Abstract
This paper investigates the asymptotic behavior of kernel-based estimators for the error distribution in a first-order autoregressive model with dependent errors. The model assumes that the error terms form an -mixing sequence with an unknown cumulative distribution function (CDF) and finite second moment. Due to the unobservability of true errors, we construct kernel-smoothed estimators based on residuals obtained via least squares. Under mild assumptions on the kernel function, bandwidth selection, and mixing coefficients, we establish a logarithmic law of the iterated logarithm (LIL) for the supremum norm difference between the residual-based kernel estimator and the true distribution function. The limiting bound is shown to be , matching the classical LIL for independent samples. To support the theoretical results, simulation studies are conducted to compare the empirical and kernel distribution estimators under various sample sizes and error term distributions. The kernel estimators demonstrate smoother convergence behavior and improved finite-sample performance. These results contribute to the theoretical foundation for nonparametric inference in autoregressive models with dependent errors and highlight the advantages of kernel smoothing in distribution function estimation under dependence.
Keywords:
autoregressive model; α-mixing sequence; kernel estimation; law of the iterated logarithm; residual-based estimator MSC:
60B10; 62G05
1. Introduction
Suppose that the sequence satisfies the first-order autoregressive process
where , are random errors with mean 0, variance , and they form a weakly stationary sequence of -mixing with an unknown cumulative distribution function (CDF) F. Henceforth, we use the term stationary to mean weakly stationary. The definition of -mixing will be provided later. It is well-known that the parameter characterizes the properties of the process . In this paper, we suppose and . Hence, is a so-called stationary process (see [1]). Throughout this paper, we consider the stationary solution of the first-order autoregressive process, which can be represented as
If were observed, then the estimation of their CDF, F, can be obtained by the empirical CDF as follows:
For any t, is the uniformly minimum variance unbiased estimator of for all continuous distribution functions, F. It is also well known as the Glivenko–Cantelli theorem that
where “a.s.” stands for “almost surely” (see Gut [2]). The law of the iterated logarithm (LIL) for , i.e.,
was obtained by Smirnov [3] and, independently, Chung [4]. Cai and Roussas [5] extended LIL of to the case that were -mixing. Since the empirical distribution function is a step function and thus discontinuous, smooth estimators are often preferred to provide continuous and differentiable approximations that are more suitable for statistical inference and further analysis. Therefore, Yamato [6] proposed the following kernel estimator:
where , h is the bandwidth and K is a kernel probability density function (PDF). Cai and Roussas [5] also studied the uniform strong rate of convergence for ; a.s., Cheng [7] obtained the uniform strong rate of convergence for , a.s., for any .
But in autoregressive model (1), only the random variables are observed. Therefore, in order to obtain an estimator of , we modify the definition in (4) by plugging in the residuals
where is an estimator of . For example, the least squares estimator of is
Therefore, the residual empirical CDF is given by
and the residual kernel estimation of F is
Under the i.i.d. errors, Cheng [8] considered the first-order autoregressive model (1) and verified that the Glivenko–Cantelli theorem still holds for the estimators and , i.e.,
Beyond the classical LIL under the supremum norm, recent research has extended the LIL framework to other normed settings. In particular, Cheng [9] considered the first-order autoregressive model (1) and obtained the integrated absolute error (i.e., -norm) of ,
Motivated by these findings, our work focuses on the LIL for the residual kernel estimator in the first-order autoregressive model (1) with -mixing errors, i.e.,
Let us recall the definition of an -mixing sequence.
Definition 1.
Denote . Let be the σ-field generated by random variables . For , we define
If as , is called a strong mixing or α-mixing sequence.
The -mixing condition is a type of weak dependence commonly used in time series analysis. It measures how quickly the dependence between past and future observations decays as the time gap increases. For more properties of -mixing sequences, one can refer to Györfi [10], Roussas [11], Fan and Yao [12], Wang et al. [13], etc.
For more research on LIL, one can refer to Gajek et al. [14] and Cheng [15] for -norms of the empirical distribution function and kernel distribution function ; Li and Wang [16] and Petrov [17] investigated the LIL for the sequences of dependent random variables; Liu and Zhang [18] studied the LIL for error density estimators in nonlinear autoregressive models, etc.
In the context of estimating the error distribution function, this paper makes three main contributions. First, we consider a linear first-order autoregressive model in which the autoregressive coefficient must be estimated rather than assumed known. Second, we study kernel-based nonparametric estimators for the error distribution, providing smoother approximations than the empirical distribution function and enabling refined probabilistic analysis. Third, we explicitly allow for dependent errors modeled by a stationary -mixing sequence, extending classical results beyond the independent error setting.
It is worth noting that for the i.i.d. case, the LIL for the empirical distribution function case has been well established by Smirnov [3] and Chung [4]. For kernel estimators of the error distribution, related results were obtained by Niu [19] and Cheng [20]. Our work extends these classical results to the dependent error setting, motivated in part by earlier studies on autoregressive processes such as that by Wang et al. [21], bridging the gap between the i.i.d. theory and time series models with weakly dependent innovations.
We also remark that alternative weak dependence structures could be considered. For example, if the errors are independent, the convergence rates simplify, and some technical conditions can be relaxed. If -mixing is replaced by other forms of weak dependence, such as -mixing, -mixing, or martingale difference sequences or the weak dependence framework of Doukhan and Louhichi [22], we expect similar LIL results to hold under appropriate moment and dependence assumptions, though the technical details and proof techniques would require adaptation. A full exploration of these generalizations is beyond the scope of the present paper, but they constitute interesting directions for future research.
The rest of this paper is organized as follows: in Section 2, we list some basic assumptions for the first-order autoregressive model (1). The main results of a uniform strong rate of and LIL of (9) are presented in Section 3. In order to check our results, some simulations are presented in Section 4. Some technical Lemmas and proofs are presented in Section 5. Last, we provide a conclusion and discussion in Section 6. Throughout the paper, we assume that limits are taken as unless otherwise specified. The denote some positive constants not depending on n, which may be different in various places.
2. Assumptions
This section presents the basic assumptions required for model (1) as well as the main theorems.
- (A1)
- In model (1), let the sequence of errors form a stationary sequence of -mixing with unknown CDF F with a bounded second-order derivative, i.e., there exists a positive constant C () such that for all . Assume and for some . The mixing coefficient satisfies , where .
- (A2)
- The kernel function , and are integrable over the real line and satisfy
- (A3)
- The bandwidth h satisfies the following conditions:
- (A4)
- In model (1) with , let the be an estimator of with the following almost-surely (a.s.) property: there exists a positive constant C such that
Remark 1.
We discuss these assumptions as follows:
- (i)
- Assumption (A1) contains the smoothness of the error CDF F and the boundness of its second derivative . It also requires the mixing coefficients satisfy , where and (p-th moment of error). If , then . It is a strong condition of mixing coefficients, which require the errors to be asymptotically independent. If , then . This requires a strong p-th moment of errors. In future research, we will try to relax the mixing coefficient condition. For more properties of α-mixing sequences, one can refer to Györfi [10], Roussas [11], Fan and Yao [12], Wang et al. [13], etc.
- (ii)
- Assumption (A2) is the common condition of kernel about non-negatively, symmetry, and integrability. Obviously, the probability density functions Gaussian kernel and Epanechnikov kernel conform to Assumption (A2). See for example, Györfi et al. [10], Roussas [11], Fan and Yao [12], Li and Racine [23], etc.
- (iii)
- Assumption (A3) is a standard condition for bandwidth selection in kernel density estimation. For example, similar conditions are used by Cheng et al. [7,9,15], particularly in the proof of Lemma 5. A commonly used bandwidth is .
- (iv)
- Assumption (A4) requires that the estimator of the autoregressive parameter ρ converges almost surely at the rate . This condition plays a key role in our theoretical results, as it ensures that the effect of estimating ρ is asymptotically negligible. Without such a rate, the additional error introduced by residuals could dominate the behavior of the kernel estimator and invalidate the uniform LIL established in this paper. When are i.i.d. errors, Koul and Zhu [24] considered a generalized M-estimator for p-th order autoregression models and obtained a strong rate of convergence for M-estimators , i.e., , a.s., including the least-squares estimator; Cheng [9] used Assumption (A4) to study the -norm of in (8). When in the first-order autoregression model (1) are α-mixing random variables with common density function f and , Gao et al. [25] used the condition to study the asymptotic normality of the kernel density estimator for the error density function f. Wu et al. [26] extended the work to nonlinear autoregressive models. In the proof by Gao et al. [25], moment inequalities were used to establish the convergence in probability. However, to extend these results to almost-sure convergence, it would be necessary to employ exponential inequalities. This in turn requires additional conditions on the α-mixing coefficients, ensuring that the covariance structure of the α-mixing sequence satisfies certain summability and decay properties. The proof of such a result is highly technical and involves delicate handling of the dependence structure. Because this is beyond the scope of the present paper, we treat Assumption (A4) as a standing assumption rather than providing a full proof here, and we leave this as an important topic for our future research.
3. Main Results
We now present the first main result of this section, which describes the uniform strong rate of convergence between and in the stationary autoregressive model (1).
Theorem 1.
By Theorem 1, one can get the uniform strong rate
Combining the LIL of in Lemma 6, i.e.,
we present the LIL for the residual kernel estimator as follows:
Theorem 2.
Under the same conditions as in Theorem 1, we have
Remark 2.
In Theorem 3.2 of Cai and Roussas’s study [5], Cai and Roussas obtained the LIL with α-mixing samples such that
They had a typo error in estimation (17) that was equal to 1 a.s. In fact, they mistakenly cited [27] [Corollary 1.15.1] and claimed that
But it is
(see the proof of Lemma 4). Thus, Theorem 2 extends the conclusion of LIL to the kernel estimator of error CDF in autoregressive model (1) based on α-mixing errors.
4. Simulations
To verify the theoretical results, we conduct simulation studies to assess the uniform convergence behavior of four distribution estimators under different error distribution settings, namely Gaussian and Gamma. The goal is to compare the accuracy of these estimators in approximating the true error distribution function, particularly in terms of the iterated logarithm convergence rate.
We consider the first-order autoregressive model:
where is a dependent error sequence following either a Gaussian distribution or a Gamma distribution.
- Gaussian errors: , where is a Toeplitz covariance matrix with entries , ensuring that the errors form an -mixing sequence. A Toeplitz matrix is a matrix in which each descending diagonal from left to right is constant. For more details about the Toeplitz matrix, we can refer to Trench [28]. As discussed in [29], it is easy to check that are -mixing with .
- Gamma errors: we adopt a Gaussian copula-based approach to generate random vectors with exact Gamma marginals and an approximately specified covariance matrix. Specifically, we first generate a multivariate normal vector , where R is the correlation matrix corresponding to the target covariance matrix . Each component of Z is then transformed to a uniform random variable via the standard normal CDF and is subsequently mapped to a Gamma(4,1) random variable using the Gamma inverse CDF. This method guarantees the correct marginal Gamma distribution, while the resulting sample covariance matrix is very close to , with only small differences. An exact covariance match can be achieved using the NORTA (Normal To Anything) method, which iteratively adjusts the Gaussian correlation matrix to perfectly reproduce the target covariance after the nonlinear transformation. However, NORTA is computationally intensive, so we do not adopt it here, given that the Gaussian copula-based approach already provides sufficient accuracy and efficiency.
For each sample size , we perform 100 Monte Carlo simulations. In each replication, the following four estimators of the error distribution function are constructed:
- : empirical distribution function based on the true errors;
- : kernel-smoothed distribution estimator based on true errors;
- : empirical distribution based on residuals (from least squares estimation);
- : kernel-smoothed distribution based on residuals (from least-squares estimation).
To measure the estimation accuracy, we compute the Kolmogorov–Smirnov (KS) distance between each estimator and the true distribution function and normalize it using the theoretical upper bound under the law of the iterated logarithm:
Define the NKS for the estimators,
A Gaussian kernel is used for smoothing, with bandwidth . The estimators are evaluated over the range .
To investigate the effect of the bandwidth h on the performance of the proposed kernel estimator, we conducted a sensitivity analysis for two representative sample sizes, and . For , the bandwidth h was taken from the set , where corresponds exactly to the suggested choice with . For , the bandwidth h was chosen from the set , where corresponds to the suggested choice with .
Figure 1 and Figure 2 present the corresponding boxplots of the statistic for these different bandwidths under the Gaussian error setting, with Figure 1 corresponding to the sample size and Figure 2 corresponding to the sample size . For , although there is mild fluctuation across different bandwidths, the boxplot corresponding to shows that its median is closer to zero and the interquartile range is under 0.5, indicating that the estimator performs more stably and with less bias at this recommended bandwidth. For , the variability of across bandwidths is smaller. Again, the boxplot for is closer to zero, further supporting the theoretical bandwidth selection. These findings confirm that is not sensitive to bandwidth variation, and they provide strong empirical evidence that the bandwidth offers a good kernel estimator for CDF F. Therefore, all subsequent simulation results reported in this paper are based on the bandwidth to ensure consistency and comparability across experiments. Figure 3, Figure 4, Figure 5 and Figure 6 display boxplots of across different sample sizes and estimation methods. Each sample size includes 100 simulation replicates per method. The vertical axis represents the NKS, and a horizontal dashed line at level 0.5 is included to indicate the asymptotic upper bound suggested by the iterated logarithm law.
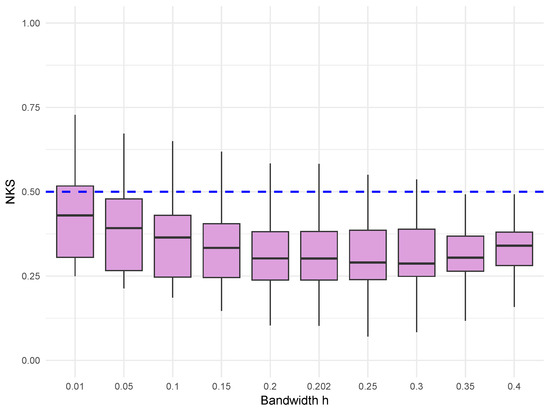
Figure 1.
Boxplot of under different bandwidth choices for sample size in the Gaussian error setting.
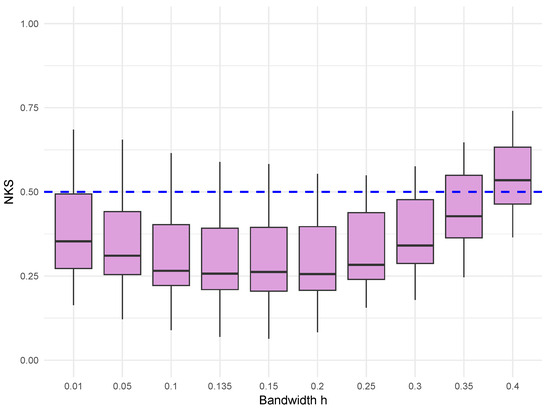
Figure 2.
Boxplot of under different bandwidth choices for sample size in the Gaussian error setting.
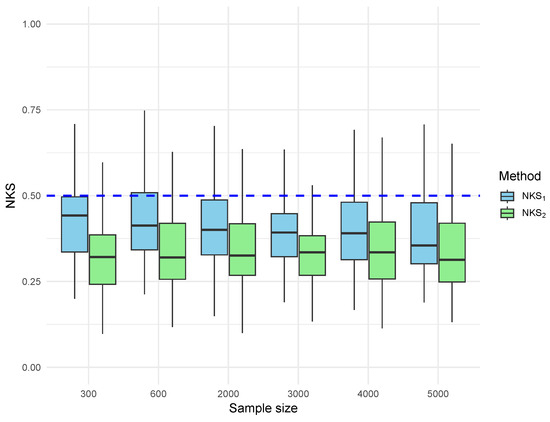
Figure 3.
Boxplot of NKS distance for error-based estimators under Gaussian errors. and are the NKS distances for and , respectively.
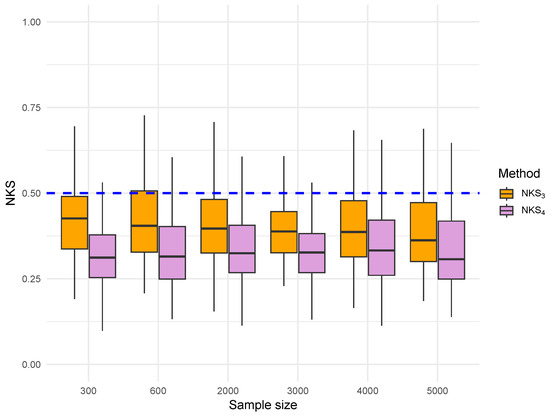
Figure 4.
Boxplot of NKS distance for residual-based estimators under Gaussian errors. and are the NKS distances for and , respectively.
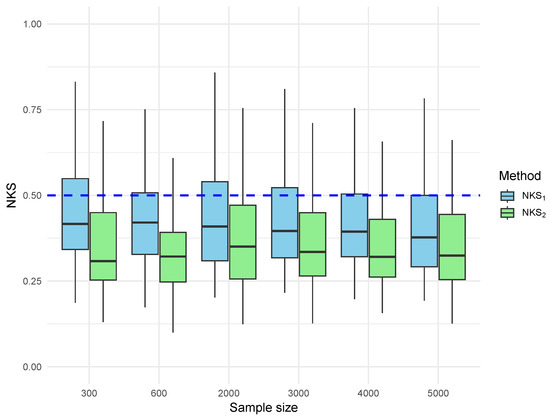
Figure 5.
Boxplot of NKS distance for error-based estimators under Gamma errors. and are the NKS distances for and , respectively.
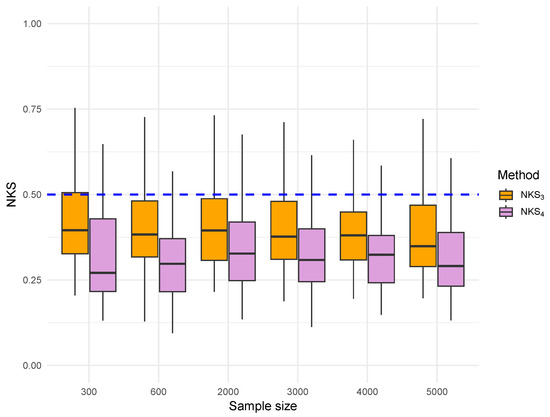
Figure 6.
Boxplot of NKS distance for residual-based estimators under Gamma errors. and are the NKS distances for and , respectively.
Figure 3 presents the NKS distances for the empirical estimator and the kernel estimator , both based on true Gaussian errors. Each boxplot summarizes the distribution of NKS across 100 replications. We observe that the upper edge of the boxes (the 75th percentile) for both estimators stays well below the 0.5 theoretical boundary, even at the smallest sample size . As the sample size increases, the entire box shrinks downward, indicating uniform improvement in estimator accuracy. The kernel estimator consistently shows a tighter spread and a lower upper quartile than , highlighting the advantage of kernel smoothing in reducing estimation variance under Gaussian error structures.
Figure 4 shows the NKS distances for the residual-based estimators and , derived from least-squares residuals under the same Gaussian error process. The results are similar to those in Figure 3. The upper quartile of the NKS remains consistently below 0.5 for both methods across all sample sizes. Again, the kernel estimator shows superior concentration, with its upper edge often well below the 0.5 threshold, even at . This suggests that residual-based estimators, particularly when smoothed, maintain excellent uniform convergence properties under Gaussian dependence, nearly matching the performance of error-based methods.
Figure 5 and Figure 6 report the results under Gamma-distributed and dependent errors. Although the Gamma distribution is skewed and heavy-tailed, the overall performance of the estimators remains similar to that observed under Gaussian errors. All estimators exhibit convergence as the sample size increases, and kernel-based methods continue to outperform empirical ones in terms of reduced dispersion and tighter concentration around the theoretical upper bound.
The simulation results confirm the validity of the iterated logarithm law for both error-based and residual-based estimators under dependent data. Among all the methods, the kernel-based estimators consistently demonstrate superior stability and accuracy across different error distributions and sample sizes.
5. Proofs of the Main Results
Lemma 1
(Hall and Heyde [30], Corollary A.2). Suppose that ξ and η are random variables which are and -measurable, respectively, , and that , , where and . Then,
Lemma 2
(Liebscher [31], Proposition 5.1). Let be a stationary α-mixing sequence with mixing coefficient . Assume that and , , . Then, for , and every ,
where .
Lemma 3.
In the first-order autoregression (1), let Assumption (A1) hold. Then for any permutation of , we have
Proof of Lemma 3.
Since , by (2), the stationary process in the first-order autoregression (1) has a representation of , . Let if and otherwise. Then,
By , , , it has . According to the Chebyshev inequality and Cauchy inequality, we have
by using the fact . So, it follows from the Borel–Cantelli Lemma that
For , set
Then,
Observe that
In the following, we show that converges to a positive and finite random variable as . Let be a positive constant sequence with . Let be a sequence of random variables satisfying
Then a.s. , where is a positive and finite random variable. For more details, see Wang [32] [Proposition 2.4.2]. Note that if and only if . Let and , which satisfies . Then we have
Then there exists a positive and finite random variable such that , a.s., . Consequently, we can obtain
In addition, as and , we have
To prove (10), we will show that
Note that
and by Assumption (A1) and Lemma 1, we have
It implies that
where . Since and according to Assumption (A1), it has . Then, by , we take in Lemma 2 and have that
for some positive . So, by the Borel–Cantelli Lemma, the proof of (11) is completed.
□
Remark 3.
Gao [33] and Sun et al. [34] considered a moving-average process, denoted by , i.e.,
with and i.i.d. errors; they obtained that for any permutation of ,
Before proceeding, we recall the definition of the Kiefer process [36].
Definition 2.
A separable Gaussian process on is called a Kiefer process if it satisfies
with mean zero
and covariance function
where is the covariance function of a separable Gaussian process on , with .
The Kiefer process generalizes the Brownian bridge to two parameters and naturally arises in the asymptotic study of empirical and residual processes, including LIL.
Lemma 4.
Let be an α-mixing sample with PDF F. Let Assumption (A1) hold. Then the LIL for the empirical distribution function is
where is defined in (3).
Proof of Lemma 4.
Similarly to Cai and Roussas [5], define the empirical process:
where . Then the covariance function is
On an enriched probability space, by Theorem 3 by Dhompongsa [36], we can redefine the process to admit a Kiefer process with covariance
such that for some , depending only on r,
Lemma 5.
Proof of Lemma 5.
Cheng [15] used the Kiefer process to obtain (18) under the i.i.d sample assumption. By the Kiefer process, Cai and Roussas [5] obtained the uniform approximation of the empirical process to under the -mixing samples (see Lemma 4). It can be seen that the proof of (18) in Cheng [15] also holds for the case of -mixing. □
Lemma 6.
In model (1), let Assumptions (A1)–(A3) be satisfied. Then
Proof of Lemma 6.
By the triangle inequality,
Thus,
Proof of Theorem 1.
From (1) and (5), it follows , and . Substituting this into the definitions of and , we use the mean-value theorem and obtain
where is defined in Assumption (A2) and is a point between and . We now consider the term in (22). Let , . By Assumption (A2), are non-negative and bounded. So, we sort by and denote the corresponding parts of as . Obviously, one can use Abel’s inequality (see [37]) and establish that
Thus, it follows from Assumption (A4), Lemma 3, and (23) that
proving . Consequently,
i.e., (1) holds. □
Proof of Theorem 2.
Similarly to the proof of Lemma 6, by the triangle inequality,
Combining Lemma 6 with Theorem 1, we complete the proof of Theorem 2. □
6. Conclusions
In this paper, we investigated the asymptotic behavior of kernel estimators for the error distribution in first-order autoregressive models (1) when the error sequence is a stationary -mixing process with an unknown distribution. Due to the unobservable nature of the true errors, we proposed a residual kernel estimator constructed from residuals and examined its convergence properties under a set of mild regularity conditions.
Our main theoretical contribution lies in establishing the LIL for the residual kernel distribution estimator. Specifically, we proved that under appropriate mixing, moment, and bandwidth conditions, the supremum norm of the deviation between the residual kernel estimator and the true error distribution function satisfies
which parallels the classical LIL for i.i.d. sequences.
Moreover, we derived an intermediate result demonstrating that the difference between the residual kernel estimator and its infeasible counterpart based on true errors converges to zero at the same logarithmic rate. This ensures that the influence of estimation error in residuals is asymptotically negligible under our conditions. These theoretical findings were further corroborated by extensive simulation studies under both Gaussian and Gamma distributed -mixing errors, which consistently showed that kernel estimators exhibit smoother behavior and smaller fluctuations compared to their empirical counterparts, especially in moderate-to-large sample sizes.
In addition to the simulation study, our proposed method has strong potential for practical applications in real data analysis. For instance, in economics and finance, AR(1) models are widely used to model interest rates, exchange rates, and stock returns, where the error terms often exhibit temporal dependence and heavy-tailed behavior. The residual-based kernel estimator provides a flexible tool for accurately estimating the error distribution in such contexts, which can improve model diagnostics, forecasting, and risk management. Future work will include applying this methodology to real-world datasets, such as macroeconomic indicators or climate time series, to demonstrate its practical utility.
The proposed approach has several strengths. It extends classical nonparametric distribution estimation to dependent data settings while maintaining desirable asymptotic properties. The kernel smoothing step improves finite-sample stability and produces smoother estimates that are more suitable for inference and visualization. However, the method also has limitations. For example, the theoretical results rely on the assumption of -mixing errors with specific decay rates, which may not hold for certain strongly dependent processes. Additionally, while the study focuses on AR(1) models, many practical systems are better described by higher-order AR(p), MA(q), and ARMA() processes.
An important open question is how to extend the present results to general AR(p), MA(q), and ARMA() processes. The main difficulty lies in handling the increased complexity of parameter estimation and residual dependence when multiple lagged terms are present. Developing a unified theoretical framework for these models would significantly broaden the applicability of the method and provide deeper insights into the asymptotic behavior of residual-based estimators. Other promising directions include exploring data-driven bandwidth selection procedures, incorporating robust kernel functions to handle outliers, and applying the methodology to multivariate or nonlinear time series.
In summary, the residual kernel estimator studied in this paper provides a theoretically sound and practically useful tool for error distribution estimation in AR(1) models with dependent errors. With further research and development, it has the potential to be extended to more complex autoregressive structures and to offer valuable insights for both theoretical and applied settings.
Author Contributions
Supervision W.Y.; software B.W. and Y.J.; writing—original draft preparation, L.W., X.S. and W.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China (12301327) and the Anhui Province University Research Project (2023AH050096).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Brockwell, P.J.; Davis, R.A. Time Series: Theory and Methods, 2nd ed.; Springer: New York, NY, USA, 1991. [Google Scholar]
- Gut, A. Probability: A Graduate Course, 2nd ed.; Springer: New York, NY, USA, 2013. [Google Scholar]
- Smirnov, N.V. An approximation to distribution laws of random quantities determined by empirical data. Uspekhi Mat. Nauk. 1944, 10, 179–206. [Google Scholar]
- Chung, K.L. An estimate concerning the Kolmogorov limit distribution. Am. Math. Soc. 1949, 67, 36–50. [Google Scholar]
- Cai, Z.W.; Roussas, G.G. Uniform strong estimation under α-mixing, with rates. Stat. Probab. Lett. 1992, 15, 47–55. [Google Scholar] [CrossRef]
- Yamato, H. Uniform convergence of an estimator of a distribution function. Bull. Math. Statist. 1973, 15, 69–78. [Google Scholar] [CrossRef] [PubMed]
- Cheng, F. Strong uniform consistency rates of kernel estimators of cumulative distribution functions. Commun. Stat. Theory Methods 2017, 46, 6803–6807. [Google Scholar] [CrossRef]
- Cheng, F. Glivenko-Cantelli Theorem for the kernel error distribution estimator in the first-order autoregressive mode. Stat. Probab. Lett. 2018, 139, 95–102. [Google Scholar] [CrossRef]
- Cheng, F. The integrated absolute error of the kernel error distribution estimator in the first-order autoregression model. Stat. Probab. Lett. 2024, 214, 110215. [Google Scholar] [CrossRef]
- Györfi, L.; Härdle, W.; Vieu, P. Nonparametric Curve Estimation from Time Series; Springer: New York, NY, USA, 1989. [Google Scholar]
- Roussas, G.G. Nonparametric regression estimation under mixing conditions. Stoch. Process. Their Appl. 1990, 36, 107–116. [Google Scholar] [CrossRef]
- Fan, J.Q.; Yao, Q.W. Nonlinear Time Series: Nonparametric and Parametric Methods; Springer: New York, NY, USA, 2003. [Google Scholar]
- Wang, J.Y.; Liu, R.; Cheng, F.X.; Yang, L.J. Oracally efficient estimation of autoregressive error distribution with simultaneous confidence band. Ann. Statist. 2014, 42, 654–668. [Google Scholar] [CrossRef]
- Gajek, L.; Kahszka, M.; Lenic, A. The law of the iterated logarithm for Lp-norms of empirical processes. Stat. Probab. Lett. 1996, 28, 107–110. [Google Scholar] [CrossRef]
- Cheng, F. The law of the iterated logarithm for Lp-norms of kernel estimators of cumulative distribution functions. Mathematics 2024, 12, 1063. [Google Scholar] [CrossRef]
- Li, Y.X.; Wang, J.F. The law of the iterated logarithm for positively dependent random variables. J. Math. Anal. Appl. 2008, 339, 259–265. [Google Scholar] [CrossRef][Green Version]
- Petrov, V.V. On the law of the iterated logarithm for sequences of dependent random variables. Vestnik St. Petersb. Univ. Math. 2017, 50, 32–34. [Google Scholar] [CrossRef][Green Version]
- Liu, T.Z.; Zhang, Y. Law of the iterated logarithm for error density estimators in nonlinear autoregressive models. Commun. Stat. Theory Methods 2019, 49, 1082–1098. [Google Scholar] [CrossRef]
- Niu, S.L. LIL for kernel estimator of error distribution in regression model. J. Korean Math. Soc. 2007, 44, 1082–1098. [Google Scholar] [CrossRef]
- Cheng, F. A law of the iterated logarithm for error density estimator in censored linear regression. J. Nonparametr. Stat. 2022, 34, 283–298. [Google Scholar] [CrossRef]
- Wang, Y.; Mao, M.; Hu, X.; He, T. The Law of Iterated Logarithm for Autoregressive Processes. Math. Probl. Eng. 2014, 2014, 972712. [Google Scholar] [CrossRef]
- Doukhan, P.; Louhichi, S. A new weak dependence condition and applications to moment inequalities. Stochastic Processes Appl. 1999, 84, 312–342. [Google Scholar] [CrossRef]
- Li, Q.; Racine, J.S. Nonparametric Econometrics: Theory and Practice; Princeton University Press: Princeton, NJ, USA, 2007. [Google Scholar]
- Koul, H.L.; Zhu, Z.W. Bahadur-Kiefer representations for M-estimators in autoregression models. Stochastic Process. Appl. 1995, 57, 167–189. [Google Scholar] [CrossRef]
- Gao, M.; Yang, W.Z.; Wu, S.P.; Yu, W. Asymptotic normality of residual density estimator in stationary and explosive autoregressive models. Comput. Stat. Data An. 2022, 175, 107549. [Google Scholar] [CrossRef]
- Wu, S.P.; Yang, W.Z.; Gao, M.; Fang, H.Y. Asymptotic results of error density estimator in nonlinear autoregressive models. J. Korean Stat. Soc. 2024, 53, 563–582. [Google Scholar] [CrossRef]
- Csörgo, M.; Révész, P. Strong Approximation in Probability and Statistics; Academic Press: New York, NY, USA, 1981. [Google Scholar]
- Gray, R.M. On the asymptotic eigenvalue distribution of Toeplitz matrices. IEEE Trans. Inf. Theory 1972, 18, 725–730. [Google Scholar] [CrossRef]
- Withers, C.S. Conditions for linear processes to be strong-mixing. Z. Wahrscheinlichkeitstheorie Verw. Gebiete 1981, 57, 477–480. [Google Scholar] [CrossRef]
- Hall, P.; Heyde, C.C. Martingale Limit Theory and Its Application; Academic Press: New York, NY, USA, 1980. [Google Scholar]
- Liebscher, E. Estimation of the density and the regression function under mixing conditions. Stat. Decis. 2001, 19, 9–126. [Google Scholar] [CrossRef]
- Wang, J.G. Fundamentals of Modern Probability Theory; Fudan University Press: Shanghai, China, 2005. [Google Scholar]
- Gao, J.T. Asymptotic theory for partly linear models. Commun. Stat. Theory Methods 1995, 24, 1985–2009. [Google Scholar] [CrossRef]
- Sun, X.Q.; You, J.H.; Chen, G.M.; Zhou, X. Convergence rates of estimators in partial linear regression models with MA(∞) error process. Commun. Stat. Theory Methods 2002, 31, 2251–2273. [Google Scholar] [CrossRef]
- Liang, H.Y.; Mammitzsch, V.; Steinebach, J. On a semiparametric regression model whose errors form a linear process with negatively associated innovations. Statistics 2006, 40, 207–226. [Google Scholar] [CrossRef]
- Dhompongsa, S. A note on the almost sure approximation of the empirical process of weakly dependent random vectors. Yokohama Math. J. 1984, 32, 113–121. [Google Scholar]
- Mitrinovic, D.S. Analytic Inequalities; Springer: New York, NY, USA, 1970. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).