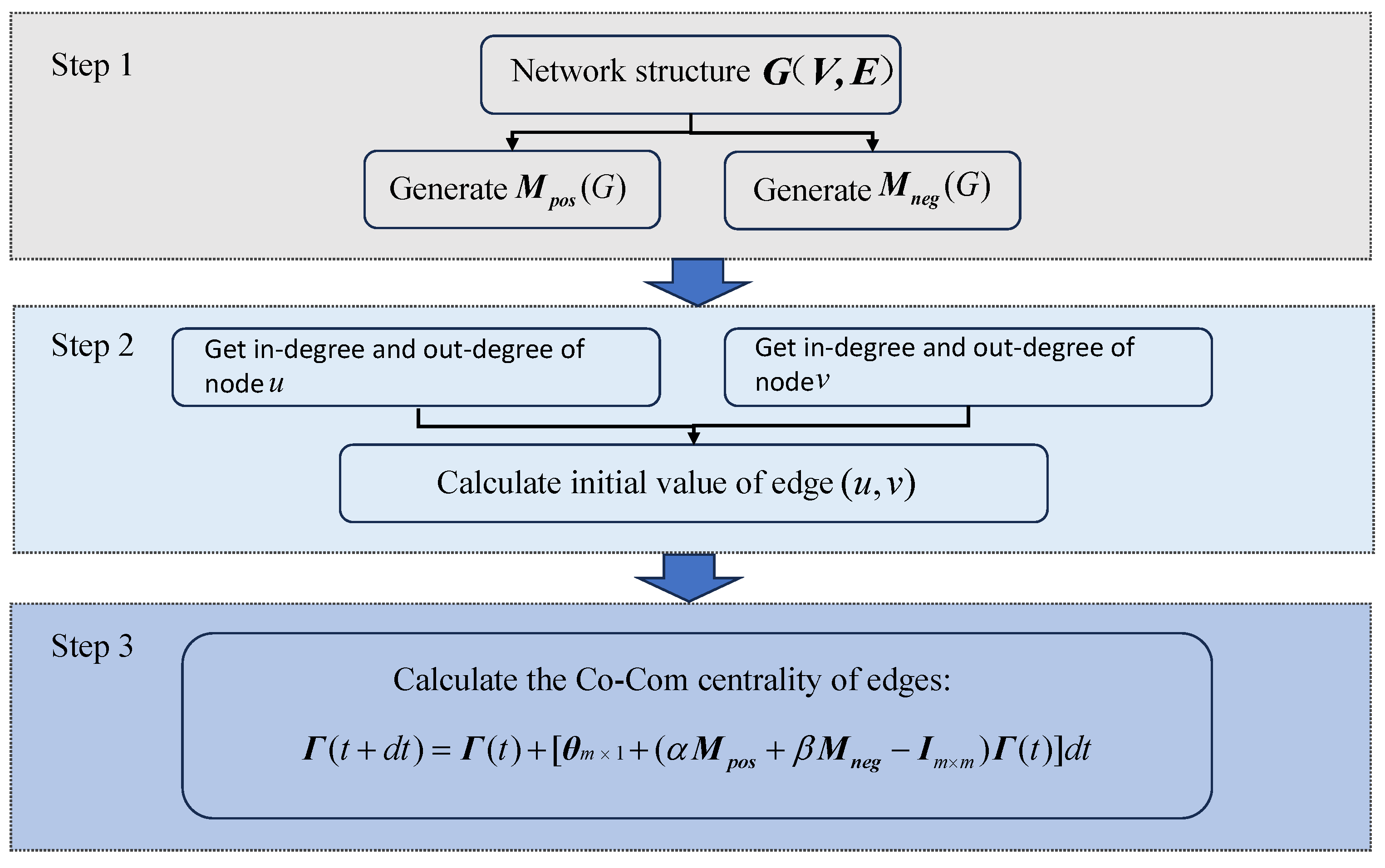
3.1. Definition of Co-Com Centrality
A classic idea [
28] holds that, in network transportation, the higher the frequency with which an edge serves as a path that must be traversed from one region to another, the greater its importance. Guided by this idea, we propose a method to measure the importance of edges in a directed graph by utilizing local information, that is, to define the importance of an edge by using all the edges that have the same nodes with this edge. For a directed edge
,
u is the source and
v is the target; the more edges that point to
u and the more edges that originate from
v, the more important the edge
is. If there are other edges originating from
u or other edges pointing to
v, the irreplaceability of
will reduce, and the importance of
will also reduce. So the importance of edge
is defined as
where
u is the source of a directed edge, and
v is the target of the directed edge.
is the in-degree of
u,
is the out-degree of
u,
is the in-degree of
v, and
is the out-degree of
v. Consider that
and
are at least one because there is an edge from
u to
v. We do not use multiplication because for those edges where the in-degree of
u is 0 or the out-degree of
v is 0, using multiplication will make their importance become 0, which will reduce the discriminability of edge importance. For weighted networks, we only need to change Equation (
7) to Equation (
8),
where
p is the set of the predecessors of node
u,
q is the set of the successors of node
u,
r is the set of the successors of node
v, and
s is the set of the predecessors of node
v.
is the weight of edge (
). The experiments in
Section 4 show that the edge importance defined by Equation (
7) can already identify important edges quite well. However, the edge importance defined solely by local information poses problems in certain situations. See
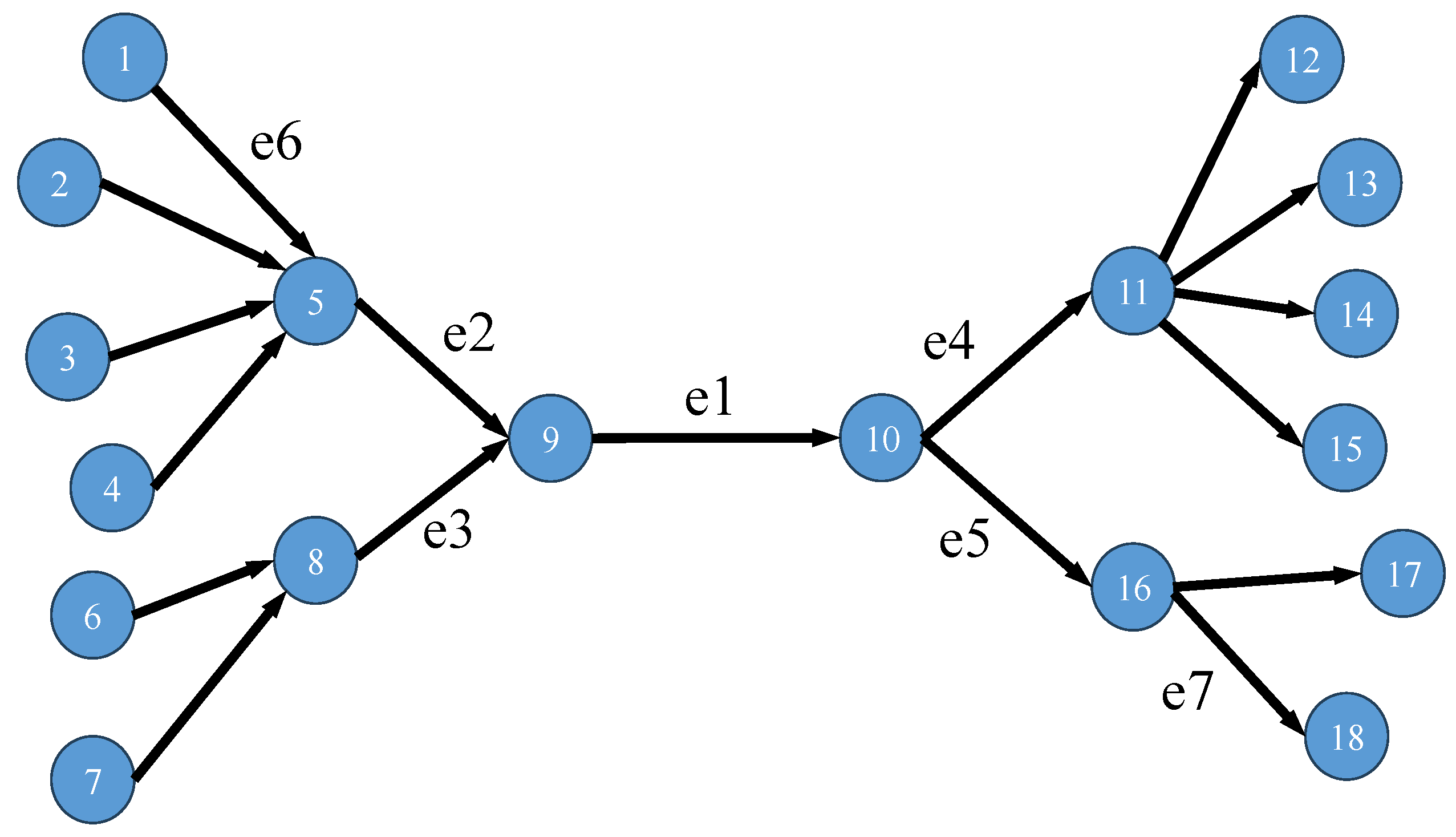
Figure 1; from the perspective of maintaining the network structure, it is obvious that
is the most important edge but, according to Equation (
7), the importance value of
is
and the importance value of
is 4. This is because Equation (
7) only takes local information into account. We need a method to consider global information, the whole network.
Our proposed method is inspired by some simple physical phenomena: assume that there is a directed river network. (i) If the flow of a river increases, the flow of its downstream rivers will increase accordingly; () if the flow of a river increases, we can speculate that the flow of its upstream rivers has increased; () assume river A and river B have the same upstream, then the flow of either A or B will not increase indefinitely; when the flow of A becomes too high, more water from the upstream will flow into B; then, the flow of A will relatively decrease; () assume river C and river D have the same downstream, then the flow of either C or D will not decrease indefinitely; when the flow of C becomes too low, more water from D will flow into downstream; the flow of C will relatively increase.
We map this relationship in a river network into a directed network and use
Figure 1 for illustration. Regard the flow of river as a kind of edge importance; then, for the directed network, the importance of each edge will satisfy the following relation: (
i) the importance of edge (
) is positively correlated with the importance of the predecessor edges of node
u (the importance of
is positively correlated with
); (
) the importance of edge (
) is positively correlated with the importance of the successor edges of node
v (the importance of
is positively correlated with
); (
) the importance of edge (
) is negatively correlated with the importance of the successor edges of node
u (the importance of
is negatively correlated with the importance of
); (
) the importance of edge (
) is negatively correlated with the importance of the predecessor edges of node
v (the importance of
is negatively correlated with
).
Regarding positive correlation as cooperation and negative correlation as competition, we propose Co-Com Centrality (Cooperation–Competition Centrality); cooperation matrix
and competition matrix
are defined to describe cooperation and competition. The diagonal elements of
are 0, the other elements are 0 or 1; if
is 1, it indicates that the
ith edge and the
jth edge have a cooperative relationship. The diagonal elements of
are also 0, but the difference is that the elements are represented by 0 or
; if
is
, it indicates that the
ith edge and the
jth edge have a competition relationship.
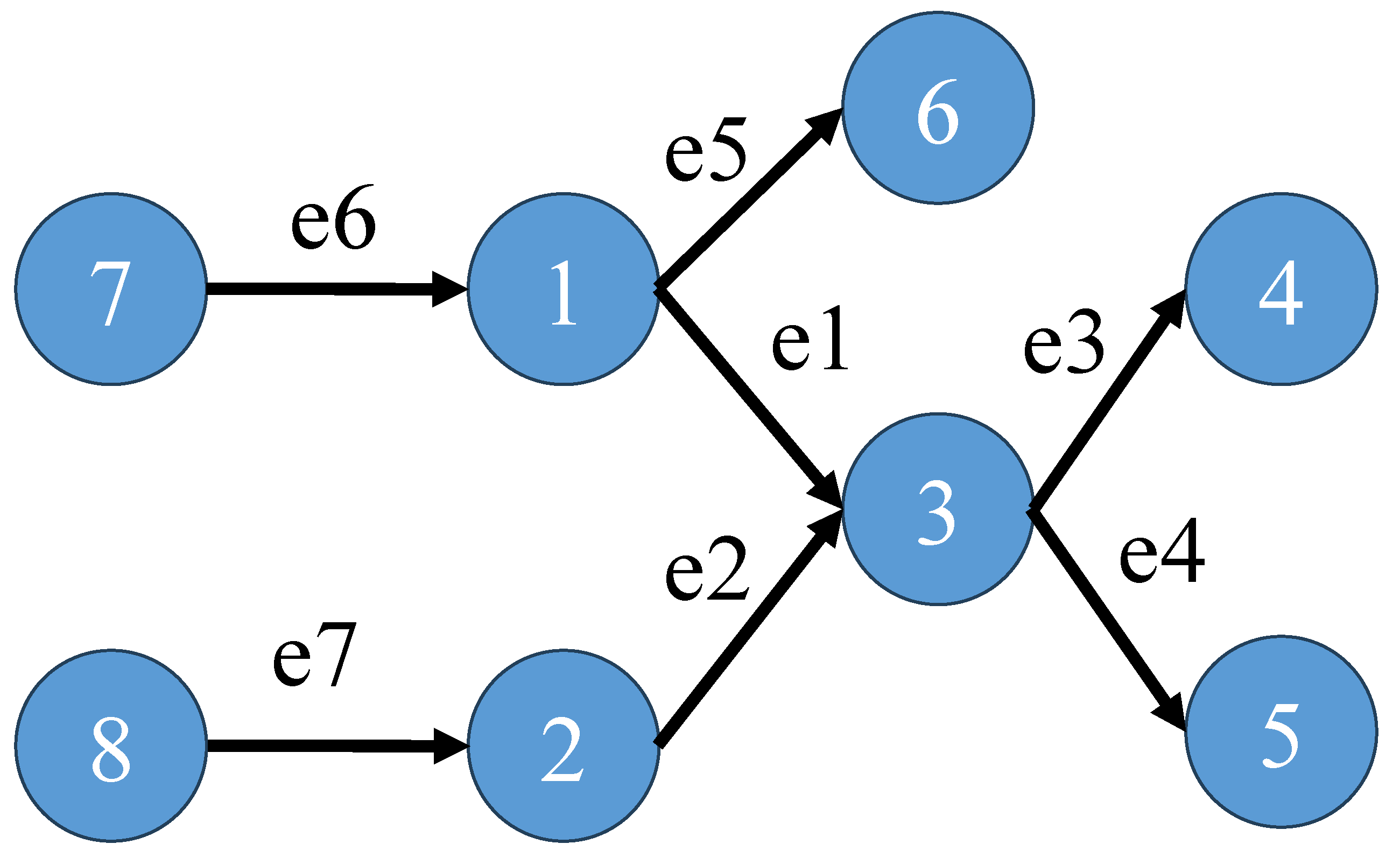
Figure 2 gives a simple example to demonstrate the cooperation matrix and the competition matrix; in this network,
competes with
,
and cooperates with
,
,
;
and
are shown as Equation (9).
We propose Co-Com Centrality, which can identify important edges in a directed network, while also being applicable to weighted directed networks. When using Co-Com Centrality analysis for a real-world network, make sure that, for the real-world network, the initial importance of an edge can be expressed using Equation (
7). For example, for transportation networks, a road is important when two regions are connected by only this road (the importance of the road can, to some extent, be quantified through Equation (
7)); however, for a word adjacency network, the edge direction only describes the relative positions of linked words in a sentence. In other words, for word adjacency networks, the importance of edges cannot be described by Equation (
7).
For a directed network with
n nodes and
m edges, Co-Com Centrality is defined as the stationary solution of the following differential equations
a higher value denotes that the edge is more important, where
and
,
, and
,
t is the time variable of the differential equations; it actually refers to the process in which the solution of the equations tends to be stationary. The edges’ importance compete and cooperate with each other over
t until the importance of each edge is stationary.
is initial centrality, and
k only plays a rescaling role on
(we choose
without loss of generality in the following experiment). Equation (
10) is a linear inhomogeneous differential equation; when
, all the real parts of the eigenvalues of matrix
are less than zero; then, the zero solution of the homogeneous system is asymptotically stable and, because the inhomogeneous term of the equation is constant, the stationary solution of the equation exists and is unique; it is a constant vector. This guarantees that Co-Com Centrality can always generate a unique importance value for any directed network.
Thus, for the
ith edge, Equation (
10) can be rewritten as
where
is the set of cooperation edges of
ith edge and
is the set of competition edges of
ith edge. The larger the value of the Co-Com Centrality, the more important the edge.
3.4. Example Analysis
Using Co-Com Centrality (select
) to calculate the importance of each edge in
Figure 1,
Table 1 shows that the importance value of
becomes higher than that of
, while the ranking of the importance of other edges remains unchanged. This indicates that aggregating global information has successfully improved the recognition accuracy of the method.
We use the network in
Figure 2 to analyze the differences between Co-Com Centrality and other methods and explain why Co-Com Centrality performs well. We calculate Co-Com Centrality (select
) and five kinds of Centrality in the network of
Figure 2. And, to explain our method clearly, we will show the calculation process in detail below.
- 1.
Generate
and
(Equation (9)) according to
Figure 2.
- 2.
Calculate the “initial value”. For example, for
, the in-degree of “node 1” is 1 and the out-degree of “node1” is 2, and the in-degree of “node3” is 2 and the out-degree of “node 3” is 2; put them into Equation (
7); the “initial value” of
is
. The “initial value” vector
of
Figure 2 is (1.5, 2, 1, 1, 0.5, 2, 1
.
- 3.
Put
,
,
,
, and
into Equation (
10) to obtain Co-Com Centrality. The complete formula is
The Co-Com Centrality of
Figure 2 is the stable solution of Equation (
18).
The detailed numerical results are shown in
Table 2.
The reason why Co-Com Centrality performs well lies in the symmetric matrices and . For directed edge , can capture the influence of edges pointing to u and edges pointing from v on , and can capture the influence of edges pointing to v and edges pointing from u on . For EEC, its definition uses the edge adjacency matrix, which makes only capture the influence of the edges that point from v, but it cannot capture the influence of the edges that point to u and the influence of the edges that point from u. The definition of EDY uses the adjacency matrix, which has similar problems. ECC measures the edge importance by the sum of the shortest paths to other edges; for the directed network, considering the direction, it can only identify the important edges that point to a large number of edges, but cannot identify the important edges that are pointed to by a large number of edges. EBC lacks special consideration of the topology structure of the directed networks; it only considers the shortest path and ignores the influence of other paths (except for the shortest path) on the edge importance. LinkRank is a PageRank-based method. For edge , it can be understood as the PageRank importance of u multiplied by the random walk probability from u to v; the disadvantage of the method is that cannot capture the influence of the edges that point from v.
Table 2 will be used to make the explanation clearer. Focus on
and
; they are in different topological structures, so their importance values should be different. However, except LinkRank and Co-Com Centrality, the edge importance calculated by other methods is the same. This is because, for other methods, whether determining edge importance through the shortest path or the network adjacency matrix, the influence of e5 on e1 is not considered. The essence of this phenomenon is to ignore the influence of “information diversion” on edge importance: e5 diverts part of the information from e6, resulting in the importance of e1 being less than that of e2. LinkRank considers “information diversion” by Google Matrix and Co-Com Centrality consider ‘information diversion’ by initial value and competition matrix, so they achieve a better classification effect. However, LinkRank cannot distinguish the difference in importance between e6 and e7, because it cannot capture the influence of
on
.




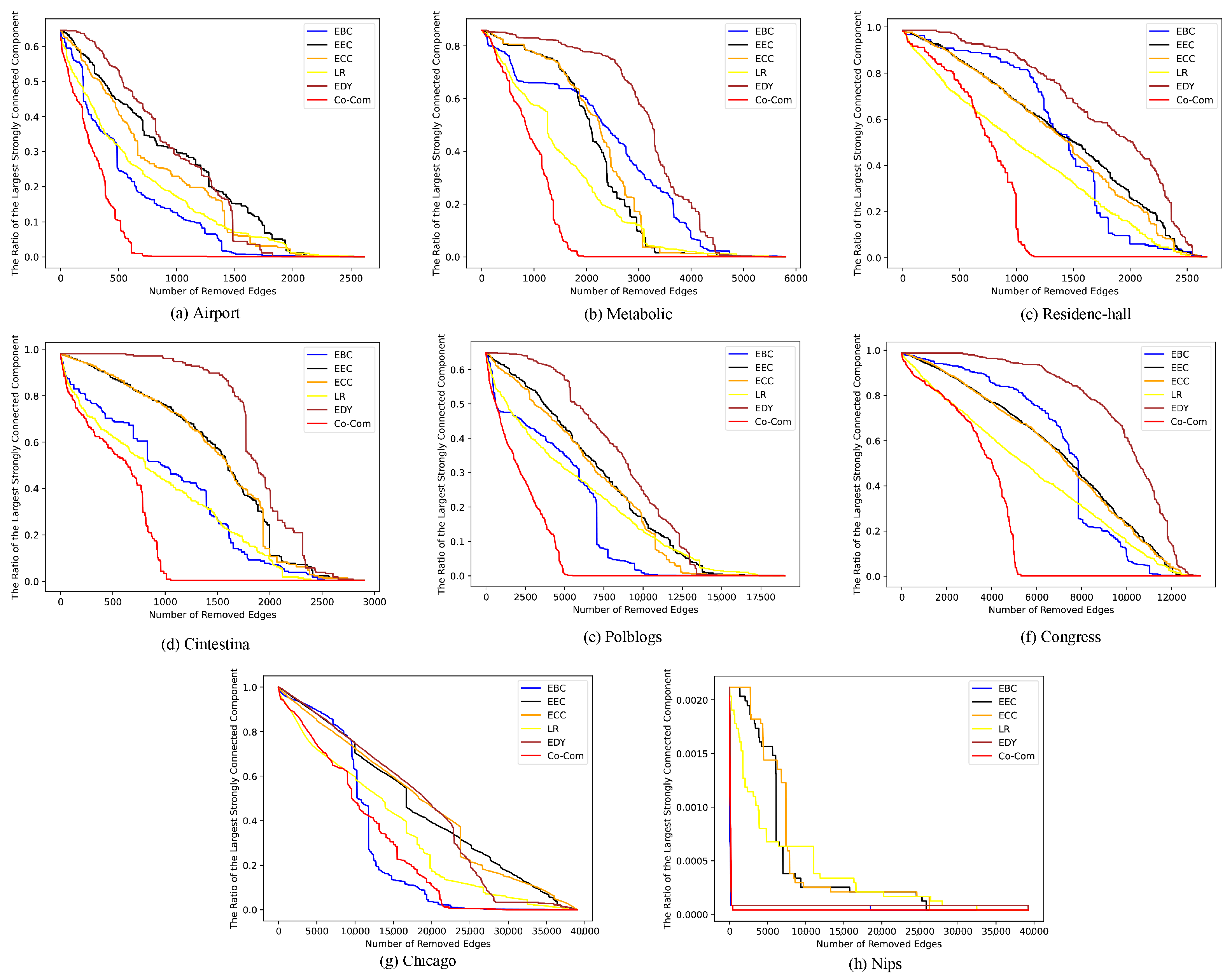
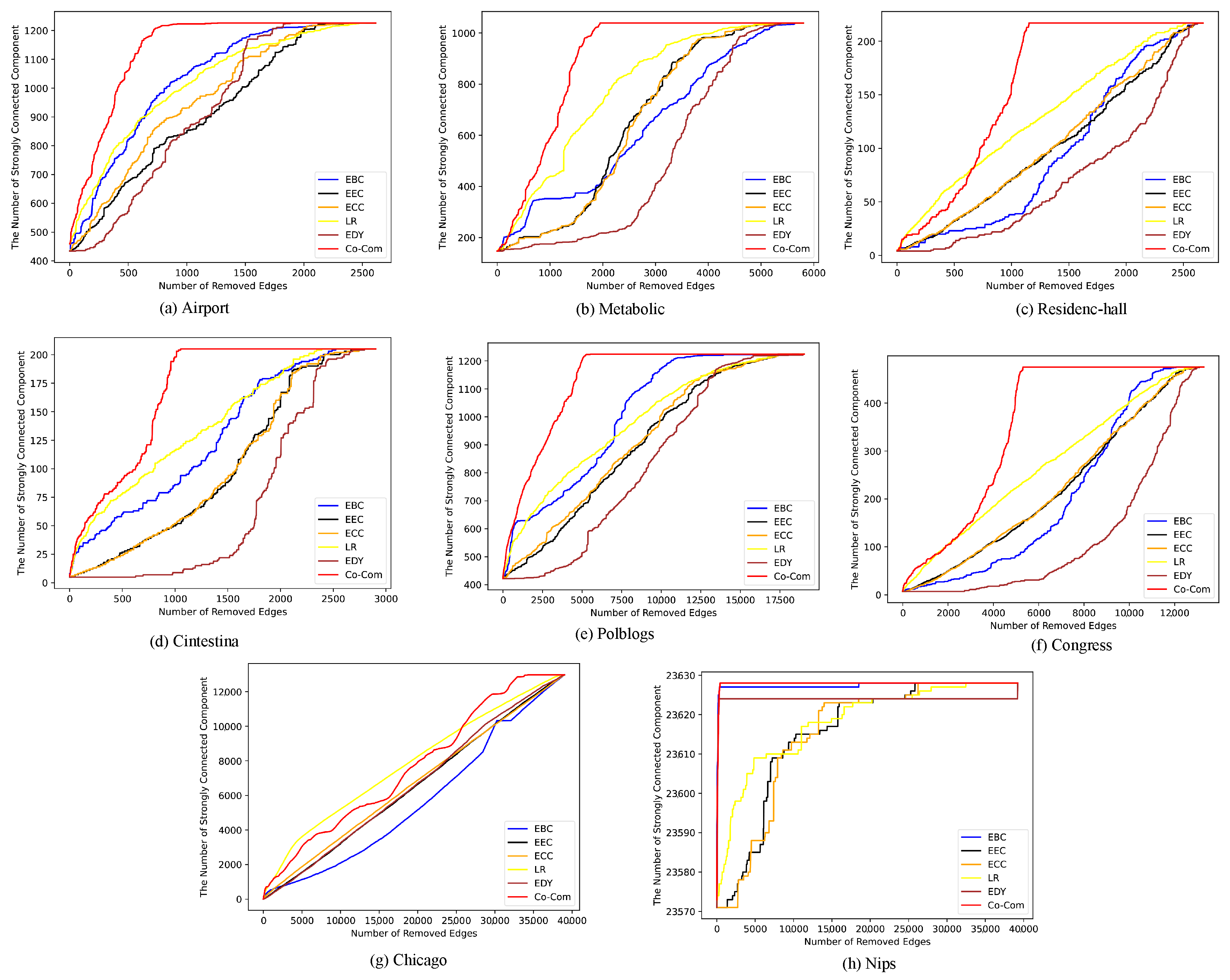
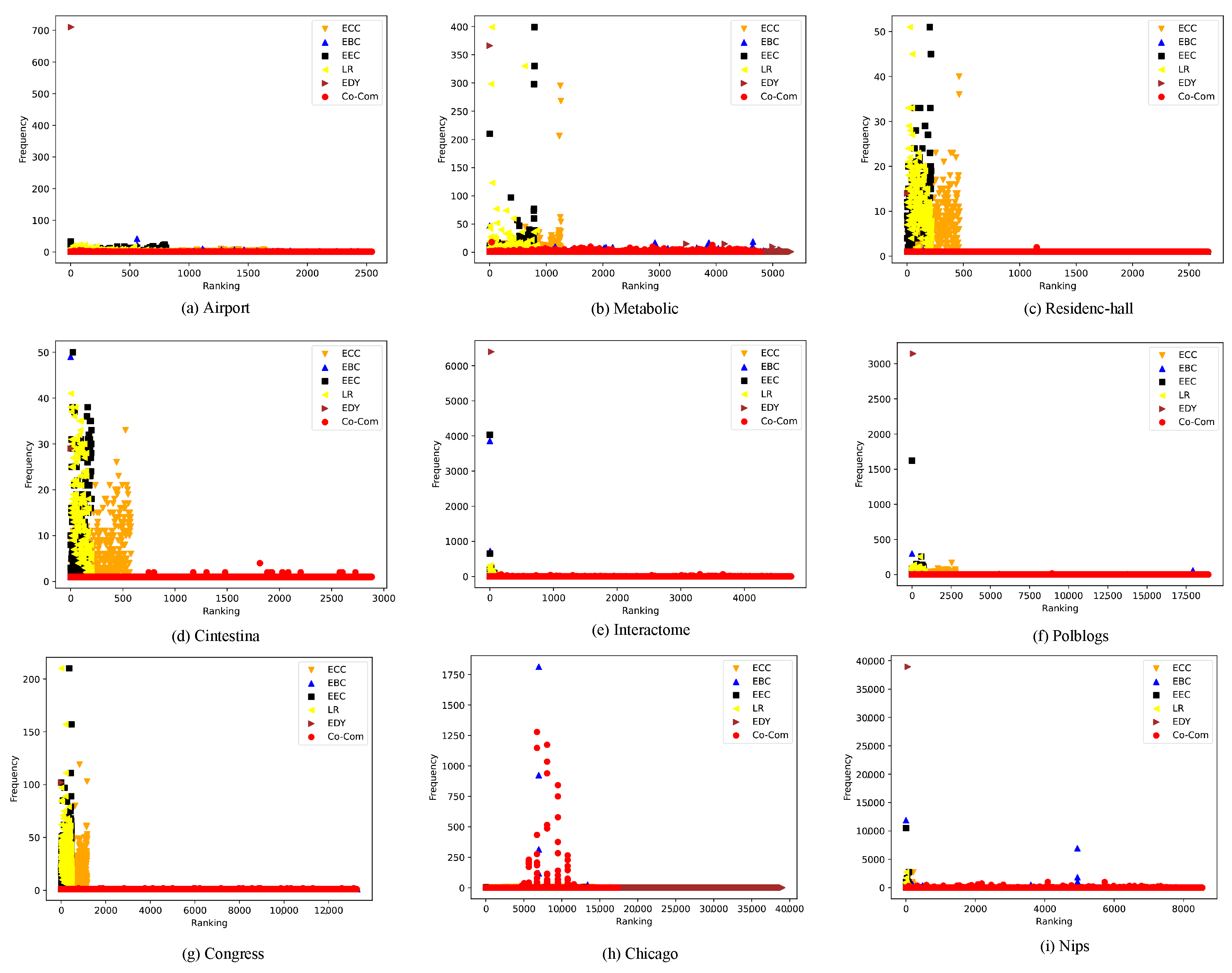

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}