1. Introduction
In 1996 the Basel Committee approved the use of proprietary Value at Risk (VaR) measures for calculating the market risk component of bank capital requirements; from that year, the scientific literature grew dramatically in order to identify the best performing way to measure VaR.
Jorion in [
1] defines VaR as the measure that is the worst expected loss over a given horizon under normal market conditions at a given level of confidence. When a bank says that the daily VaR of its trading portfolio is
$1 million at the 95 percent confidence level, it means if no negative event occurs, while only five percent of the time, the daily loss will exceed
$1 million. The VaR is thus a conditional quantile of the asset return loss distribution.
Despite the VaR is an intuitive concept, its computation may be complex; a detailed review about the classical methodologies is in [
2] where they are classified into three sets (i) the variance–covariance approach, also called the Parametric method, (ii) the Historical Simulation (Non-parametric method) and (iii) the Monte Carlo simulation, which is a Semi-parametric method. In the first papers based on the comparison between the three approaches, no methodology seemed to perform better than the others. However, more recently some contributions report that the Historical Simulation produces almost poor VaR estimates basically because it does not offer an efficient use of the available information.
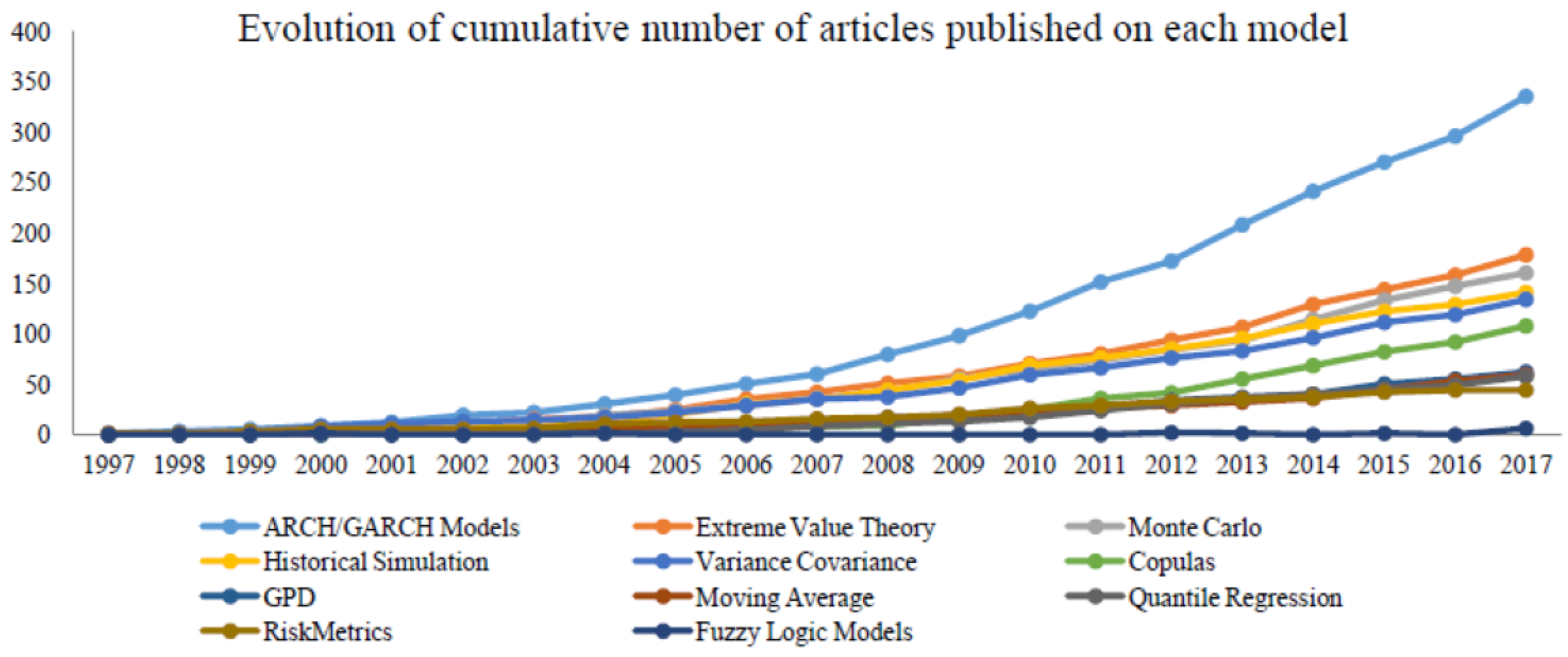
A more recent review, presented in [
3], concerns studies for VaR computations including several approaches, related literature is relatively scarce, developed when uncertainty modeling is based on fuzzy logic; the authors show in
Figure 1 the amount of articles within each methodology in a time period of twenty years.
About twenty years ago, the first attempt to apply Fuzzy Logic in the estimation of VaR was shown in [
4] where market liquidity is a key factor in the definition of a pricing model through a fuzzy measure.
Fuzzy numbers describe the implicit vagueness within VaR in [
5]; they play the role of a sensitivity analysis while the stochastic nature of the risky component is preserved.
In [
6] interval estimation of VaR values are the input variables of a Fuzzy Slack-Based Measurement that is useful for representing the implications of risk and the effects of risk on efficiency.
The situation of leptokurtic and imprecise risk factors modelled as fuzzy random variables, generalizing [
7], is analyzed in Reference [
8] where linear portfolio VaR and expected shortfall (ES) are computed. The models imply the possibility of taking into account pessimistic or optimistic investor’s believes.
In [
9] VaR is estimated by using probabilistic fuzzy systems (PFSs) which are semi-parametric methods that combines a linguistic description of the system behavior with statistical properties of the data; the approach to designing probabilistic fuzzy VaR models is compared with GARCH model and statistical back testing always accepts PFS models after tuning, whereas GARCH models may be rejected in some situations.
A possibilistic portfolio model is proposed in [
10] as an expansion of the possibilistic mean-variance model by with VaR constraint and risk-free investment are computed taking the assumption that the expected rate of returns is a fuzzy number. In [
11] the authors suggest an evolving possibilistic fuzzy modeling (ePFM) approach to estimate VaR; data from the main global equity market indexes are used to estimate VaR using ePFM and the performance of ePFM is compared with traditional VaR benchmarks producing encouraging results. A growing interest for researches and practitioners is directed to VaR estimation in the case of operational risk, in [
12] the intrinsic properties of the data as fuzzy sets are related to the linguistic variables of the observed data (external), allowing an organization to supervise operational VaR over time.
The notion of credibilistic average VaR is detailed in [
13] where simulation algorithms support its use in many real problems of risk analysis.
An alternative nonparametric approach based on maxitive kernel estimation of VaR is studied in [
14] where the obtained interval-valued VaR estimates are the key factors to lead to accurate decisions involving uncertainty.
Nevertheless, we believe that the modeling of uncertainty through fuzzy logic in decision making and risk management deserves in-depth analysis; just to mention some of our contributions, we developed the rigorous use of the extension principle for fuzzy-valued functions in [
15] where we show that fuzzy financial option prices can capture the unavoidable uncertainty of several stylized facts in real markets and the subjective believes of the investor. It is a matter of interest the use of VaR as a factor fixing decision-making believes for risk-averse investors, for example in [
16], the process of recovering investment opportunities with projects that have been rejected when applying the criterion of the Value-at-Risk method, is studied.
In [
17] we took three financial time series and we modeled them with two non-parametric smoothing techniques defined in terms of expectile and quantile fuzzy-valued Fuzzy-transform, respectively obtained by minimizing a least squares (L
-norm) operator and a L
-norm operator. The relevance of expectiles in risk management is also focused in [
18] where it is shown that several limits of VaR and expected shortfall can be overcome by expectiles because they are the only elicitable law-invariant coherent risk measures.
The goal of the present paper is to highlight potentialities of fuzzy numbers in VaR estimation which is a fundamental topic in risk management because the amount of capital to be allocated in case of future losses has to be identified carefully—if it is too small then it does not cover from adverse events and if it is too large then the allocated capital can not be used for other crucial activities. To reach the goal we apply two results which provide instruments for detecting time series properties and for modelling their uncertainty.
The first VaR estimation is produced by the mentioned smoothing techniques, based on Fuzzy-transform and evaluated by performing a rolling window analysis along twelve years of daily returns, during which we count the number of violations and we compare it to the traditional historical simulation.
The second approach addresses non parametric methods and, as in [
19], we propose a method to estimate quantiles through a nonparametric estimates of the cumulative distribution function deduced by using the Average Cumulative Function (ACF) which plays the role of the double kernel smoothing in the mentioned paper.
The choice of ACF, introduced in [
20] as an alternative representation of fuzzy numbers, is justified in terms of an interesting link which can be established between ACF-representation and quantile functions, without requiring distributional assumptions. In [
21] we extend the ACF analysis and in particular we clarify the crucial role of ACF in determining the membership function from experimental data. Again we compare the number of violations when VaR is defined in terms of ACF, with the same number obtained through the historical simulation of VaR.
The paper is organized into seven sections. The second section fixes the basis of the F-transform smoothing techniques that are applied in
Section 3 within the case of VaR estimates for daily S&P500 index data, from June 2007 to June 2019. The fourth section gives the basic knowledge of the Average Cumulative Function which allows the interpretation of the fuzzy quantile function in terms of VaR; in
Section 5 experiments are given with the same time series as in
Section 3, in relation to which the comparison is detailed in
Section 6. Highlights on possible future researches are investigated in
Section 7.
2. Fuzzy-Transform Smoothing
In [
17] two non-parametric smoothing methodologies are introduced; the expectile fuzzy-valued F-transform is based on the classical F-transform obtained by minimizing a least squares (
-norm) operator, while the quantile fuzzy-valued F-transform is based on the
-type F-transform, obtained by minimizing an
-norm operator.
The F-transform smoothing methodologies are compared with:
- (1)
expectreg and quantreg package, implemented in R language(CRAN repository);
- (2)
SVM-type (Support Vector Machine) non-parametric learning algorithms, implemented in R language (CRAN repository)
Eight measures are checked and they are minimized by both quantile and expectile smoothed series, where quantile performs slightly better for those time series having steep peaks. In addition, the robustness is confirmed within time series of various types. We detail some useful preliminaries explaining the theoretical steps in the discrete case which fits the time series experiments in
Section 3.
Given
m values
,
,
, of a function
, a fuzzy partition
of
such that each subinterval
contains at least one point
in its interior (so that the basic functions
satisfy
for all
k), then the discrete direct F-transform of
f with respect to
is the
n-tuple of real numbers
given by
where
minimizes the function
Under certain hypothesis, the minimization of
and
produces two values
and
, for
that are the (midpoint) minimizers of functions
and
; when
then the compact intervals are defined as:
Then, for each
, the family of intervals
defines the
-cuts of a fuzzy number
having membership function
Given a set of
m points
,
of a function
and given a fuzzy partition
of
, the (
n)-vector of fuzzy numbers
where each fuzzy interval
has
-cuts
, is called the discrete direct quantile fuzzy transform of
f with respect to
, based on the data-set
.
The corresponding inverse expectile fuzzy transform of
f is the fuzzy-valued function defined by
In the same framework established to deduce (
1), the discrete direct F-transform
of f with respect to
is the
n-tuple of real numbers
given by
and, in the
-norm case, each
minimizes the function.
Under some hypothesis, the minimization of
and
produces two values
and
, for
that are the (midpoint) minimizers of functions
and
; consider
the compact intervals
form the
-cuts of a fuzzy number
having membership function
Given a set of
m points
,
, of a function
and given a fuzzy partition
of
, the (
n)-vector of fuzzy numbers
where each fuzzy interval
has
-cuts
, is called the discrete direct quantile fuzzy transform of
f with respect to
, based on the data-set
.
The corresponding inverse quantile fuzzy transform of
f is the fuzzy-valued function defined by
3. Value at Risk through Smoothed Series
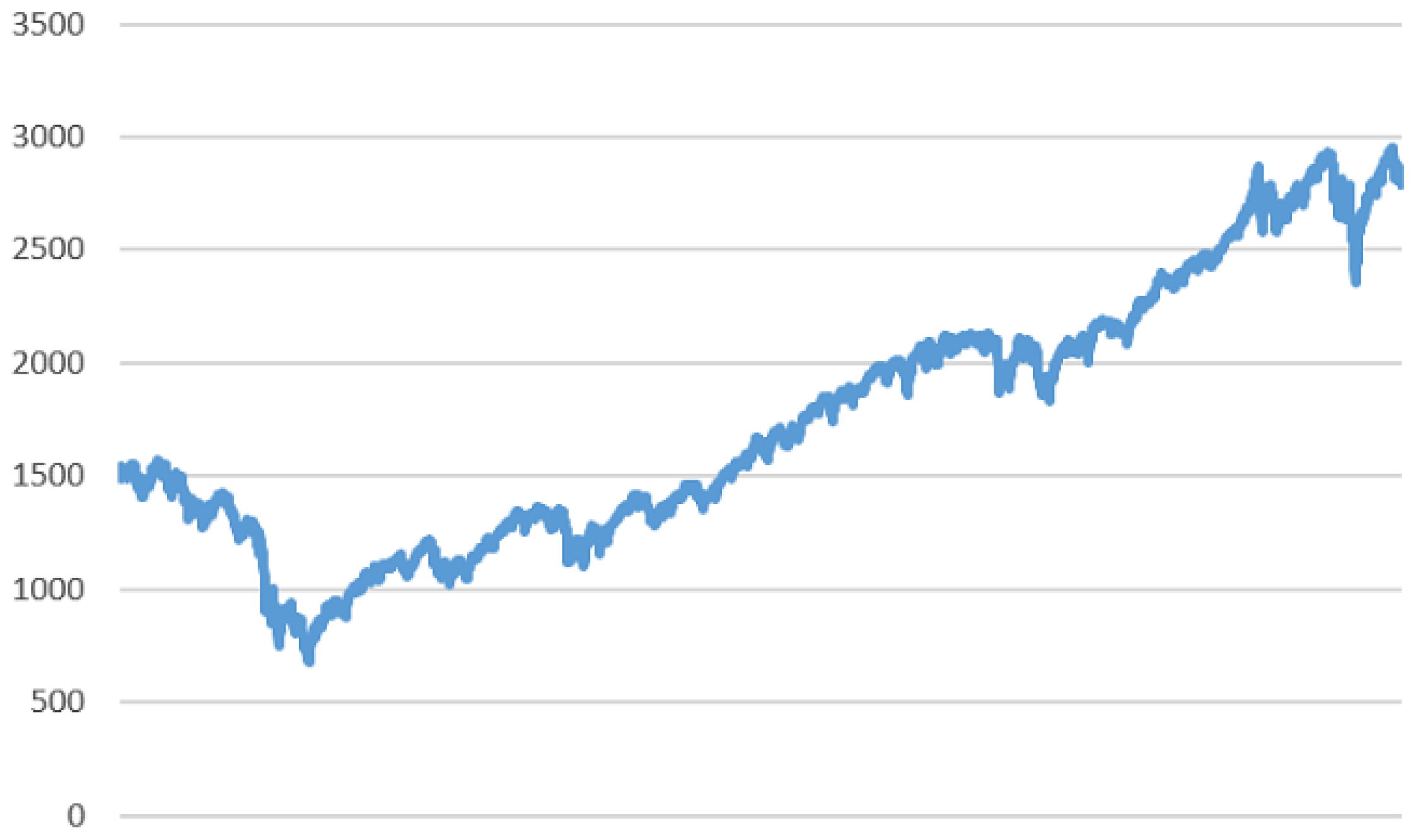
In order to evaluate the contribution of the smoothing techniques based on F-transform, we consider a time series of 3020 values (pictured in
Figure 2), covering the time period form June 2007 to June 2019, of the S&P500 index which measures the cumulative float-adjusted market capitalization of 500 of the United States largest corporations.
The number
n of subintervals in the fuzzy partition
is
As in kernel smoothing, the basic functions
, defined on the intervals
, are obtained by translating and rescaling the same symmetric fuzzy number
, defined on
and centered at the origin, with membership
where the basic functions are increasing rational spline defined as
with slope parameters
,
. In general, the smoothing effect is not so much depending on the choice of function
, instead, the number
n of subintervals of the decomposition
P and the bandwidth
r strongly impact the smoothing effect; the best combinations of
n and
r have been chosen by a generalized cross validation (GCV) approach.
Expectile and quantile smoothed curves
and
(given a specific value
) are obtained from the
-cuts of the fuzzy-valued expectile function
, as in (
6) and the fuzzy-valued quantile function
as in (
12) as follows:
As we mentioned in the introduction, historical simulation for Value at Risk estimation is the most widely implemented nonparametric approach but it is not always the best performing. Its main advantages can be phrased as follows—(1) generally the implementation is very easy, (2) it does not depend on parametric assumptions on returns distribution implying that it can accommodate wide tails, skewness and any other non-normal features in financial observations.
On the other hand, the strongest weakness is its completely dependence on the data set.
Many contributions find that historical simulation underestimates risk in an unusually quiet period and it is sometimes slow to reflect market turbulence. The non parametric smoothing methods based on F-transform can weaken these distortions as we show in some simple experiments.
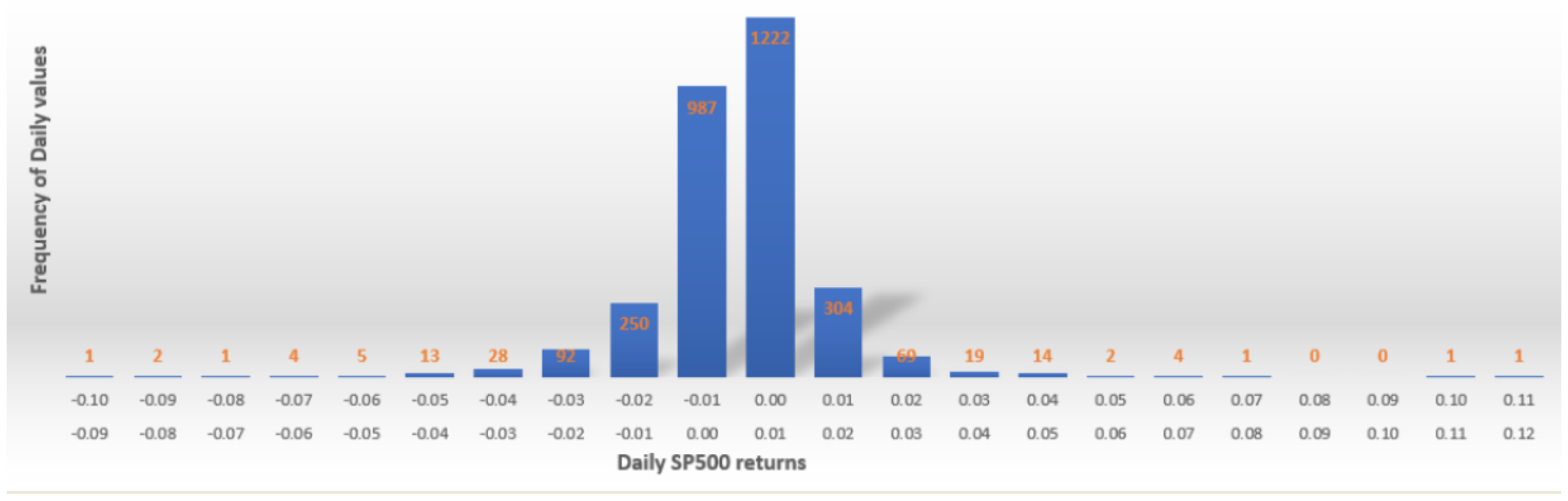
In our findings, when no smoothing technique is applied, the value VaR
is computed for the time series of returns of S&P500 index which are plotted in
Figure 3 and, as it is expected, show a quite modest volatility with a low numbers of values in the left tail. The 95% confidence level and the time period of one day imply that
corresponds to the 5th quantile of the daily S&P500 returns with a negative sign because VaR is always interpreted as a loss.
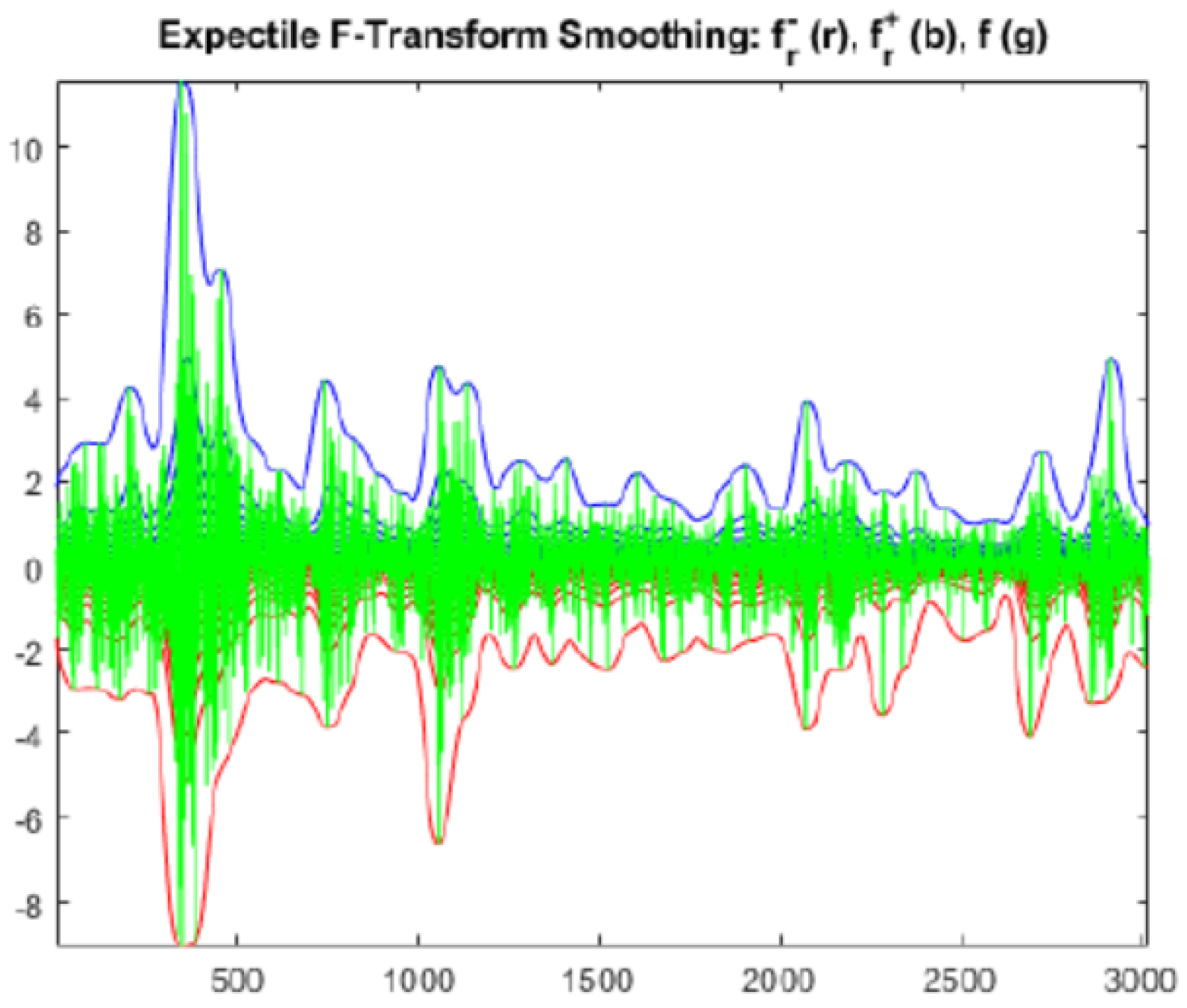
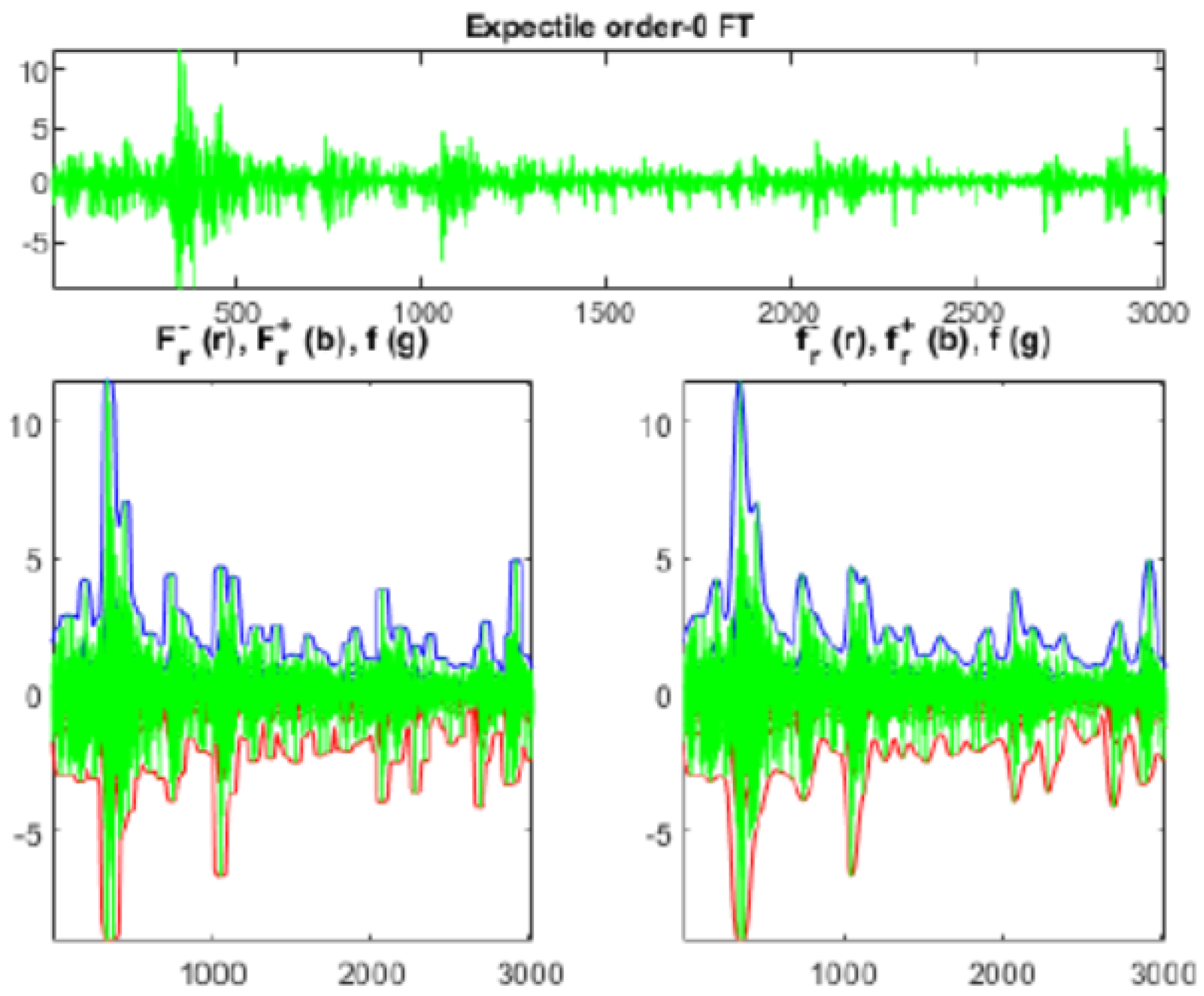
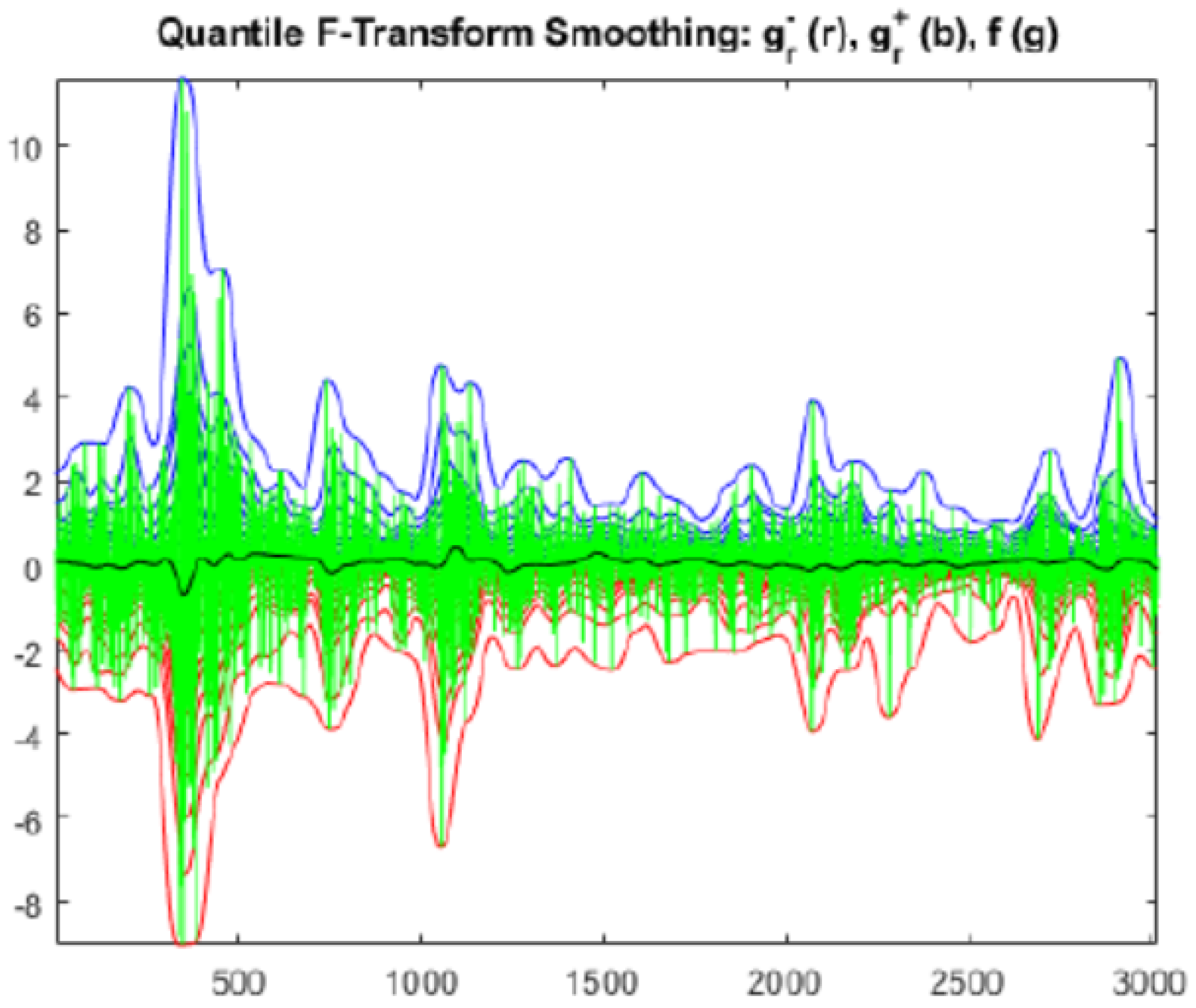
In
Figure 4 the effects of the smoothing procedure based on
minimization (
Figure 5 shows the dynamics of left and right minimizers) are applied for 3020 daily values of the S&P500 index, proving itself to be an efficient methodology.
Figure 6 shows that the bandwidth of the quantile smoothing is slightly smaller than the expectile one, especially for the downside returns which mostly affect the Value at Risk; more evident differences could be appreciated in case of higher volatile time series.
In
Figure 7 the left and right minimizers in the smoothing procedure based on
minimization are represented.
Given the smoothed time series, VaR is the value obtained with the expectile smoothing, whereas VaR is the same value obtained with the quantile smoothing.
We consider rolling windows, each one made up of 500 observations (two financial years). S&P500 index returns within the first window are sorted in ascending order and the 5-quantile of interest is given by the return that leaves 5% of the observations on its left side and 95% on its right side. The 5% allows to include an higher number of returns, considering the small number of outliers. To compute the VaR the following day, the whole window is moved forward by one observation and the entire procedure is repeated.
Consequently, the first window consists of the returns from June 2007 to May 2009 for a total amount of 503 returns over a total of 3020. It implies that the first VaR is related to 1 June 2009 and the next values are related to each following day.
A back-testing procedure is adopted to compare the three VaRs in terms of violations which are the unpredicted losses with the actual losses realized on each day.
The back-testing analysis takes into account 2516 rolling windows for a total number of 2515 VaR values. The results are shown in
Table 1 which offers the possibility of some observations: first of all, the number of violations is slightly reduced when a smoothing methodology is applied and the reduction is more evident when the quantile one is performed, confirming its results extensively analyzed in [
17].
4. Average Cumulative Function
The ACF-representation and its properties are studied in [
20] where the relationship between ACF and quantile functions, which we apply to Value at Risk hereafter, is proved and resumed in what follows.
The ACF is a representation based on the following assumptions:
u are real fuzzy intervals with compact support and compact nonempty core where , their space is ;
the membership function of
can be represented in the form
where
is a nondecreasing right-continuous function,
for
, called the
left side of the fuzzy interval and
is a nonincreasing left-continuous function,
for
, called the
right side of the fuzzy interval. The two functions
and
are extended to the real domain by setting
There exists a pair of cumulative distribution functions, called the lower cdf and the upper cdf of
u, based on the extended left side function
and the extended right side function
such that
, where
and
implying that the
-Average Cumulative function (
-ACF) of
u is defined for a fixed value of
as the following convex combination of
and
, for all
,
where
is non-decreasing, right continuous on
, left continuous on
and above all, its generalized inverse, defined by
is the quantile function of
.
A quantile of order
for a cdf
(or for the associated random variable
X) is a real value
such that
and considering a simple sample
from a real random variable
X; for a value of
, the (empirical)
p-quantile
is obtained by minimizing, with respect to
k, the following (empirical) function
furthermore,
is an unbiased estimate of
.
A relevant property states that when the fuzzy intervals have continuous membership function and , is their -ACF, then for all , the -cuts of u are such that is the -quantile of and is the -quantile of .
In our financial experiments the fuzzy number is “measured” at N (independent) observations which are the daily data of S&P500 index and this is equivalent to consider a set of independent variables identically distributed on the support and to extract a simple sample of N distinct values from each , .
Consider the decomposition
of the support
, obtained by ordering the
such that
and defining
for
. We define the corresponding empirical AC function as:
where
For
, the
-cuts of
u can be estimated by computing the empirical
-quantile of the sample data
and the empirical
-quantile of the data
. The two following empirical functions, as in Equation (
25):
and
are minimized and the obtained values
give an estimate
of the
-cut
of
u and are obtained without computing directly the (empirical) AC function from the data; in addition, the estimated value
is exactly the
-quantile of the sample data
; so, the extreme values
and
of each
-cut of
u can be estimated, statistically, by an
-quantile and an
-quantile, respectively.
6. Closing Considerations
The adopted back-testing procedure studies the performance of the three values VaR, VaR VaR in terms of the number of violations over 2515 values when they are compared to the value VaR violations have a strong concrete meaning because they detect all the days in which the actual losses are not predicted by the VaR estimation implying a scarce amount of capital for facing adverse situations.
Despite the limitation regarding the fact that only one single asset (S&P500 index) is tested,
Table 1 and
Table 2 show that VaR
performing is effectively the best; in 2010 the percentage of violations moves from 14.6% for VaR
to 10.3% for VaR
, also in 2018 the reduction has a similar order of magnitude. However, also the smoothing effects on returns are evident because the number of violations for VaR
and VaR
is reduced, even if in a more soft way. The limitation of a single asset can have a strong impact because an index is generally less volatile than a stock price, as it is computed as a weighted mean, and the smoothing effect could be theoretically mostly effective when the volatility is higher.
In VaR estimation through the ACF, the investigation of the properties which relate the non parametric estimation and the uncertainty modeling deserves a further appropriate theoretical investigation devoted to the combination between probability and possibility settings.
However, preliminary results strongly encourage the adoption of models based on Fuzzy set theory for calculating VaR and possibly several more risk measures, due to their capability to contemplate uncertainty in a rigorous way. The paradigm of uncertainty is crucial not only in financial time series but in the whole field of data science which includes all real life data, from social media to medicine, from ecology to history.
7. Paths for Future Research
The amount of promising research paths for uncertainty theories in risk management is huge (as described in [
22]), here we just give a flavour of the most appealing from our point of view. Vagueness sources in real data can be viewed as a mixture of stochastic and fuzzy approaches as in [
23] where a given interval describes the available information regarding the evolution of certain variables is vague. Also the possibility of introducing random-fuzzy variables (as in [
24]) in the evaluation of risk measures deserves more efforts in order to be combined with the stochastic nature of the traditional model.
In order to extend the research from a unique stock to a portfolio, a possible research is to apply the introduced non parametric estimation in the case of a portfolio selection model with VaR constraint under different attitudes, as studied in [
25].
A challenging future research path can be the extension of the proposed approaches within the field of neutrosophic logic (derived from the seminal philosophical paper by Samarandache in [
26]) which is compared in [
27] with well-known frameworks for reasoning with uncertainty and vagueness.
The concept of set highlights the main difference between fuzzy logic and neutrosophic logic; a fuzzy set is defined through association with a scale of grades of membership, its generalization is called intuitionistic fuzzy set and it assigns two values called membership degree and non-membership degree respectively, when an additional parameter for neutrality is introduced, then the neutrosophic fuzzy set is defined.
In particular, many contributions based on neutrosophic statistics (broadly detailed in [
28]) are decisively successful when data have indeterminate observations. Consequently, classical statistical tests can be rephrased as in [
29], where the Kolmogorov–Smirnov tests is applied when the data contain neutrosophic observations, or in [
30], where a chi-square test of independence under indeterminacy is introduced; moreover, in [
31] the Dixon’s test is extended within a complex systems when observations are not all determined as it happens in experiment’s results when testing the normality of the data through neutrosophic statistics as in [
32]. In social sciences as Economics and Management the scarce availability of certain data can be approached through neutrosophic statistics as in [
33], where an efficient and flexible acceptance criterion is introduced for a two-stage process for multiple lines. Also in medical science uncertainty is a common feature and neutrosophic statistics is a rigorous way to model it as it is shown in [
34] where uncertain data from an healthcare department are analyzed and in [
35] where an investigation is introduced to classify when patients have the diabetes or not.
In addition, widening the scenario of uncertainty modelling, the tail VaR metric on a tree network, as shown in [
36], computes the probability of the loss and its severity in an uncertain environment.
Finally, the classical statistical research path in risk management is largely fertile; just to give an example, a recent nonparametric method (detailed in [
37]) for VaR extracts the quantile of a conditional distribution which is estimated considering the density of the copula describing the dependence observed in the series of returns.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}