
SQL and NoSQL Databases in the Context of Industry 4.0

 ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
- The paper databases used in the search were: Web of Science, IEEEXplore, Science Direct, Scopus, and Google Scholar;
- The following search string was defined to find papers: “Asset Administration Shell” AND “Database”;
- It was observed that, among the selected databases, the only one to return a considerable number of papers was Google Scholar, which included papers from the other databases and, therefore, was the only one used. The application of search string returned 139 papers;
- The following keywords were defined for ranking the papers: “AAS”; “Asset Administration Shell”; “Database”; “DBMS” (database management system); “Implement*”; and “Storage”;
- Each occurrence of any keyword in the title of the paper assigned 5 points to it (the Google Scholar platform does not allow exporting the abstract or keywords of the article). For instance, the paper entitled “Toward Industry 4.0 Components: Insights into and Implementation of Asset Administration Shells” contains the keywords implementation and “Asset Administration Shell” so it scored 10 points;
- Papers with a score greater than or equal to 5 were classified as accepted, and their content was analyzed;
- It was researched which of the papers classified as accepted cited the implementation data model and/or DBMS used.
3. Basic Concepts
3.1. Relational and NoSQL Databases
3.1.1. Relational Data Model
3.1.2. ACID and BASE Transactional Properties and CAP Theorem
- Atomicity: The transaction must be executed in its entirety or not to be executed. If during the transaction, any failure occurs that prevents the transaction from being completed, any changes that it has performed in the database must be undone;
- Consistency: If a transaction runs entirely from start to finish, without interference from other transactions, it should take the database from one consistent state to another. A consistent database state satisfies the constraints specified in the schema as well as any other database constraints that must be maintained;
- Isolation: The execution of a transaction must not be interfered with by any other transaction running at the same time;
- Durability: Changes applied to the database by a committed transaction must persist in the database. These changes must not be lost due to any failure.
- Single server: There is no distribution. The database runs on a single machine that handles all operations. It is an example of a centralized AAS implementation;
- Partitioning: Different pieces of data on different machines. Aggregate models are ideal here, as they form a natural partitioning unit, making certain users access, most of the time, the same server so there is no need to gather information from different servers, which increases performance compared to a single server implementation;
- Replication: Data can be replicated in a master–slave schema where the master processes updates and replicates this data to other nodes or in a peer-to-peer schema where all nodes can process updates and propagate them.
- Consistency (C): Ensuring that all nodes have identical copies of replicated data visible to applications. It is a little different from the consistency concept of ACID properties. In that case, consistency means not violating database restrictions. However, it can be considered that “having the same copy of a data replicated in all nodes that this data is replicated on” is a restriction, so the concepts start to resemble each other;
- Availability (A): Each write or read operation will be successfully processed (system available) or will fail (system unavailable). A “down” node is not said to be unavailable;
- Partition Tolerance (P): A partition tolerant system continues to operate if a network fails to connect nodes, resulting in one or more network partitions. In this case, nodes in a partition only communicate with each other.
- Basically available (BA): the system must be available even if partial failures occur;
- Flexible State (S): the system may not have consistent data all the time;
- Eventually consistent (E): consistency will be achieved once all writes are propagated to all nodes.
3.1.3. NoSQL Data Models
- They do not use the SQL language: The absence of a declarative query language, with a wide range of “features” that are sometimes unnecessary, requires more significant effort for developers since the functions and operations have to be implemented through the language of programming [26];
- Horizontally scalable: The ability of NoSQL DBMS to scale out is linked to two main characteristics. (1) By not having ACID transactional properties (aggregate-oriented models), it allows for relaxing consistency, and thus balancing the consistency–latency trade-off in the way which is most suitable for the application, without giving up partition tolerance, as it was previously discussed. (2) The orientation to aggregates allows for a “natural” or intuitive data partitioning unit, as data from an aggregate are commonly accessed together and can be allocated on the same server, which makes the user of this data access, in the majority sometimes, the same server [27].
- Key-value: Key-value DBMSs are possibly the simplest NoSQL systems. These DBMSs store their data in a table without a rigid schema, where each line corresponds to a unique key and a set of self-described objects called value. These can take different formats, from the simplest as strings, passing through tables as in the relational model, reaching more elaborate formats such as JavaScript Object Notation (JSON) and eXtensible Markup Language (XML) documents. Thus, they can store structured, semi-structured, and unstructured data in one format (key, value). The key-value data model is often represented as a hash table. This data model is aggregate oriented, meaning that each value associated with a unique key can be understood as an aggregate of objects that can be retrieved in their entirety through the key. The content of these aggregates can be different for each key. The aggregate’s opacity guarantees the possibility of storing any data in the aggregates; that is, the DBMS does not interpret the aggregate content, seeing it only as a set of bits that must always be associated with its unique key. This has the practical implication of generally not allowing partial retrievals on aggregate content. The operations implemented by key-value DBMSs are the insertion or update of a pair (key, value), the retrieval of a value from its key, or the deletion of a key;
- Documents: Document-oriented DBMSs are those in which data is stored in document format. They can be understood as a key-value DBMS in which the only allowed formats for the values are documents such as XML, JSON, or PDF. A fundamental difference between the document and key-value data models is that the former allows for partial aggregate retrievals as it stores self-described data format. In other words, aggregates are not opaque, they are not seen by the DBMS merely as a set of bits, and it is possible to define indexes on the contents of the aggregates that allow operations to be performed on specific items of this data set. As with the key-value data model, the content of each document does not follow a fixed schema. Document labels that guarantee the self-description of the data and enable partial recoveries also allow different keys to have documents with different content (attributes). Thus, it allows the storage of structured and semi-structured data. There are still DBMSs that allow the storage of unstructured data such as texts;
- Column family: In column family databases, data is stored similarly to key-value databases. However, the value can only be composed of a set of tables, each of which has a name (identifier) and forms a column family. In each of these tables, columns are self-described; they have a key (also called a qualifier) and its value, which is the data itself. Thus, a column family database is formed by a table without a rigid structure containing unique keys and a series of column family associated with each key in each row.Some considerations can be made about this model. The first is that keys do not need to have the same column family. The second observation is that, for each key, each column family can only contain the columns of interest; that is, the column family does not need to be composed of the same columns for all the keys. The column family forms a data aggregate that is frequently accessed together and, because these columns contain their keys, the aggregates are not opaque to the DBMS, thus being possible to perform partial recoveries through the aggregates through the indexes of the columns;
- Graphs: In graph-oriented DBMSs, data is stored in a collection of nodes, which represent entities, and directed vertices, which represent relationships among these entities. The set of nodes and vertices form graphs in which the two elements that compose them can contain labels and attributes associated with them, which are the data itself. Regarding the characteristics of the data models presented so far, the flexibility in data representation due to the absence of a fixed schema is one of the few similarities between the graph data model and the other data models mentioned, as both vertices and nodes can contain attributes different from each other. Concerning differences, the graph model is not aggregate oriented, it usually has ACID transactional properties, it is best suited for single server (non-distribution) implementations, can represent small records with complex relationships to each other, and it is more efficient in identifying patterns. Unlike aggregate-oriented models, where partial recoveries can only be made on one aggregate at a time (when allowed), in the graph model they can be conducted for the graph as a whole.
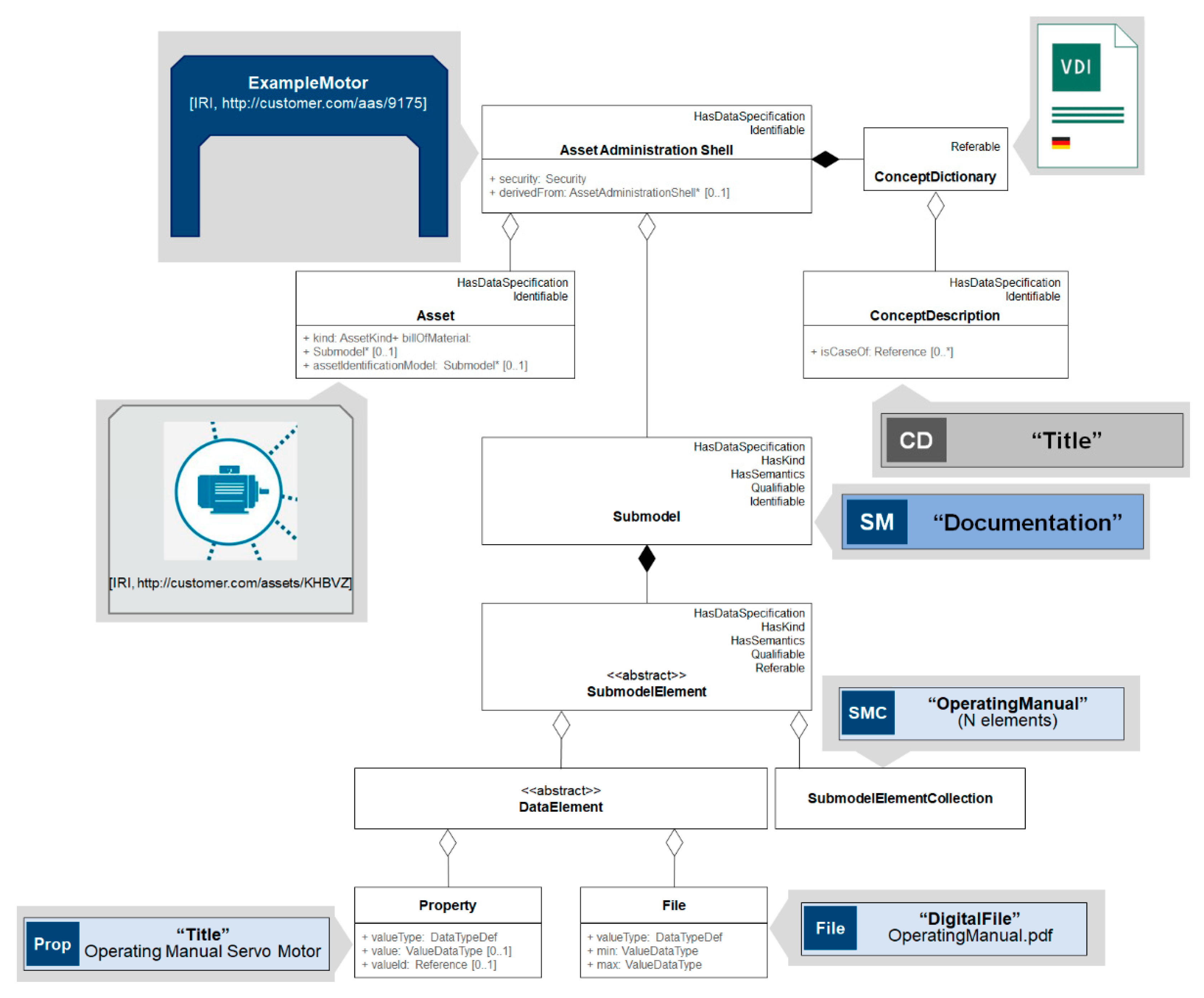
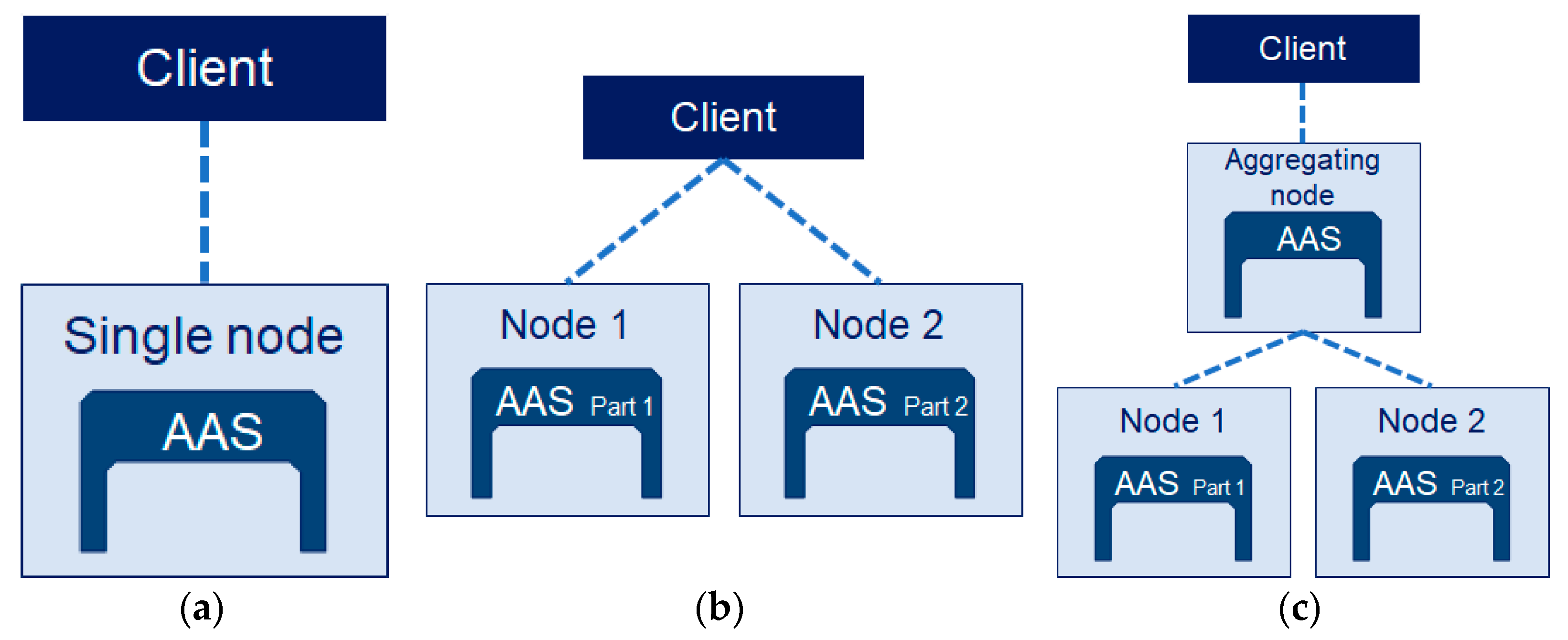
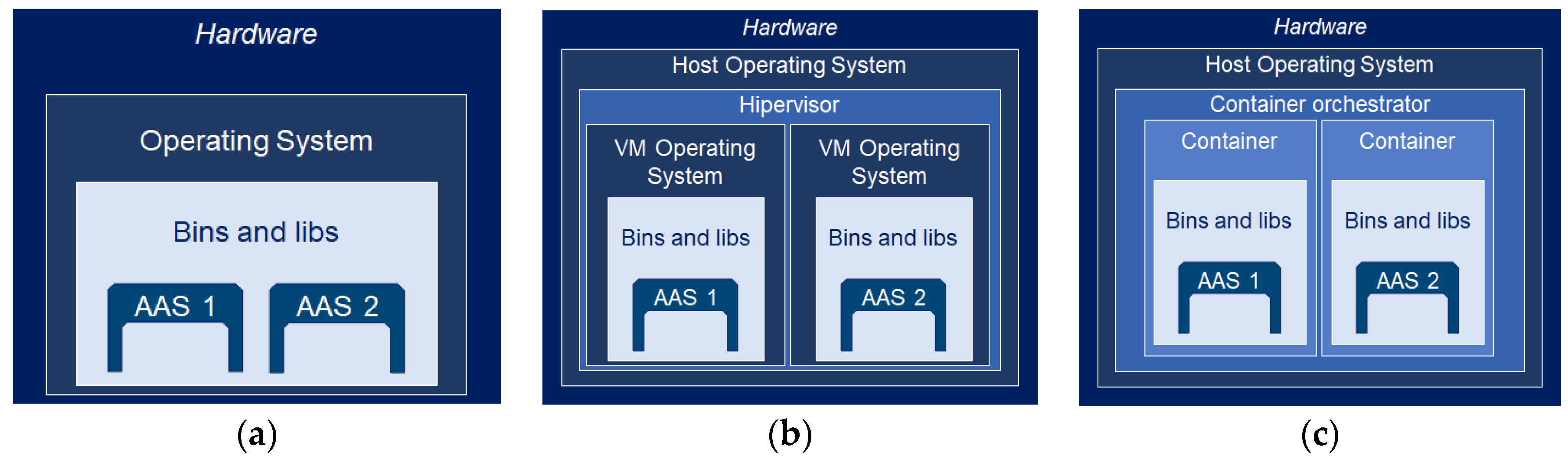
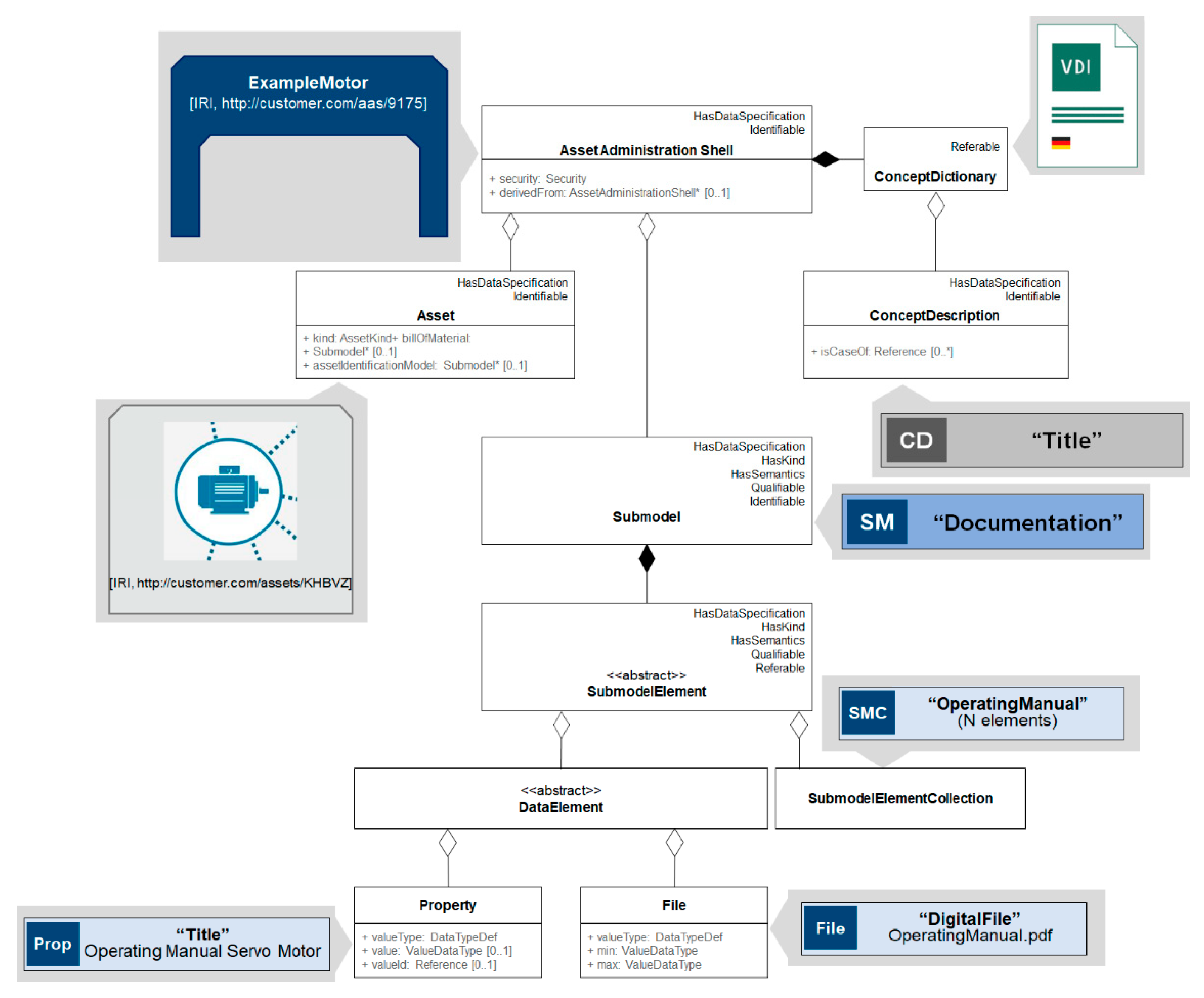
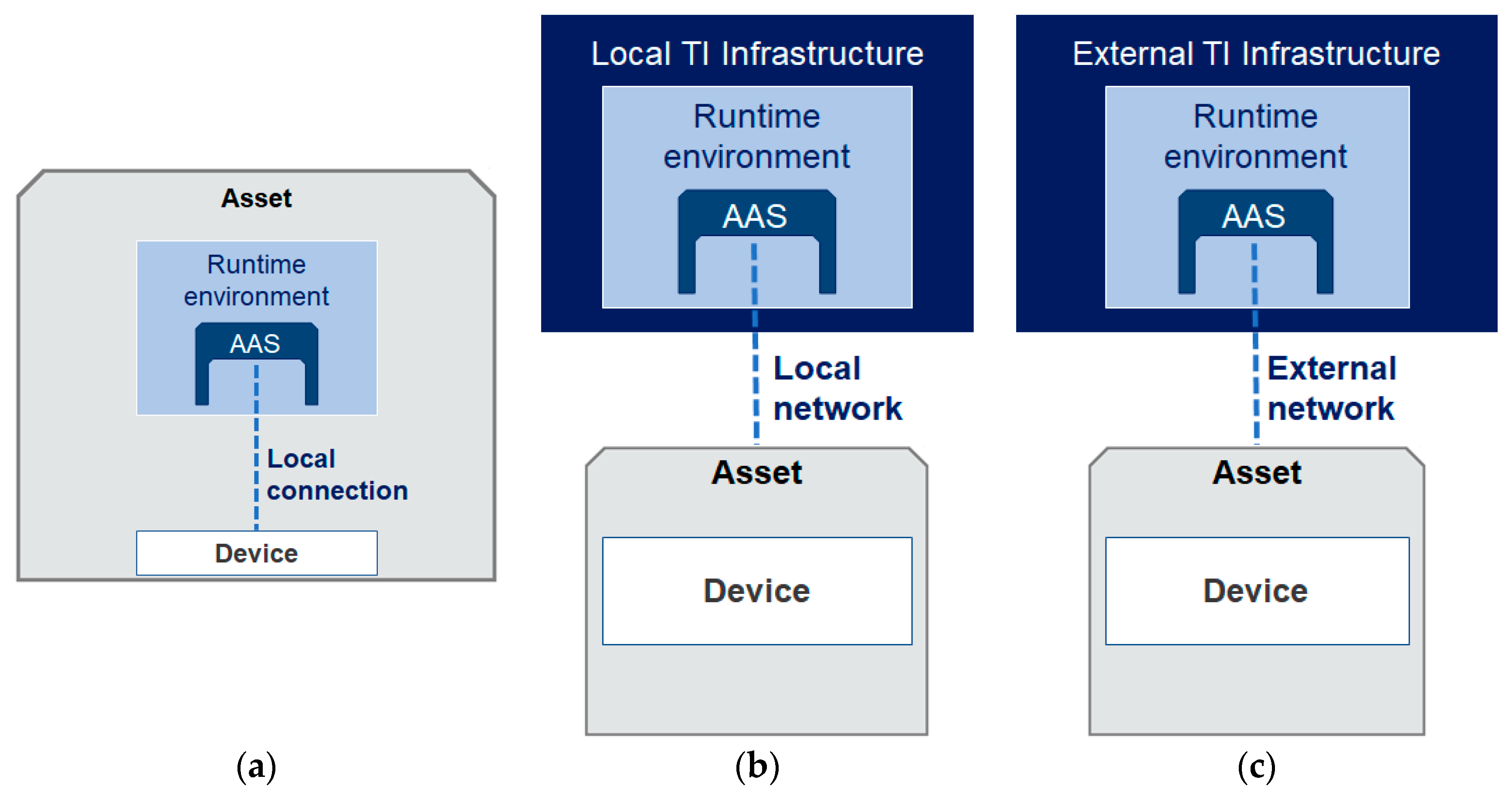
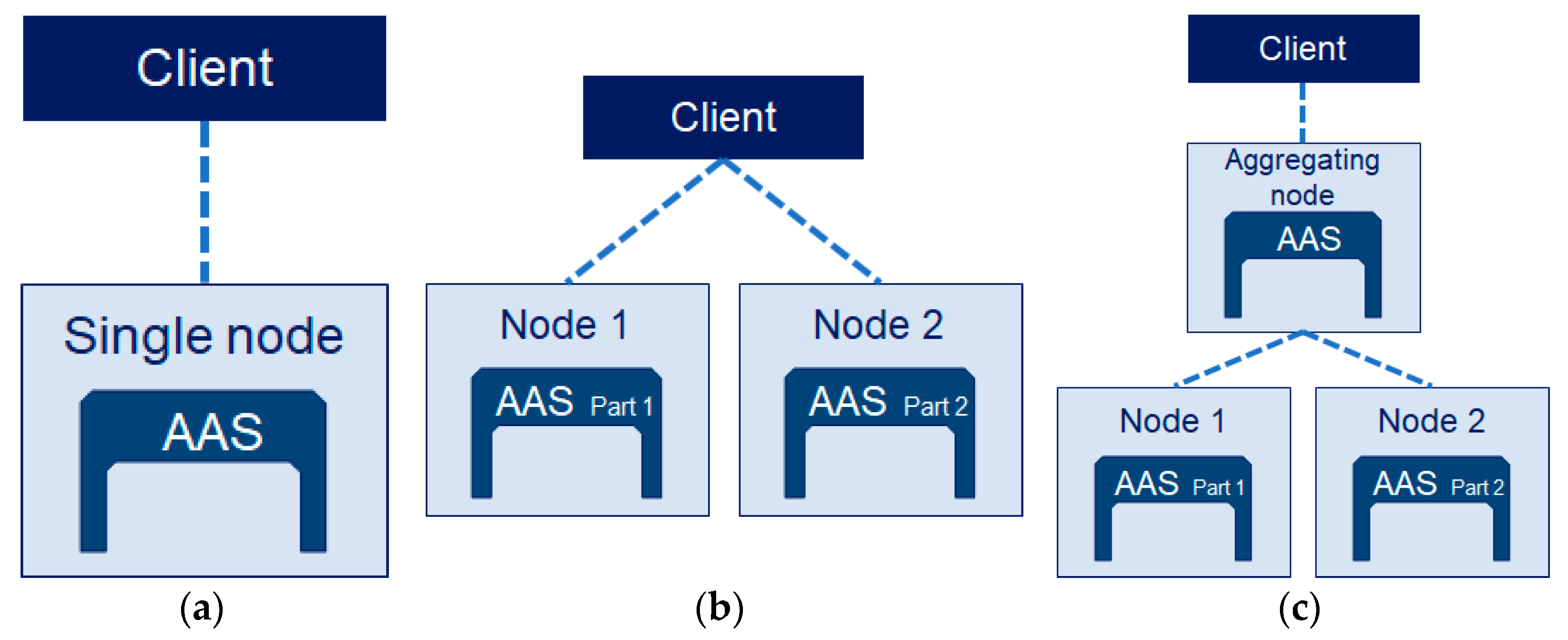
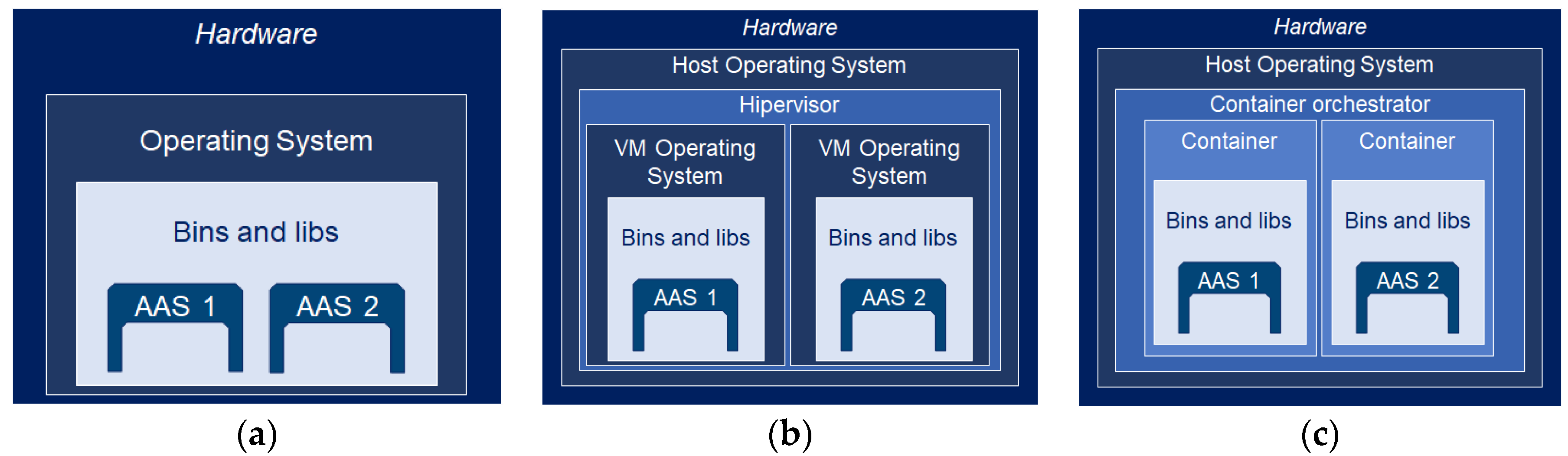
3.2. Asset Administration Shell
4. Results
4.1. Data Characteristics in the Context of I4.0
4.2. Data Models in the Context of Industry 4.0
4.2.1. Operational and Analytical Databases
- Operations: Operational databases are generally dedicated to online transaction processing (OLTP) applications, routine operations of an organization, which act on small fractions of the data, occur with great frequency, and must be processed efficiently, usually in real time [25]. Such operations are, for example, insertions, updates, deletions, and queries [26]. Analytical databases, in turn, are optimized for online analytical processing (OLAP), which allow you to extract value from the data through complex analytics. They are mainly dedicated to data recovery, involving grouping and joining operators, statistical functions, and complex Boolean conditions [26], applied to a large number of records and which, for this reason, usually occur in batches;
- Volume and volatility: Data analysis requires not only a comprehensive system perspective but often a considerable amount of historical data, such as time series. Thus, an analytical DB stores volumes of data much larger than its data sources—transactional DBs—in addition to ensuring the persistence of this data for much longer, while traditional DBs usually store current and non-historical data [62]. Thus, changes in the content of an analytical DB usually occur incrementally and in batches, while changes in transactional DBs occur continuously [26,62];
- Orientation and users: Analytical DBs are systems dedicated to facilitating the exploratory analysis of data, aiding decision-making and business processes [24]. For this reason, they are said to be subject oriented and generally dedicated to few users. Operational DBs, in turn, are purpose oriented and may have few to many users [62].
4.2.2. Volume
4.2.3. Variety
4.2.4. Velocity
- Speed: deals with the speed at which data can be processed. To calculate the processing speed, the time spent to capture data should not be taken into account, considering only the actual processing time;
- Consistency: concerns the accuracy and precision of the results obtained from data processing. Inconsistent systems cannot use all available data to be processed, adopting sampling techniques, which leads to less precision and accuracy of results. On the other hand, systems with greater consistency use all available data in processing, obtaining more precise and accurate results;
- Volume: deals with the amount of data that can be processed. Large volumes of data require distributed processing, while smaller volumes can be processed centrally.
4.2.5. Veracity
4.2.6. Value
5. Discussion
- The first scenario characterized by low volume, velocity, and veracity is more likely to be observed in operational DBs even though low velocity is usually not desirable. Considering the correlation between veracity and consistency presented in Section 4.2.5, the BASE model allows flexibility of consistency and, consequently, of veracity. This is the determinant factor for this recommendation;
- The second scenario with low volume and high veracity is again more likely to be observed in operational DBs despite the low velocity. As there is no need for distribution due to the low volume nor high-velocity requirements, ACID and BASE can ensure high veracity;
- The third scenario with low volume, high velocity, and low veracity can represent an operational DB. As there is a demand for high velocity at the expense of veracity, the BASE model is more suitable as it allows for relaxation of consistency in favor of availability;
- The scenario with low volume and high velocity and veracity well represent an operational DB as well as an analytical DB in its early stages. Since the database design needs to take into account the evolution of the DB, this analysis is made considering the former. Based on the CAP theorem and the SCV principle, the requirements of high speed and veracity imply the need for centralization of the database so that it is not subject to partition. Since the volume of data considered is small, there is no problem regarding distribution. For a CA system such as this, the ACID model is more suitable;
- Despite the low veracity, the fifth scenario may better represent an analytical DB than an operational DB. Although this type of DB requires high veracity (consistency), the distribution and the lack of strict concurrency control make the BASE model more suitable;
- The sixth scenario represents an analytical DB well. The requirement of high veracity (consistency) at the expense of speed can be initially associated with the ACID model. However, the distribution and no need for strict concurrency control present in an analytical DB mean that the BASE model can also be used;
- The scenario with high volume and velocity and low veracity illustrates an operational DB well. As there is a demand for high speed at the expense of veracity, the BASE model is more suitable as it allows for relaxation of consistency in favor of availability, especially in a distributed system;
- Regarding the eighth scenario, even though it is ideal for both an operational and an analytical DB, based on the CAP theorem and the SCV principle, it is not possible to guarantee the three properties simultaneously neither with the BASE model nor with ACID. However, it is important to recognize that the very nature of the analytical distributed DB without the need for concurrency control contributes to high veracity. Thus, in an analytical database, to ensure distribution of a large volume of data and high processing speed, the BASE model can be used;
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nakayama, R.S.; de Mesquita Spínola, M.; Silva, J.R. Towards I4.0: A Comprehensive Analysis of Evolution from I3.0. Comput. Ind. Eng. 2020, 144, 106453. [Google Scholar] [CrossRef]
- Tyrrell, A. Management Approaches for Industry 4.0: A Human Resource Management Perspective. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 5309–5316. [Google Scholar]
- Lasi, H.; Fettke, P.; Kemper, H.G.; Feld, T.; Hoffmann, M. Industry 4.0. Bus. Inf. Syst. Eng. 2014, 6, 239–242. [Google Scholar] [CrossRef]
- Fragapane, G.; Ivanov, D.; Peron, M.; Sgarbossa, F.; Strandhagen, J.O. Increasing Flexibility and Productivity in Industry 4.0 Production Networks with Autonomous Mobile Robots and Smart Intralogistics. Ann. Oper. Res. 2020. [Google Scholar] [CrossRef] [Green Version]
- Yazdi, P.G.; Azizi, A.; Hashemipour, M. An Empirical Investigation of the Relationship between Overall Equipment Efficiency (OEE) and Manufacturing Sustainability in Industry 4.0 with Time Study Approach. Sustainability 2018, 10, 3031. [Google Scholar] [CrossRef] [Green Version]
- Mohamed, N.; Al-Jaroodi, J.; Lazarova-Molnar, S. Leveraging the Capabilities of Industry 4.0 for Improving Energy Efficiency in Smart Factories. IEEE Access 2019, 7, 18008–18020. [Google Scholar] [CrossRef]
- Brozzi, R.; D’Amico, R.D.; Pasetti Monizza, G.; Marcher, C.; Riedl, M.; Matt, D. Design of Self-Assessment Tools to Measure Industry 4.0 Readiness. A Methodological Approach for Craftsmanship SMEs. IFIP Adv. Inf. Commun. Technol. 2018, 540, 566–578. [Google Scholar] [CrossRef]
- Morkovkin, D.E.; Gibadullin, A.A.; Kolosova, E.V.; Semkina, N.S.; Fasehzoda, I.S. Modern Transformation of the Production Base in the Conditions of Industry 4.0: Problems and Prospects. J. Phys. Conf. Ser. 2020, 1515, 032014. [Google Scholar] [CrossRef]
- Hozdić, E. Smart Factory for Industry 4.0: A Review. Int. J. Mod. Manuf. Technol. 2015, 7, 28–35. [Google Scholar]
- Shi, Z.; Xie, Y. Smart Factory in Industry 4.0. Syst. Res. Behav. Sci. 2020, 37, 607–617. [Google Scholar] [CrossRef]
- Wang, S.; Wan, J.; Li, D.; Zhang, C. Implementing Smart Factory of Industrie 4.0: An Outlook. Int. J. Distrib. Sens. Netw. 2016, 12, 3159805. [Google Scholar] [CrossRef] [Green Version]
- Klingenberg, C.O.; Borges, M.A.V.; Antunes, J.A.V. Industry 4.0 as a Data-Driven Paradigm: A Systematic Literature Review on Technologies. J. Manuf. Technol. Manag. 2021, 32, 570–592. [Google Scholar] [CrossRef]
- Adolphs, P.; Bedenbender, H.; Dirzus, D.; Ehlich, M.; Epple, U.; Hankel, M.; Heidel, R.; Hoffmeister, M.; Huhle, H.; Kärcher, B.; et al. Reference Architecture Model Industrie 4.0 (RAMI4.0); ZVEI—German Electrical and Electronic Manufacturers’ Association: Berlin, Germany, 2015. [Google Scholar]
- IVI—Industrial Value Chain Initiative. Industrial Value Chain Reference Architecture (IVRA); Chiyoda: Chuo-ku, Japan, 2016. [Google Scholar]
- Lin, S.-W.; Murphy, B.; Clauser, E.; Loewen, U.; Neubert, R.; Bachmann, G.; Pai, M.; Hankel, M. Architecture Alignment and Interoperability. Plattf. Ind. 4.0 2017, 19, 2–15. [Google Scholar]
- De Oliveira, V.F.; Pinheiro, E.; Daniel, J.F.L.; Guerra, E.M.; Junqueira, F.; Santos Fo, D.J.; Miyagi, P.E. Infraestrutura de Dados Para Sistemas de Manufatura Inteligente. In Proceedings of the 14th IEEE International Conference on Industry Applications, São Paulo, Brazil, 15–18 August 2021; pp. 516–523. [Google Scholar]
- Schwab, K. The Fourth Industrial Revolution; World Economic Forum: Geneva, Switzerland, 2017; ISBN 9781944835019. [Google Scholar]
- Castelo-Branco, I.; Cruz-Jesus, F.; Oliveira, T. Assessing Industry 4.0 Readiness in Manufacturing: Evidence for the European Union. Comput. Ind. 2019, 107, 22–32. [Google Scholar] [CrossRef]
- Lu, Y. Industry 4.0: A Survey on Technologies, Applications and Open Research Issues. J. Ind. Inf. Integr. 2017, 6, 1–10. [Google Scholar] [CrossRef]
- Hermann, M.; Pentek, T.; Otto, B. Design Principles for Industrie 4.0; Technology University Dortmund: Dortmund, Germany, 2015; Volume 15. [Google Scholar]
- Kagermann, H.; Riemensperger, F.; Hoke, D.; Schuh, G.; Scheer, A.-W. Recommendations for the Strategic Initiative Web-Based Services for Businesses. Acatech Rep. 2014, 112, 5–6. [Google Scholar]
- Da Xu, L.; Xu, E.L.; Li, L. Industry 4.0: State of the Art and Future Trends. Int. J. Prod. Res. 2018, 56, 2941–2962. [Google Scholar] [CrossRef] [Green Version]
- Bangemann, T.; Bauer, C.; Bedenbender, H.; Braune, A.; Diedrich, C.; Diesner, M.; Epple, U.; Elmas, F.; Friedrich, J.; Göbe, F.; et al. Status Report—Industrie 4.0 Service Architecture—Basic Concepts for Interoperability; ZVEI—German Electrical and Electronic Manufacturers’ Association: Frankfurt, Germany, 2016; Volume 1. [Google Scholar]
- Elmasri, R.; Navathe, S.B. Sistemas de Banco de Dados, 4th ed.; Pearson: London, UK, 2005; ISBN 9788578110796. [Google Scholar]
- Ramakrishnan, R.; Gehrke, J. Sistemas de Gerenciamento de Banco de Dados, 3rd ed.; McGraw Hill: New York, NY, USA, 2008; Volume 14, ISBN 9788577803828. [Google Scholar]
- Elmasri, R.; Navathe, S.B. Fundamentals of Database Systems, 7th ed.; Pearson: Hoboken, NJ, USA, 2000; ISBN 9780133970777. [Google Scholar]
- Sadalage, P.J.; Fowler, M. NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence; Pearson: Hoboken, NJ, USA, 2013; ISBN 9780321826626. [Google Scholar]
- Codd, E.F. A Relational Model of Data for Large Shared Data Banks. Commun. ACM 1983, 26, 64–69. [Google Scholar] [CrossRef]
- Özsu, M.T.; Valduriez, P. Distributed and Parallel Database Systems. ACM Comput. Surv. 1996, 28, 125–128. [Google Scholar] [CrossRef]
- Özsu, M.T.; Valduriez, P. Principles of Distributed Database Systems, 3rd ed.; Springer: London, UK, 2011; ISBN 9781441988331. [Google Scholar]
- NOSQL Databases. Available online: https://www.christof-strauch.de/nosqldbs.pdf (accessed on 2 August 2021).
- Moniruzzaman, A.B.M.; Hossain, S.A. NoSQL Database: New Era of Databases for Big Data Analytics—Classification, Characteristics and Comparison. Int. J. Database Theory Appl. 2013, 6, 1–14. [Google Scholar] [CrossRef]
- Abadi, D.J. Consistency Tradeoffs in Modern Distributed Database System Design: CAP Is Only Part of the Story. Computer 2012, 45, 37–42. [Google Scholar] [CrossRef]
- Bader, S.; Barnstedt, E.; Bedenbender, H.; Billman, M.; Boss, B.; Braunmandl, A. Details of the Asset Administration Shell Part 1—The Exchange of Information between Partners in the Value Chain of Industrie 4.0; Federal Ministry for Economic Affairs and Energy (BMWi): Berlin, Germany, 2019. [Google Scholar]
- Bedenbender, H.; Billmann, M.; Epple, U.; Hadlich, T.; Hankel, M.; Heidel, H.; Hillermeier, O.; Hoffmeister, M.; Huhle, H.; Jochem, M.; et al. Examples of the Asset Administration Shell for Industrie 4.0 Components—Basic Part; German Electrical and Electronic Manufacturers’ Association: Frankfurt, Germany, 2017. [Google Scholar]
- Gastaldi, L.; Appio, F.P.; Corso, M.; Pistorio, A. Managing the Exploration-Exploitation Paradox in Healthcare: Three Complementary Paths to Leverage on the Digital Transformation. Bus. Process Manag. J. 2018, 24, 1200–1234. [Google Scholar] [CrossRef]
- Inigo, M.A.; Porto, A.; Kremer, B.; Perez, A.; Larrinaga, F.; Cuenca, J. Towards an Asset Administration Shell Scenario: A Use Case for Interoperability and Standardization in Industry 4.0. In Proceedings of the IEEE/IFIP Network Operations and Management Symposium, NOMS 2020, Budapest, Hungary, 20–24 April 2020. [Google Scholar] [CrossRef]
- Gayko, J. The Reference Architectural Model Rami 4.0 and the Standardization Council as an Element of Success for Industry 4.0. 2018. Available online: https://www.din.de/resource/blob/271306/340011c12b8592df728bee3815ef6ec2/06-smart-manufacturing-jens-gayko-data.pdf (accessed on 2 August 2021).
- Adolphs, P.; Auer, S.; Bedenbender, H.; Billmann, M.; Hankel, M.; Heidel, R.; Hoffmeister, M.; Huhle, H.; Jochem, M.; Kiele-Dunsche, M.; et al. Structure of the Asset Administration Shell: Continuation of the Development of the Reference Model for the Industrie 4.0 Component; Federal Ministry for Economic Affairs and Energy (BMWi): Berlin, Germany, 2016. [Google Scholar]
- Ye, X.; Hong, S.H. Toward Industry 4.0 Components: Insights into and Implementation of Asset Administration Shells. IEEE Ind. Electron. Mag. 2019, 13, 13–25. [Google Scholar] [CrossRef]
- Boss, B.; Malakuti, S.; Lin, S.-W.; Usländer, T.; Clauer, E.; Hoffmeister, M.; Stokanovic, L. Digital Twin and Asset Administration Shell Concepts and Application in the Industrial Internet and Industrie 4.0; Industrial Internet Consortium: Boston, MA, USA, 2020. [Google Scholar]
- Bedenbender, H.; Bentkus, A.; Epple, U.; Hadlich, T.; Heidel, R.; Hillermeier, O.; Hoffmeister, M.; Huhle, H.; Kiele-Dunsche, M.; Koziolek, H.; et al. Industrie 4.0 Plug-and-Produce for Adaptable Factories: Example Use Case Definition, Models, and Implementation; Federal Ministry for Economic Affairs and Energy (BMWi): Berlin, Germany, 2017. [Google Scholar]
- Gerend, J. Contêineres vs. Máquinas Virtuais. Available online: https://docs.microsoft.com/pt-br/virtualization/windowscontainers/about/containers-vs-vm (accessed on 15 June 2021).
- Xavier, M.G.; Neves, M.V.; Rossi, F.D.; Ferreto, T.C.; Lange, T.; De Rose, C.A.F. Performance Evaluation of Container-Based Virtualization for High Performance Computing Environments. In Proceedings of the IEEE 2013 21st Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP 2013), Belfast, UK, 27 February–1 March 2013; pp. 233–240. [Google Scholar] [CrossRef]
- De Mauro, A.; Greco, M.; Grimaldi, M. A Formal Definition of Big Data Based on Its Essential Features. Libr. Rev. 2016, 65, 122–135. [Google Scholar] [CrossRef]
- Lichtblau, K.; Stich, V.; Bertenrath, R.; Blum, M.; Bleider, M.; Millack, A.; Schmitt, K.; SChmitz, E.; Schröter, M. Industry 4.0 Readiness; IMPULS—Institute for Mechanical Engineering, Plant Engineering, and Information Technology: Frankfurt, Germany, 2015. [Google Scholar]
- Russom, P. Big Data Analytics; TWDI—Transforming Data with Intelligence: Renton, WA, USA, 2011. [Google Scholar]
- Yin, S.; Kaynak, O. Big Data for Modern Industry: Challenges and Trends. Proc. IEEE 2015, 103, 143–146. [Google Scholar] [CrossRef]
- Kagermann, H.; Wahlster, W.; Helbig, J. Securing the Future of German Manufacturing Industry: Recommendations for Implementing the Strategic Initiative INDUSTRIE 4.0. Final Rep. Ind. 4.0 Work. Gr. 2013, 1–84. Available online: https://www.din.de/blob/76902/e8cac883f42bf28536e7e8165993f1fd/recommendations-for-implementing-industry-4-0-data.pdf (accessed on 2 August 2021).
- Gil, D.; Song, I.Y. Modeling and Management of Big Data: Challenges and Opportunities. Futur. Gener. Comput. Syst. 2016, 63, 96–99. [Google Scholar] [CrossRef] [Green Version]
- NIST Big Data Public Working Group. NIST Big Data Interoperability Framework: Volume 6—Reference Architecture; NIST—National Institute of Standards and Technology: Gaithersburg, MD, USA, 2019; Volume 6.
- Russmann, M.; Lorenz, M.; Gerbert, P.; Waldner, M.; Justus, J.; Engel, P.; Harnisch, M. Industry 4.0: The Future of Productivity and Growth in Manufacturing Industries. Bost. Consult. Gr. 2015, 1–20. Available online: https://www.bcg.com/pt-br/publications/2015/engineered_products_project_business_industry_4_future_productivity_growth_manufacturing_industries (accessed on 2 August 2021).
- Bechtold, J.; Kern, A.; Lauenstein, C.; Bernhofer, L. Industry 4.0—The Capgemini Consulting View; Capgmenini Consulting: Paris, France, 2014. [Google Scholar]
- Bauer, H.; Baur, C.; Camplone, G.; George, K.; Ghislanzoni, G.; Huhn, W.; Kayser, D.; Löffler, M.; Tschiesner, A.; Zielke, A.E.; et al. Industry 4.0: How to Navigate Digitization of the Manufacturing Sector; McKinsey Digital: New York, NY, USA, 2015. [Google Scholar]
- Petrillo, A.; De Felice, F.; Cioffi, R.; Zomparelli, F. Fourth Industrial Revolution: Current Practices, Challenges, and Opportunities. In Digital Transformation in Smart Manufacturing; Intechopen: London, UK, 2018; pp. 1–20. [Google Scholar]
- Wan, J.; Cai, H.; Zhou, K. Industrie 4.0: Enabling Technologies. In Proceedings of the International Conference on Intelligent Computing and Internet of Things, ICIT 2015, Harbin, China, 17–18 January 2015; pp. 135–140. [Google Scholar] [CrossRef]
- Fatima, H.; Wasnik, K. Comparison of SQL, NoSQL and NewSQL Databases for Internet of Things. In Proceedings of the 2016 IEEE Bombay Section Symposium (IBSS), Baramati, India, 21–22 December 2016. [Google Scholar] [CrossRef]
- Rautmare, S.; Bhalerao, D.M. MySQL and NoSQL Database Comparison for IoT Application. In Proceedings of the 2016 IEEE International Conference on Advances in Computer Applications, Coimbatore, Tamilnadu, India, 24 October 2016; pp. 235–238. [Google Scholar]
- Di Martino, S.; Fiadone, L.; Peron, A.; Vitale, V.N.; Riccabone, A. Industrial Internet of Things: Persistence for Time Series with NoSQL Databases. In Proceedings of the IEEE 28th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises, Naples, Italy, 12–14 June 2019; pp. 340–345. [Google Scholar]
- Bonnet, L.; Laurent, A.; Sala, M.; Laurent, B.; Sicard, N. Reduce, You Say: What NoSQL Can Do for Data Aggregation and BI in Large Repositories. In Proceedings of the International Workshop on Database and Expert Systems Applications, Toulouse, France, 29 August–2 September 2011; pp. 483–488. [Google Scholar]
- Guzzi, P.H.; Veltri, P.; Cannataro, M. Experimental Evaluation of Nosql Databases. Int. J. Database Manag. Syst. 2014, 6, 656–660. [Google Scholar] [CrossRef]
- Teorey, T.; Lightstone, S.; Nadeau, T.; Jagadish, H.V. Database Modeling and Design; Elsevier: Burlington, MA, USA, 2005. [Google Scholar]
- Fowler, M. Reporting Database. Available online: https://martinfowler.com/bliki/ReportingDatabase.html (accessed on 15 June 2021).
- Han, J.; Haihong, E.; Le, G.; Du, J. Survey on NoSQL Database. In Proceedings of the 2011 6th International Conference on Pervasive Computing and Applications, Port Elizabeth, South Africa; 2011; pp. 363–366. [Google Scholar] [CrossRef]
- Khine, P.P.; Wang, Z. A Review of Polyglot Persistence in the Big Data World. Information 2019, 10, 141. [Google Scholar] [CrossRef] [Green Version]
- Cattell, R. Scalable SQL and NoSQL Data Stores. SIGMOD Rec. 2010, 39, 12–27. [Google Scholar] [CrossRef] [Green Version]
- Lee, E.A. Cyber Physical Systems: Design Challenges; Electrical Engineering and Computer Sciences, University of California at Berkeley: Berkeley, CA, USA, 2017. [Google Scholar]
- Cavalieri, S.; Salafia, M.G. A Model for Predictive Maintenance Based on Asset Administration Shell. Sensors 2020, 20, 6028. [Google Scholar] [CrossRef] [PubMed]
- Lang, D.; Grunau, S.; Wisniewski, L.; Jasperneite, J. Utilization of the Asset Administration Shell to Support Humans during the Maintenance Process. In Proceedings of the 2019 IEEE 17th International Conference on Industrial Informatics, Helsinki, Finland, 22–25 July 2019; pp. 768–773. [Google Scholar] [CrossRef]
- Ye, X.; Jiang, J.; Lee, C.; Kim, N.; Yu, M.; Hong, S.H. Toward the Plug-and-Produce Capability for Industry 4.0. IEEE Ind. Electron. Mag. 2020, 14, 146–157. [Google Scholar] [CrossRef]
- OPC Foundation. OPC 10000-6: OPC Unified Architecture—Part 6: Mappings 2017. Available online: https://reference.opcfoundation.org/v104/Core/docs/Part6/ (accessed on 2 August 2021).
- Erl, T.; Khattak, W.; Buhler, P. Big Data Fundamentals: Concepts, Drivers & Techniques; Prentice Hall: Hoboken, NJ, USA, 2016; ISBN 0975442201. [Google Scholar]
- Stonebraker, M. SQL Databases v. NoSQL Databases. Commun. ACM 2010, 53, 10–11. [Google Scholar] [CrossRef]
- Inmon, W.H. Building the Data Warehouse, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2002; ISBN 0-471-08130-2. [Google Scholar]
- Thomsen, E. OLAP Solutions: Building Multidimensional Information Systems, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2002; ISBN 0471400300. [Google Scholar]
- Bicevska, Z.; Oditis, I. Towards NoSQL-Based Data Warehouse Solutions. Procedia Comput. Sci. 2016, 104, 104–111. [Google Scholar] [CrossRef]
- Chevalier, M.; El Malki, M.; Kopliku, A.; Teste, O.; Tournier, R. Implementing Multidimensional Dasta Warehouse into NoSQL. In Proceedings of the 17th International Conference on Enterprise Information Systems, Barcelona, Spain, 27–30 April 2015. [Google Scholar]
- Yangui, R.; Nabli, A.; Gargouri, F. Automatic Transformation of Data Warehouse Schema to NoSQL Data Base: Comparative Study. Procedia Comput. Sci. 2016, 96, 255–264. [Google Scholar] [CrossRef] [Green Version]
- Mathew, A.B. Data Allocation Optimization for Query Processing in Graph Databases Using Lucene. Comput. Electr. Eng. 2018, 70, 1019–1033. [Google Scholar] [CrossRef]
- Tan, Z.; Babu, S. Tempo: Robust and Self-Tuning Resource Management in Multi-Tenant Parallel Databases. In Proceedings of the 42th International Conference on Very Large Databases, New Delhi, India, 5–9 September 2016; Volume 9, pp. 720–731. [Google Scholar]
- Atzeni, P.; Bugiotti, F.; Cabibbo, L.; Torlone, R. Data Modeling in the NoSQL World. Comput. Stand. Interfaces 2020, 67, 103149. [Google Scholar] [CrossRef]
- Ali, W.; Shafique, M.U.; Majeed, M.A.; Raza, A. Comparison between SQL and NoSQL Databases and Their Relationship with Big Data Analytics. Asian J. Res. Comput. Sci. 2019, 4, 1–10. [Google Scholar] [CrossRef]
- Li, Y.; Manoharan, S. A Performance Comparison of SQL and NoSQL Databases A Performance Comparison of SQL and NoSQL Databases. In Proceedings of the IEEE Pacific Rim Conference on Communications, Computers and Signal Processing, Victoria, BC, Canada, 27–29 August 2013; pp. 15–19. [Google Scholar]
- Swaminathan, S.N.; Elmasri, R. Quantitative Analysis of Scalable NoSQL Databases. In Proceedings of the International Congress on Big Data, San Francisco, CA, USA, 27 June–2 July 2016; pp. 323–326. [Google Scholar]
- Aravanis, A.I.; Voulkidis, A.; Salom, J.; Townley, J.; Georgiadou, V.; Oleksiak, A.; Porto, M.R.; Roudet, F.; Zahariadis, T. Metrics for Assessing Flexibility and Sustainability of next Generation Data Centers. In Proceedings of the 2015 IEEE Globecom Workshops, San Diego, CA, USA, 6–10 December 2015. [Google Scholar]
- Nagpal, S.; Gosain, A.; Sabharwal, S. Complexity Metric for Multidimensional Models for Data Warehouse. In Proceedings of the CUBE International Information Technology Conference, Pune, India, 3–5 September 2012; pp. 360–365. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technology | Rüssmann (2015) [52] | Bechtold et al. (2014) [53] | Lichtblau et al. (2015) [46] | Bauer et al. (2015) [54] | Petrillo et al. (2018) [55] | Wan, Cai, Zhou (2015) [56] |
|---|---|---|---|---|---|---|
| Big data and analytics | x | x | x | x | x | x |
| Advanced robotics | x | x | x | x | ||
| Systems integration | x | x | x | |||
| Internet of things | x | x | x | x | x | |
| Simulation | x | x | ||||
| Additive manufacturing | x | x | x | x | x | |
| Cloud computing | x | x | x | x | x | |
| Virtual/augmented reality | x | x | x | x | ||
| Cybersecurity | x | x | ||||
| Machine-to-machine | x | x | ||||
| Mobile technologies | x | x | ||||
| Location and detection technologies | x | |||||
| Human–machine interfaces | x | x | ||||
| Authentication and fraud detection | x | |||||
| Smart sensors | x | |||||
| Interaction with customers | x | |||||
| Community platforms | x | |||||
| Embedded projects | x | |||||
| Self-guided vehicles | x | |||||
| Social networks | x |
| Volume | Velocity | Veracity | Database Type | Suitable Model of Transactional Properties |
|---|---|---|---|---|
| Low | Low | Low | Operational | BASE |
| High | Operational | Both | ||
| High | Low | Operational | BASE | |
| High | Operational | ACID | ||
| High | Low | Low | Analytical | BASE |
| High | Analytical | Both | ||
| High | Low | Operational | BASE | |
| High | Analytical | BASE |
| Variety | Access Flexibility | Data Linkage Complexity | Suitable Logical Data Model |
|---|---|---|---|
| Low | Low | Low | Relational |
| High | Graph | ||
| High | Low | Relational | |
| High | Graph | ||
| High | Low | Low | Graph |
| High | Graph | ||
| High | Low | Graph | |
| High | Graph |
| Variety | Access Flexibility | Data Linkage Complexity | Suitable Logical Data Model |
|---|---|---|---|
| Low | Low | Low | Key-value |
| High | Document | ||
| High | Low | Column family | |
| High | Document | ||
| High | Low | Low | Column family |
| High | Document | ||
| High | Low | Column family | |
| High | Document |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Oliveira, V.F.; Pessoa, M.A.d.O.; Junqueira, F.; Miyagi, P.E. SQL and NoSQL Databases in the Context of Industry 4.0. Machines 2022, 10, 20. https://doi.org/10.3390/machines10010020
de Oliveira VF, Pessoa MAdO, Junqueira F, Miyagi PE. SQL and NoSQL Databases in the Context of Industry 4.0. Machines. 2022; 10(1):20. https://doi.org/10.3390/machines10010020
Chicago/Turabian Stylede Oliveira, Vitor Furlan, Marcosiris Amorim de Oliveira Pessoa, Fabrício Junqueira, and Paulo Eigi Miyagi. 2022. "SQL and NoSQL Databases in the Context of Industry 4.0" Machines 10, no. 1: 20. https://doi.org/10.3390/machines10010020
APA Stylede Oliveira, V. F., Pessoa, M. A. d. O., Junqueira, F., & Miyagi, P. E. (2022). SQL and NoSQL Databases in the Context of Industry 4.0. Machines, 10(1), 20. https://doi.org/10.3390/machines10010020