




Development and Application of Knowledge Graphs for the Injection Molding Process
 , and
, and
Abstract
:1. Introduction
2. Background Knowledge
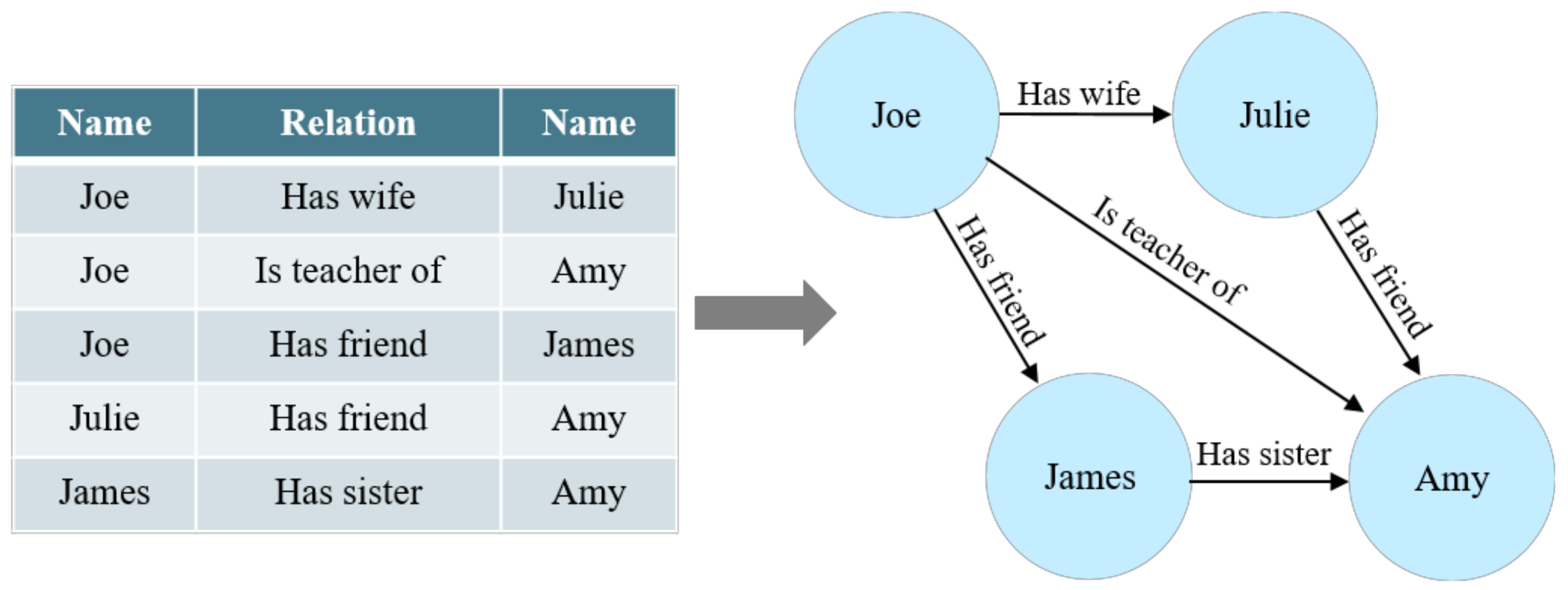
2.1. Knowledge Graph
2.2. Database
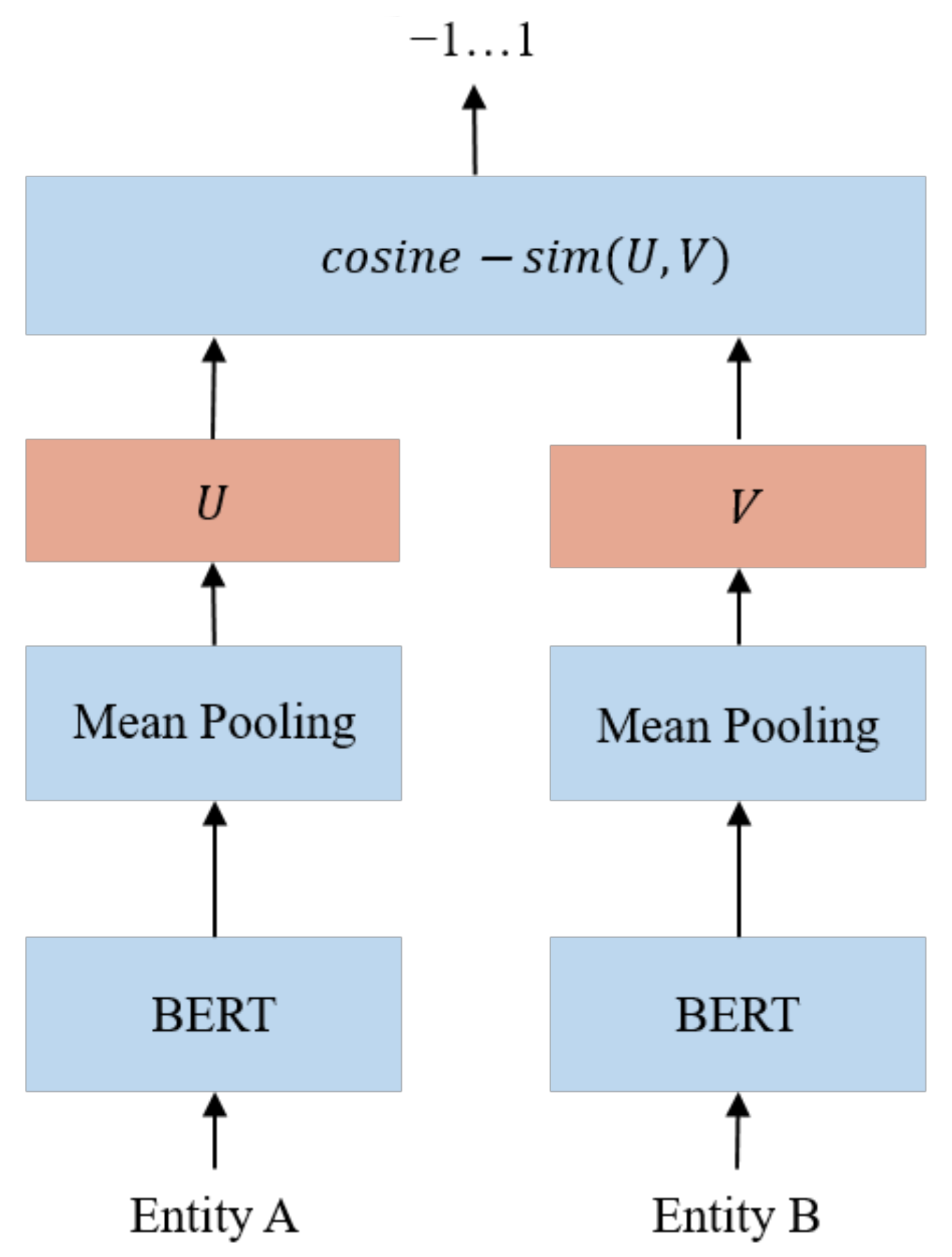
2.3. BERT
3. Methodology
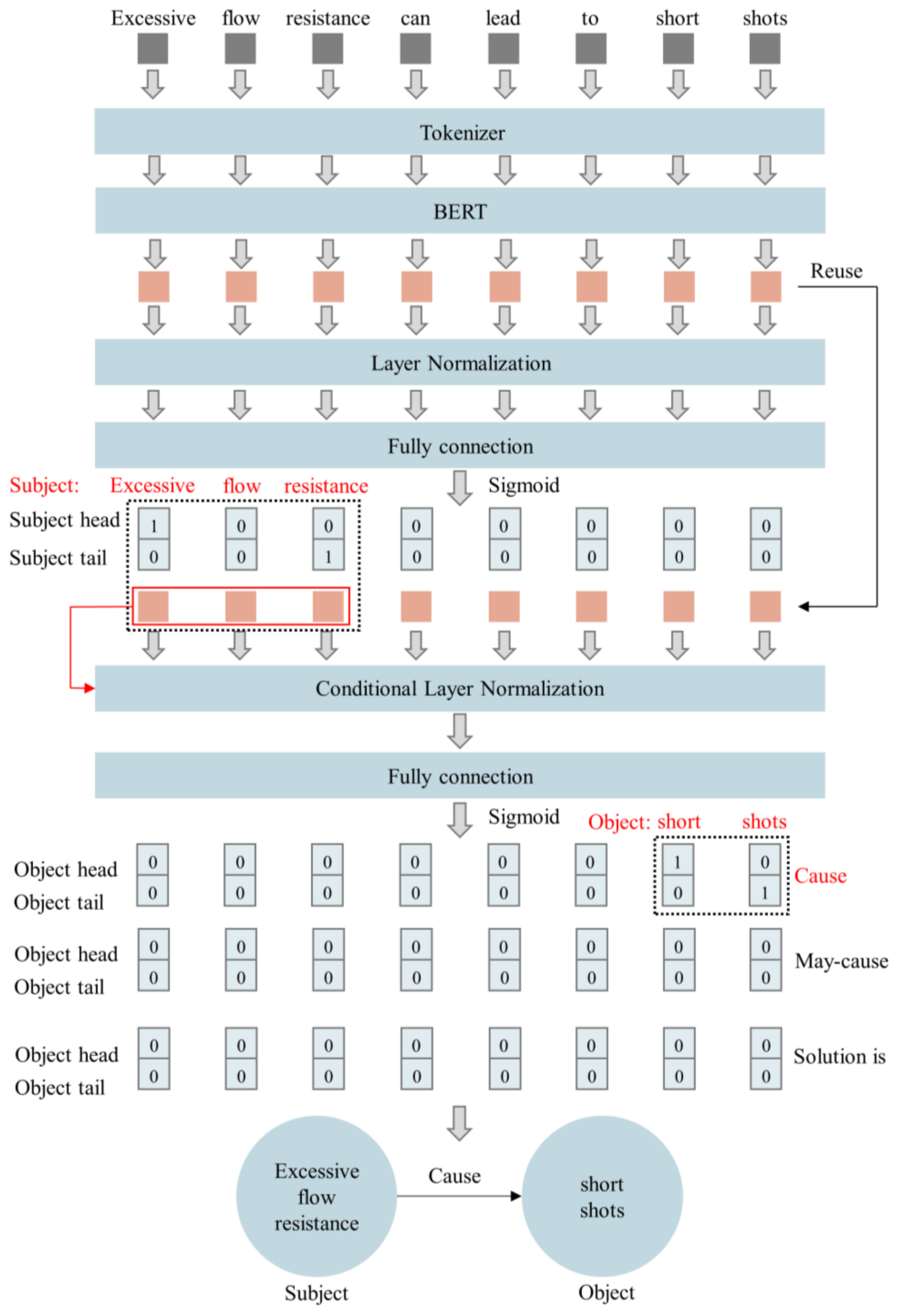
3.1. Knowledge Extraction
3.2. Entity Alignment
3.3. Entity Classification
4. Discussion
4.1. Knowledge Extraction Results
4.2. Entity Alignment Results
4.3. Entity Classification Results
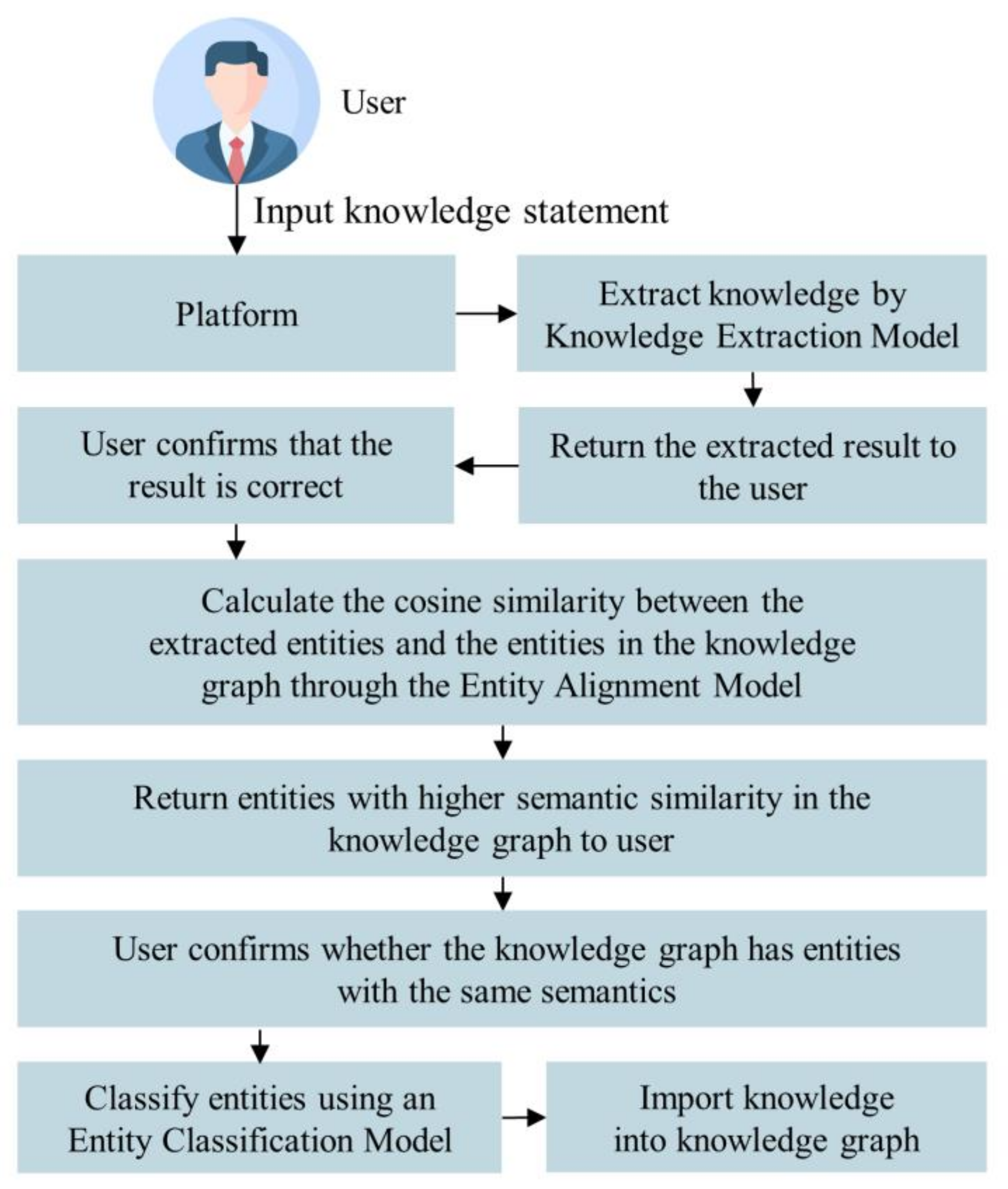
4.4. Practical Application
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jong, W.R.; Wu, C.H.; Li, M.Y. Web-based navigating system for conceptual mould design with knowledge management. Int. J. Prod. Res. 2010, 49, 553–567. [Google Scholar] [CrossRef]
- Jong, W.R.; Ting, Y.H.; Li, T.C.; Chen, K.Y. An integrated application for historical knowledge management with mould design navigating process. Int. J. Prod. Res. 2012, 51, 3191–3205. [Google Scholar] [CrossRef]
- Khosravani, M.R.; Nasiri, S.; Weinberg, K. Application of case-based reasoning in a fault detection system on production of drippers. Appl. Soft Comput. 2018, 75, 227–232. [Google Scholar] [CrossRef]
- Mikos, W.L.; Ferreira, J.C.E.; Gomes, F.G.C. A distributed system for rapid determination of nonconformance causes and solutions for the thermoplastic injection molding process: A Case-Based Reasoning Agents approach. In Proceedings of the IEEE International Conference on Automation Science and Engineering, Trieste, Italy, 24–27 August 2011. [Google Scholar]
- Sebastian, R.B.; Irlan, G.G.; Priyanka, N.; Maria-Esther, V.; Maria, M. A Knowledge Graph for Industry 4.0. Semant. Web 2020, 1212, 465–480. [Google Scholar]
- Chi, Y.; Yu, C.; Qi, X.; Xu, H. Knowledge Management in Healthcare Sustainability: A Smart Healthy Diet Assistant in Traditional Chinese Medicine Culture. Sustainability 2018, 10, 4197. [Google Scholar] [CrossRef]
- Lee, J.W.; Park, J. An Approach to Constructing a Knowledge Graph Based on Korean Open-Government Data. Appl. Sci. 2019, 9, 4095. [Google Scholar] [CrossRef]
- Jiang, Y.; Gao, X.; Su, W.; Li, J. Systematic Knowledge Management of Construction Safety Standards Based on Knowledge Graphs: A Case Study in China. Environ. Res. Public Health 2021, 18, 10692. [Google Scholar] [CrossRef] [PubMed]
- Gao, H.; Miao, L.; Liu, J.; Dong, K.; Lin, X. Construction and Application of Knowledge Graph for Power System Dispatching. In Proceedings of the International Forum on Electrical Engineering and Automation, Hefei, China, 25–27 September 2020. [Google Scholar]
- Zhang, J.; Song, Z. Research on knowledge graph for quantification of relationship between enterprises and recognition of potential risks. In Proceedings of the IEEE International Conference on Cybernetics, Beijing, China, 5–7 July 2019. [Google Scholar]
- Hossayni, H.; Khan, I.; Aazam, M.; Taleghani-Isfahani, A.; Crespi, N. SemKoRe: Improving Machine Maintenance in Industrial IoT with Semantic Knowledge Graphs. Appl. Sci. 2020, 10, 6325. [Google Scholar] [CrossRef]
- Harnoune, A.; Rhanoui, M.; Mikram, M.; Yousfi, S.; Elkaimbillah, Z.; Asri, B.E. BERT based clinical knowledge extraction for biomedical knowledge graph construction and analysis. Comput. Methods Programs Biomed. Update 2021, 1, 100042. [Google Scholar] [CrossRef]
- Chansai, T.; Rojpaismkit, R.; Boriboonsub, T.; Tuarob, S.; Yin, M.S.; Haddawy, P.; Hassan, S.; Pomarlan, M. Automatic Cause-Effect Relation Extraction from Dental Textbooks Using BERT. In Proceedings of the 23rd International Conference on Asia-Pacific Digital Libraries, Virtual Event, 1–3 December 2021. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual Event, 5–10 July 2020. [Google Scholar]
- Yutaka, S. The Truth of the F-Measure; Technical Report; University of Manchester: Manchester, UK, 2007. [Google Scholar]
- Evan, S. The New York Times Annotated Corpus LDC2008T19. In Web Download; Linguistic Data Consortium: Philadelphia, PA, USA, 2008. [Google Scholar]
- Gardent, C.; Shimorina, A.; Narayan, S.; Perez-Beltrachini, L. Creating Training Corpora for NLG Micro-Planners. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July 2017. [Google Scholar]
- Yang, S.; Yoo, S.; Jeong, O. DeNERT-KG: Named Entity and Relation Extraction Model Using DQN, Knowledge Graph, and BERT. Appl. Sci. 2020, 10, 6429. [Google Scholar] [CrossRef]
- Yuhao, Z.; Zhong, V.; Chen, D.; Angeli, G.; Manning, C.D. Position-aware Attention and Supervised Data Improve Slot Filling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- Dang, J.; Wei, H.; Yan, Y.; Jia, R.; Li, Y. Construction of Knowledge Graph of Electrical Equipment Based on Sentence—BERT. In Proceedings of the 2021 International Conference on Advanced Electrical Equipment and Reliable Operation, Beijing, China, 15 October 2021. [Google Scholar]
- Zheng, X.; Wang, B.; Zhao, Y.; Mao, S.; Tang, Y. A knowledge graph method for hazardous chemical management: Ontology design and entity identification. Neurocomputing 2020, 430, 104–111. [Google Scholar] [CrossRef]
- Yu, J.; Sun, J.; Dong, Y.; Zhao, D.; Chen, X.; Chen, X. Entity recognition model of power safety regulations knowledge graph based on BERT-BiLSTM-CRF. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications, Shenyang, China, 22–24 January 2021. [Google Scholar]
- Zhou, Z.-W.; Ting, Y.-H.; Jong, W.-R.; Chiu, M.-C. Knowledge Management for Injection Molding Defects by a Knowledge Graph. Appl. Sci. 2022, 12, 11888. [Google Scholar] [CrossRef]
- Bachhofner, S.; Kiesling, E.; Revoredo, K.; Waibel, P.; Polleres, A. Automated Process Knowledge Graph Construction from BPMN Models. In Proceedings of the International Conference on Database and Expert Systems Applications, Database and Expert Systems Applications, Vienna, Austria, 22–24 August 2022. [Google Scholar]
- Wang, Y.; Zou, J.; Wang, K.; Yuan, X.; Xie, S. Injection Molding Knowledge Graph Based on Ontology Guidance and Its Application to Quality Diagnosis. J. Electron. Inf. Technol. 2022, 44, 1521–1529. [Google Scholar]
- Singhal, A. Introducing the Knowledge Graph: Things, Not Strings. 2021. Available online: https://googleblog.blogspot.co.at/2012/05/introducing-knowledge-graph-things-not (accessed on 6 August 2022).
- Guia, J.; Soares, V.G.; Bernardino, J. Graph Databases: Neo4j Analysis. In Proceedings of the International Conference on Enterprise Information Systems, Porto, Portugal, 26–29 April 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Su, J. bert4keras. Available online: https://github.com/bojone/bert4keras (accessed on 23 October 2022).


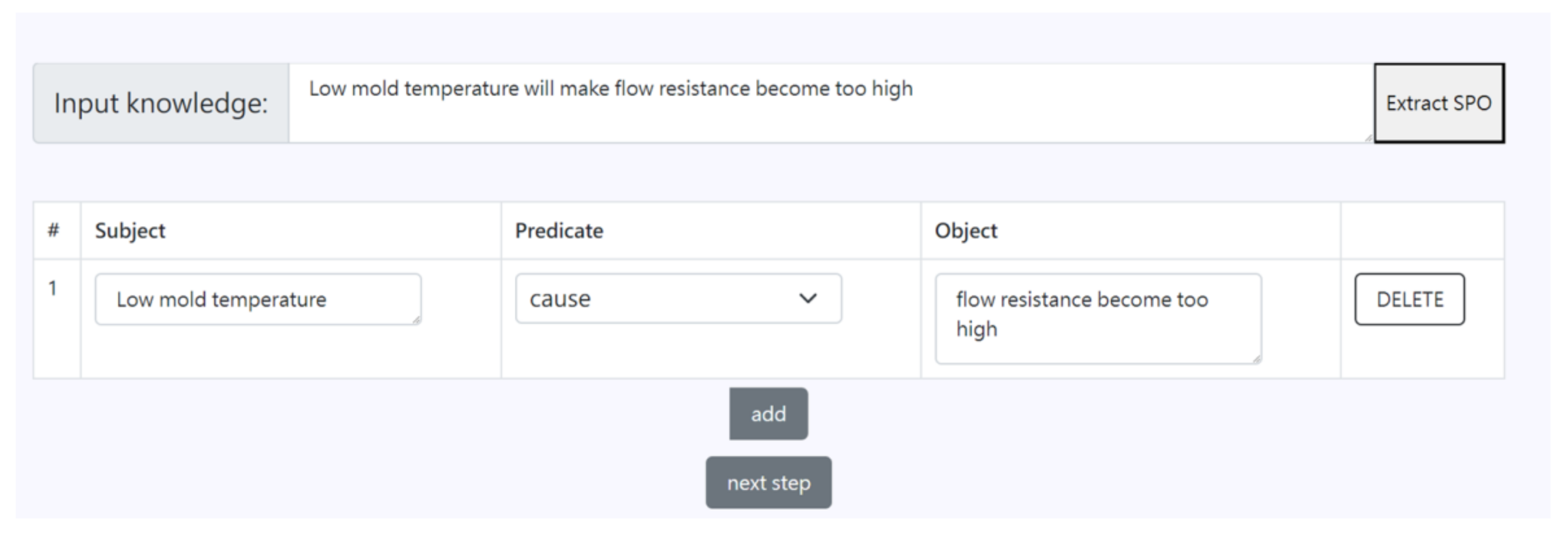
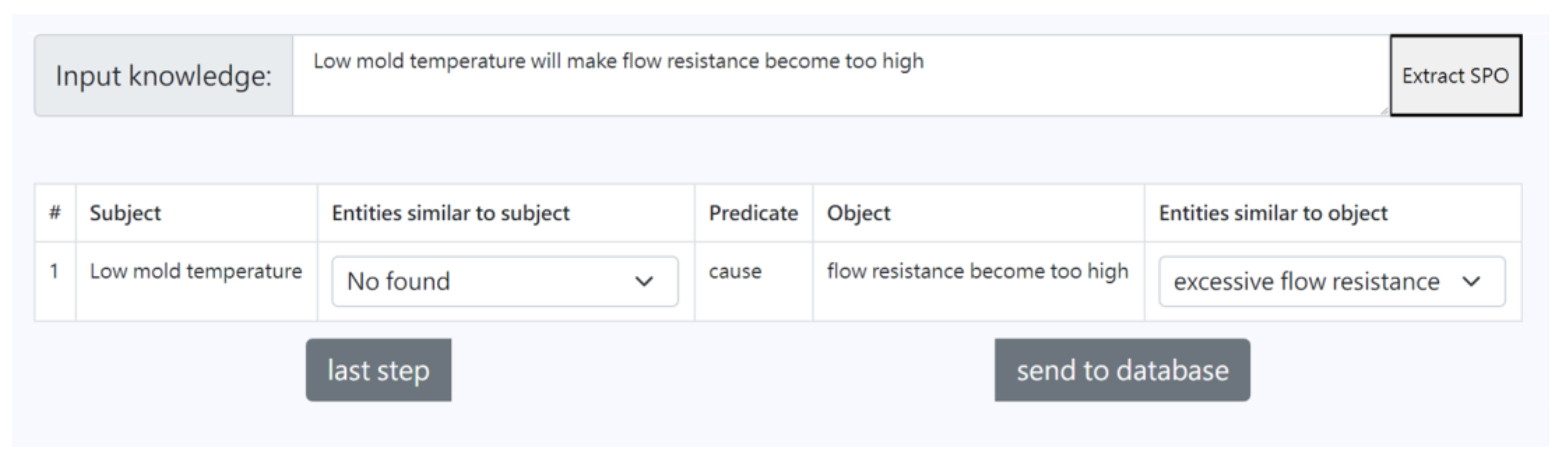
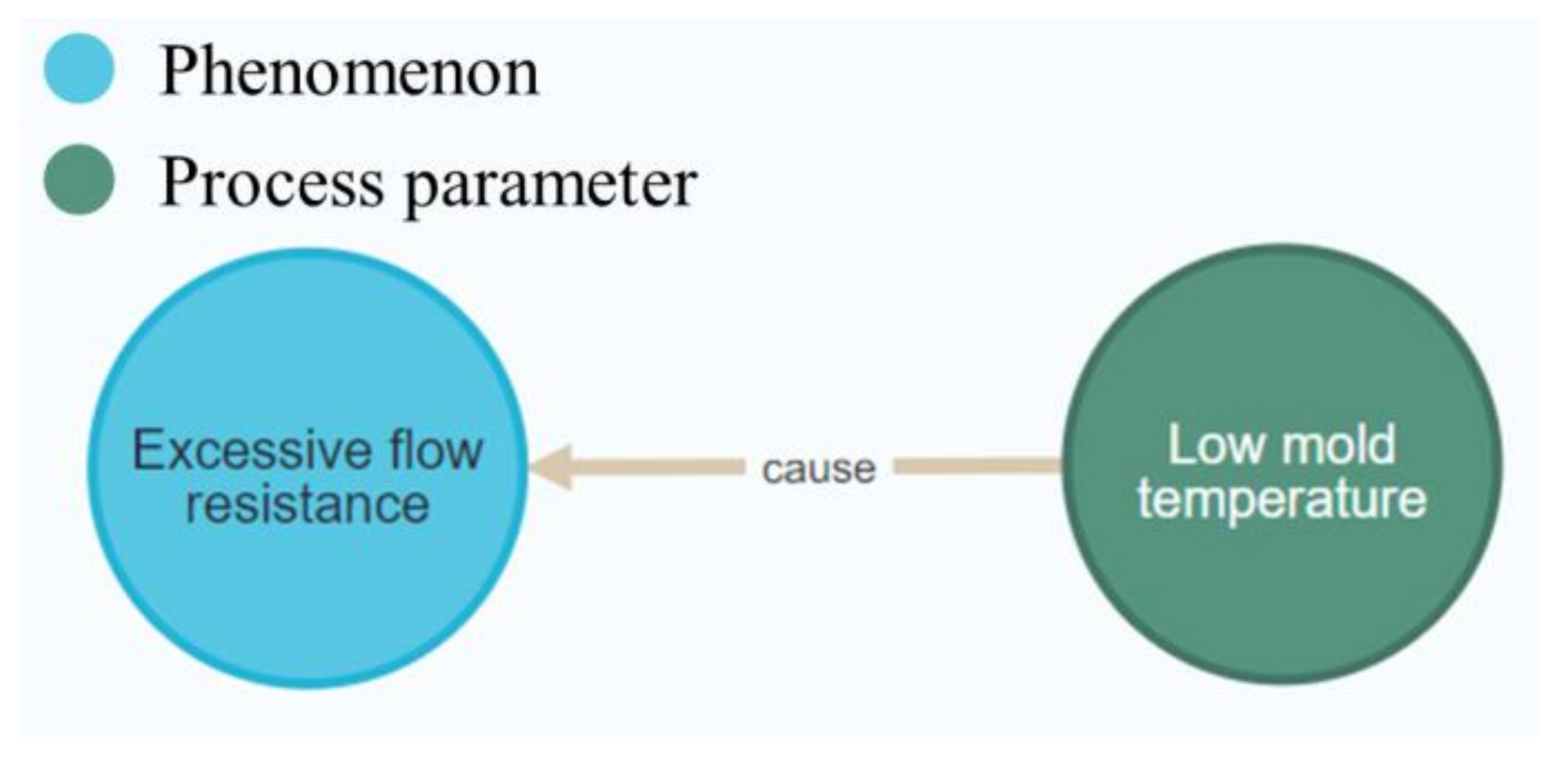




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Text |
|---|---|
| 1 | Insufficient injection pressure and excessive flow resistance cause short shots. |
| 2 | High flow resistance can be improved by reducing the melt viscosity. |
| 3 | Too-low mold temperatures and too-slow injection speeds cause the solidified layer to be too thick, which further leads to excessive flow resistance. |
| 4 | Too-low melting temperatures cause excessive melt viscosity, which further causes excessive flow resistance. |
| 5 | Reason for excessive flow resistance: (1) inappropriate gate location, (2) nozzle size is too small, or (3) product is too thin. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.-W.; Ting, Y.-H.; Jong, W.-R.; Chen, S.-C.; Chiu, M.-C. Development and Application of Knowledge Graphs for the Injection Molding Process. Machines 2023, 11, 271. https://doi.org/10.3390/machines11020271
Zhou Z-W, Ting Y-H, Jong W-R, Chen S-C, Chiu M-C. Development and Application of Knowledge Graphs for the Injection Molding Process. Machines. 2023; 11(2):271. https://doi.org/10.3390/machines11020271
Chicago/Turabian StyleZhou, Zhe-Wei, Yu-Hung Ting, Wen-Ren Jong, Shia-Chung Chen, and Ming-Chien Chiu. 2023. "Development and Application of Knowledge Graphs for the Injection Molding Process" Machines 11, no. 2: 271. https://doi.org/10.3390/machines11020271
APA StyleZhou, Z.-W., Ting, Y.-H., Jong, W.-R., Chen, S.-C., & Chiu, M.-C. (2023). Development and Application of Knowledge Graphs for the Injection Molding Process. Machines, 11(2), 271. https://doi.org/10.3390/machines11020271