1. Introduction
With the development of modern industrial technology, the working process of rotating machinery is more integrated and intelligent [
1,
2,
3]. Mechanical components inevitably fail because of the complexity, harshness, and uncertainty of the working environment. The faults that are not detected early can cause serious damage to the equipment and significantly increase the cost of maintenance [
4,
5]. Therefore, providing effective fault monitoring and health management for mechanical systems plays a crucial role [
6].
The response of the defective mechanical parts to the external excitation is abnormal, and thus, the fault signals are generated. The traditional condition monitoring method is to analyze the probability distribution of the signals for fault diagnosis. Such methods are based on artificial feature engineering with a large amount of expert experience, and their capabilities are limited by complex and variable mechanical systems [
7,
8].
In recent years, deep learning (DL) methods with multi-level nonlinear transformations have been used to autonomously mine information, such as statistical and structural relationships, between data to establish reliable diagnostic models. Consequently, DL methods that can realize the expression of high-dimensional feature information of data have been widely developed. Lei et al. [
9] systematically reviewed the development of intelligent diagnosis and provided future prospects. DL methods are continuously improved to solve specific problems. For example, for the problem that samples are disturbed by complex environmental noise in industrial practice, Zhang et al. [
10] applied multi-scale feature extraction units to vibration signals for learning complementary and rich fault information on different time scales. Then, a novel easy-to-train module based on adversarial learning was used to improve the feature learning ability and generalization ability of the model. Faced with the problem of variable working conditions, Shao et al. [
11] proposed an improved convolutional neural network with transfer learning, which had excellent diagnostic performance in rotor-bearing systems under different working conditions. Therefore, to monitor the invisible faults, Chen et al. [
12] exploited the domain-invariant knowledge of the data through adversarial learning between feature extractors and domain classifiers. The fault classifier generalized the knowledge from the source domain to diagnose invisible faults in the meantime. The interpretability of the DL method has also received attention recently. Zhao et al. [
13] developed a model-driven deep unrolling approach to realize ante-hoc interpretability, the core of which was to unroll a corresponding optimization algorithm of a predefined model into a neural network, which was naturally interpretable. Additionally, some advanced techniques, such as contrastive self-supervised learning [
14], meta-learning [
15], metric learning [
16] and incremental learning [
17], are also utilized by some scholars to solve specific problems in fault diagnosis.
Most existing DL-related methods assume that the distribution of training data is balanced. Nevertheless, the rotating machinery systems often operate in a healthy state, and the collected fault samples only account for a small part. DL models will be dominated by classes with sufficient samples and ignore the minority classes with insufficient feature understanding [
18,
19,
20], which leads to overfitting. If the model is severely biased, resulting in a sharp decrease in the classification accuracy of the minority class, it will influence the maintenance efficiency of the mechanical system. More importantly, it is expensive to collect sufficient annotation signals from industrial equipment. In consequence, it is of great practical significance to correctively classify small and imbalanced data [
21,
22].
Fault diagnosis methods for small and imbalanced data can be mainly divided into three categories: methods based on sampling technology, data generation and cost-sensitive learning. In general, methods based on sampling techniques are classified as either over-sampling the minority class or under-sampling the majority class [
23]. Among them, the synthetic minority over-sampling technique (SMOTE) has yielded many achievements, which augments the data sets by randomly selecting some samples within the nearest neighbor range. Georgios et al. [
24] proposed a heuristic over-sampling method based on K-means clustering and SMOTE to generate artificial data, which enabled various classifiers to attain high classification results on class imbalanced data sets. In addition, the adaptive synthetic (ADASYN) over-sampling approach has been used by many researchers to alleviate the degree of class imbalance. Li et al. [
25] proposed a fault diagnosis model incorporating ADASYN, a reconstructed data manner and a deep coupled dense convolutional neural network (CDCN), which had satisfactory results on the data set of power transformers. Although resampling methods such as SMOTE and ADASYN have improved the diagnostic performance to a certain extent, the distribution of the sample feature space is difficult to learn due to the complexity of the vibration signals of mechanical equipment, and thereby problems such as distribution marginalization can occur that result in the generation of invalid samples.
With the in-depth study of generative deep learning models, data generation methods represented by generative adversarial networks (GANs) and variational auto-encoders (VAEs) have become the most common means to solve class-imbalanced problems because of their better generated data [
23]. VAEs and GANs using unsupervised learning do not aim at extracting features to establish a mapping between input and output but rather learn the distribution of training data and then generate similar data to weaken the impact of class imbalance. Liu et al. [
26] proposed a novel data synthesis approach called deep feature enhanced generative adversarial network, where a pull-away function is integrated into the objective function of the generator to improve the stability of the generative adversarial network. This method shows great potential in class-imbalance bearing fault diagnosis. In Ref. [
27], an approach based on a conditional variational auto-encoder generative adversarial network (CVAE-GAN) was proposed for imbalanced fault diagnosis. The method utilized an encoder to attain the sample distribution and then generated similar samples by a decoder, and it was optimized continuously through an adversarial learning mechanism. Since the optimization of deep generative models is high-latitude non-convex optimization, such models are usually difficult to train and consume a lot of computational resources, which will miss the optimal time for maintenance during actual fault monitoring. Additionally, if only a few samples are available for training, the real data distribution cannot be fully learned and the quality of the fault samples generated will be too low to meet the requirement of intelligent diagnosis.
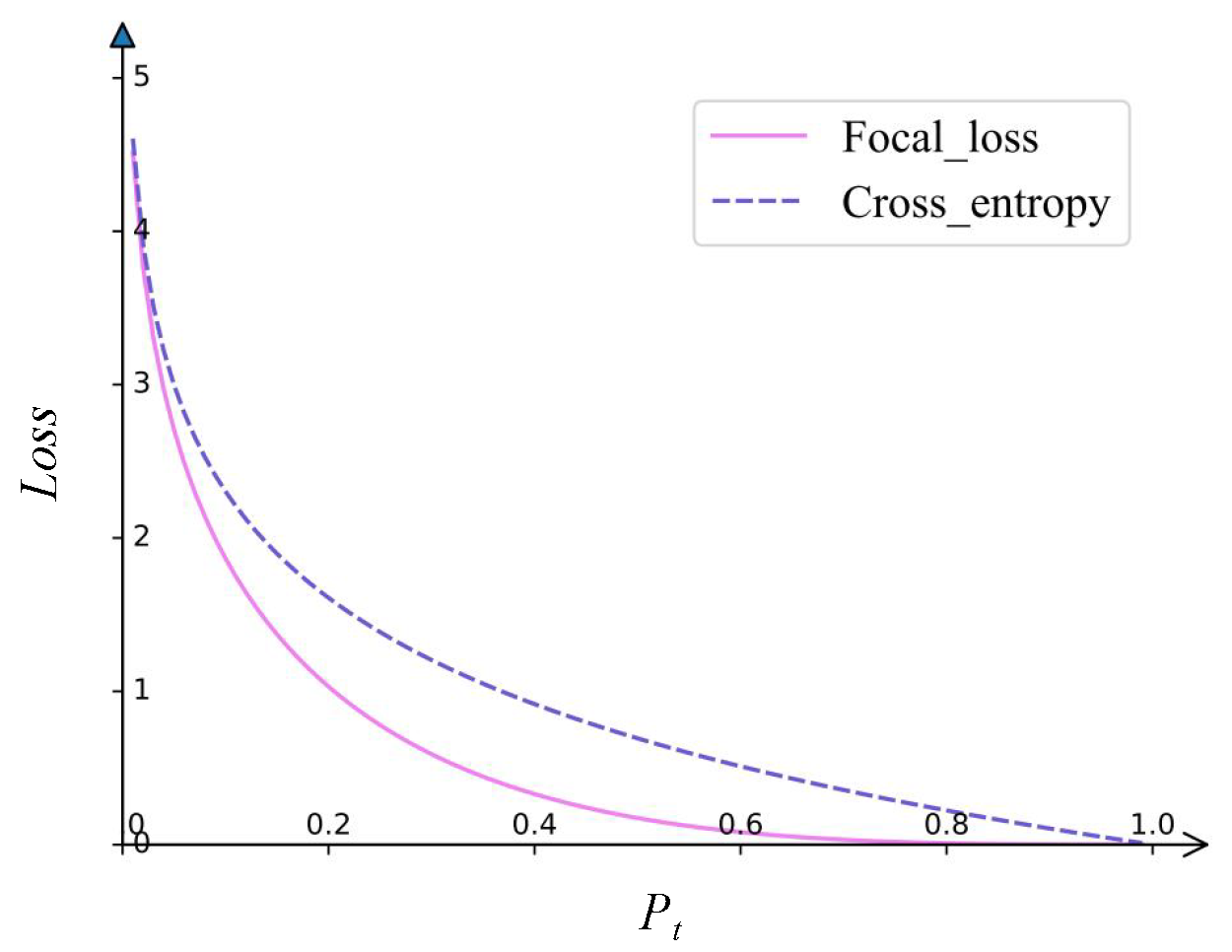
The algorithms based on cost-sensitive learning are dedicated to adjusting the contribution of diverse samples in the model training process by applying cost-sensitive losses [
28]. The class-imbalanced problem is solved by imposing cost penalties on distinct classes at the algorithmic level, and such methods are more economical in terms of computational resources and more suitable for establishing lightweight models. Recently, a series of cost loss functions, such as focal loss (FL) [
29], class-balanced loss [
30], etc., have been proposed to deal with long-tailed distribution data. In the field of fault diagnosis, Geng et al. [
31] proposed a new loss function, namely imbalance-weighted cross-entropy (IWCE), which was employed for learning deep residual networks to handle imbalanced bogies fault data from rail transit systems. In Ref. [
32], a new CNN-based imbalance diagnosis method was proposed because of the long-tail distribution data from the sensor system. The feature extraction module was optimized by the weighted-center-label loss, while the fault recognition module adopted the distance between the feature and the pattern center vector to diagnose the fault. This manner exhibited effective diagnosis capability for imbalanced data through the automatic extraction of separable and discriminative features. However, many existing cost-sensitive learning methods do not pay attention to the dynamic changes of the corresponding contributions of various samples during the model training. Furthermore, when faced with extremely small samples and serious class imbalance problems, the feature extraction module will fail to fully excavate key features from limited data, which further curbs the effectiveness of cost-sensitive learning methods.
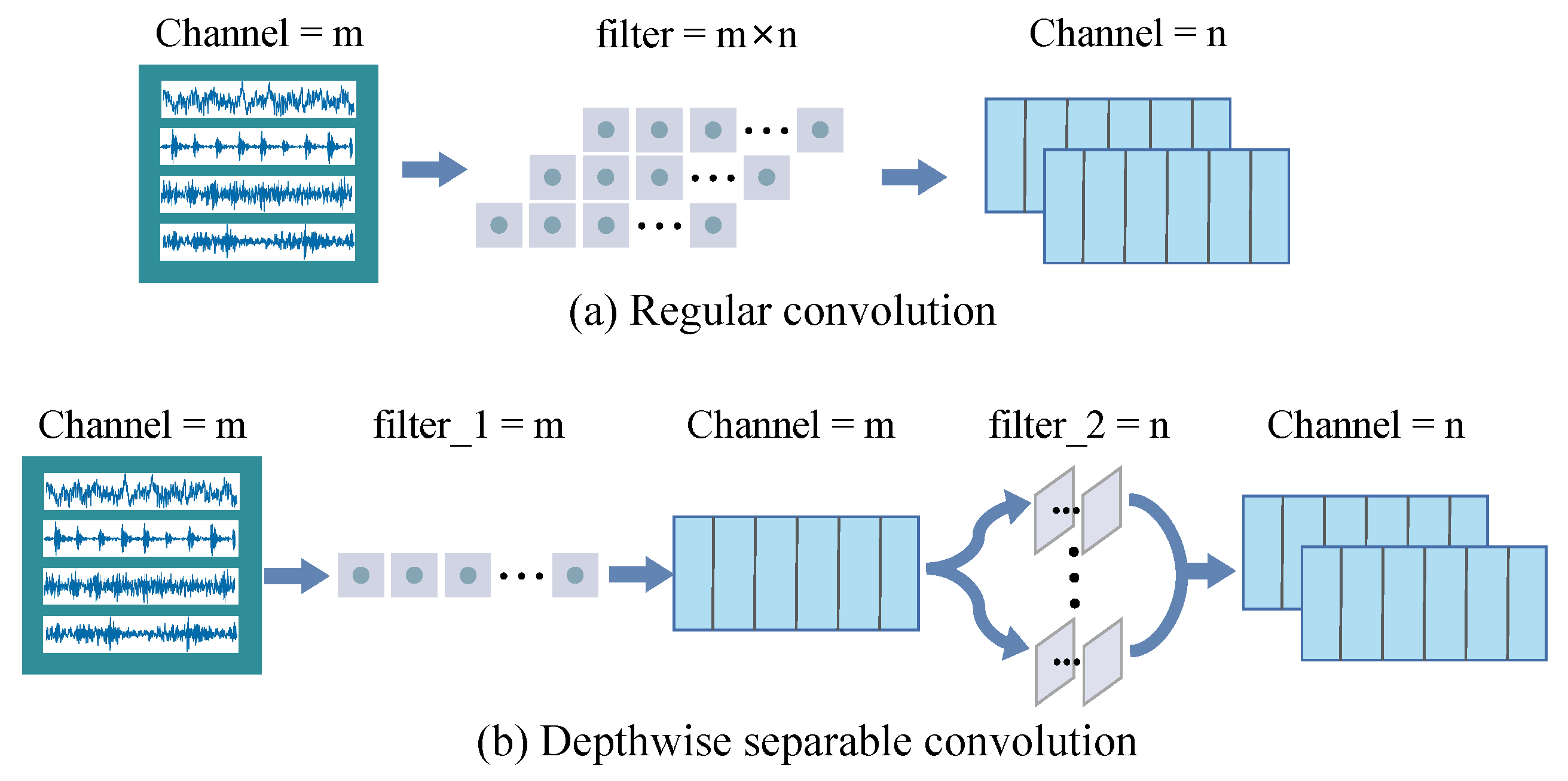
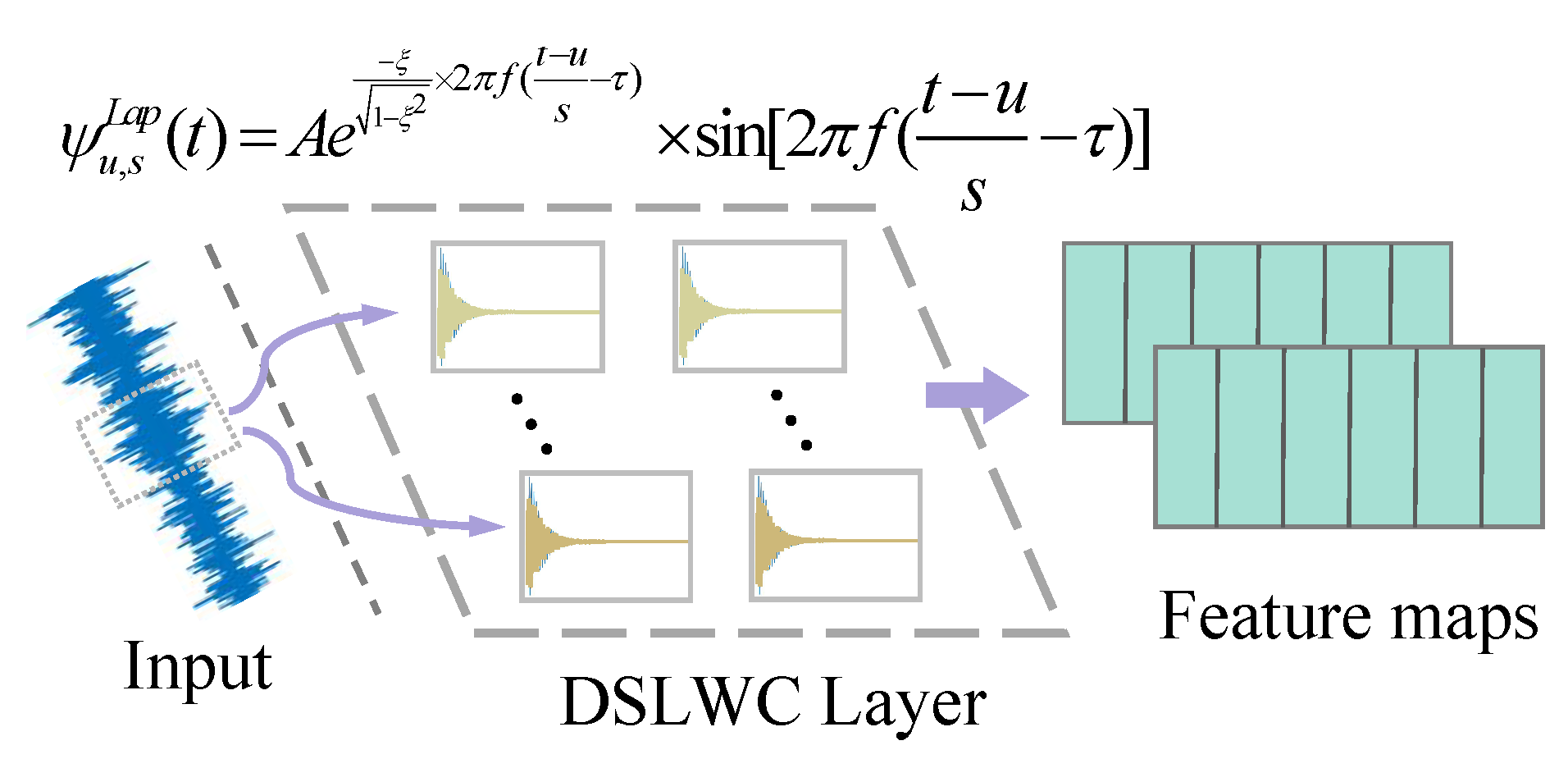
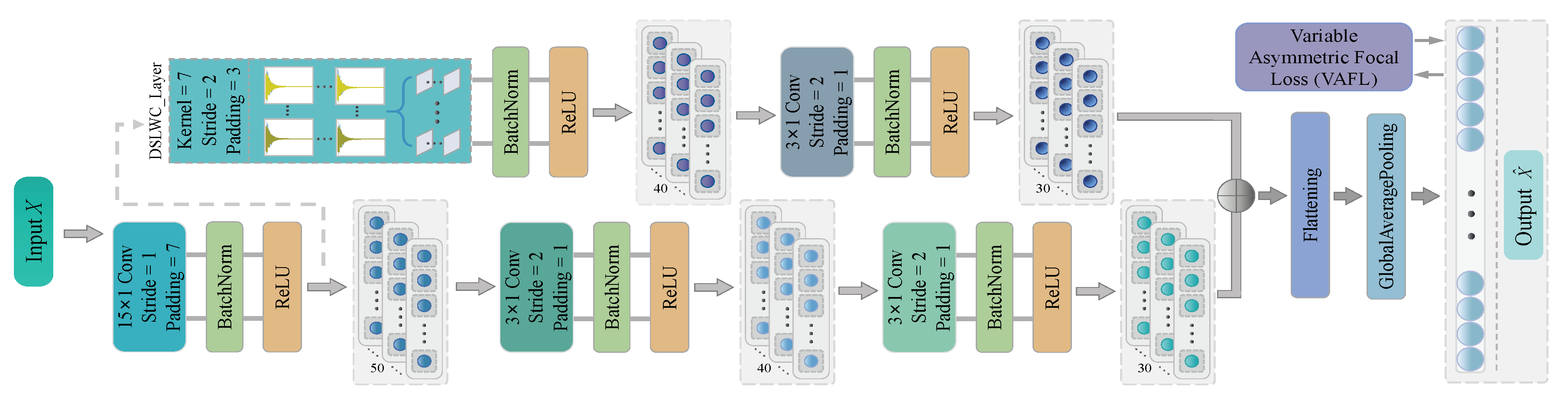
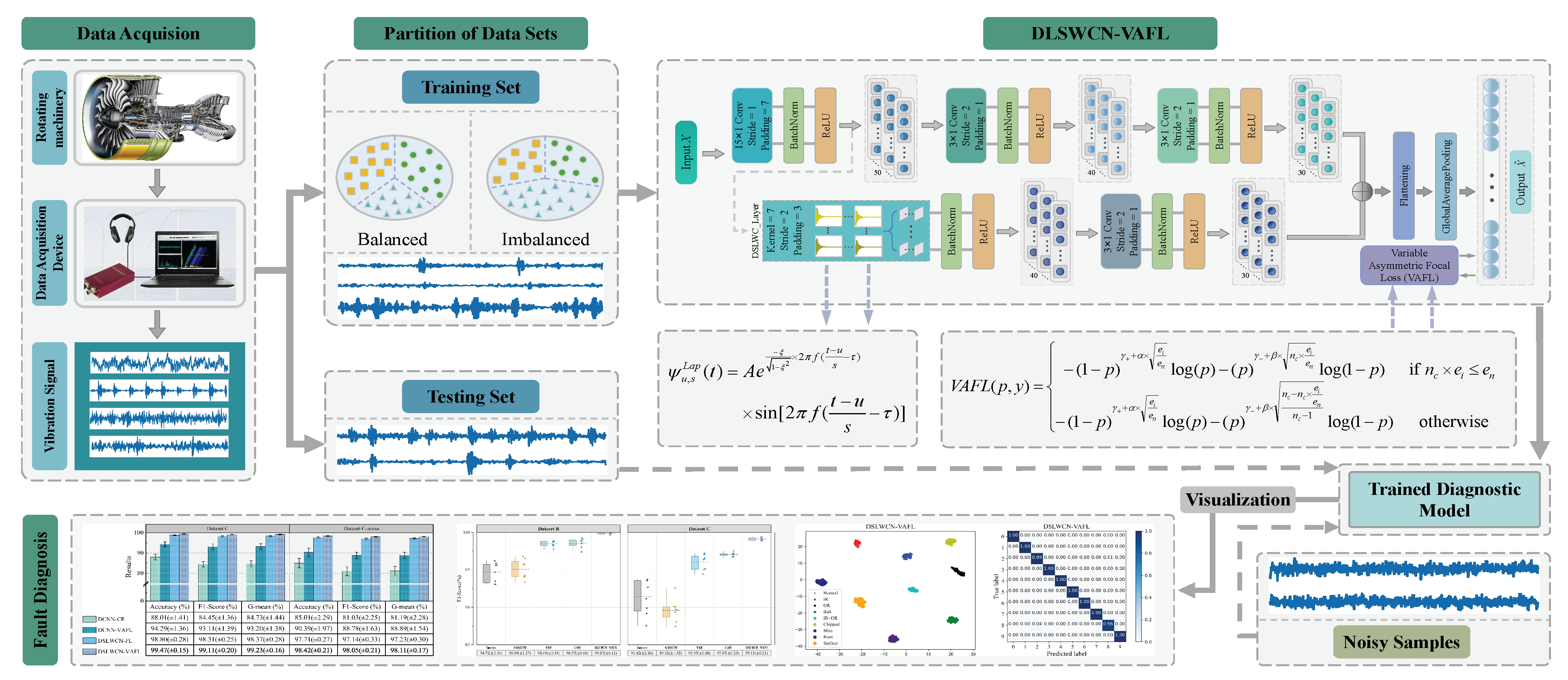
Above all, a lightweight diagnosis framework based on deep separable Laplace-wavelet convolutional network with variable-asymmetric focal loss (DSLWCN-VAFL) is constructed to improve the diagnostic performance in small and imbalanced cases while taking into account the timeliness of faults monitoring. In this method, on the one hand, the multi-scale regular convolutional branch fully learns the time-domain features of the data. On the other hand, the proposed depthwise separable Laplace-wavelet convolution layer containing fewer parameters can excavate the time-frequency features of the data, and then the deeper abstract features are captured by the conventional convolution layer. The combination of these two branches allows for a rich set of discriminative features to be attained from limited samples. In addition, the introduction of global average pooling (GAP) fully retains part of the spatial encoding information of the signals, which not only strengthens the inter-channel connection and reduces the number of parameters but also improves the robustness of the model by increasing the receptive field. Subsequently, a novel asymmetric soft-threshold loss VAFL is designed, which dynamically adjusts the contributions of distinct samples during the convergence of the neural network to alleviate the bias problem of the model. The main contributions of the work are as follows:
- 1.
A lightweight framework for small and imbalanced fault diagnosis is established, namely DSLWCN-VAFL. This method performs well on extremely small samples and seriously imbalanced class data sets, and it consumes only a small amount of computational resources, whose application prospect is very good.
- 2.
A new DSLWC branch with few parameters is designed. The branch containing the DSLWC layer can mine the time-frequency features from the input data while increasing few parameters and then cooperate with the multi-scale regular convolutional branch that fully learns the time-domain features so that the model can extract more abundant sensitive feature vectors of different types from the limited signal samples, thereby improving the classification ability.
- 3.
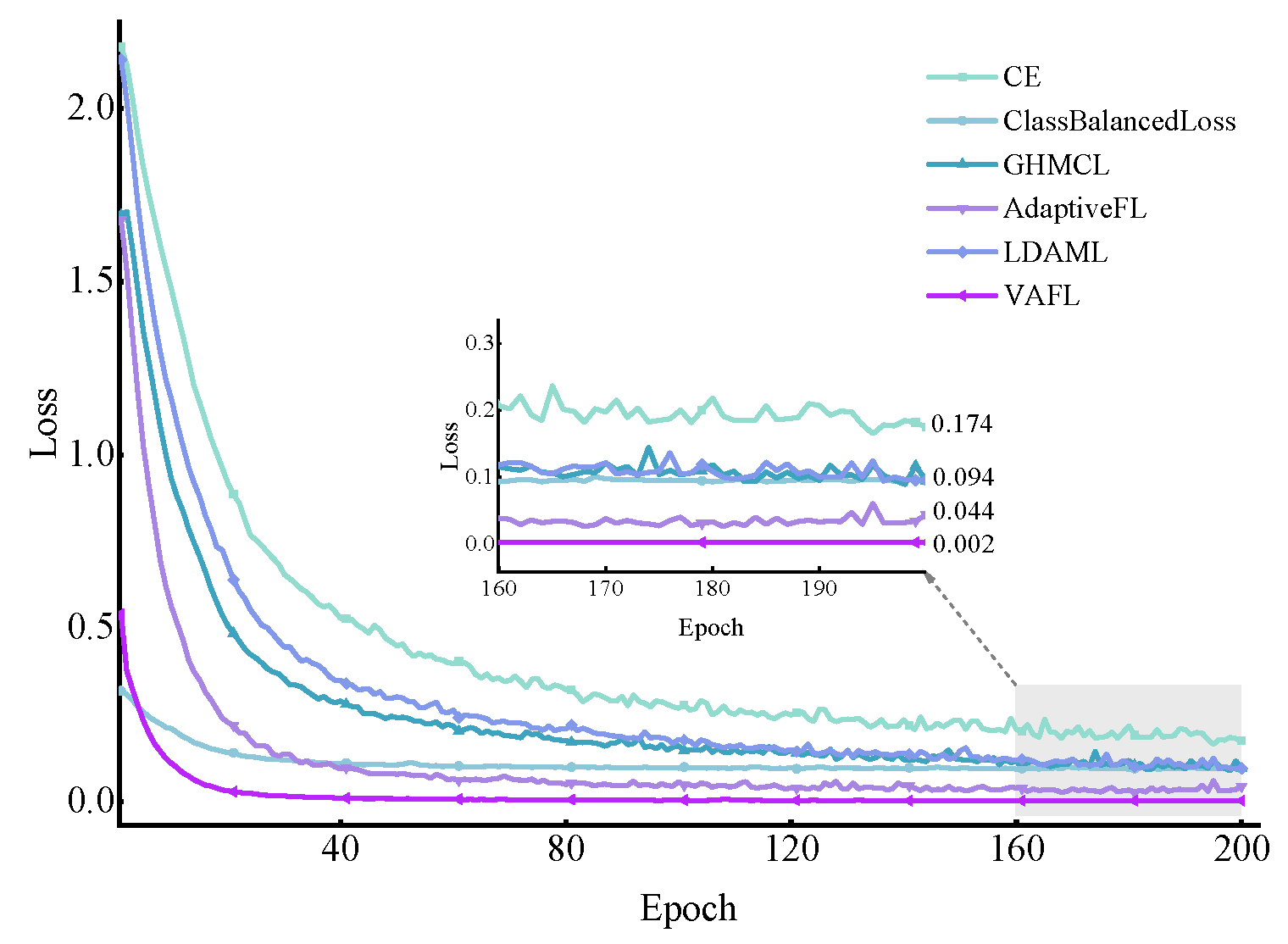
A novel cost-sensitive loss, VAFL, is proposed. VAFL implements that samples of distinct categories impose a variable cost to highlight the misclassified samples of a minority class, which reasonably rebalances the contributions of diverse samples and alleviates the bias problem caused by imbalanced class data.
- 4.
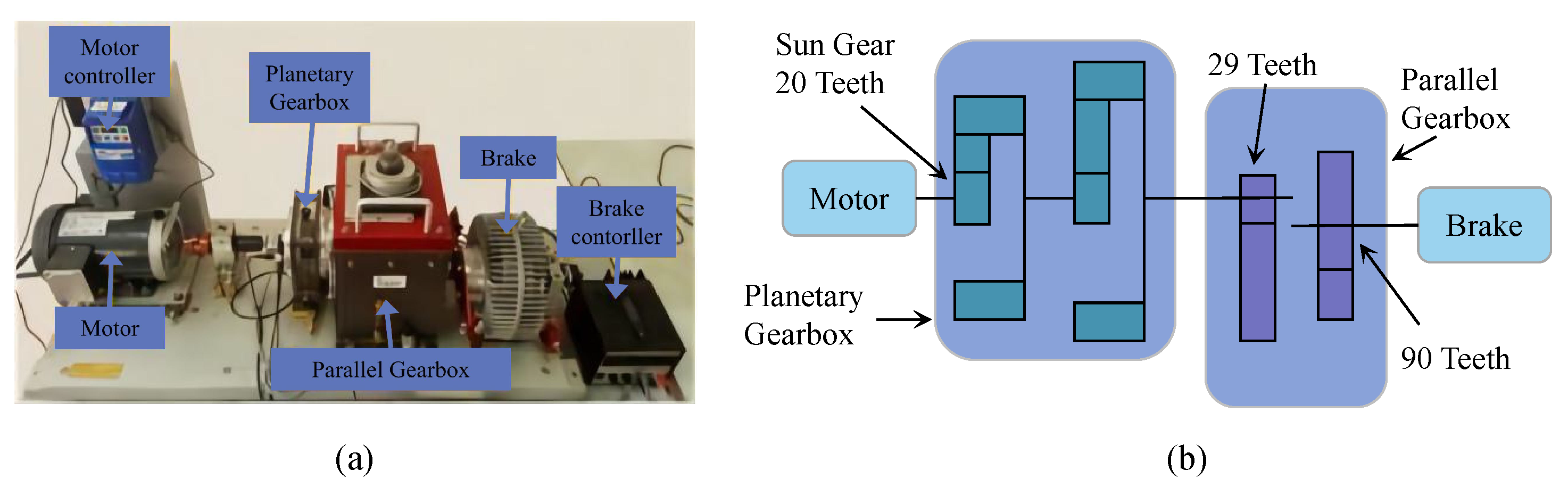
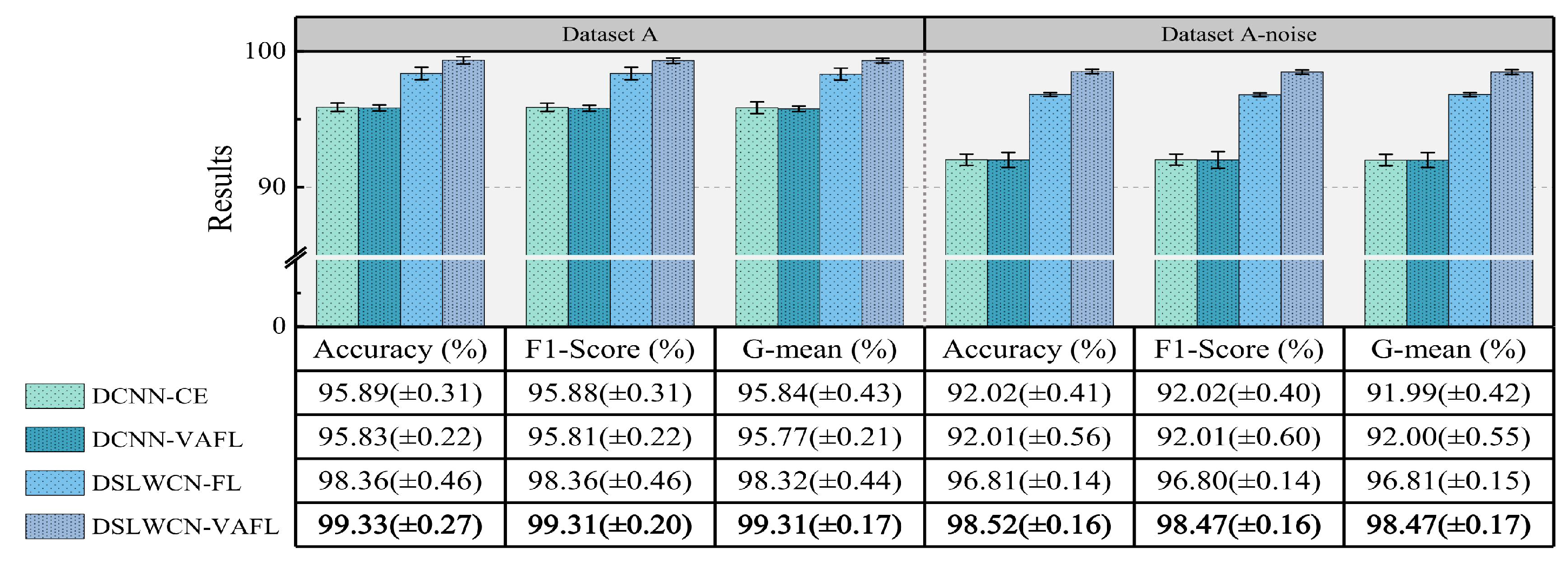
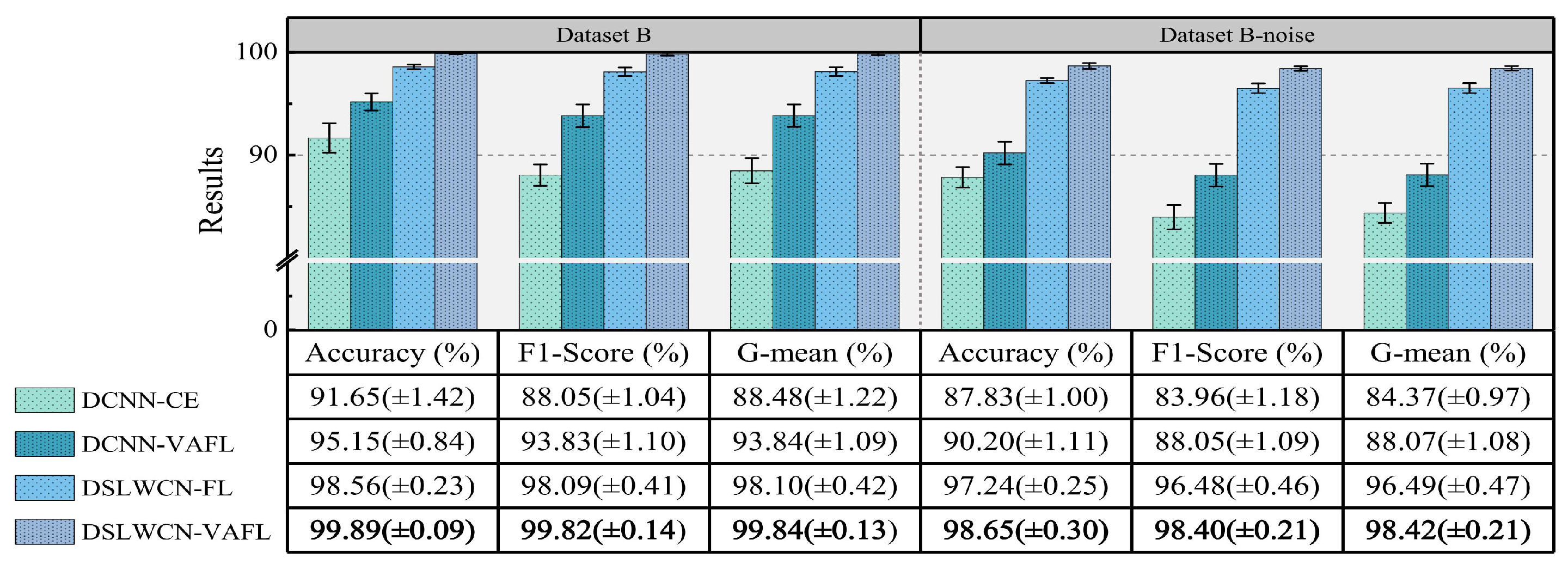
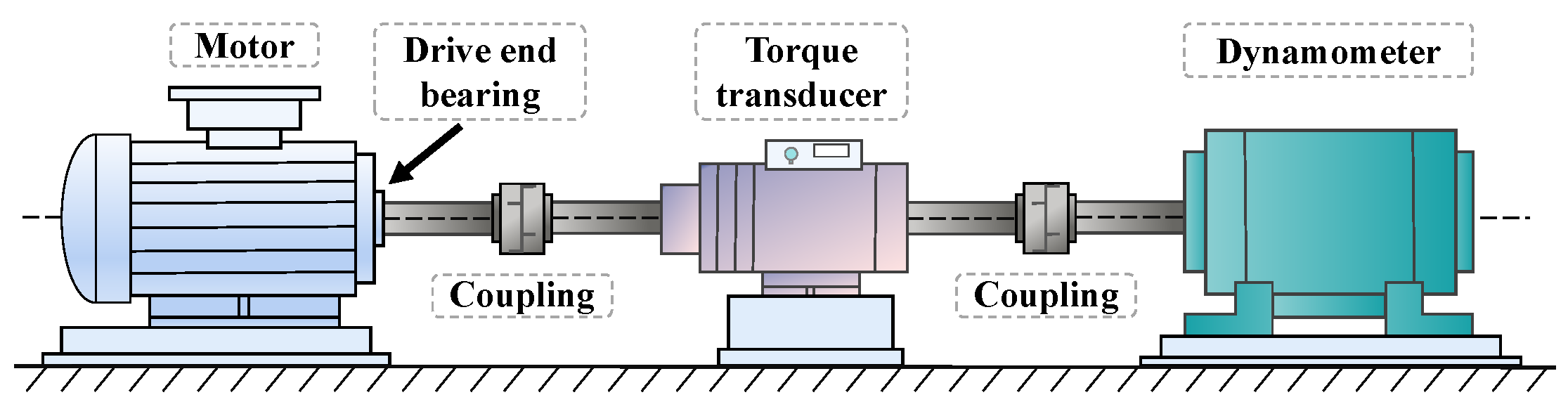
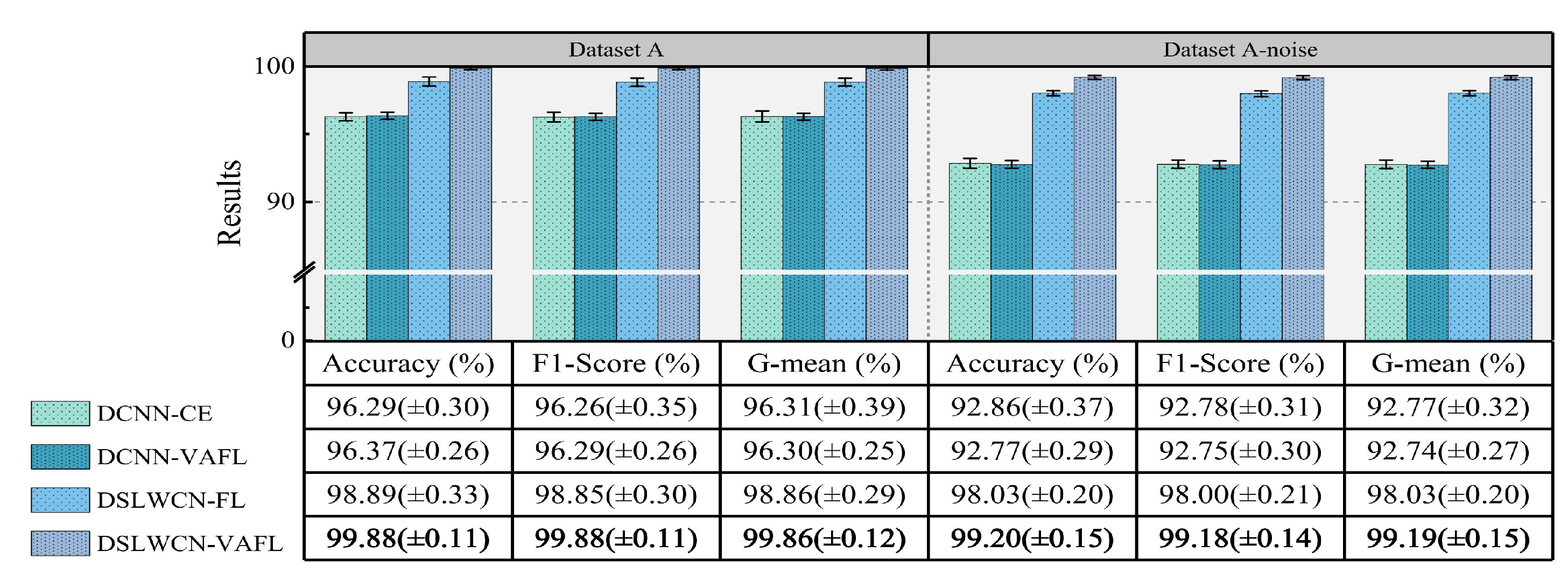
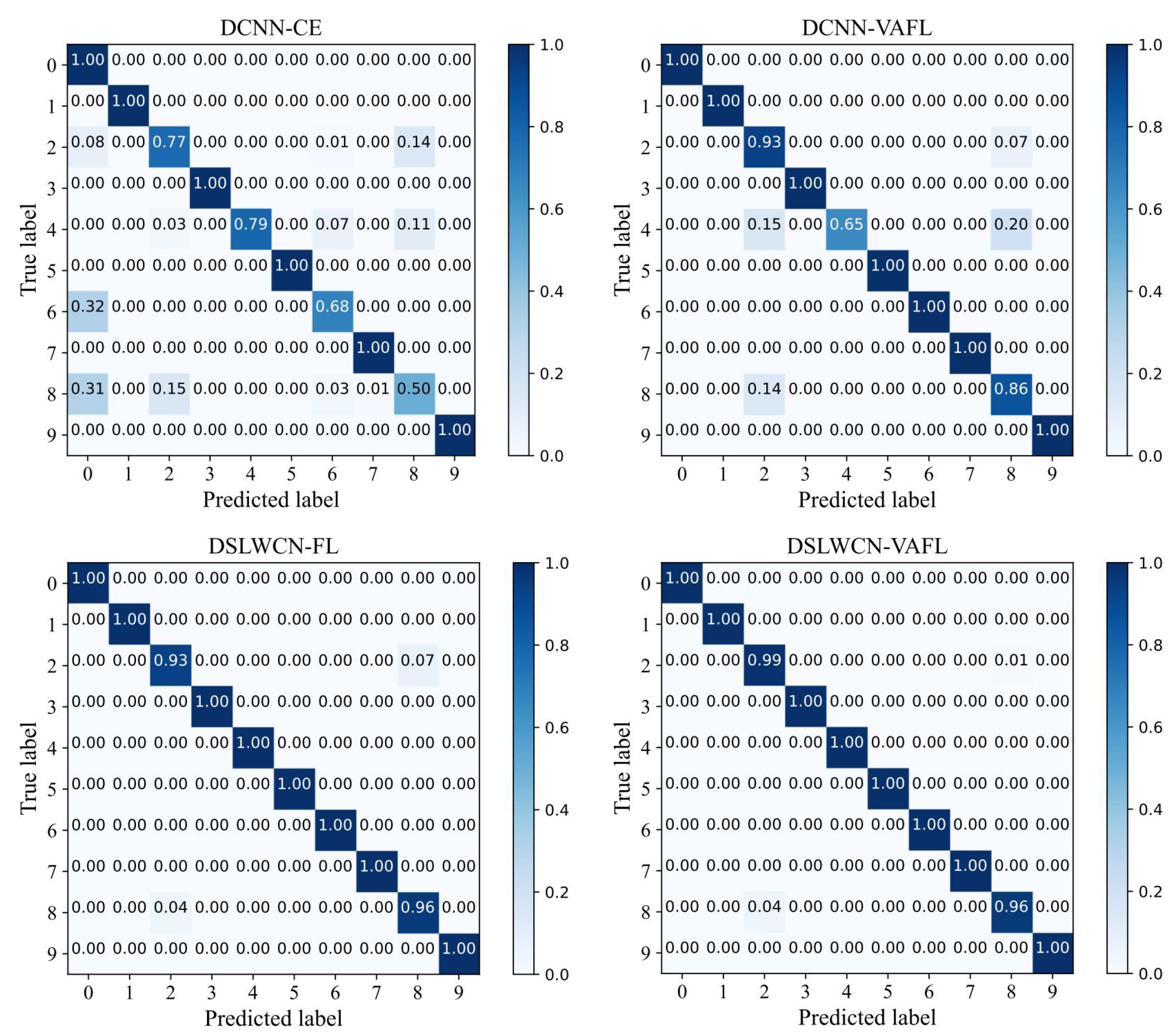
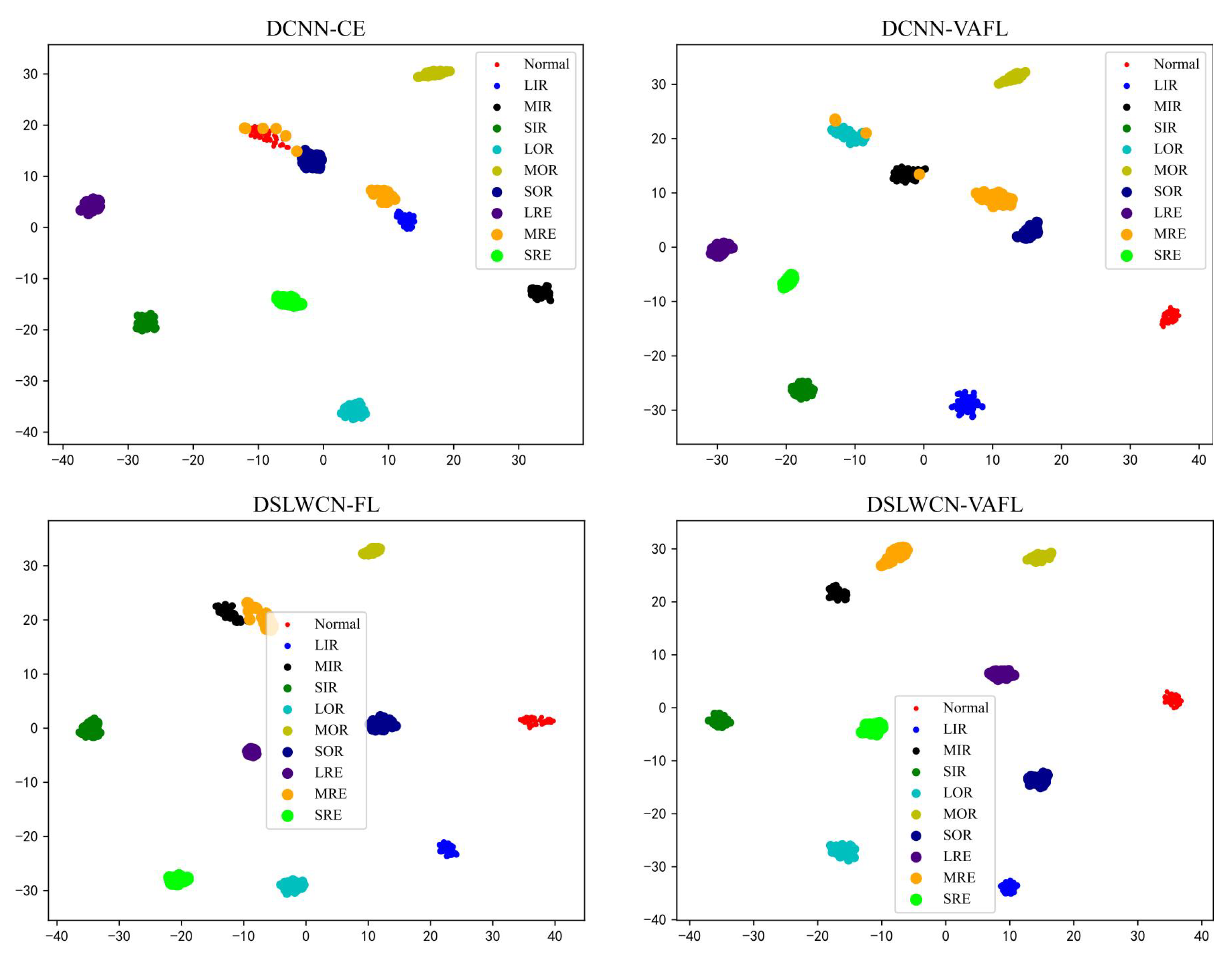
Finally, experiments are conducted on the gear and bearing data sets. The experimental results demonstrate that compared with several popular means, the proposed method achieves an eminent advantage in terms of diagnostic capability and efficiency in the case of limited samples, class imbalance and noisy interference.
The rest of the paper is organized as follows.
Section 2 introduces the basic theories briefly. The proposed method is described in detail in
Section 3.
Section 4 analyzes the proposed method on the gear and bearing signal data sets, respectively. Finally, the conclusion is drawn in
Section 5.
5. Conclusions
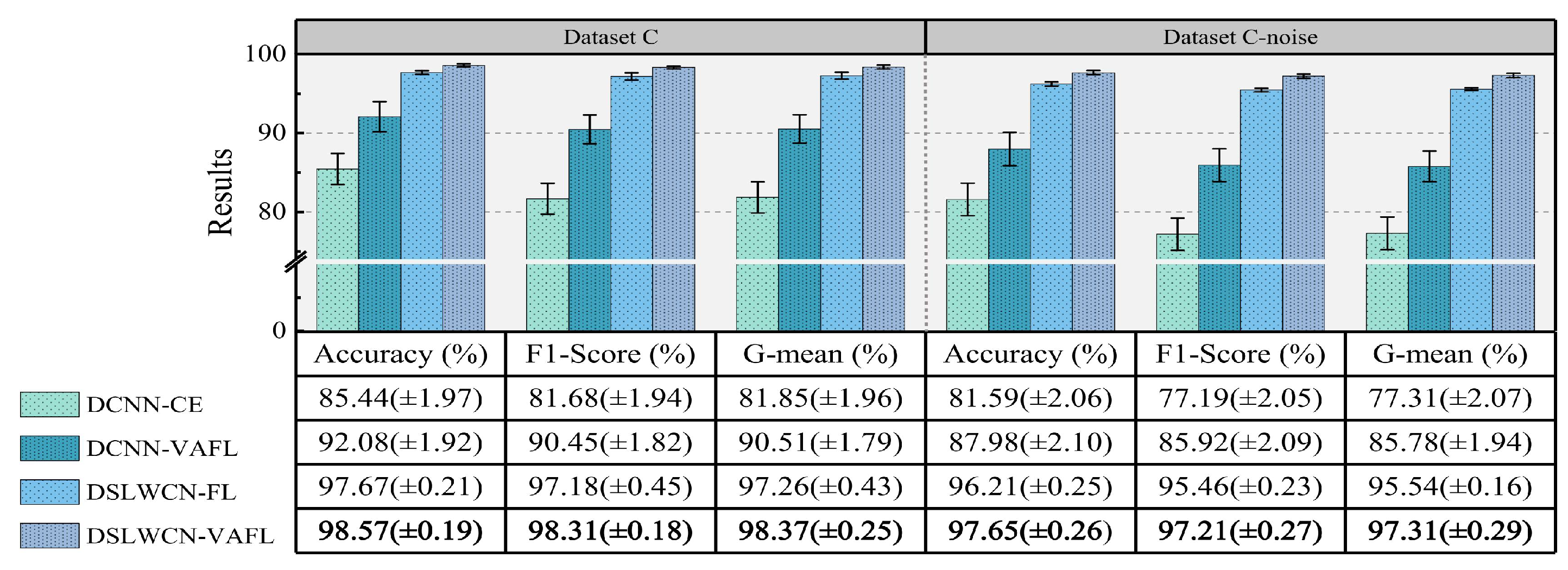
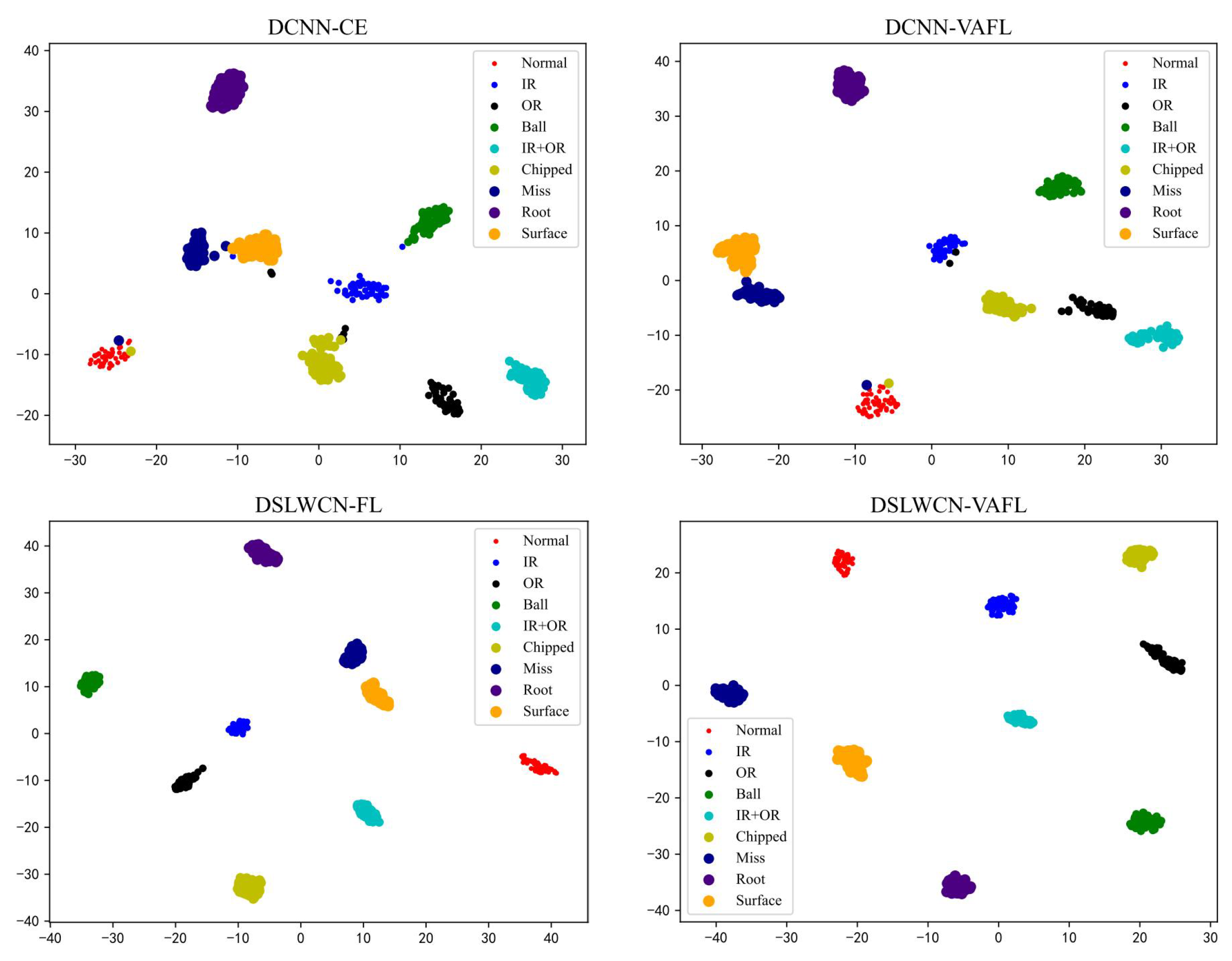
In this paper, a lightweight method named DSLWCN-VAFL is proposed to solve the problem of small and imbalanced data sets. As one of the key technologies in this method, the DSLWC layer not only possesses fewer parameters than regular convolution but also captures time-frequency features from the input 1D data. The branch with the DSLWC layer, combined with the branch of multi-scale regular convolution that can fully learn the time-domain features, achieves abundant discriminative features from limited samples to improve the classification ability of the model. Furthermore, another key technology, namely the novel cost loss VAFL, is designed. The loss function with the ability of dynamic adjustment rebalances the influence of different samples on the convergence of the neural network. Based on the gear and bearing data sets, the diagnostic performance and anti-noise capability of DSLWCN-VAFL in the presence of extremely limited samples and severe class imbalance are discussed in detail. In addition, the effectiveness of each module in the proposed method is verified by ablation experiments. The comparative experiments with some popular methods highlight the superiority of the proposed method. DSLWCN-VAFL not only has promising prospects of application but also provides a new research idea for the solution of class-imbalanced problems.
For future work, the effective processing of multi-source heterogeneous data collected from different sensors is also worth considering, and the noise-insensitive practicability when the data dimension is under strong background noise needs to be further improved. In addition, if faced with variable operating conditions or cross-device diagnosis, it is also worthwhile investigating the employment of techniques such as domain adaptation or transfer learning to solve the imbalanced problem. Finally, the methods for small and imbalanced fault diagnosis through zero-sample learning remain to be explored in extreme cases where no fault samples are available at all.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}