
Fault Diagnosis of a Switch Machine to Prevent High-Speed Railway Accidents Combining Bi-Directional Long Short-Term Memory with the Multiple Learning Classification Based on Associations Model

 ,
,
Abstract
:1. Introduction
2. Literature Review
2.1. Fault Diagnosis of High-Speed Railway Switch Machines
2.2. Fault Diagnosis of Rail Transit with Text Data
3. Data Description
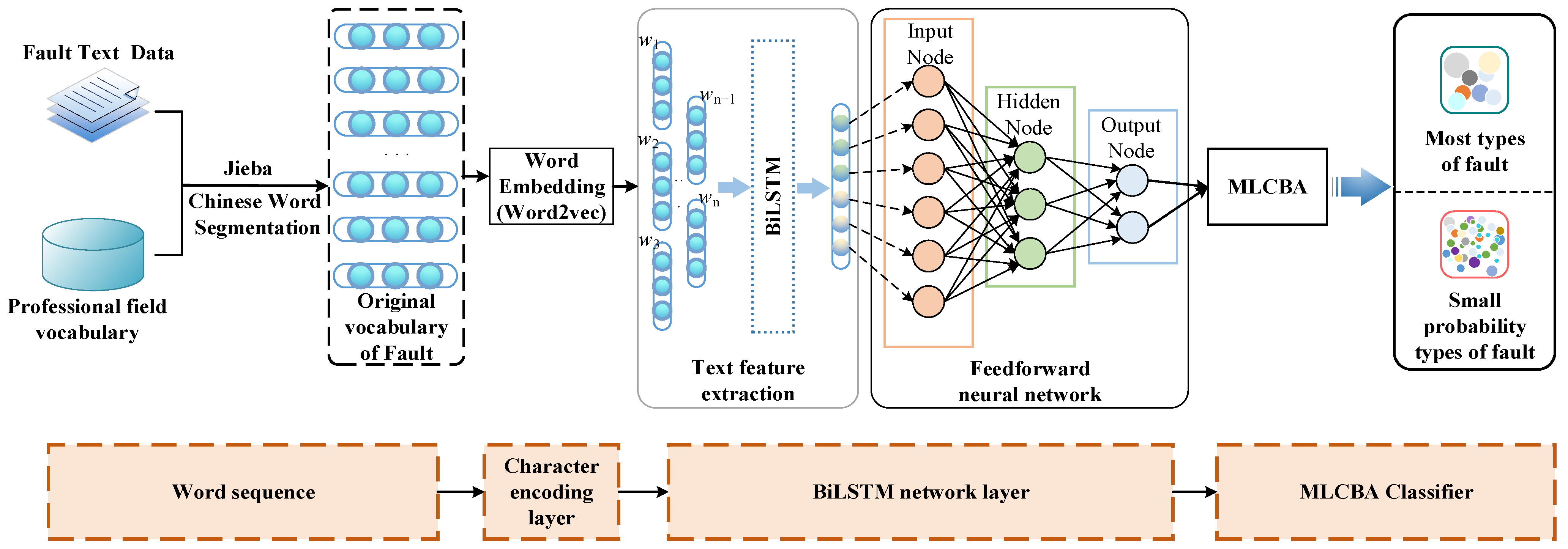
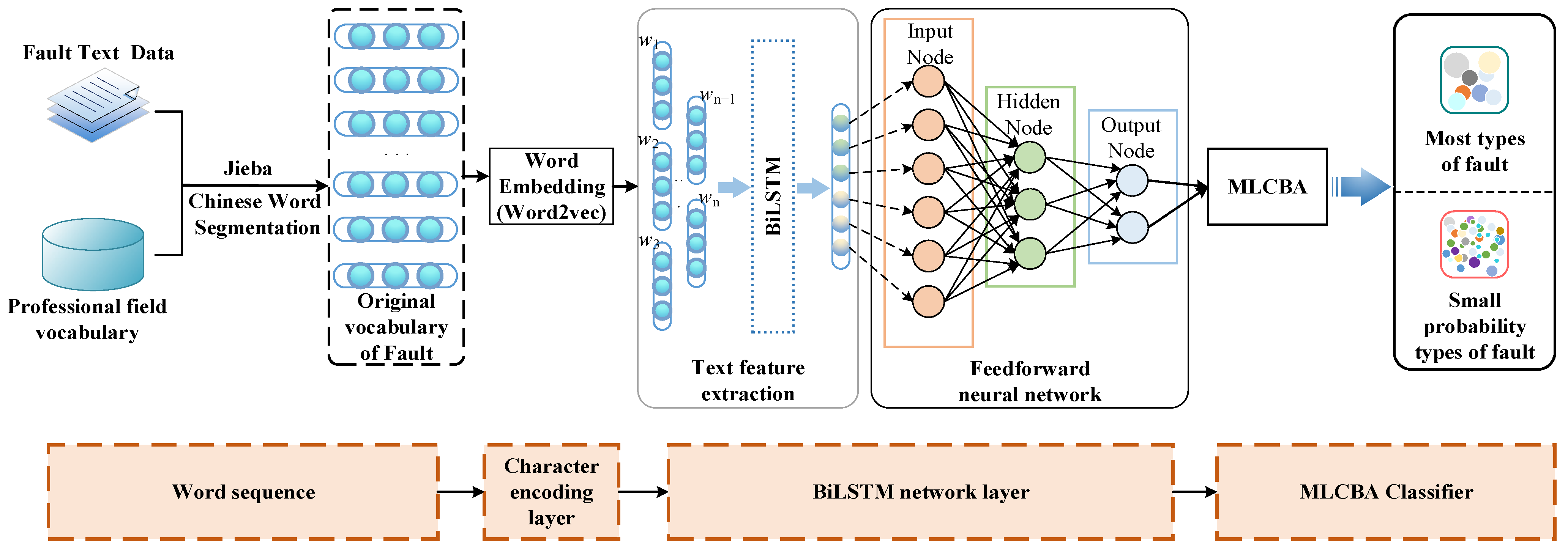
4. Method Description
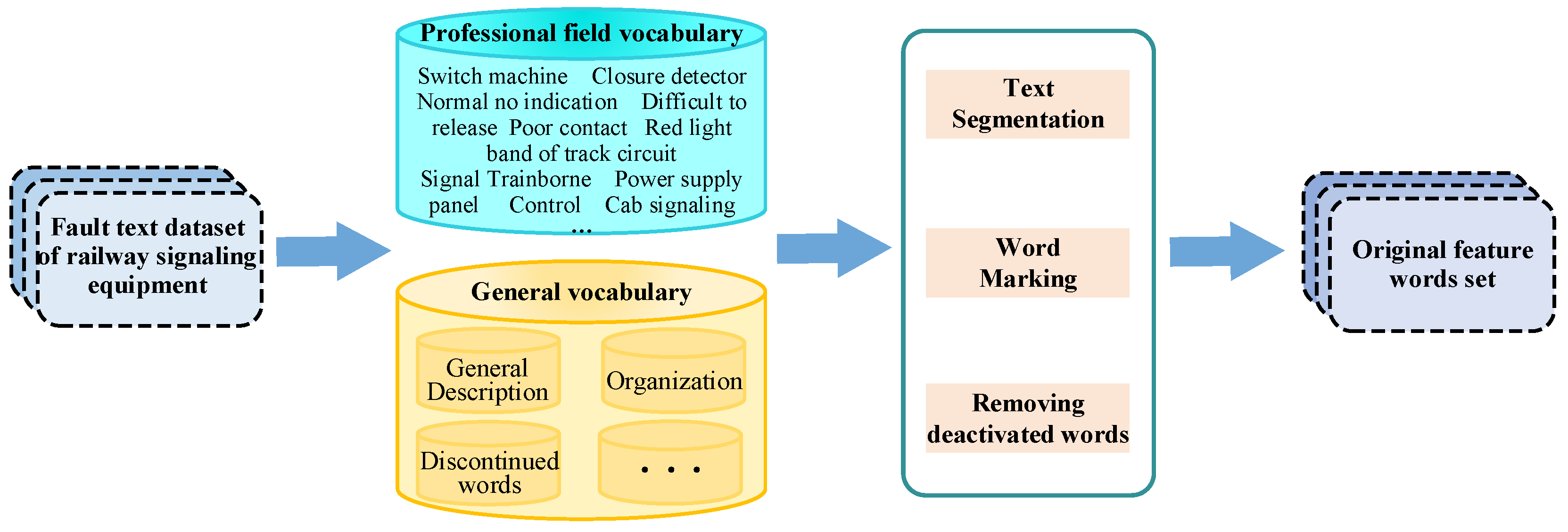
4.1. Data Processing
4.2. Feature Extraction
- (1)
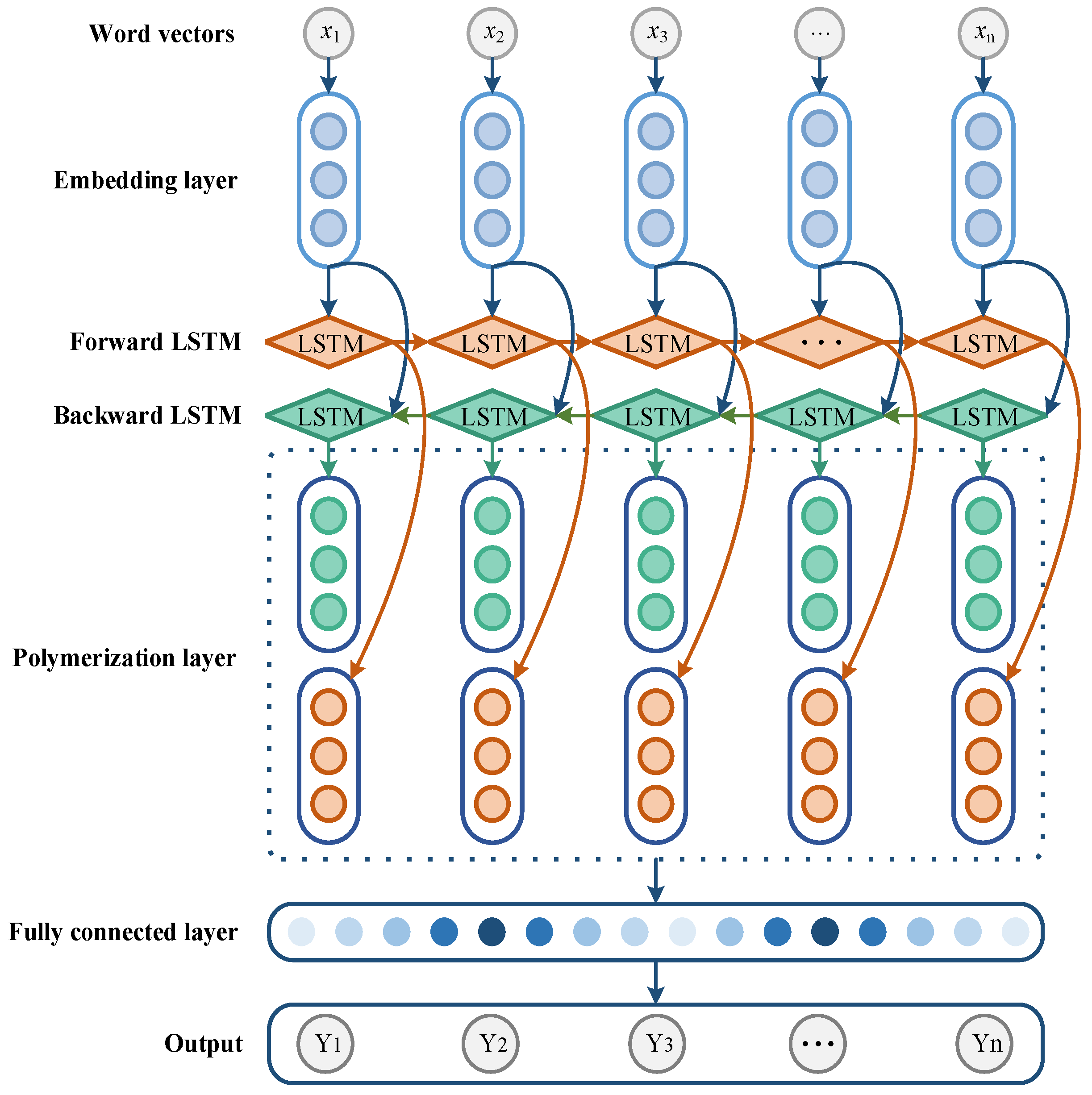
- The word vectors obtained with fault data processing are input to the embedding layer. The length of a statement in the input fault text data is supposed to be m. represents the word vector of the word, , where n is the word vector dimension and R is the set of word vectors. Hence, all the statements can be expressed as follows:
- (2)
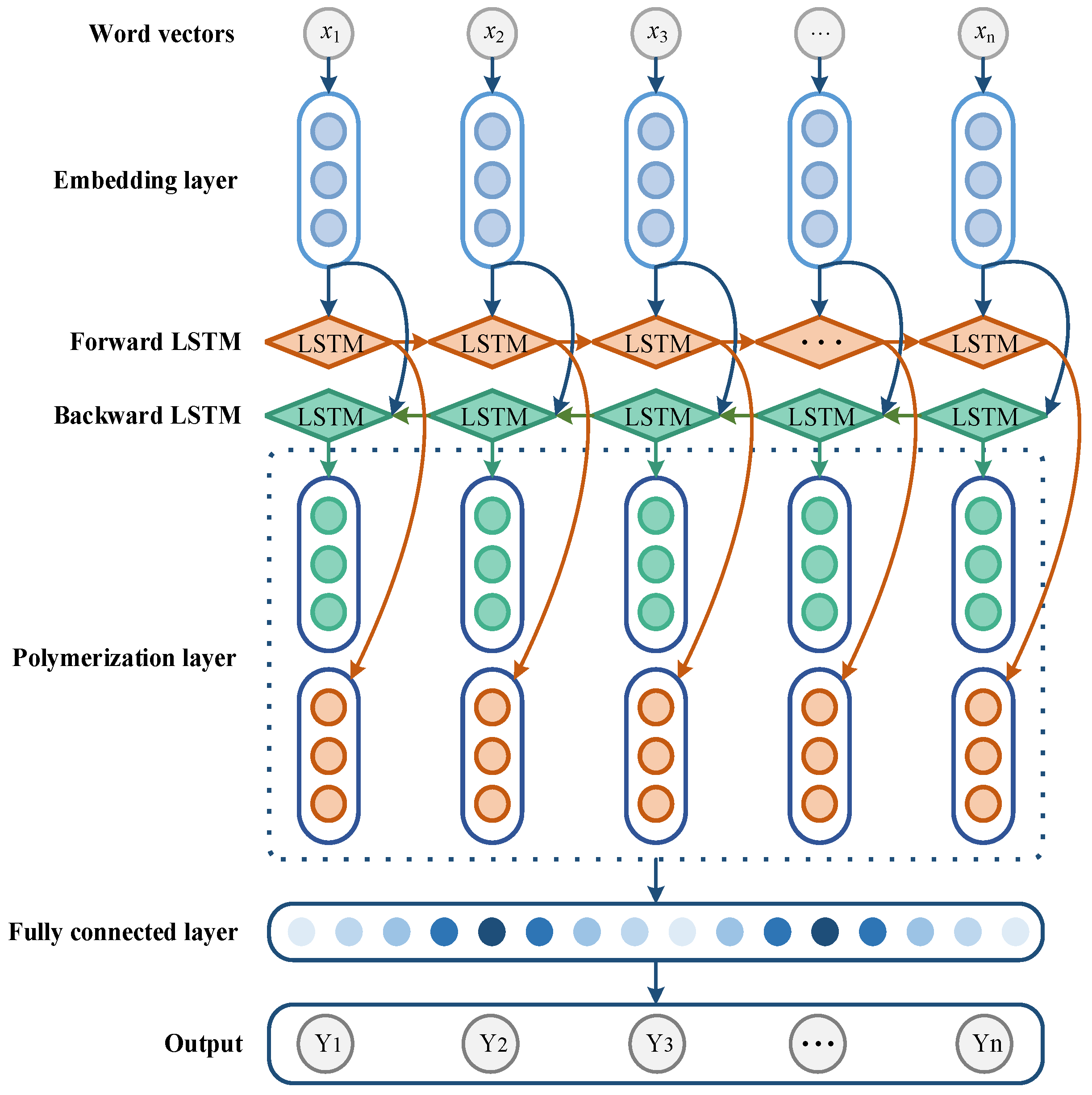
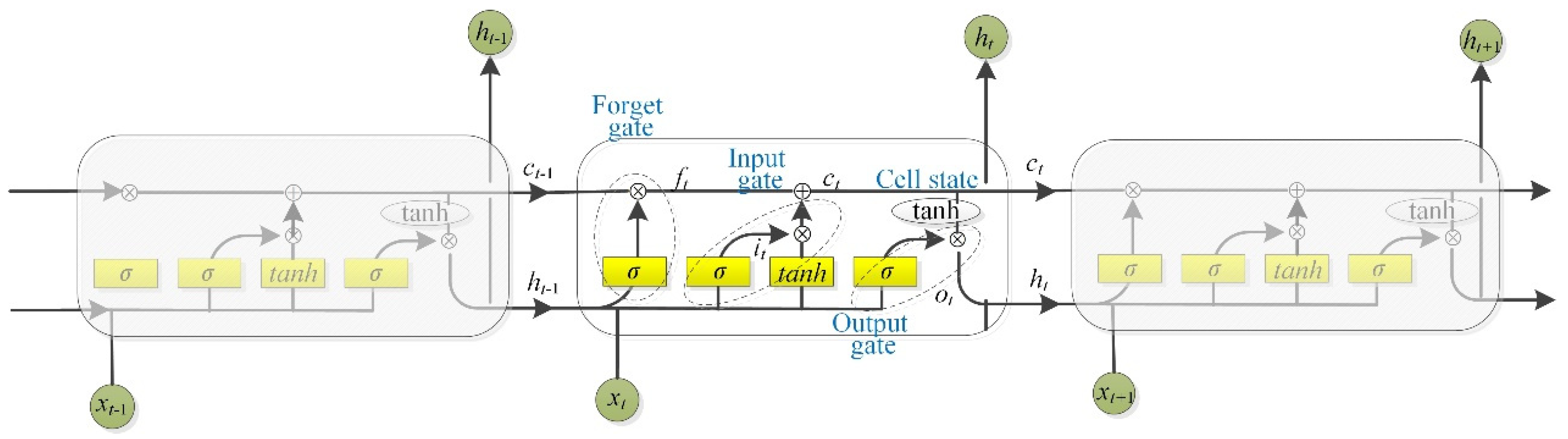
- BiLSTM is composed of two LSTM neural networks. Figure 4 shows the basic structure of the LSTM neural network model. The forget gate, input gate, output gate, and cell state are the components of the LSTM, and they are given by Equations (3)–(7).
- (3)
- The overall feature vectors of the text data can be obtained with the forward and backward bi-directional processing between the two-way LSTM layers. Additionally, the fault text features can be generated through aggregation and used as input for the classifier.
- (4)
- The classification result can be converted into a probability value between 0 and 1 by the SoftMax classifier, and the fault type values can be finally output as the classification results.
4.3. Rule Classification
4.3.1. Basic Definition of Correlation Rule Classification
- (1)
- The support expression is as follows:
- (2)
- The confidence expression is as follows:
- (3)
- Furthermore, the degree of lift is expressed as follows:
- (4)
- is the class support between sets A and B, which is expressed as shown in Equation (11). Additionally, the class support of the association rule may be higher when there is a small amount of data in a certain type B.
- (5)
- The complement class support is expressed as follows:
- (6)
- The expression of the Laplace rule strength is as follows:
- (7)
- In correlation rule classification, the corresponding concept of the correlation degree is put forward for the unbalanced data, and it is expressed as follows:
- (8)
- The rule strength is expressed as follows:
4.3.2. Fault Classification Process of High-Speed Railway Switch Machines
- (1)
- First, the number of multiple learning times and the extraction ratio of each learning instance are set, and the thresholds of the support and correlation degrees are set simultaneously.
- (2)
- Second, the frequent item sets of the new training sets are mined by the support threshold, and the new training sets are randomly selected from the original training sets.
- (3)
- Next, the correlation degree of the frequent item sets mined from each new training set to each type is calculated, and the appropriate rules with the threshold of correlation degree are explored.
- (4)
- Then, all the rules learned each time are merged, the repeated rules are eliminated, and the rules are pruned at the same time.
- (5)
- Finally, the training examples that cannot be judged in the training set are learned again, and the new rules are extracted and added to the rule set. Therefore, the full rule of the training example can be covered completely, and all rules can be sorted by the strength of the RS rule.
5. Empirical Results and Discussion
5.1. Empirical Results
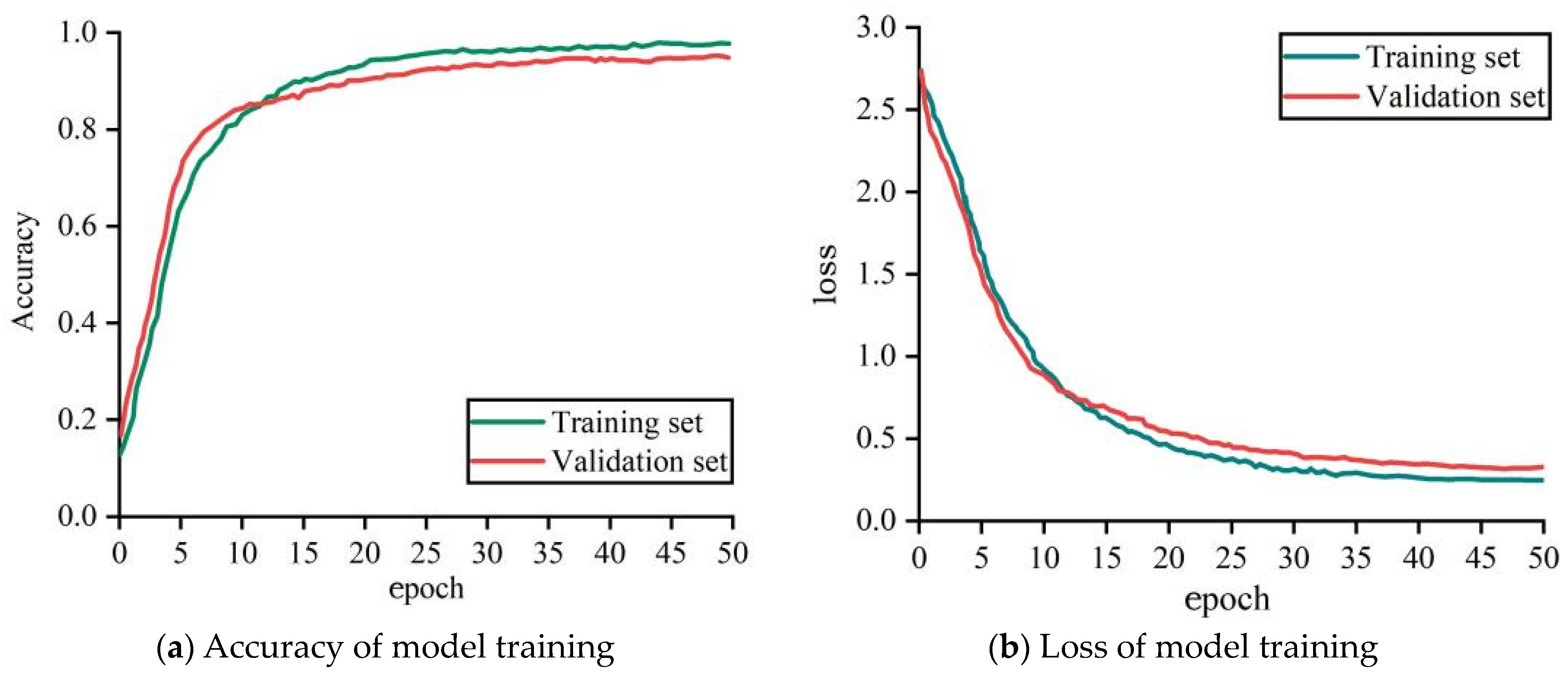
5.1.1. Environment and Configuration Parameters for Simulation
5.1.2. Evaluation Indicators of the BiLSTM-MLCBA Fault Diagnosis Model
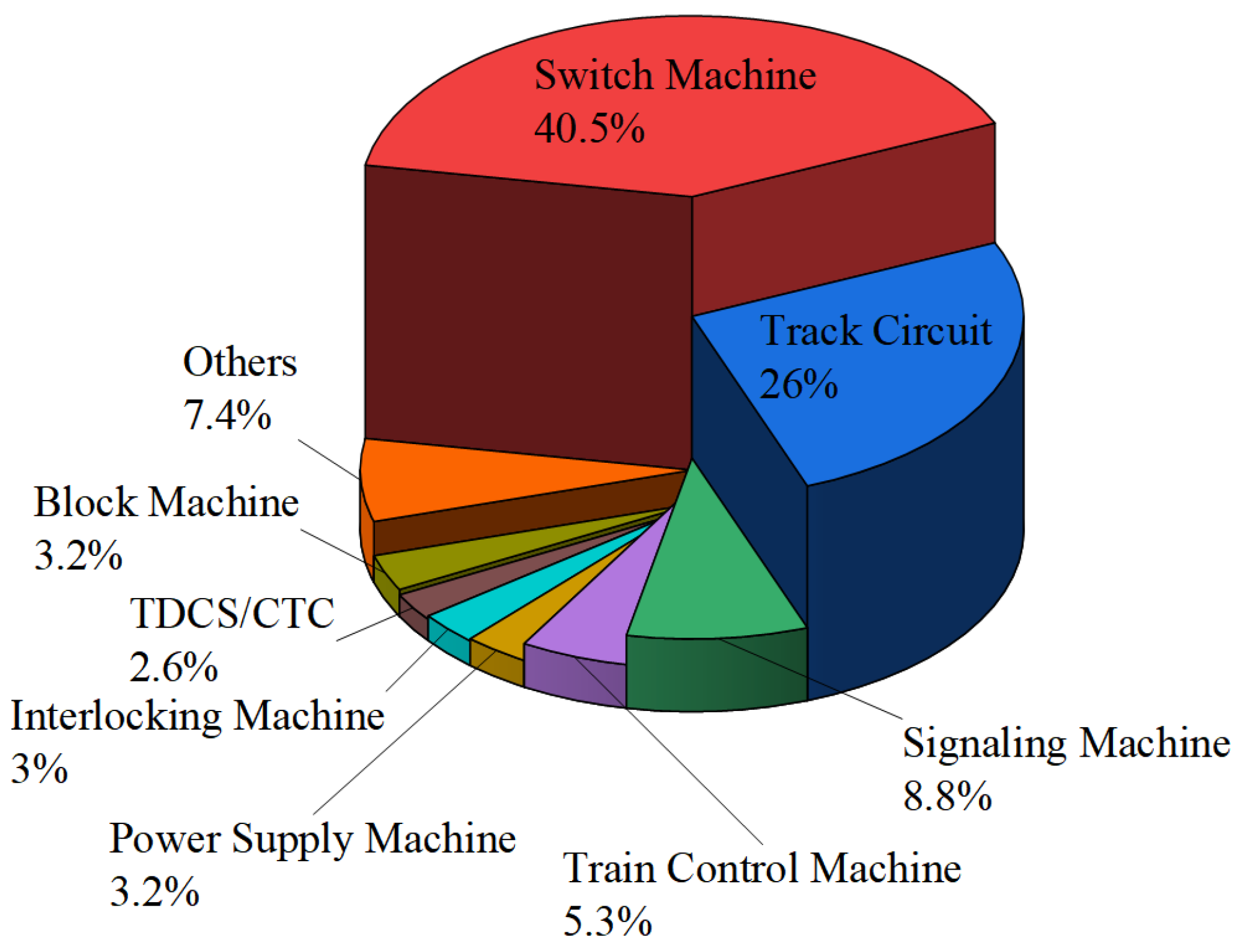
5.1.3. Fault Text Data Preprocessing for a High-Speed Railway with a ZYJ7
Switch Machine
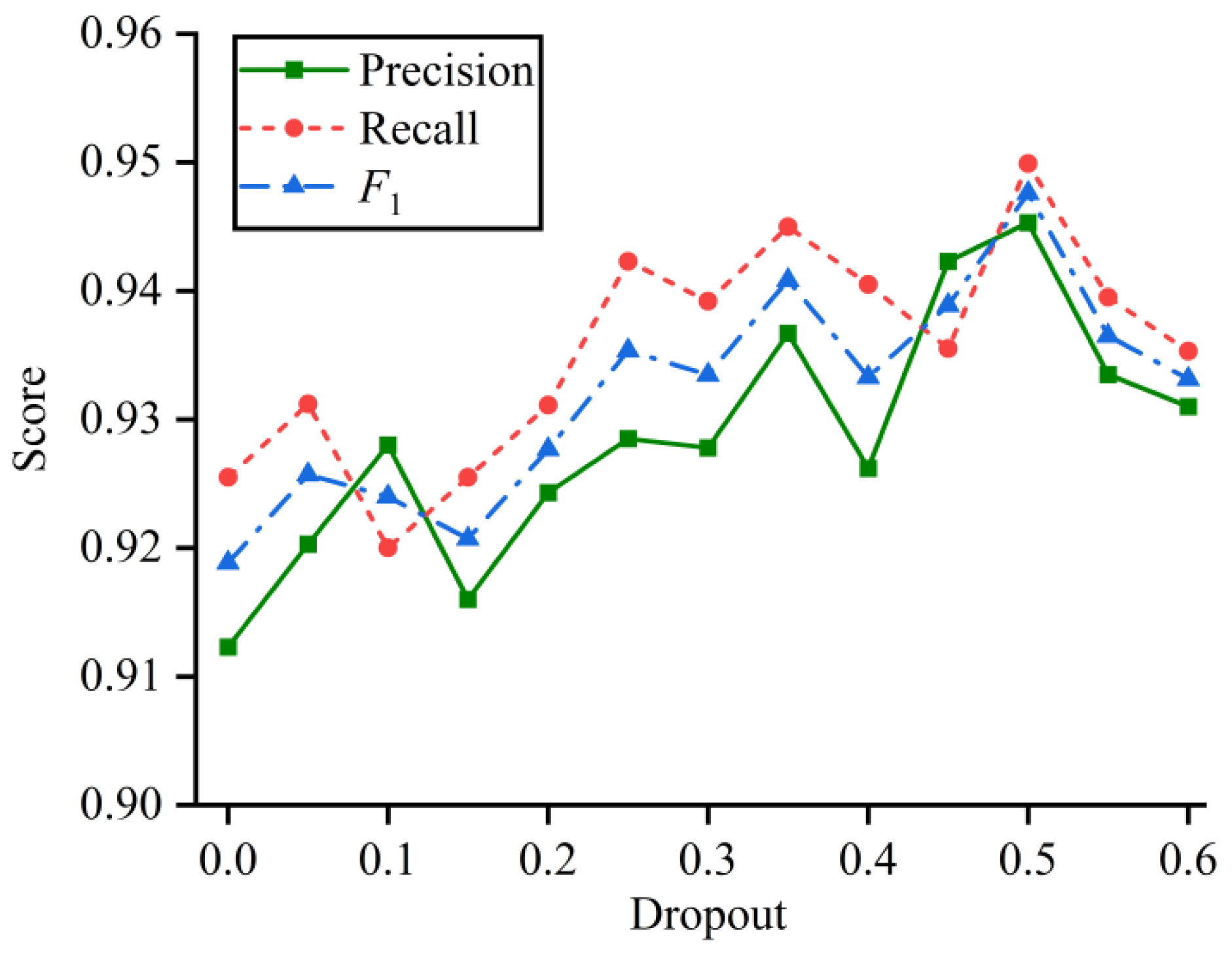
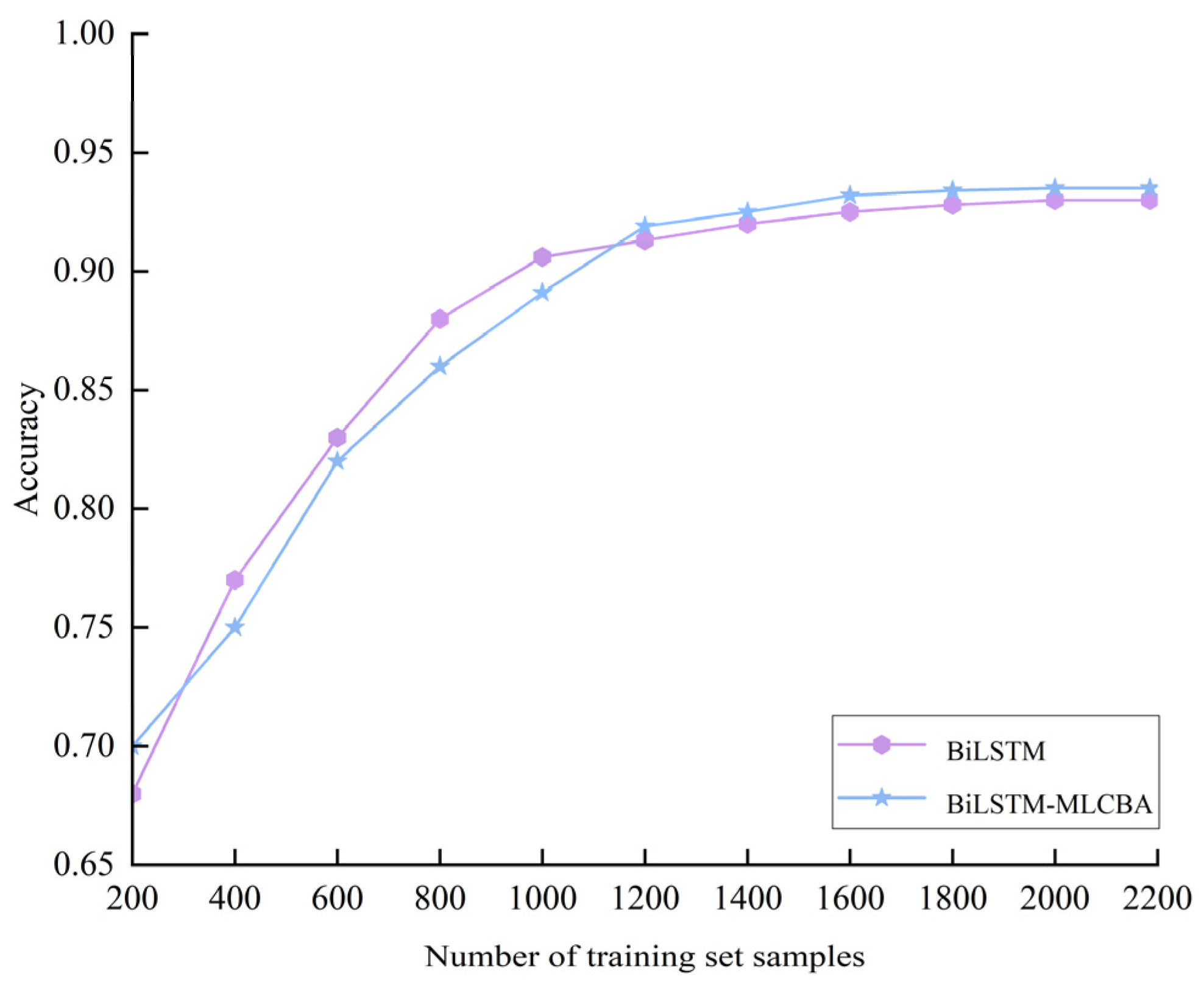
5.1.4. Analysis of Different Hyper-Parameters in the BiLSTM Model
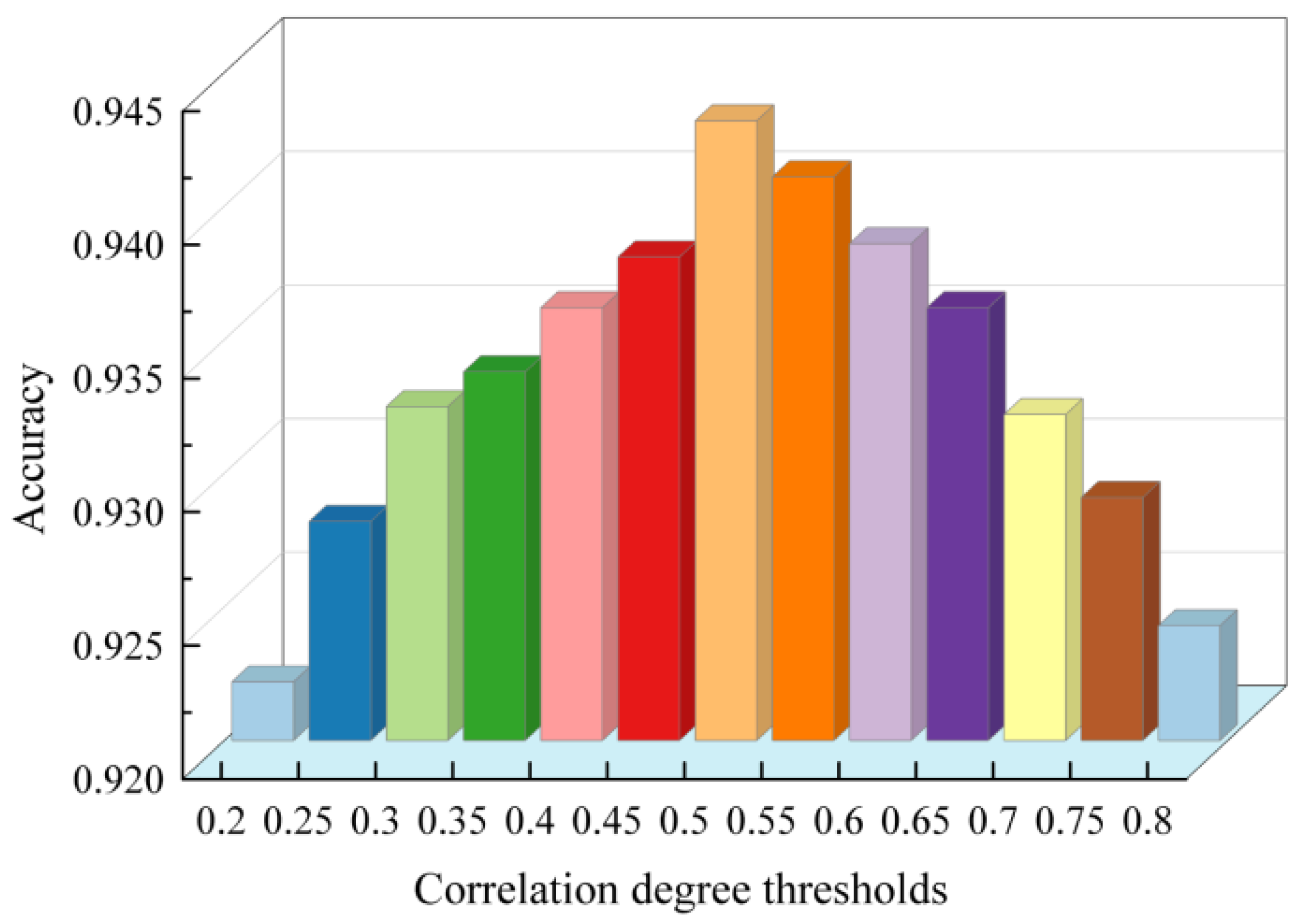
5.1.5. Study of the Threshold of Correlation Degree for the MLCBA Algorithm
5.2. Results and Discussions
5.2.1. Study of the Threshold of Correlation Degree for the MLCBA Algorithm
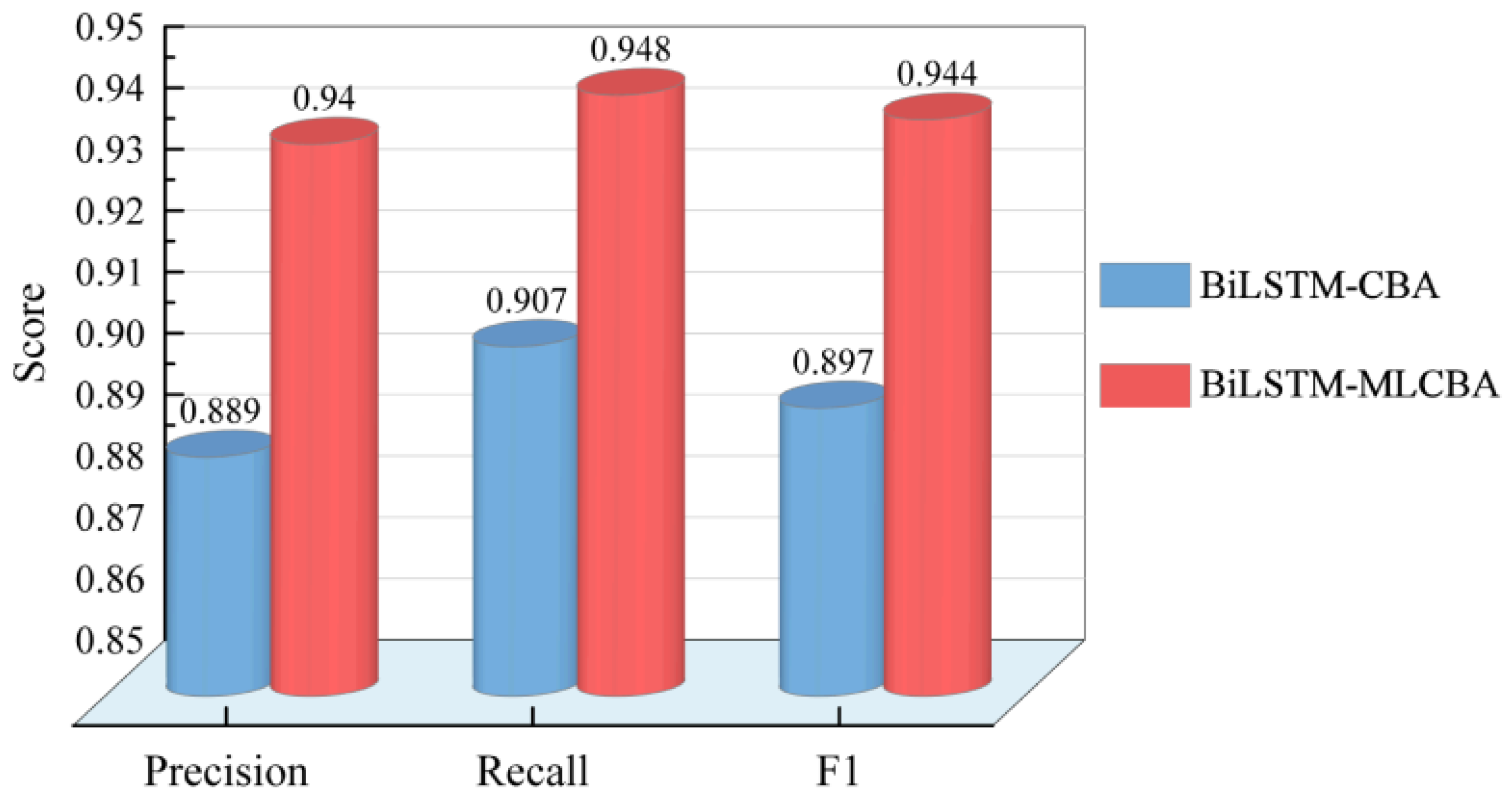
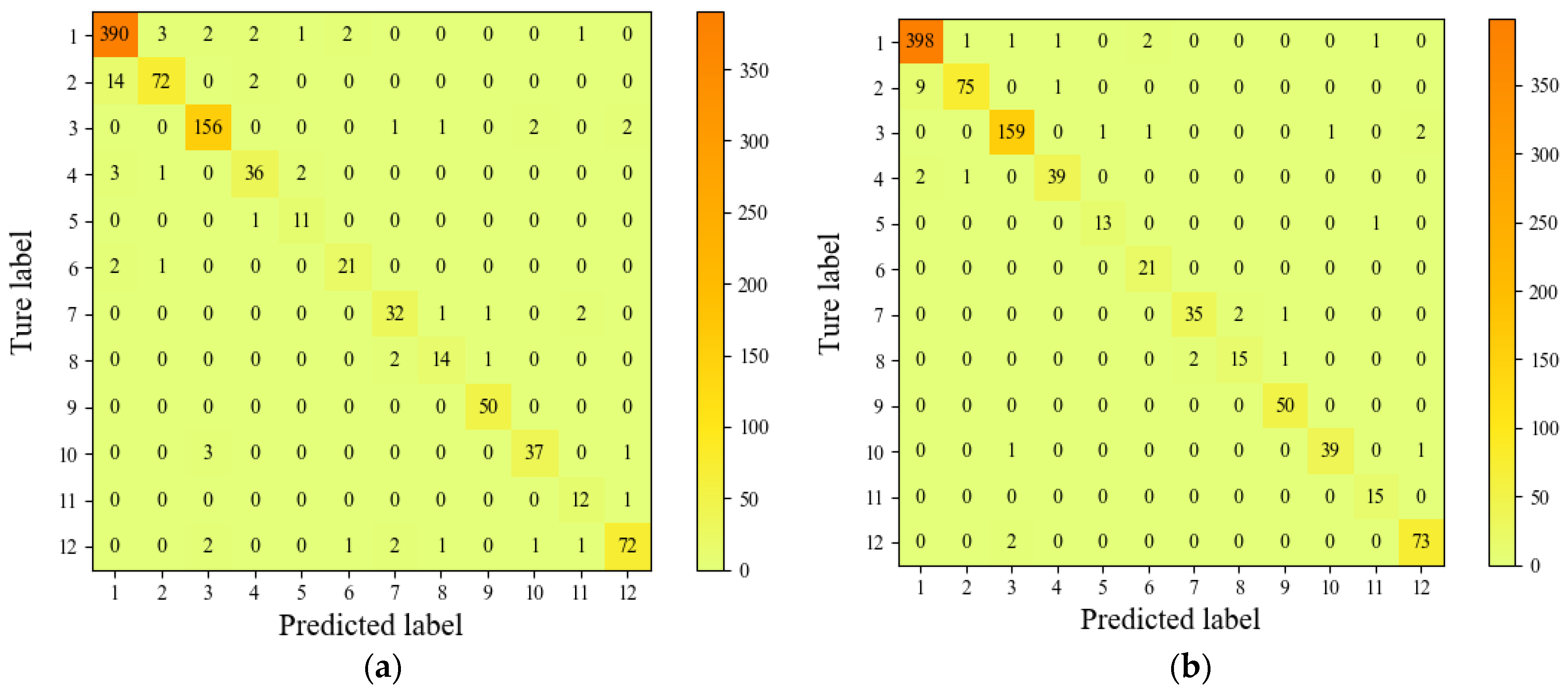
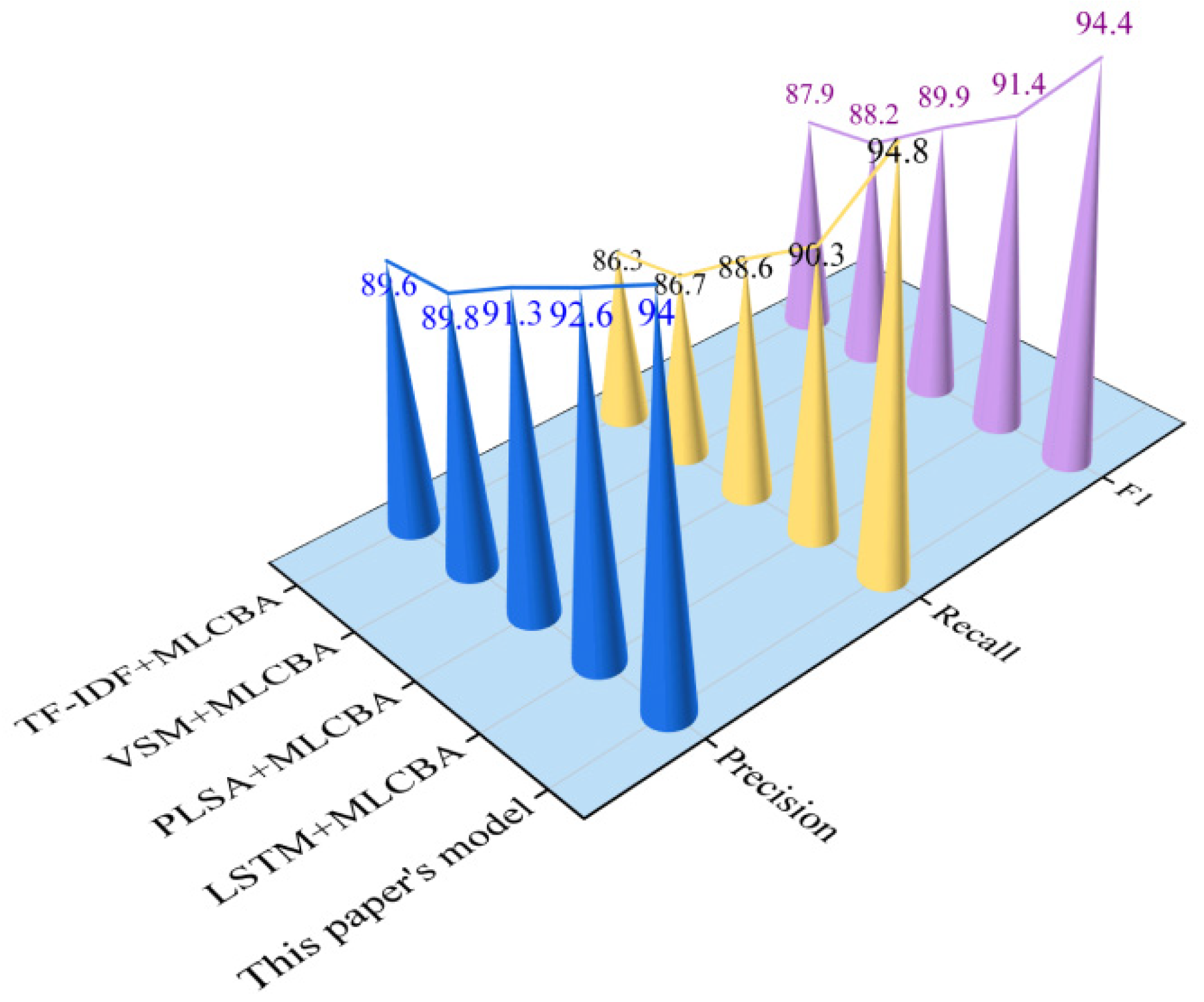
5.2.2. Comparative Analysis of BiLSTM-CBA and Other Models
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- China Railway Kunming Group Co., Ltd. Principle of Turnout Switching Machine and Failure Cases; China Railway Publishing House: Beijing, China, 2022. [Google Scholar]
- National Railway Administration of People’s Republic of China. Research and Investigation Points on the Causes of Railway Traffic Accidents; China Railway Publishing House: Beijing, China, 2019.
- Cao, Y.; An, Y.T.; Su, S.; Xie, G. A statistical study of railway safety in China and Japan 1990–2020. Accid. Anal. Prev. 2022, 175, 106764. [Google Scholar] [CrossRef] [PubMed]
- Li, X.Q.; Zhang, P.X.; Shi, T.Y.; Li, P. Research on fault diagnosis method for high-speed railway signal equipment based on deep learning integration. J. China Railw. Soc. 2020, 42, 97–105. [Google Scholar]
- Yang, L.B.; Shen, X.; Li, X.Q.; Dong, X.Z.; Xue, R.; Xu, G.H. Classification model of high-speed railway turnout failures based on text analysis. China Railw. 2020, 8, 13–18. [Google Scholar] [CrossRef]
- Hamadache, M.; Dutta, S.; Olaby, O.; Ambur, R.; Stewart, E.; Dixon, R. On the fault detection and diagnosis of railway switch and crossing systems: An overview. Appl. Sci. 2019, 9, 5129. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, J.; Li, F.; Zhang, K.; Lv, H.; He, S.; Xu, E. Intelligent fault diagnosis of machines with small & imbalanced data: A state-of-the-art review and possible extensions. ISA Trans. 2022, 119, 152–171. [Google Scholar] [CrossRef] [PubMed]
- Dai, Q.J.; Chen, Y.G.; Tao, R.J. Research on PHM model of switch machine based on dynamic particle swarm optimization. Railw. Stand. Des. 2018, 62, 174–178. [Google Scholar] [CrossRef]
- Eker, O.F.; Camci, F.; Kumar, U. SVM based diagnostics on railway turnouts. Int. J. Perform. Eng. 2012, 8, 289–298. [Google Scholar]
- Zhang, Q.Q. Research on the design of expert system for fault diagnosis of railway signal equipment. Technol. Dev. Enterp. 2016, 35, 28–29. [Google Scholar]
- Bian, C.; Yang, S.; Huang, T.; Xu, Q.; Liu, J.; Zio, E. Degradation state mining and identification for railway point machines. Reliab. Eng. Syst. Saf. 2019, 188, 432–443. [Google Scholar] [CrossRef]
- Zhang, T.F. Intelligent analysis of the action current curve of S700K switch machine. J. Manu. Auto. 2014, 36, 71–74. [Google Scholar]
- Lei, Y.T. Switch machine diagnostic system based on WPT And EMD incorporated feature extraction. Mach. Build. Autom. 2017, 46, 219–222. [Google Scholar] [CrossRef]
- Liu, Y.J.; Si, Y.B.; Chen, G.W.; Wei, Z.S. Turnout fault diagnosis based on CDET/MPSO-SVM. J. Beijing Jiaotong Univ. 2021, 45, 52–59. [Google Scholar]
- Wu, X.C.; Chu, X. Research on Division of Degradation Stage of Turnout Equipment Based on Wavelet Packet Decomposition and GG Fuzzy Clustering. J. China Rail. Soc. 2022, 44, 79–85. [Google Scholar]
- Zhang, K. The railway turnout fault diagnosis algorithm based on BP neural network. In Proceedings of the IEEE International Conference on Control Science and Systems Engineering IEEE, Yantai, China, 29–30 December 2014; pp. 135–138. [Google Scholar]
- Liang, X.; Wang, H.F.; Guo, J.; Xu, T.H. Bayesian network based fault diagnosis method for on-board equipment of train control system. J. China Railw. Soc. 2017, 39, 93–100. [Google Scholar]
- Fan, L.H.; Wu, X.C.; Guo, R.C. Working State Evaluation Method of On-board Equipment of Train Control System Based on Association Rules and Variable Weight Coefficient. J. Rail. Stand. Desi. 2021, 65, 171–176. [Google Scholar]
- Li, J.; Wang, J.P.; Xu, N.; Zhou, Z. Analysis of safety risk factors for metro construction based on text mining method. Tunn. Constr. 2017, 37, 160–166. [Google Scholar]
- Zhou, L.J.; Dong, Y. Research on fault diagnosis method for on-board equipment of train control system based on GA-BP neural network. J. Railw. Sci. Eng. 2018, 15, 3257–3265. [Google Scholar] [CrossRef]
- Zhao, Y.; Xu, T.H.; Zhou, Y.P. Text mining based fault diagnosis for vehicle on-board equipment of high-speed railway signal system. J. China Railw. Soc. 2015, 37, 53–59. [Google Scholar]
- Zhong, Z.W.; Tang, T.; Wang, F. Research on fault extraction and diagnosis of railway based on PLSA and SVM. J. China Railw. Soc. 2018, 40, 80–87. [Google Scholar]
- Hang, X.Y.; Liu, G.F.; Liu, X.Y.; Yang, A.; Ling, Y. Sentiment classification depth model based on word2vec and bi-directional LSTM. Appl. Res. Comput. 2019, 36, 3583–3587. [Google Scholar] [CrossRef]
- Zhu, F.P.; Wang, X.F. Text classification for ship industry news. J. Electron. Meas. Instrum. 2020, 34, 149–155. [Google Scholar] [CrossRef]
- Gao, H.; Zeng, X.; Yao, C. Application of improved distributed Naive Bayesian algorithms in text classification. J. Supercomput. 2019, 75, 5831–5847. [Google Scholar] [CrossRef]
- Ge, S.; Zhuang, Y.; Hu, Y.; Ai, X. Research on enterprise hidden danger association rules based on text analysis. IOP Conf. Ser. Earth Environ. Sci. 2019, 252, 032170. [Google Scholar] [CrossRef]
- Xie, M.J.; He, J.F.; Hu, X.X. Fault diagnosis for urban rail transit track side signaling equipment based on fault logs. J. Beijing Jiaotong Univ. 2020, 44, 27–35. [Google Scholar]
- Ding, J.Q.; Li, B.; Qiao, Y. Crop disease diagnosis method based on multi-type data fusion of plant electronic medical records. Trans. Chin. Soc. Agric. Mach. 2023, 54, 196–204+223. [Google Scholar]
- Xie, X.J.; Gu, B. Analysis of antimicrobial drug resistance based on deep learning. J. Hunan Univ. (Nat. Sci. Ed.) 2021, 48, 113–120. [Google Scholar]
- Yuan, H.; Zhang, Q.; Tang, Q. A modified yield-based mean-variance model with survivorship bias. J. Asset Manag. 2019, 20, 145–157. [Google Scholar]
- Xie, H.Y. Research and case analysis of apriori algorithm based on mining frequent Item-Sets. Open J. Soc. Sci. 2021, 9, 458. [Google Scholar] [CrossRef]
- Ji, H.P.; Wang, T.Y.; Liu, J.; Fan, S.Y.; Wang, Z.P.; Zhang, K.R. An efficient parallel association rules mining algorithm for fault diagnosis. Key Eng. Mater. 2016, 693, 1326–1330. [Google Scholar] [CrossRef]
- Lin, H.X.; Lu, R.; Lu, R.J.; Xu, L.; Zhao, Z.X.; Bai, W.S. Fault diagnosis for turnout of high-speed railway based on LDA-CLCBA hybrid model. J. Electron. Meas. Instrum. 2022, 36, 251–259. [Google Scholar] [CrossRef]
- Deng, J.F.; Cheng, L.L.; Wang, Z.W. Attention-based BiLSTM fused CNN with gating mechanism model for Chinese long text classification. Comput. Speech Lang. 2021, 68, 101182. [Google Scholar] [CrossRef]
- Zhu, Y.T.; Zhang, J.; Cao, X.B. Predicion of railway passenger ticket booking quantity based on ensembles of multi-step LSTM. J. China Railw. Soc. 2021, 43, 19–25. [Google Scholar]
- Zhang, S.R.; Zhu, Z.B.; Feng, B. New channel selection and classification algorithm based on group sparse Bayesian logistic regression motor imagery EEG signal classification model. Chin. J. Sci. Instrum. 2019, 40, 179–191. [Google Scholar] [CrossRef]
- Chen, Z.; Zhou, L.J.; Da, L.X.; Zhang, J.N.; Huo, W.J. The Lao text classification method based on KNN. Procedia Comput. Sci. 2020, 166, 523–528. [Google Scholar] [CrossRef]
- Zhen, J.; Lee, D.J. Implementation of fatigue identification system using C4.5 algorithm. J. Korea Converg. Soc. 2019, 10, 21–26. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Description of ZYJ7 Switch Machine Fault | Title 3 |
|---|---|---|
| 1 | On 24 August 2017, from xx to xx, the poor sealing of the purple copper gasket in the main host 121177# air cylinder resulted in oil leakage. | Fault of “air cylinder” |
| 2 | On 6 July 2017, from xx to xx, there was oil seepage at the pressure sensor of the startup oil cylinder in “11992#”, making it impossible to disassemble. | Fault of “hydraulic cylinder assembly” |
| 3 | On 18 December 2018, from xx to xx, the roller inside the switch machine of “173046#” failed to unlock, causing the turnout to be unable to move. | Fault of “contact assembly” |
| 4 | On 17 June 2019, from xx to xx, it was reported on-site that the unlocking pressure of the operating lever in “174602#” was excessive, resulting in a high unlocking curve. | Fault of “operating lever” |
| Title | Fault Type | Number of Fault Cases | Fault Occurrence Rate (%) |
|---|---|---|---|
| C1 | The assembly of the motor oil pump | 1366 | 40.37 |
| C2 | The assembly of the hydraulic cylinder | 253 | 8.12 |
| C3 | The assembly of the contacts | 545 | 24.09 |
| C4 | The joint of the oil pipe | 136 | 3.67 |
| C5 | Bottom case | 48 | 0.98 |
| C6 | Air cylinder | 89 | 2.23 |
| C7 | Operating lever | 122 | 2.98 |
| C8 | The rod indicating the locking status | 56 | 1.02 |
| C9 | Defects in the railway track | 173 | 3.81 |
| C10 | Relay | 136 | 3.51 |
| C11 | Circuit breaker | 58 | 1.14 |
| C12 | Cable circuit | 247 | 8.08 |
| Professional Field Vocabulary of Switch Machine | Number of Term |
|---|---|
| Normal position of switch | 234 |
| Reverse position of switch | 128 |
| Switch blocked | 341 |
| Electro-hydraulic switch machine | 230 |
| Electro-pneumatic switch machine | 412 |
| Switch restored | 145 |
| Switch connecting rod | 189 |
| Switch point closure | 367 |
| Switch closure adjustment | 120 |
| Loss of indication of a switch | 156 |
| Switch locking | 78 |
| …… | …… |
| Experimental Environment | Environment Configuration |
|---|---|
| Operating system | Linux (manufacturer: IBM, Armonk, NY, USA) |
| CPU | Intel (R) Core (TM) (manufacturer: Intel, Santa Clara, CA, USA) |
| GPU | NVIDIA GeForce RTX3090Ti (manufacturer: NVIDIA Corporation, Santa Clara, CA, USA) |
| CUDA | Version No.: 11.2.162 |
| Memory | 64 GB |
| Programming language | Python 3.7 |
| Word segmentation tool | Jieba |
| Word Vector Training Toolkit | Gensim (Version No. 4.1.0) |
| Deep learning framework | TensorFlow-GPU (Version No. 1.14.0) |
| C10 | 136 |
| C11 | 58 |
| C12 | 247 |
| Data Category | Positive Example of Projection | Negative Example of Projection |
|---|---|---|
| Positive example of reality | TP | FN |
| Negative example of reality | FP | TN |
| Models | Precision | Recall | F1 | Processing Speed/s |
|---|---|---|---|---|
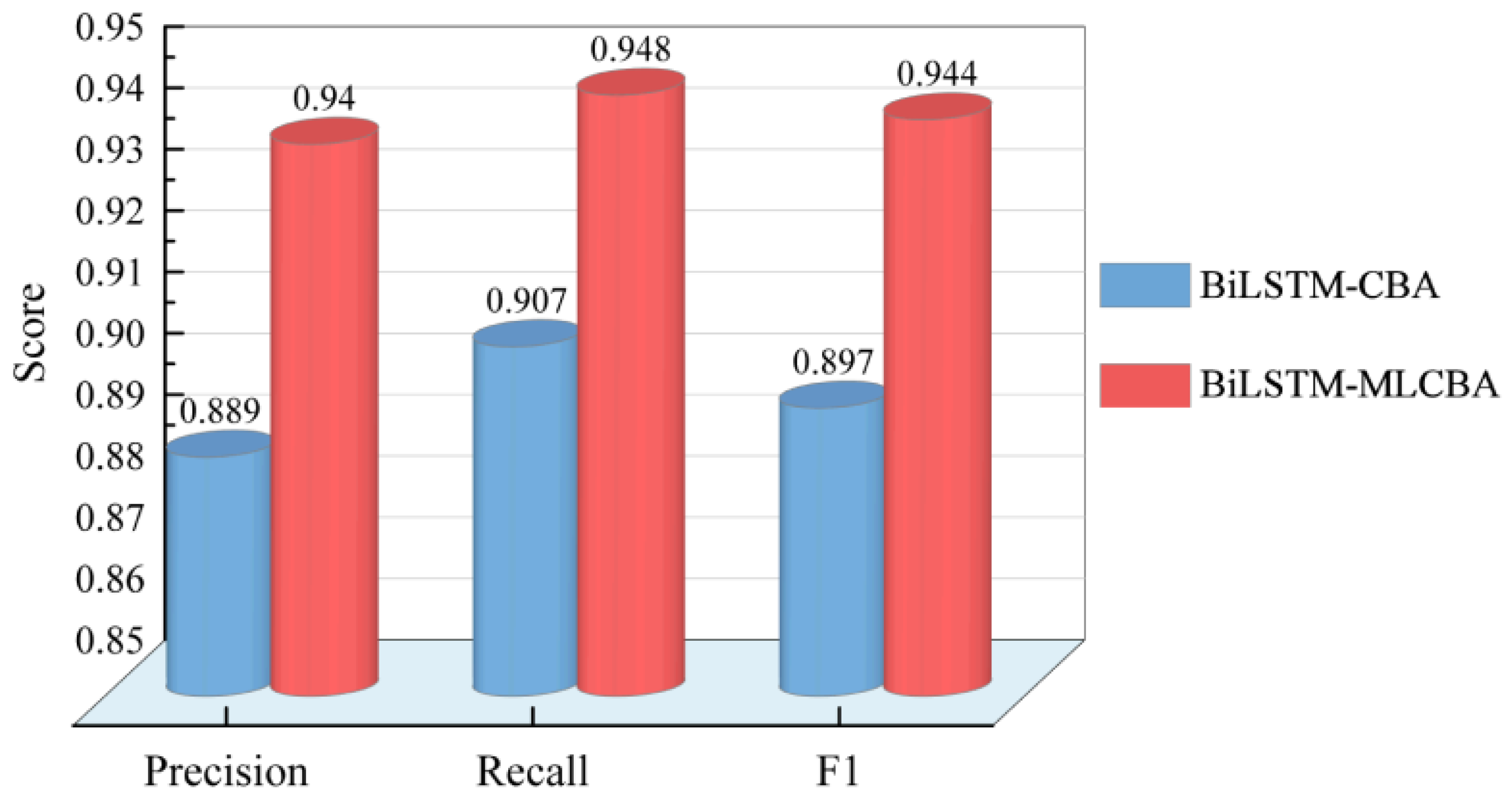
| BiLSTM-MLCBA | 0.9404 | 0.9478 | 0.9441 | 1.12 |
| BiLSTM-NB | 0.9235 | 0.8911 | 0.9070 | 0.98 |
| BiLSTM-KNN | 0.8989 | 0.8466 | 0.8719 | 1.38 |
| BiLSTM-C4.5 | 0.8543 | 0.8481 | 0.8512 | 1.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, H.; Hu, N.; Lu, R.; Yuan, T.; Zhao, Z.; Bai, W.; Lin, Q. Fault Diagnosis of a Switch Machine to Prevent High-Speed Railway Accidents Combining Bi-Directional Long Short-Term Memory with the Multiple Learning Classification Based on Associations Model. Machines 2023, 11, 1027. https://doi.org/10.3390/machines11111027
Lin H, Hu N, Lu R, Yuan T, Zhao Z, Bai W, Lin Q. Fault Diagnosis of a Switch Machine to Prevent High-Speed Railway Accidents Combining Bi-Directional Long Short-Term Memory with the Multiple Learning Classification Based on Associations Model. Machines. 2023; 11(11):1027. https://doi.org/10.3390/machines11111027
Chicago/Turabian StyleLin, Haixiang, Nana Hu, Ran Lu, Tengfei Yuan, Zhengxiang Zhao, Wansheng Bai, and Qi Lin. 2023. "Fault Diagnosis of a Switch Machine to Prevent High-Speed Railway Accidents Combining Bi-Directional Long Short-Term Memory with the Multiple Learning Classification Based on Associations Model" Machines 11, no. 11: 1027. https://doi.org/10.3390/machines11111027
APA StyleLin, H., Hu, N., Lu, R., Yuan, T., Zhao, Z., Bai, W., & Lin, Q. (2023). Fault Diagnosis of a Switch Machine to Prevent High-Speed Railway Accidents Combining Bi-Directional Long Short-Term Memory with the Multiple Learning Classification Based on Associations Model. Machines, 11(11), 1027. https://doi.org/10.3390/machines11111027