
Assistive Self-Driving Car Networks to Provide Safe Road Ecosystems for Disabled Road Users

 ,
,  ,
,  and
and 
Abstract
:1. Introduction
- The definition of the ASC framework is composed of modules for D-VRU recognition, hand gesture interaction and its corresponding feedback, and a network architecture for self-driving car interaction.
- The definition, challenges, and requirements for an ASC to improve its interaction with D-VRUs.
- A mechanism based on NN and a wearable device that accurately identifies pedestrians with disabilities and their specific type of impairment to enable interaction with the pedestrian through an appropriate interface for feedback.
- An algorithm based on recurrent NN that identifies hand gestures as a means for the interaction between the D-VRU and the self-driving assistive car.
2. State of the Art
2.1. Current Pedestrian–Car Communication
2.2. Pedestrian–Self-Driving Car Communication
2.3. Requirements for Pedestrian–Self-Driving Car Communication
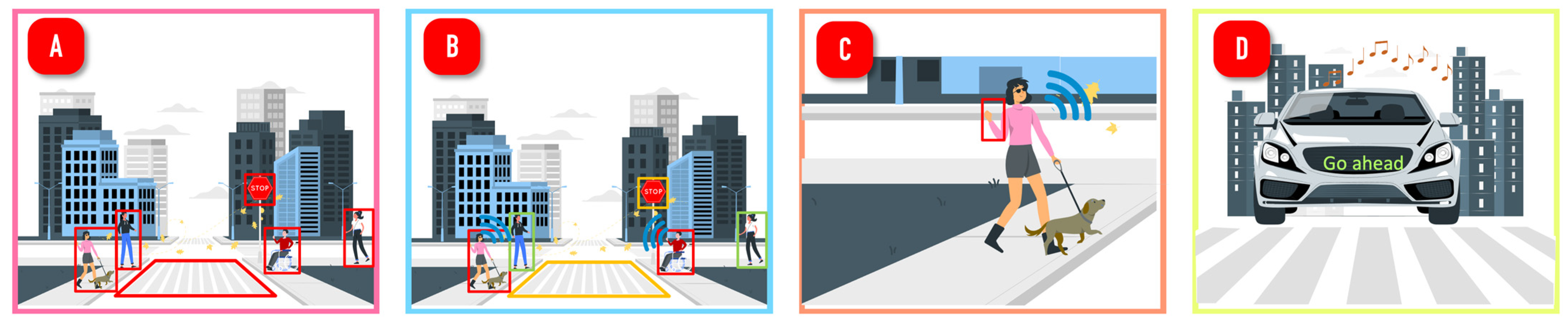
2.4. Pedestrian Detection
3. Materials and Methods
3.1. Assistive Self-Driving Cars
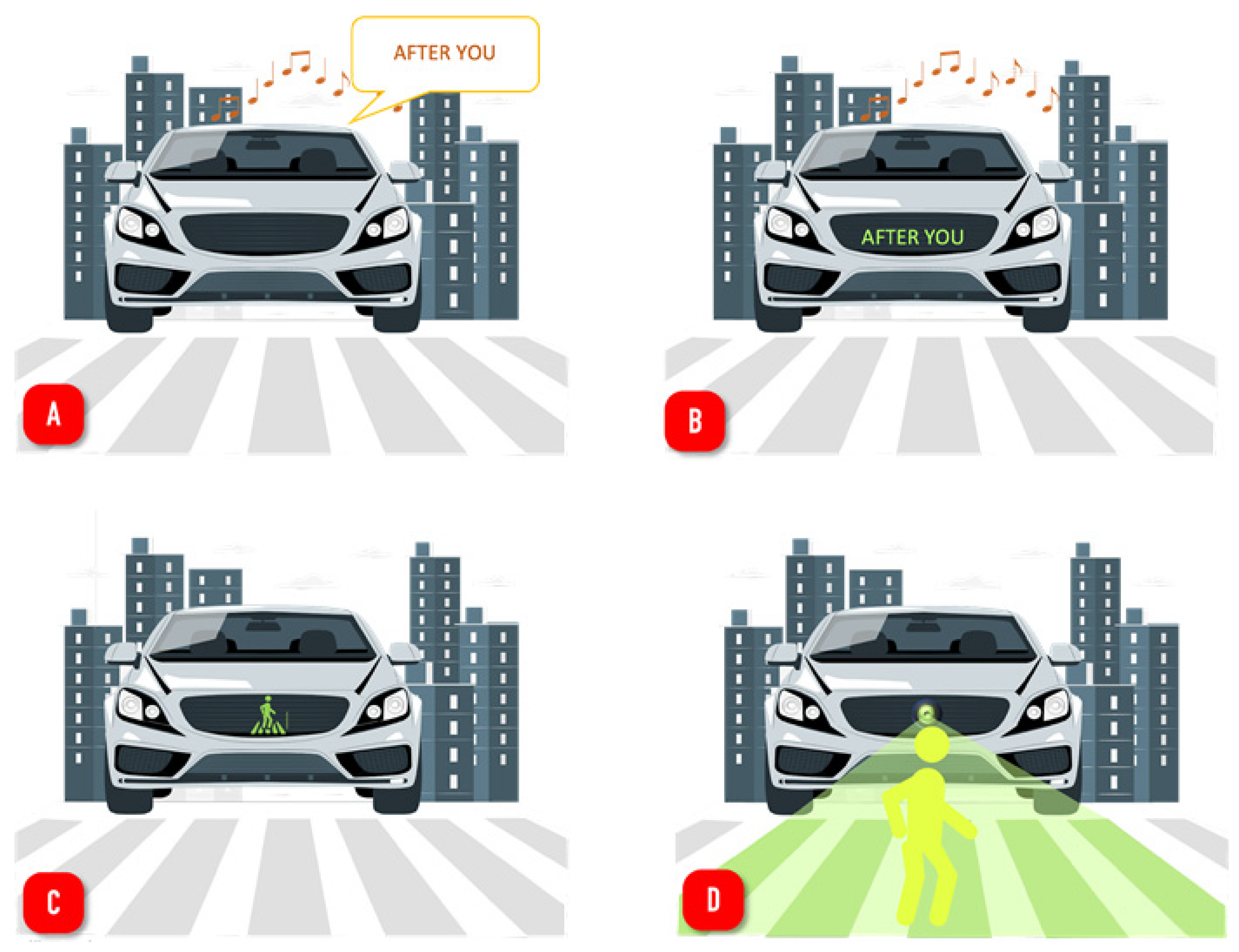
3.2. Scenario
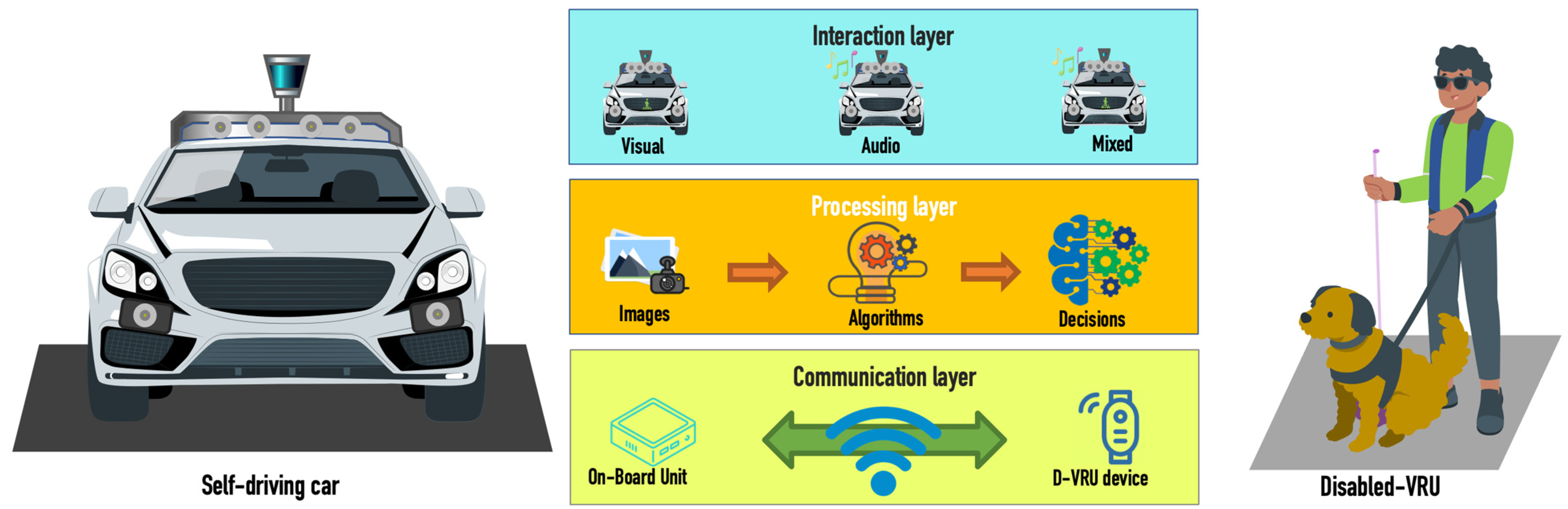
3.3. Proposed Architecture
3.3.1. Communication Layer
3.3.2. Processing Layer
3.3.3. Interaction Layer
3.3.4. Validation System
3.4. D-VRU Device
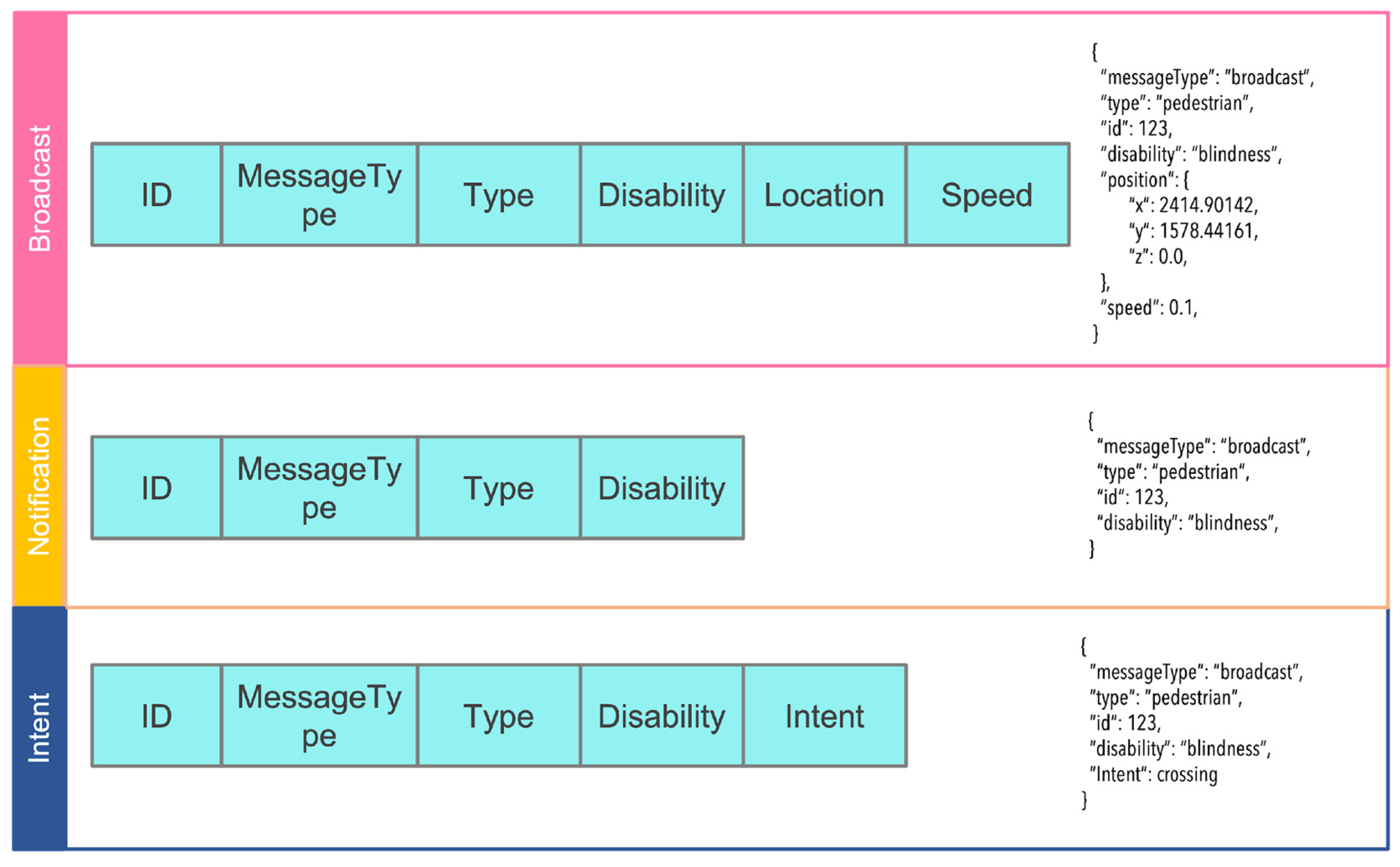
Message Structure
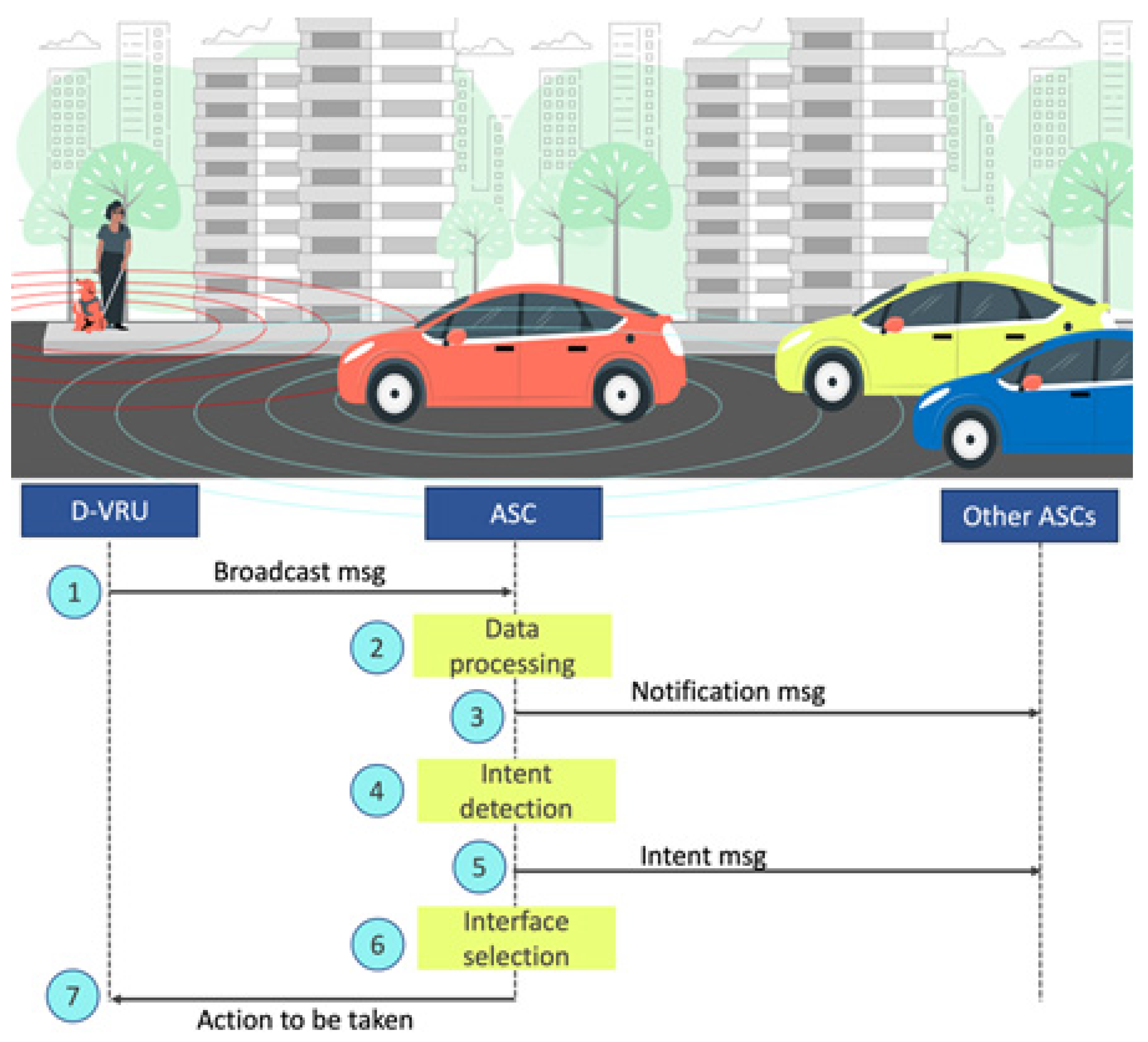
3.5. D-VRU/ASC Interaction Process
- The disabled pedestrian sends a “broadcast” message to assistive self-driving cars near his environment every second.
- Nearby ASCs receive and process the broadcast messages.
- All ASCs receiving the “broadcast” message send “notification” messages so that vehicles behind them out of range of the D-VRU’s broadcast message can be alerted to the presence of a person with a disability. The “notification” message informs vehicles out of range of the presence of a person with a disability at the intersection. To extend the range of the notification, the receiving vehicles forward the message. After three hops, the message is discarded.
- When the car detects the D-VRU, the hand gesture recognition process starts to identify the pedestrian’s intention.
- When the ASC detects the intent of the D-VRU, it sends an “intent” message to nearby vehicles. This message indicates what action the pedestrian will take.
- The ASC chooses the interaction interface that best suits the physical conditions of the D-VRU.
- Finally, the ASC notifies the D-VRU, via the appropriate interface, of the action to be taken to establish a secure environment.
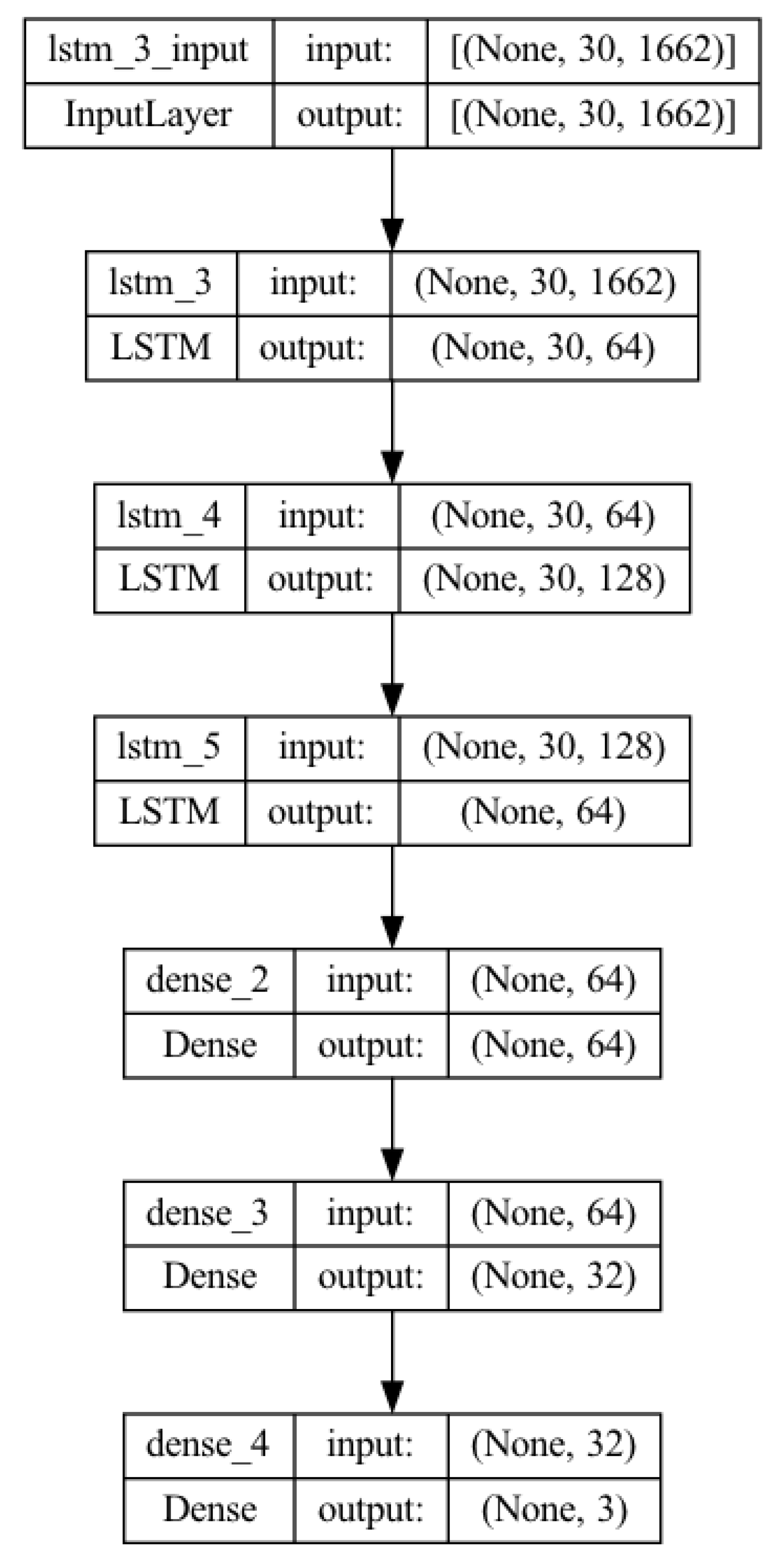
3.6. D-VRU Detection Algorithm
3.7. Hand Gesture Detection Algorithm
4. Results and Discussions
4.1. Evaluation Metrics
4.2. Data Validation
4.3. ASC–D-VRU Interaction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Road Traffic Injuries. Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries (accessed on 9 February 2023).
- European Commission. ITS & Vulnerable Road Users. 2015. Available online: https://transport.ec.europa.eu/transport-themes/intelligent-transport-systems/road/action-plan-and-directive/its-vulnerable-road-users_en (accessed on 11 October 2023).
- Schwartz, N.; Buliung, R.; Daniel, A.; Rothman, L. Disability and pedestrian road traffic injury: A scoping review. Health Place 2022, 77, 102896. [Google Scholar] [CrossRef] [PubMed]
- Kraemer, J.D.; Benton, C.S. Disparities in road crash mortality among pedestrians using wheelchairs in the USA: Results of a capture–recapture analysis. BMJ Open 2015, 5, e008396. [Google Scholar] [CrossRef] [PubMed]
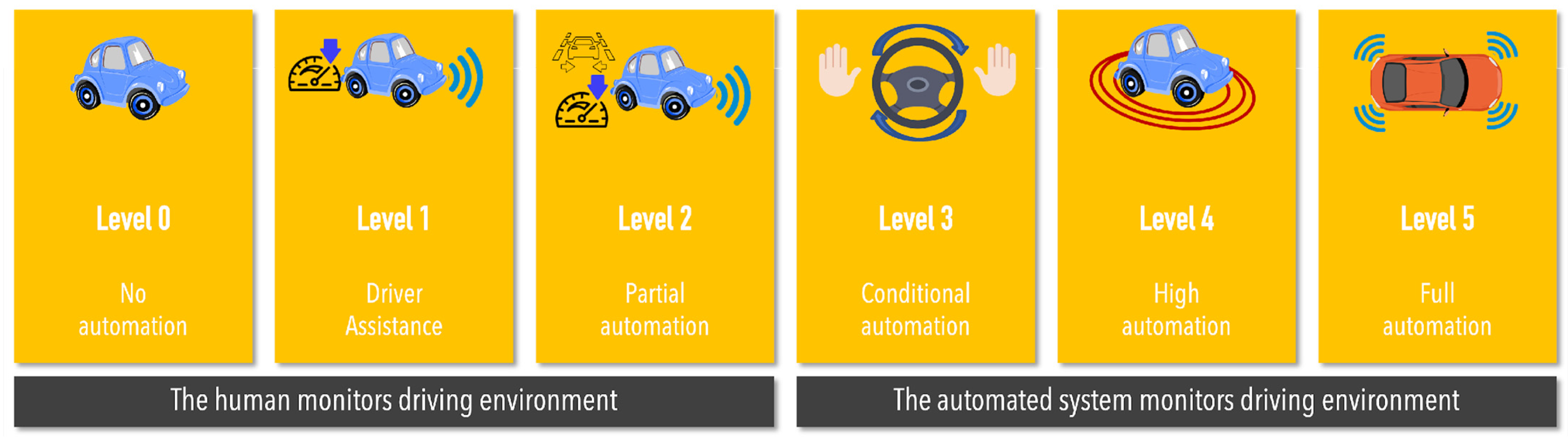
- Society of Automotive Engineers. Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles. 2014. Available online: https://www.sae.org/standards/content/j3016_202104/ (accessed on 11 October 2023).
- Lahijanian, M.; Kwiatkowska, M. Social Trust: A Major Challenge for the Future of Autonomous Systems; AAAI Association for the Advancement of Artificial Intelligence: Palo Alto, CA, USA, 2016. [Google Scholar]
- Rasouli, A.; Tsotsos, J.K. Autonomous Vehicles That Interact With Pedestrians: A Survey of Theory and Practice. IEEE Trans. Intell. Transp. Syst. 2020, 21, 900–918. [Google Scholar] [CrossRef]
- Kaur, K.; Rampersad, G. Trust in driverless cars: Investigating key factors influencing the adoption of driverless cars. J. Eng. Technol. Manag. 2018, 48, 87–96. [Google Scholar] [CrossRef]
- Ragesh, N.K.; Rajesh, R. Pedestrian Detection in Automotive Safety: Understanding State-of-the-Art. IEEE Access 2019, 7, 47864–47890. [Google Scholar] [CrossRef]
- Reyes-Muñoz, A.; Guerrero-Ibáñez, J. Vulnerable Road Users and Connected Autonomous Vehicles Interaction: A Survey. Sensors 2022, 22, 4614. [Google Scholar] [CrossRef]
- ATiA. What Is AT? Assistive Technology Industry Association: Chicago, IL, USA, 2015; Available online: https://www.atia.org/home/at-resources/what-is-at/ (accessed on 11 October 2023).
- Zhou, Y.; Li, G.; Wang, L.; Li, S.; Zong, W. Smartphone-based Pedestrian Localization Algorithm using Phone Camera and Location Coded Targets. In Proceedings of the 2018 Ubiquitous Positioning, Indoor Navigation and Location-Based Services (UPINLBS), Wuhan, China, 22–23 March 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Yang, L.; Zou, J.; Li, Y.; Rizos, C. Seamless pedestrian navigation augmented by walk status detection and context features. In Proceedings of the 2016 Fourth International Conference on Ubiquitous Positioning, Indoor Navigation and Location Based Services (UPINLBS), Shanghai, China, 2–4 November 2016; pp. 20–28. [Google Scholar] [CrossRef]
- Shit, R.C.; Sharma, S.; Puthal, D.; James, P.; Pradhan, B.; van Moorsel, A.; Zomaya, A.Y.; Ranjan, R. Ubiquitous Localization (UbiLoc): A Survey and Taxonomy on Device Free Localization for Smart World. IEEE Commun. Surv. Tutor. 2019, 21, 3532–3564. [Google Scholar] [CrossRef]
- Chen, L.; Lin, S.; Lu, X.; Cao, D.; Wu, H.; Guo, C.; Liu, C.; Wang, F.-Y. Deep Neural Network Based Vehicle and Pedestrian Detection for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3234–3246. [Google Scholar] [CrossRef]
- Zheng, G.; Chen, Y. A review on vision-based pedestrian detection. In Proceedings of the 2012 IEEE Global High Tech Congress on Electronics, Shenzhen, China, 18–20 November 2012; pp. 49–54. [Google Scholar] [CrossRef]
- Guéguen, N.; Meineri, S.; Eyssartier, C. A pedestrian’s stare and drivers’ stopping behavior: A field experiment at the pedestrian crossing. Saf. Sci. 2015, 75, 87–89. [Google Scholar] [CrossRef]
- Rothenbücher, D.; Li, J.; Sirkin, D.; Mok, B.; Ju, W. Ghost driver: A field study investigating the interaction between pedestrians and driverless vehicles. In Proceedings of the IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), New York, NY, USA, 26–31 August 2016. [Google Scholar] [CrossRef]
- Merat, N.; Louw, T.; Madigan, R.; Wilbrink, M.; Schieben, A. What externally presented information do VRUs require when interacting with fully Automated Road Transport Systems in shared space? Accid. Anal. Prev. 2018, 118, 244–252. [Google Scholar] [CrossRef]
- Reig, S.; Norman, S.; Morales, C.G.; Das, S.; Steinfeld, A.; Forlizzi, J. A Field Study of Pedestrians and Autonomous Vehicles. In Proceedings of the AutomotiveUI ’18: The 10th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Toronto, ON, Canada, 23–25 September 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 198–209. [Google Scholar] [CrossRef]
- Löcken, A.; Golling, C.; Riener, A. How Should Automated Vehicles Interact with Pedestrians? A Comparative Analysis of Interaction Concepts in Virtual Reality. In Proceedings of the AutomotiveUI ’19 the 11th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Utrecht, The Netherlands, 21–25 September 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 262–274. [Google Scholar] [CrossRef]
- Vinkhuyzen, E.; Cefkin, M. Developing Socially Acceptable Autonomous Vehicles. Ethnogr. Prax. Ind. Conf. Proc. 2016, 2016, 522–534. [Google Scholar] [CrossRef]
- Habibovic, A.; Fabricius, V.; Anderson, J.; Klingegard, M. Communicating Intent of Automated Vehicles to Pedestrians. Front. Psychol. 2018, 9, 1336. [Google Scholar] [CrossRef] [PubMed]
- Habibovic, A.; Andersson, J.; Lundgren, V.M.; Klingegård, M.; Englund, C.; Larsson, S. External Vehicle Interfaces for Communication with Other Road Users? In Road Vehicle Automation 5; Meyer, G., Beiker, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 91–102. [Google Scholar]
- Strauss, T. Breaking down the Language Barrier between Autonomous Cars and Pedestrians. 2018. Available online: https://uxdesign.cc/wave-breaking-down-the-language-barrier-between-autonomous-cars-and-pedestrians-autonomy-tech-a8ba1f6686 (accessed on 3 May 2022).
- Autocar. The Autonomous Car that Smiles at Pedestrians. 2016. Available online: https://www.autocar.co.uk/car-news/new-cars/autonomous-car-smiles-pedestrians (accessed on 3 May 2022).
- Kitayama, S.; Kondou, T.; Ohyabu, H.; Hirose, M. Display System for Vehicle to Pedestrian Communication. SAE Technical paper 2017-01-0075. 2017. Available online: https://www.sae.org/publications/technical-papers/content/2017-01-0075/ (accessed on 11 October 2023).
- Deb, S.; Strawderman, L.J.; Carruth, D.W. Investigating pedestrian suggestions for external features on fully autonomous vehicles: A virtual reality experiment. Transp. Res. Part F Traffic Psychol. Behav. 2018, 59, 135–149. [Google Scholar] [CrossRef]
- Costa, G. Designing Framework for Human-Autonomous Vehicle Interaction. Master’s Thesis, Keio University Graduate School of Media Design, Yokohama, Japan, 2017. [Google Scholar]
- Chang, C.-M.; Toda, K.; Sakamoto, D.; Igarashi, T. Eyes on a Car: An Interface Design for Communication between an Autonomous Car and a Pedestrian. In Proceedings of the AutomotiveUI ’17: The 9th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Oldenburg, Germany, 24–27 September 2017; p. 73. [Google Scholar] [CrossRef]
- Ochiai, Y.; Toyoshima, K. Homunculus: The Vehicle as Augmented Clothes. In Proceedings of the AH ’11: The 2nd Augmented Human International Conference, Tokyo, Japan, 13 March 2011; Association for Computing Machinery: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Jaguar Land Rover. The Virtual Eyes Have It. 2018. Available online: https://www.jaguarlandrover.com/2018/virtual-eyes-have-it (accessed on 16 October 2023).
- Le, M.C.; Do, T.-D.; Duong, M.-T.; Ta, T.-N.-M.; Nguyen, V.-B.; Le, M.-H. Skeleton-based Recognition of Pedestrian Crossing Intention using Attention Graph Neural Networks. In Proceedings of the 2022 International Workshop on Intelligent Systems (IWIS), Ulsan, Republic of Korea; 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Mínguez, R.Q.; Alonso, I.P.; Fernández-Llorca, D.; Sotelo, M.Á. Pedestrian Path, Pose, and Intention Prediction Through Gaussian Process Dynamical Models and Pedestrian Activity Recognition. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1803–1814. [Google Scholar] [CrossRef]
- Fang, Z.; López, A.M. Intention Recognition of Pedestrians and Cyclists by 2D Pose Estimation. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4773–4783. [Google Scholar] [CrossRef]
- Perdana, M.I.; Anggraeni, W.; Sidharta, H.A.; Yuniarno, E.M.; Purnomo, M.H. Early Warning Pedestrian Crossing Intention from Its Head Gesture using Head Pose Estimation. In Proceedings of the 2021 International Seminar on Intelligent Technology and Its Applications (ISITIA), Surabaya, Indonesia, 21–22 July 2021; pp. 402–407. [Google Scholar] [CrossRef]
- Rehder, E.; Kloeden, H.; Stiller, C. Head detection and orientation estimation for pedestrian safety. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 2292–2297. [Google Scholar] [CrossRef]
- Quan, R.; Zhu, L.; Wu, Y.; Yang, Y. Holistic LSTM for Pedestrian Trajectory Prediction. IEEE Trans. Image Process. 2021, 30, 3229–3239. [Google Scholar] [CrossRef]
- Huang, Z.; Hasan, A.; Shin, K.; Li, R.; Driggs-Campbell, K. Long-Term Pedestrian Trajectory Prediction Using Mutable Intention Filter and Warp LSTM. IEEE Robot. Autom. Lett. 2021, 6, 542–549. [Google Scholar] [CrossRef]
- Mahadevan, K.; Somanath, S.; Sharlin, E. Communicating Awareness and Intent in Autonomous Vehicle-Pedestrian Interaction. In Proceedings of the CHI ’18 the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–12. [Google Scholar] [CrossRef]
- Jaber, A.K.; Abdel-Qader, I. Hybrid Histograms of Oriented Gradients-compressive sensing framework feature extraction for face recognition. In Proceedings of the 2016 IEEE International Conference on Electro Information Technology (EIT), Grand Forks, ND, USA, 19–21 May 2016; pp. 442–447. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.; Li, J.; Li, J.; Lou, X. Histogram of Oriented Gradients Feature Extraction Without Normalization. In Proceedings of the 2020 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Ha Long, Vietnam, 8–10 December 2020; pp. 252–255. [Google Scholar] [CrossRef]
- Sasongko, A.; Sahbani, B. VLSI Architecture for Fine Grained Pipelined Feature Extraction using Histogram of Oriented Gradient. In Proceedings of the 2019 IEEE 7th Conference on Systems, Process and Control (ICSPC), Melaka, Malaysia, 13–14 December 2019; pp. 143–148. [Google Scholar] [CrossRef]
- Liu, G.; Liu, W.; Chen, X. An Improved Pairwise Rotation Invariant Co-occurrence Local Binary Pattern Method for Texture Feature Extraction. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 29–31 March 2019; pp. 431–436. [Google Scholar] [CrossRef]
- Kaur, N.; Nazir, N. Manik. A Review of Local Binary Pattern Based texture feature extraction. In Proceedings of the 2021 9th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 3–4 September 2021; pp. 1–4. [CrossRef]
- Ansari, M.D.; Ghrera, S.P. Feature extraction method for digital images based on intuitionistic fuzzy local binary pattern. In Proceedings of the 2016 International Conference System Modeling & Advancement in Research Trends (SMART), Moradabad, India, 25–27 November 2016; pp. 345–349. [Google Scholar] [CrossRef]
- Li, J.; Wong, H.-C.; Lo, S.-L.; Xin, Y. Multiple Object Detection by a Deformable Part-Based Model and an R-CNN. IEEE Signal Process. Lett. 2018, 25, 288–292. [Google Scholar] [CrossRef]
- Jie, G.; Honggang, Z.; Daiwu, C.; Nannan, Z. Object detection algorithm based on deformable part models. In Proceedings of the 2014 4th IEEE International Conference on Network Infrastructure and Digital Content, Beijing, China, 19–21 September 2014; pp. 90–94. [Google Scholar] [CrossRef]
- Tang, J.; Lin, Z.; Zhang, Y. Rapid Forward Vehicle Detection Based on Deformable Part Model. In Proceedings of the 2017 2nd International Conference on Multimedia and Image Processing (ICMIP), Wuhan, China, 17–19 March 2017; pp. 27–31. [Google Scholar] [CrossRef]
- Huang, K.; Li, J.; Liu, Y.; Chang, L.; Zhou, J. A Survey on Feature Point Extraction Techniques. In Proceedings of the 2021 18th International SoC Design Conference (ISOCC), Jeju Island, Republic of Korea, 6–9 October 2021; pp. 201–202. [Google Scholar] [CrossRef]
- Sajat, M.A.S.; Hashim, H.; Tahir, N.M. Detection of Human Bodies in Lying Position based on Aggregate Channel Features. In Proceedings of the 2020 16th IEEE International Colloquium on Signal Processing & Its Applications (CSPA), Langkawi, Malaysia, 28–29 February 2020; pp. 313–317. [Google Scholar] [CrossRef]
- Ragb, H.K.; Ali, R.; Asari, V. Aggregate Channel Features Based on Local Phase, Color, Texture, and Gradient Features for People Localization. In Proceedings of the 2019 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 July 2019; pp. 351–355. [Google Scholar] [CrossRef]
- Li, Y.; Cui, F.; Xue, X.; Chan, J.C.-W. Coarse-to-fine salient object detection based on deep convolutional neural networks. Signal Process. Image Commun. 2018, 64, 21–32. [Google Scholar] [CrossRef]
- Chen, E.; Tang, X.; Fu, B. A Modified Pedestrian Retrieval Method Based on Faster R-CNN with Integration of Pedestrian Detection and Re-Identification. In Proceedings of the 2018 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 16–17 July 2018; pp. 63–66. [Google Scholar] [CrossRef]
- Shi, P.; Wu, J.; Wang, K.; Zhang, Y.; Wang, J.; Yi, J. Research on Low-Resolution Pedestrian Detection Algorithms based on R-CNN with Targeted Pooling and Proposal. In Proceedings of the 2018 Eighth International Conference on Image Processing Theory, Tools and Applications (IPTA), Xi’an, China, 7–10 November 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zhao, Z.; Ma, J.; Ma, C.; Wang, Y. An Improved Faster R-CNN Algorithm for Pedestrian Detection. In Proceedings of the 2021 11th International Conference on Information Technology in Medicine and Education (ITME), Wuyishan, China, 19–21 November 2021; pp. 76–80. [Google Scholar] [CrossRef]
- Zhu, K.; Li, L.; Hu, D.; Chen, D.; Liu, L. An improved detection method for multi-scale and dense pedestrians based on Faster R-CNN. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Malbog, M.A. MASK R-CNN for Pedestrian Crosswalk Detection and Instance Segmentation. In Proceedings of the 2019 IEEE 6th International Conference on Engineering Technologies and Applied Sciences (ICETAS), Kuala Lumpur, Malaysia, 20–21 December 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Shen, G.; Jamshidi, F.; Dong, D.; ZhG, R. Metro Pedestrian Detection Based on Mask R-CNN and Spatial-temporal Feature. In Proceedings of the 2020 IEEE 3rd International Conference on Information Communication and Signal Processing (ICICSP), Shanghai, China, 12–15 September 2020; pp. 173–178. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- IEEE. IEEE Draft Guide for Architectural Framework and Application of Federated Machine Learning. In IEEE P3652.1/D6; IEEE: Piscataway, NJ, USA, 2020; pp. 1–70. [Google Scholar]
- Bonawitz, K.; Kairouz, P.; Mcmahan, B.; Ramage, D. Federated Learning and Privacy. Commun. ACM 2022, 65, 90–97. [Google Scholar] [CrossRef]
- Sommer, C.; German, R.; Dressler, F. Bidirectionally Coupled Network and Road Traffic Simulation for Improved IVC Analysis. IEEE Trans. Mob. Comput. 2011, 10, 3–15. [Google Scholar] [CrossRef]
- Guerrero-Ibañez, A.; Amezcua-Valdovinos, I.; Contreras-Castillo, J. Integration of Wearables and Wireless Technologies to Improve the Interaction between Disabled Vulnerable Road Users and Self-Driving Cars. Electronics 2023, 12, 3587. [Google Scholar] [CrossRef]
- U.S. Space Force. GPS Accuracy. Available online: https://www.gps.gov/systems/gps/performance/accuracy/ (accessed on 27 September 2023).
- Nozaki. Whitecane Dataset, Roboflow Universe. Roboflow, May 2022. Available online: https://universe.roboflow.com/nozaki/whitecane-mzmlr (accessed on 11 October 2023).
- Wheelchair Detection Dataset, Roboflow Universe. Roboflow, November 2021. Available online: https://universe.roboflow.com/2458761304-qq-com/wheelchair-detection (accessed on 11 October 2023).
- Jang, B.H. Visually impaired (whitecane). Available online: https://www.kaggle.com/datasets/jangbyeonghui/visually-impairedwhitecane (accessed on 24 April 2023).
- Yang, J.; Gui, A.; Wang, J.; Ma, J. Pedestrian Behavior Interpretation from Pose Estimation. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3110–3115. [Google Scholar] [CrossRef]
- Samant, A.P.; Warhade, K.; Gunale, K. Pedestrian Intent Detection using Skeleton-based Prediction for Road Safety. In Proceedings of the 2021 2nd International Conference on Advances in Computing, Communication, Embedded and Secure Systems (ACCESS), Ernakulam, India, 2–4 September 2021; pp. 238–242. [Google Scholar] [CrossRef]
- Saleh, K.; Hossny, M.; Nahavandi, S. Intent Prediction of Pedestrians via Motion Trajectories Using Stacked Recurrent Neural Networks. IEEE Trans. Intell. Veh. 2018, 3, 414–424. [Google Scholar] [CrossRef]
- Hand Signals. Available online: https://static.nhtsa.gov/nhtsa/downloads/NTI/Responsible_Walk-Bike_Activities/ComboLessons/L3Handouts/8009_HandSignals_122811_v1a.pdf (accessed on 16 April 2023).
- DVM. Hand Signals Guide. Available online: https://www.dmv.org/how-to-guides/hand-signals-guide.php (accessed on 16 April 2023).
- Shaotran, E.; Cruz, J.J.; Reddi, V.J. Gesture Learning For Self-Driving Cars. In Proceedings of the 2021 IEEE International Conference on Autonomous Systems (ICAS), Montreal, QC, Canada, 11–13 August 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Uçkun, F.A.; Özer, H.; Nurbaş, E.; Onat, E. Direction Finding Using Convolutional Neural Networks and Convolutional Recurrent Neural Networks. In Proceedings of the 2020 28th Signal Processing and Communications Applications Conference (SIU), Gaziantep, Turkey, 5–7 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Xiao, Y.; Keung, J. Improving Bug Localization with Character-Level Convolutional Neural Network and Recurrent Neural Network. In Proceedings of the 2018 25th Asia-Pacific Software Engineering Conference (APSEC), Nara, Japan, 4–7 December 2018; pp. 703–704. [Google Scholar] [CrossRef]
- Podlesnykh, I.A.; Bakhtin, V.V. Mathematical Model of a Recurrent Neural Network for Programmable Devices Focused on Fog Computing. In Proceedings of the 2022 Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus), Saint Petersburg, Russia, 25–28 January 2022; pp. 395–397. [Google Scholar] [CrossRef]
- Song, J.; Zhao, Y. Multimodal Model Prediction of Pedestrian Trajectories Based on Graph Convolutional Neural Networks. In Proceedings of the 2022 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Xi’an, China, 28–30 October 2022; pp. 271–275. [Google Scholar] [CrossRef]
- Zha, B.; Koroglu, M.T.; Yilmaz, A. Trajectory Mining for Localization Using Recurrent Neural Network. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; pp. 1329–1332. [Google Scholar] [CrossRef]
- Ono, T.; Kanamaru, T. Prediction of pedestrian trajectory based on long short-term memory of data. In Proceedings of the 2021 21st International Conference on Control, Automation and Systems (ICCAS), Jeju Island, Republic of Korea, 12–15 October 2021; pp. 1676–1679. [Google Scholar] [CrossRef]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.L.; Yong, M.G.; Lee, J.; et al. MediaPipe: A Framework for Building Perception Pipelines. arXiv 2019, arXiv:1906.08172. [Google Scholar]
- Khan, I.; Zhang, X.; Rehman, M.; Ali, R. A Literature Survey and Empirical Study of Meta-Learning for Classifier Selection. IEEE Access 2020, 8, 10262–10281. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Description |
|---|---|
| Distracted road users | A type of pedestrian walking on the road but is distracted by an additional activity (such as using a cell phone, conversing with another person, or thinking about something else). |
| Road users inside the vehicle | Category refers to the occupants of an automated or a conventional vehicle. |
| Special road users | Pedestrians with very low walking speeds, such as older people and children, are included in this category. |
| Users of transport devices | Users who use transport devices such as skates, scooters, roller skis or skates, and kick sleds or kick sleds equipped with wheels. |
| Animals | Refer to animals within the driving zone, including dogs, horses, and cats. |
| Road users with disabilities | People who move within the driving zone and have a disability, such as blindness, deafness, or wheelchair users. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guerrero-Ibañez, J.; Contreras-Castillo, J.; Amezcua-Valdovinos, I.; Reyes-Muñoz, A. Assistive Self-Driving Car Networks to Provide Safe Road Ecosystems for Disabled Road Users. Machines 2023, 11, 967. https://doi.org/10.3390/machines11100967
Guerrero-Ibañez J, Contreras-Castillo J, Amezcua-Valdovinos I, Reyes-Muñoz A. Assistive Self-Driving Car Networks to Provide Safe Road Ecosystems for Disabled Road Users. Machines. 2023; 11(10):967. https://doi.org/10.3390/machines11100967
Chicago/Turabian StyleGuerrero-Ibañez, Juan, Juan Contreras-Castillo, Ismael Amezcua-Valdovinos, and Angelica Reyes-Muñoz. 2023. "Assistive Self-Driving Car Networks to Provide Safe Road Ecosystems for Disabled Road Users" Machines 11, no. 10: 967. https://doi.org/10.3390/machines11100967
APA StyleGuerrero-Ibañez, J., Contreras-Castillo, J., Amezcua-Valdovinos, I., & Reyes-Muñoz, A. (2023). Assistive Self-Driving Car Networks to Provide Safe Road Ecosystems for Disabled Road Users. Machines, 11(10), 967. https://doi.org/10.3390/machines11100967