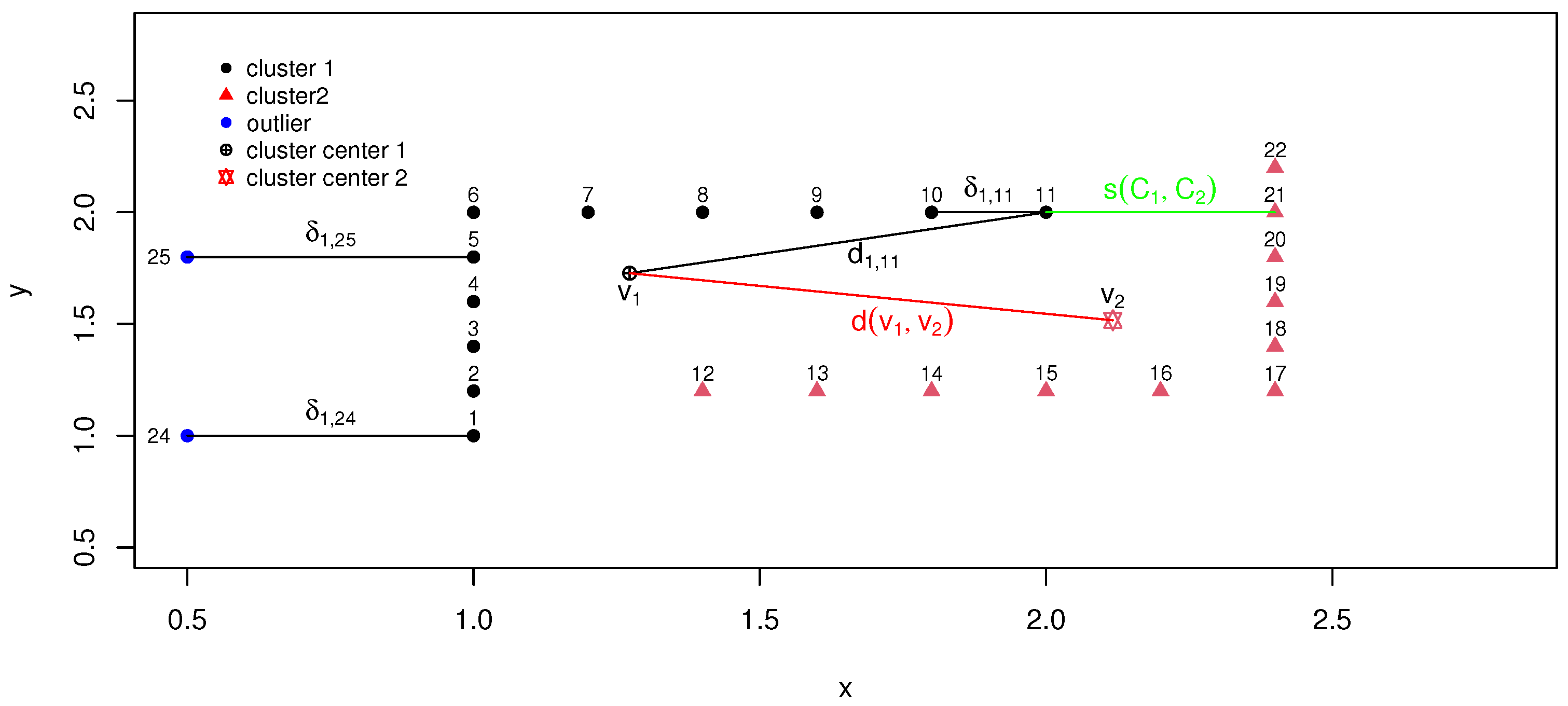
The primary utility of clustering validity indices (CVIs) lies in their capacity to identify the optimal number of clusters when the ground-truth cluster structure is unknown. To rigorously evaluate the effectiveness of various CVIs, benchmark synthetic datasets with well-defined cluster characteristics serve as invaluable tools for performance validation. In the synthetic dataset experiments conducted for visualization purposes, we systematically employ two-dimensional datasets to facilitate geometric interpretability, while maintaining algorithmic complexity comparable to higher-dimensional scenarios. These datasets are specifically designed to exhibit diverse clustering challenges, with the true number of clusters varying from 2 to 10. This experimental configuration enables a comprehensive assessment of CVIs’ discriminative power across varying degrees of cluster separability, density heterogeneity, and structural complexity, providing critical insights into their practical applicability in real-world scenarios where cluster boundaries may be ambiguous or overlapping. The two-dimensional parameterization strikes a strategic balance between computational tractability and the need for intuitive visualization of decision boundaries, ensuring both analytical rigor and interpretative clarity.
5.1.1. Well-Separated Datasets
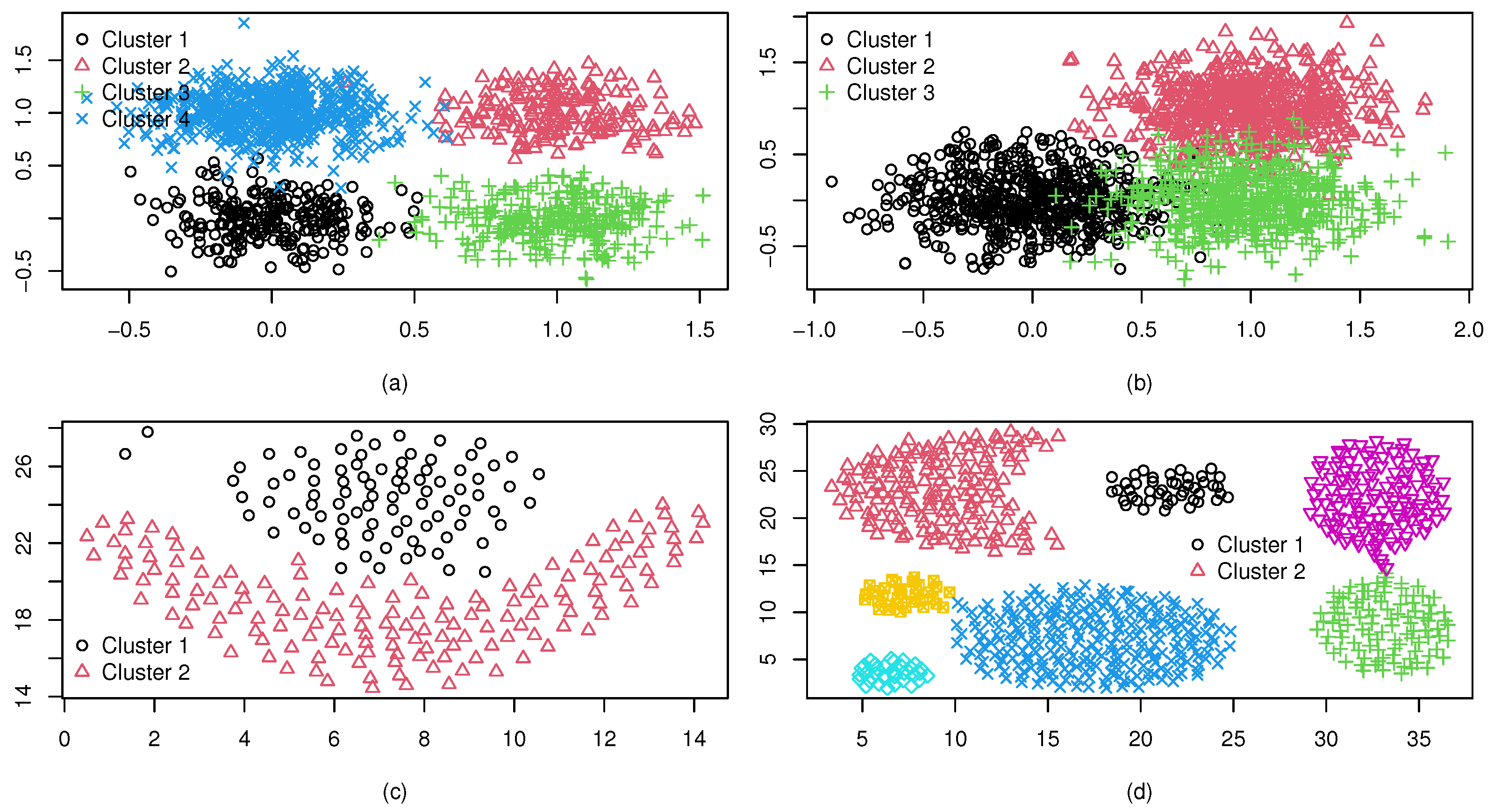
We consider some synthetic datasets with cluster shapes different from an ellipsoid, and denote them as
. The dataset
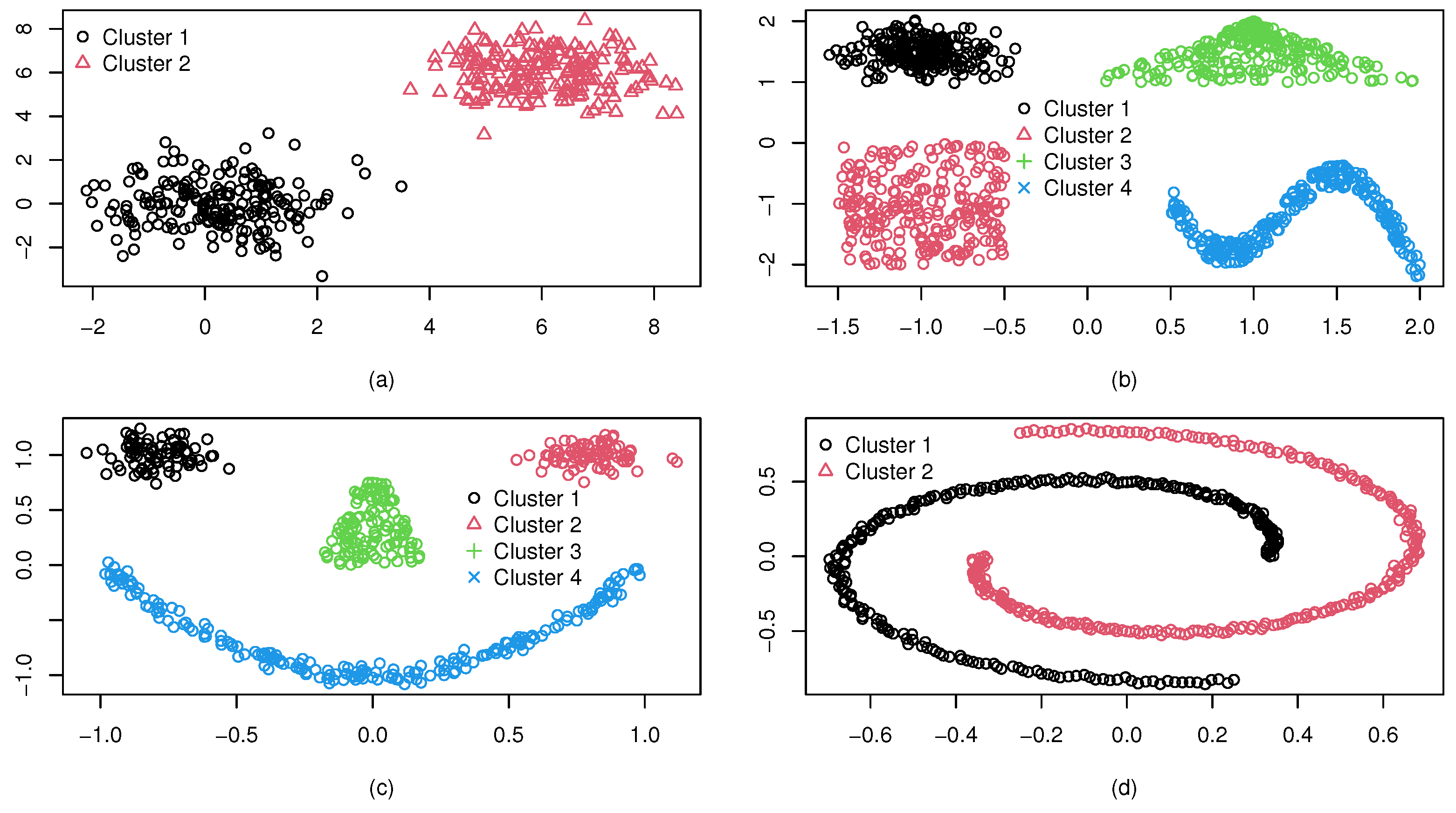
(a) consists of two isolated clusters, each with 200 observations generated from Gaussian distributions. Dataset
(b) consists of four isolated clusters with different shapes: elliptical, triangular, rectangular, and wave. In dataset
(c), there are also four isolated clusters of different shapes. However, the ellipsoid boundaries are not fully isolated, unlike the case in dataset
(b). Dataset
(d) contains two spiral clusters each of 250 observations. All the synthetic datasets are in two dimensions, which were randomly generated by using the package “‘mlbench’” in R.
Figure 4 shows the four synthetic datasets, and it can be seen that the cluster numbers of
(a)–(d) are 2, 4, 4, and 2, respectively.
To address the substantial discrepancies in results generated by different indices and enable their visualization within a unified coordinate system, we applied Min–Max normalization (Equation (
25)) to the outputs. This transformation scales all index values into the
interval while preserving the original ordinal relationships between values. By maintaining the relative ordering of scores, this preprocessing step facilitates direct comparative analysis across indices with distinct magnitude ranges, ensuring consistent interpretation within the standardized scale.
To eliminate clustering randomness, each experiment was repeated ten times, with the average results.
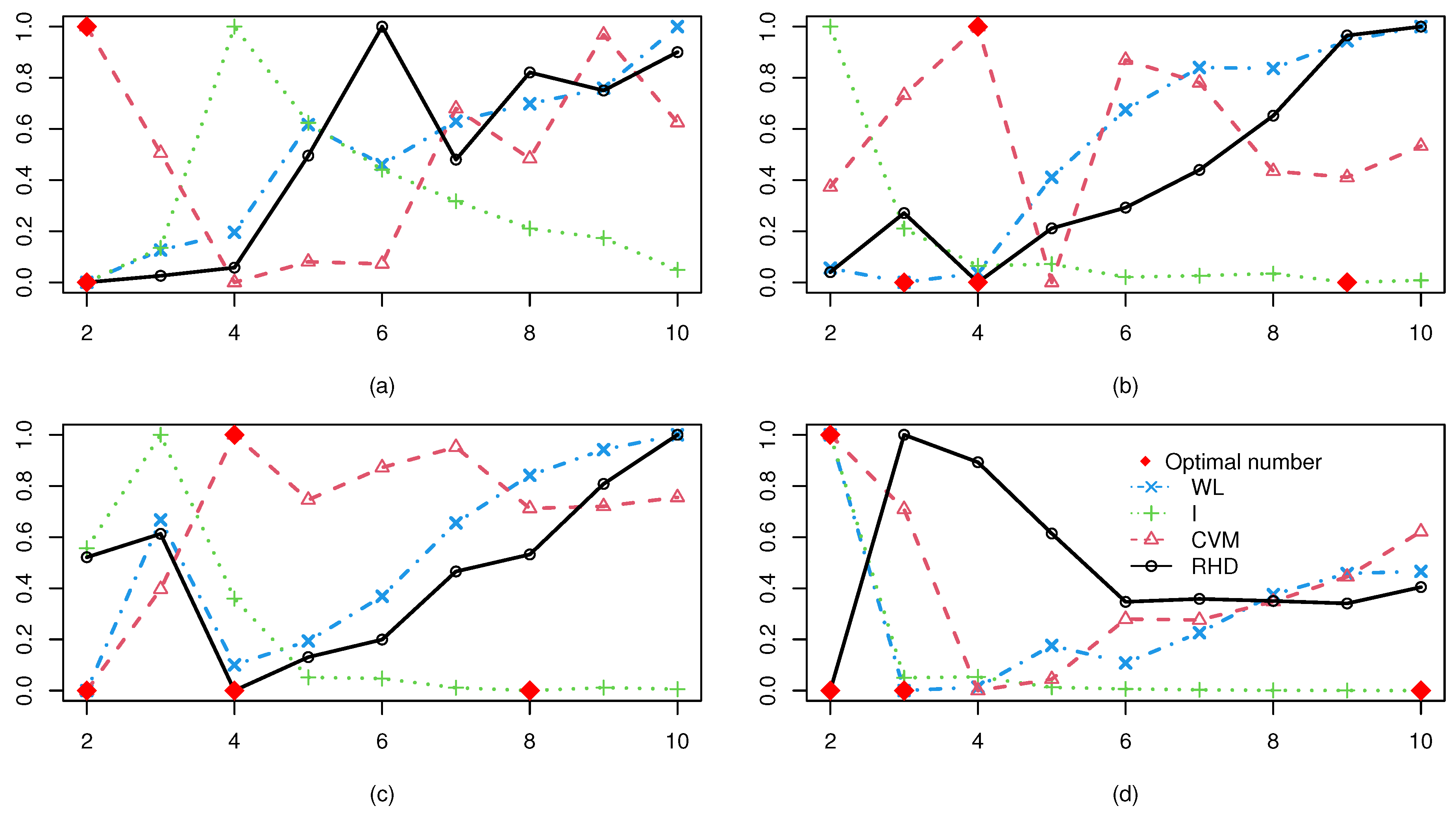
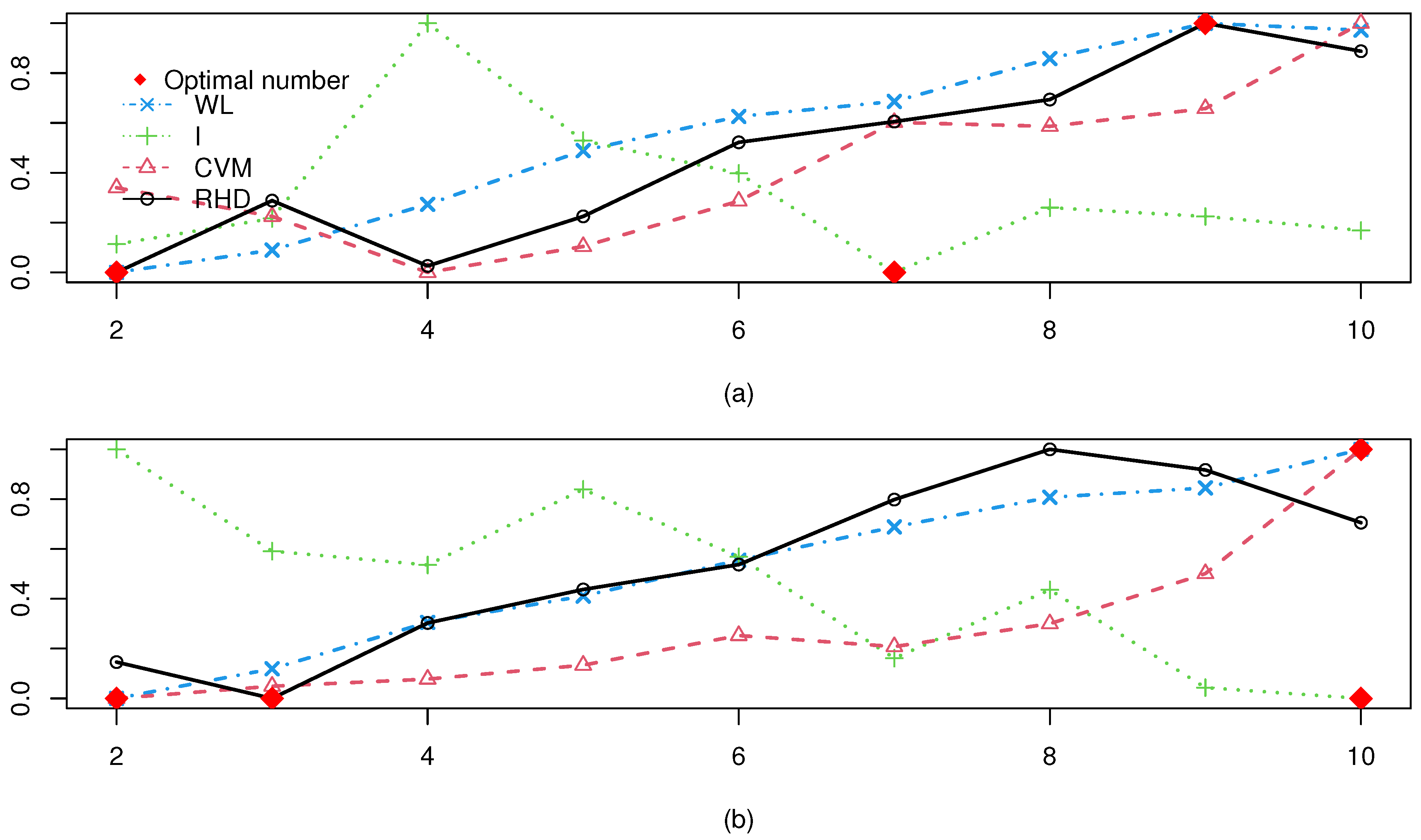
Figure 5 displays WL, I, CVM, and RHD index values from spectral clustering with varying cluster numbers for
(a)–(d). The optimal cluster count for each CVI is marked by a red diamond. Analysis shows that the RHD and CVM indices exhibit consistent reliability across all datasets, accurately identifying the true cluster numbers as 2, 4, 4, and 2 for
(a)–(d), respectively. This precision aligns with the ground-truth structures. In contrast, the WL and I indices achieve comparable accuracy only for
(a), but fail to determine optimal partitions for the other three datasets. These results highlight RHD and CVM’s superior adaptability to complex scenarios, particularly for non-convex distributions and varying dimensionality in the
series. This also proves that the WL and the I-index are only suitable for ellipsoidal clusters, even when well separated.
Table 1 evaluates the classification accuracy (%) of four CVIs—WL, I, CVM, and RHD—applied to dataset
(a)–(d). Key findings reveal a distinct performance hierarchy: CVM and RHD achieved 100% accuracy across all
variants, demonstrating robust adaptability to diverse data characteristics. In contrast, performance disparities emerged among other indices. While all CVIs attained 100% accuracy in
(a) (indicating ideal separability), the subsequent variants exposed limitations. Specifically, WL accuracy exhibited a V-shaped trend, declining from 75.00% (
(b)) to 50.00% (
(c)) before recovering to 86.80% (
(d)). Index I displayed marked instability, oscillating between 60.60% (
(d)) and 64.80% (
(c)) with an intermediate value of 64.00% (
(b)). Notably, the synergy between FSDP and CVM/RHD produced flawless classifications even in complex scenarios like
(c), where WL and I indices’ accuracy dropped below 65%. This underscores their enhanced resilience to challenges such as non-convex boundaries and noise interference. Collectively, these results highlight the critical role of CVI selection in ensuring algorithmic reliability.
5.1.2. Overlapped Datasets
In the preceding section, we rigorously demonstrated the exceptional discriminative capability of both CVM and the proposed RHD index for well-separated clusters. Building on this foundation, a more challenging question arises: whether RHD and CVM maintain proficiency in determining optimal cluster numbers when handling overlapping data distributions. This question directly investigates the robustness of the novel index under non-ideal conditions, specifically its ability to overcome the limitations of conventional validity measures that falter in detecting overlapping structures. Resolving this issue is pivotal for validating the algorithm’s practical applicability in complex real-world scenarios with compromised data separability.
Figure 6 presents four synthetic datasets with varying degrees of cluster overlap, designated as
(a)–(d). The first two datasets,
(a) and
(b), were algorithmically generated using stochastic sampling techniques to simulate controlled overlap scenarios. Specifically,
a comprises four clusters with moderate pairwise overlaps, as visualized in
Figure 6a, while
(b) (panel b) contains three clusters with highly complex inter-cluster boundaries and significant overlap regions. The latter two datasets,
(c)–(d), were selected from established clustering datasets
https://github.com/milaan9/Clustering-Datasets (accessed on 15 June 2025) benchmarks to introduce real-world complexity. Dataset
(c) (
Figure 6c) corresponds to the renowned “Frame” structure, featuring a flame-like bimodal distribution with ambiguous decision boundaries between two elongated clusters. Of particular interest is dataset
(d) (
Figure 6d), the aggregation benchmark, which consists of seven clusters with heterogeneous geometries: a crescent moon, dual balloon-shaped clusters, and four ellipsoidal clusters of varying sizes and densities. This configuration introduces substantial overlaps between adjacent clusters while preserving distinct morphological features, creating a challenging validation scenario for clustering validity indices.
Table 2 summarizes the clustering validity results for datasets
(a)–(d), with
denoting the ground-truth cluster count. The boldfaced values indicate correctly identified optimal cluster counts. In
Table 2, all experiments were repeated 10 times; the notation
represents the algorithm’s determination that
a is the optimal cluster number in
b out of 10 independent trials. For instance, regarding dataset
, the notation
under the WL index indicates that, across 10 experiments, the WL index determined the optimal number of clusters as three in six cases and as two in four cases.
The analysis of results presented in
Table 2 reveals that for the
(a) dataset, both the I index and RHD correctly identified the true cluster count (four clusters). This demonstrates their superior discriminative ability for ellipsoid-shaped clusters with mild overlaps, where conventional metrics may struggle with boundary ambiguity. The consistent success across 10 trials (10/10 for I and RHD) underscores their robustness in this scenario. For the
(b) dataset: This highly overlapping dataset (three clusters) posed significant challenges. RHD achieved remarkable performance with 8/10 correct identifications, while all other indices failed completely. This highlights RHD’s enhanced capability to resolve complex decision boundaries in densely overlapping structures, a critical advantage over existing metrics. For the
(c) dataset (Frame): The flame-like bimodal distribution with ambiguous boundaries was accurately resolved by WL and RHD (both 10/10). Conversely, I and CVM failed to detect the correct two-cluster structure, indicating their sensitivity to elongated, non-convex geometries where density gradients become critical. For the
(d) dataset (Aggregation): This heterogeneous benchmark (seven clusters) introduced morphological diversity and varying overlaps. Interestingly, I demonstrated partial success (3/10) by occasionally capturing dominant density patterns, while RHD and WL failed completely. CVM’s rare success (1/10) suggests its susceptibility to noise in multi-scale cluster configurations. This dataset exposes limitations of all the indices in highly heterogeneous environments.
As evidenced by the cross-algorithm accuracy comparisons in
Table 2, the proposed RHD index consistently outperforms existing metrics, achieving 70.00% overall accuracy (28/40 cases)—a 37.5 percentage point improvement over the suboptimal I index (32.50%). While the WL index ranked third (25.00%), the CVM metric exhibited severe limitations in resolving non-linear manifold structures, attaining only 2.50% accuracy. This stark contrast underscores the vulnerability of CVM’s feature-space partitioning strategy to local optima within high-dimensional, geometrically complex data regimes.
The experiments reveal RHD’s exceptional versatility across mild-to-severe cluster overlaps and geometric complexities. Its superior performance in (b) and (c) validates its robustness to boundary ambiguity and non-convex structures. While Index I exhibits niche strengths in specific morphologies ((a) and (d)), Index I’s inconsistency across datasets contrasts with RHD’s reliable pattern recognition. These findings underscore RHD’s potential for real-world clustering challenges with compromised data separability, offering significant methodological advances over traditional validity indices.
Based on the cross-dataset results in
Table 2, the RHD index exhibits significant advantages in low-to-moderate overlap scenarios (e.g., 100% correct identification in
(a)). Crucially, in the highly overlapping
(d), it maintains an 80% correct identification rate. Although Index I matches RHD’s performance in simple structures (
(a)), its discriminative ability deteriorates significantly with increasing data complexity (
(c)–(d)). This contrast highlights RHD’s robustness to inter-cluster boundary ambiguity, with its core advantage lying in joint modeling of the local density and global separation.
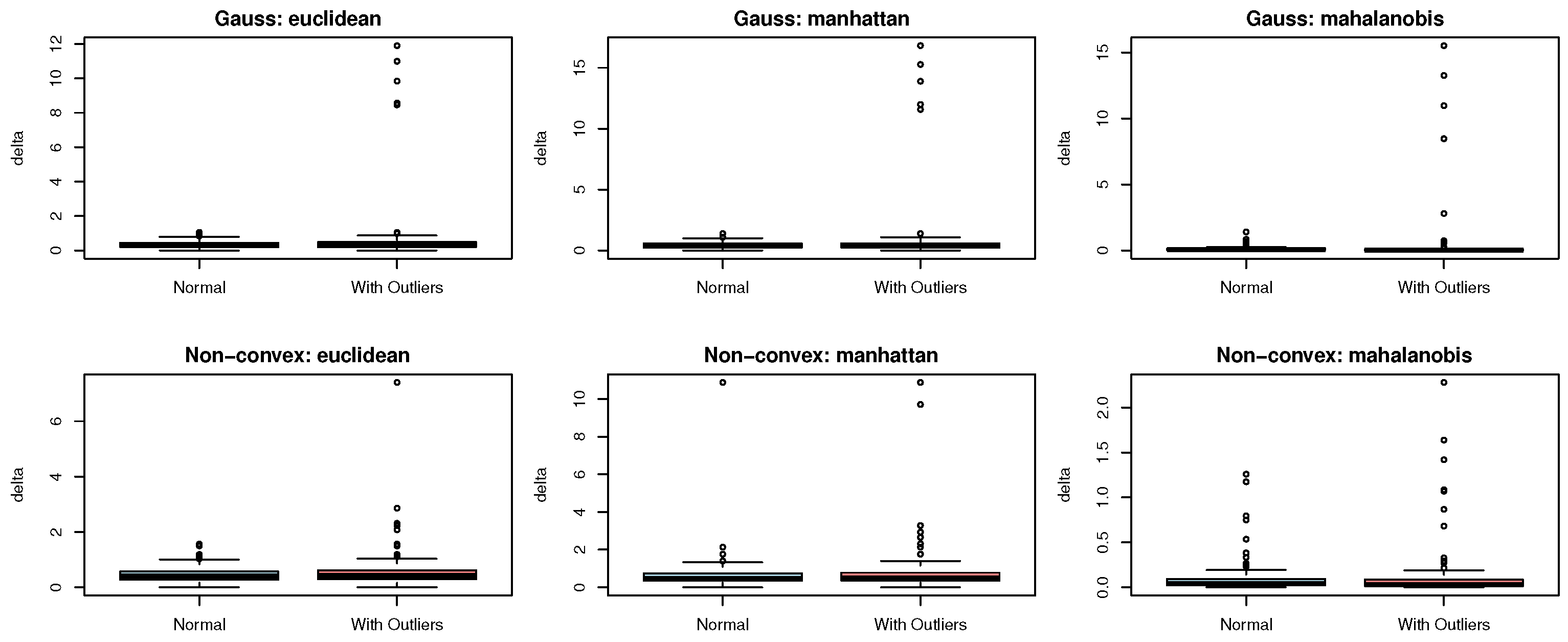
However, RHD exhibits a key limitation in hybrid cluster structures, when datasets contain both well-separated clusters and overlapping clusters (e.g., the aggregation structure (d)), as this index tends to over-merge overlapping regions. Mechanism analysis reveals that this phenomenon stems from the definition of the inter-class difference measure . Specifically, yields higher values for well-separated clusters but decreases significantly for overlapping clusters. When both types coexist, the global mean is depressed by low-value overlapping regions; according to the formula, a reduced denominator s inversely amplifies the index value. Consequently, the algorithm mistakenly believes merging overlapping clusters improves clustering quality. The failure of CVM arises because increasing cluster counts shrink , causing the compactness to rise progressively. This ultimately elevates the CVM values. Since larger CVM values indicate better clustering, the cluster number may be overestimated.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}