1. Introduction
Gearboxes have been widely used in many fields, such as aerospace, machine tool, automobiles, etc. As the core components of the gearboxes, gears and bearings are considered to be very prone to failure because of long−term operation under extreme conditions. A statistical report by Neale Consulting Engineers Ltd. showed that most gearbox failures (49%) are caused by the bearings, and the gears are considered as the second leading cause of failures (41%), followed by other components accounting for 10% of the failures [
1]. The failure sequence frequently starts with a bearing, rather than a gear. The degradation and failure of bearings will cause a decline in performance and an increase in vibration, leading to overall damage to the rotating machinery system, economic losses, or even human casualties. Therefore, bearing fault diagnosis is of paramount importance to guarantee stable, reliable, safe operation of the machines and reduce avoidable economic losses. Bearing fault diagnosis techniques, including vibration signal analysis, acoustic analysis, and temperature monitoring, have been studied for many years [
2]. Among these, vibration signal analysis has been widely developed because vibration signals contain abundant dynamic information about rotating machinery. Donelson and Dicus [
3] adopted envelope analysis in the bearing fault diagnosis of freight cars. Pan and Tsao [
4] utilized ensemble empirical mode decomposition (EEMD) and envelope analysis to detect the multiple faults of ball bearing. Cai [
5] employed empirical mode decomposition (EMD) and high−order statistics to extract the fault features of rolling bearing in a Gaussian noisy environment. Wang et al. [
6] proposed an improved EMD method, called EMD manifold, to enhance the fault detection of rotating machines. However, owing to the complexity of operating conditions, the traditional diagnostic techniques may not be able to make an accurate diagnosis, so more advanced diagnostic approaches should be developed.
As a research hotspot in signal processing over the past thirty years, blind source separation (BSS) has been widely used in many fields, including speech processing, vibration analysis, biomedical engineering, etc. [
7]. It is an effective approach to obtain the source signal estimation from the observed signals (mixed signals) in the case where both the source signals and the mixing manner are unknown [
8]. Since Gelle et al. [
9] first introduced the BSS algorithm into rotating machinery fault diagnosis, more and more researchers have applied BSS theory to provide reliable fault diagnosis methods. Bouguerriou et al. [
10] presented a BSS solution based on second order statistical properties and used it to detect the bearing faults. Li et al. [
11] combined independent component analysis (ICA) with fuzzy k−nearest neighbor to diagnose the multi−faults of gears. Miao et al. [
12] utilized median filter and the improved joint approximate diagonalization of eigenmatrices algorithm to identify the faults of rotating machinery. However, most studies mainly focus on the BSS problems in which the number of observed signals exceeds the number of source signals, namely the overdetermined BSS (OBSS) problem. In practice, the lack of prior knowledge about the sources makes it hard to pre−set the number of sensors that need to be installed. Meanwhile, objective factors such as the installation space of sensors will limit the collection of observed signals. Hence, the number of observed signals less than that of the source signals is in line with engineering practice, and it is imperative to seek the solution of underdetermined blind source separation (UBSS) for fault diagnosis in bearings.
Currently, some research work has been conducted to resolve the UBSS problem, which is mainly classified into two solutions [
13]. The first one is to decompose the finite number of raw observed signals into multiple components through signal decomposition methods. Generally speaking, the number of multi−channel components is much larger than that of the source signals. Thus, the UBSS problem can be effectively converted into an overdetermined one, and then the ICA is employed to obtain the estimation of source signals. Another one takes advantage of the sparsity property of signals in the sparse domain, typically known as sparse component analysis (SCA), to resolve the UBSS in two stages: estimate the mixing matrix first and then recover the sources. In the first solution, the most commonly used decomposition methods are EMD, local mean decomposition (LMD), and variational mode decomposition (VMD), which have excellent performance when dealing with nonlinear signals [
14]. The multi−channel components obtained by these decomposition methods are regarded as the virtual sensor outputs, hence the accuracy of the signal decomposition is crucial for source signal recovery. However, these decomposition methods still have some drawbacks. EMD suffers from mode mixing and end effect problems [
15]. In the LMD algorithm, the calculation process of local mean function and local envelope function is accomplished based on the moving average method, which may lead to low decomposition efficiency and accuracy in processing non−stationary signals [
16]. The performance of the VMD method relies largely on the appropriate choice of balance parameter and the number of decomposed modes [
17]. These shortcomings may affect the accuracy of decomposition, resulting in inaccurate generation of virtual observed signals, and thus affect the recovery of source signals. In addition, although ICA is an operative method to solve the OBSS problem, it is necessary to strictly satisfy the assumption of the statistical independence of source signals. It is also assumed that the number of Gaussian components must be no more than one. Nevertheless, in engineering practice, the vibration signals do not always fulfill all assumptions, which limits the application scope of the ICA. Unlike ICA, SCA−based approaches do not require source independence or irrelevance, and sparsity of signals is the only requirement that needs to be met. Therefore, SCA is a more suitable method for dealing with the UBSS problem and can achieve better source separation performance, especially in rotating machinery fault diagnosis. Nevertheless, SCA−based approaches are difficult to implement with unknown source numbers. Furthermore, in the clustering stage, a large number of scatter points will increase the amount of computation and reduce the clustering accuracy, resulting in the failure to obtain accurate estimation of the mixing matrix.
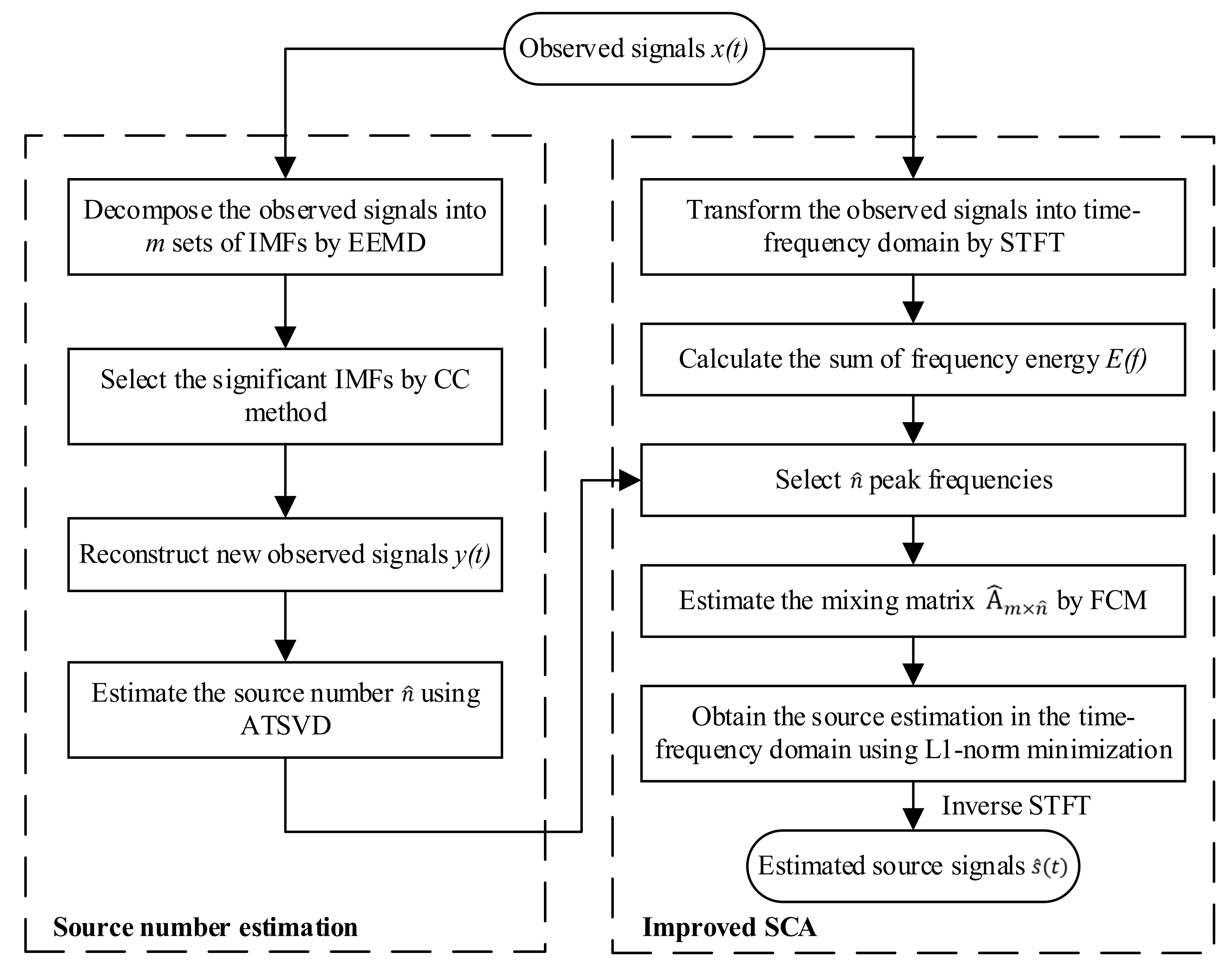
In terms of UBSS, it is urgent to solve the problem of determining how many source signals need to be recovered and how to accurately separate the observed signals. In this paper, a novel UBSS solution combining source number estimation and improved SCA is investigated for bearing fault diagnosis. Firstly, the EEMD and CC methods are adopted to obtain a group of significant IMFs. An eigenvalue method called adaptive threshold singular value decomposition (ATSVD) is adopted to obtain the number estimation of source signals. Secondly, short−time Fourier transform (STFT) is utilized to convert the observed signals into time−frequency domains. According to the obtained number estimation of source signals, the frequency energy is employed to reduce the amount of computation and improve the accuracy of fuzzy C−means (FCM) clustering, so as to ensure the accuracy estimation of the mixing matrix. Thirdly, the L1−norm minimization method is utilized to estimate the source signals. The numerical results demonstrate that the proposed method is able to effectively separate the simulated vibration signals, both in linear and nonlinear mixed cases, and can well identify the fault frequency in the inner race and outer race fault experiments.
The rest of this paper is organized as follows:
Section 2 presents the source number estimation method based on the EEMD, CC, and ATSVD joint approach.
Section 3 presents the mixing matrix estimation method based on the frequency energy and FCM clustering algorithm in detail and describes the source recovery by using L1−norm minimization.
Section 4 evaluates the effectiveness and applicability of the proposed approach through simulation analysis. In
Section 5, an inner race fault testbed experiment is conducted to validate the performance of the proposed approach in bearing fault diagnosis. Finally, the conclusions are drawn in
Section 6.
2. Source Number Estimation Based on EEMD, CC, and ATSVD Joint Approach
Assuming that
are
m−dimensional observed signals, which are generated by unknown source signals
, the linear instantaneous mixed model of UBSS can be described as follows:
where
is an uncharted
linear mixing matrix,
, and
represents the observation moment. The purpose of UBSS is to obtain the estimation of sources
without any prior information of
and
. In general, the first step of SCA is to estimate the mixing matrix. If inaccurate mixing matrix estimation is generated, it will inevitably affect the separation result. Therefore, the mixing matrix estimation is the key to source signal recovery. The column number of
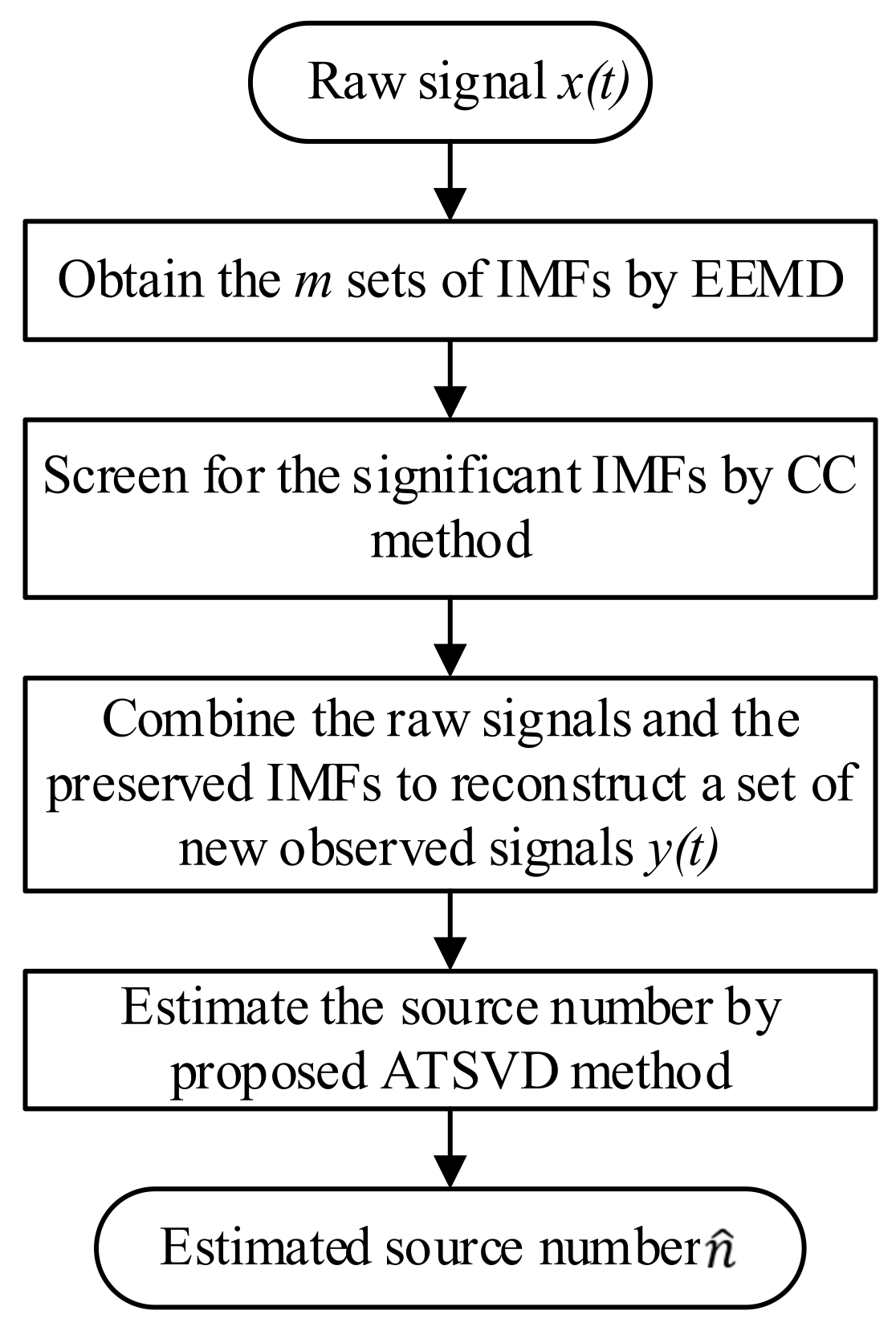
represents the number of source signals, and hence the accuracy of source number estimation is crucial for mixing matrix estimation. In this section, a novel source number estimation approach based on EEMD, CC, and ATSVD is presented to convert the underdetermined source number estimation into an overdetermined one. Firstly, EEMD is utilized to decompose the original observed signals into
sets of IMFs. Secondly, to remove the redundant IMFs and reduce the computational complexity, the CC method is utilized to screen for the significant components. Finally, an eigenvalue−based method named ATSVD is proposed to obtain the estimation of source number. The details are presented as follows.
2.1. Signal Decomposition Based on EEMD Algorithm
EMD is a powerful technique that can decompose a non−stationary and nonlinear signal into multiple IMFs. In general, each IMF is a mono−component function that satisfies the following conditions: (1) the number of extreme points (local minima and maxima) and that of zero crossing points must differ by one at most in the entire data set. (2) At any point, the mean of the upper and lower envelope must be zero [
18]. Given one of the observed signals,
, the EMD can decompose it as follows:
where
is the obtained IMFs,
denotes the number of IMFs, and
is the residue that denotes the central trend of
.
Although traditional EMD is a powerful technique for processing non−stationary and nonlinear signals, it still has the mode mixing problem. To overcome the mode mixing issue, an improved EMD named EEMD was proposed by Wu and Huang [
19]. The basic idea is to add several instances of white noise to the raw signal, so that the components of different scales can be automatically projected to the proper scale related to the white noise [
14]. Given the observed signal,
, the procedures of EEMD are listed as follows:
- Step 1:
Add white noise,
, to the observed signal,
, and the mixed signal is:
- Step 2:
Use EMD to decompose the mixed signal,
, into a group of IMFs as follows:
- Step 3:
Add different white noise,
to
, again and repeat Step 1 and Step 2 for
times. Each time a new group of IMFs is acquired:
where
is the
jth IMF of the
ith EMD trial.
- Step 4:
Average the corresponding IMFs to eliminate the effect of the white noise, and the final result can be obtained:
In this study, considering the computational cost and referring to parameter settings in some of the literature, the standard deviation of white noise is set as 0.2 times the raw signal, and the number of iterations,
Ne, is set as 200 [
20]. Thus, the raw signal can be effectively decomposed into a group of representative IMFs whose frequency bands are automatically arranged from high to low.
2.2. Significant Component Selection Based on the CC Method
The EEMD can effectively decompose a signal into a group of IMFs adaptively, with each IMF having the same length as the raw signal. However, the noise introduced during the decomposition process may cause the IMFs to contain redundant components [
21]. To eliminate the influence of noise and reduce the subsequent computation, a simple selecting criterion called the correlation coefficient (CC) is employed to screen for the significant IMFs. The CC value can be calculated by the following formula:
where
is the raw signal and
denote the mean value of
,
is the
jth IMF and
denote the mean value of
, and
donates the number of the data points of
. After calculation, the IMFs with significantly low CC values are screened out, and the preserved IMFs are the significant components that contain more defect information and the trend of the raw signal. Thus, each preserved IMF can be viewed as the output of a virtual sensor and treated as a new observed signal. Then, the preserved IMFs and the raw observed signals
are set as the new observed signals, which are rewritten as
, where
is the sum of dimensions of the raw observed signals and the preserved IMFs. In this way, the UBSS problem can be effectively converted into an overdetermined one, and thus the source number estimation methods used in the overdetermined case can be applied.
2.3. Source Number Estimation Based on the ATSVD Method
In order to obtain accurate source recovery, the source number needs to be determined before the mixing matrix estimation. In previous research, some common information−based methods, such as Akaike information criterion and Bayesian information criterion, have been typically utilized to estimate the number of sources [
14]. Nevertheless, these methods are only effective for estimating the source number in the white noise environment, but are invalid in the color noise environment. To ensure the accurate estimation of the mixing matrix, an eigenvalue method called ATSVD is proposed to estimate the number of source signals in this study. Firstly, the eigenvalues of the sample covariance matrix are obtained by singular value decomposition (SVD), then the source number is determined by the distribution of eigenvalues. In linear algebra, SVD is a commonly used matrix factorization technique that can decompose a matrix,
, into three matrices as follows:
where
U and
V represent
unitary matrices and
S denotes an
diagonal matrix. The diagonal elements
of
S are the eigenvalues of
X and can be written in the descending order, e.g.,
. In general, the eigenvalues of source signal subspace
are much larger than the eigenvalues of noise subspace
. At present, the two subspaces are usually distinguished by setting a threshold. However, the selection of threshold directly affects the accuracy of source number estimation. In this work, the estimation of source number is realized by calculating the contribution rate of eigenvalues. Given the new observed signals
, the key steps of the ATSVD algorithm can be summarized as follows:
- Step 1:
Calculate the covariance matrix of
as follows:
where
represents the complex conjugate transpose.
- Step 2:
Decompose the covariance matrix, , by SVD to obtain the eigenvalues , then remove eigenvalues less than 0.001, and the retained eigenvalues are used to constitute a new eigenvector of length .
- Step 3:
Sum all the eigenvalues and then calculate the ratio of each eigenvalue, i.e., contribution rate:
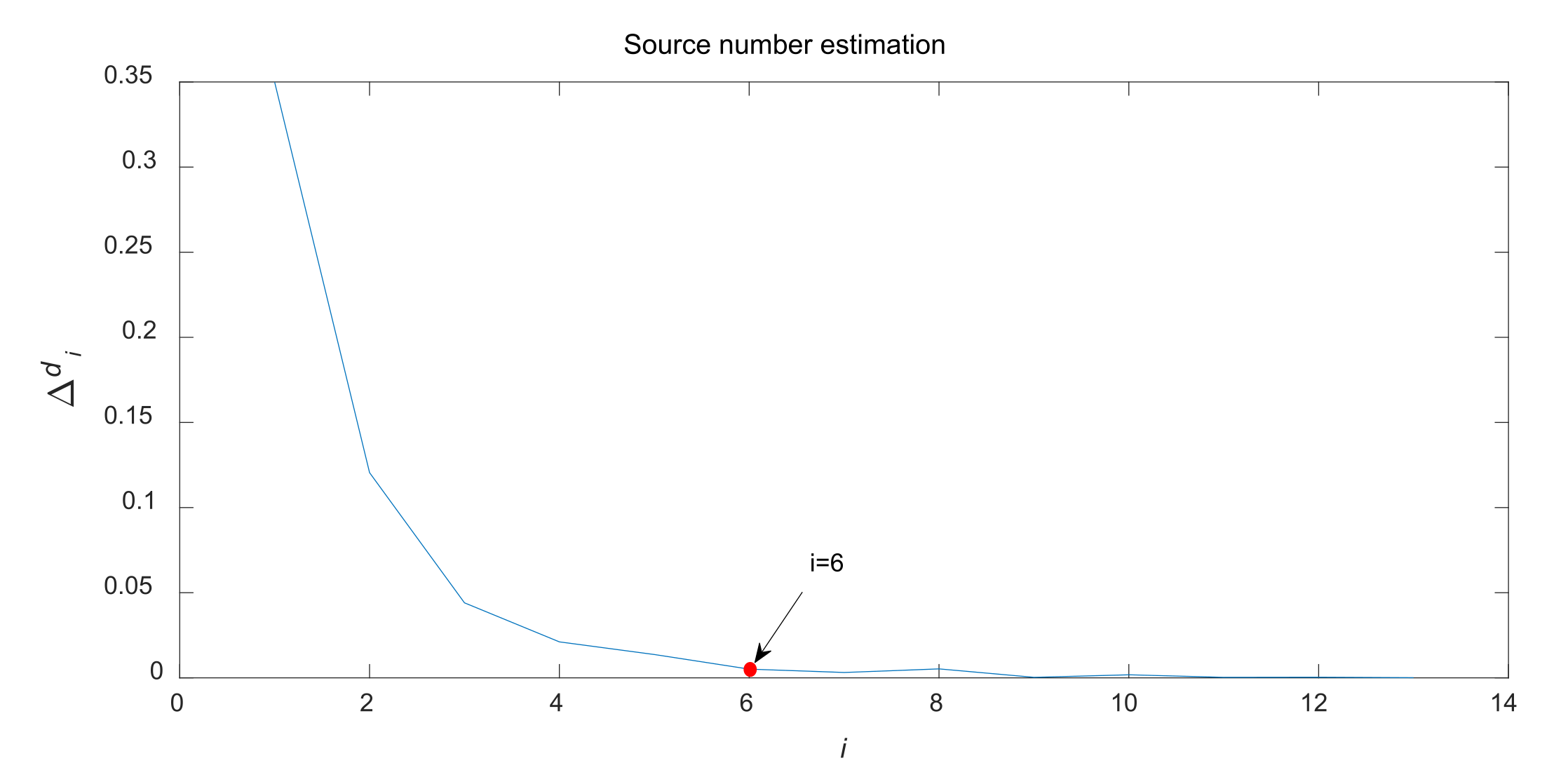
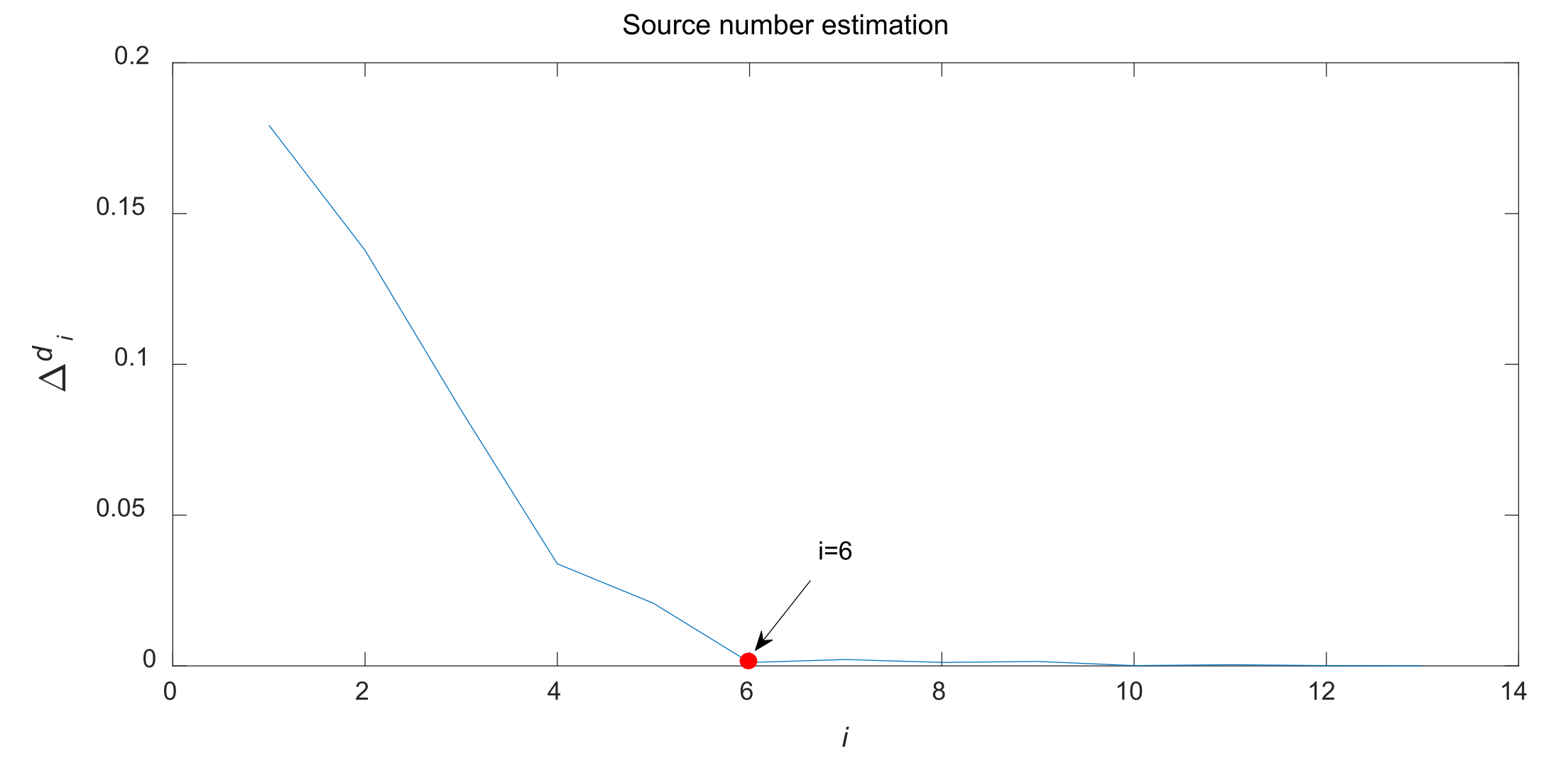
- Step 4:
Calculate the difference between the two adjacent contribution rates:
Herein, the maximum value (
is set as the threshold to distinguish the source signal subspace and noise subspace, and
is the estimated number of sources. In summary, the procedure of source number estimation is described as
Figure 1. Based on the estimated number,
, the number of clustering centers can be determined in advance.
3. Source Signal Recovery Based on Improved SCA
SCA is an effective approach to resolving the UBSS problem and has been widely applied in vibration analysis, image processing, modal identification, etc. Signal sparsity refers to the fact that most points in the signal are zero or near zero, but a few points are obviously greater than zero. However, most vibration signals cannot meet the sparse requirement in the time domain. In order to improve the sparsity of the observed signals, STFT is first carried out to convert the signals from the time domain to the time−frequency domain. In engineering, the frequency of each source signal is usually different to avoid resonance. Therefore, there is generally only one source at a specific time−frequency point. It must be emphasized that although the gearbox is a nonlinear system, such nonlinearity will not affect the defect frequency, hence SCA is able to reserve the fault information in the time−frequency domain. In this section, an improved SCA is employed to separate the mixed signals. Firstly, FCM clustering is adopted to estimate the mixing matrix, and frequency energy is employed to improve the clustering accuracy. Secondly, the L1−norm minimization method is utilized to estimate the source signals. The details are presented as follows.
3.1. Mixing Matrix Estimation Based on FCM and Frequency Energy
Mixing matrix estimation is the most critical part of the SCA because the estimated mixing matrix determines the accuracy of signal separation. In the literature, the main methods of mixing matrix estimation are the potential function method and the clustering method. The potential function method expands the angle of the clustering line to the polar coordinate axis and determines the angle between the clustering line and the coordinate axis by calculating the peak value points, so as to obtain the column vectors of the mixing matrix. However, it can only be used for two−channel mixed signals, which has certain limitations. In contrast, the clustering method determines the mixing matrix by estimating the center of the clustering line, which is not limited by the number of channels. Currently, the most−used clustering algorithms are K−means and FCM. The former is a hard partition−based clustering method, while the latter is a soft partition derived from the fuzzy set theory [
22]. In this work, FCM clustering is selected to realize the mixing matrix estimation because the strict attributes are usually not available for vibration signals.
Denote
as a set of limited observation sample. The FCM is a clustering algorithm that can produce membership degree
for each data point. The objective function of FCM is given as follows:
where
is the cluster number,
is the number of data points in
, and
denotes a fuzzy partition matrix exponent for controlling the degree of fuzzy overlap, with
. Fuzzy overlap refers to how fuzzy the boundaries between clusters are, that is the number of data points that have significant membership in more than one cluster;
is the
jth data point,
is the center of the
ith cluster, and
is the membership degree of
in the
ith cluster, which satisfies
.
Then, the Lagrange multiplier method is adopted to minimize the objective function. The degree of membership and the centers of clusters can be updated by the following formulas:
and
The procedures of FCM clustering can be listed as follows:
- Step 1:
Fix the number of clusters, , the value of the fuzzy partition matrix exponent, , and the iteration deadline error, ;
- Step 2:
Initialize the degree of membership matrix, ;
- Step 3:
Calculate the clustering center matrix, , based on Equation (14);
- Step 4:
Update the degree of membership matrix, , based on Equation (13);
- Step 5:
Compare and ; if , terminate the iteration; otherwise update and return to Step 3.
FCM is an excellent clustering algorithm with a mature theory and wide applications. Nevertheless, the actual collected signals are mixed by multiple source signals, resulting in more clustering directions in the scatter graph. When the number of data points is too large in the process of clustering, it will not only increase the computational burden but also affect the clustering accuracy, resulting in the inability to obtain an accurate mixing matrix. To address this issue, a simple method, namely frequency energy, is adopted to improve the accuracy of mixing matrix estimation [
23,
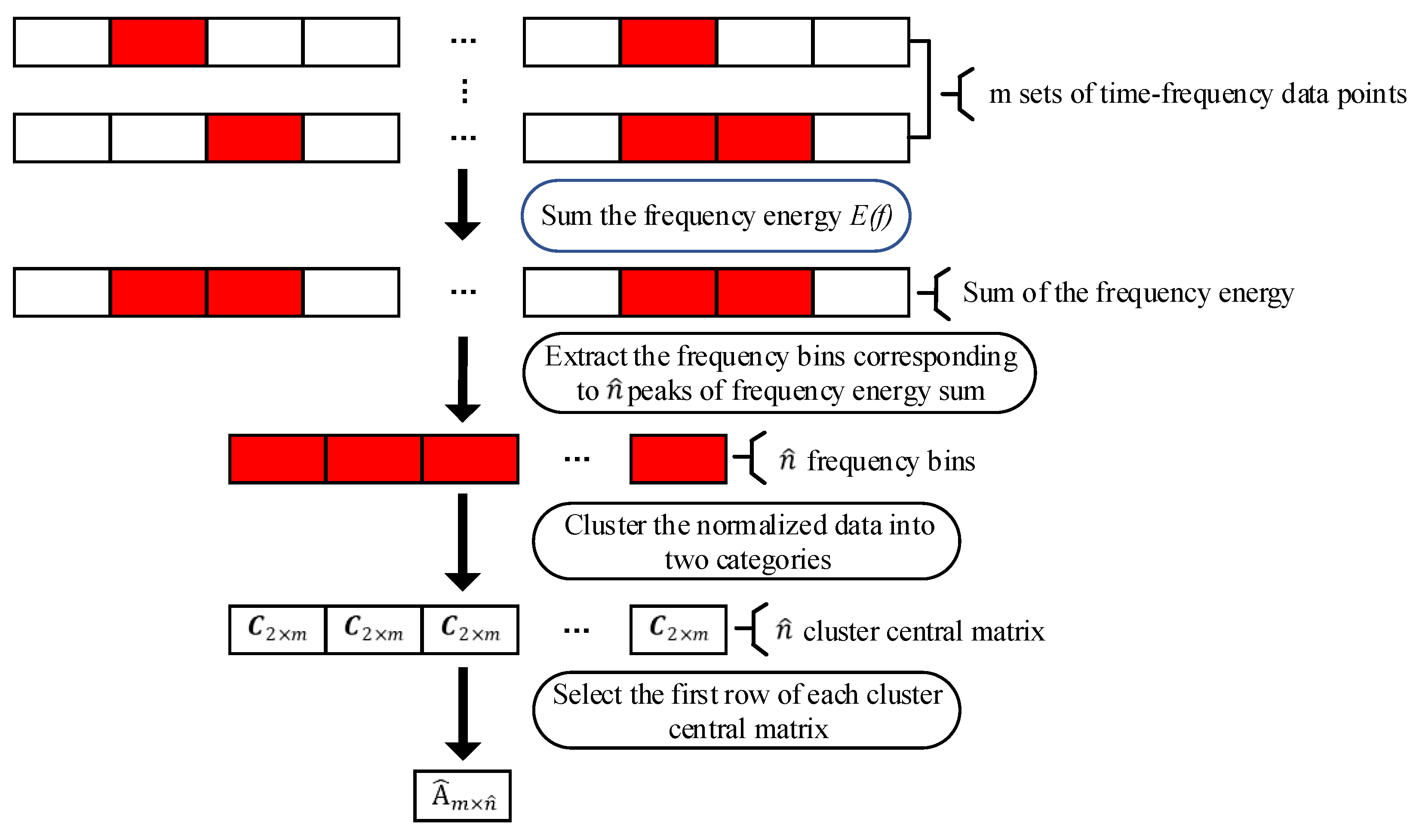
24]. In engineering practice, the energy of vibration signals is generally concentrated at some frequency points, and the clustering direction at the local maximum frequency points can be used as the clustering direction of the source signals. Thus, the estimated mixing matrix can be obtained only by finding the clustering direction at these peak frequency points, which can significantly reduce the amount of computation and increase the accuracy of clustering. In this work, the energy distribution of each observed signal is first calculated, and then the energy distribution of all the observed signals is added at the same frequency point; that is:
where
denotes the energy sum of all the observed signals at each frequency point and
is the number of observed signals;
and
represent the real and imaginary parts of the
ith sensor signal after STFT, respectively.
In summary, the schematic diagram of the mixing matrix estimation is presented in
Figure 2 and the steps can be listed as follows:
- Step 1:
Adopt STFT to transform the observed signals into the time−frequency domain, and the matrix expression can be denoted as , where , and is the number of observed signals;
- Step 2:
Calculate the sum of the energy, , and then utilize the peak detection method to select peaks of frequency energy sum (), where is the estimated source number;
- Step 3:
Select the data points of a certain frequency (e.g., from to ) to form a new matrix, ;
- Step 4:
Normalize , then utilize FCM to divide it into two categories, and the cluster central matrix can be represented as . The first row of is selected as a column vector of the estimated mixing matrix;
- Step 5:
Alter the frequency and repeat Step 3 and Step 4 times; the estimated mixing matrix of can be obtained.
3.2. Source Signal Recovery Based on L1−Norm Minimization
According to the estimated mixing matrix,
, the estimated source signals can be obtained by
in the overdetermined or determined case. However, in the underdetermined case, there are still multiple valid solutions despite the determination of the mixing matrix. Previous studies have confirmed that the solution derived from the minimum of L1−norm is the optimal solution of the underdetermined system of equations [
25]. Thus, the source recovery problem can be converted into an optimization problem. The estimated mixing matrix,
, can be generated into
submatrices by reducing dimensions, and these submatrices correspond to
sets of valid solutions. The optimal solution fulfilling the following equation can be obtained among all valid solutions:
where
is the optimal source estimation in the time−frequency domain. The main steps of the L1−norm minimization method can be summarized as follows:
- Step 1:
Generate submatrices from the estimated mixing matrix and set as ;
- Step 2:
Denote as a point in the time−frequency domain, calculate all possible solutions ;
- Step 3:
Calculate the L1−norm of each solution, and the minimum L1−norm is taken as the optimal estimation of the source signal, which is given by ;
- Step 4:
Repeat Step 2 and Step 3 and the optimal source estimation in the time−frequency domain can be obtained;
- Step 5:
Perform inverse STFT to obtain the estimated source signals in the time domain.
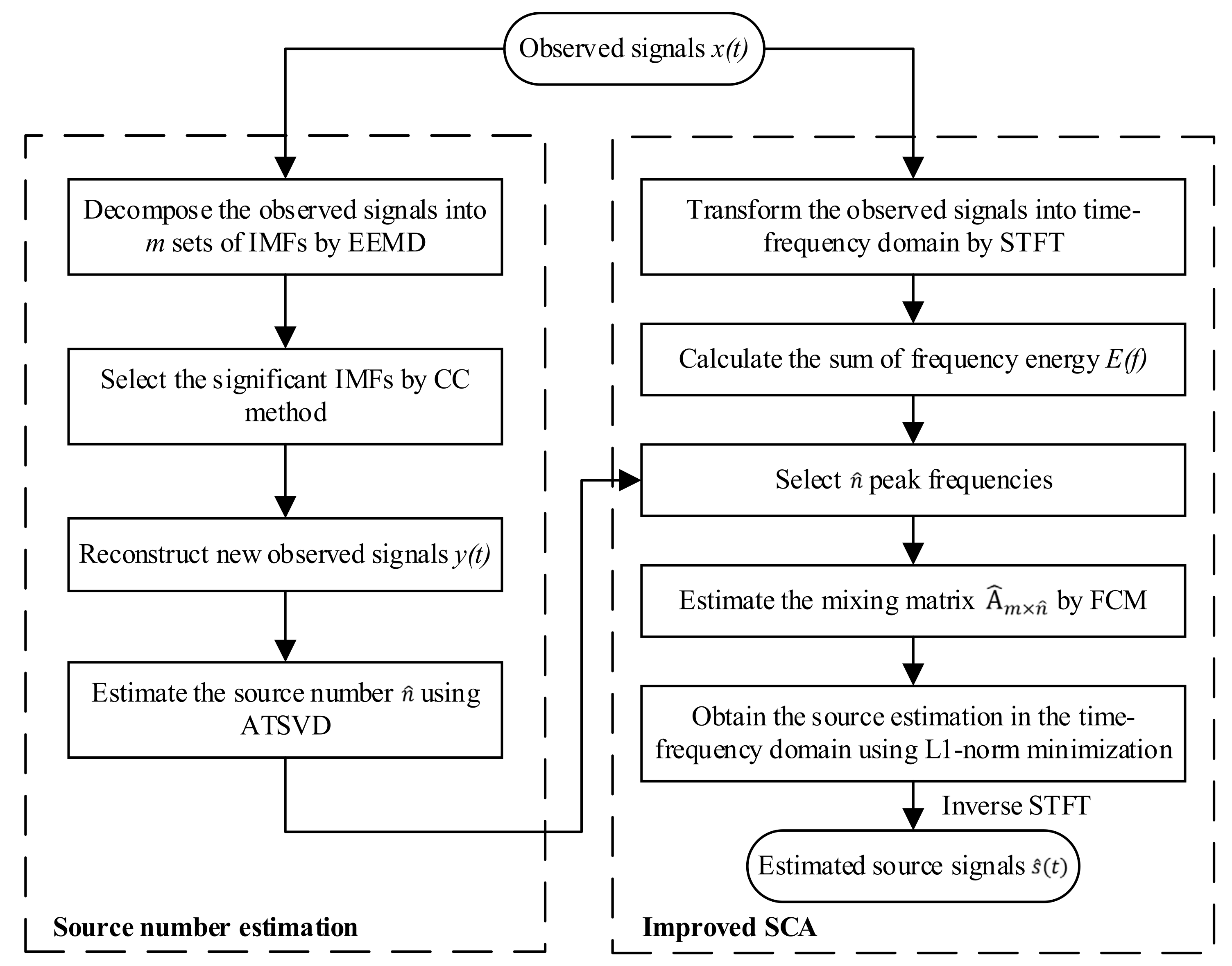
In summary, the flowchart of the proposed UBSS solution is illustrated in
Figure 3.
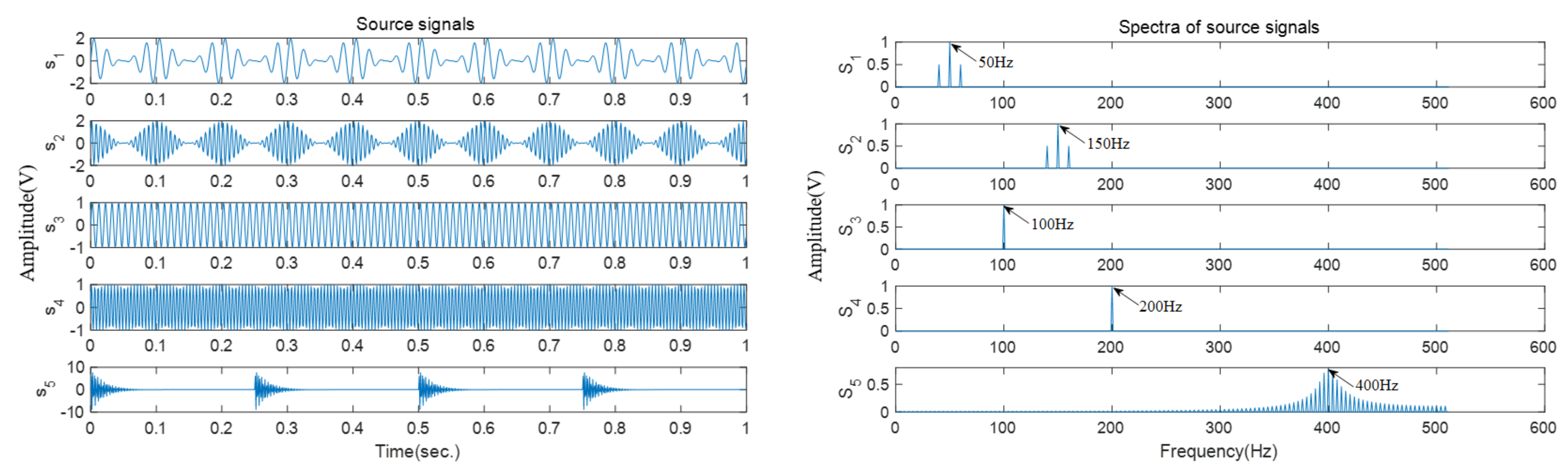
5. Experiment and Results
This section carries out the bearing fault testbed experiments to verify the separation performance of the proposed approach for actual measured signals. The rolling bearing fault testbed consists of a rolling bearing, two acceleration sensors, and an alternating current (AC) variable frequency motor.
Figure 11a shows the tested rolling bearing; the type is HRB 7208AC. In order to simulate the bearing fault in actual working conditions, two types of single point fault, which are inner race fault and outer race fault, are artificially introduced to the tested bearing by means of electrical discharge machining.
Figure 11b,c present the faulty inner ring and outer ring, respectively. It can be seen that there is an artificial gap of 2 mm in both the inner and outer rings. The bearing is preloaded axially. The sensors are installed on the bearing housing; the type is CA–YD–182. The motion in the test is generated by an AC variable frequency motor, which is shown in
Figure 11d; the type is SIEMENS 1LE0001–0DB32. The rotating speed is set to 4000 rpm and the vibration signals are acquired by the dynamic signal analyzer. The sampling frequency is 4000 Hz, and 1 s is intercepted as a time fragment.
Table 4 presents the specifications and parameters of the tested bearing. When the bearing is running, the fault feature frequency of the rolling bearing is the recurrence frequency of the vibration pulse generated via the contact between the defect and the raceways or rollers. The fault characteristic frequencies of a rolling bearing can be obtained by the following theoretical formula:
where
represents the frequency of the inner race fault point passing each rolling element and
represents the frequency of the outer race fault point passing each rolling element. The calculation results are 302.6 Hz and 217.4 Hz, respectively.
5.1. Inner Race Fault
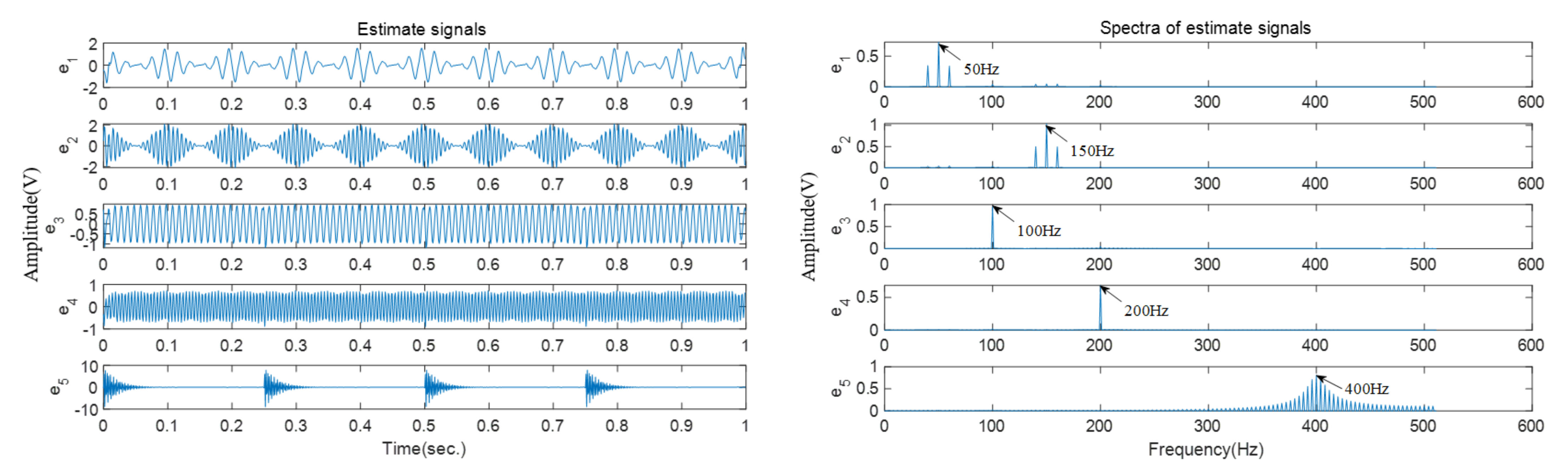
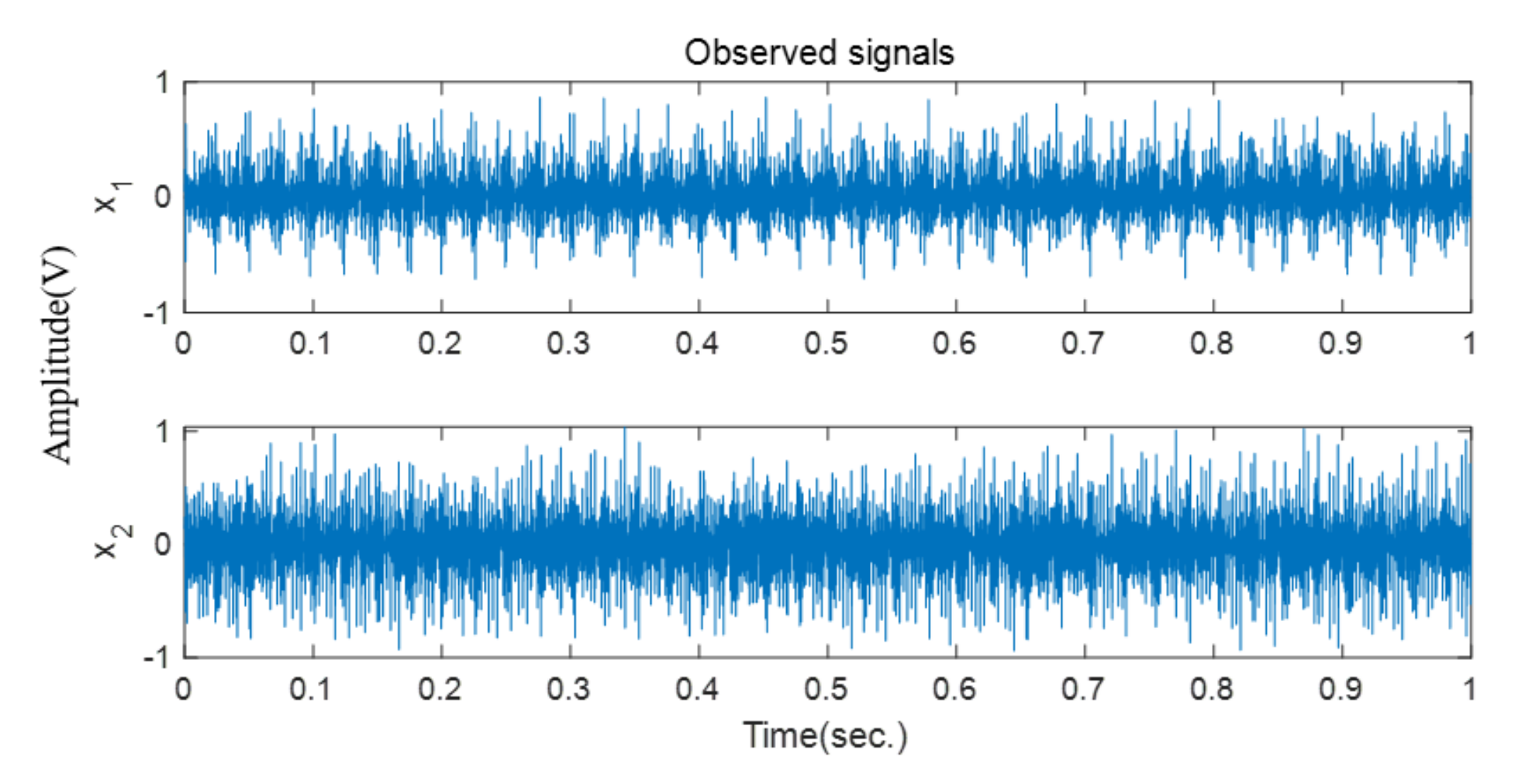
In this case, two vibration signals are collected and presented in
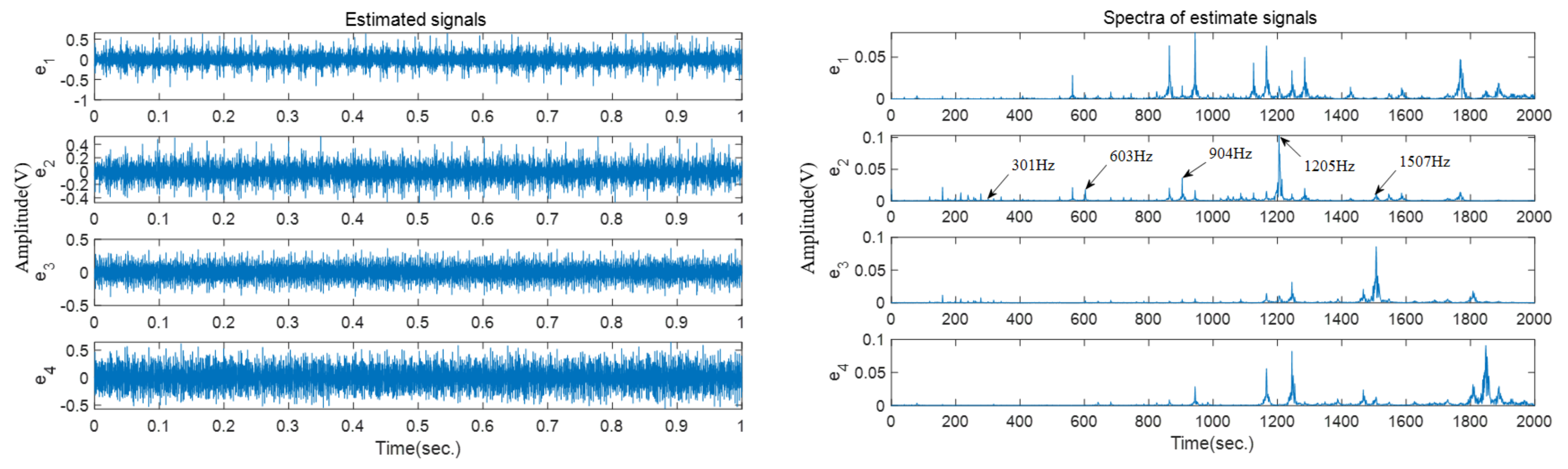
Figure 12. The source number is first estimated and then four estimated source signals are obtained based on the improved SCA method.
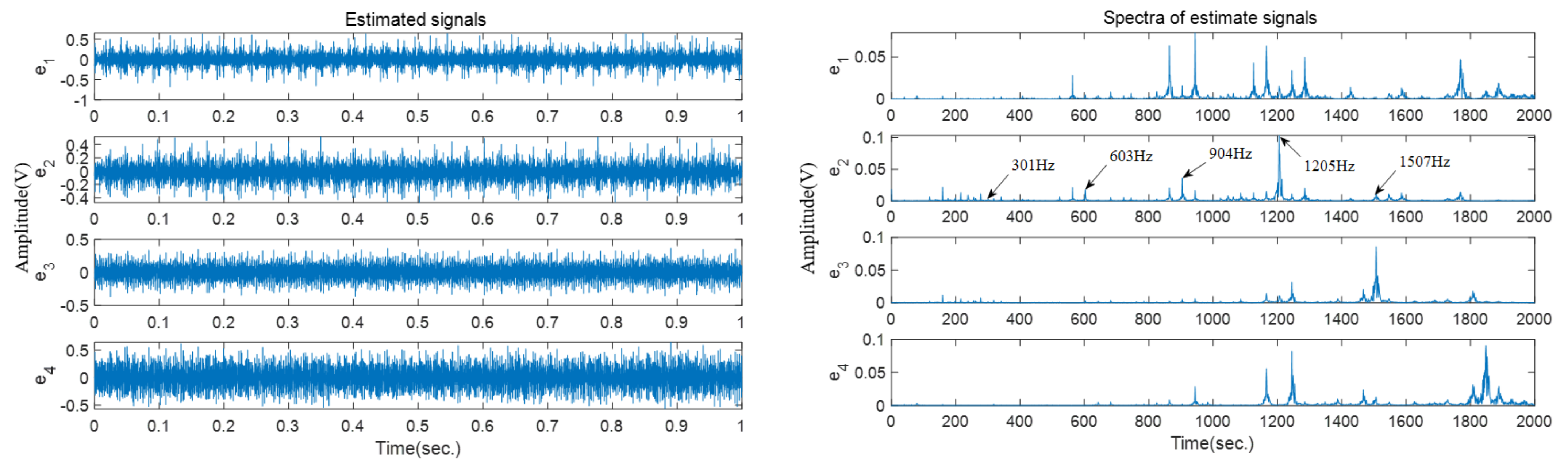
Figure 13 shows the time−domain waveforms and frequency spectra of these four estimated vibration signals. As is shown in the frequency spectra, the harmonic frequencies of the inner race fault can be easily identified in the frequency spectrum of
; for example,
.
5.2. Outer Race Fault
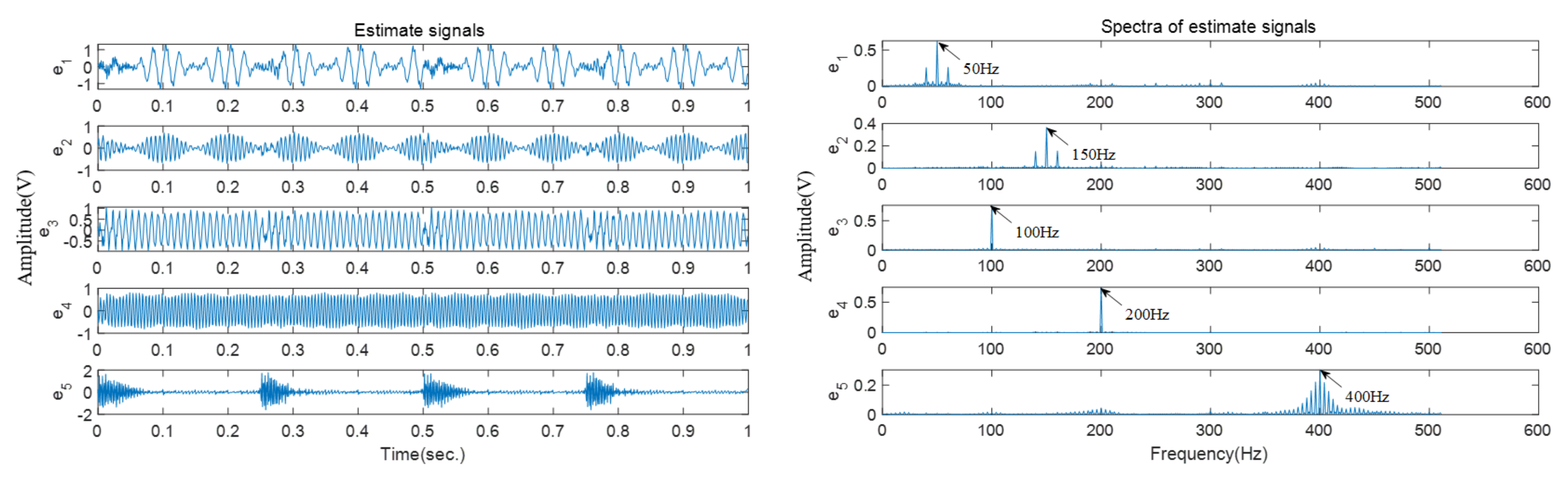
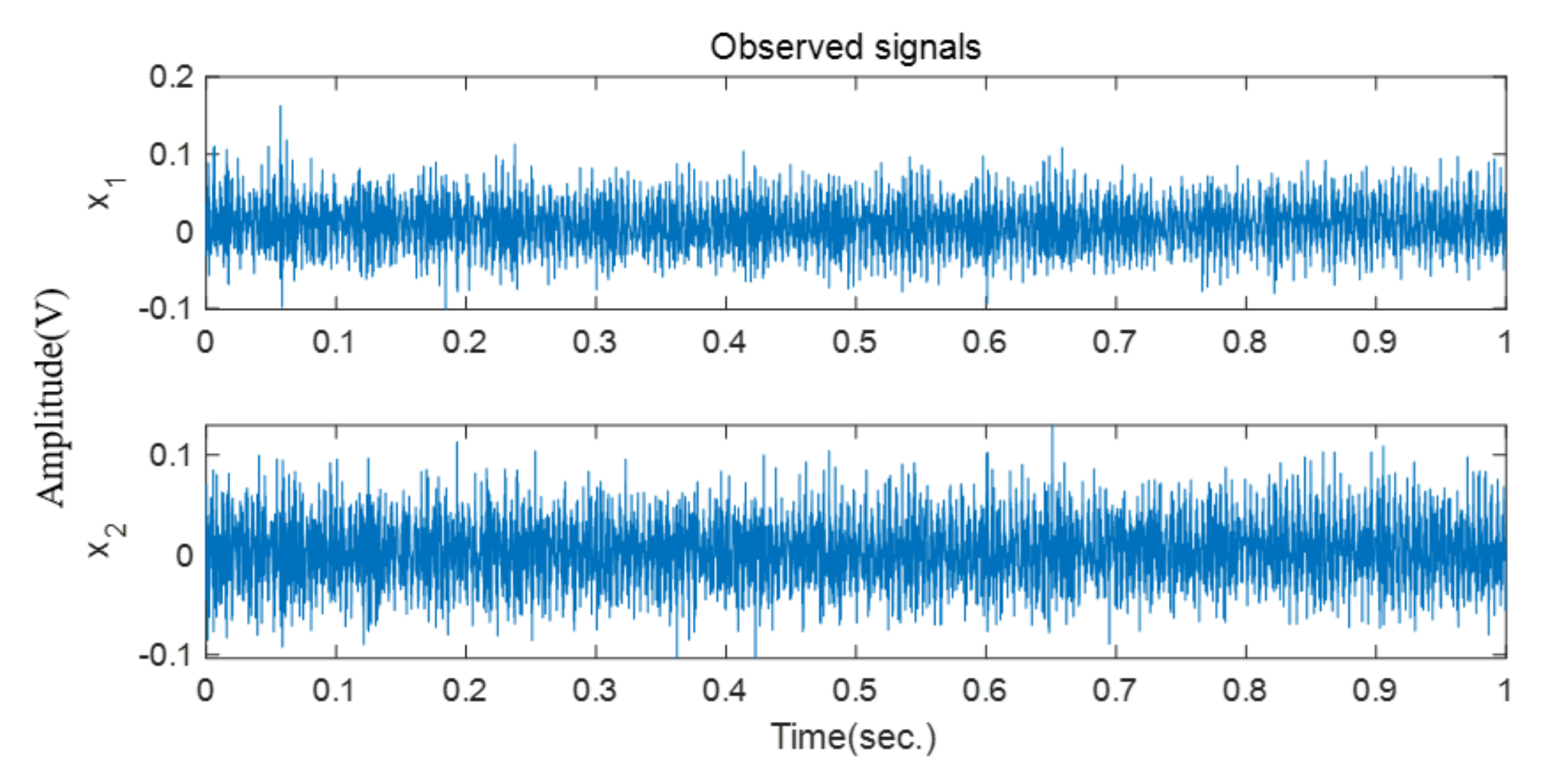
In this case, two collected vibration signals are used to validate the effectiveness of the proposed approach.
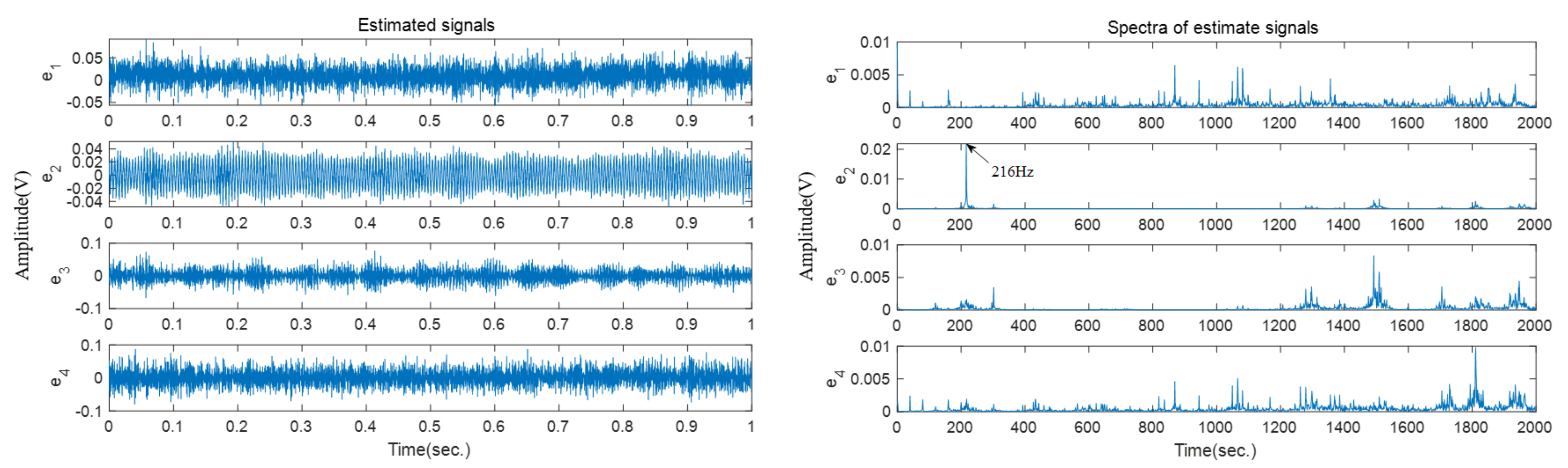
Figure 14 shows the time domain waveforms of these signals. Based on the proposed solution, four source signals are recovered, as shown in
Figure 15, then the recovered signals are further transformed into the frequency domain. It can be seen that the peak frequency of
well match the expected frequency of the outer race fault. The results of the inner and outer race fault amply prove the effectiveness of the proposed bearing fault diagnosis approach.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}