1. Introduction
Data clustering is one of the most important topics in pattern recognition, machine learning and data mining. Generally, data clustering is the task of grouping a set of objects in such a way that objects in the same group (cluster) are more similar to each other than to those in other groups (clusters). In the past few decades, many clustering algorithms have been proposed, such as
k-means clustering [
1], hierarchical clustering [
2], spectral clustering [
3], etc. The clustering technique has been used in many fields, including image analysis, bioinformatics, data compression, computer graphics and so on [
4,
5,
6].
The
k-means algorithm is one of the typical hard clustering algorithms that is widely used in real applications due to its simplicity and efficiency. Unlike hard clustering, the fuzzy
c-means (FCM) algorithm [
7] is one of the most popular soft clustering algorithms in which each data point belongs to a cluster to some degree that is specified by membership degrees in
, and the sum of the clusters for each of the data should be equal to one. In recent years, many improved algorithms for FCM have been proposed. There are three main ways to build the clustering algorithm. First is extensions of the traditional fuzzy sets. In this way, numerous fuzzy clustering algorithms based on the extension fuzzy sets, such as the intuitionistic fuzzy set, the Type-2 fuzzy set, etc., are built. By replacing traditional fuzzy sets with intuitionistic fuzzy set, Chaira introduced the intuitionistic fuzzy clustering (IFC) method in [
8], which integrated the intuitionistic fuzzy entropy with the objective function. Hwang and Rhee suggested deploying FCM on (interval) Type-2 fuzzy set sets in [
9], which aimed to design and manage uncertainty for fuzzifier
m. Thong and Son proposed picture fuzzy clustering based on the picture fuzzy set (PFS) in [
10]. Second, the kernel-based method is applied to improve the fuzzy clustering quality. For example, Graves and Pedrycz presented a kernel version of the FCM algorithm, namely KFCM in [
11]. Ramathilagam et al. analyzed the Lung Cancer database by incorporating the hyper tangent kernel function [
12]. Third, adding regularization terms to the objective function is used to improve the clustering quality. For example, Yasuda proposed an approach to FCM based on entropy maximization in [
13]. Of course, we can use these together to obtain better clustering quality.
The neutrosophic set was proposed by Smarandache [
14] in order to deal with real-world problems. Now, the neutrosophic set is gaining significant attention in solving many real-life problems that involve uncertainty, impreciseness, incompleteness, inconsistency and indeterminacy. A neutrosophic set has three membership functions, and each membership degree is a real standard or non-standard subset of the nonstandard unit interval
. Wang et al. [
15] introduced single-valued neutrosophic sets (SVNSs), which are an extension of intuitionistic fuzzy sets. Moreover, the three membership functions are independent, and their values belong to the unit interval
. In recent years, the studies of SVNSs have been rapidly developing. For example, Majumdar and Samanta [
16] studied the similarity and entropy of SVNSs. Ye [
17] proposed correlation coefficients of SVNSs and applied them to single-valued neutrosophic decision-making problems, etc. Zhang et al. in [
18] proposed a new definition of the inclusion relation of neutrosophic sets (which is also called the Type-3 inclusion relation), and a new method of ranking neutrosophic sets was given. Zhang et al. in [
19] studied neutrosophic duplet sets, neutrosophic duplet semi-groups and cancelable neutrosophic triplet groups.
The clustering methods by the neutrosophic set have been studied deeply. In [
20], Ye proposed a single-valued neutrosophic minimum spanning tree (SVNMST) clustering algorithm, and he also introduced single-valued neutrosophic clustering methods based on similarity measures between SVNSs [
21]. Guo and Sengur introduced the neutrosophic
c-means clustering algorithm [
22], which was inspired by FCM and the neutrosophic set framework. Thong and Son did significant work on clustering based on PFS. In [
10], a picture fuzzy clustering algorithm, called FC-PFS, was proposed. In order to determine the number of clusters, they built an automatically determined most suitable number of clusters based on particle swarm optimization and picture composite cardinality for a dataset [
23]. They also extended the picture fuzzy clustering algorithm for complex data [
24]. Unlike the method in [
10], Son presented a novel distributed picture fuzzy clustering method on the picture fuzzy set [
25]. We can note that the basic ideas of the fuzzy set, the intuitionistic fuzzy set and the SVNS are consistent in the data clustering, but there are differences in the representation of the objects, so that the clustering objective functions are different. Thus, the more adequate description can be better used for clustering. Inspired by FCM, FC-PFS, SVNS and the maximization entropy method, we propose a new clustering algorithm, the single-valued neutrosophic clustering algorithm based on Tsallis entropy maximization (SVNCA-TEM), in this paper, and the experimental results show that the proposed algorithm can be considered as a promising tool for data clustering and image processing.
The rest of paper is organized as follows.
Section 2 shows the related work on FCM, IFC and FC-PFS.
Section 3 introduces the proposed method, using the Lagrange multiplier method to solve the objective function. In
Section 4, the experiments on some benchmark UCI datasets indicate that the proposed algorithm can be considered as a useful tool for data clustering and image processing. The last section draws the conclusions.
2. Related Works
In general, suppose dataset includes n data points, each of the data is a d-dim feature vector. The aim of clustering is to get k disjoint clusters satisfying and . In the following, we will briefly introduce three fuzzy clustering methods, which are FCM, IFC and FC-PFS.
2.1. Fuzzy c-Means
The FCM was proposed in 1984 [
7]. FCM is a data clustering technique wherein each data point belongs to a cluster to some degree that is specified by a membership grade. A data point
of cluster
is denoted by the term
, which shows the fuzzy membership degree of the
i-th data point in the
j-th cluster. We use
to describe the cluster centroids of the clusters, and
is the cluster centroid of
. The FCM is based on the minimization of the following objective function:
where
m represents the fuzzy parameter and
. The constraints for (
1) are,
Using the Lagrangian method, the iteration scheme to calculate cluster centroids
and the fuzzy membership degrees
of the objective function (
1) is as follows:
The iteration will not stop until it reaches the maximum iterations or , where and are the objection function value at -th and -th iterations, and is a termination criterion between zero and . This procedure converges to a local minimum or a saddle point of J. Finally, each data point is assigned to a different cluster according to the fuzzy membership value, that is belongs to if .
2.2. Intuitionistic Fuzzy Clustering
The intuitionistic fuzzy set is an extension of fuzzy sets. Chaira proposed intuitionistic fuzzy clustering (IFC) [
8], which integrates the intuitionistic fuzzy entropy with the objective function of FCM. The objective function of IFS is:
where
, and
is the hesitation degree of
for
. The constraints of IFC are similar to (
2). Hesitation degree
is initially calculated using the following form:
and the intuitionistic fuzzy membership values are obtained as follows:
where
denotes the intuitionistic (conventional) fuzzy membership of the
i-th data in the
j-th class. The modified cluster centroid is:
The iteration will not stop until it reaches the maximum iterations or the difference between and is not larger than a pre-defined threshold , that is .
2.3. Picture Fuzzy Clustering
In [
26], Cuong introduced the picture fuzzy set (which is also called the standard neutrosophic set [
27]), which is defined on a non-empty set
S,
, where
is the positive degree of each element
,
is the neutral degree and
is the negative degree satisfying the constraints,
The refusal degree of an element is calculated as:
In [
10], Thong and Son proposed picture fuzzy clustering (FC-PFS), which is related to neutrosophic clustering. The objective function is:
where
,
.
and
are the positive, neutral and refusal degrees, respectively, for which each data point
belongs to cluster
. Denote
and
as the matrices whose elements are
and
, respectively. The constraints for FC-PFS are defined as follows:
Using the Lagrangian multiplier method, the iteration scheme to calculate
,
and
for the model (
11,
12) is as the following equations:
The iteration will not stop until it reaches the maximum iterations or .
3. The Proposed Model and Solutions
Definition 1. [
15]
Set U as a space of points (objects), with a generic element in U denoted by u. A SVNS A in U is characterized by three membership functions, a truth membership function , an indeterminacy membership function and a falsity-membership function , where . That is, and . There is no restriction on the sum of and ; thus, . Moreover, the hesitate membership function is defined as and .
Entropy is a key concept in the uncertainty field. It is a measure of the uncertainty of a system or a piece of information. It is an improvement of information entropy. The Tsallis entropy [
28], which is a generalization of the standard Boltzmann–Gibbs entropy, is defined as follows.
Definition 2. [
28]
Let be a finite set and X be a a random variable taking values , with distribution . The Tsallis entropy is defined as , where and . For FCM,
denotes the fuzzy membership degree of
to
, and supports
. From Definition 2, the Tsallis entropy of
can be described by
.
n being a fixed number, Yasuda [
13] used the following formulary to describe the the Tsallis entropy of
:
The maximum entropy principle has been widely applied in many fields, such as spectral estimation, image restoration, error handling of measurement theory, and so on. In the following, the maximum entropy principle is applied to the single-valued neutrosophic set clustering. After the objection function of clustering is built, the maximum fuzzy entropy is used to regularize variables.
Suppose that there is a dataset
D consisting of
n data points in
d dimensions. Let
and
be the truth membership degree, falsity-membership degree, indeterminacy membership degree and hesitate membership degree, respectively, that each data point
belongs to cluster
. Denote
and
as the matrices, the elements of which are
and
, respectively, where
. The single-valued neutrosophic clustering based on Tsallis entropy maximization (SVNC-TEM) is the minimization of the following objective function:
The constraints are given as follows:
The proposed model in Formulary (
18)–(
21) is applied to the maximum entropy principle of the SVNS. Now, let us summarize the major points of this model as follows.
The first term of the objection function (
18) describes the weighted distance sum of each data point
to the cluster center
.
being from the positive aspect and
(four is selected in order to guarantee
in the iterative calculation) from the negative aspect, denoting the membership degree for
to
, we use
to represent the “integrated true” membership of the
i-th data point in the
j-th cluster. From the maximum entropy principle, the best to represent the current state of knowledge is the one with largest entropy, so the second term of the objection function (
18) describes the negative Tsallis entropy of
, which means that the minimization of (
18) is the maximum Tsallis entropy.
is the regularization parameter. If
, the proposed model returns the FCM model.
Formulary (
19) guarantees the definition of the SVNS (Definition 1).
Formulary (
20) implies that the “integrated true” membership of a data point
to the cluster center
satisfies the sum-row constraint of memberships. For convenience, we set
, and
belongs to class
if
.
Equation (
21) guarantees the working of the SVNS since at least one of two uncertain factors, namely indeterminacy membership degree and hesitate membership degree, always exists in the model.
Theorem 1. The optimal solutions of the systems(
18–
21)
are: Proof. The Lagrangian multiplier of the optimization model (
18–
21) is:
where
and
are Lagrangian multipliers.
In order to get , taking the derivative of the objective function with respect to , we have . Since , so .
Similarly, .
From (
20), we can get
, that is
, so
; thus, (
23) holds.
From (
23), we can also get
, so
; thus, (
24) holds.
Similarly,
. From (
21), we have
. Therefore, we have
.
Finally, from Definition 1, we can get
. Thus, (
26) holds. ☐
Theorem 1 guarantees the convergence of the proposed method. The detailed descriptions of SVNC-TEM algorithm are presented in the following Algorithm 1:
| Algorithm 1: SVNC-TEM |
| Input: Dataset (n elements, d dimensions), number of clusters k, maximal number of iterations (Max-Iter), parameters: |
| Output: Cluster result |
| 1: | ; |
| 2: | Initialize satisfies Constraints (19) and (20); |
| 3: | Repeat |
| 4: | ; |
| 5: | Update using Equation (22); |
| 6: | Update using Equation (23); |
| 7: | Update using Equation (24); |
| 8: | Update using Equation (25); |
| 9: | Update using Equation (26); |
| 10: | Update ; |
| 11: | Update using Equation (18); |
| 12: | Until or Max-Iter is reached. |
| 13: | Assign to the l-th class if . |
Compared to FCM, the proposed algorithm needs additional time to calculate and in order to more precisely describe the object and get better performance. If the dimension of the given dataset is d, the number of objects is n, the number of clusters is c and the number of iterations is t, then the computational complexity of the proposed algorithm is . We can see that the computational complexity is very high if d and n are large.
4. Experimental Results
In this section, some experiments are intended to validate the effectiveness of the proposed algorithm SVNC-TEM for data clustering. Firstly, we used an artificial dataset to show that SVNC-TEM can cluster well. Secondly, the proposed clustering method was used in image segmentation using an example. Lastly, we selected five benchmark datasets, and SVNC-TEM was compared to four state-of-the-art clustering algorithms, which were: k-means, FCM, IFC and FS-PFS.
In the experiments, the parameter m was selected as two and . The maximum iterations (Max-Iter) . The selected datasets have class labels, so the number of cluster k was known in advance. All the codes in the experiments were implemented in MATLAB R2015b.
4.1. Artificial Data to Cluster by the SVNC-TEM Algorithm
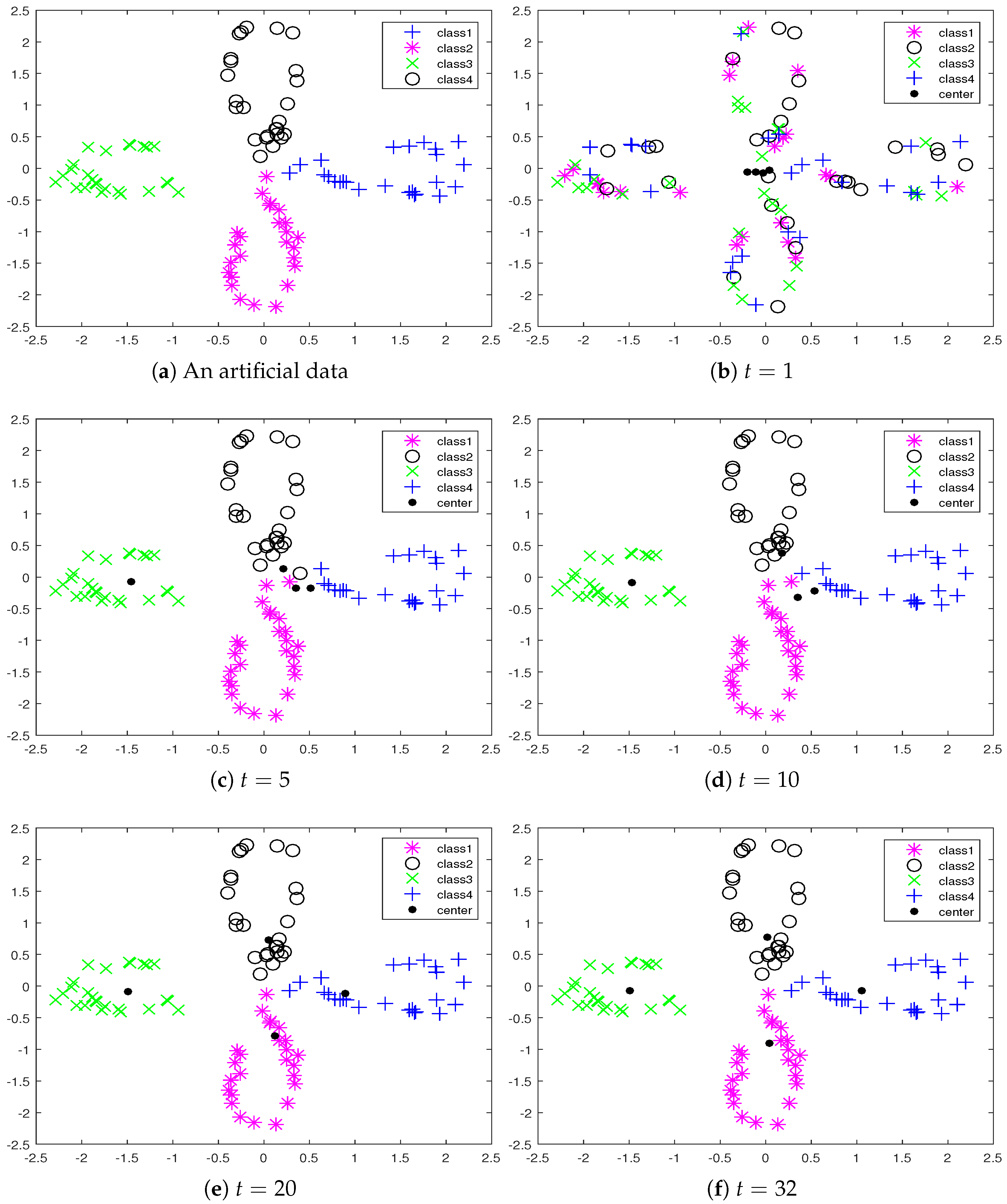
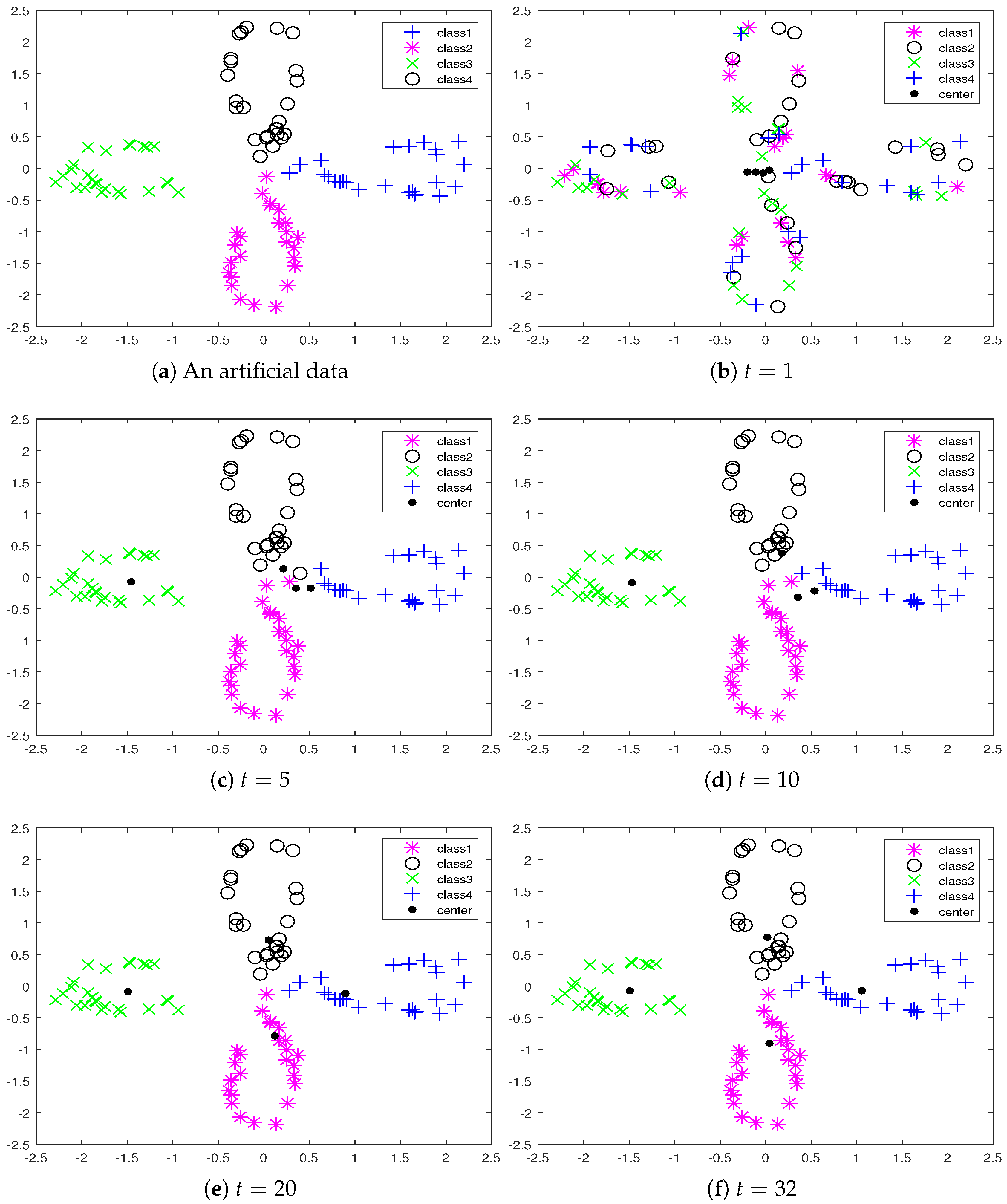
The activities of the SVNC-TEM algorithm are illustrated to cluster artificial data, which was two-dimensional data and had 100 data points, into four classes. We use an example to show the clustering process of the proposed algorithm. The distribution of data points is illustrated in
Figure 1a.
Figure 1b–e shows the cluster results when the number of iterations was
1, 5, 10, 20, respectively. We can see that the clustering result was obtained when
.
Figure 1f shows the final results of the clustering; the number of iterations was 32. We can see that the proposed algorithm gave correct clustering results from
Figure 1.
4.2. Image Segmentation by the SVNC-TEM Algorithm
In this subsection, we use the proposed algorithm for image segmentation. As a simple example, the Lena image was used to test the proposed algorithm for image segmentation. Through this example, we wish to show that the proposed algorithm can be applied to image segmentation.
Figure 2a is the original Lena image.
Figure 2b shows the segmentation images when the number of clusters was
2, and we can see that the quality of the image was greatly reduced.
Figure 2c–f shows the segmentation images when the number of clusters was
5, 8, 11 and 20, respectively. We can see that the quality of segmentation image was improved very much with the increase of the clustering number.
The above two examples demonstrate that the proposed algorithm can be effectively applied to clustering and image processing. Next, we will further compare the given algorithm to other state-of-art clustering algorithms on benchmark datasets.
4.3. Comparison Analysis Experiments
In order to verify the clustering performance, in this subsection, we experiment with five benchmark datasets of the UCI Machine Learning Repository, which are IRIS, CMC, GLASS, BALANCE and BREAST. These datasets were used to test the performance of the clustering algorithm.
Table 1 shows the details of the characteristics of the datasets.
In order to compare the performance of the clustering algorithms, three evaluation criteria were introduced as follows.
Given one data point
, denote
as the truth class and
as the predicted clustering class. The clustering accuracy (ACC) measure is evaluated as follows:
where
n is the total number of data points,
if
; otherwise,
.
is the best permutation mapping function that matches the obtained clustering label to the equivalent label of the dataset. One of the best mapping functions is the Kuhn–Munkres algorithm [
29]. The higher the ACC was, the better the clustering performance was.
Given two random variables
X and
Y,
is the mutual information of
X and
Y.
and
are the entropies of
P and
Q, respectively. We use the normalized mutual information (NMI) as follows:
The clustering results
and the ground truth classes
are regarded as two discrete random variables. Therefore, NMI is specified as follows:
The higher the NMI was, the better the clustering performance was.
The Rand index is defined as,
where
a is the number of pairs of data points belonging to the same class in
C and to the same cluster in
.
d is the number of pairs of data points belonging to the different class and to the different cluster.
n is the number of data points. The larger the Rand index is, the better the clustering performance is.
We did a series of experiments to indicate the performance of the proposed method for data clustering. In the experiments, we set the parameters of all approaches in the same way to make the experiments fair enough, that is for parameter
, we set
. For
, we set
. For each parameter, we ran the given method 50 times and selected the best mean value to report.
Table 2,
Table 3 and
Table 4 show the results with the different evaluation measures. In these tables, we use bold font to indicate the best performance.
We analyze the results from the dataset firstly. For IRIS dataset, the proposed method obtained the best performance for ACC, NMI and RI. For the CMC dataset, the proposed method had the best performance for ACC and RI. For the GLASS and BREAST datasets, the proposed method obtained the best performance for ACC and NMI. For the BALANCE dataset, the proposed method had the best performance for NMI and RI. On the other hand, from the three evaluation criteria, for ACC and NMI, the proposed method beat the other methods for four datasets. For RI, SVNC-TEM beat the other methods for three datasets. From the experimental results, we can see that the proposed method had better clustering performance than the other algorithms.





{kind=link}
{kind=link}