1. Introduction
The complexity of statistical analysis increases even more when failures arise from multiple competing causes, a scenario central to the study of competing risks (CRs). CRs occur when there are different failure mechanisms, with each independently capable of causing the event of interest. This is particularly relevant in medical research, such as in studies investigating the outcomes of patients with lung cancer, where mortality can be the result of cancer itself or other underlying conditions. Similarly, in reliability studies of mechanical and electronic systems, failures may be attributed to various factors such as corrosion, vibration, or other environmental stresses. In recent years, analytical attention has increasingly focused on models that account for specific risk factors within the CRs framework, utilizing datasets that comprise failure times alongside indicators that specify the cause of failure. For a complete review of the CRs models, refer to [
1,
2].
Lifetime analysis is essential in various real-world applications, particularly in medical and engineering disciplines, as it helps to evaluate unit reliability distributions. Analyzing data from such studies requires selecting an appropriate lifetime distribution, which is a critical step. Ref. [
3] introduced the generalized linear exponential (GLE) distribution, which is highly beneficial, as it encompasses several well-known distributions as special cases. Moreover, the GLE distribution offers enhanced flexibility when handling complex real-life datasets. This distribution is advantageous for modeling failure behaviors that exhibit decreasing, increasing, or non-monotonic hazard rates, including the bathtub-shaped hazard function. Its ability to accurately capture complex failure patterns makes it a valuable tool in reliability engineering, epidemiological studies, and industrial quality control. Due to its adaptability, the GLE distribution is widely applicable in diverse areas such as biomedical survival studies; one of the recent applications of this distribution is presented in [
4], where a novel GLE CRs model called the additive generalized linear exponential model was developed to improve survival analysis. It was designed to handle complex risk scenarios in medical data, particularly in the context of blood cancer. The study focused on analyzing multiple risk factors that interact and compete to cause events such as remission, relapse, and treatment complications.
Across diverse domains, including biomedical research and industrial manufacturing, researchers often face the challenge of censored data, where the complete failure times of observed units are partially unknown. This issue is not merely a statistical hurdle, but a practical limitation arising from factors such as time constraints, ethical considerations, and financial implications. These challenges become particularly significant when dealing with high-value items or subjects of long duration. To address these limitations, specialized censoring schemes have been developed, with Type-I and Type-II censoring being among the most widely utilized approaches. In particular, the progressive Type-II right censoring (PT-IIRC) scheme has gained prominence because of its ability to optimize the utilization of time and resources while maintaining the validity of experimental results.
The analysis of lifetime models under various censoring schemes in the presence of CRs has been extensively explored in the literature. Numerous researchers have contributed to this field by developing statistical methodologies for parameter estimation, reliability analysis, and optimal censoring strategies. For example, but not limited to this alone, Ref. [
5] investigated CRs data under progressive Type-II censoring. The study assumed independent exponential failure distributions and derived maximum likelihood estimators and uniformly minimum variance unbiased estimators for failure rates. The exact distributions of the estimators were obtained, and hypothesis testing frameworks were developed. Bayesian estimation was performed using inverse gamma priors, and confidence intervals were constructed using exact, asymptotic, and bootstrap-based methods. The performance of the estimators was evaluated using Monte Carlo simulations and real-world data analysis. Extensions to Weibull models and dependent causes of failure were also discussed. Ref. [
6] introduced a Type-II progressively hybrid censoring scheme for CRs data, where the experiment terminates at a prespecified time. The study developed likelihood-based inference to estimate unknown parameters under the assumption that failure times follow independent exponential distributions. The results demonstrated that the proposed scheme is effective in reducing experimental cost and time while maintaining statistical efficiency. Ref. [
7] investigated parameter estimation within CRs models, assuming that failure causes follow generalized exponential distributions. Their work specifically addressed issues associated with incomplete and censored data, which are prevalent in reliability analysis. This contribution improved CRs modeling by introducing more flexible failure time distributions and advancing statistical estimation methodologies. Ref. [
8] analyzed the problem of progressively Type-II censored CRs data under the Weibull distribution. The study assumes that failure times are independent and follow Weibull distributions with a common shape parameter but different scale parameters. The study discussed various optimality criteria and proposed selected optimal progressive censoring plans. Ref. [
9] developed inference methods for CRs models involving multiple failure causes and censored data. Their framework incorporated both complete and right-censored observations by modifying the likelihood function to handle partially observed failure times. This enabled the estimation of model parameters under exponential, Weibull, and Chen distributions, enhancing applicability to real-world reliability and survival data. Ref. [
10] examined a CRs model under progressively Type-II censored data, assuming that failure times follow Lomax distributions. Maximum likelihood estimators were derived for the distribution parameters, and the expected Fisher information matrix was computed. The study also discussed optimal censoring plans based on Fisher information criteria, showing that the optimal censoring scheme depends on the specific parameterization of the Lomax distribution. Ref. [
11] proposed parametric methods for analyzing CRs data under interval censoring, emphasizing direct modeling of cumulative incidence functions using Gompertz distributions. Their framework addressed mixed and independent inspection processes and was validated using human immunodeficiency virus (HIV) transmission data, highlighting the importance of proper handling of interval censoring for reliable inference. Ref. [
12] examined statistical inference procedures for CRs models under hybrid censoring schemes, utilizing Cox’s latent failure time framework. Their model assumes two independent causes of failure, with latent lifetimes following Weibull distributions that share a similar shape parameter but have different scale parameters. A key aspect of their analysis is the treatment of Type-I hybrid censoring, where the experiment was terminated either upon observing a prespecified number of failures or reaching a predefined time limit, whichever occurred first. This censoring structure leads to a partially observed phenomenon. Ref. [
13] studied parameter estimation in CRs models under an adaptive progressive Type-II censoring scheme, assuming exponential lifetimes. The study addressed the practical complication of unknown failure causes and developed both maximum likelihood and Bayesian estimators. Exact and asymptotic confidence intervals were derived, and simulation results confirmed the efficiency of the proposed methods, which were further validated using real data applications. Ref. [
14] investigated CRs data under a generalized progressive hybrid censoring scheme, assuming exponential lifetimes and developing both classical and Bayesian inferential procedures. In contrast, Ref. [
15] proposed a CRs model based on Kumaraswamy distributions within progressively Type-II censored data. Similarly, Ref. [
16] examined the Rayleigh distribution under the same censoring framework. More recently, Ref. [
17] examined the Bayesian inference of Weibull distribution parameters under progressively Type-II censored CRs data with binomial removals. The study assumed that failure times follow a Weibull distribution and derived Bayes estimators under both symmetric and asymmetric loss functions. Ref. [
18] considered CRs models assuming Chen-distributed failure times, with shared shape and distinct scale parameters, also under progressive Type-II censoring. Ref. [
19] analyzed the statistical inference of the weighted exponential distribution in the context of progressively Type-II censored CRs data. The study assumed that latent failure causes follow independent weighted exponential distributions with different parameters. Ref. [
20] studied the estimation of unknown parameters, survival, and hazard functions in Weibull models under adaptive progressively Type-II censored CRs data. The study considered independent and dependent CRs, where failure causes followed Weibull distributions with different scale and shape parameters. The study examined the expected experimentation time and extended the model to the case of dependent failure modes using the Marshall–Olkin bivariate Weibull distribution. Ref. [
21] analyzed the statistical inference and optimal censoring scheme for a CRs model under progressively Type-II censored data from the generalized Rayleigh distribution. Ref. [
22] conducted a statistical inference study on a CRs model using adaptive progressively Type-II censored Gompertz life data, with applications in industrial and medical fields. Ref. [
23] proposed an accelerated competing failure model under progressively Type-II censored data, assuming that failure times follow inverse Weibull distributions. Their framework incorporated a constant-stress life testing setup with independent CRs and employed maximum likelihood estimation along with both asymptotic and bootstrap confidence intervals. Simulation studies and a real thermal stress dataset were used to evaluate the model’s performance, revealing the superiority of bootstrap intervals, especially for small sample sizes. Ref. [
24] performed a statistical inference study on a CRs model under the improved adaptive Type-II progressive censoring scheme. The study assumed that the lifetimes of competing causes of failure follow independent exponential distributions with different parameters. Ref. [
25] analyzed the statistical inference and optimal censoring scheme for a CRs model under Type-II progressive censoring. The study assumed that the lifetimes of CRs follow an inverted exponentiated Rayleigh distribution, which allows for a non-monotonic hazard function. Ref. [
26] examined the inference of CRs data under an improved adaptive Type-II progressive censoring scheme for Weibull lifetime models. The study employed the latent failure time model, in which failure times follow independent Weibull distributions with a common shape parameter and distinct scale parameters. Ref. [
27] developed a CRs model under progressively Type-II censored data with random removals, assuming that the lifetimes follow the generalized power half-logistic geometric distribution. Their work incorporates binomial-based censoring schemes and derives both maximum likelihood and Bayesian estimators using Markov Chain Monte Carlo methods. The model addresses flexible hazard structures, and simulation studies confirmed the effectiveness of the proposed estimation methods. A real-data application further demonstrated the model’s practical relevance in reliability analysis. Ref. [
28] studied parametric inference for lifetime models with CRs under middle censored data. Assuming that latent failure times follow independent Burr-XII distributions, they derived maximum likelihood estimators and asymptotic confidence intervals using the observed Fisher information.
The recent surge of studies addressing CRs models under PT-IIRC schemes has significantly enriched the literature on lifetime data analysis. Researchers have explored various parametric distributions such as the exponential, Weibull, Lomax, Kumaraswamy, and Rayleigh models, utilizing both frequentist and Bayesian estimation techniques. These models have been applied in various real-world contexts, including medical diagnostics, industrial reliability, and genomic data analysis. The frequent inclusion of causes of masked failure, random removal, and adaptive censoring further underscores the growing complexity and practical relevance of these studies.
Although various studies have explored parametric models related to the generalized linear exponential submodels, such as the Weibull, Rayleigh, and exponential distributions, there appears to be an absence of research directly applying the generalized linear exponential distribution itself to CRs data, particularly under progressive censoring schemes. Its capacity to accommodate known, unknown, and mixed causes of failure in such contexts remains largely uninvestigated.
Furthermore, while estimation methods have been increasingly developed in the broader literature, a cohesive modeling framework that integrates multiple estimation strategies and validates their effectiveness using simulated and real-world data continues to present a valuable direction for further exploration.
In this study, we consider CRs data under PT-IIRC. The progressively Type-II right-censored sample can be described as follows: Consider a life-testing experiment in which n units are placed under observation following a predefined progressive censoring scheme, denoted by . Assume that there are M independent causes of failure that are known. The number of observed failure times, denoted by m, is predetermined such that .
At the time of the first observed failure, the
units are removed from the remaining
units. Subsequently, upon the occurrence of the second failure, additional
units are withdrawn from the remaining
units. This process continues iteratively until the occurrence of the
failure. At this stage, denoted as
, all remaining surviving units are removed from the experiment, marking its termination. The progressive censoring scheme
must satisfy the following constraint:
If , then the last removal is given by , which reduces the setup to the conventional Type-II right censoring scheme.
If , then , which corresponds to a complete sample.
For a comprehensive discussion on progressive censoring schemes, refer to [
29].
The primary goal of this study is to deliver the first comprehensive treatment of the GLE CRs model under the PT-IIRC pattern that arises routinely in long-term biomedical, biological, and industrial reliability studies. Integrating PT-IIRC with a parametric CRs framework goes beyond mathematical elegance: it mirrors real-world data collection practice, yields more efficient estimators, permits cost sensitive experimental designs, and provides a common analytic language across disparate application domains. Because progressive censoring records additional early and mid-time information, coupling it with the flexible GLE CRs model improves the identifiability of contrasting cause-specific hazard shapes. Moreover, in CRs settings, the withdrawal process may act preferentially on a single cause (e.g., patients removed owing to drug toxicity or machines retired by policy). The parametric formulation adopted here allows for formal testing of whether removal rates differ by latent cause, thereby strengthening validity checks and inference.
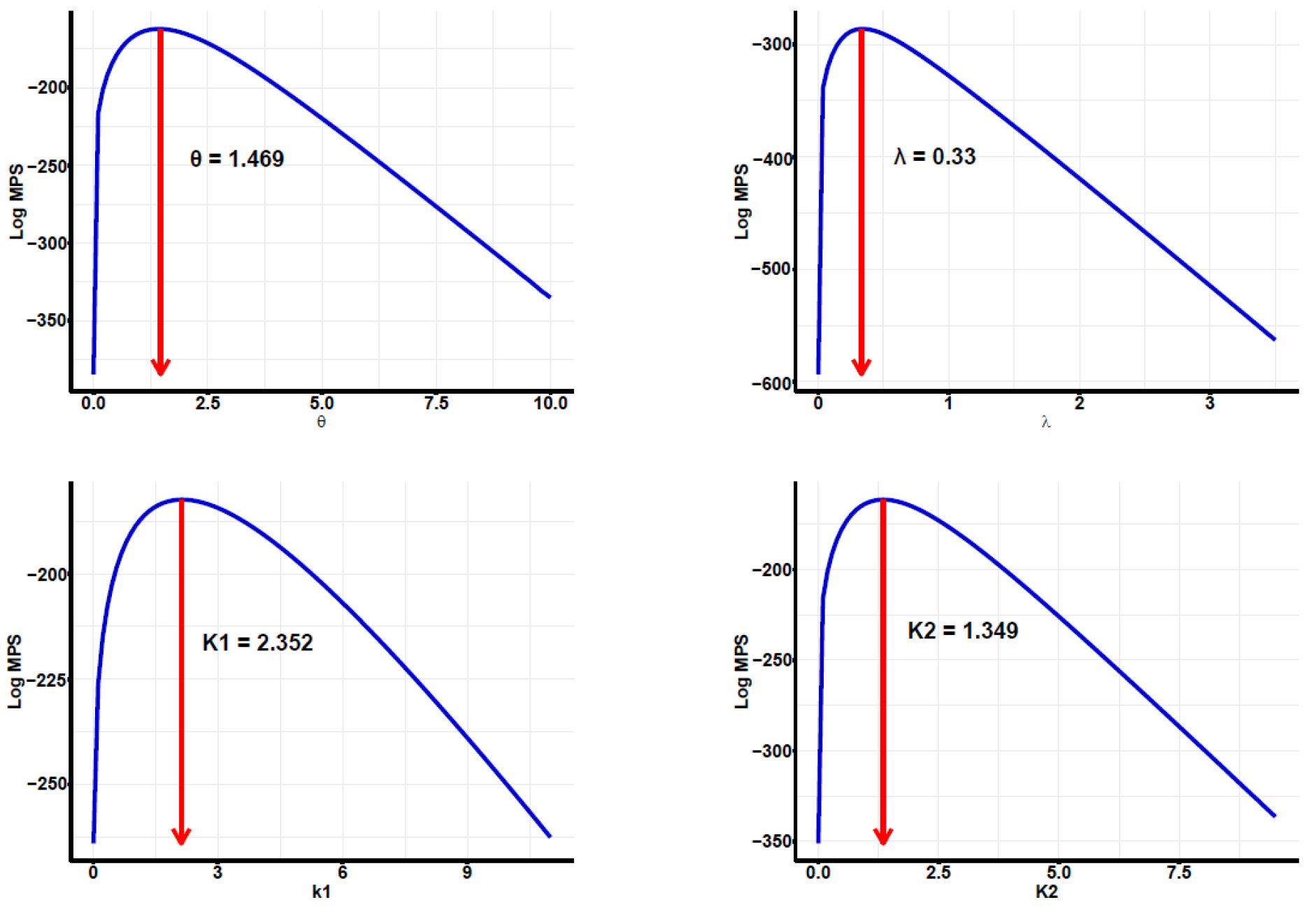
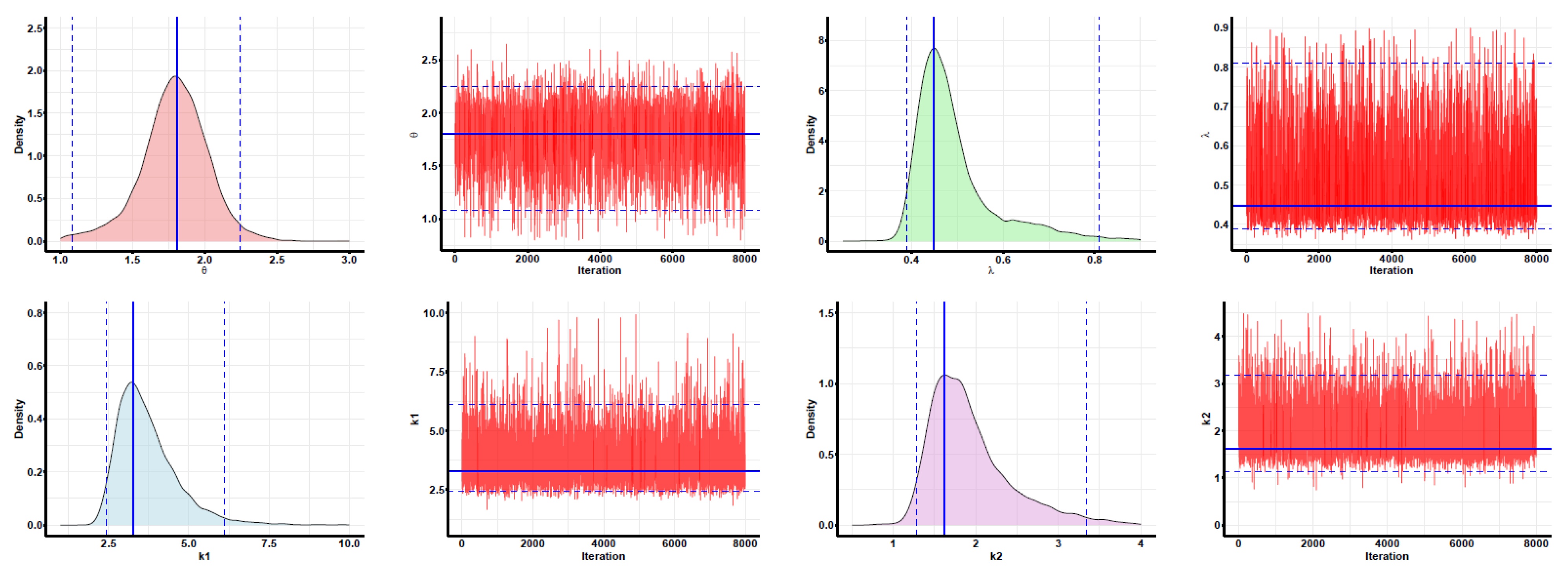
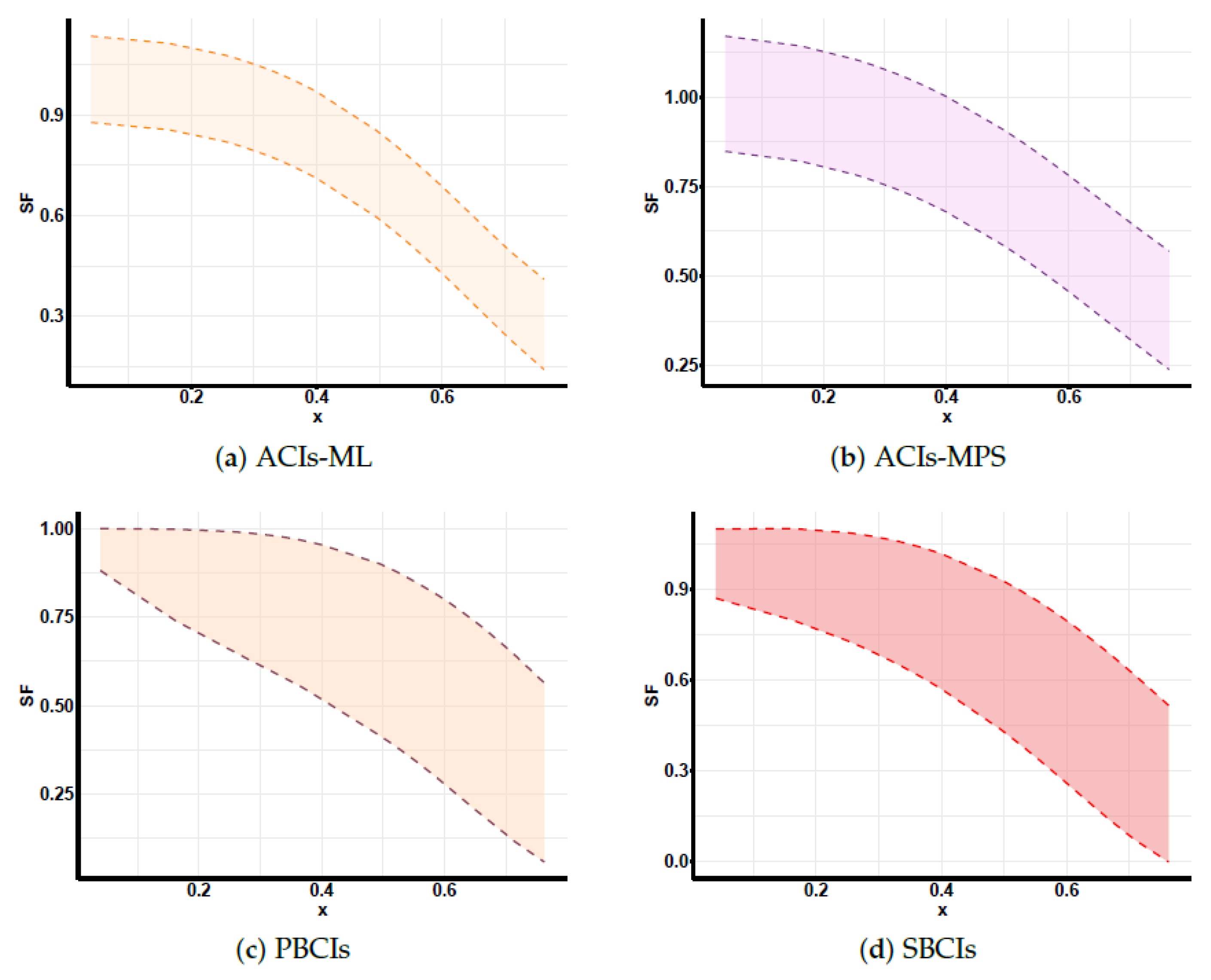
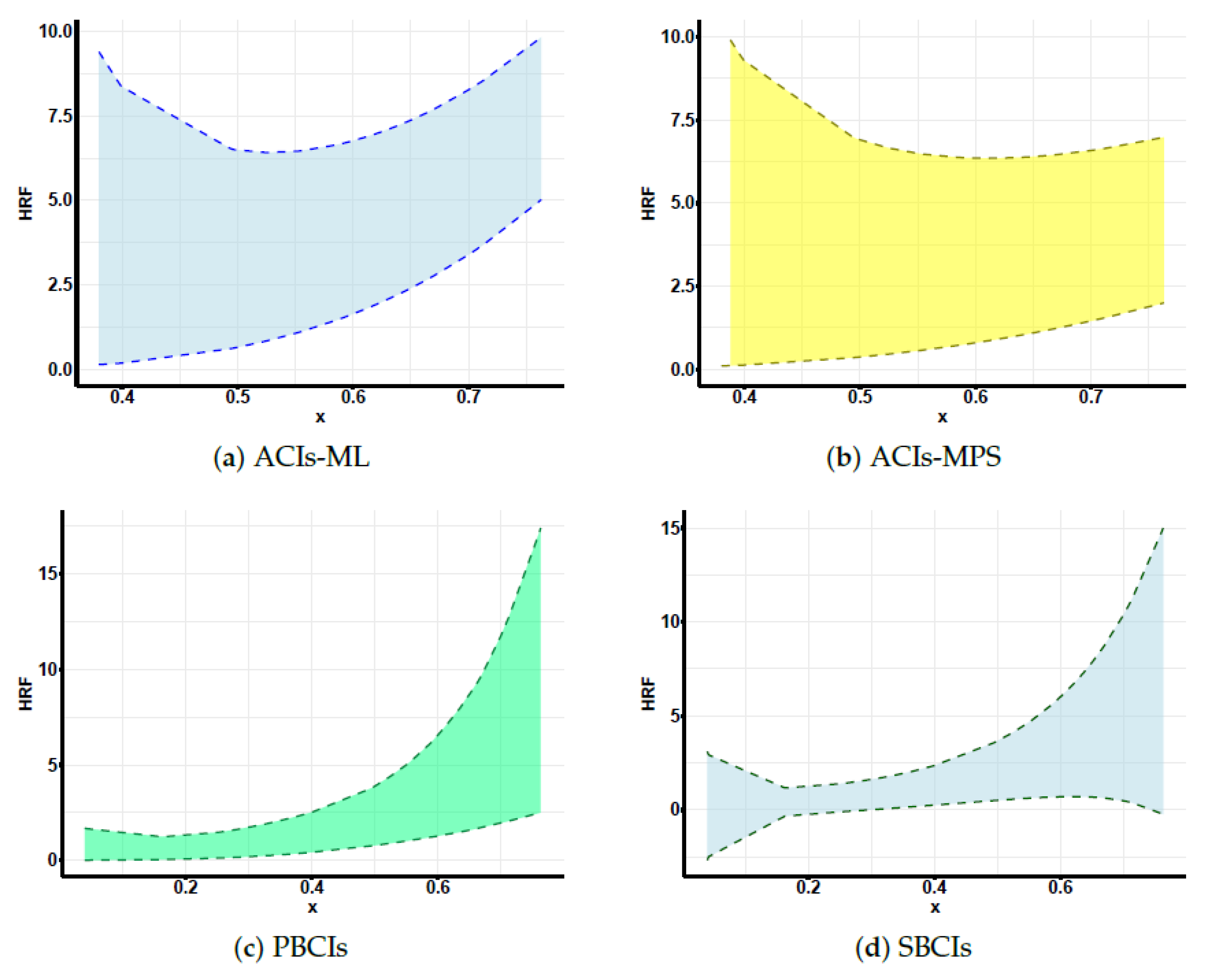
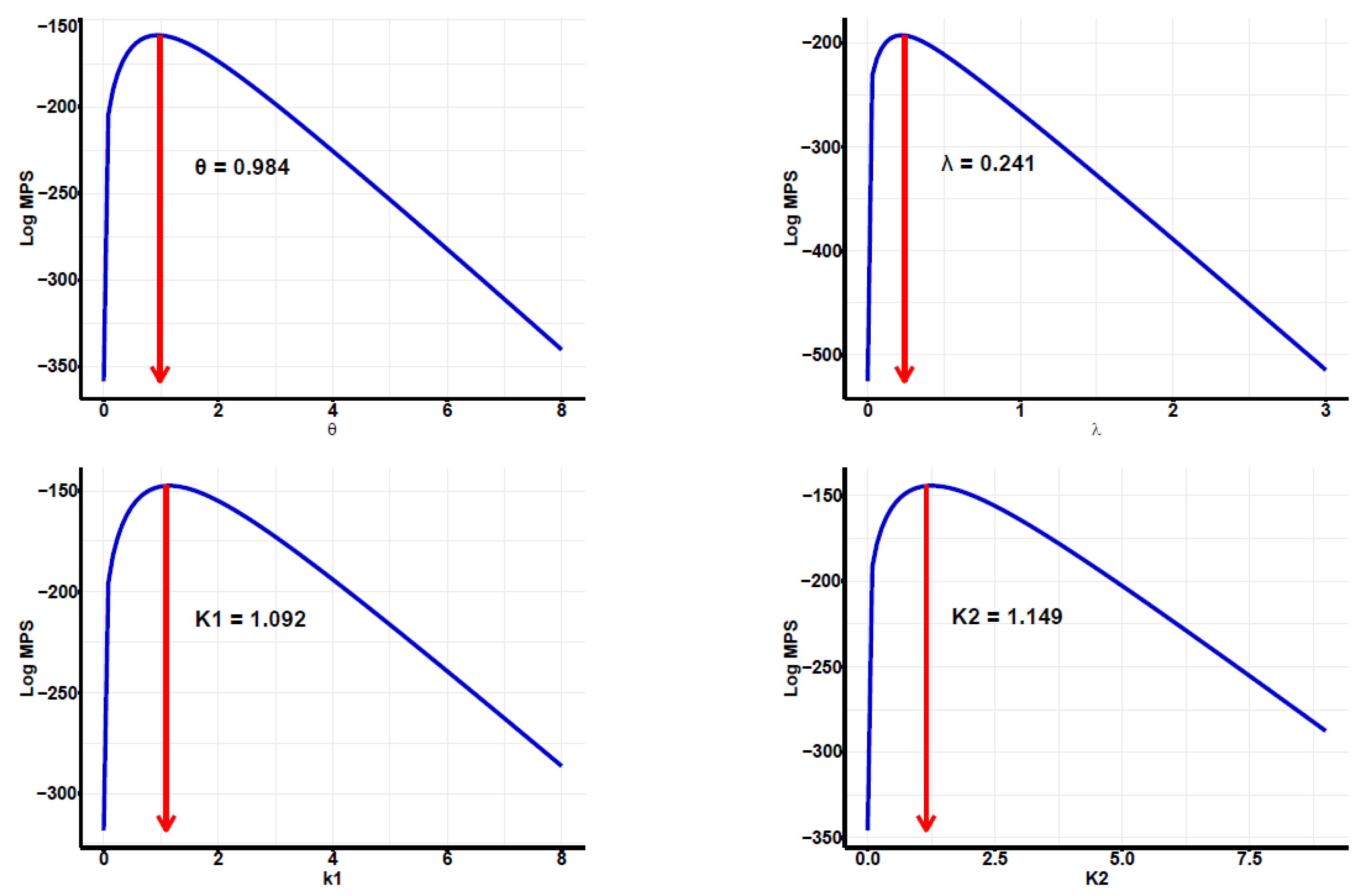
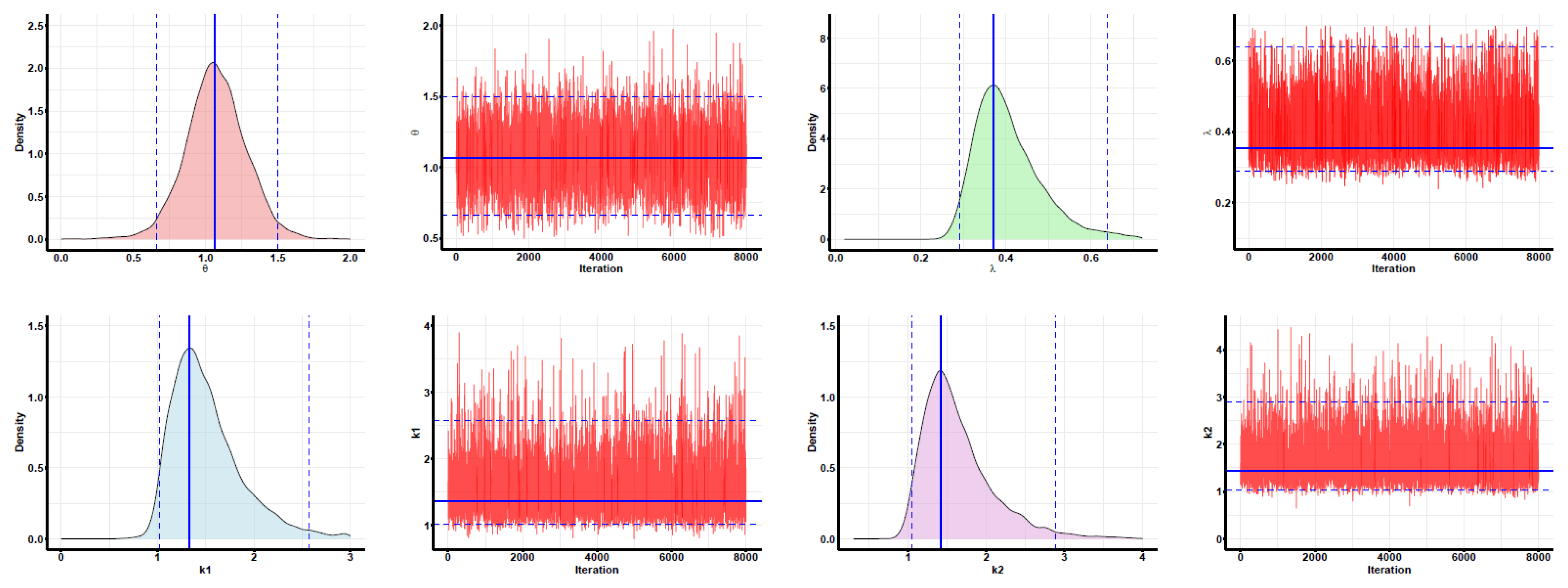
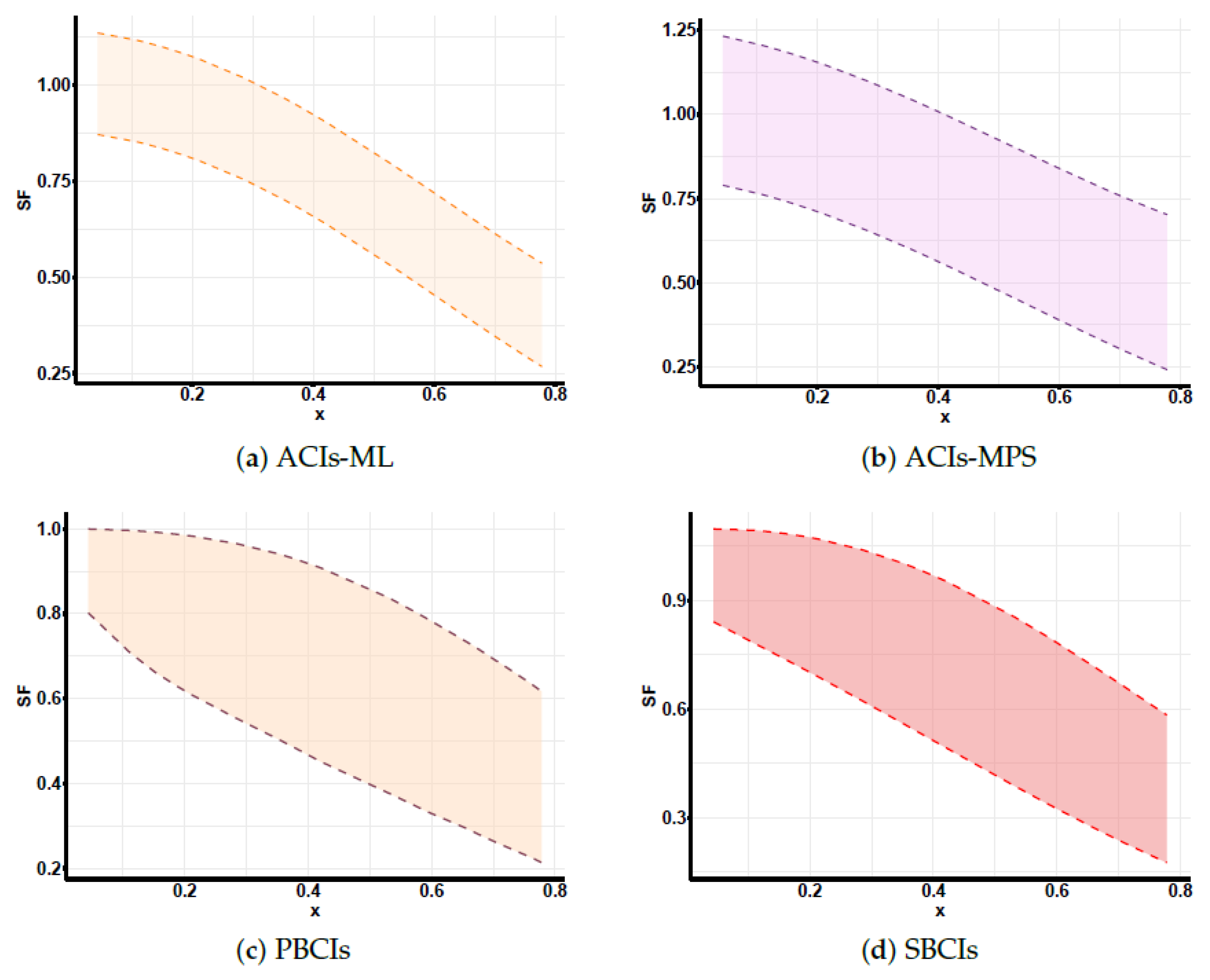
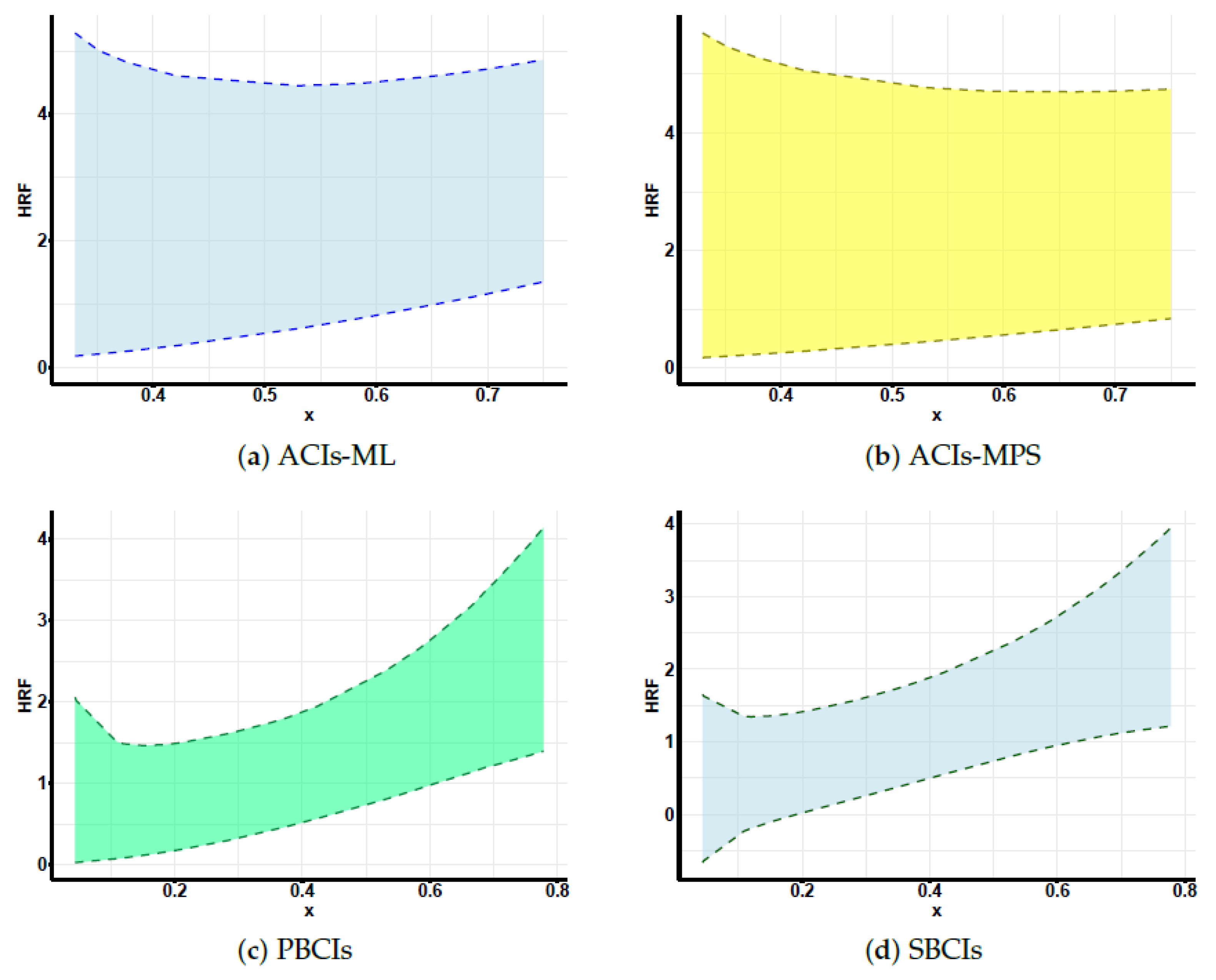
Developing maximum likelihood estimators (MLEs) and maximum product of spacing estimators (MPSEs): In addition, three distinct types of confidence intervals are developed: asymptotic confidence intervals (ACIs), percentile bootstrap confidence intervals (PBCIs), and studentized bootstrap confidence intervals (SBCIs). A Monte Carlo simulation is performed to evaluate and contrast the effectiveness of the proposed methods. Lastly, the proposed methods are applied to two real-world datasets for validation, with all analyses and computations performed using the R programming language to ensure accurate and efficient statistical processing.
The structure of the paper is as follows.
Section 2 provides a detailed description of the model and introduces the necessary notation. The maximum likelihood estimation of unknown parameters is discussed in
Section 3.
Section 4 presents the maximum product of spacing estimation method and its theoretical foundations.
Section 5 introduces the construction of bootstrap confidence intervals. A simulation study, along with its results and performance evaluation, is provided in
Section 6. In
Section 7, real-world datasets are analyzed to illustrate the practical applicability of the proposed methods. Finally, the study concludes with a summary of findings and potential future research directions in
Section 8.
2. Model Description and Notation
Consider a system with two independent failure causes (). Let and () represent the latent failure times associated with the two failure causes. Assume that these failure times are independent and identically distributed GLE distributions. Here, represents the latent failure time of the unit that corresponds to the cause of failure , where .
Each failure in the experiment can occur due to one of distinct causes. The failure mechanism is characterized as follows:
m represents the total number of observed failures.
denotes the total number of censored units.
The cause of the failure is identified using an indicator variable , where if the failure of is attributed to the risk of .
Thus, the number of observed failures associated with the
risk, denoted as
, is given by
where
, and
is an indicator function defined as
The progressive Type-II censored CRs (PT-IIRCCR) data structure is represented as
where
denote the observed failure times.
represent the corresponding causes of failure.
indicate the number of units removed from the experiment at each observed failure time.
Several special cases of this censoring mechanism warrant further discussion.
Under these assumptions, the survival function (SF) of
is expressed as
The cumulative distribution function (CDF) and the probability density function (PDF) of
are expressed as follows:
and its PDF is
The hazard rate function (HRF) is given by
Consider a reliability study involving identical
n units in a lifetime experiment, where each unit may fail due to one of two competing causes. The observed failure time for the
unit is given by
Using Equations (
2) and (
3), the CDF and PDF of
can be derived as follows:
and
where
represents the vector of model parameters, which is defined within the parameter space
, that is,
In the same way, the SF and HRF of
can be expressed as follows:
and
All items under study undergo similar conditions, whether patients or engineered components operate in the same external environment and are exposed to similar baseline stresses (temperature, workload, treatment protocol, etc.). We therefore adopt the rate parameters
and an acceleration term
that apply uniformly to every latent failure time. The different physical or biological mechanisms of failure are instead represented by the shape parameters
and
. Hence, the parsimonious four-parameter specification achieves better numerical stability and provides a clearer, mechanism-oriented interpretation.












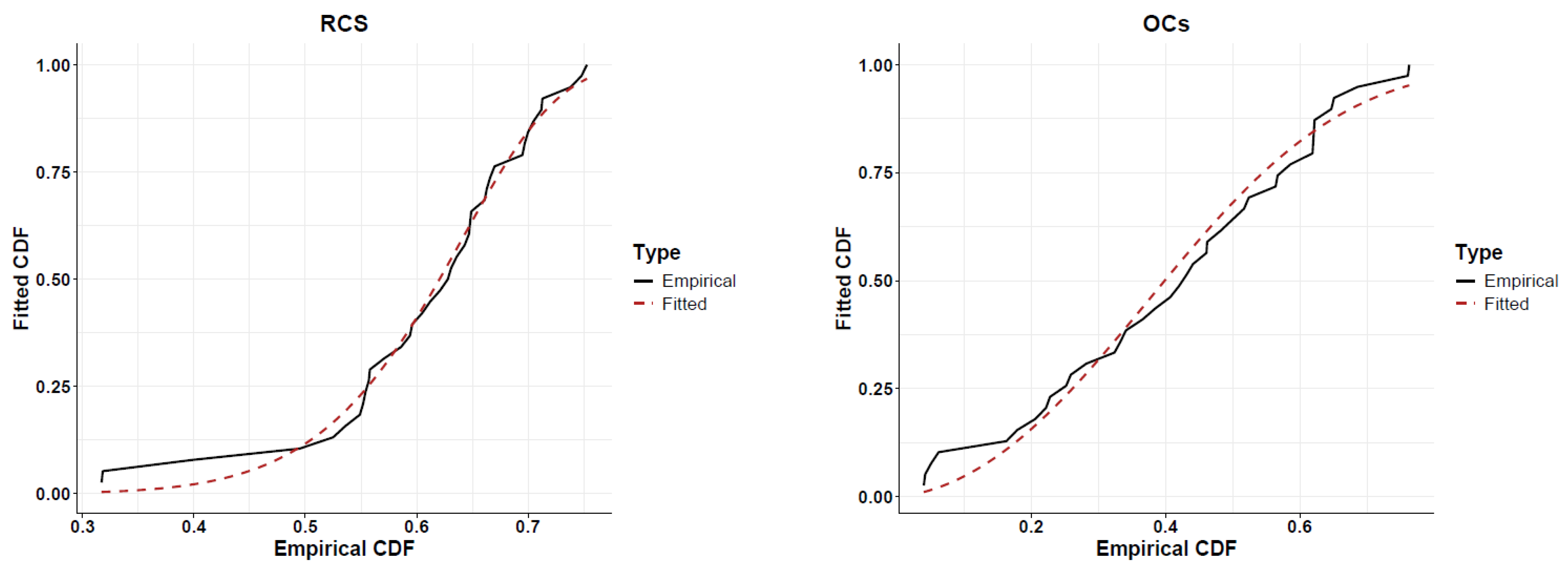
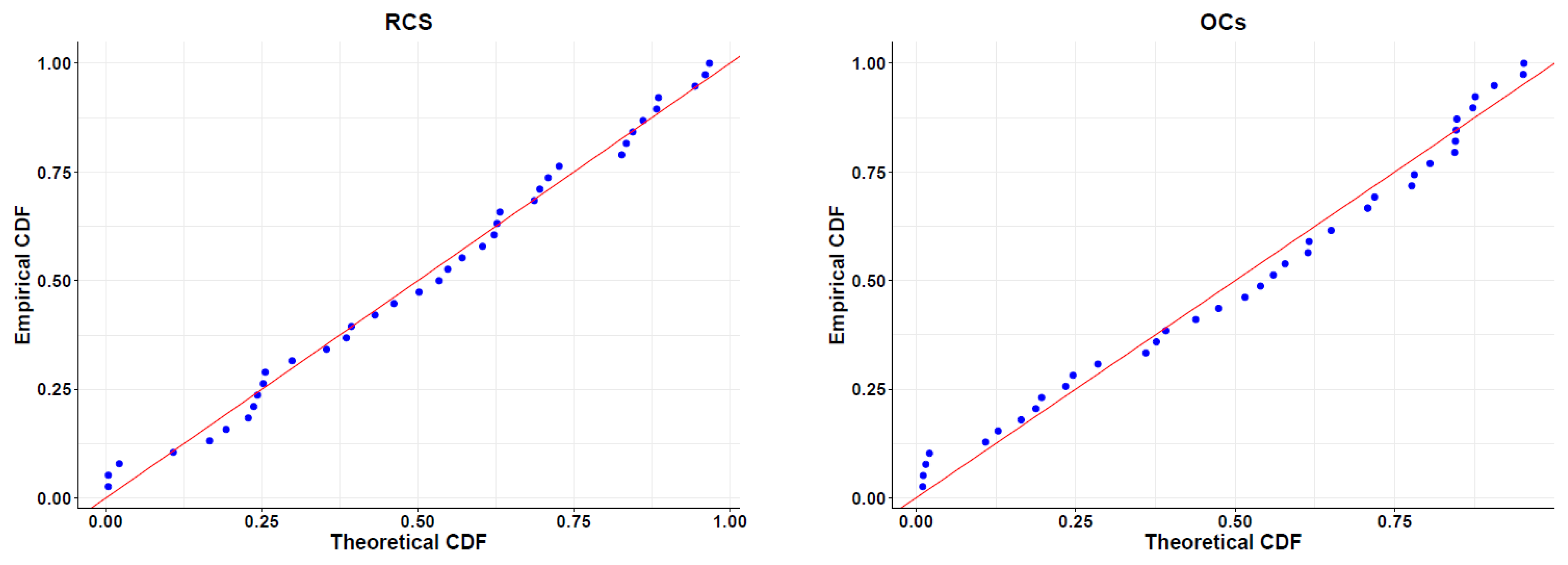
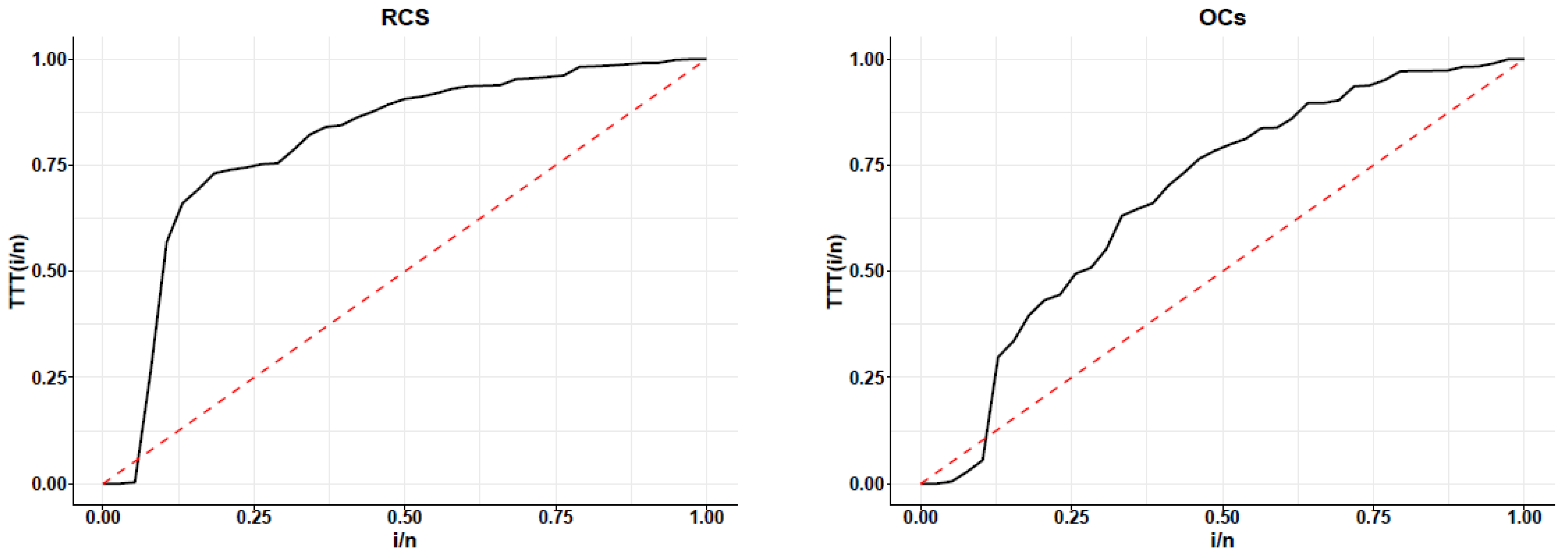
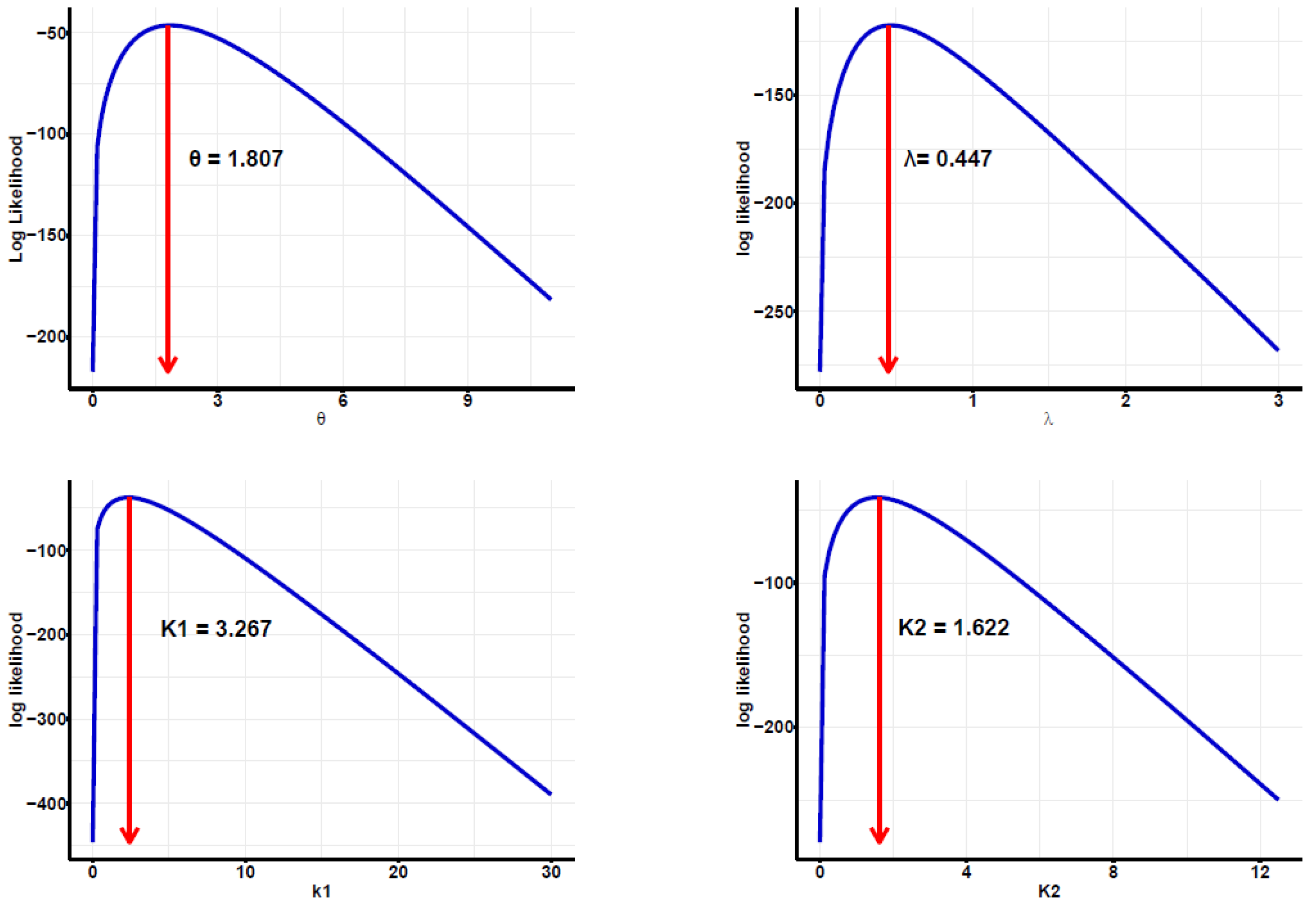
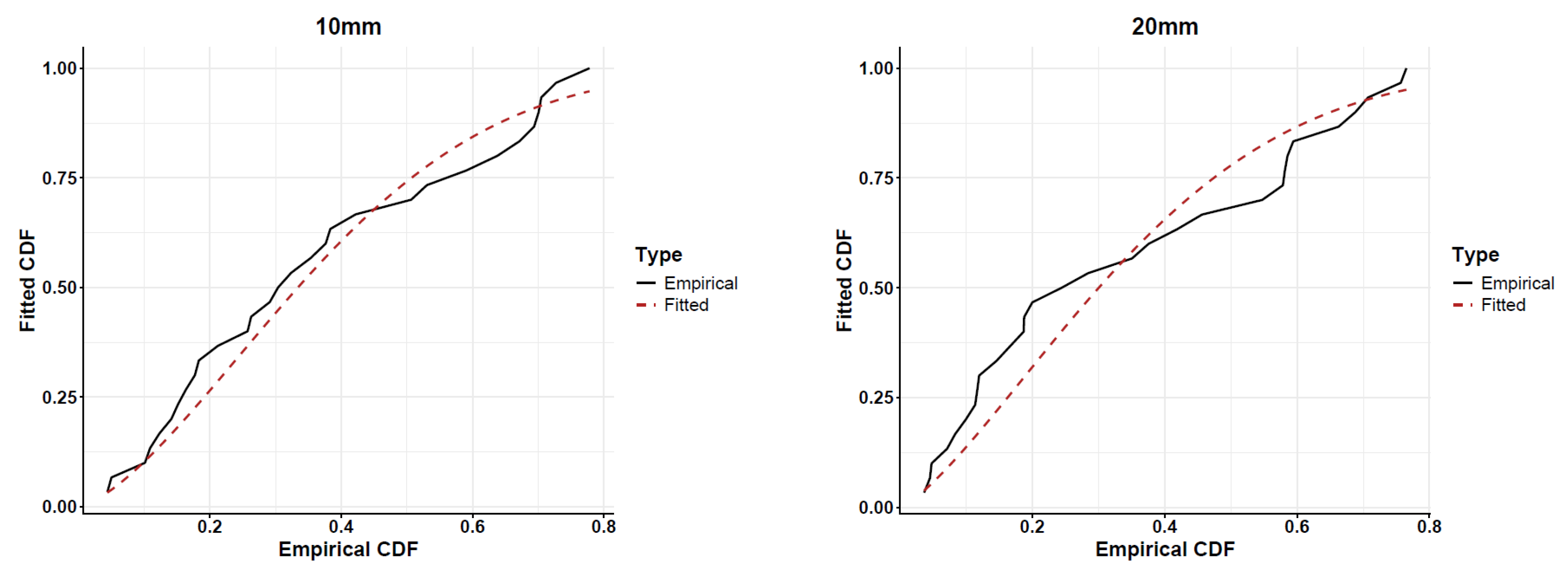
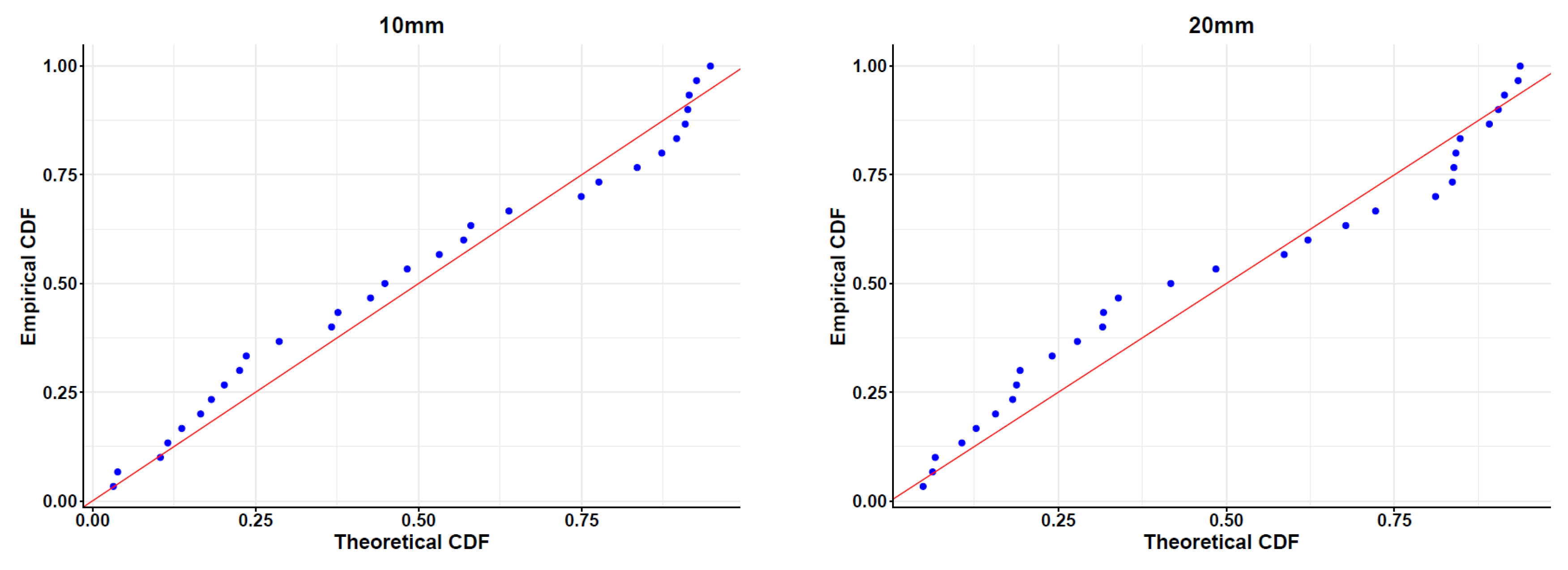
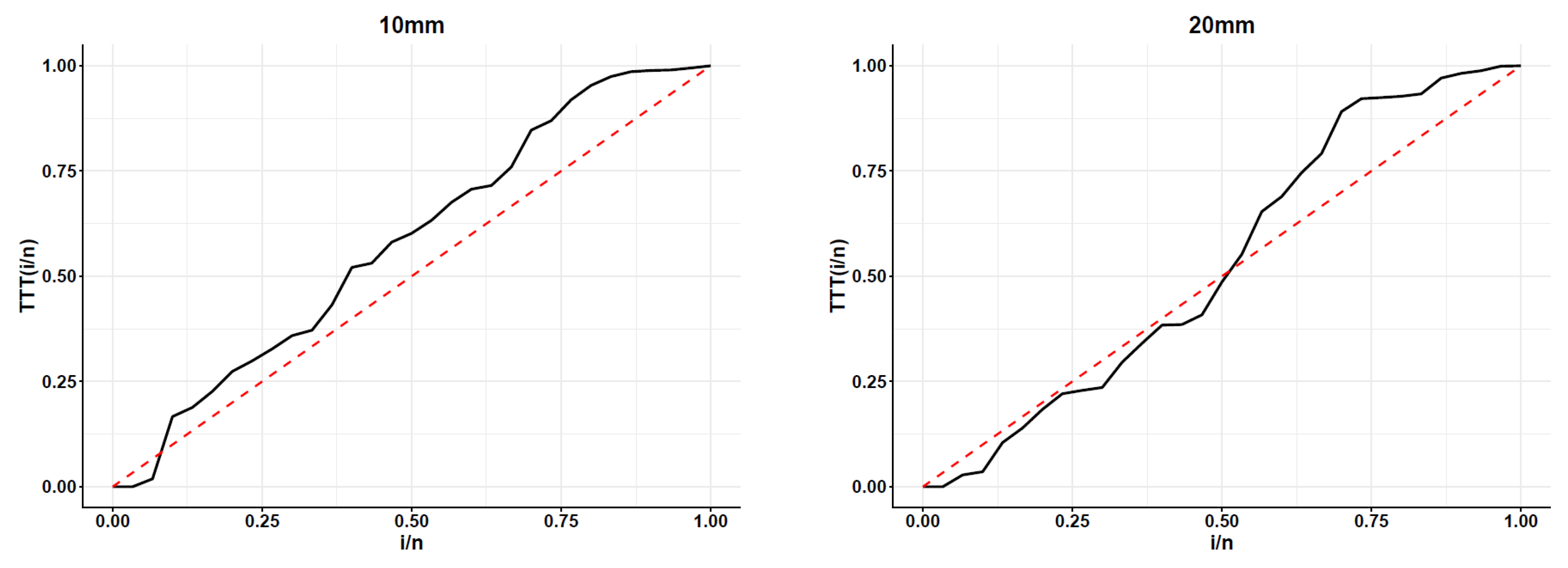
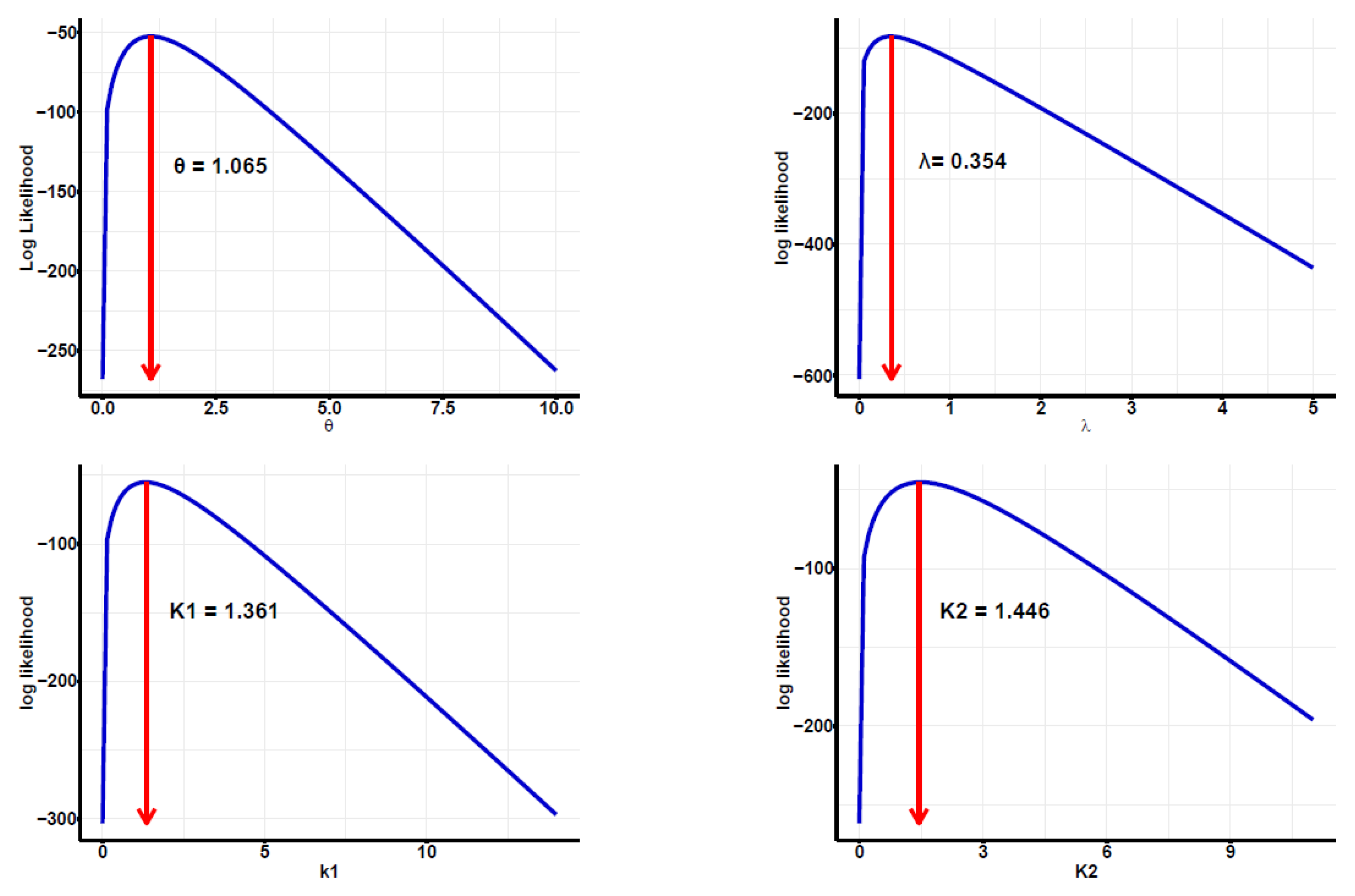

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}