3.1. Constructing the Fuzzy Concept Space
This section introduces a correlation coefficient matrix to construct the correlation similarity granule for achieving concept characterization.
Definition 2. Given a fuzzy formal context , for any , the correlation coefficient between and is defined as follows:where denotes the membership degree of object with respect to attribute , while represents the average membership degree of across the attribute set A. That is to say, . The value of explains the similarity degree between and . The pairwise correlation coefficients form a symmetric matrix Q, where quantifies the linear relationship between objects and . Meanwhile, this correlation coefficient matrix can be used to construct the correlation similarity granule. Definition 3. Given an FFDC , for any , the correlation similarity granule of object x is given bywhere β is a threshold and is the correlation similarity degree between x and y. Definition 4. Given an FFDC , where , for any , the fuzzy concept subspace about is denoted as follows:where β is a threshold and is the correlation similarity degree between x and y. Subsequently, we denote by the fuzzy concept space, where is named a fuzzy subspace of . It should be emphasized that comprehensive feature learning of each individual object serves as a prerequisite for achieving optimal classification performance. Then we propose the procedure of constructing the fuzzy concept space in Algorithm 1 with the time complexity of .
| Algorithm 1: Constructing fuzzy concept space (CFCS). |
![Axioms 14 00593 i001]() |
Example 1. Table 1 is an FFDC , where and . d is the decision attribute that partitions all objects into two classes, with and . The correlation coefficient matrix Q is computed as follows: Given , for the objects in decision class , we can have the correlation similarity granule , , , and . Next, fuzzy concept subspace .
For the objects in decision class , their correlation similarity granule and fuzzy concept subspace are as follows: , and . .
Table 1.
An FFDC.
| U | a1 | a2 | a3 | a4 | d |
|---|
| 0.7 | 0.3 | 0.4 | 0.5 | 1 |
| 0.1 | 0.8 | 0.5 | 0.9 | 1 |
| 0.3 | 0.5 | 0.6 | 0.7 | 1 |
| 0.4 | 0.3 | 0.4 | 0.4 | 1 |
| 0.6 | 0.4 | 0.3 | 0.9 | 2 |
| 0.3 | 0.5 | 0.6 | 0.4 | 2 |
| 0.2 | 0.5 | 0.4 | 0.3 | 2 |
| 0.1 | 0.7 | 0.8 | 0.8 | 2 |
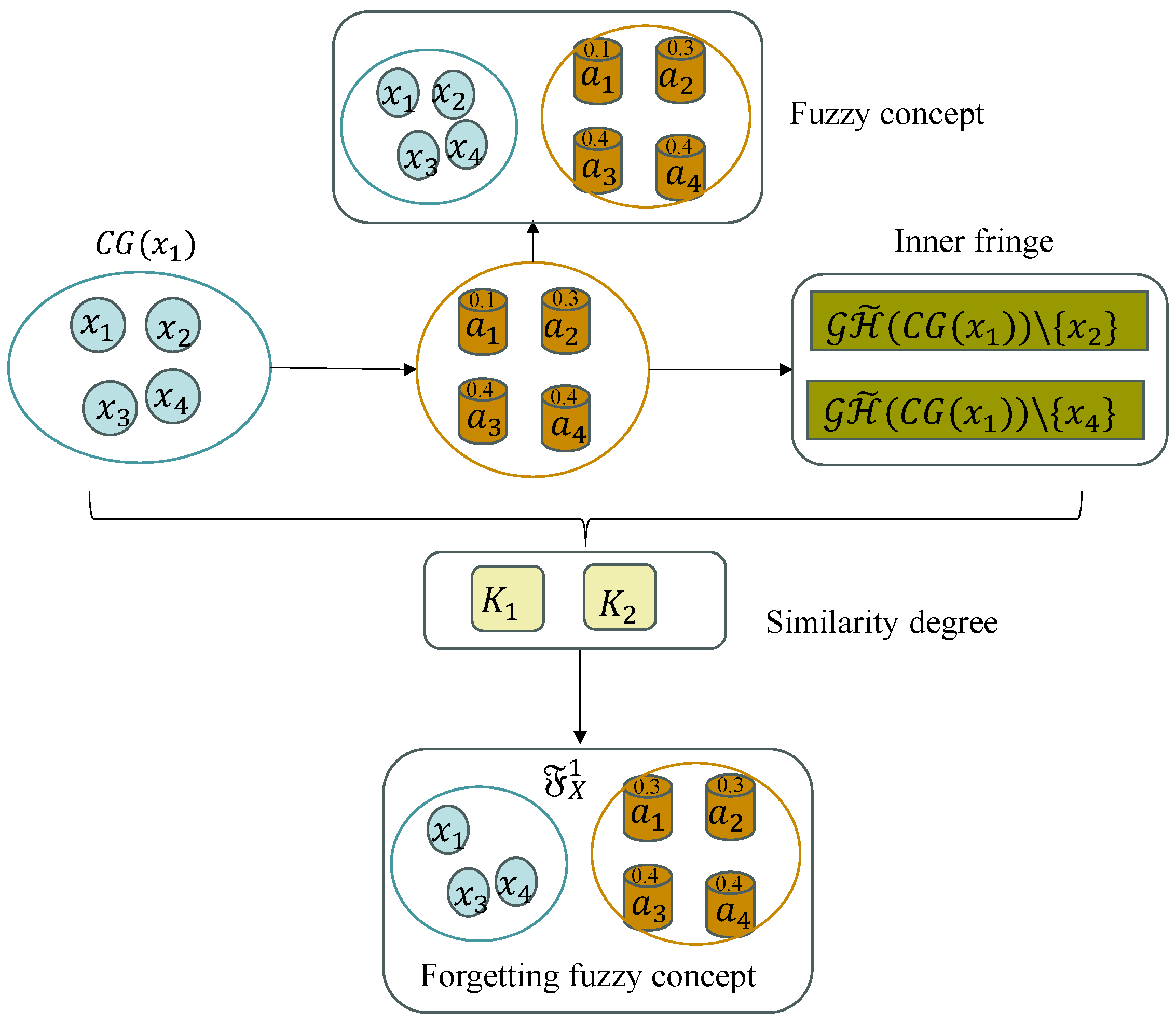
3.2. Constructing the Forgetting Fuzzy Concept Space
Section 3.1 discusses the construction process of the fuzzy concept space through the correlation similarity granule and a pair of cognitive operators
and
. However, since
, some of the objects in extent
may be forgotten because of knowledge forgetting.
Definition 5. Given an FFDC , for arbitrary , the inner fringe of X is denoted aswhere and for . Definition 5 introduces a method for forgetting the minimal object set that is proximate to a certain object in the extent . Then the above forgetting minimal object set can be represented by a Boolean matrix, shown as Proposition 1.
Proposition 1. Let be an FFDC. is an inner fringe of . Then, we know the following:where andfor . Proof. For any
,
means that
That is to say, for any any
, it implies that
. Hence, for any
, if
, then it is obvious that
. □
Proposition 2. Let be an FFDC. is an inner fringe of . For any , is a fuzzy concept.
Proof. It is obvious from Definition 1. □
In fact, there are multiple elements in . After applying knowledge forgetting, the obtained forgetting fuzzy concept is defined, which is maximally similar to fuzzy concept . For two concepts and , the similarity degree is .
Definition 6. Let be an FFDC. For , the collection of forgetting fuzzy concepts is defined as follows:where . In a fuzzy formal decision context and , there are some fuzzy subconcepts of ; that is, certain fuzzy concepts can be obtained from after knowledge forgetting through the inner fringe . From Proposition 2, for any , is a fuzzy concept obtained from after knowledge forgetting. It is obvious that . The higher the similarity between and , the higher the probability that objects in are forgotten.
In addition, given , the forgetting fuzzy concept subspace is denoted as . At the same time, the process of constructing the forgetting fuzzy concept space is shown as Algorithm 2, where is run in Steps 3–11, which can be taken in , and some unnecessary objects are reduced in Steps 12–25, which can be measured in , where means the zone of proximal development of an object. Hence, the time complexity of Algorithm 2 is .
Example 2. Continue with Example 1. With respect to class , we now discuss the forgetting fuzzy concept of in . In fact, , which implies that . Then we have two fuzzy concepts, and . Subsequently, and . Hence, we know that . Similarly, . Finally, we have the forgetting fuzzy concept subspace .
In addition, the forgetting fuzzy concept subspace in is .
Meanwhile, the process of learning the forgetting fuzzy concept is shown in
Figure 2.
| Algorithm 2: Constructing forgetting fuzzy concept space (CFFCS). |
![Axioms 14 00593 i002]() |
3.3. Fusing Concept
Mutual information exists among forgetting fuzzy concepts, manifested through their bidirectional influence mechanisms. In order to overcome the limitations of individual cognition and the incomplete cognitive environment [
28], we propose a new method to fuse concepts through the forgetting fuzzy concept space.
Definition 7. Given an FFDC , for a forgetting fuzzy concept subspace , if there exist forgetting fuzzy concepts , satisfying , then is regarded as the supremum fuzzy concept, and then the fusing forgetting fuzzy pseudo-concept is defined as follows:where n means the number of forgetting fuzzy concepts. Generally speaking, the fusing forgetting fuzzy concept space is denoted as , where , in which n is the number of pseudo-concepts in . The intent explicitly characterizes the magnitude of the pseudo-concept, in which the intents of subconcepts have been assigned different weights according to their corresponding extents. In other words, the greater the extent is, the larger the weight of its corresponding intent is. Finally, Algorithm 3 describes the clustering process of the fusing forgetting fuzzy concept space with the worst-case time complexity of .
| Algorithm 3: Cognitive process of fusing forgetting fuzzy concept space. |
![Axioms 14 00593 i003]() |
Example 3. Continuing to Example 2, according to Definition 7, fusing forgetting fuzzy concept spaces are represented as follows: It should be noted that there are two fusing forgetting fuzzy concepts in each decision class. It is evident that these concepts preserve the initial information while eliminating the redundant forgetting fuzzy concepts, which significantly enhances the efficiency of concept-cognitive learning.
3.4. Class Prediction
It should be noted that the class prediction of a testing sample is primarily determined based on the Euclidean distance between the testing sample and existing fuzzy concept clustering space [
27,
29,
30].
Definition 8. Let be a testing sample. is a new fuzzy concept; then the distance between and pseudo-concept in is defined as follows: As is well known, is the distance similarity. The smaller the distance value , the stronger the correlation between two fuzzy concepts. Consequently, class determination for a new sample can be achieved by computing their similarity. Algorithm 4 describes the class prediction with the time complexity of .
| Algorithm 4: Class prediction of testing sample. |
![Axioms 14 00593 i004]() |
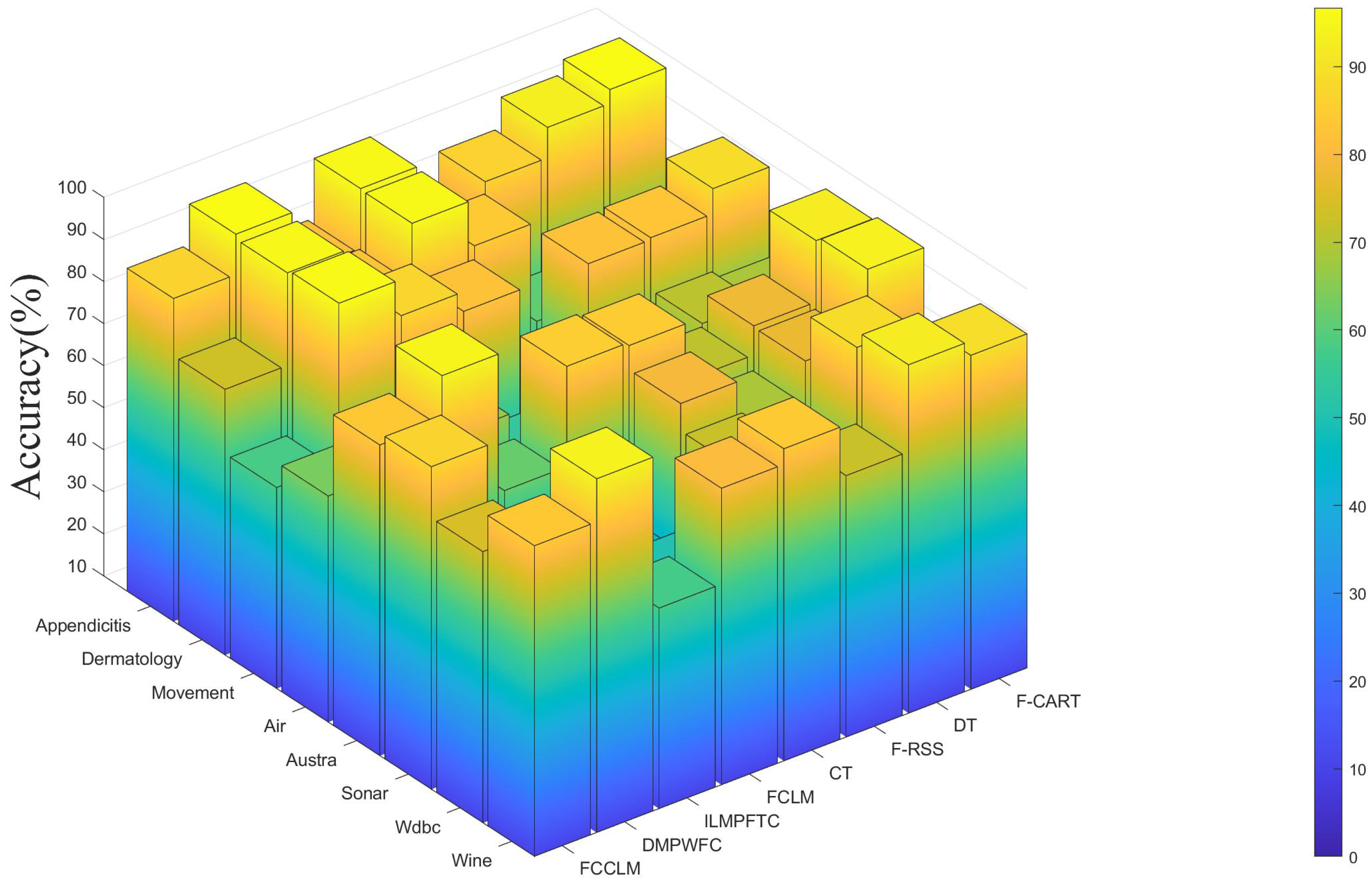
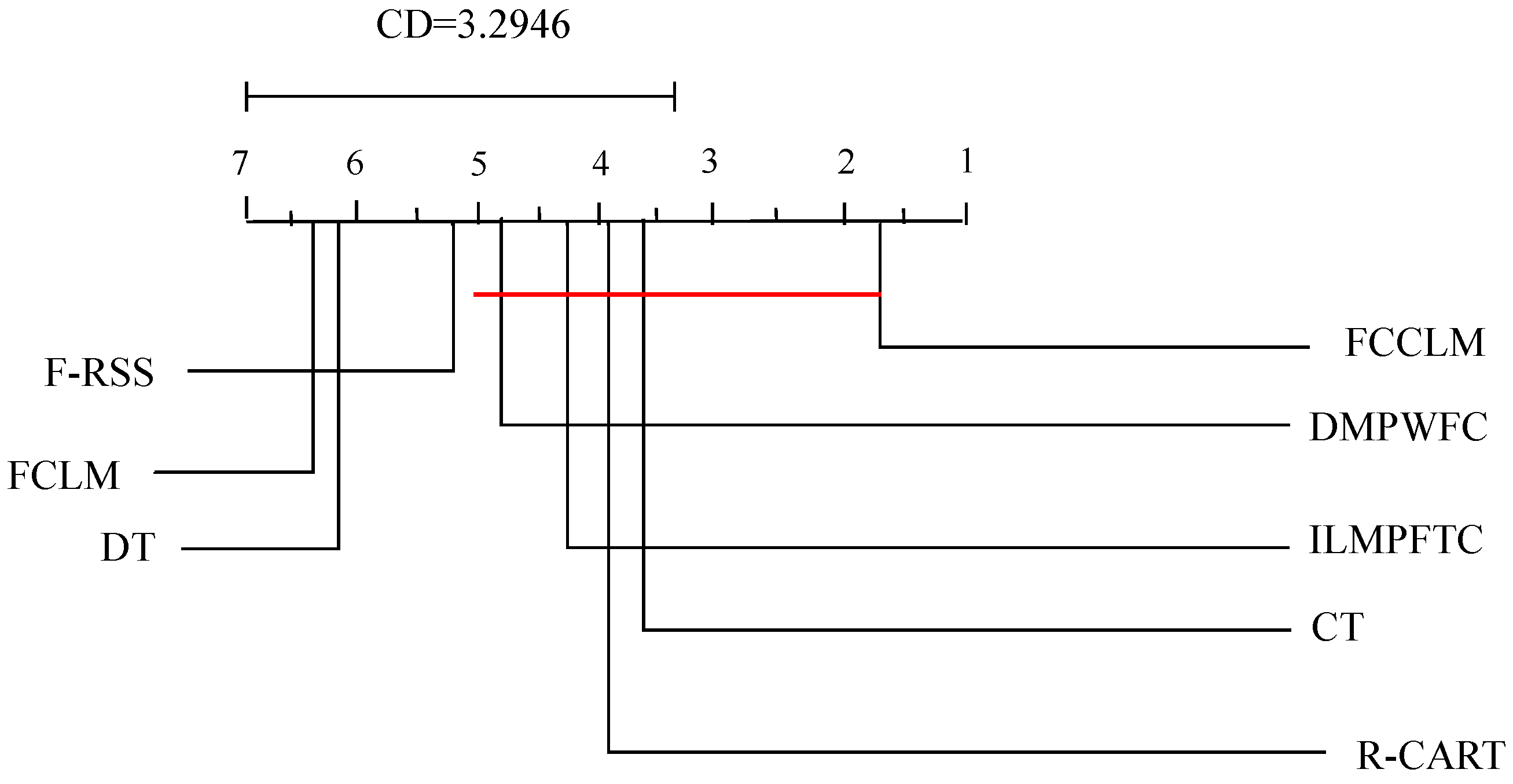
Example 4. In the FFDC of Table 2, where are from Example 1, are two new testing objects. Regarding the object , the membership degree about is , while its true label is 2. Subsequently, the Euclidean distance between and the existing fusing forgetting fuzzy concept space is computed as follows: , , , and . Indeed, the distance between and attains its minimum in . Consequently, should be classified into decision class , which perfectly matches its real label 2.
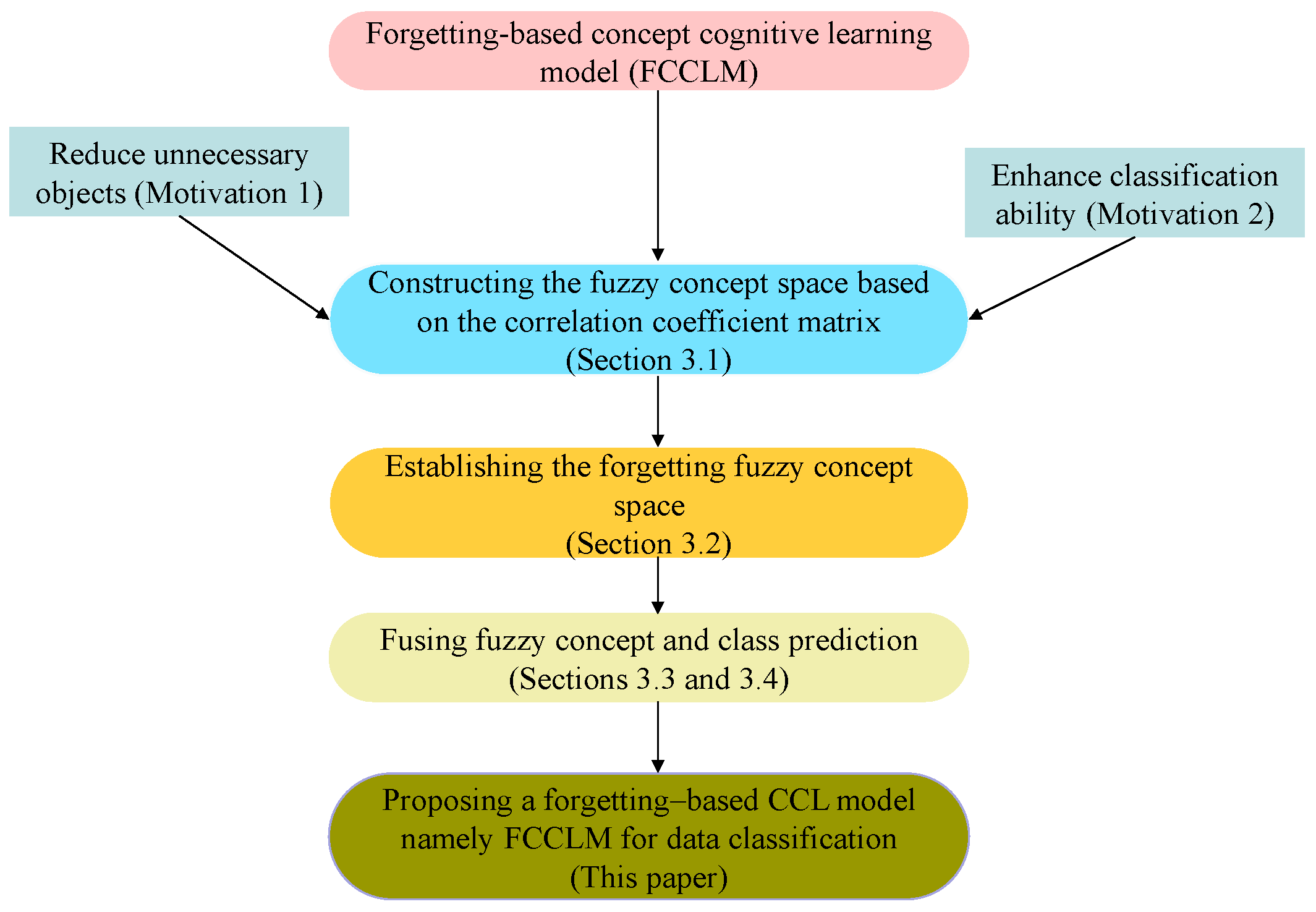
Based on the above discussion,
Figure 3 describes the overall flowchart of the FCCLM, which includes four parts, namely (1) constructing a fuzzy concept space; (2) constructing a forgetting fuzzy concept space; (3) constructing a fusing forgetting fuzzy concept space; and (4) class prediction. In summary, the total time complexity of our model FCCLM is
.
Table 2.
A FFDC.
| U | a1 | a2 | a3 | a4 | d |
|---|
| 0.7 | 0.3 | 0.4 | 0.5 | 1 |
| 0.1 | 0.8 | 0.5 | 0.9 | 1 |
| 0.3 | 0.5 | 0.6 | 0.7 | 1 |
| 0.4 | 0.3 | 0.4 | 0.4 | 1 |
| 0.6 | 0.4 | 0.3 | 0.9 | 2 |
| 0.3 | 0.5 | 0.6 | 0.4 | 2 |
| 0.2 | 0.5 | 0.4 | 0.3 | 2 |
| 0.1 | 0.7 | 0.8 | 0.8 | 2 |
| 0.6 | 0.5 | 0.1 | 0.6 | 2 |
| 0.2 | 0.6 | 0.4 | 0.9 | 2 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}