
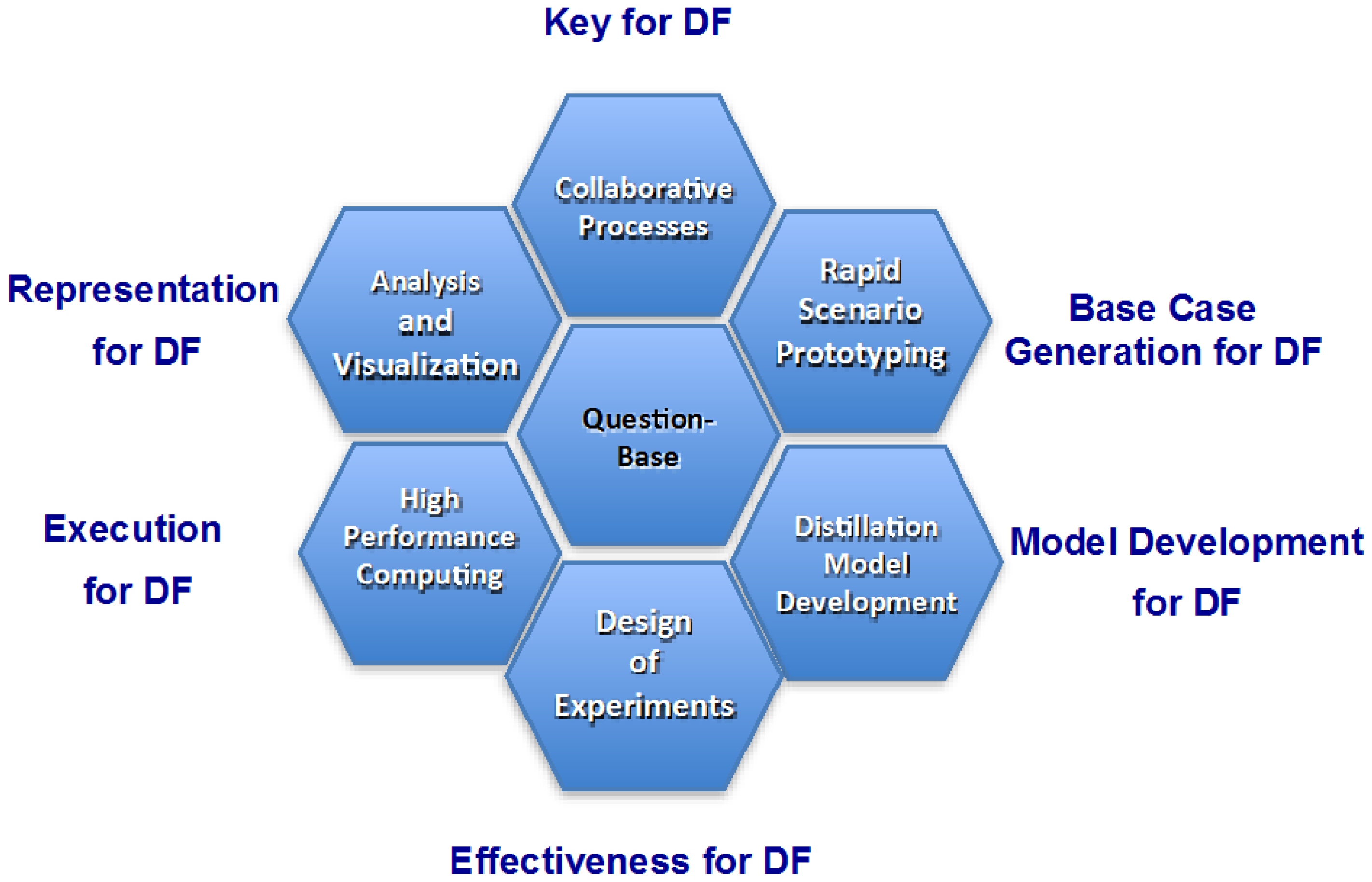
Summary of Data Farming

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
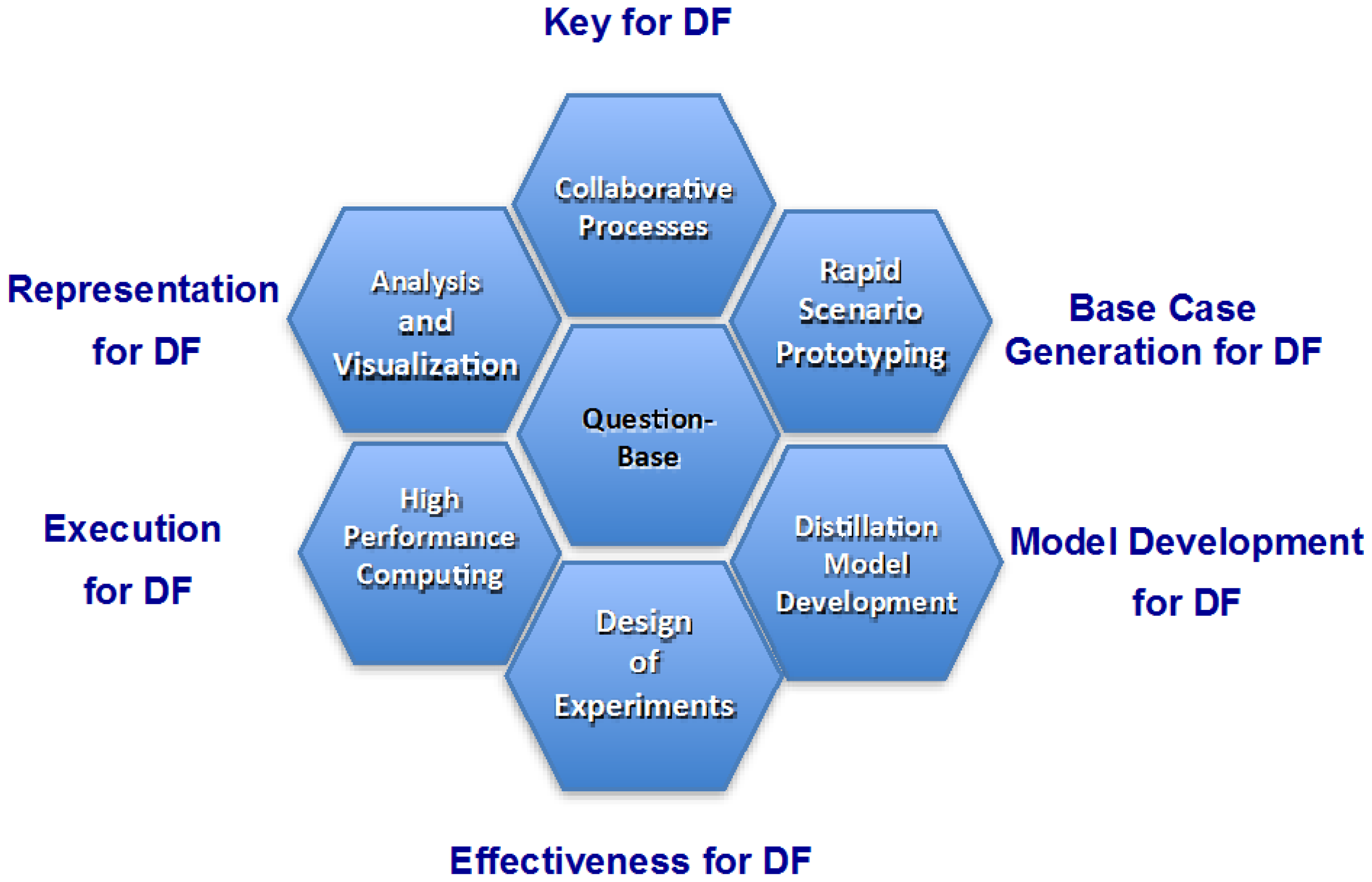
:1. State of the Art in Data Farming
2. Introduction
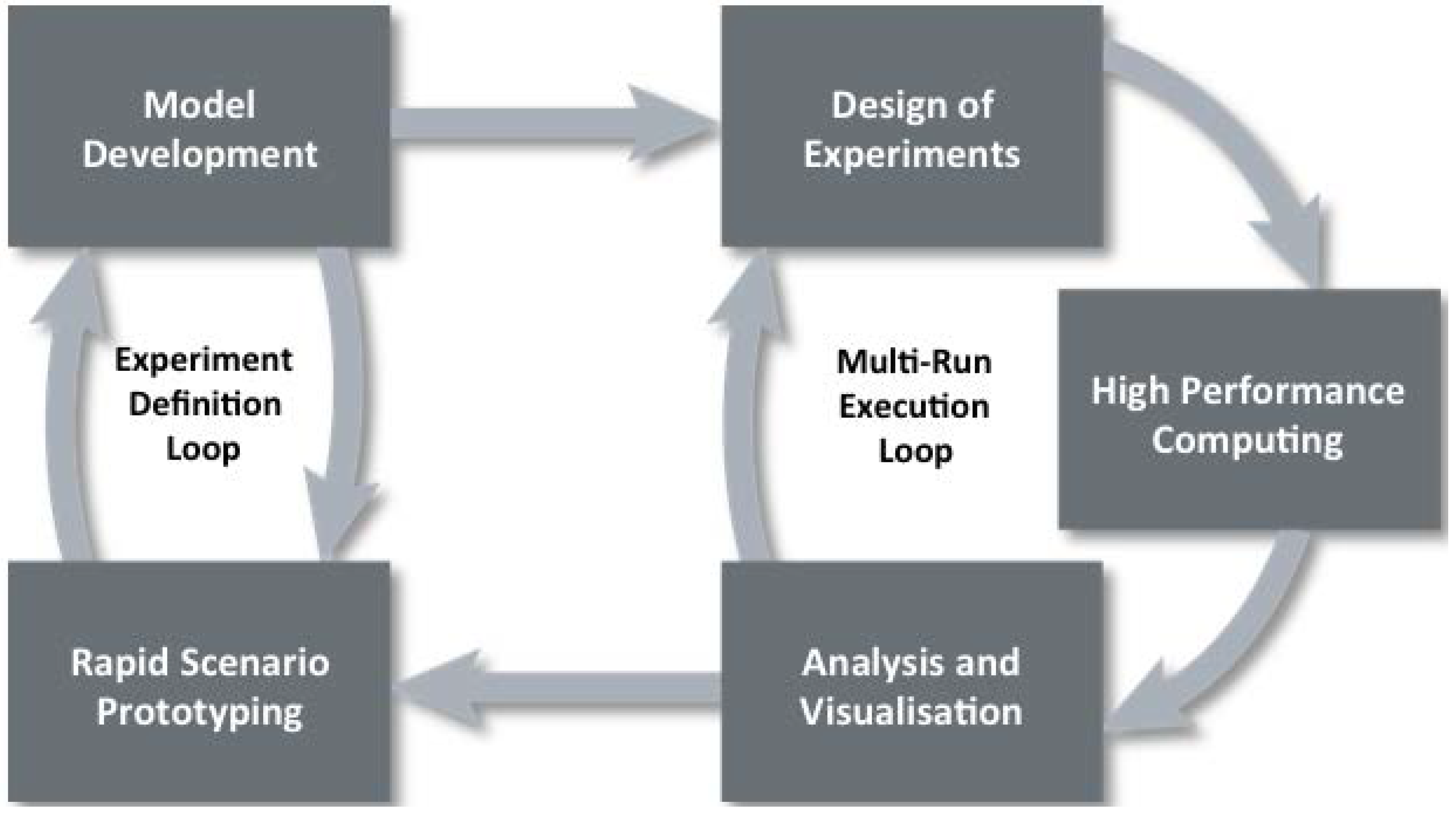
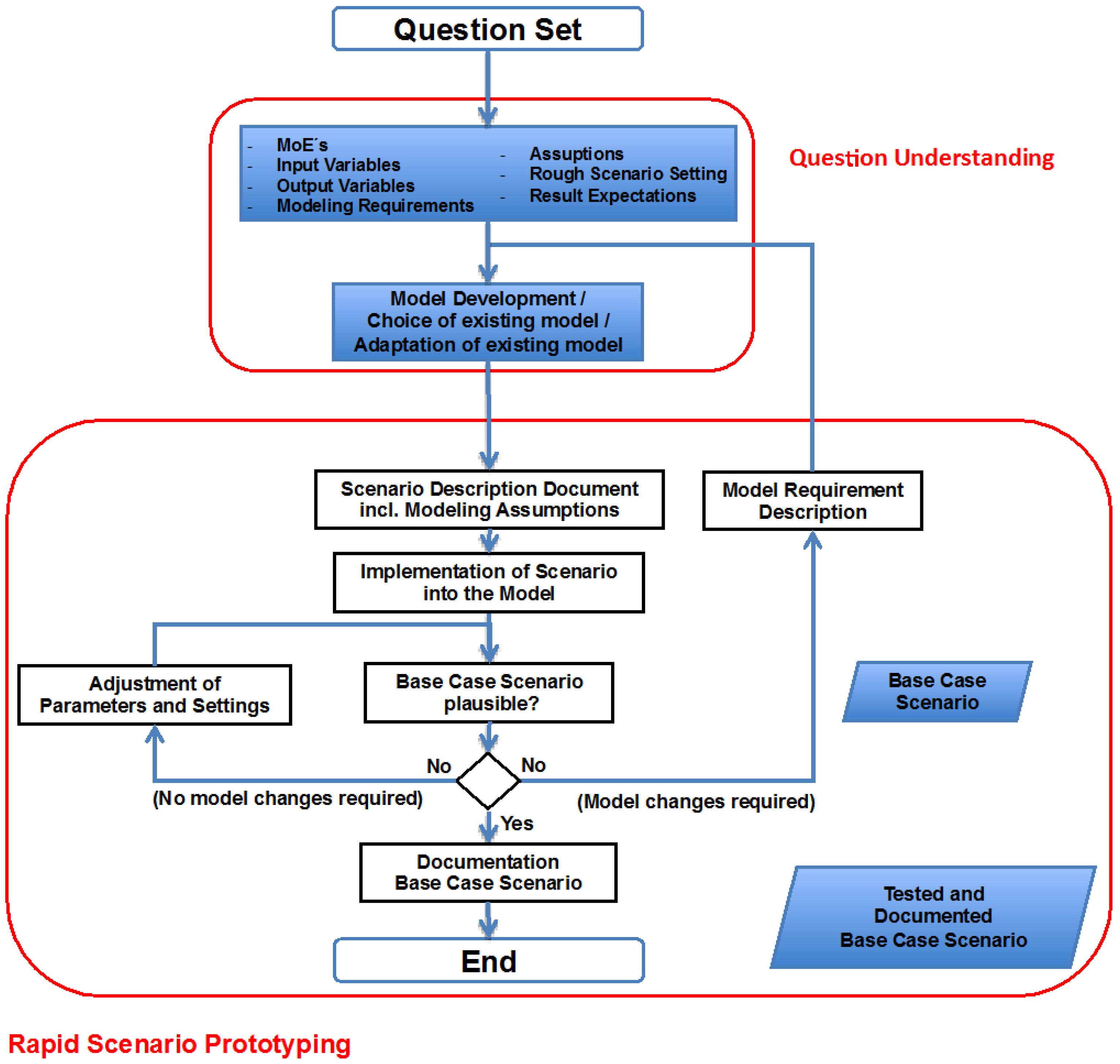
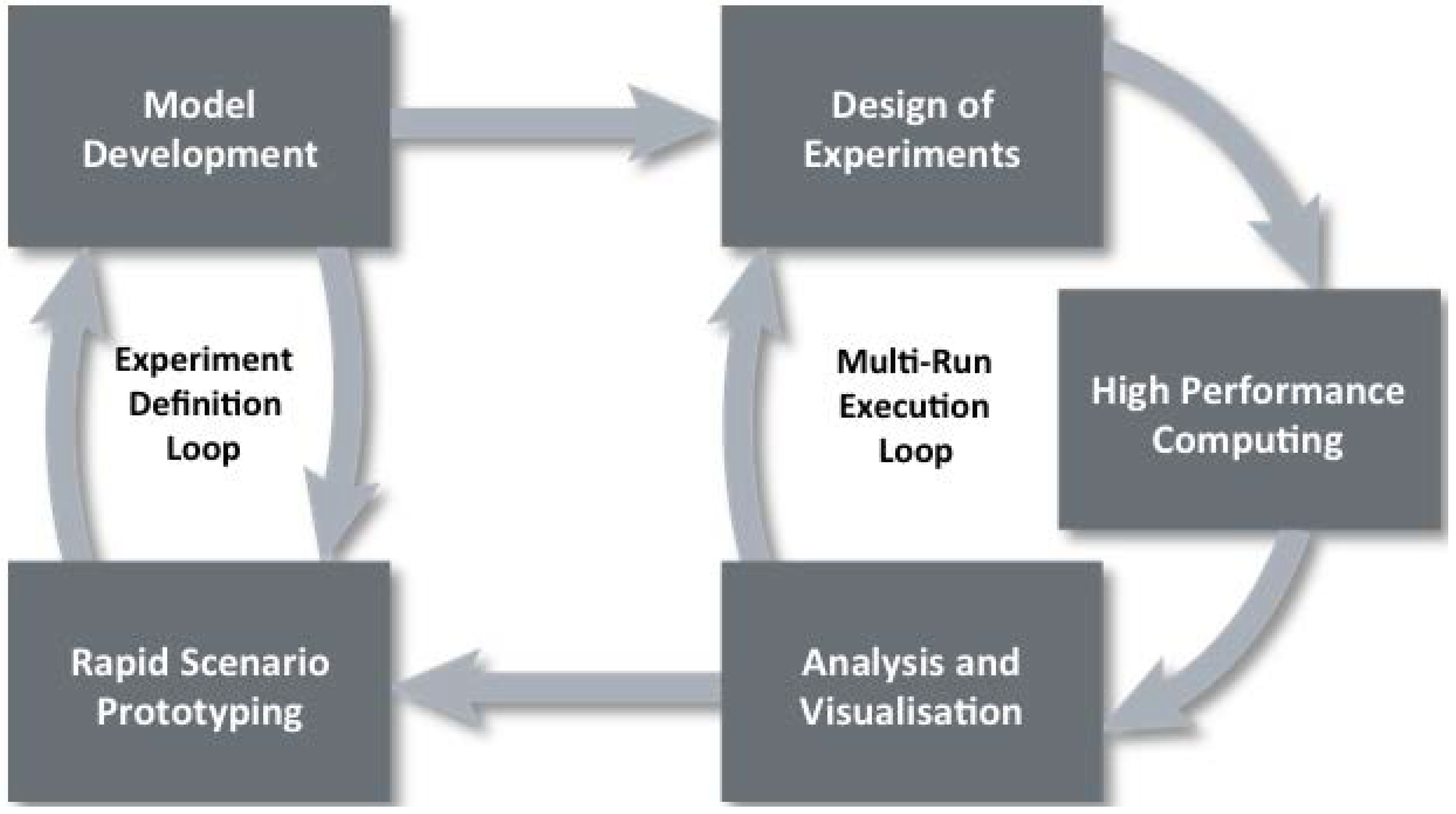
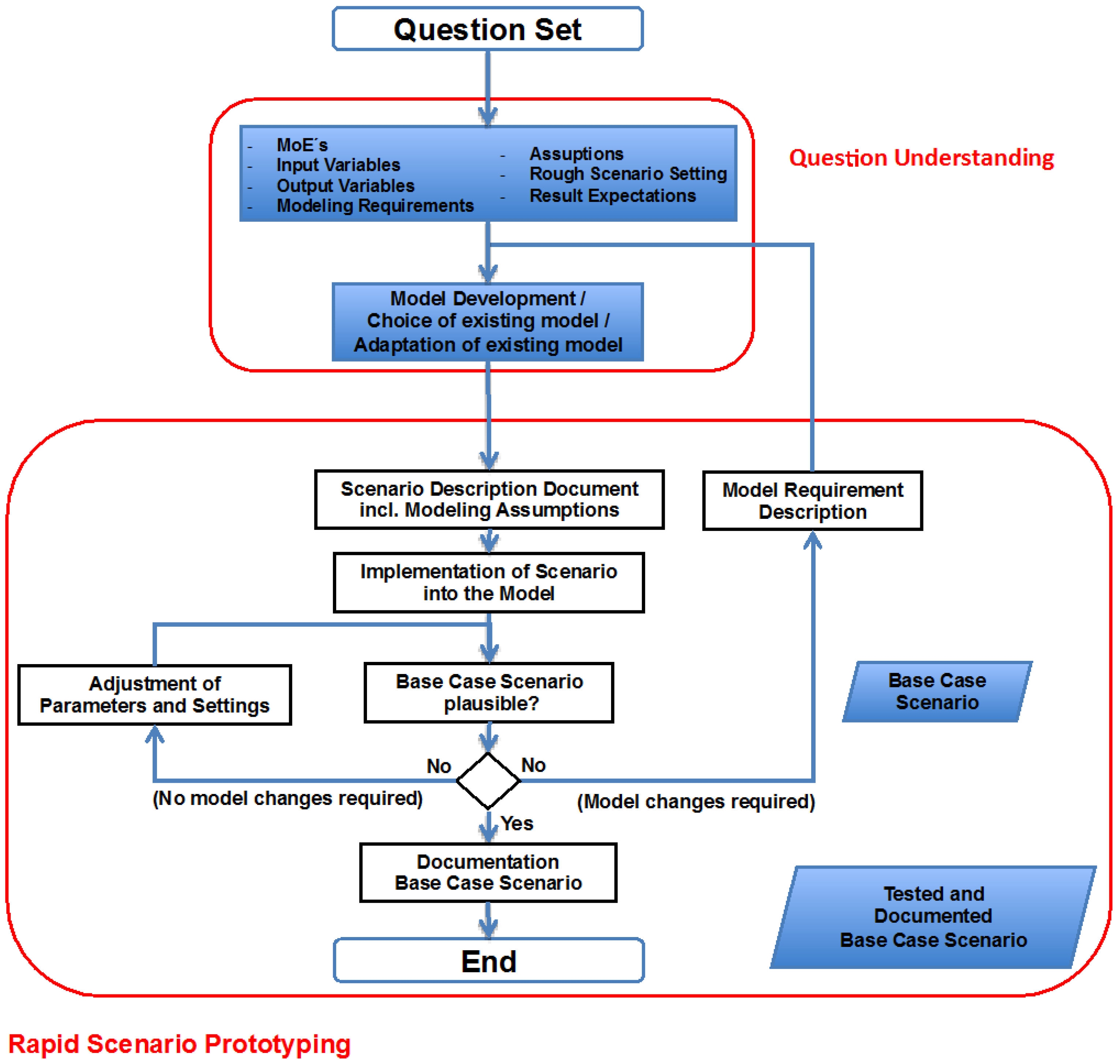
3. Rapid Scenario Prototyping
- Scenario implementation without analysis question: A common problem if analysis team and model experts work separately. In addition, a common malpractice is to build a model, implement a scenario and then to ask: “Which question can we answer now?” This leads to adjustment of questions to the tool and often to answers nobody needs.
- Wrong model for the question: Common causes of this problem might be that someone ordered the use a specific model or that the analyst is familiar with a certain model and wants to use only this model or that only one model is available for usage. Using a “wrong” model clearly limits the amount and scope of insight we can expect from the analysis. The analysis team has to communicate this to the client (decision-maker). It might be necessary to adjust the questions, to refocus the analysis or to stop the analysis project in order to avoid getting useless results.
- Data not available or of bad quality: Data problems often lead to additional assumptions. Sometimes during model development, data “dummies” are used to test the model and later left in as parameters. If this is not known or forgotten, it can lead to wrong conclusions or recommendations.
- Bad or missing model documentation: The model documentation should answer the question “How are things modeled?” It is obvious that bad or missing model documentation seriously impedes a useful scenario implementation. Model documentation cannot replace the model expert, but there is no model expert without model documentation; again, a serious threat for the success of the whole analysis project!
- SMEs not available: This is certainly a kill-criterion for a successful analysis. During RSP, SME knowledge is needed to implement and test the scenario. For the usefulness and acceptance of analysis results, the involvement of SMEs is essential.
- Model expert not available: Even a good model documentation cannot replace an experienced model expert, because model expert means much more than being able to handle the simulation model. Knowing how things are modelled in the model is the crucial part here. The model expert is not only necessary for implementing and testing the scenario, but also later for interpreting simulation results together with analysts and SMEs.
- Too much detail in modeling: The art of modeling is to get the level of abstraction right. Too much detail in the scenario will make it nearly impossible to extract the relevant information and to come to valid conclusions pertaining to the problem area. The analysis team has to withstand the temptation to put more and more details into the model and the scenario. The required level of detail should be determined by the analysis questions only.
- Not enough detail in modeling: If the model or the scenario is not detailed enough, the analysis will not reveal the kind of insights we hope for. Much thought has to be spent in the starting phase of the analysis to get the right level of abstraction.
- Missing possibilities for editing the scenario settings: Suitable editors should be available to implement and adjust scenario settings. This is not only important to save time, but also to better involve SMEs in this process. An example might be an editor to create or change rule sets for agents in the simulation model. Parameters or data hardcoded into the model often create the necessity to construct work-arounds.
- Missing equipment or software: An effective RSP requires the right tools. Insufficient support in this area leads to more time-consuming and inefficient processes. A common example is the need to generate or manipulate terrain databases for the simulation system.
- Question changes during RSP process: Whenever an analysis question changes, the analysis team has to check the implications on all the aspects of the analysis, including the model and scenario, otherwise the analysis work might be invalid and the findings useless.
- Exaggerated Political Correctness: The scenario description within RSP used as a basis for scenario implementation should be separated and distinguished from more general scenario context descriptions, which often include many more domains like historical development of the situation. The RSP scenario description should strongly focus on the investigation of the analysis question, otherwise other influences might reduce the usability of the scenario for the analysis.
- Model still under development: It is not uncommon that a model still under development is chosen for the analysis. In this case, it is important to use a specified version of the model (“freeze the model”) for the analysis; otherwise, simulation output might change due to the influence of new model features without being aware of this cause.
- MOE/input data/output data not defined: Scenario implementation and testing should take the required simulation input and output data as well as the MOE into account, otherwise the analysis project will re-enter the RSP sooner than expected.
- Insufficient time for RSP: Rapid is relative. The analysis team should not underestimate the time necessary to implement and test the scenario. Insufficient time can lead to a low quality base case scenario, which will lead to low quality analysis results.
- Assumptions not documented: Assumptions and development of assumptions can have a large impact on the interpretation of simulation results. Different groups need a common understanding, and if the assumptions are documented there may be less room for error.
- Reality not reflected sufficiently in scenario (“Working on the wrong model”): The simulation will still produce numbers, which we can analyze, and statistical insights can be visualized. We can even draw conclusions and give recommendations but they might not be applicable or even dangerous. This shows that involvement of SMEs is essential during the whole RSP process.
- Simulation produces unwanted effects not present in the real world: This aspect might be caused by model errors, work-arounds or modeling errors during scenario implementation. Such effects oftentimes remain undiscovered until the analysis of the data farming results or until the interpretation of these results. For example, in the Humanitarian Assistance case study in [1], some initial incorrect coding of hospital ship capacity led to no difference in effectiveness when there should have been. These unwanted effects can be dangerous if they are never discovered, because they can lead to wrong conclusions as a result of the whole analysis project.
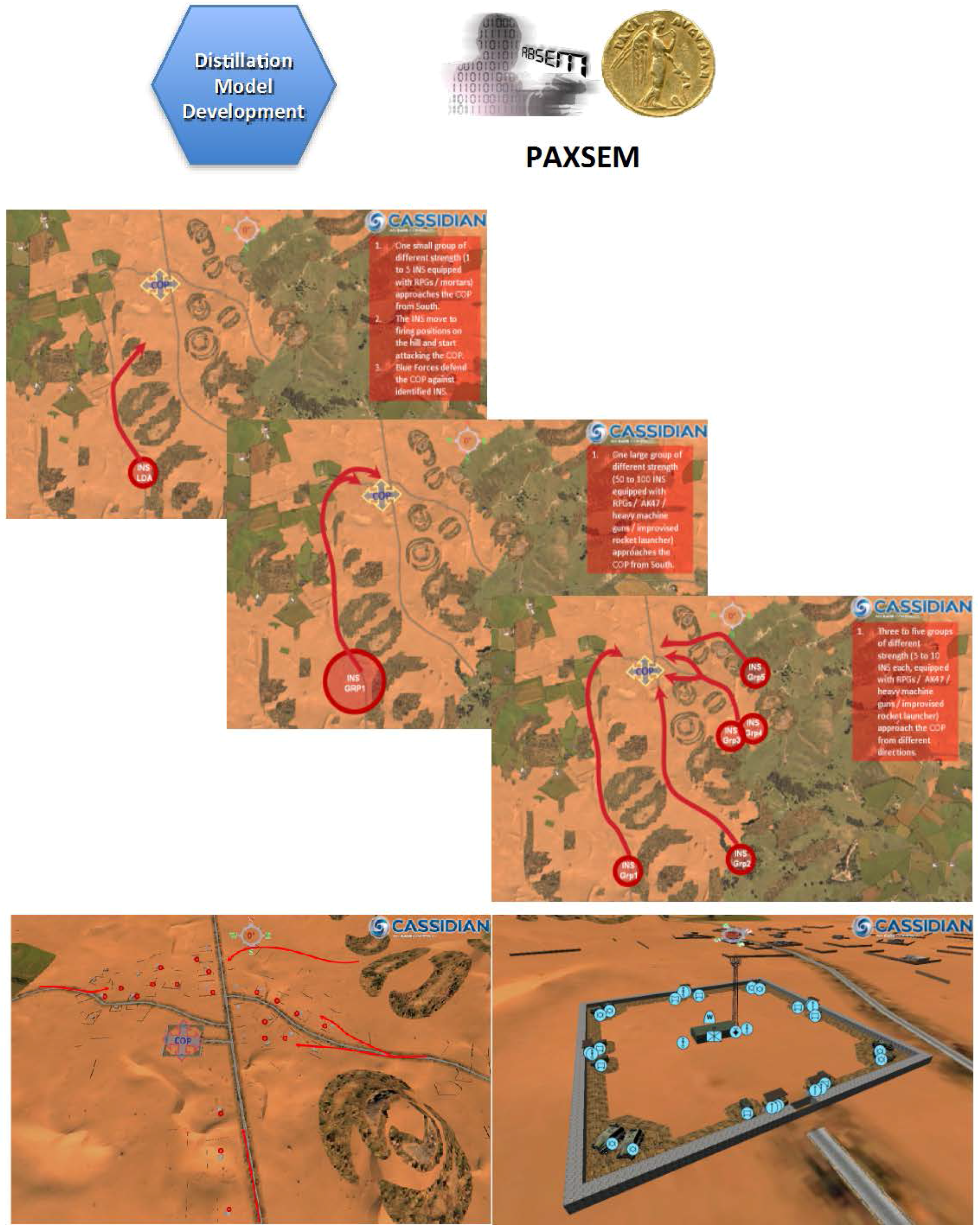
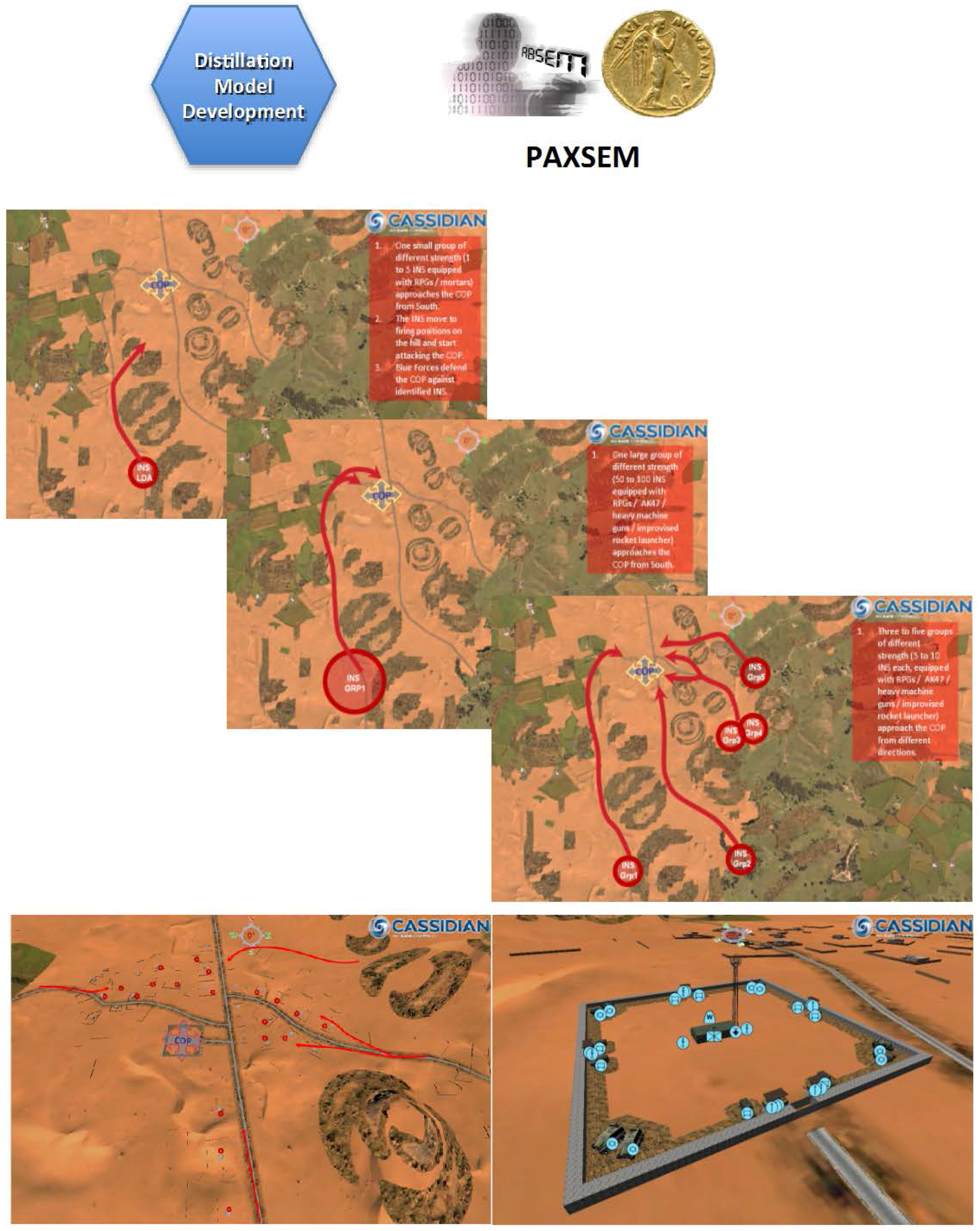
4. Distillation Model Development
- MANA (Map Aware Non-uniform Automata) is an agent-based, time-stepped, distillation model developed by the New Zealand Defence Technology Agency (DTA) for the New Zealand Defence Force. The model was built on the idea that overly detailed models are not helpful in finding robust system settings for desired battlefield outcomes because they are too focused on extraneous issues. MANA, and therefore models only the essential details of a scenario and tries to create a complex adaptive system that mimics real-world factors of combat. The agents are map aware, meaning that the map serves as the agent's impression of its environment. This modeling environment has a relatively easy GUI, allows for quicker scenario development, and is capable of data farming.
- Pythagoras is a multi-sided agent-based model (ABM) created to support the growth and refinement of the U.S. Marine Corps Warfighting Laboratory’s Project Albert. Anything with a behavior can be represented as an agent. The interaction of the agents and their behaviors can lead to unexpected or emerging group behaviors, which is the primary strength of this type of modeling approach. As Pythagoras has grown in capability, it has been applied to a wide variety of tactical, operational and campaign level topics in conventional and irregular warfare.
- ITSimBw is a multi-agent simulation system designed to simulate and analyze military operations in asymmetric warfare. The core abilities are data farming, optimization and analysis. It is designed to adapt to different military scenarios scalable in time, space and functionality. Therefore, several so called “Szenarkits” were developed to cover certain question-driven surveys inspired by the German Bundeswehr.
- PAXSEM is an agent-based simulation system developed in Germany for sensor-effector simulations (ABSEM) on the technical and tactical level that can be used for high performance data farming experimentation. PAXSEM addresses combat-oriented questions as well as questions relevant to peace support operations. For being able to take into account civilians in military scenarios, PAXSEM also contains a psychological model that can be used to model civilians in an adequate way. Civilians in PAXSEM behave according to the current status of certain motives, such as fear, anger, obedience, helpfulness or curiosity (PAX). According to the motivational strength of these human factors, the civilian agent will choose and execute certain actions.
- SANDIS is a novel military operational analysis tool developed in Finland and used by Finnish Defence Forces (FDF) for comparative combat analysis from platoon to brigade level. In addition, it can be used to study the lethality of indirect fire, since it includes a high-resolution physics-based model for fragmenting ammunition. SANDIS has also been used for analyses of medical evacuation and treatment. The software is based on Markovian combat modeling and fault logic analysis.
- ABSNEC is a simulation system developed in Canada that is able to represent realistic force structures with tiered C2 architectures, as well as human factors such as stress, fear, and other factors towards the analysis of battle outcomes in network operations. In addition, the simulation system provides flexibility to users in creating customized algorithms that define network agents in route control and bandwidth capacity assignment in the communication network.
- RSEBP is a simulation-based decision support system developed in Sweden for evaluation of operational plans for expeditionary operations. The system simulates a blue forces operational plan against a scenario of red and green group actors. This system uses a special form of data farming based on A*-search, a tree of alternative plan actions, where a full plan instance corresponds to one data input point.
- C2WS is a command and control simulation system developed in Sweden. The system models all levels from combat up to operational levels. It can be used for planning, procurement, and training/exercises. This system does not currently use data farming; it may be extended to include data farming under a data farming wrapper.
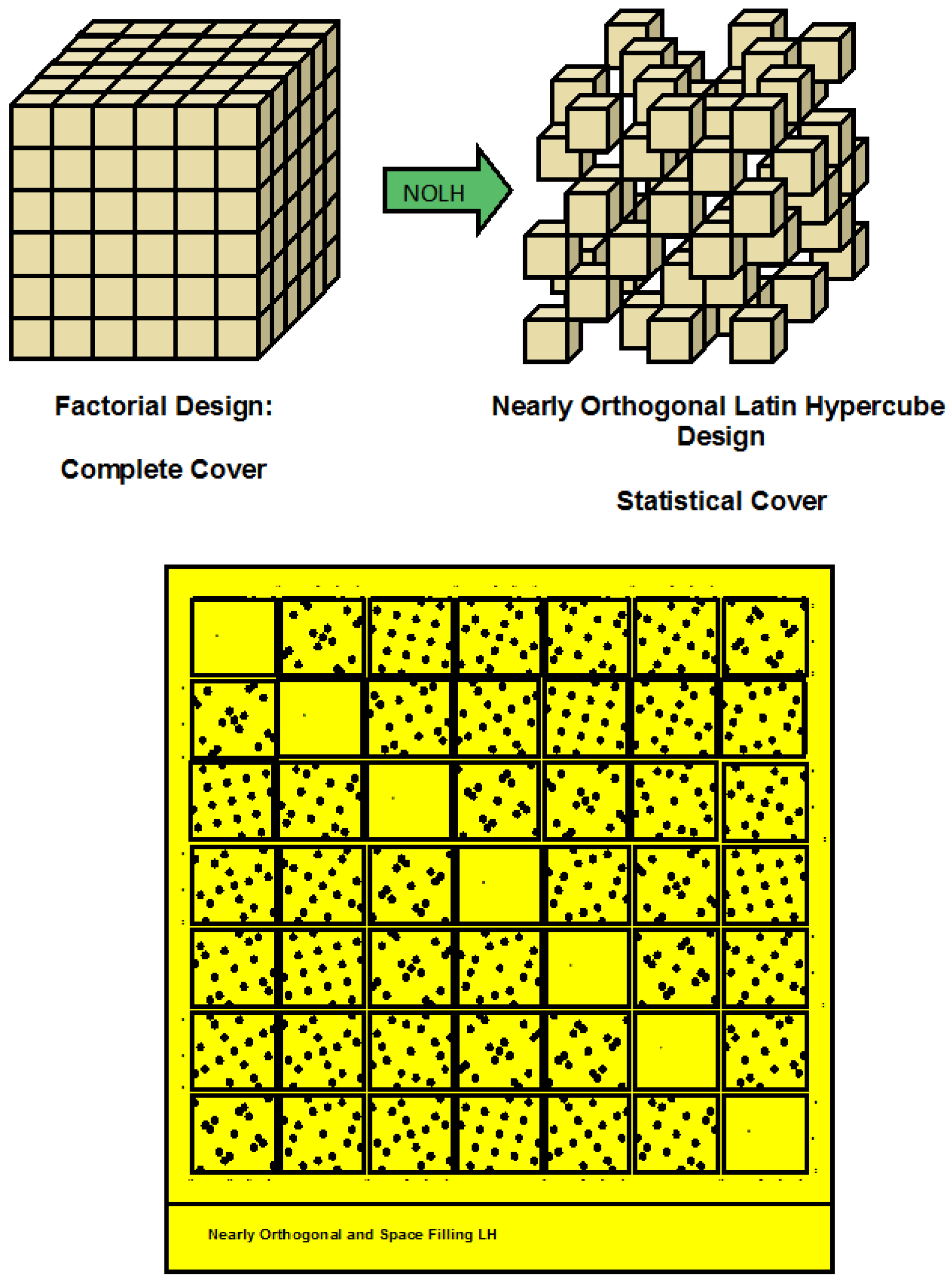
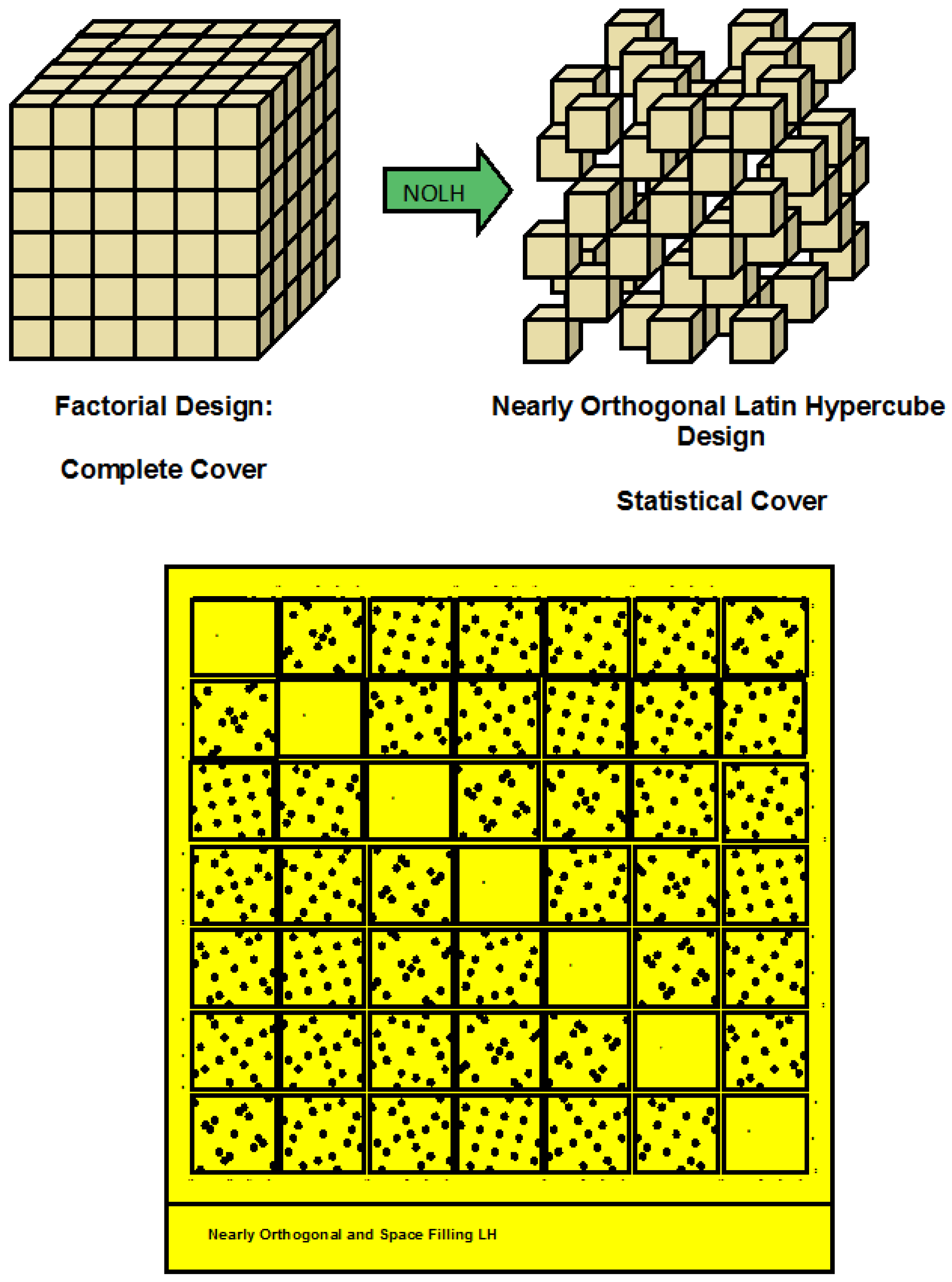
5. Design of Experiments
6. High Performance Computing
- 1
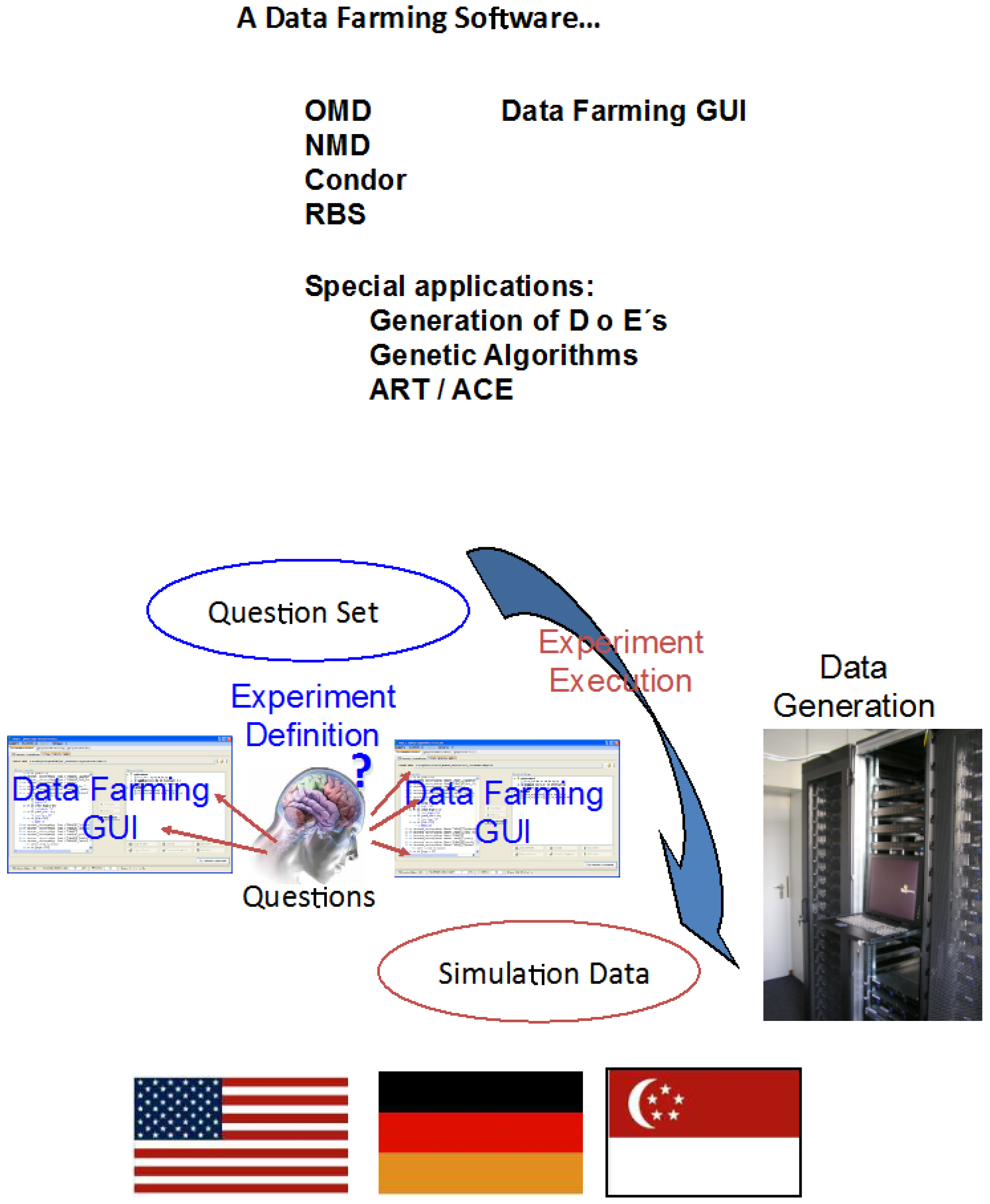
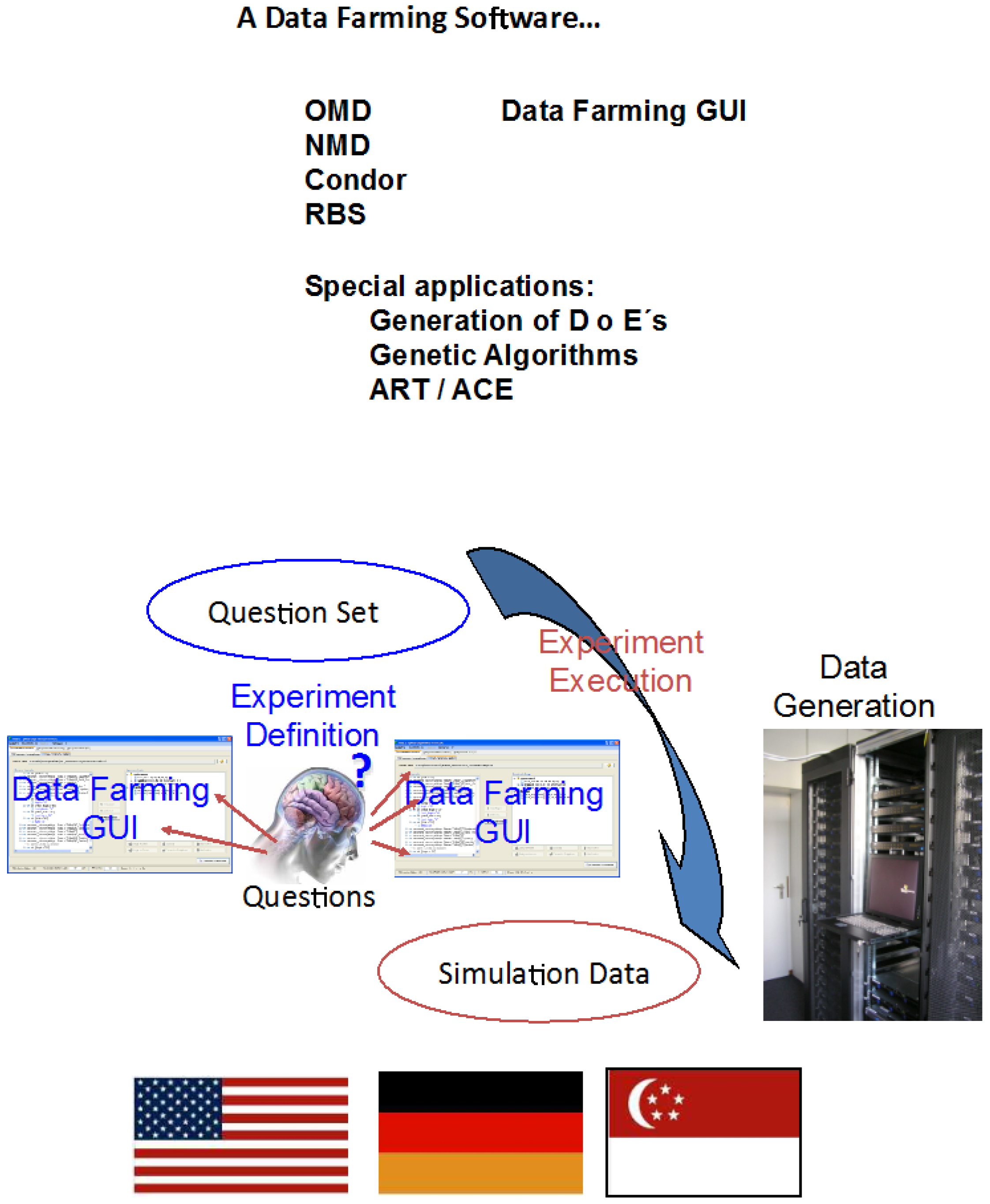
- A “data farmable” model (we use the term “model” generically; it can refer to any computational model or simulation).
- 2
- A set of model inputs, generically called the “base case”.
- 3
- A specification of your experiment (the set of factors in your design and a mechanism for finding and setting those in the set of model inputs).
- 4
- A set of HPC resources, both software and hardware, needed to execute a model “instance”.
- 5
- The data farming software.
- 6
- A set of model outputs.
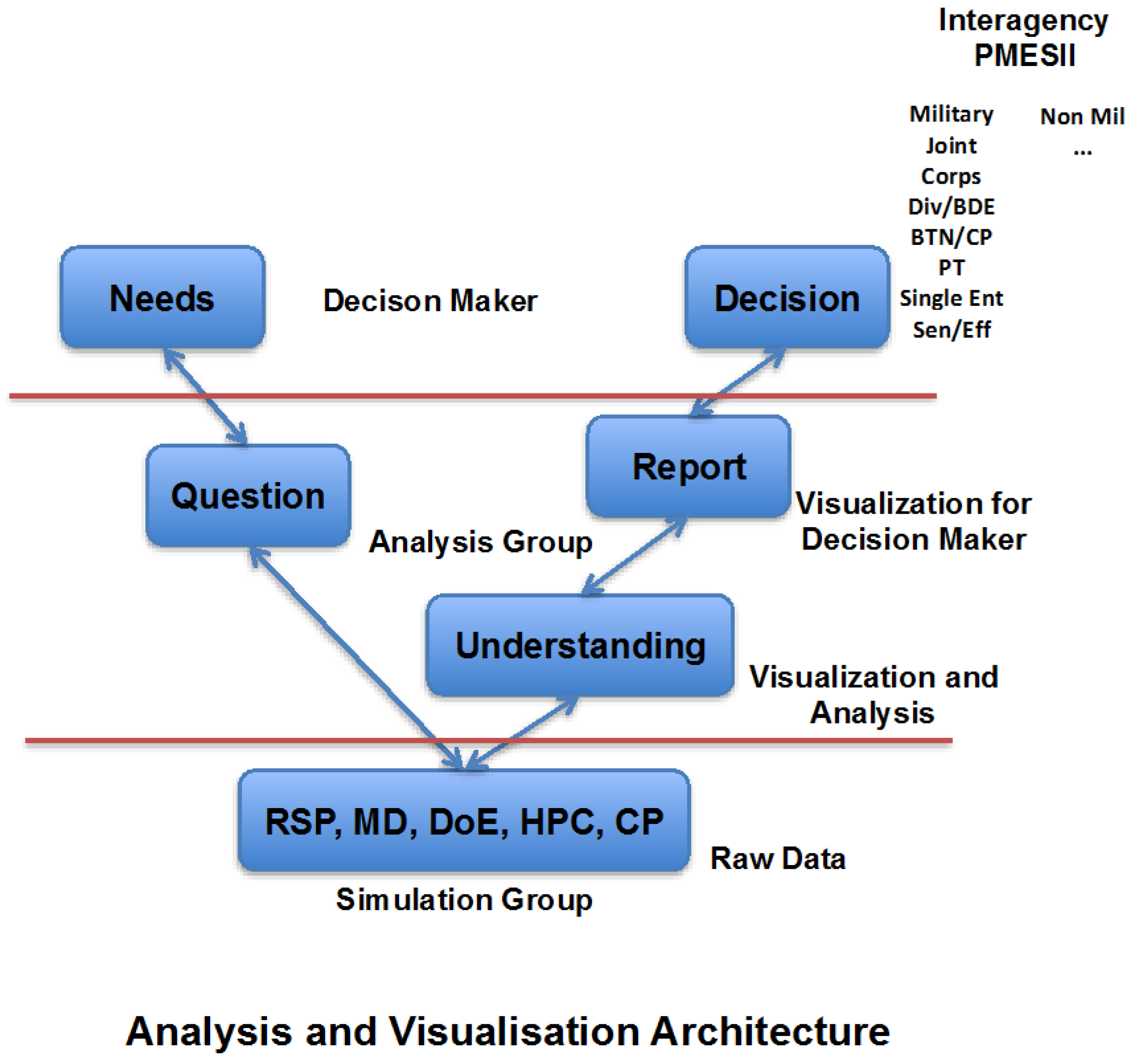
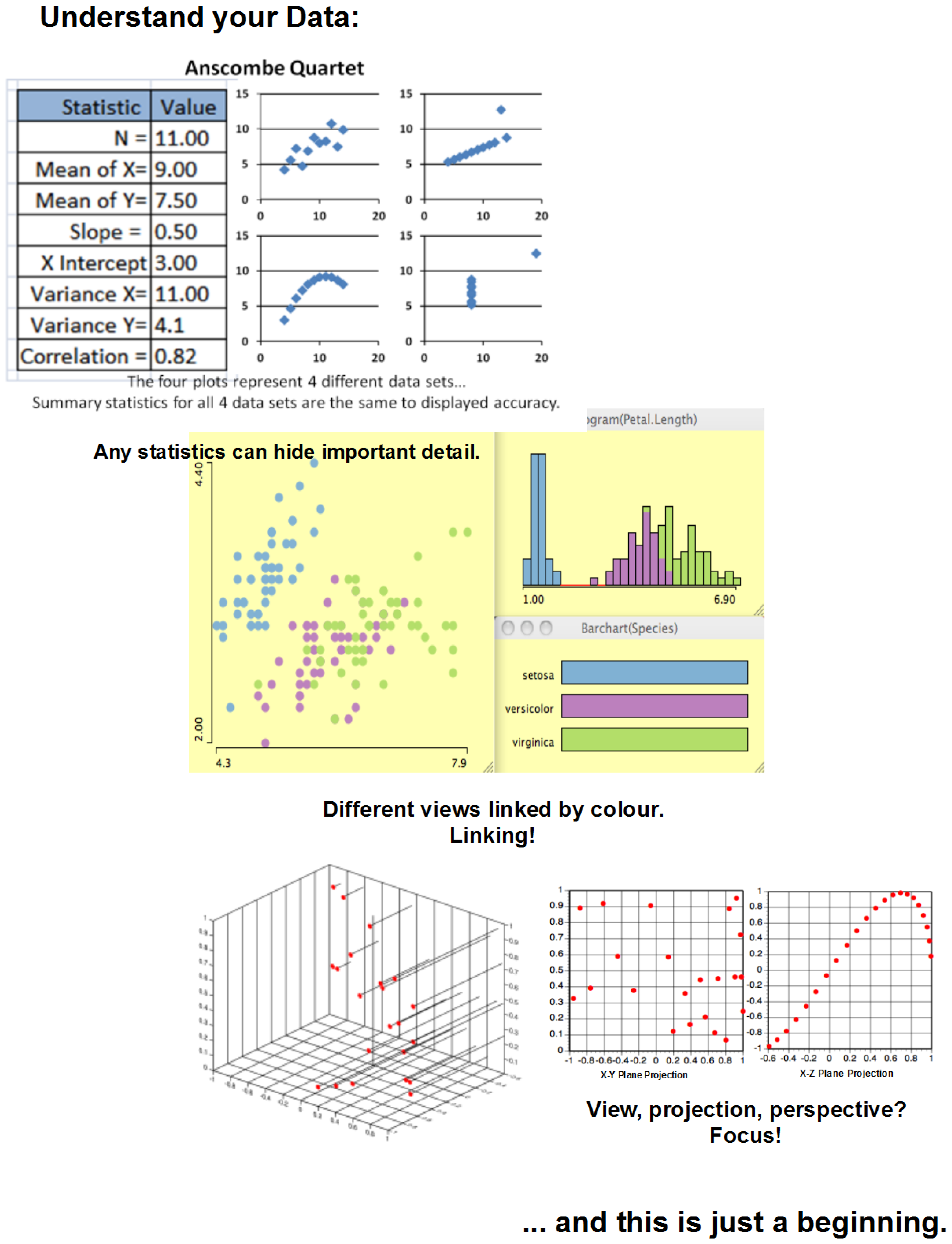
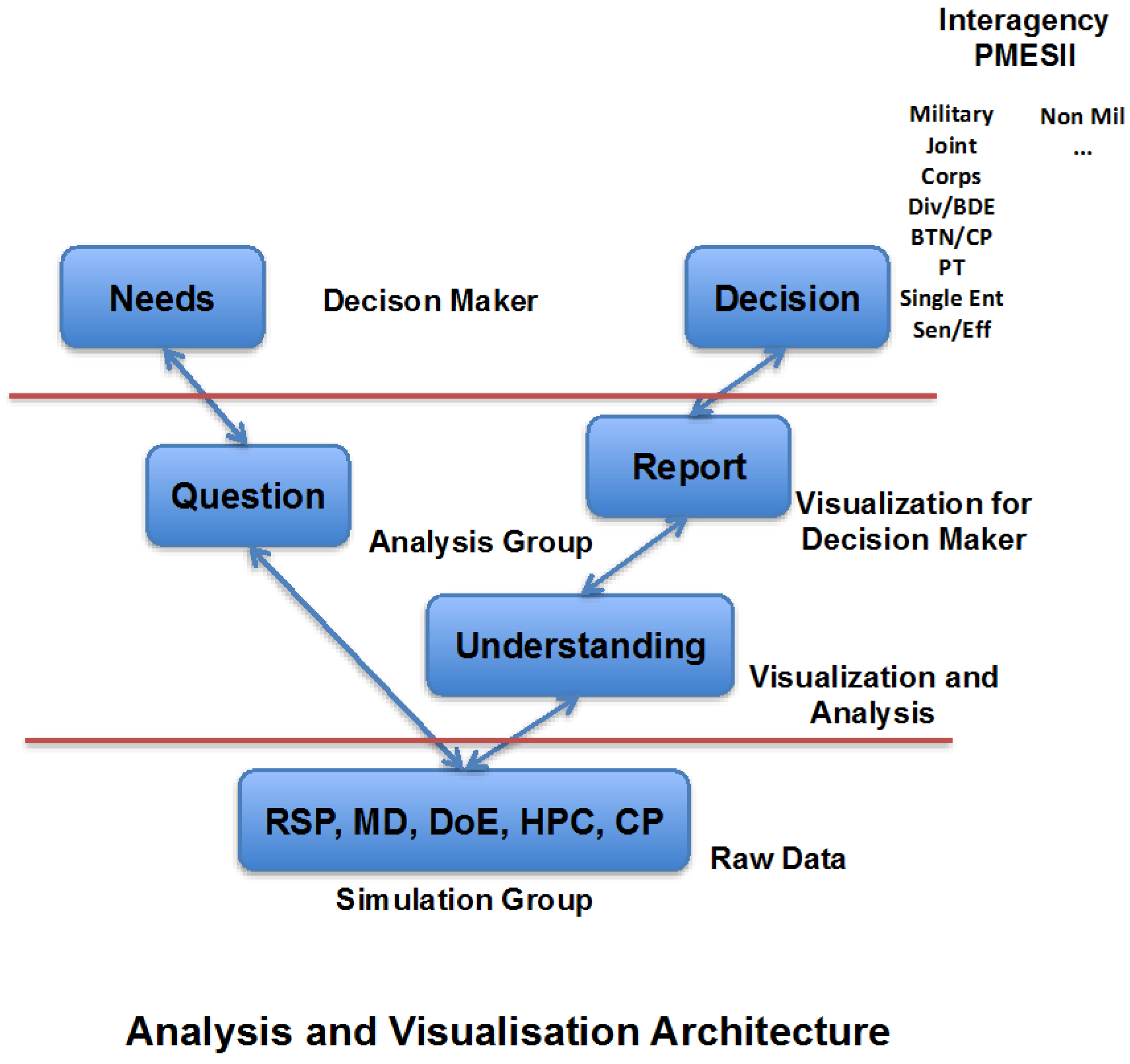
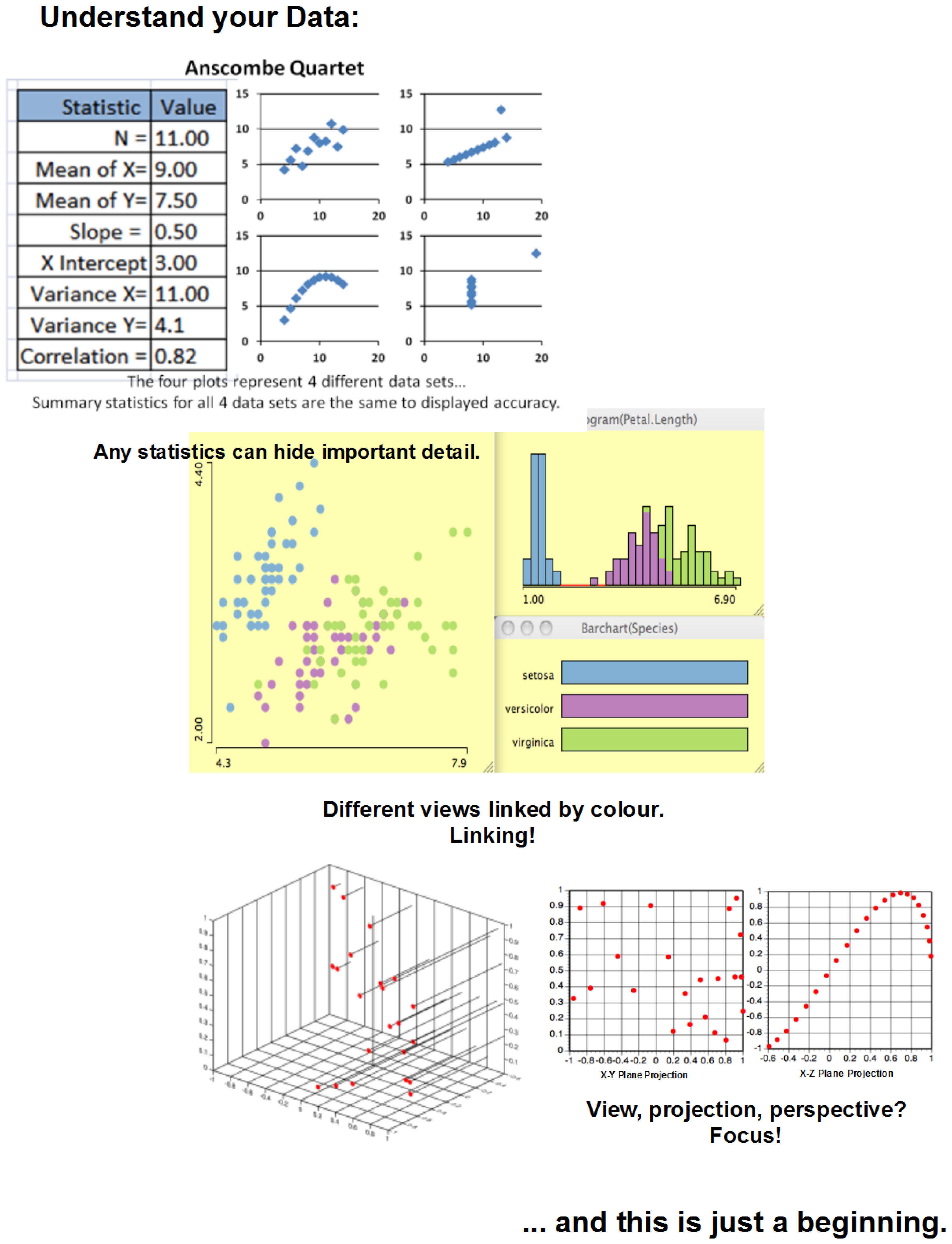
7. Analysis and Visualization
- Question 1: What was the spread of the responses over the entire experiment?
- Question 2: How much random variation was observed just over the random replications?
- Question 3: Were there any outliers?
- Question 4: Were the responses correlated?
- Question 5: Which factors were most influential?
- Question 6: Were there any significant interactions?
- Question 7: What were the interesting regions and threshold values?
- Question 8: Are any of your results counter-intuitive?
- Question 9: Which configurations were most robust?
- Question 10: Are there any configurations that satisfy multiple objectives?
8. Collaboration
9. Humanitarian Assistance/Disaster Relief Case Study
- How do the distribution of medical resources and evacuation chains affect the loss of life?
- Where can the response be improved and where are the bottlenecks?
- What are the probability distributions for different triage classes over time under various conditions?
- What are the effects of changes in coordination, capacity, and resource distribution on triage classes/loss of life?
- How would better allocation of transportation resources affect the performance measures?
- What if improved ship-to-shore assets are available? What are the implications regarding this greater capacity on coordination, evacuation/treatment, and kinds of resources available?
10. Force Protection Case Study
Acknowledgments
Author Contributions
Conflicts of Interest
References and Notes
- Horne, G.; Åkesson, B.; Meyer, T.; Anderson, S.; Narayanan, F.; Bottiger, M.; Chong, N.E.; Britton, M.; Ng, K.; Bruun, R.; et al. MSG-088 Data Farming in Support of NATO; Final Report; NATO Science and Technology Office (STO): Paris, France, March 2014. [Google Scholar]
- Horne, G. Data Farming: A Meta-Technique for Research in the 21st Century; Naval War College: Newport, RI, USA, 1997. [Google Scholar]
- Horne, G. Maneuver warfare distillations: Essence not verisimilitude. In Proceedings of the 1999 Winter Simulation Conference, Phoenix, AZ, USA, 5–8 December 1999; Farrington, A., Nembhard, H.B., Sturrock, D.T., Evans, G.W., Eds.; pp. 1147–1151.
- Horne, G.; Leonardi, M. Maneuver Warfare Science 2001; Marine Corps Combat Development Command: Quantico, VA, USA, 2001. [Google Scholar]
- Horne, G.; Meyer, T. Data farming: Discovering Surprise. In Proceedings of the 2004 Winter Simulation Conference, Savannah, GA, USA, 7–10 December 2004; Ingalls, R., Rossetti, M.D., Smith, J.S., Peters, B.A., Eds.; Institute of Electrical and Electronics Engineers, Inc.: Piscataway, NJ, USA; pp. 171–180.
- Horne, G.; Meyer, T. Data farming: Discovering surprise. In Proceedings of the 2005 Winter Simulation Conference, Orlando, FL, USA, 4 December 2005.
- Hoffman, F.; Horne, G. Maneuver Warfare Science; United States Marine Corps Project Albert: Quantico, VA, USA, 1998. [Google Scholar]
- Meyer, T.; Horne, G. Scythe, the Proceedings and Bulletin of the International Data Farming Community. Available online: http://www.datafarming.org (accessed on 1 January 2016).
- Horne, G. MSG-088 Data Farming in Support of NATO. In MSG-088 Program of Work; NATO Research and Technology Office (RTO): Paris, France, 2010. [Google Scholar]
- Horne, G.; Seichter, S. Data Farming Support to NATO: A summary of MSG-088 work. In Proceedings of the MSG-111 Symposium, Paper Number 14, Sydney, Australia, 17 October 2013.
- Seichter, S. MSG-088 Data Farming in Support of NATO: Case Study Force Protection. In Proceedings of the MSG-111 Symposium, Paper Number 17, Sydney, Australia, 18 October 2013.
- University of Bundeswehr, Leitfaden simulationsgestützte Analysen in der Bundeswehr, Code of best practice of simulation based analyses in the German Armed Forces, Institute for Technology of Intelligent Systems, Center of Transformation of the Bundeswehr, Munich, 2011.
- Kallfass, D.; Schlaak, T. NATO MSG-088 Case study results to demonstrate the benefit of using Data Farming for military decision support. In Proceedings of the 2012 Winter Simulation Conference, Berlin, Germany, 9–12 December 2012.
- Sanchez, S.M. Work smarter, not harder: Guidelines for designing simulation experiments. In Proceedings of the 2006 Winter Simulation Conference, Monterey, CA, USA, 3–6 December 2006; Perrone, L.F., Wieland, F.P., Liu, J., Lawson, B.G., Nicol, D.M., Fujimoto, R.M., Eds.; Institute of Electrical and Electronic Engineers, Inc.: Piscataway, NJ, USA; pp. 47–57.
- Choo, C.S.; Chua, C.L.; Low, S.; Ong, D. A co-evolutionary approach for military operational analysis. In Proceedings of the World Summit on Genetic and Evolutionary Computation, Shanghai, China, 12–14 June 2009.
- McCourt, R.; Ng, K. Enhanced network modelling in ABSNEC. In Proceedings of the International Simulation Multi-Conference, Orlando, FL, USA, 11–15 April 2010; pp. 537–544.
- Ng, K.; Rempel, M. ABSNEC—An agent-based system for network enabled capabilities/operations—I. In Proceedings of the International Simulation Multi-Conference, IEEE Catalogue No. CFP0974, Istanbul, Turkey, 13–16 July 2009.
- McCourt, R.; Ng, K.; Mitchell, R. A Canadian approach towards network enabled capabilities. In Proceedings of the International Defence & Homeland Security Simulation Workshop, Rome, Italy, 12–14 September 2011.
- McCourt, R.; Ng, K.; Mitchell, R. An agent based approach towards network-enabled capabilities—I: Simulation validation & illustrative examples. J. Def. Model. Simul. 2012. [Google Scholar] [CrossRef]
- Moradi, F.; Schubert, J. Modelling a simulation-based decision support system for effects-based planning. In Proceedings of the NATO Symposium on Use of M&S in: Support to Operations, Irregular Warfare, Defence Against Terrorism and Coalition Tactical Force Integration (MSG-069), Brussels, Belgium, 15–16 October 2009; NATO Research and Technology Organisation: Neuilly-sur-Seine, France, 2009; pp. 1–14. [Google Scholar]
- Schubert, J.; Moradi, F.; Asadi, H.; Hörling, P.; Sjöberg, E. Simulation-based decision support for effects-based planning. In Proceedings of the 2010 IEEE International Conference on Systems, Man and Cybernetics (SMC 2010), Istanbul, Turkey, 10–13 October 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 636–645. [Google Scholar]
- Schubert, J.; Asadi, H.; Harrysson, F.; Hörling, P.; Kamrani, F.; Kylesten, B.; Linderhed, A.; Moradi, F.; Sjöberg, E. Real-Time Simulation Supporting Effects-Based Planning 2008–2010—Final Report; Swedish Defence Research Agency: Stockholm, Sweden, 2010. [Google Scholar]
- Cioppa, T.M.; Lucas, T.W.; Sanchez, S.M. Military Applications of Agent-based Simulations. In Proceedings of the 2004 Winter Simulation Conference, Washington, DC, USA, 5–8 December 2004; Ingalls, R.G., Rossetti, M.D., Smith, J.S., Peters, B.A., Eds.; Institute for Electrical and Electronic Engineers: Piscataway, NJ, USA, 2004; pp. 171–180. [Google Scholar]
- Kleijnen, J.P.C.; Sanchez, S.M.; Lucas, T.W.; Cioppa, T.M. A user’s guide to the brave new world of designing simulation experiments. Inf. J. Comput. 2005, 17, 263–289. [Google Scholar] [CrossRef]
- Sanchez, S.M. Robust design: Seeking the best of all possible worlds. In Proceedings of the 2000 Winter Simulation Conference, Orlando, FL, USA, 10–13 December 2000; Joines, J.A., Barton, R.R., Kang, K., Fishwick, P.A., Eds.; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2000; pp. 69–76. [Google Scholar]
- Sanchez, S.M.; Lucas, T.W. A two-phase screening procedure for simulation experiments. In Proceedings of the 2005 Winter Simulation Conference, Orlando, FL, USA, 4–7 December 2005; Kuhl, M.E., Steiger, N.M., Armstrong, F.B., Joines, J.A., Eds.; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2005; pp. 223–230. [Google Scholar]
- Sanchez, S.M.; Sanchez, P.J. Very large fractional factorial and central composite designs. ACM Trans. Model. Comput. Simul. 2005, 15, 362–377. [Google Scholar] [CrossRef]
- Sanchez, S.M.; Wan, H. Work smarter, not harder: A tutorial on designing and constructing simulation experiments. In Proceedings of the 2012 Winter Simulation Conference, Berlin, Germany, 9–12 December 2012; Laroque, C., Himmelspach, J., Pasupathy, R., Rose, O., Urmacher, A.M., Eds.; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2012. [Google Scholar]
- Sanchez, S.M.; Moeeni, F.; Sanchez, P.J. So many factors, so little time Simulation experiments in the frequency domain. Int. J. Prod. Econ. 2006, 103, 149–165. [Google Scholar] [CrossRef]
- Sanchez, S.M.; Wan, H.; Lucas, T.W. Two-phase screening procedure for simulation experiments. ACM Trans. Model. Comput. Simul. 2009, 19. [Google Scholar] [CrossRef]
- Sanchez, S.M.; Lucas, T.W.; Sanchez, P.J.; Nannini, C.J.; Wan, H. Designing Large Scale Simulation Experiments, with Applications to Defense and Homeland Security; Hinkelmann, K., Ed.; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Sanchez, S.M. Better than a petaflop: The power of efficient experimental design. In Proceedings of the 2008 Winter Simulation Conference, Miami, FL, USA, 7–10 December 2008; Hill, R.R., Mönch, L., Rose, O., Jefferson, T., Fowler, J.W., Mason, S.J., Eds.; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2008; pp. 73–84. [Google Scholar]
- Lucas, T.W.; Sanchez, S.M.; Sanchez, P.J.; Law, A.; Seagren, C.; McDonald, M.L.; Upton, S.C. The Joint Strike Fighter Program’s Integrated Training Center (ITC) Model: Supporting Model Verification and Validation and Improving Analysis; Naval Postgraduate School: Monterey, CA, USA, 2012. [Google Scholar]
- McDonald, M. A Brief Introduction to Analyzing the Result of Data Farming: Top Ten Questions to Ask of Your Experiment Results; Naval Postgraduate School: Monterey, CA, USA, 2010. [Google Scholar]
- Meyer, T.; McDonald, M.; Upton, S.; Middleton, D.; Holland, T.; Lewis, K.; Schaub, H.; Freire, F.; Bouwens, C. Applying social network analysis to data farming of agent-based models. In Proceedings of the International Data Farming Workshop 20, Monterey, CA, USA, March 2010; Naval Postgraduate School: Monterey, CA, USA, 2010. [Google Scholar]
- Meyer, T.; Pfeiffer, V.; Luotsinen, L.; Silwood, N.; Moore, T. Using social network analysis to enhance data farming analysis. In Proceedings of the International Data Farming Workshop 23, Team 6 Outbrief, Riihimäki, Finland, 23 September 2011.
- Meyer, T. Command and control and Project Albert: Red Orm and modeling a common operating picture (COP). In Maneuver Warfare Science; Horne, G., Johnson, S., Eds.; USMC Combat Development Command: Quantico, VA, USA, 2001. [Google Scholar]
- Brandstein, A.; Horne, G. Asymmetric evolutions and revolutions in military analysis. In The Cornwallis Group II: Analysis for and of the Resolution of Conflict, The Canadian Peacekeeping Press of the Lester B; Pearson Canadian International Peacekeeping Training Centre: Cornwallis Park, NS, Canada, 1998. [Google Scholar]
- Henscheid, Z.; Middleton, D.; Bitinas, E. Pythagoras: An Agent-Based Simulation Environment. In Proceedings of the International Data Farming Workshop 13, Scheveningen, The Netherlands, 2006.
- Brandstein, A. Operational synthesis: Supporting the maneuver warrior. In Proceedings of the 2nd Annual Defense Planning & Analysis Society Symposium, Rosslyn, VA, USA, 1999.
- Horne, G.; Schwierz, K. Data Farming Around the World. In Proceedings of the 2008 Winter Simulation Conference, Miami, FL, USA, 7–10 December 2008.
- Horne, G.; Schwierz, K. Data Farming Around the World Overview. In Proceedings of the The Cornwallis Group XIV: Analysis of Societal Conflict and Counter Insurgency, Vienna, Austria, 6–9 April 2009.
- Lawler, M. Data Farming Cultivates New Insights; Signal, International Journal of the Armed Forces Communications and Electronics Association: Fairfax, VA, USA, 2005. [Google Scholar]
- McDonald, M. The use of agent-based modeling and data farming for planning system of systems tests in joint environments. In Proceedings of the 76th Military Operations Research Society Symposium, New London, CT, USA, June 2008.
- McDonald, M. Training Tutorial: A Brief Introduction to Analyzing the Result of Data Farming: Top Ten Questions to Ask of Our Simulation Results. In Presented at MSG-088 Meeting 2, Alexandria, VA, USA, December 2010.
- Meyer, C.; Davis, S. It’s Alive; Ernst and Young Center for Business Innovation: Cambridge, MA, USA, 2003. [Google Scholar]
- Meyer, T. Training Tutorial: Visualization and Data Farming. In Presented at MSG-088 Meeting 2, Alexandria, VA, USA, December 2010.
- Sanchez, S.; Lucas, T. Tutorial: Exploring the World of Agent-based Simulations: Simple models, Complex Analyses. In Proceedings of the 2002 Winter Simulation Conference, San Diego, CA, USA, 8–11 December 2002; Yucesan, E., Chen, C.H., Snowdon, J.L., Charnes, J.M., Eds.; pp. 116–126.
- Sanchez, S. Training Tutorial: Breakthroughs in Simulation Studies: Making Our Models Work for Us. In Presented at MSG-088 Meeting 2, Alexandria, VA, USA, December 2010.
- Schwierz, K. Chronicle of data farming: The story of success. In Proceedings of the IDFW 16, Monterey, CA, USA, July 2008.
- Upton, S. User’s Guide: OldMcData, the Data Farmer, Version 1.0; United States Marine Corps Project Albert: Quantico, VA, USA, 2004. [Google Scholar]
- Choo, C.S.; Ng, E.C.; Ang, C.K.; Chua, C.L. Systematic data farming: An application to a military scenario. In Proceedings of Army Science Conference 2006, Orlando, FL, USA, 27–30 November 2006.
- Vieira, H., Jr.; Sanchez, S.M.; Kienitz, K.H.; Belderrain, M.C.N. Improved efficient, nearly orthogonal, nearly balanced mixed designs. In Proceedings of the 2006 Winter Simulation Conference, Monterey, CA, USA, 3–6 December 2006; Jain, S., Creasey, R.R., Himmelspach, J., White, K.P., Fu, M., Eds.; Institute of Electrical and Electronics Engineers, Inc.: Piscataway, NJ, USA, 2011. [Google Scholar]
- Lappi, E.; Åkesson, B.M.; Mäki, S.; Pajukanta, S.; Stenius, K. A model for simulating medical treatment and evacuation of battle casualties. In Proceedings of the 2nd Nordic Military Analysis Symposium, Stockholm, Sweden, 17–18 November 2008.
- Hämäläinen, J.S. Using Sandis Software Combined with Data Farming to Analyze Evacuation of Casualties from the Battlefield. In the Proceedings of the 4th International Sandis Workshop; Defence Forces Technical Research Centre: Riihimäki, Finland, 2011. [Google Scholar]
- Åkesson, B.; Pettersson, V. Mathematical Modeling and Simulation of Medical Treatment and Evacuation of Battle Casualties. In the Proceedings of the 4th International Sandis Workshop; Defence Forces Technical Research Centre: Riihimäki, Finland, 2011. [Google Scholar]
- Åkesson, B.; Horne, G.; Mässeli, K.; Narayanan, F.; Pakkanen, M.; Shockley, J.; Upton, S.; Yildirim, Z.; Yigit, A. MSG-088 Data farming Case Study on Humanitarian Assistance/Disaster Relief. In the Scythe, Proceedings and Bulletin of the International Data Farming Community, Riihimäki, Finland, March 2012.
- Lappi, E. Computational Methods for Tactical Simulation. Ph.D. Thesis, National Defence University, Helsinki, Finland, 2012. [Google Scholar]

© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Horne, G.; Schwierz, K.-P. Summary of Data Farming. Axioms 2016, 5, 8. https://doi.org/10.3390/axioms5010008
Horne G, Schwierz K-P. Summary of Data Farming. Axioms. 2016; 5(1):8. https://doi.org/10.3390/axioms5010008
Chicago/Turabian StyleHorne, Gary, and Klaus-Peter Schwierz. 2016. "Summary of Data Farming" Axioms 5, no. 1: 8. https://doi.org/10.3390/axioms5010008
APA StyleHorne, G., & Schwierz, K.-P. (2016). Summary of Data Farming. Axioms, 5(1), 8. https://doi.org/10.3390/axioms5010008