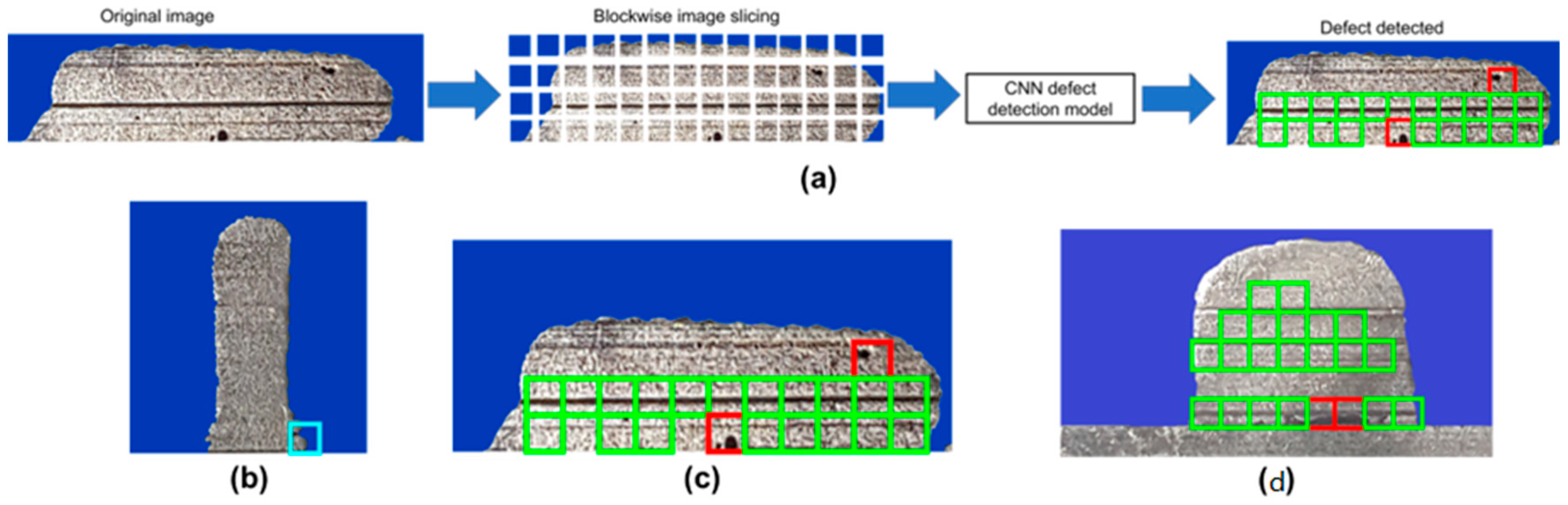
3.2. Defect Detection
4. Conclusions
- The proposed robust methodology for deep learning is highly reliable for automating the defect detection process and classifying defects such as void, flash formation and rough texture in laser additive manufactured components.
- The different deep learning models such as VGG16, AlexNet, GoogLeNet and ResNet used to classify defects, showed good applicability for the additive manufactured horizontal wall structure, vertical wall structure and cuboid structure.
- The VGG16 CNN architecture achieved the best results and outperformed the results of the other CNN architectures. With augmentation, the VGG16 approach obtained a test accuracy of 0.947, as well as a precision of 0.890, a recall of 0.893, and an F1-Score of 0.895.
- The VGG16 model gave a good F1-score (F1-score 0.895) compared to other CNN models, this indicates that a VGG16 gave an effective and better classification of defects using images of components manufactured using the laser additive process.
- Although the proposed deep learning approach detected defects more accurately, the method requires further tuning considering complex geometries and other categories of defects.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sames, W.J.; List, F.A.; Pannala, S.; Dehoff, R.R.; Babu, S.S. The metallurgy and processing science of metal additive manufacturing. Int. Mater. Rev. 2016, 61, 315–360. [Google Scholar] [CrossRef]
- Gong, H.; Rafi, K.; Gu, H.; Janaki Ram, G.; Starr, T.; Stucker, B. Influence of defects on mechanical properties of Ti-6Al-4V components produced by selective laser melting and electron beam melting. Mater. Des. 2015, 86, 545–554. [Google Scholar] [CrossRef]
- Nikam, S.H.; Jain, N.K. Laser-Based Repair of Damaged Dies, Molds, and Gears. In Advanced Manufacturing Technologies: Materials Forming, Machining and Tribology, 1st ed.; Gupta, K., Ed.; Springer International Publishing: Cham, Switzerland, 2017; pp. 137–159. [Google Scholar] [CrossRef]
- Liu, Q.; Elambasseril, J.; Sun, S.; Leary, M.; Brandt, M.; Sharp, P. The effect of manufacturing defects on the fatigue behaviour of Ti-6Al-4V specimens fabricated using selective laser melting. Adv. Mater. Res. 2014, 891–892, 1519–1524. [Google Scholar] [CrossRef]
- Pal, R.; Basak, A. Linking Powder Properties, Printing Parameters, Post-Processing Methods, and Fatigue Properties in Additive Manufacturing of AlSi10Mg. Alloys 2022, 1, 149–179. [Google Scholar] [CrossRef]
- Arias-González, F.; Rodríguez-Contreras, A.; Punset, M.; Manero, J.M.; Barro, Ó.; Fernández-Arias, M.; Lusquiños, F.; Gil, F.J.; Pou, J. In-Situ Laser Directed Energy Deposition of Biomedical Ti-Nb and Ti-Zr-Nb Alloys from Elemental Powders. Metals 2021, 11, 1205. [Google Scholar] [CrossRef]
- Tapia, G.; Elwany, A. A Review on Process Monitoring and Control in Metal-Based Additive Manufacturing. J. Manuf. Sci. Eng. Trans. ASME 2014, 136, 060801. [Google Scholar] [CrossRef]
- Harkin, R.; Wu, H.; Nikam, S.; Yin, S.; Lupoi, R.; Walls, P.; McKay, W.; McFadden, S. Evaluation of the role of hatch-spacing variation in a lack-of-fusion defect prediction criterion for laser-based powder bed fusion processes. Int. J. Adv. Manuf. Technol. 2023, 126, 659–673. [Google Scholar] [CrossRef]
- Khanzadeh, M.; Chowdhury, S.; Tschopp, M.A.; Doude, H.R.; Marufuzzaman, M.; Bian, L. In-Situ monitoring of melt pool images for porosity prediction in directed energy deposition processes. IISE Trans. 2018, 51, 437–455. [Google Scholar] [CrossRef]
- Spierings, A.; Schneider, M.; Eggenberger, R. Comparison of density measurement techniques for additive manufactured metallic parts. Rapid Prototyp. J. 2011, 17, 380–386. [Google Scholar] [CrossRef]
- Wits, W.; Carmignato, S.; Zanini, F.; Vaneker, T. Porosity testing methods for the quality assessment of selective laser melted parts. CIRP Ann. Manuf. Technol. 2016, 65, 201–204. [Google Scholar] [CrossRef]
- Kim, M.J.; Saldana, C. Thin wall deposition of IN625 using directed energy deposition. J. Manuf. Process. 2020, 56, 1366–1373. [Google Scholar] [CrossRef]
- Kersten, S.; Praniewicz, M.; Kurfess, T.; Saldana, C. Build Orientation Effects on Mechanical Properties of 316SS Components Produced by Directed Energy Deposition. Procedia Manuf. 2020, 48, 730–736. [Google Scholar] [CrossRef]
- Zheng, B.; Haley, J.C.; Yang, N.; Yee, J.; Terrassa, K.W.; Zhou, Y.; Lavernia, E.J.; Schoenung, J.M. On the evolution of microstructure and defect control in 316L SS components fabricated via directed energy deposition. Mater. Sci. Eng. A 2019, 764, 138243. [Google Scholar] [CrossRef]
- Saddoud, R.; Sergeeva-Chollet, N.; Darmon, M. Eddy Current Sensors Optimization for Defect Detection in Parts Fabricated by Laser Powder Bed Fusion. Sensors 2023, 23, 4336. [Google Scholar] [CrossRef]
- Geľatko, M.; Hatala, M.; Botko, F.; Vandžura, R.; Hajnyš, J. Eddy Current Testing of Artificial Defects in 316L Stainless Steel Samples Made by Additive Manufacturing Technology. Materials 2022, 15, 6783. [Google Scholar] [CrossRef] [PubMed]
- Kobryn, P.A.; Moore, E.H.; Semiatin, S.L. The effect of laser power and traverse speed on microstructure, porosity, and build height in laser-deposited Ti-6Al-4V. Scr. Mater. 2000, 43, 299–305. [Google Scholar] [CrossRef]
- Galarraga, H.; Lados, D.A.; Dehoff, R.R.; Kirka, M.M.; Nandwana, P. Effects of the microstructure and porosity on properties of Ti-6Al-4V ELI alloy fabricated by electron beam melting (EBM). Addit. Manuf. 2015, 10, 47–57. [Google Scholar] [CrossRef]
- Aminzadeh, M.; Kurfess, T. Layerwise Automated Visual Inspection in Laser Powder-Bed Additive Manufacturing. In Proceedings of the ASME 2015 International Manufacturing Science and Engineering Conference, Charlotte, NC, USA, 8–12 June 2015. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Guo, W.; Tian, Q.; Guo, S.; Guo, Y. A physics-driven deep learning model for process-porosity causal relationship and porosity prediction with interpretability in laser metal deposition. CIRP Ann. 2020, 69, 205–208. [Google Scholar] [CrossRef]
- Cui, W.; Zhang, Y.; Zhang, X.; Li, L.; Liou, F. Metal Additive Manufacturing Parts Inspection Using Convolutional Neural Network. Appl. Sci. 2020, 10, 545. [Google Scholar] [CrossRef]
- Garcıa-Moreno, A.-I. Automatic quantification of porosity using an intelligent classifier. Int. J. Adv. Manuf. Technol. 2019, 105, 1883–1899. [Google Scholar] [CrossRef]
- Zhang, Y.; Soon, Y.D.; Fuh, J.Y.H.; Zhu, K. Powder-bed fusion process monitoring by machine vision with hybrid convolutional neural networks. IEEE Trans. Ind. Inform. 2020, 16, 5769–5779. [Google Scholar] [CrossRef]
- Patil, D.B.; Nigam, A.; Mohapatra, S. Image processing approach to automate feature measuring and process parameter optimizing of laser additive manufacturing process. J. Manuf. Process. 2021, 69, 630–647. [Google Scholar] [CrossRef]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Patil, D.B.; Nigam, A.; Mohapatra, S. Automation of geometric feature computation through image processing approach for single-layer laser deposition process. Int. J. Comput. Integr. Manuf. 2020, 33, 895–910. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Westphal, E.; Seitz, H. A machine learning method for defect detection and visualization in selective laser sintering based on convolutional neural networks. Addit. Manuf. 2021, 41, 101965. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Shin, H.; Roth, H.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks, Advances in Neural Information Processing Systems. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Samir, S.; Emary, E.; El-Sayed, K.; Onsi, H. Optimization of a pre-trained AlexNet model for detecting and localizing image forgeries. Information 2020, 11, 275. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Khan, S.U.; Islam, N.; Jan, Z.; Din, I.U.; Joel, J.P.; Rodrigues, C. A novel deep learning based framework for the detection and classification of breast cancer using transfer learning. Pattern Recognit. Lett. 2019, 125, 1–6. [Google Scholar] [CrossRef]
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K.Q. Deep Networks with Stochastic Depth. In Computer Vision—ECCV 2016, 1st ed.; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9908, pp. 646–661. [Google Scholar] [CrossRef]
- Pandiyan, V.; Drissi-Daoudi, R.; Shevchik, S.; Masinelli, G.; Le-Quang, T.; Logé, R.; Wasmer, K. Deep transfer learning of additive manufacturing mechanisms across materials in metal-based laser powder bed fusion process. J. Mater. Process. Technol. 2022, 303, 117531. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tsiakmaki, M.; Kostopoulos, G.; Kotsiantis, S.; Ragos, O. Transfer learning from deep neural networks for predicting student performance. Appl. Sci. 2020, 10, 2145. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Laser power | 800 W to 1100 W |
| Powder feed rate | 5 g/min to 10 g/min |
| Heat Source travel rate | 500 mm/min to 700 mm/min |
| Laser spot diameter | 2 mm |
| Hatch spacing | 1 mm |
| Slicing thickness | 1 mm |
| Scan pattern | Zigzag |
| Cost Function | Learning Rate | Optimizer | No. Epochs | Batch Size | Learning Rate Decay | Early Stopping |
|---|---|---|---|---|---|---|
| Binary cross-entropy | 0.0001 | Adam β1 = 0.85 β2 = 0.988 | 35 | 48 | Patience = 8 | Patience = 32 |
| Without Augmentation | With Augmentation | |||||||
|---|---|---|---|---|---|---|---|---|
| Void | Flash Formation | Rough Texture | Non Defective | Void | Flash Formation | Rough Texture | Non Defective | |
| VGG-16 | 190 | 16 | 12 | 7 | 203 | 7 | 6 | 9 |
| 14 | 188 | 8 | 15 | 3 | 210 | 5 | 7 | |
| 13 | 7 | 195 | 10 | 14 | 7 | 192 | 12 | |
| 17 | 15 | 8 | 185 | 11 | 8 | 11 | 195 | |
| AlexNet | 182 | 18 | 14 | 11 | 189 | 15 | 13 | 8 |
| 24 | 154 | 19 | 28 | 22 | 180 | 10 | 13 | |
| 18 | 16 | 176 | 15 | 12 | 15 | 186 | 12 | |
| 22 | 25 | 12 | 166 | 25 | 27 | 17 | 156 | |
| GoogLeNet | 193 | 15 | 8 | 9 | 195 | 13 | 9 | 8 |
| 22 | 163 | 14 | 26 | 8 | 193 | 11 | 13 | |
| 18 | 21 | 167 | 19 | 13 | 9 | 189 | 14 | |
| 19 | 25 | 10 | 171 | 8 | 13 | 15 | 189 | |
| ResNet | 128 | 38 | 30 | 29 | 159 | 19 | 23 | 24 |
| 30 | 142 | 21 | 32 | 18 | 173 | 21 | 13 | |
| 27 | 30 | 136 | 32 | 10 | 13 | 186 | 16 | |
| 32 | 29 | 32 | 132 | 12 | 18 | 16 | 179 | |
| Settings | Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Without augmentation | VGG16 | 0.924 | 0.843 | 0.844 | 0.849 |
| Alex net | 0.876 | 0.760 | 0.747 | 0.746 | |
| GoogLeNet | 0.882 | 0.783 | 0.791 | 0.768 | |
| ResNet | 0.801 | 0.604 | 0.600 | 0.596 | |
| With augmentation | VGG16 | 0.947 | 0.890 | 0.893 | 0.895 |
| Alex net | 0.899 | 0.792 | 0.767 | 0.789 | |
| GoogLeNet | 0.928 | 0.857 | 0.853 | 0.855 | |
| ResNet | 0.886 | 0.778 | 0.767 | 0.770 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patil, D.B.; Nigam, A.; Mohapatra, S.; Nikam, S. A Deep Learning Approach to Classify and Detect Defects in the Components Manufactured by Laser Directed Energy Deposition Process. Machines 2023, 11, 854. https://doi.org/10.3390/machines11090854
Patil DB, Nigam A, Mohapatra S, Nikam S. A Deep Learning Approach to Classify and Detect Defects in the Components Manufactured by Laser Directed Energy Deposition Process. Machines. 2023; 11(9):854. https://doi.org/10.3390/machines11090854
Chicago/Turabian StylePatil, Deepika B., Akriti Nigam, Subrajeet Mohapatra, and Sagar Nikam. 2023. "A Deep Learning Approach to Classify and Detect Defects in the Components Manufactured by Laser Directed Energy Deposition Process" Machines 11, no. 9: 854. https://doi.org/10.3390/machines11090854
APA StylePatil, D. B., Nigam, A., Mohapatra, S., & Nikam, S. (2023). A Deep Learning Approach to Classify and Detect Defects in the Components Manufactured by Laser Directed Energy Deposition Process. Machines, 11(9), 854. https://doi.org/10.3390/machines11090854