
Equivalence Test and Sample Size Determination Based on Odds Ratio in an AB/BA Crossover Study with Binary Outcomes


Abstract
1. Introduction
2. Model and Parameter Estimation
3. Hypothesis Testing
3.1. Test Statistics
- (i)
- Wald-type test statistic ()
- (ii)
- Wald-type test statistic ()
- (iii)
- Likelihood ratio test statistic ()
- (iv)
- Score test statistic ()
3.2. Test Procedures
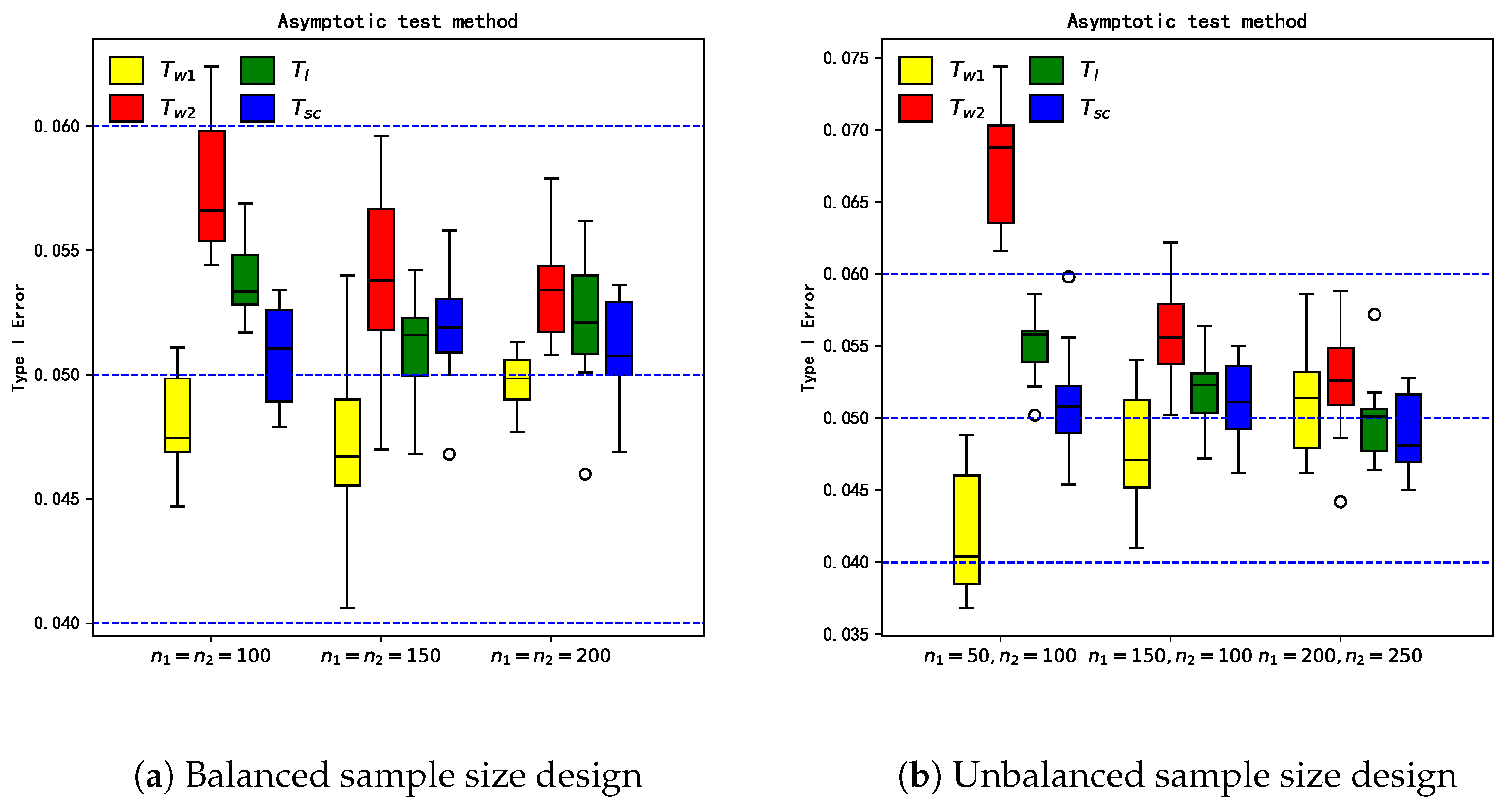
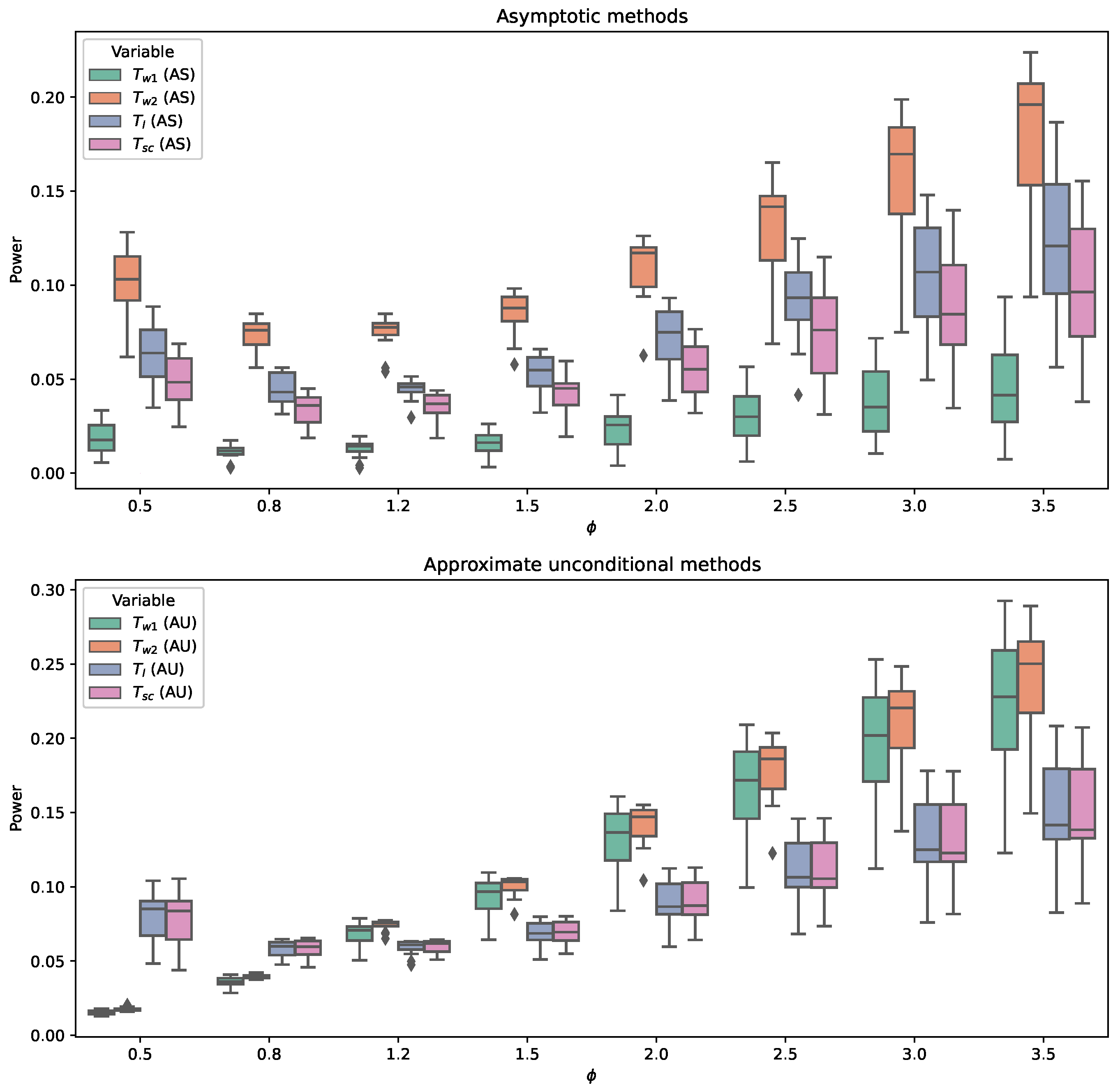
3.2.1. Asymptotic Test Procedure
3.2.2. Approximate Unconditional Test Procedure
4. Confidence Interval
4.1. Wald CIs
4.2. CI Based on Likelihood Ratio Test
4.3. CI Based on Score Test
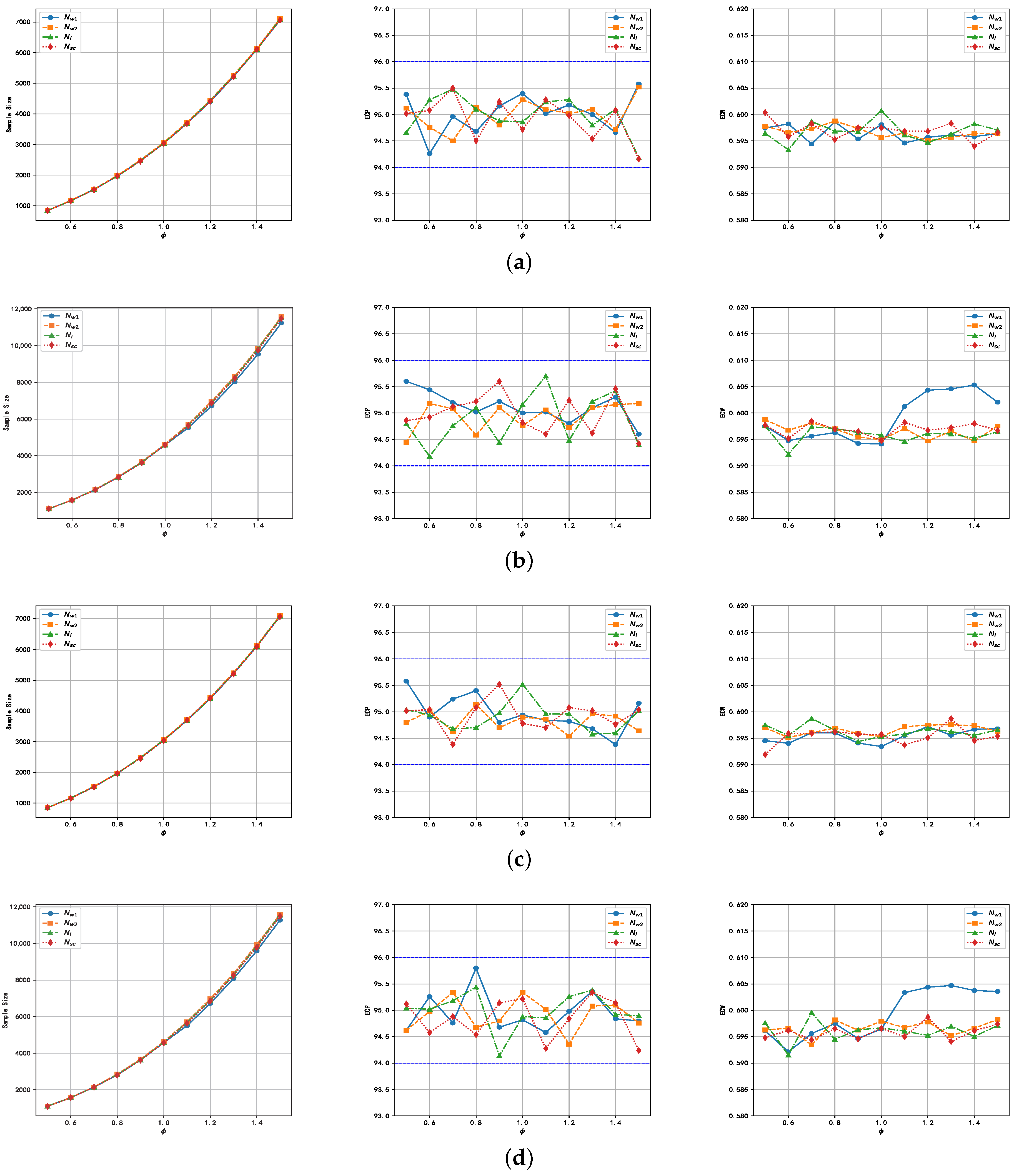
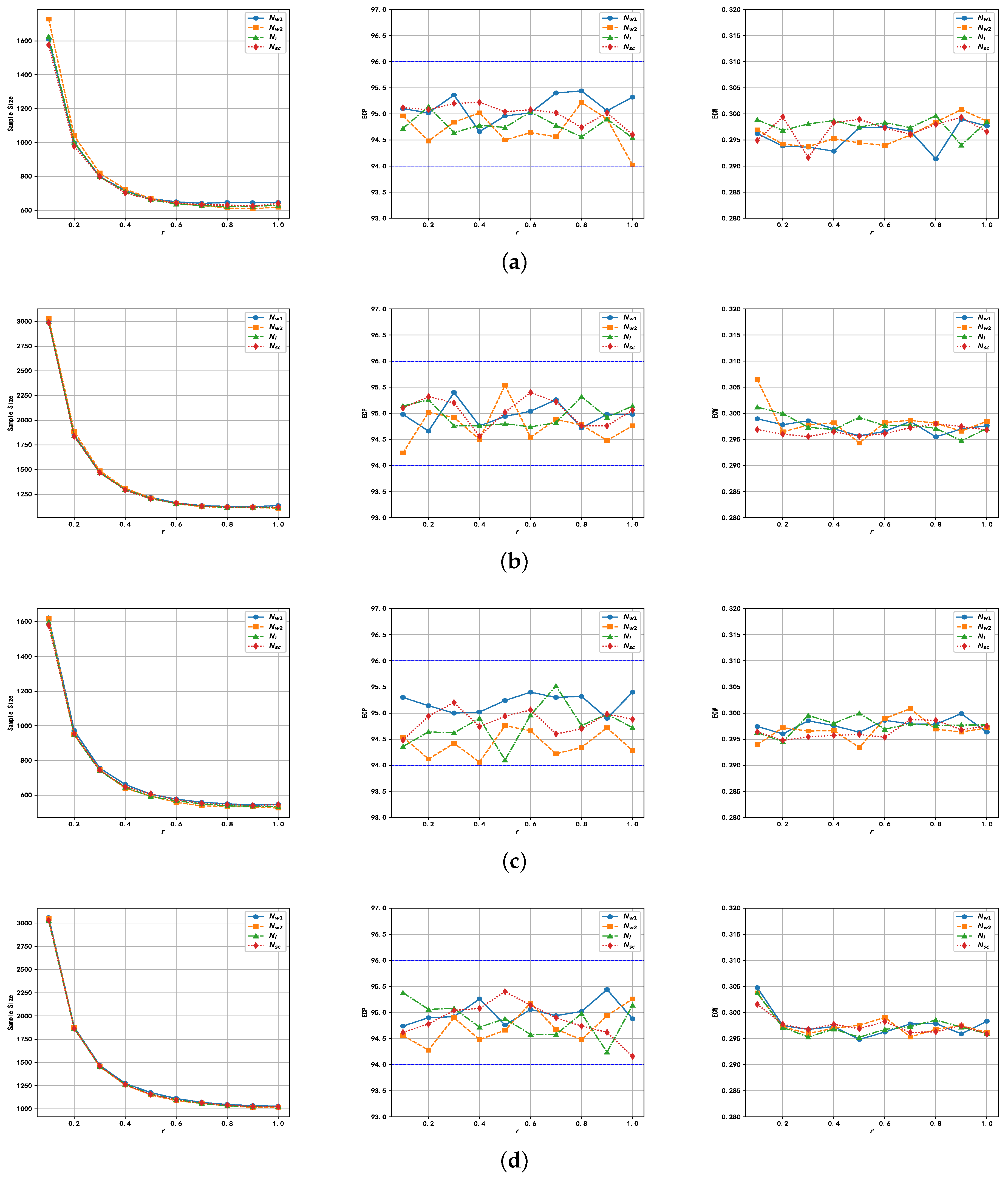
5. Sample Size Determination
6. Simulation Studies
6.1. Empirical Study for Hypothesis Testing
6.2. Empirical Study for Confidence Interval
- (i)
- Empirical coverage probability (ECP)
- (ii)
- Empirical coverage width (ECW)
- (iii)
- Left and right non-coverage probability (LNCP, RNCP)
6.3. Empirical Study for Sample Size Determination
7. Real Example
7.1. Example of Two New Devices Delivering Salbutamol
7.2. Example of Relieving Heartburn
8. Conclusions and Discussion
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Derivation of the CMLE of Given ϕ
Appendix B. Derivation of the Asymptotical Distribution of the Test Statistic Tw1 (Tw2)
Appendix C. Derivation of Score Test Statistic
References
- Hills, M.; Armitage, P. The two-period cross-over clinical trial. Br. J. Pharmacol. 1979, 8, 7. [Google Scholar] [CrossRef] [PubMed]
- Fleiss, J.L. The Design and Analysis of Clinical Experiments; John Wiley & Sons: New York, NY, USA, 1986. [Google Scholar]
- Senn, S.J. Cross-Over Trials in Clinical Research, 2nd ed.; John Wiley & Sons, Ltd.: Chichester, UK, 2002. [Google Scholar]
- Sever, P.S.; Poulter, N.R.; Bulpitt, C.J. Double-blind crossover versus parallel groups in hypertension. Am. Heart J. 1989, 117, 735–739. [Google Scholar] [CrossRef] [PubMed]
- Ménard, J.; Serrurier, D.; Bautier, P.; Plouin, P.-F.; Alexandre, J.-M.; Corvol, P. Crossover design to test antihypertensive drugs with self-recorded blood pressure. Hypertension 1988, 117, 153–159. [Google Scholar] [CrossRef] [PubMed]
- Grenet, G.; Blanc, C.; Bardel, C.; Francillard, I.; Combret, S.; Pivot, X.; Roy, P. Comparison of crossover and parallel-group designs for the identification of a binary predictive biomarker of the treatment effect. Basic Clin. Physiol. Pharmacol. 2020, 126, 59–64. [Google Scholar] [CrossRef]
- Jones, B.; Kenward, M.G. Design and Analysis of Cross-Over Trials; Chapman and Hall: London, UK, 1989. [Google Scholar]
- Senn, S. Cross-over trials in Statistics in Medicine: The first ‘25’ years. Stat. Med. 2006, 25, 3430–3442. [Google Scholar] [CrossRef]
- Mills, E.J.; Chan, A.W.; Wu, P.; Vail, A.; Guyatt, G.H.; Altman, D.G. Design, Analysis, and Presentation of Crossover Trials. Trials 2009, 10, 27. [Google Scholar] [CrossRef]
- Fava, G.M.; Patel, H.I. A Survey of Crossover Designs Used in Industry. Unpublished manuscript. 1986. [Google Scholar]
- Jones, B.; Kenward, M.G. Design and Analysis of Cross-Over Trials, 3rd ed.; Chapman & Hall/CRC, Taylor & Francis: Boca Raton, FL, USA, 2014. [Google Scholar]
- Kershner, R.P.; Federer, W.T. Two-treatment crossover designs for estimating a variety of effects. J. Am. Stat. Assoc. 1981, 76, 612–619. [Google Scholar] [CrossRef]
- Ezzet, F.; Whitehead, J. A random effects model for binary data from crossover clinical trials. J. R. Stat. Soc. C-Appl. 1992, 41, 117–126. [Google Scholar] [CrossRef]
- Becker, M.P.; Balagtas, C.C. Marginal modeling of binary cross-over data. Biometrics 1993, 49, 997–1009. [Google Scholar] [CrossRef]
- Jaki, T.; Pallmann, P. Estimation in AB/BA crossover trials with application to bioequivalence studies with incomplete and complete data designs. Stat. Med. 2013, 32, 5469–5483. [Google Scholar] [CrossRef]
- Lui, K.J.; Chang, K.C. Hypothesis testing and estimation in ordinal data under a simple crossover design. J. Biopharm. Stat. 2012, 22, 1137–1147. [Google Scholar] [CrossRef]
- Lui, K.J. Crossover Designs: Testing, Estimation, and Sample Size; John Wiley & Sons, Ltd.: Chichester, UK, 2016. [Google Scholar]
- Li, X.; Li, H.; Jin, M.; Goldberg, J.D. Likelihood ratio and score tests to test the non-inferiority (or equivalence) of the odds ratio in a crossover study with binary outcomes. Stat. Med. 2016, 35, 3471–3481. [Google Scholar] [CrossRef]
- Lui, K.J. Estimation of the treatment effect under an incomplete block crossover design in binary data-a conditional likelihood approach. Stat. Methods Med. Res. 2017, 26, 2197–2209. [Google Scholar] [CrossRef]
- Lui, K.J. Testing equality of treatments under an incomplete block crossover design with ordinal responses. Int. J. Biostat. 2017, 13, 20160069. [Google Scholar] [CrossRef]
- Lui, K.J.; Chang, K.C. Exact tests in binary data under an incomplete block crossover design. Stat. Methods Med. Res. 2018, 27, 579–592. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Lui, K.J. Notes on misspecifying the random effects distribution regarding analysis under the AB/BA crossover trial in dichotomous data-a Monte Carlo evaluation. Commun. Stat. Simul. Comput. 2020, 49, 419–435. [Google Scholar] [CrossRef]
- Rao, C.R. Linear Statistical Inference and Its Applications, 2nd ed.; Wiley: New York, NY, USA, 1985. [Google Scholar]
- Tang, N.S.; Tang, M.L.; Qiu, S.F. Testing the equality of proportions for correlated otolaryngologic data. Comput. Stat. Data Anal. 2008, 52, 3719–3729. [Google Scholar] [CrossRef]
- Alhija, F.N.A.; Levy, A. Effect size reporting practices in published articles. Educ. Psychol. Meas. 2009, 69, 245–265. [Google Scholar] [CrossRef]
- Odgaard, E.C.; Fowler, R.L. Confidence intervals for effect sizes: Compliance and clinical significance in the Journal of Consulting and clinical Psychology. J. Consult. Clin. Psychol. 2010, 78, 287–297. [Google Scholar] [CrossRef]
- Sun, S.; Pan, W.; Wang, L.L. A comprehensive review of effect size reporting and interpreting practices in academic journals in education and psychology. J. Educ. Psychol. 2010, 102, 989–1004. [Google Scholar] [CrossRef]
- Dunst, C.J.; Hamby, D.W. Guide for calculating and interpreting effect sizes and confidence intervals in intellectual and developmental disability research studies. J. Intellect. Dev. Disabil. 2012, 37, 89–99. [Google Scholar] [CrossRef]
- Fritz, C.O.; Morris, P.E.; Richler, J.J. Effect size estimates: Current use, calculations, and interpretation. J. Exp. Psychol. Gen. 2012, 141, 2–18. [Google Scholar] [CrossRef] [PubMed]
- American Psychological Association. Publication Manual of the American Psychological Association, 6th ed.; American Psychological Association: Washington, DC, USA, 2009. [Google Scholar]
- Traub, J.F. Iterative Methods for the Solution of Equations; American Mathematical Society: Providence, RI, USA, 1982. [Google Scholar]
- Lui, K.J.; Chang, K.C. Exact Sample-Size Determination in Testing Non-Inferiority under a Simple Crossover Trial. Pharm. Stat. 2012, 11, 129–134. [Google Scholar] [CrossRef] [PubMed]
- Koch, G.G.; Gitomer, S.L.; Skalland, L.; Stokes, M.E. Some non-parametric and categorical data analysis for a change-over design study and discussion of apparent carry-over effects. Stat. Med. 1983, 2, 397–412. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AB Sequence | ||||
| Period 2 | ||||
| 1 | 0 | Total | ||
| Period 1 | 1 | |||
| 0 | ||||
| Total | ||||
| BA Sequence | ||||
| Period 2 | ||||
| 1 | 0 | Total | ||
| Period 1 | 1 | |||
| 0 | ||||
| Total | ||||
| Par. | Par. | ||
|---|---|---|---|
| (0.5, 0.25, 0.4, 0.35, 0.10) | (0.5, 0.20, 0.4, 0.10, 0.25) | ||
| (0.5, 0.25, 0.4, 0.35, 0.15) | (0.5, 0.20, 0.4, 0.10, 0.30) | ||
| (0.4, 0.25, 0.4, 0.25, 0.15) | (0.5, 0.20, 0.2, 0.30, 0.30) | ||
| (0.4, 0.25, 0.4, 0.25, 0.20) | (0.5, 0.20, 0.2, 0.20, 0.30) | ||
| (0.5, 0.20, 0.5, 0.20, 0.15) | (0.5, 0.20, 0.2, 0.20, 0.40) | ||
| (0.5, 0.20, 0.4, 0.10, 0.20) | (0.3, 0.25, 0.4, 0.30, 0.15) |
| n | Par. | AS | AU | AS | AU | AS | AU | AS | AU |
|---|---|---|---|---|---|---|---|---|---|
| 0.06 | 3.02 | 3.38 | 4.04 | 1.90 | 4.93 | 0.64 | 4.97 | ||
| 0.12 | 3.02 | 3.32 | 4.04 | 1.50 | 4.93 | 0.90 | 5.11 | ||
| 0.24 | 4.14 | 5.04 | 5.45 | 2.90 | 5.51 | 1.44 | 5.79 | ||
| 0.44 | 4.14 | 5.52 | 5.45 | 2.36 | 5.51 | 1.28 | 5.89 | ||
| 0.10 | 3.94 | 4.98 | 5.06 | 2.50 | 5.48 | 1.58 | 5.74 | ||
| 10 | 0.62 | 3.67 | 5.24 | 4.59 | 2.96 | 5.03 | 2.00 | 5.33 | |
| 0.60 | 4.51 | 4.86 | 5.26 | 3.62 | 5.25 | 1.92 | 5.55 | ||
| 0.32 | 4.91 | 4.84 | 5.42 | 2.74 | 5.06 | 1.96 | 5.38 | ||
| 0.32 | 4.81 | 5.42 | 5.49 | 2.74 | 5.13 | 1.98 | 5.46 | ||
| 0.40 | 4.42 | 6.08 | 5.12 | 3.20 | 5.18 | 3.00 | 5.42 | ||
| 0.40 | 5.24 | 4.68 | 5.34 | 2.94 | 4.83 | 2.36 | 5.12 | ||
| 0.24 | 4.23 | 5.32 | 5.44 | 3.16 | 5.45 | 1.86 | 5.74 | ||
| 0.22 | 5.06 | 5.16 | 6.51 | 3.30 | 4.72 | 1.84 | 5.03 | ||
| 0.40 | 4.05 | 5.80 | 5.30 | 2.92 | 4.72 | 2.14 | 5.08 | ||
| 1.20 | 5.26 | 8.26 | 5.85 | 4.92 | 5.99 | 3.72 | 6.06 | ||
| 1.22 | 5.26 | 7.92 | 5.85 | 4.46 | 5.99 | 2.84 | 6.08 | ||
| 0.82 | 4.99 | 7.34 | 5.88 | 4.08 | 5.67 | 2.84 | 5.91 | ||
| 15 | 1.42 | 4.64 | 7.26 | 5.33 | 4.44 | 5.67 | 4.04 | 5.69 | |
| 1.44 | 5.44 | 7.14 | 5.69 | 4.46 | 5.85 | 3.32 | 5.85 | ||
| 1.24 | 5.82 | 6.76 | 5.75 | 4.38 | 5.66 | 3.68 | 5.70 | ||
| 1.40 | 5.78 | 7.10 | 5.75 | 4.44 | 5.74 | 3.82 | 5.72 | ||
| 1.94 | 5.33 | 7.10 | 5.68 | 4.56 | 5.70 | 3.74 | 5.49 | ||
| 1.12 | 5.91 | 5.94 | 5.61 | 4.16 | 5.36 | 3.50 | 5.28 | ||
| 1.38 | 5.29 | 7.54 | 5.75 | 5.04 | 5.98 | 3.54 | 6.00 | ||
| Par. | ||||
|---|---|---|---|---|
| A1 | 95.18 (2.50, 2.32) 1.68 | 94.02 (2.40, 3.58) 4.66 | 94.48 (2.56, 2.96) 1.68 | 94.66 (2.72, 2.62) 1.64 |
| A2 | 95.98 (2.40, 1.62) 1.93 | 93.08 (1.84, 5.08) 2.07 | 94.56 (2.52, 2.92) 1.94 | 94.92 (2.76, 2.32) 1.85 |
| A3 | 95.18 (2.44, 2.38) 1.25 | 94.14 (2.32, 3.54) 3.97 | 94.60 (2.44, 2.96) 1.25 | 94.88 (2.52, 2.60) 1.23 |
| A4 | 95.88 (2.02, 2.10) 1.35 | 94.64 (1.90, 3.46) 1.39 | 95.08 (2.08, 2.84) 1.34 | 95.36 (2.22, 2.42) 1.32 |
| A5 | 95.26 (2.36, 2.38) 1.45 | 94.20 (2.16, 3.64) 1.50 | 94.70 (2.42, 2.88) 1.45 | 94.78 (2.62, 2.60) 1.43 |
| A6 | 95.34 (2.66, 2.00) 1.19 | 94.46 (2.56, 2.98) 1.23 | 94.98 (2.64, 2.38) 1.19 | 95.06 (2.70, 2.24) 1.18 |
| A7 | 95.88 (2.22, 1.90) 1.21 | 94.04 (1.96, 4.00) 1.21 | 95.08 (2.14, 2.78) 1.20 | 95.38 (2.40, 2.22) 1.19 |
| A8 | 96.04 (2.26, 1.70) 1.31 | 92.22 (1.66, 6.12) 1.28 | 94.62 (2.06, 3.32) 1.28 | 95.20 (2.44, 2.36) 1.28 |
| A9 | 95.56 (2.42, 2.02) 1.30 | 92.20 (1.82, 5.98) 1.26 | 94.46 (2.30, 3.24) 1.27 | 94.92 (2.58, 2.50) 1.27 |
| A10 | 95.90 (2.16, 1.94) 1.16 | 94.52 (1.68, 3.80) 1.16 | 95.44 (2.08, 2.48) 1.14 | 95.48 (2.32, 2.20) 1.14 |
| A11 | 96.26 (2.46, 1.28) 1.38 | 90.78 (1.36, 7.86) 1.30 | 94.48 (2.16, 3.36) 1.33 | 95.04 (2.68, 2.28) 1.34 |
| A12 | 95.46 (2.16, 2.38) 1.25 | 94.58 (2.10, 3.32) 1.55 | 94.90 (2.24, 2.86) 1.26 | 95.12 (2.30, 2.58) 1.23 |
| A1 | 95.24 (2.52, 2.24) 2.80 | 94.14 (2.52, 3.34) 3.09 | 94.64 (2.72, 2.64) 2.86 | 94.76 (2.72, 2.52) 2.73 |
| A2 | 95.36 (2.48, 2.16) 2.93 | 93.34 (2.50, 4.16) 4.33 | 94.52 (2.76, 2.72) 3.01 | 94.88 (2.70, 2.42) 2.83 |
| A3 | 95.04 (2.46, 2.50) 2.02 | 94.38 (2.66, 2.96) 2.13 | 94.64 (2.62, 2.74) 2.04 | 94.78 (2.58, 2.64) 1.99 |
| A4 | 95.26 (2.40, 2.34) 2.08 | 94.46 (2.64, 2.90) 2.21 | 94.84 (2.60, 2.56) 2.10 | 94.94 (2.60, 2.46) 2.04 |
| A5 | 95.30 (2.38, 2.32) 2.29 | 94.44 (2.64, 2.92) 2.46 | 94.78 (2.56, 2.66) 2.32 | 95.02 (2.54, 2.44) 2.25 |
| A6 | 95.24 (2.68, 2.08) 1.97 | 94.54 (2.98, 2.48) 2.19 | 94.88 (2.86, 2.26) 2.01 | 94.96 (2.80, 2.24) 1.93 |
| A7 | 95.58 (2.28, 2.14) 1.90 | 94.56 (2.40, 3.04) 2.00 | 95.22 (2.34, 2.44) 1.91 | 95.34 (2.44, 2.22) 1.87 |
| A8 | 95.24 (2.40, 2.36) 1.98 | 93.86 (2.32, 3.82) 2.03 | 94.64 (2.50, 2.86) 1.97 | 94.86 (2.54, 2.60) 1.95 |
| A9 | 95.56 (2.22, 2.22) 1.96 | 94.28 (2.14, 3.58) 2.01 | 95.10 (2.30, 2.60) 1.95 | 95.26 (2.36, 2.38) 1.93 |
| A10 | 95.66 (2.36, 1.98) 1.81 | 94.50 (2.54, 2.96) 1.91 | 95.16 (2.50, 2.34) 1.82 | 95.38 (2.44, 2.18) 1.78 |
| A11 | 95.70 (2.28, 2.02) 2.00 | 92.30 (1.84, 5.86) 1.99 | 94.68 (2.24, 3.08) 1.98 | 94.94 (2.54, 2.52) 1.96 |
| A12 | 95.24 (2.04, 2.72) 1.97 | 94.58 (2.26, 3.16) 2.10 | 94.90 (2.22, 2.88) 1.99 | 95.04 (2.20, 2.76) 1.94 |
| A1 | 95.10 (2.54, 2.36) 4.69 | 94.14 (0.12, 5.64) 5.03 | 94.40 (3.00, 2.60) 5.04 | 94.72 (2.80, 2.48) 4.50 |
| A2 | 95.18 (2.56, 2.26) 4.37 | 93.68 (2.70, 3.62) 5.11 | 94.52 (2.94, 2.54) 4.55 | 94.78 (2.76, 2.46) 4.24 |
| A3 | 95.12 (2.40, 2.48) 3.19 | 94.44 (2.72, 2.84) 3.58 | 94.74 (2.60, 2.66) 3.26 | 94.84 (2.54, 2.62) 3.14 |
| A4 | 95.22 (2.52, 2.26) 3.11 | 94.48 (2.88, 2.64) 3.40 | 94.70 (2.78, 2.52) 3.16 | 94.86 (2.62, 2.52) 3.06 |
| A5 | 95.36 (2.36, 2.28) 3.54 | 94.46 (2.84, 2.70) 3.96 | 94.92 (2.66, 2.42) 3.63 | 95.04 (2.54, 2.42) 3.48 |
| A6 | 95.38 (2.44, 2.18) 3.23 | 94.62 (2.68, 2.70) 3.85 | 94.82 (2.94, 2.24) 3.39 | 94.96 (2.72, 2.32) 3.15 |
| A7 | 95.64 (2.20, 2.16) 2.94 | 94.80 (2.76, 2.44) 3.30 | 95.16 (2.54, 2.30) 3.01 | 95.28 (2.38, 2.34) 2.89 |
| A8 | 95.22 (2.38, 2.40) 2.93 | 94.44 (2.60, 2.96) 3.13 | 94.80 (2.52, 2.68) 2.96 | 94.84 (2.54, 2.62) 2.88 |
| A9 | 95.64 (2.14, 2.22) 2.90 | 94.82 (2.40, 2.78) 3.10 | 95.20 (2.34, 2.46) 2.93 | 95.32 (2.32, 2.36) 2.86 |
| A10 | 95.52 (2.26, 2.22) 2.80 | 94.88 (2.72, 2.40) 3.17 | 95.10 (2.56, 2.34) 2.87 | 95.30 (2.38, 2.32) 2.75 |
| A11 | 95.50 (2.44, 2.06) 2.89 | 94.24 (2.44, 3.32) 3.00 | 95.08 (2.56, 2.36) 2.90 | 95.14 (2.58, 2.28) 2.84 |
| A12 | 94.98 (2.64, 2.38) 3.03 | 94.38 (2.98, 2.64) 3.31 | 94.68 (2.84, 2.48) 3.08 | 94.78 (2.72, 2.50) 2.98 |
| Par. | ||||
|---|---|---|---|---|
| A1 | 94.90 (2.70, 2.40) 0.97 | 94.42 (2.56, 3.02) 0.97 | 94.64 (2.72, 2.64) 0.97 | 94.72 (2.78, 2.50) 0.96 |
| A2 | 95.48 (2.14, 2.38) 1.07 | 94.54 (2.00, 3.46) 1.08 | 95.14 (2.12, 2.74) 1.06 | 95.18 (2.26, 2.56) 1.05 |
| A3 | 94.48 (2.90, 2.62) 0.78 | 94.12 (2.76, 3.12) 0.78 | 94.22 (2.90, 2.88) 0.77 | 94.34 (2.98, 2.68) 0.77 |
| A4 | 95.38 (2.28, 2.34) 0.81 | 94.80 (2.08, 3.12) 0.81 | 95.20 (2.28, 2.52) 0.81 | 95.20 (2.36, 2.44) 0.81 |
| A5 | 95.58 (2.42, 2.00) 0.87 | 95.00 (2.20, 2.80) 0.87 | 95.12 (2.38, 2.50) 0.86 | 95.44 (2.44, 2.12) 0.86 |
| A6 | 95.14 (2.44, 2.42) 0.74 | 94.72 (2.34, 2.94) 0.75 | 94.98 (2.46, 2.56) 0.74 | 95.02 (2.52, 2.46) 0.74 |
| A7 | 95.32 (2.64, 2.04) 0.76 | 94.78 (2.32, 2.90) 0.76 | 95.16 (2.48, 2.36) 0.76 | 95.18 (2.70, 2.12) 0.75 |
| A8 | 95.34 (2.74, 1.92) 0.82 | 94.86 (2.28, 2.86) 0.81 | 95.08 (2.66, 2.26) 0.81 | 95.06 (2.84, 2.10) 0.81 |
| A9 | 95.42 (2.52, 2.06) 0.82 | 94.68 (2.02, 3.30) 0.81 | 94.96 (2.40, 2.64) 0.81 | 95.08 (2.66, 2.26) 0.81 |
| A10 | 95.32 (2.52, 2.16) 0.73 | 94.62 (2.24, 3.14) 0.73 | 94.98 (2.44, 2.58) 0.73 | 95.04 (2.58, 2.38) 0.73 |
| A11 | 95.94 (2.22, 1.84) 0.85 | 94.88 (1.48, 3.64) 0.83 | 95.52 (2.06, 2.42) 0.84 | 95.52 (2.44, 2.04) 0.84 |
| A12 | 94.88 (2.58, 2.54) 0.77 | 94.20 (2.56, 3.24) 0.78 | 94.52 (2.58, 2.90) 0.77 | 94.66 (2.62, 2.72) 0.76 |
| A1 | 94.98 (2.76, 2.26) 1.57 | 94.26 (2.92, 2.82) 1.62 | 94.70 (2.80, 2.50) 1.58 | 94.86 (2.80, 2.34) 1.56 |
| A2 | 95.36 (2.18, 2.46) 1.60 | 94.56 (2.36, 3.08) 1.66 | 94.92 (2.34, 2.74) 1.61 | 95.06 (2.36, 2.58) 1.59 |
| A3 | 94.90 (2.74, 2.36) 1.23 | 94.56 (2.84, 2.60) 1.25 | 94.70 (2.82, 2.48) 1.24 | 94.70 (2.88, 2.42) 1.23 |
| A4 | 95.84 (2.08, 2.08) 1.24 | 95.54 (2.18, 2.28) 1.27 | 95.66 (2.20, 2.14) 1.25 | 95.70 (2.20, 2.10) 1.24 |
| A5 | 95.58 (2.24, 2.18) 1.36 | 95.22 (2.38, 2.40) 1.38 | 95.38 (2.36, 2.26) 1.36 | 95.38 (2.38, 2.24) 1.35 |
| A6 | 94.88 (2.56, 2.56) 1.19 | 94.60 (2.72, 2.68) 1.23 | 94.74 (2.62, 2.64) 1.20 | 94.76 (2.60, 2.64) 1.19 |
| A7 | 94.90 (2.40, 2.70) 1.18 | 94.42 (2.40, 3.18) 1.19 | 94.70 (2.46, 2.84) 1.18 | 94.76 (2.46, 2.78) 1.17 |
| A8 | 95.08 (2.56, 2.36) 1.23 | 94.56 (2.42, 3.02) 1.23 | 94.66 (2.58, 2.76) 1.22 | 94.88 (2.60, 2.52) 1.22 |
| A9 | 95.04 (2.66, 2.30) 1.23 | 94.66 (2.50, 2.84) 1.24 | 94.82 (2.64, 2.54) 1.23 | 94.82 (2.78, 2.40) 1.22 |
| A10 | 95.28 (2.52, 2.20) 1.13 | 94.84 (2.56, 2.60) 1.15 | 95.14 (2.58, 2.28) 1.14 | 95.16 (2.62, 2.22) 1.13 |
| A11 | 95.04 (2.76, 2.20) 1.25 | 94.28 (2.32, 3.40) 1.24 | 94.60 (2.68, 2.72) 1.24 | 94.84 (2.78, 2.38) 1.23 |
| A12 | 94.62 (2.66, 2.72) 1.21 | 94.16 (2.84, 3.00) 1.24 | 94.38 (2.78, 2.84) 1.22 | 94.46 (2.74, 2.80) 1.21 |
| A1 | 94.78 (2.70, 2.52) 2.48 | 94.00 (3.26, 2.74) 2.64 | 94.36 (2.98, 2.66) 2.51 | 94.46 (2.88, 2.66) 2.45 |
| A2 | 95.12 (2.42, 2.46) 2.40 | 94.80 (2.66, 2.54) 2.53 | 94.88 (2.62, 2.50) 2.43 | 95.00 (2.50, 2.50) 2.38 |
| A3 | 94.80 (2.48, 2.72) 1.90 | 94.42 (2.74, 2.84) 1.97 | 94.60 (2.58, 2.82) 1.91 | 94.64 (2.52, 2.84) 1.89 |
| A4 | 95.20 (2.44, 2.36) 1.85 | 94.88 (2.70, 2.42) 1.90 | 94.98 (2.58, 2.44) 1.86 | 95.02 (2.54, 2.44) 1.84 |
| A5 | 95.30 (2.32, 2.38) 2.05 | 94.82 (2.64, 2.54) 2.12 | 95.00 (2.52, 2.48) 2.07 | 95.08 (2.44, 2.48) 2.04 |
| A6 | 95.18 (2.54, 2.28) 1.87 | 94.76 (3.12, 2.12) 2.00 | 94.90 (2.84, 2.26) 1.90 | 94.92 (2.70, 2.38) 1.86 |
| A7 | 95.36 (2.52, 2.12) 1.78 | 94.98 (2.92, 2.10) 1.85 | 95.18 (2.70, 2.12) 1.80 | 95.30 (2.58, 2.12) 1.77 |
| A8 | 95.14 (2.62, 2.24) 1.80 | 94.82 (2.78, 2.40) 1.84 | 94.96 (2.70, 2.34) 1.80 | 95.06 (2.66, 2.28) 1.79 |
| A9 | 94.94 (2.54, 2.52) 1.81 | 94.52 (2.72, 2.76) 1.85 | 94.80 (2.60, 2.60) 1.82 | 94.84 (2.62, 2.54) 1.80 |
| A10 | 95.32 (2.24, 2.44) 1.71 | 94.74 (2.74, 2.52) 1.77 | 95.08 (2.42, 2.50) 1.72 | 95.16 (2.34, 2.50) 1.70 |
| A11 | 95.00 (2.46, 2.54) 1.78 | 94.54 (2.48, 2.98) 1.80 | 94.78 (2.54, 2.68) 1.78 | 94.88 (2.56, 2.56) 1.76 |
| A12 | 95.00 (2.44, 2.56) 1.83 | 94.54 (2.72, 2.74) 1.88 | 94.82 (2.56, 2.62) 1.84 | 94.84 (2.52, 2.64) 1.82 |
| Par. | ||||
|---|---|---|---|---|
| A1 | 95.36 (2.16, 2.48) 1.41 | 94.04 (2.10, 3.86)1.47 | 94.62 (2.24, 3.14) 1.41 | 94.94 (2.34, 2.72) 1.39 |
| A2 | 95.38 (2.12, 2.50) 1.66 | 93.86 (1.74, 4.40)1.78 | 94.78 (2.38, 2.84) 1.73 | 94.98 (2.34, 2.68) 1.60 |
| A3 | 95.20 (2.08, 2.72) 1.08 | 94.44 (2.02, 3.54)1.09 | 94.84 (2.10, 3.06) 1.07 | 94.90 (2.18, 2.92) 1.06 |
| A4 | 95.06 (2.34, 2.60) 1.17 | 94.02 (2.46, 3.52)1.25 | 94.50 (2.48, 3.02) 1.18 | 94.56 (2.54, 2.90) 1.15 |
| A5 | 95.24 (2.40, 2.36) 1.26 | 94.32 (2.48, 3.20)1.32 | 94.78 (2.58, 2.64) 1.26 | 94.90 (2.58, 2.52) 1.23 |
| A6 | 95.14 (2.64, 2.22) 1.01 | 94.52 (2.52, 2.96)1.01 | 94.82 (2.66, 2.52) 1.00 | 94.82 (2.84, 2.34) 1.00 |
| A7 | 95.36 (2.46, 2.18) 1.02 | 94.80 (2.32, 2.88)1.03 | 95.14 (2.44, 2.42) 1.02 | 95.22 (2.54, 2.24) 1.01 |
| A8 | 95.06 (2.54, 2.40) 1.11 | 94.20 (2.18, 3.62)1.12 | 94.60 (2.50, 2.90) 1.10 | 94.72 (2.70, 2.58) 1.09 |
| A9 | 96.00 (2.08, 1.92) 1.09 | 94.82 (1.78, 3.40)1.10 | 95.22 (2.04, 2.74) 1.09 | 95.50 (2.28, 2.22) 1.08 |
| A10 | 95.52 (2.50, 1.98) 0.97 | 94.68 (2.22, 3.10)0.97 | 95.08 (2.48, 2.44) 0.97 | 95.24 (2.58, 2.18) 0.96 |
| A11 | 95.78 (2.60, 1.62) 1.14 | 94.26 (1.94, 3.80)1.14 | 95.02 (2.50, 2.48) 1.12 | 95.20 (2.78, 2.02) 1.12 |
| A12 | 95.16 (2.40, 2.44) 1.13 | 94.22 (2.64, 3.14)1.21 | 94.64 (2.58, 2.78) 1.14 | 94.80 (2.64, 2.56) 1.11 |
| A1 | 95.40 (2.22, 2.38) 2.32 | 93.96 (2.54, 3.50) 2.47 | 94.82 (2.42, 2.76) 2.34 | 94.86 (2.80, 2.34) 1.56 |
| A2 | 95.48 (2.26, 2.26) 2.52 | 94.24 (2.02, 3.74) 2.79 | 94.80 (2.68, 2.52) 2.63 | 95.06 (2.36, 2.58) 1.59 |
| A3 | 95.58 (2.22, 2.20) 1.75 | 94.66 (2.34, 3.00) 1.80 | 95.18 (2.28, 2.54) 1.75 | 94.70 (2.88, 2.42) 1.23 |
| A4 | 94.52 (2.32, 3.16) 1.80 | 93.48 (2.90, 3.62) 1.97 | 94.14 (2.54, 3.32) 1.83 | 95.70 (2.20, 2.10) 1.24 |
| A5 | 95.02 (2.42, 2.56) 1.98 | 94.02 (2.70, 3.28) 2.14 | 94.52 (2.56, 2.92) 2.01 | 95.38 (2.38, 2.24) 1.35 |
| A6 | 94.70 (2.46, 2.84) 1.60 | 94.04 (2.66, 3.30) 1.66 | 94.40 (2.56, 3.04) 1.61 | 94.76 (2.60, 2.64) 1.19 |
| A7 | 95.22 (2.30, 2.48) 1.59 | 94.50 (2.42, 3.08) 1.63 | 94.92 (2.46, 2.62) 1.59 | 94.76 (2.46, 2.78) 1.17 |
| A8 | 95.04 (2.46, 2.50) 1.67 | 94.44 (2.56, 3.00) 1.72 | 94.74 (2.52, 2.74) 1.67 | 94.88 (2.60, 2.52) 1.22 |
| A9 | 94.70 (2.50, 2.80) 1.65 | 94.02 (2.52, 3.46) 1.71 | 94.40 (2.56, 3.04) 1.66 | 94.82 (2.78, 2.40) 1.22 |
| A10 | 95.46 (2.06, 2.48) 1.49 | 95.08 (2.08, 2.84) 1.53 | 95.26 (2.06, 2.68) 1.50 | 95.16 (2.62, 2.22) 1.13 |
| A11 | 95.08 (2.52, 2.40) 1.67 | 94.18 (2.50, 3.32) 1.71 | 94.68 (2.54, 2.78) 1.67 | 94.84 (2.78, 2.38) 1.23 |
| A12 | 95.22 (2.30, 2.48) 1.78 | 94.48 (2.68, 2.84) 1.94 | 94.72 (2.64, 2.64) 1.80 | 94.46 (2.74, 2.80) 1.21 |
| A1 | 95.36 (2.40, 2.24) 3.65 | 93.94 (2.72, 3.34) 4.03 | 94.78 (2.62, 2.60) 3.71 | 94.46 (2.88, 2.66) 2.45 |
| A2 | 95.12 (2.18, 2.70) 3.74 | 93.72 (2.18, 4.10) 4.22 | 94.60 (2.52, 2.88) 3.93 | 95.00 (2.50, 2.50) 2.38 |
| A3 | 95.18 (2.52, 2.30) 2.69 | 94.42 (2.68, 2.90) 2.84 | 94.74 (2.60, 2.66) 2.71 | 94.64 (2.52, 2.84) 1.89 |
| A4 | 94.80 (2.30, 2.90) 2.72 | 94.18 (2.84, 2.98) 2.99 | 94.56 (2.50, 2.94) 2.77 | 95.02 (2.54, 2.44) 1.84 |
| A5 | 95.40 (2.02, 2.58) 2.95 | 94.76 (2.40, 2.84) 3.21 | 95.10 (2.16, 2.74) 3.00 | 95.08 (2.44, 2.48) 2.04 |
| A6 | 94.88 (2.58, 2.54) 2.59 | 94.28 (3.08, 2.64) 2.84 | 94.56 (2.78, 2.66) 2.64 | 94.92 (2.70, 2.38) 1.86 |
| A7 | 94.66 (2.10, 3.24) 2.39 | 94.26 (2.36, 3.38) 2.51 | 94.42 (2.28, 3.30) 2.42 | 95.30 (2.58, 2.12) 1.77 |
| A8 | 94.78 (2.52, 2.70) 2.47 | 94.28 (2.72, 3.00) 2.60 | 94.44 (2.66, 2.90) 2.49 | 95.06 (2.66, 2.28) 1.79 |
| A9 | 95.54 (1.80, 2.66) 2.42 | 95.06 (2.08, 2.86) 2.54 | 95.38 (1.92, 2.70) 2.44 | 94.84 (2.62, 2.54) 1.80 |
| A10 | 95.18 (1.86, 2.96) 2.25 | 94.62 (2.18, 3.20) 2.37 | 94.90 (2.00, 3.10) 2.28 | 95.16 (2.34, 2.50) 1.70 |
| A11 | 95.14 (2.50, 2.36) 2.43 | 94.56 (2.84, 2.60) 2.54 | 94.86 (2.68, 2.46) 2.44 | 94.88 (2.56, 2.56) 1.76 |
| A12 | 95.48 (2.24, 2.28) 2.70 | 94.32 (2.84, 2.84) 2.96 | 94.80 (2.54, 2.66) 2.74 | 94.84 (2.52, 2.64) 1.82 |
| AB Sequence | ||||
| Period 2 | ||||
| 1 | 0 | Total | ||
| Period 1 | 1 | 26 | 41 | 67 |
| 0 | 15 | 57 | 72 | |
| Total | 41 | 98 | 139 | |
| BA Sequence | ||||
| Period 2 | ||||
| 1 | 0 | Total | ||
| Period 1 | 1 | 38 | 16 | 54 |
| 0 | 32 | 54 | 86 | |
| Total | 70 | 70 | 140 | |
| Period II | ||||
|---|---|---|---|---|
| Sequence | Period I | R | NR | Total |
| A:P | R | 0 | 7 | 7 |
| NR | 1 | 7 | 8 | |
| Total | 1 | 14 | 15 | |
| P:A | R | 0 | 3 | 3 |
| NR | 10 | 2 | 12 | |
| Total | 10 | 5 | 15 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, S.-F.; Yu, X.-Q.; Poon, W.-Y. Equivalence Test and Sample Size Determination Based on Odds Ratio in an AB/BA Crossover Study with Binary Outcomes. Axioms 2025, 14, 582. https://doi.org/10.3390/axioms14080582
Qiu S-F, Yu X-Q, Poon W-Y. Equivalence Test and Sample Size Determination Based on Odds Ratio in an AB/BA Crossover Study with Binary Outcomes. Axioms. 2025; 14(8):582. https://doi.org/10.3390/axioms14080582
Chicago/Turabian StyleQiu, Shi-Fang, Xue-Qin Yu, and Wai-Yin Poon. 2025. "Equivalence Test and Sample Size Determination Based on Odds Ratio in an AB/BA Crossover Study with Binary Outcomes" Axioms 14, no. 8: 582. https://doi.org/10.3390/axioms14080582
APA StyleQiu, S.-F., Yu, X.-Q., & Poon, W.-Y. (2025). Equivalence Test and Sample Size Determination Based on Odds Ratio in an AB/BA Crossover Study with Binary Outcomes. Axioms, 14(8), 582. https://doi.org/10.3390/axioms14080582