Abstract
Let be a supercritical branching process with offspring distribution such that and , where . The Lotka–Nagaev estimator is an important estimator for the offspring mean . In this paper, we establish a self-normalized large deviation result and self-normalized Cramér type moderate deviations for the Lotka–Nagaev estimator. An application to constructing confidence intervals for m is also discussed.
MSC:
60F10; 60J80; 62F12; 62F03
1. Introduction
A branching process can be described as follows: for all ,
where stands for the offspring number of the i-th individual of the generation n. We assume that the random variables are independent of each other and share a common distribution law as follows:
Moreover, they are also independent of . An important task for the branching processes is to estimate the offspring mean m of an individual. Clearly, it holds
All over the paper, we assume that and denote , which means each individual has at least offsprings. To avoid the deterministic case, we also assume that The Lotka–Nagaev [1,2] estimator is an important estimator for the estimation of the offspring mean m. It is obvious that almost surely (a.s.) as . Thus, according to the strong law of large numbers, it holds as ,
Thus, the Lotka–Nagaev estimator is well defined -a.s.
For the branching processes, Athreya [3] has established large deviation principles for the normalized Lotka–Nagaev estimator; Ney and Vidyashankar [4,5] and He [6] obtained some rate estimates for the large deviations of the Lotka–Nagaev estimator; Bercu and Touati [7] gave some exponentially large deviation inequalities for the Lotka–Nagaev estimator with self-normalized martingale methods. When , Chu [8] has established a sharp self-normalized large deviation result, see also Fan and Shao [9,10] for self-normalized Cramér type moderate deviations for the weighted Lotka–Nagaev estimator. Recently, Doukhan et al. [11] obtained some standardized Cramér moderate deviations for the Lotka–Nagaev estimator. Cramér moderate deviations have attracted a lot of attention. We refer to Petrov [12], Beknazaryan, Sang and Xiao [13], Fan and Shao [14] for such results. For the self-normalized Cramér type moderate deviations, we refer to Jing et al. [15], Fan, Hu and Xu [16] and Fan and Shao [9]. The advantage of self-normalized Cramér moderate deviations lays in the fact that it adopts to the case that the variances of random variables are unknown.
Despite the fact that the Lotka–Nagaev estimator is well studied, there is no result for self-normalized large deviation principles and Cramér type moderate deviations for the Lotka–Nagaev estimator, provided that . The main goal of this paper is to fill this gap.
The paper is organized as follows: In Section 2, we present a self-normalized large deviation principle result and some self-normalized Cramér type moderate deviations for the Lotka–Nagaev estimator, provided that . In Section 3, we give an application of self-normalized Cramér type moderate deviations to constructing confidence intervals of m. The remaining sections in the paper are devoted to the proofs of theorems and their corollaries.
2. Main Results
The following theorem gives a self-normalized large deviation principle for supercritical branching processes in the case that and for some .
Theorem 1.
Assume and let . For all , then there exists such that
Remark 1.
Some remarks on Theorem 1 follow.
- 1.
- Assume the conditions of Theorem 1. Ney and Vidyashankar [5] have established the following large deviation result: If for some constant , then there exists such that for all ,Obviously, Theorem 1 gives an extension of the last result to the self-normalized case. Compared with the last result (4), Theorem 1 holds without the moment generating function.
- 2.
- Assume that and . Ney and Vidyashankar [5] proved that if for some constant , then there exists a positive function such that it holds for all ,For the explicit expression of , we refer to Ney and Vidyashankar [5]. Chu [8] obtained a self-normalized version of (5): There exists a function such that it holds for all ,For the explicit expression of , we refer to Theorem 1 of Chu [8].
Assume that the random variables can be observed. Let
be the t-statistic for the Lotka–Nagaev estimator . Denote the standard normal distribution function. We have the following self-normalized Cramér type moderate deviations for .
Theorem 2.
Assume and let . If for some , then it holds
uniformly for , . Furthermore, this equality remains true when is substituted with .
Remark 2.
Compared with the normalized Cramér moderate deviations (cf. Doukhan et al. [11]), the advantage of self-normalized Cramér moderate deviations lies in the fact that Theorem 2 holds without the existence of a moment generating function, and that it is applicable provided the variance of is unknown.
From Theorem 2, by the inequality for all , we obtain the following corollary with respect to the relative error of the normal approximation.
Corollary 1.
Assume that the conditions of Theorem 2 are satisfied. Then it holds
uniformly for , . In particular, the last equality implies that
holds uniformly for , . Moreover, the same equalities also hold when is replaced by .
For the equality (10), we can see that the relative error of normal approximation for tends to zero uniformly for , .
Moreover, Theorem 2 also implies the following self-normalized MDP result.
Corollary 2.
Assume the conditions of Theorem 2 are satisfied. Denote as any sequence of real positive numbers satisfying and as . For each Borel set B, we have
where and are the interior and the closure of B, respectively.
By Theorem 2, we can deduce the following Berry–Esseen bound for the self-normalized process .
Corollary 3.
Assume that the conditions of Theorem 2 are satisfied. The following inequality holds
where is a constant that does not depend on n.
3. Simulation Study for Corollary 1
Next, we give a simulation study for Corollary 1. Denote , where is given by (2). We consider the case and
Figure 1 and Figure 2 show the simulated ratios From the figures, we see that the ratios are close to 1 for x less than Moreover, as x moves away from 0, the ratios fluctuate wildly, which means the normal approximations for become worse. This feature coincides with (9).
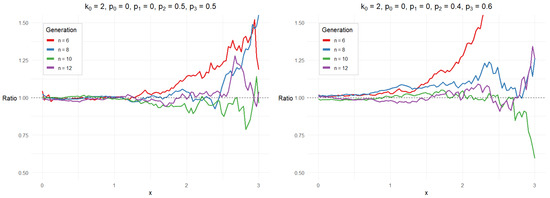
Figure 1.
Ratios for and .
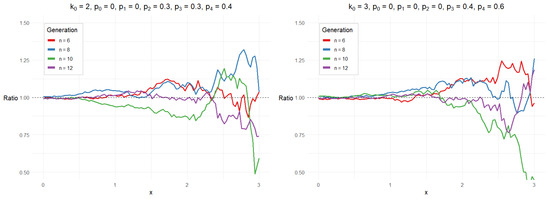
Figure 2.
Ratios for and .
4. Application to Constructing Confidence Intervals of
Assume that the offspring numbers can be observed for some n. By self-normalized Cramér type moderate deviations, we have the following result for constructing confidence intervals of m.
Proposition 1.
Assume that the conditions of Theorem 2 are satisfied. Let such that it holds
Denote
Then is a 1- confidence interval for m as n is large enough, where
Proof.
By Corollary 1, the following equalities
hold uniformly for , . Denote the inverse function of the standard normal distribution function . Then it satisfies the following asymptotic expansion
When the condition (13) is satisfied, it holds ). Thus is of order as . Then, applying the last equality to (15), we obtain
Clearly, the inequality is equivalent to while is equivalent to Then we complete the proof of Proposition 1. □
5. Proof of Theorem 1
The proof of Theorem 1 is based on the following technical lemma of Shao [17] and the total probability formula. The total probability formula allows us to fix the population such that the large deviation probabilities can be approximated by the self-normalized large deviation principle of Shao [17].
For self-normalized sums of independent random variables, Shao [17] has established the following large deviation principle.
Lemma 1.
Let be i.i.d. random variables. Assume that . Denote and . Then it holds for any ,
In the sequel, we present the proof of Theorem 1. Denote
Let be a sequence of independent random variables with the same distribution as . For a deterministic sample size k, denote
Then we have and
When , the probability in (3) can be reformulated as
By the assumption of the theorem, it holds and , where . Thus, it holds a.s. for any integer . Recall that and are independent. By the total probability formula, we obtain for any
Now, we divide the term into two parts
For , we have the following estimation
Note that
Thus, the second term in (21) can be reformulated as
According to Lemma 1 with centered variables , for any small positive , it holds for all the integers t to be large enough,
where
Similarly, for the second term on the right-hand side of (22), it holds for all integers t to be large enough,
where
Similarly, for any , we can deduce that for any positive and all integers t to be large enough,
where
By an argument similar to the estimation of , we can deduce that for any positive it holds for all integers t to be large enough,
with some . Now we define and choose a such that . Therefore, by (21)–(26), we can deduce that for any and all the n to be large enough,
Thus, when , the probability (20) can be rewritten as follows: For any
By taking logarithms of both sides, we can deduce that for any
where . This completes the proof of Theorem 1.
6. Proof of Theorem 2
The proof of Theorem 2 is based on the following technical lemma of Jing et al. [15] and the total probability formula. For self-normalized sums of independent random variables, Jing et al. [15] have established the following self-normalized Cramér moderate deviation.
Lemma 2.
Let be a sequence of i.i.d. and centered random variables. Assume there exists a constant such that . Denote and . Then it holds
uniformly for , .
Recall that is the number of individuals in the n-th generation, and , , is the offspring number of the i-th individual in the n-th generation. Denote
Then it holds
Therefore, we can rewrite as follows
Recall that and are independent. By the law of total probability, we can deduce that for any ,
For any integer , it is easy to see that for all ,
We first give an estimation for . Recall that are independent of . When , by Lemma 2, we obtain for all ,
Using the inequalities
we can deduce that for all and ,
Using the last inequality, we deduce that for all and all ,
which gives an estimation of .
Next, we consider the estimation of . Notice that
Then we have
Applying Lemma 2 to the centered random variables we deduce that for all and all ,
where the last inequality follows by (32). Again by (32), we obtain for all and all ,
which gives an estimation of .
Combining (32), (34) and (35) together, we obtain for all and all ,
Returning to (31), by the last inequality, we deduce that for all ,
Next, we give an estimation for the lower bound of . For , it is easy to see that for all and all ,
When , by Lemma 2, we obtain for all ,
Returning to (31), we obtain for all ,
Combining (37) and (38) together, we obtain the desired inequality.
The same argument holds for . Therefore, the first equality also holds when is replaced by . Then we complete the proof of Theorem 2.
7. Proof of Corollary 2
Firstly, we show that it holds for any Borel set B,
Indeed, when , the equality (39) holds obviously. When , for and , define . Then, by Theorem 2, we obtain
Notice the fact that and . Combining the above inequality with (32), we obtain
Notice that when , then
which gives (39).
Next, we show that the following lower bound holds
When , the last inequality holds obviously. When , as is an open set, for any small enough, we can find an such that the following inequalities hold
Since is an open set, for and some small , we have . Then,
By Theorem 2, we can deduce that when and , it holds
By (32) and the last equality, we deduce that there exists a large number N such that for all ,
which implies that
Letting , we obtain (43). Combining inequalities (39) and (43) together, we obtain the desired result.
8. Proof of Corollary 3
Author Contributions
Writing—original draft, P.D., H.H., T.M. and C.Z. All authors contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Natural Science Foundation of Hebei Province (Grant no. A2025501005).
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
The authors deeply indebted to the editor and the anonymous referees for their helpful comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lotka, A. Theorie analytique des assiciation biologiques. Actualités Sci. Ind. 1939, 780, 123–136. [Google Scholar]
- Nagaev, S.V. On estimating the expected number of direct descendants of a particle in a branching process. Theory Probab. Appl. 1967, 12, 314–320. [Google Scholar] [CrossRef]
- Athreya, K.B. Large deviation rates for branching processes. I. Single type case. Ann. Appl. Probab. 1994, 4, 779–790. [Google Scholar] [CrossRef]
- Ney, P.E.; Vidyashankar, A.N. Harmonic moments and large deviation rates for supercritical branching processes. Ann. Appl. Probab. 2003, 13, 475–489. [Google Scholar] [CrossRef]
- Ney, P.E.; Vidyashankar, A.N. Local limit theory and large deviations for supercritical branching processes. Ann. Appl. Probab. 2004, 14, 1135–1166. [Google Scholar] [CrossRef]
- He, H. On large deviation rates for sums associated with Galton-Watson processes. Adv. Appl. Probab. 2016, 48, 672–690. [Google Scholar] [CrossRef]
- Bercu, B.; Touati, A. Exponential inequalities for self-normalized martingales with applications. Ann. Appl. Probab. 2008, 18, 1848–1869. [Google Scholar] [CrossRef]
- Chu, W. Self-normalized large deviation for supercritical branching processes. J. Appl. Probab. 2018, 55, 450–458. [Google Scholar] [CrossRef]
- Fan, X.; Shao, Q.M. Self-normalized Cramér moderate deviations for a supercritical Galton-Watson process. J. Appl. Probab. 2023, 60, 1281–1292. [Google Scholar] [CrossRef]
- Fan, X.; Shao, Q.M. Self-normalized Cramér type moderate deviations for martingales and applications. Bernoulli 2025, 31, 130–161. [Google Scholar] [CrossRef]
- Doukhan, P.; Fan, X.; Gao, Z.Q. Cramér moderate deviations for a supercritical Galton-Watson process. Statist. Probab. Letters 2023, 192, 109711. [Google Scholar] [CrossRef]
- Petrov, V.V. Sums of Independent Random Variables; Springer: Berlin, Germany, 1975. [Google Scholar]
- Beknazaryan, A.; Sang, H.; Xiao, Y. Cramér type moderate deviations for random fields. J. Appl. Probab. 2019, 56, 223–245. [Google Scholar] [CrossRef]
- Fan, X.; Shao, Q.M. Cramér’s moderate deviations for martingales with applications. Ann. Inst. H. Poincaré Probab. Statist. 2024, 60, 2046–2074. [Google Scholar] [CrossRef]
- Jing, B.Y.; Shao, Q.M.; Wang, Q. Self-normalized Cramér-type large deviations for independent random variables. Ann. Probab. 2003, 31, 2167–2215. [Google Scholar] [CrossRef]
- Fan, X.; Hu, H.; Xu, L. Normalized and self-normalized Cramér-type moderate deviations for Euler-Maruyama scheme for SDE. Sci. China Math. 2024, 67, 1865–1880. [Google Scholar] [CrossRef]
- Shao, Q.M. Self-normalized large deviations. Ann. Probab. 1997, 25, 285–328. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).