
On the Bayesian Two-Sample Problem for Ranking Data


Abstract
1. Introduction
2. One-Sample Angle-Based Model
2.1. Maximum Likelihood Estimation (MLE)
2.2. Bayesian Method with Conjugate Prior
3. Two-Sample Problem
| Criterion | Interpretation |
| 1 ≤ BF < 3 | Weak evidence for |
| 3 ≤ BF < 10 | Moderate evidence for |
| BF ≥ 10 | Strong evidence for |
| BF < 1/3 | Moderate evidence for |
| BF < 1/10 | Strong evidence for |
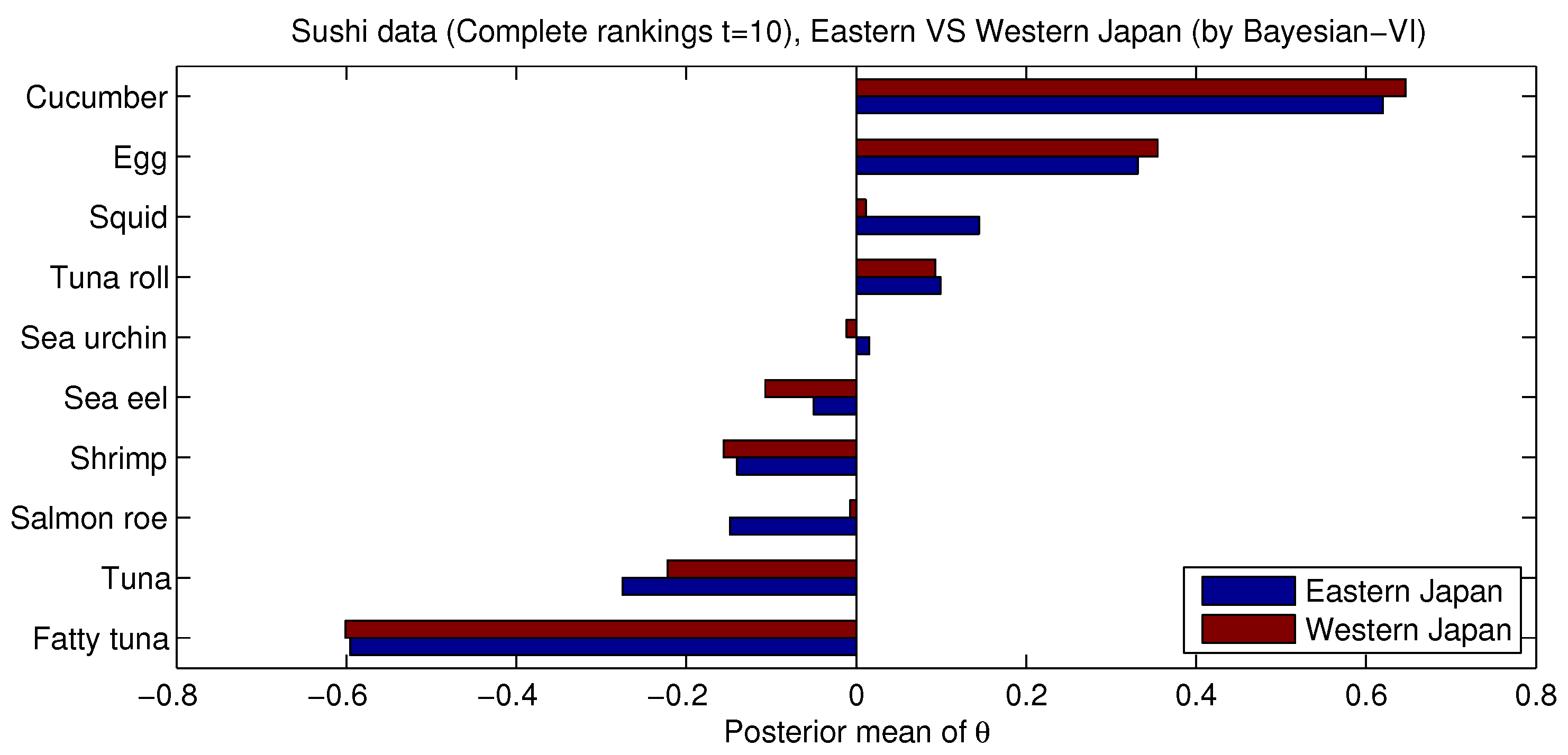
4. Application
5. Conclusions and Discussion
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alvo, M.; Yu, P. Statistical Methods for Ranking Data; Springer: New Yrok, NY, USA, 2014. [Google Scholar]
- Fagin, R.; Kumar, R.; Sivakumar, D. Comparing top k lists. SIAM J. Discret. 2003, 17, 134–160. [Google Scholar] [CrossRef]
- Xu, H.; Alvo, M.; Yu, P. Angle-based models for ranking data. Comput. Stat. Data Anal. 2018, 121, 113–136. [Google Scholar]
- Banerjee, A.; Dhillon, I.; Ghosh, J.; Sra, S. Clustering on the unit hypersphere using von Mises-Fisher distributions. J. Mach. Learn. Res. 2005, 6, 1345–1382. [Google Scholar]
- Nunez-Antonio, G.; Gutiérrez-Pena, E. A bayesian analysis of directional data using the von misesfisher distribution. Commun.-Stat.-Simul. Comput. 2005, 34, 989–999. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Kass, R.E.; Raftery, A.E. Bayes factors. J. Am. Stat. Assoc. 1995, 90, 773–795. [Google Scholar]
- Kamishima, T.; Akaho, S. Efficient clustering for orders. In Proceedings of the 2nd International Workshop on Mining Complex Data, Hong Kong, China, 18–22 December 2006; pp. 274–278. [Google Scholar]


{kind=link}
{kind=link}
| Posterior Parameter | Eastern Japan | Western Japan |
|---|---|---|
| 1458.85 | 741.61 | |
| a | 18,509.84 | 9462.70 |
| b | 3801.57 | 2087.37 |
| Posterior Mean of | 4.87 | 4.53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alvo, M. On the Bayesian Two-Sample Problem for Ranking Data. Axioms 2025, 14, 292. https://doi.org/10.3390/axioms14040292
Alvo M. On the Bayesian Two-Sample Problem for Ranking Data. Axioms. 2025; 14(4):292. https://doi.org/10.3390/axioms14040292
Chicago/Turabian StyleAlvo, Mayer. 2025. "On the Bayesian Two-Sample Problem for Ranking Data" Axioms 14, no. 4: 292. https://doi.org/10.3390/axioms14040292
APA StyleAlvo, M. (2025). On the Bayesian Two-Sample Problem for Ranking Data. Axioms, 14(4), 292. https://doi.org/10.3390/axioms14040292