1. Introduction
Insulators play a key role in the electrical insulation and mechanical fixation of overhead transmission lines. They can withstand high voltages for long periods and occasionally encounter natural disasters. Therefore, timely inspection and maintenance are required to ensure the normal operation of insulators [
1]. Given that transmission lines are being laid more and more widely, the traditional manual approach to inspecting insulators requires considerable human resources, and the inspection efficiency is low. The use of new line inspection equipment, such as unmanned aerial vehicles (UAV) to collect insulator images, and computer vision algorithms to identify insulators and insulator defects has become a new mode of inspection [
2,
3].
Early computer vision algorithms were primarily based on using the geometric features of insulators represented in image pixel values to identify insulator defects. These kinds of algorithms firstly highlight the insulator information based on the image processing method and then input the processed image data into the neural network to discriminate the condition of the insulator. Wang et al. [
4] extracted edge features based on a wavelet method, and the thickness of ice coating insulators was determined according to the number of pixels between ice edges. Yan et al. [
5] detected the water bead edge of insulators based on the Canny operator, and the hydrophobicity of water on insulators was identified with a classification algorithm. Li et al. [
6] studied insulator edge detection based on the Canny operator optimized using a two-dimensional maximum entropy threshold, which effectively extracted the edge information of insulator images and improved the accuracy of insulator crack detection. However, the insulator images used in these methods required that the insulator objects occupy a large proportion of images and are poorly applicable to UAV aerial images with a large number of objects and diverse scales; therefore, the application of the methods described above remains relatively limited in practice.
Deep learning object detection algorithms take the complete image as input, carry out image feature extraction and object prediction through a convolutional neural network (CNN) [
7], and can output the position of insulators and defects in the image, which is very easy for transmission line operation and maintenance personnel to discriminate the condition of insulators. Deep learning object detection algorithms are more suitable for insulator and defect detection scenarios with many small-scale objects and complex backgrounds; therefore, research on using these methods has been widely conducted in recent years. Deep learning object detection algorithms can be largely divided into two categories. The first includes two-stage object detection algorithms represented by faster region convolutional neural network (Faster R-CNN) [
8], which propose suggestion boxes through a region proposal network in the first stage and obtain the object detection results based on suggestion boxes in the second stage. The second includes single-stage object detection algorithms such as single-shot multibox detector (SSD) [
9] and you only look once (YOLO) [
10,
11,
12,
13], which omit the step of proposing suggestion boxes and predict object box results based on anchors alone. The detection speed of single-stage object algorithms is generally higher than that of two-stage object algorithms. These algorithms [
14,
15,
16] have been adopted to study the detection of insulators and defects, and satisfactory detection results were obtained through adaptive adjustment of the detection models.
Edge computing is a method of processing data near the source. It was first proposed by Akamai in 1998 to solve the problem of network congestion [
17]. In 2016, Shi et al. [
18] provided a widely recognized definition of edge computing as referring to the enabling technologies allowing computation to be performed at the edge of the network on downstream data on behalf of cloud services and upstream data on behalf of Internet of Things (IoT) services. Because edge computing has the advantages of avoiding large-scale data transmission and centralized processing, image data processing is gradually shifting from cloud servers to edge computing devices [
17,
19]. However, owing to the limited computing and storage resources of edge computing devices, they cannot implement detection models with large numbers of parameters and high computational complexity. Hence, higher requirements for lightweight operation have been proposed for detection models [
20]. The detection accuracy of lightweight detection models generally decreases compared to the more computationally intensive methods. Thus, it is important to obtain a detection model with both accuracy and rapidity on edge computing devices.
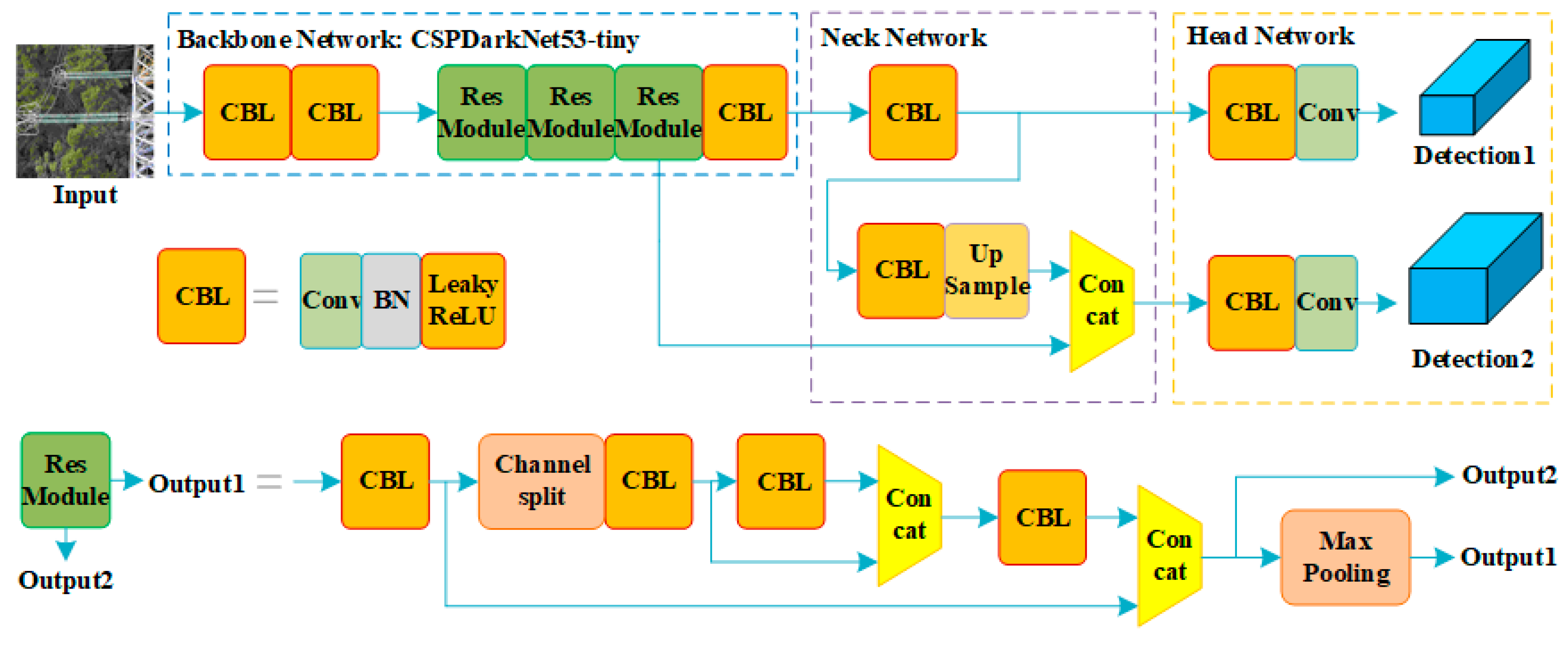
YOLOv4-tiny [
21] is a representative lightweight object-detection model in the YOLO series. It performs detection relatively rapidly on edge computing devices, but its detection accuracy is generally lower than that of heavier object detection models. In this study, we propose an improved detection model based on YOLOv4-tiny designed to maintain high detection speed on edge computing devices to improve detection accuracy. In order to obtain the insulator and defect detection model with accuracy and rapidity on the edge computing device, we mainly improved YOLOv4-tiny in terms of the following three aspects:
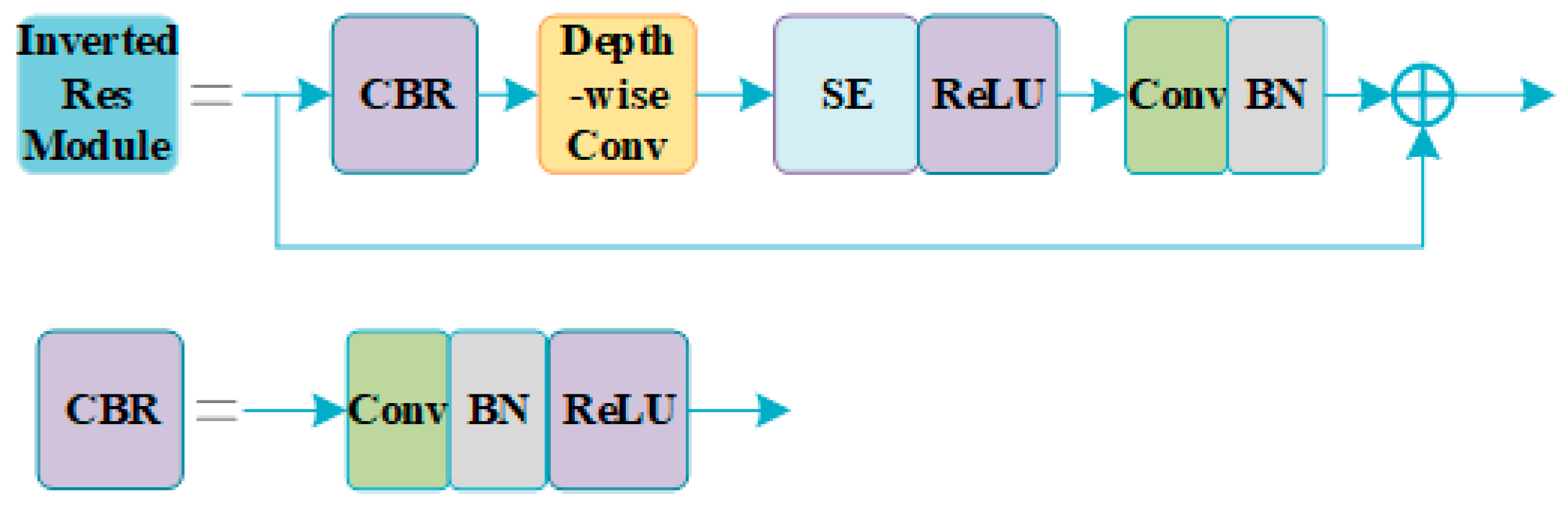
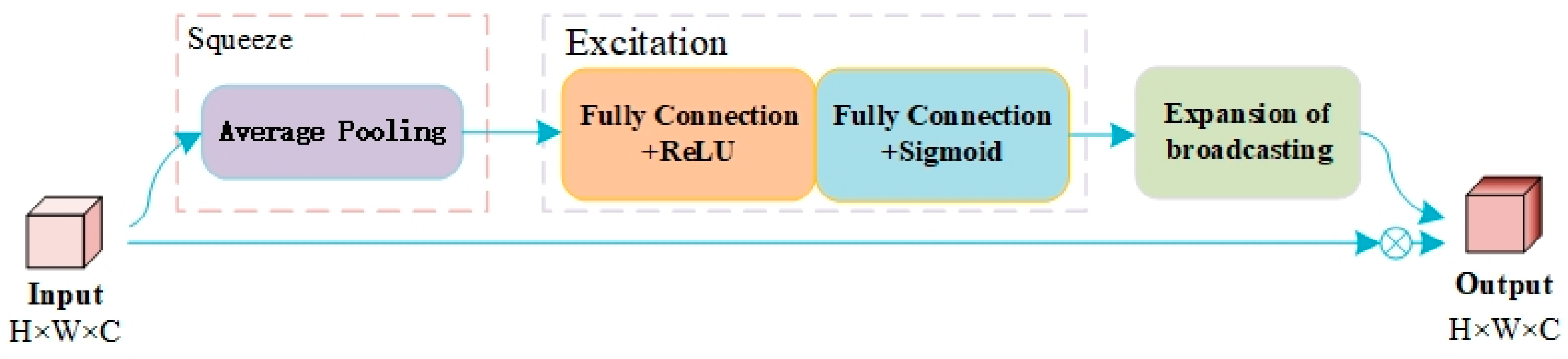
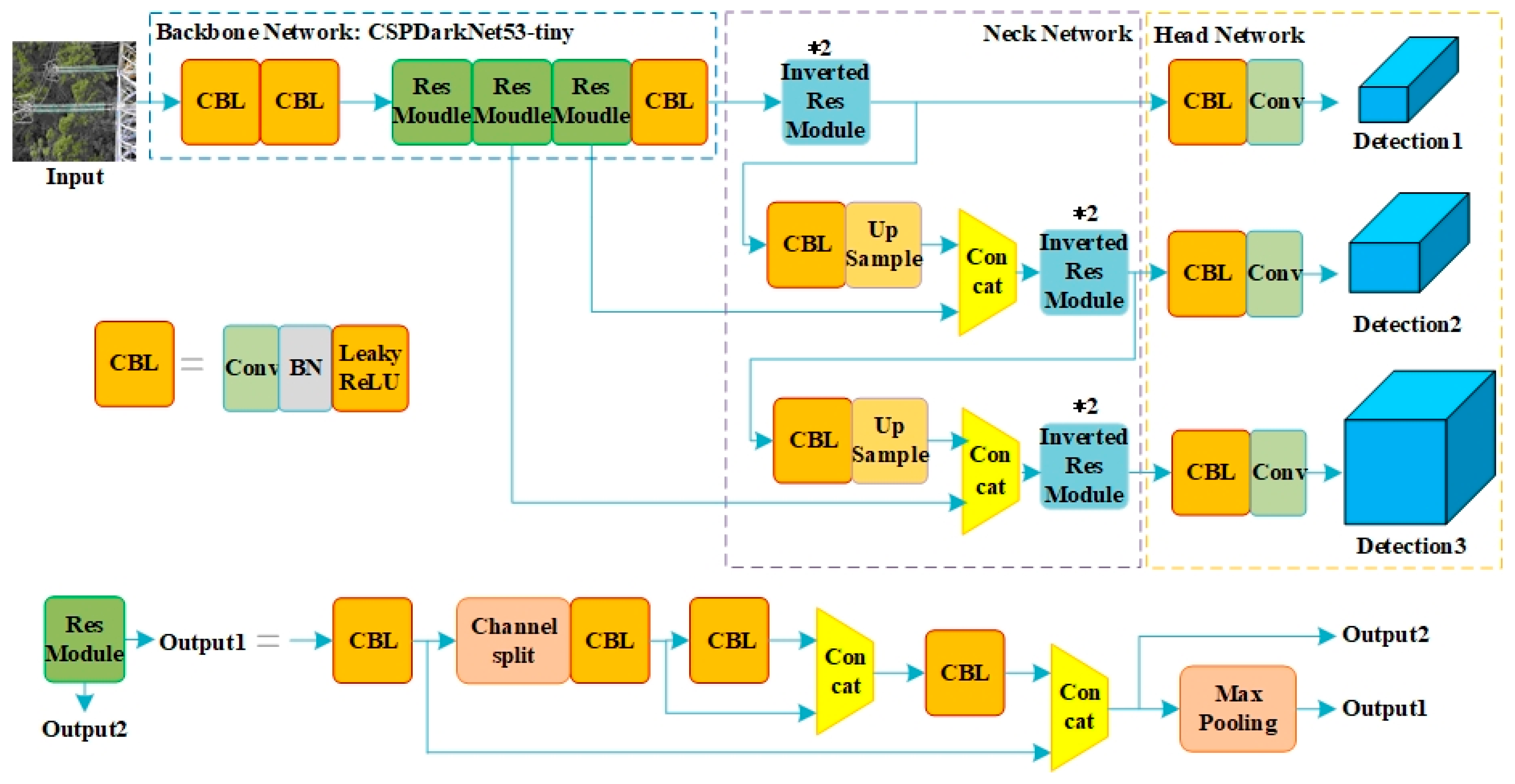
(1) Considering the problem of positioning deviation owing to the thin neck network structure, two serial inverted residual modules were used as the neck feature fusion modules of YOLOv4-tiny to enhance the feature fusion ability of the backbone network.
(2) Considering YOLOv4-tiny’s tendency to miss defect objects or detect them incorrectly, a detection output head suitable for small-scale objects was added to the original network structure, and the detection accuracy of small defects was improved without affecting detection accuracy for large insulators.
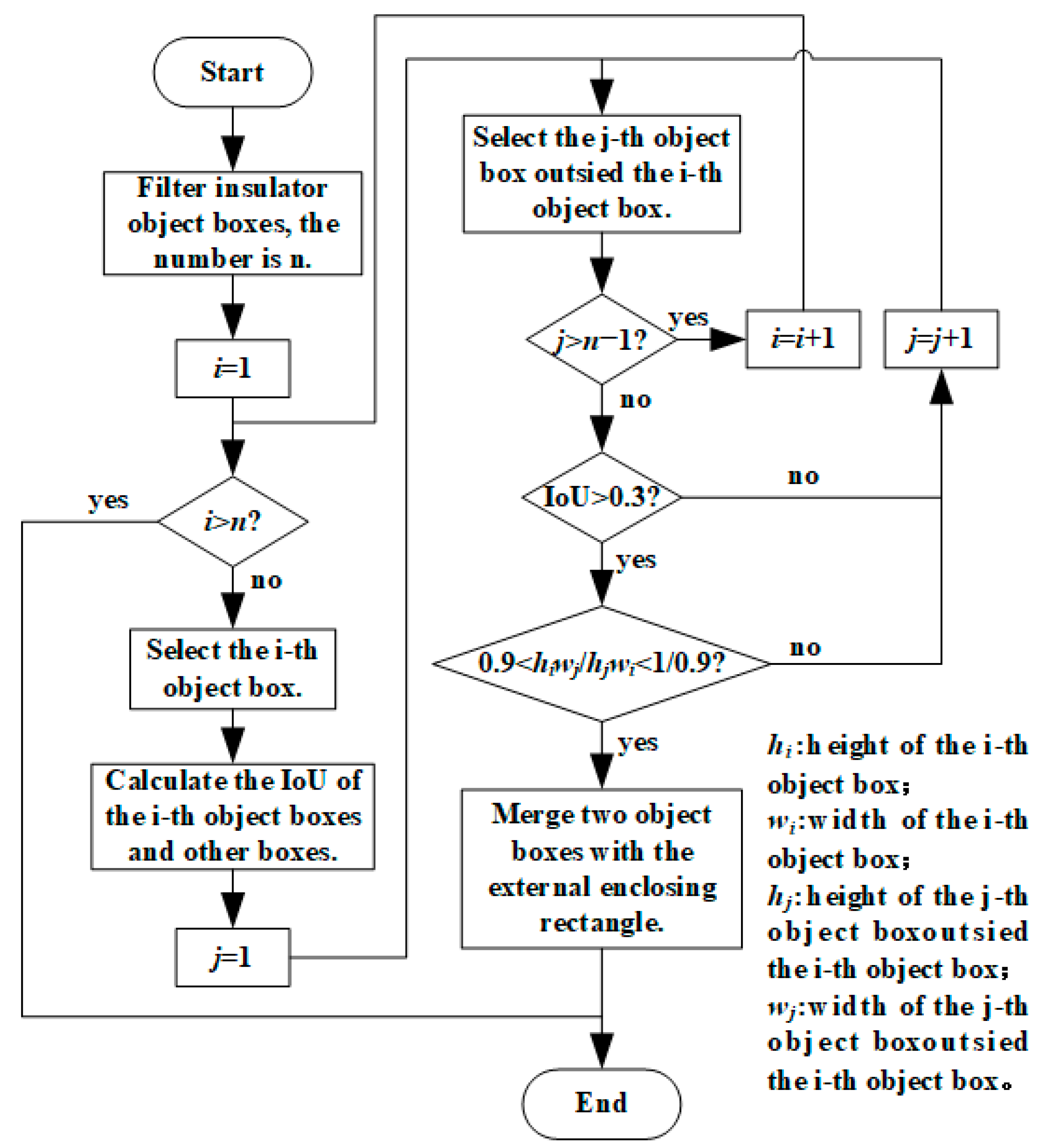
(3) Considering the problem of split detection boxes, split object boxes were determined after non-maximum suppression (NMS) through the intersection over union (IoU) and aspect ratio and then replaced by an external enclosing rectangular box to improve detection performance.
4. Conclusions
In this study, we developed a method to detect insulators and their defects with an improved YOLOv4-tiny model taking account of data processing shifted to an edge computing device. The accuracy and speed of the model were tested on the edge computing device. The specific conclusions of this work are listed as follows:
(1) YOLOv4-tiny is more applicable to edge computing devices owing to its faster detection speed and fewer parameters, but some room for improvement remains in terms of detection accuracy.
(2) By using the inverted residual module as the feature fusion module, the insulator positioning accuracy of the model was enhanced, and the insulator detection accuracy increased from 89.62% to 96.65%.
(3) By changing the network structure of YOLOv4-tiny to three output head designs, the detection ability of the model for small-scale defect objects was improved. The recall and accuracy of defects increased from 91.26% and 96.25%, respectively, with the original model to 92.56% and 100.00%.
(4) Post-processing of the prediction box was added to the YOLOv4-tiny model to combine the split prediction boxes of large-scale insulators in the form of an external enclosing rectangular box to improve the actual detection performance of the model.
(5) The insulator AP, defect AP, and mAP of the improved YOLOv4-tiny were 97.95%, 94.49%, and 96.22%, respectively, and the detection speed on the edge computing device reached 10.398 FPS, which basically meets the requirements of accuracy and speed in insulator and defect detection scenarios.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





















