1. Introduction
If a measurement can be regarded as an unbiased estimation of some observable, then, by definition, one can expect (in terms of probability) the mean of several measurements to be closer to the true value than what is given by a single measurement. This simple idea has many practical applications, but, surprisingly, no such idea can be found in the literature with respect to round-off errors (often thought of as random). Here, we elaborate on this idea, although the main concept is elementary and may intuitively be seen as valid. Therefore, we focus mostly on technical aspects and arguments to show its mechanism in more detail. The commonly used normal distribution, where individual measurements are assumed to have uncorrelated errors, leads to
where
is the error with which we estimate the mean,
is the standard deviation of the probability distribution with the mean
from which the sample originates and
N is the number of measurements. As can be readily seen, the precision increases with repeated measurements as
.
We have already covered many aspects of this method in [
1]; however, the primary focus there was on numerical differentiation. Here, we aim to adopt a more general approach whose scope is numerically unstable problems in general, which are usually (but not necessarily) ill conditioned (the instability of a numerical computation can result not only from the underlying ill-conditioned mathematical problem but also from an inappropriate implementation of the solution (see
Section 3.1)) in the mathematical sense, too. Also, we want to examine new possible dependencies not covered until now, namely, the dependence of the results on the programming language, processor architecture and operating system.
One needs to understand what the method is suited for and what it is not. First of all, we regard our result primarily as a theoretical message, which was not so clearly stated until now: namely, one can, routinely and without some specific requirements, go beyond the usual round-off error precision. From the practical point of view, this, however, applies mostly to situations where no other means (such as arbitrary-precision software) for increasing the precision are available in circumstances where the increase in the precision is of uttermost importance. This may correspond to the evaluation of a black-box function in a fixed number format environment, like when using compiled libraries or when obtaining function values from a server where the function-evaluation process is hidden from the client. It may also possibly apply to situations where re-programming (let us say in arbitrary-precision software) is possible but very costly. The obvious disadvantage is the time consumption (see Equation (
6)), together with the fact that a precision increase is typically limited to a few orders of magnitude (in absolute errors).
The extent of numerical problems we are aiming at is very broad: basically any unstable numerical computation. What generally applies to this domain is that round-off errors are considered random. This point of view is very common and found in many texts; see, e.g., [
2,
3,
4,
5]. What distinguishes us from these authors is the way we use the randomness assumption: the cited texts apply it to stable numerical problems, in which the control of the error is important, and theoretically derive confidence intervals for the results. We, on the contrary, analyze unstable computations, where we let the computer actually perform error propagation in the perturbed-argument scenario with subsequent outcome averaging. Our theoretical concern is only to show that the averaging is justified, our aim being less ambitious: support the claim that the error is generally reduced without precisely quantifying by how much (as numerical experiments show, this does depend on the problem and cannot be reliably quantified in the “black-box” scenario).
In
Section 2, we carry out a theoretical analysis of the approach that we propose, and in
Section 3, numerical experiments are presented.
3. Numerical Experiments
The numerical investigation of the averaging approach can be performed in a large number of directions. One could study the dependence of the results on the size of the perturbation
h, on the precision order
k of the estimator, on the function
f and its test point
, on the statistics
N or on the processor architecture and the programming language (and others). We applied our approach to the numerical differentiation in [
1], where the dependencies on
,
k,
and
N were studied, and we consider them covered. We, therefore, study the two remaining; plus, we test the behavior of the approach for functions with more parameters (which can be perturbed independently). In what follows, we investigate the following:
The evaluation of a function of a single variable;
A matrix inversion in the context of trigonometric interpolation;
The evaluation of higher derivatives of a function.
In all cases, the numerical evaluation is (purposely made) unstable so as to make sense of the averaging procedure. The argument perturbations are generated as random numbers with a uniform distribution from the interval , where h is chosen in the form , , such that it gives the best results. This means that we evaluate using the averaging procedure for various , , and choose the best, which we then compare to the outcome of the single evaluation of . All variables are double precision.
The tested architectures are as follows:
The tested programming languages are as follows:
Three operating systems were used:
Linux Open SUSE Leap 15.1, kernel 4.12.14-lp151.28.91-default;
Android 13, 5.10.186-android12, Motorola Moto G54 Power;
Windows 10 Pro.
From these, the tested combinations (Cx) are shown in
Table 1. When running JavaScript, the Chrome web browser was used in all cases.
For the averaging procedure, we used the Kahan summation algorithm [
7] to have a numerically stable computation of arithmetic means.
3.1. Simple Function
We present two examples of the averaging method applied to the evaluation of a real function of one real variable.
3.1.1. First Example
Inspired by [
8], we investigate the function
at
. The implemented recurrent definition (
7) is numerically unstable, although the alternative expression
implies that the mathematical dependence is not ill conditioned. Actually, a stable evaluation on a computer is also possible, e.g., using a numerical integration method. For averaging, we use
and determine the optimal step to be
. The results are shown in
Table 2. We see an enhancement of the precision by orders of magnitude. Although the numbers differ in various rows, the difference seems to be mainly due to statistical fluctuations (random
generation). This can be seen by looking at the value from the single evaluation (at
) where differences are small: all Linux and ARM calculations agree that
, although Windows scenarios C6 and C7 give a quite different value:
. Still, the difference
is significantly smaller than the error produced by the single evaluation,
. These large fluctuations at such large statistics are somewhat surprising; nevertheless, in any scenario, the precision increase is significant and exceeds one order of magnitude.
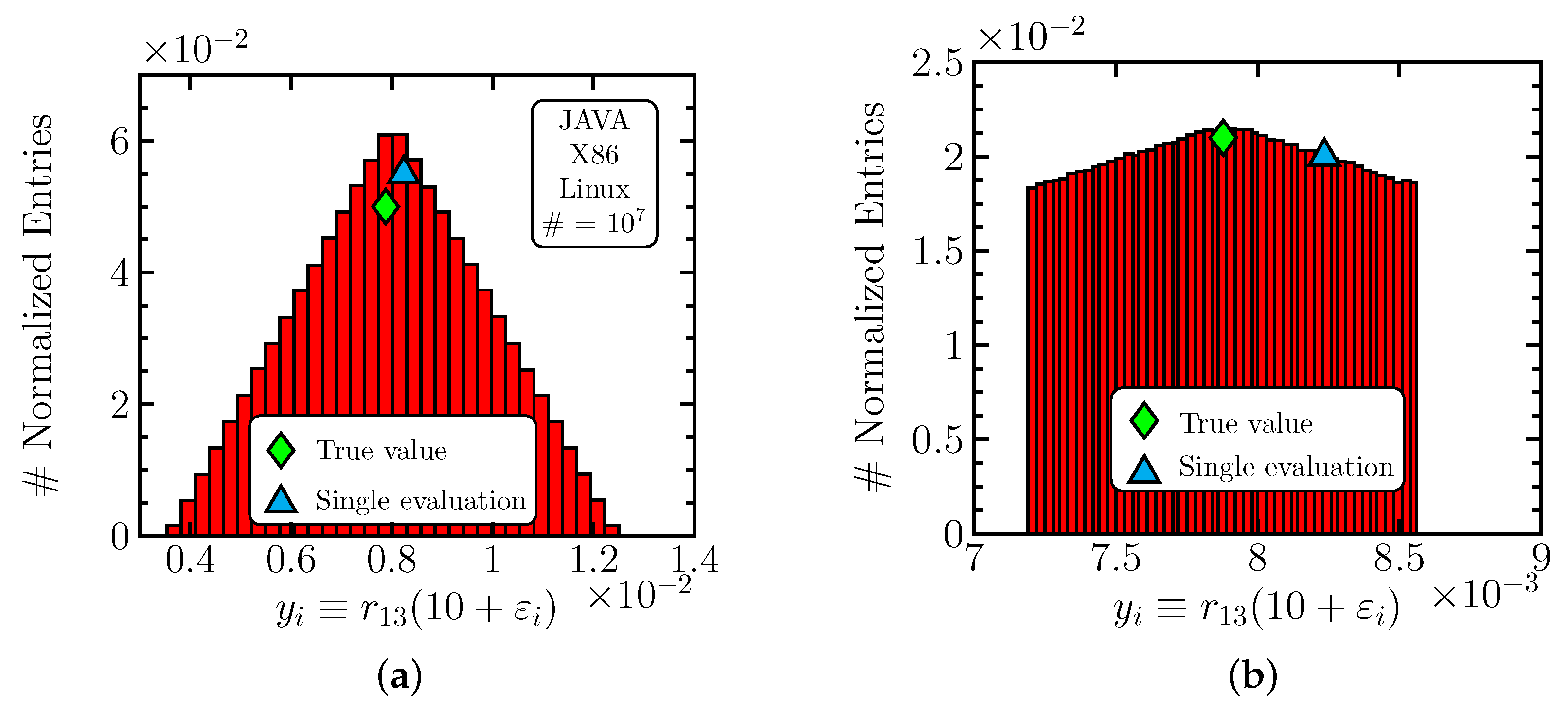
It may be interesting to examine the statistical distribution of
. Because all computing environments give similar results, we show only scenario C1 in
Figure 1. One sees that the distribution is very symmetric but quite broad, meaning that the single evaluation (blue triangle) is close to its peak when compared to the distribution spread. Yet, in sub-figure (b), one observes that the peak of the distribution is significantly closer to the true value (green diamond) than the single evaluation result.
3.1.2. Second Example
We investigate a simple exponentiation implemented in an unstable manner:
Choosing
and
, we compute
using the recurrent relation
where we perturb the value of
. We use
and
. The outcomes are shown in
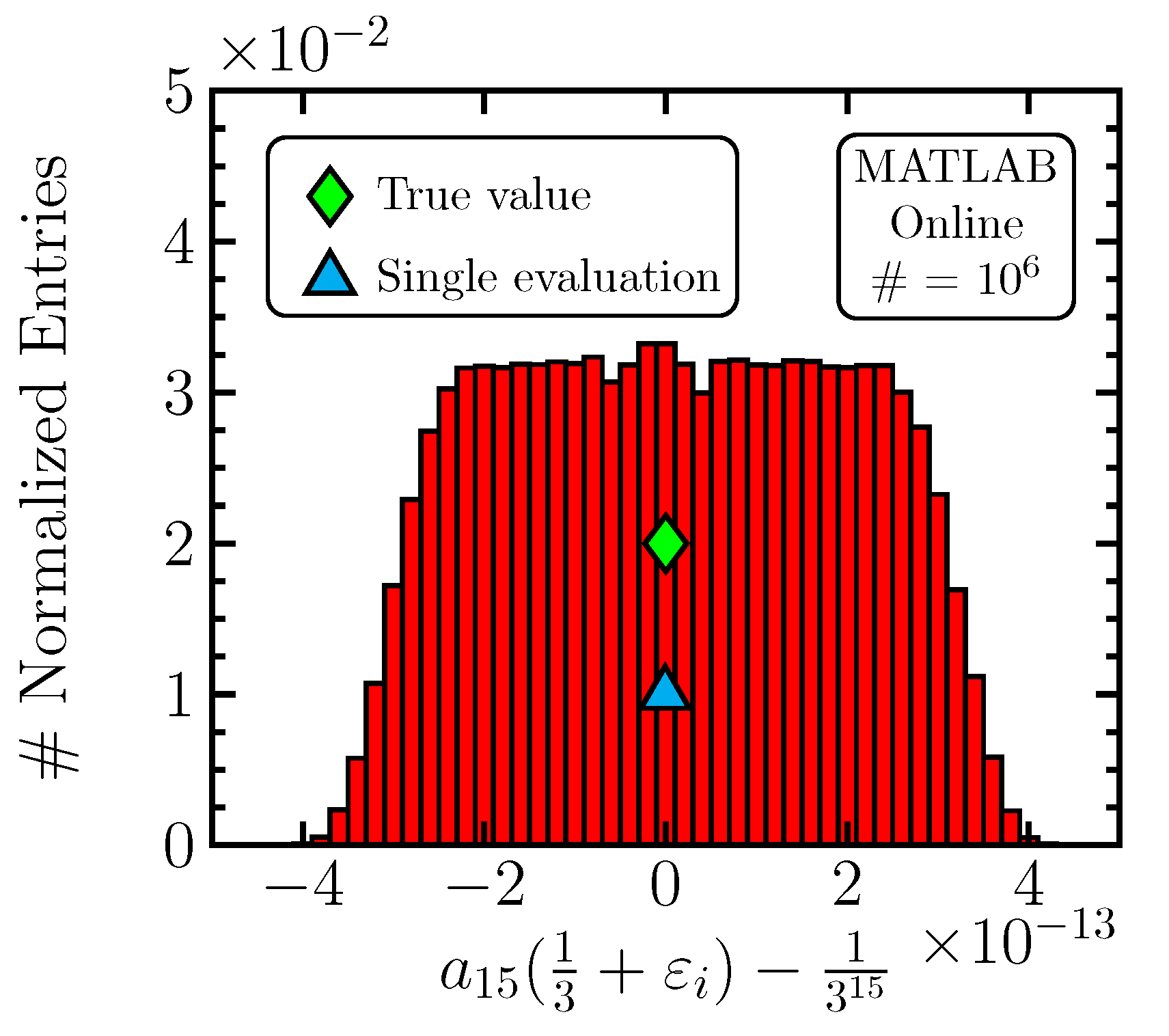
Table 3, and, again, the validity of the averaging approach is demonstrated despite important fluctuations in the entries in the table (observed when attempting to reproduce them). The effect is, however, smaller than in the previous case.
The error distribution for this computation in scenario C8 is shown in
Figure 2.
The “simple function” examples fulfill the expectations that we have with respect to the method: we obtain a symmetric error distribution that provides, by averaging, a significant improvement in precision.
3.2. Matrix Inversion in Trigonometric Interpolation
In this section, we search for coefficients
such that the trigonometric polynomial
interpolates
, with
,
and
, with
Obviously, the correct values are
,
,
and
. The problem is written in a matrix form,
, where
The task is to invert the matrix and find
:
As a matter of fact, the problem is ill conditioned because
is small, and rows of
M are very similar. Various strategies can be adopted when implementing perturbations: e.g., perturb the elements of
M, those of
y, or both. Every option can be studied, but here, we have chosen the first one, because the problem is often stated as “matrix inversion” alone, not necessarily related to some specific vector
y. In each studied case, we independently perturb every element of
M by a random amount, with all perturbations being from the same interval
I. We observe that a typical perturbation (to obtain the best results) is significantly smaller than in the previous case (the
function). The size of the statistical sample is
. The code for matrix inversion differs considerably, depending on the programming language. For Java, we used the
Jama “Matrix” library (
https://math.nist.gov/javanumerics/jama/, accessed on 27 June 2024); for C(++), we borrowed a code published online (
https://github.com/altafahmad623/Operation-Research/blob/master/inverse.c, accessed on 27 June 2024); for Python, the
linalg library from the
numpy package was called; and for JavaScript, we again referred to an implementation found online (
https://web.archive.org/web/20210406035905/http://blog.acipo.com/matrix-inversion-in-javascript/, accessed on 27 June 2024). It turns out that the matrix inversion implementation is the most significant source of differences between various scenarios and, for the C(++) implementation, is unsatisfactory in the current setting due to producing nonsense numbers. For this reason, we make an exception and decrease, in this case, the condition number by setting
. Each result is represented by a set of four numbers, and the outcomes produced under various conditions are summarized in
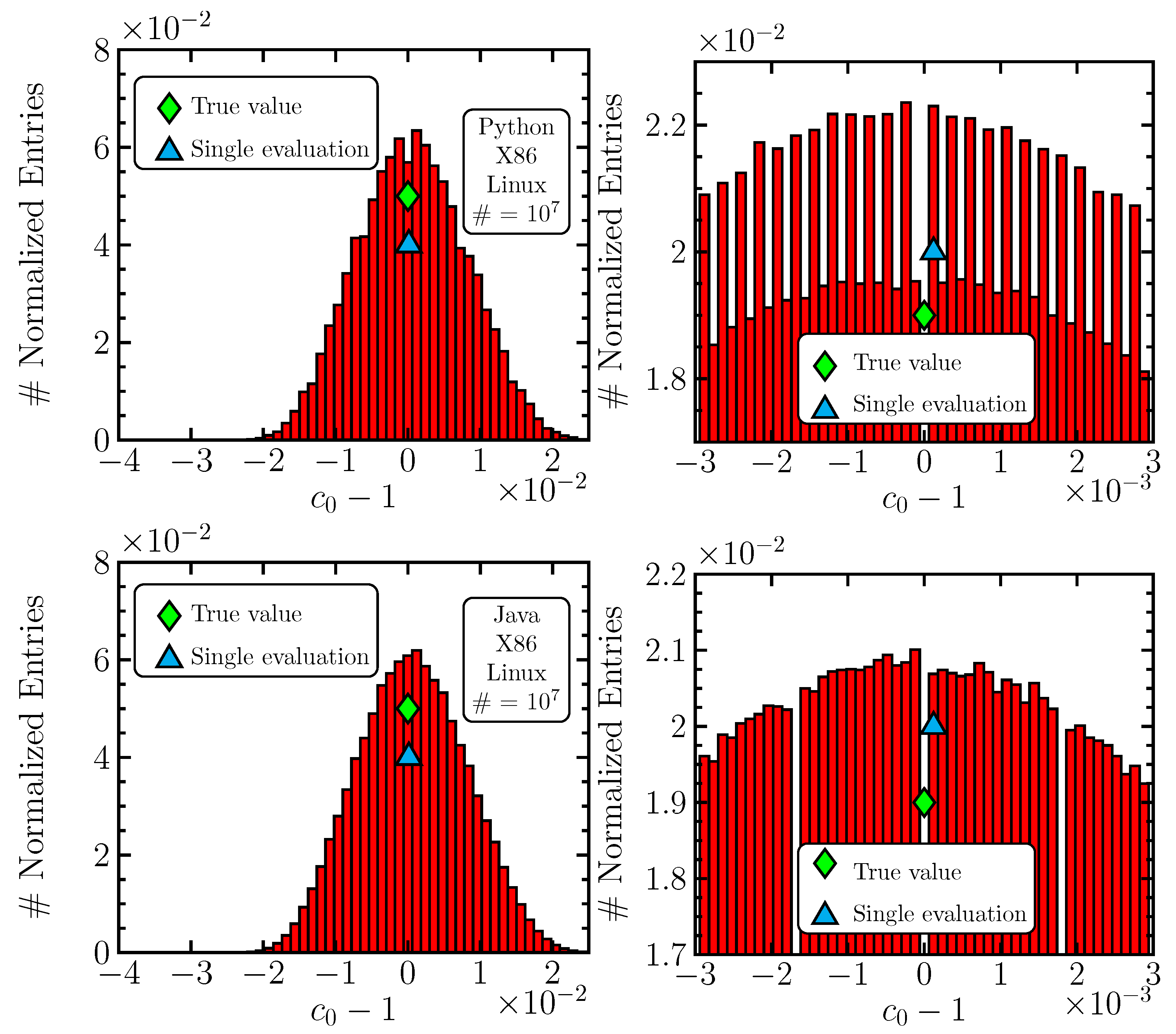
Table 4. Illustrative error-distribution histograms for the
coefficient are shown for the C1 and C3 scenarios in
Figure 3. This time, the shape is Gaussian, and, surprisingly, the Python implementation manifests regular oscillatory structures, certainly a numerical effect, which is missing for Java. Still, both results are comparable since oscillations are also averaged.
The main conclusion that one can draw is that an increase in precision is observed with a significance of around one order of magnitude. Beyond doubt, this cannot be explained by statistical fluctuations, and the averaging method has an effect. The most important factor that determines the outcome is the implementation of the specific mathematical operation (matrix inversion, in our case), and, for an altered scenario with the C(++) code, the increase in precision is much more important (although the code’s performance is much lower because it cannot deal with ).
3.3. Higher-Order Derivatives
The numerical instability increases with the increasing derivative order, and at some point, any method of computation fails. It is interesting to see how various approaches behave in this respect. We obtain inspiration from [
9] and differentiate
at
. All derivatives are integers, and we focus on the few first of them:
We use central difference formulas to obtain estimates; see
Table 5. The formulas depend on two parameters,
and
, and we perturb both of them, one at a time, thus producing two result tables,
Table 6 and
Table 7. Perturbing
is straightforward, and
is perturbed around the optimal value
, which we find by applying the averaging method for an integer
k. Similarly, we compute derivatives (single estimations) at zero, testing different integers
k, and, by comparing them to the true values, we choose the best. The values in the averaging approach are perturbed randomly in the interval
. We set the statistics to
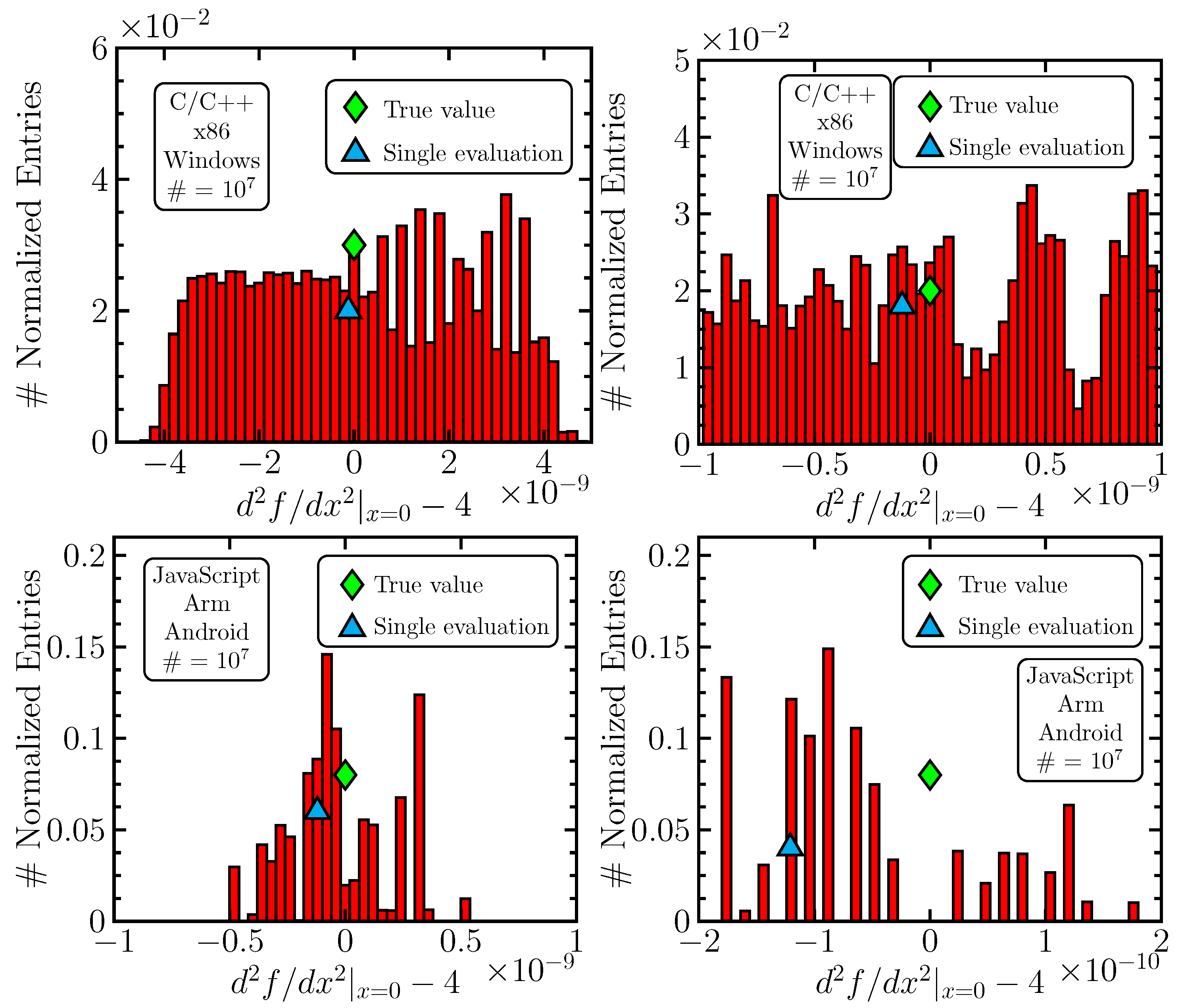
. As illustrative examples, we provide histograms for error distributions of the second derivative for the C5 and C6 scenarios in
Figure 4 and
Figure 5.
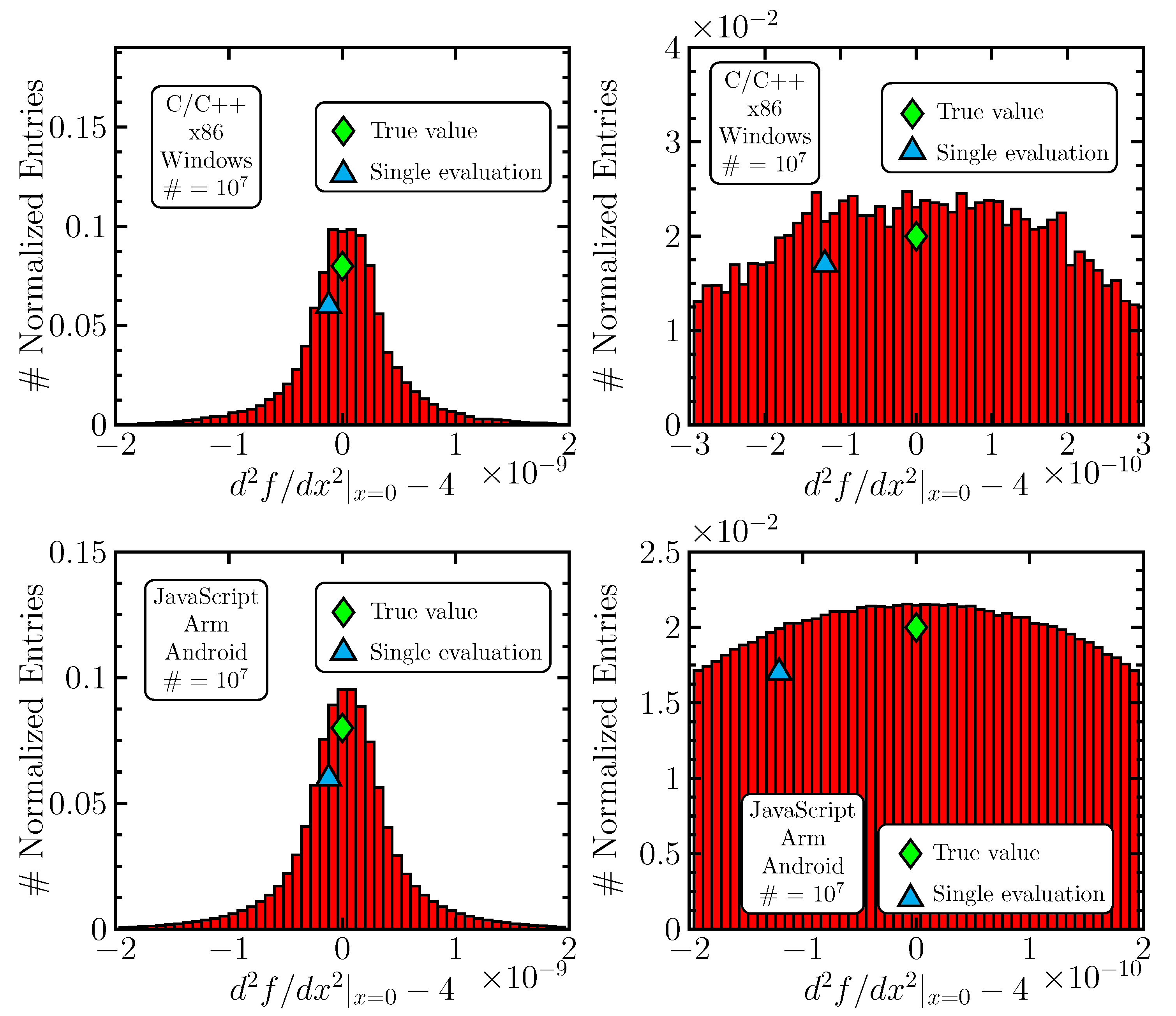
One sees that the averaging method provides an improvement in precision for the first two derivatives, which is generally lost for the third and fourth derivatives. Also, the perturbation in gives more important improvements. It is necessary to understand why the method fails above the second derivative, and we provide, in what follows, a dedicated section to this issue.
The better performance of the
-based approach may be qualitatively understood, since the smallness of the
parameter causes
catastrophic cancellation; i.e., if
is big, then no instability will be present, even for small
x-perturbations. Thus, by varying
in the finite difference
(as an example), a large number of
various values are created, forming an approximate Gaussian, and can be averaged (
Figure 5). Performing a shift in
x, i.e., varying
in
with
fixed, computes function values at two points, which always have the same distance,
. The function value differences then tend to be strongly correlated, and a linear function gives a constant. At the scale
(see
Table 6), the function (
10) is well described by its linear approximation; the small deviation from linearity (and possibly rounding effects) leads to a limited number of floating-point values that the finite difference can take and that are, in addition, unevenly distributed (
Figure 4). Nevertheless, one also observes some differences between the upper and lower pictures in
Figure 5, which indicates that the computing environment also plays a role, because the program codes are more or less equivalent in all scenarios. Another interesting observation is the third derivative in the C6 scenario in both
Table 6 and
Table 7; the precision is significantly increased (unlike in all other scenarios) and is even greater than for the second derivative in the same case. We do not have an understanding of this effect but see it as a further confirmation of the fact that the computing environment may induce important and unpredictable changes in results.
4. Fourth Derivative
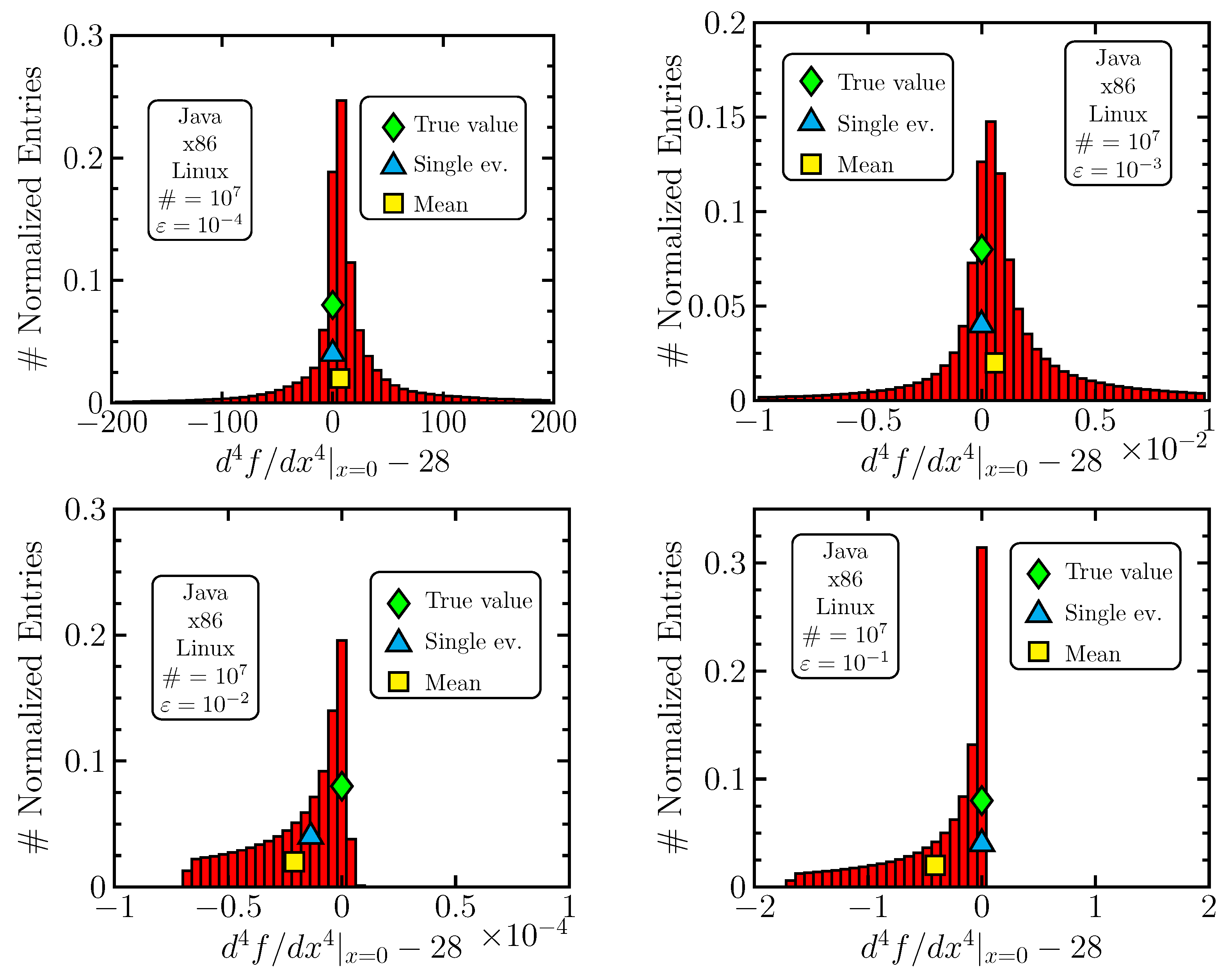
For space and brevity reasons, we do not perform an exhaustive search including all scenarios and analyze the problem only in the C1 case (Java, Linux, x86) by perturbing . We believe that the generalization of our findings is valid, yet, for further confirmation, this issue may be subject to additional studies in the future.
We learn the most by looking at the error histograms. We produced a few of them using
,
,
and
with
(see
Table 7); a larger variation,
, already hits the closest singularity of (
10) at
and leads to strongly disturbed results. The histograms are shown in
Figure 6 and their zoomed-in versions in
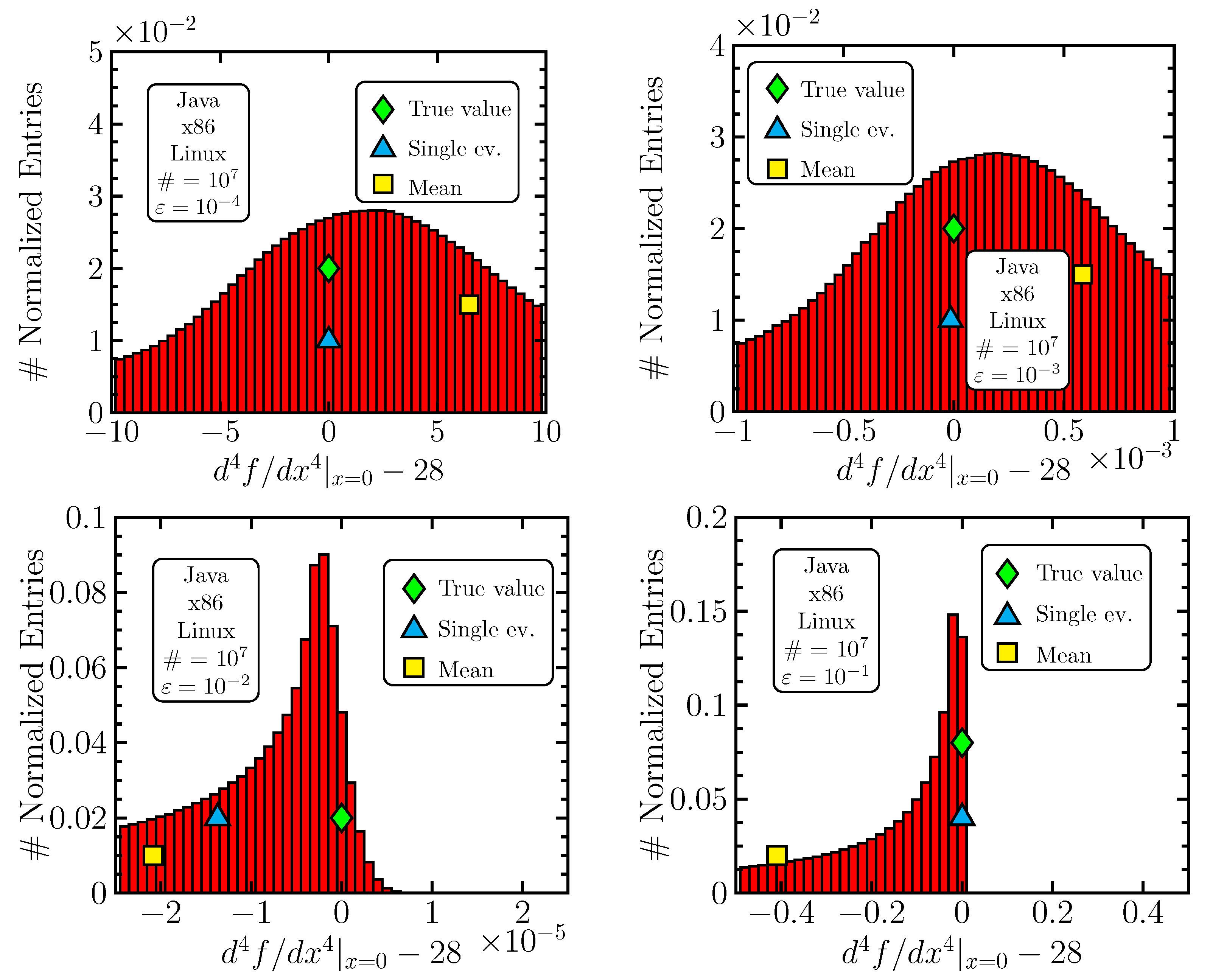
Figure 7. The impact of round-off errors is most easily assessed by (practically) removing them using arbitrary-precision software. In our case, we benefited from the
Apfloat library (
http://www.apfloat.org/, accessed on 27 June 2024) using 300 valid decimal digits and
(and higher). Also, we did not use a random generation of
but regularly divided the interval and performed calculation scanning with the step
. This was carried out with the aim of removing the possible bias from a non-ideal random number generator. This may introduce another bias, which would be, however, uncorrelated. The round-off-error-free histograms are presented in
Figure 8.
The mere description of what one sees in
Figure 6 and
Figure 7 is that the distributions are shifted (the mean of the histogram is represented by the yellow square) and sometimes highly asymmetric. One also observes that the spread of the distribution changes dramatically when changing the discretization parameter
. When compared to
Figure 8, it becomes clear what is going on. For small
, round-off errors appear and make the distribution more symmetric (as we argued), with, however, a (very) large spread. All distributions have some systematic shift, as seen from plots in
Figure 8, which, however, decreases (as expected) with decreasing
. Despite the true value lying in the most probable bin, it is positioned at the edge of the distribution, which makes averaging ineffective. Nevertheless, it is still competitive in precision for
: the fact that the averaging method “loses” can be interpreted as random bad luck; the single-evaluation value (blue triangle, bottom-left graphics in
Figure 6) could have been (if interpreted as random, with the histogram representing the probability distribution function) situated left to the mean. Nevertheless, it is clear that averaging is unable to provide any substantial improvement. For both values
, the round-off effects lose significance, yet a notable rise in bias and spread appears.
As a general assertion, one may say that for very unstable computations, changes in the tested sizes of perturbations (we used a discrete set of the form ) may lead to a steep rise in the systematic bias (which cannot be averaged) and distribution widths. Here, one should distinguish between two cases:
In the second situation, the choice of some perturbation (e.g., , ) may be too small, so the round-off effects dominate. The next, larger choice (e.g., , ) may already be too big, so a significant bias is induced, implying that the region (interval) where the values of the parameter give reasonable results is very small. The first situation is similar: the interval that provides reasonable estimates may be very small around the true value, and going beyond it means a steep rise in the bias and distribution widths. In both scenarios, one can try to make the averaging approach work in this small interval.
In conclusion, we presume that the failure of the averaging approach is generally related to strong variations in the bias and width of the error distribution when perturbing the argument. This causes the interval of possible values of perturbations
to be very small, conflicting with the fact that the machine numbers have non-zero spacing. The distributions to be averaged are then unevenly populated and strongly impaired by numerical effects, sometimes containing only a limited number of discrete values. If a perturbation from outside this interval is used, then other effects that are not round-off-error-related may appear and cause a systematic shift. Further interesting questions related to this topic are discussed in
Appendix B.
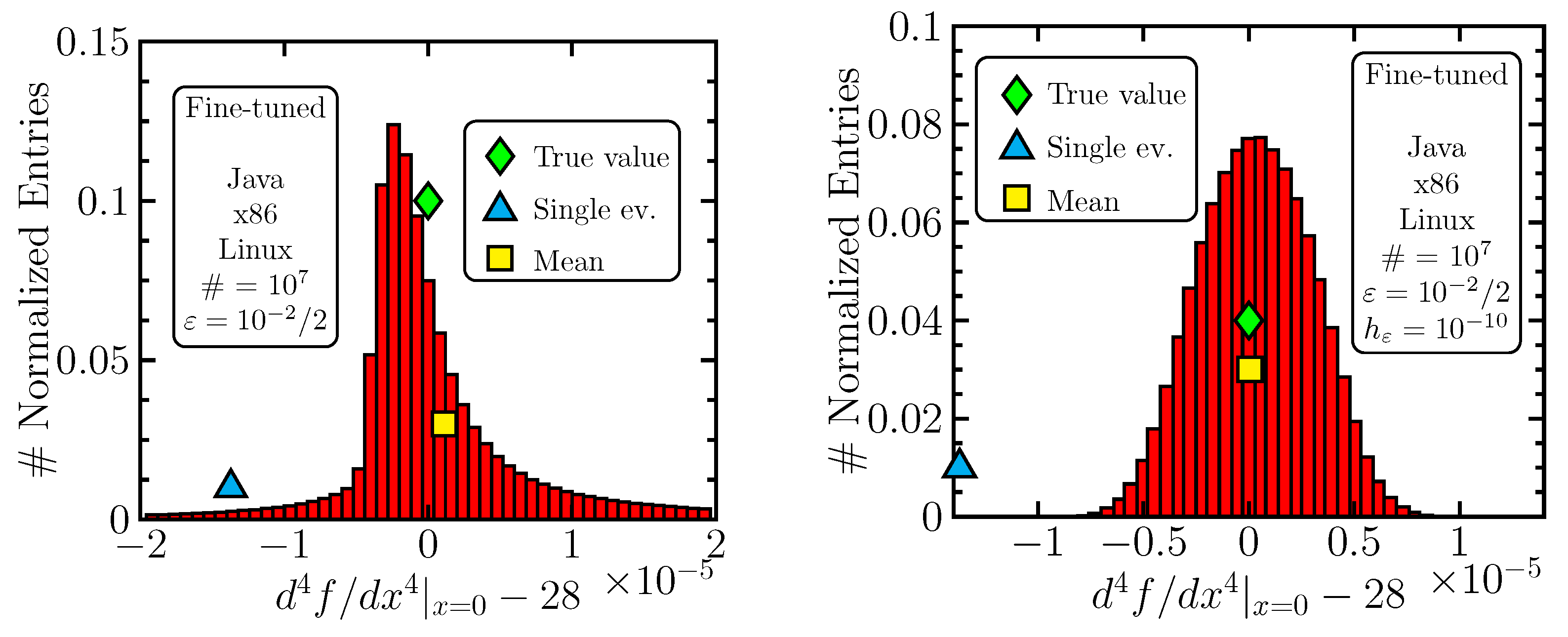
At last, let us perform a simple test: if we change the mean size of the discretization parameter
, we also change, by our convention, the amplitude of its perturbations
, i.e.,
. The average size of the perturbation and, consequently, the length of the interval from which
values are taken are thus adjusted automatically once the choice of
is made. The latter takes the form
, which was chosen for a reason: in a black-box scenario, without the knowledge of the true values, one might only guess which
is desirable and cannot fine-tune. Keeping this in mind, we do not want our results to appear fine-tuned, so the step between the consecutive sizes that we tested is rather big. Let us now allow for some fine-tuning and see what happens for
. The results are
The effect is there: averaging “wins”, and only the appropriate averaging interval went unnoticed by our
scanning radar. The error histogram is shown in
Figure 9—left.
The effect can be strongly amplified if we break our convention: by choosing a smaller value for
, we significantly shorten the interval of the used perturbations
. One notices that the length of this interval is still much greater than computer precision. We obtain
See
Figure 9—right.
5. Summary, Discussion, Conclusions and Outlook
As shown throughout this work, averaging, meant as a tool for suppressing round-off errors in unstable calculations, is effective. For this, we have provided theoretical support and several numerical experiments. If we have the means to fine-tune the size of perturbations and possibly other parameters (the step in differentiation), then in almost every numerical problem, one can choose such values as to outperform the single evaluation in precision. It may happen that the length of the interval around the true (or optimal) value, where the bias and width of the error distributions remain small, is very short and can be compared to the spacing of the floating-point numbers. Then, the averaging approach may suffer from severe numerical effects and may not provide an improvement (but remains competitive).
Averaging can be used in a scenario where any prior information (about the function or numerical effects) is poor, and the question about the optimal size of perturbations is difficult to answer. It seems safe to use perturbations that are small but greater (by an order of magnitude) than the smallest possible one (for a given floating-point arithmetic). With such a choice, an improvement is expected, yet it may be far from the optimal choice. One may also attempt to derive theoretical estimates if at least some constraints are available (bounds on the function and its derivatives); this is our outlook. Still, the safest approach for a given computation is probably to study special cases of this computation or problems that are computationally very similar and have known answers so that the amplitude of perturbations can be tuned.
Nevertheless, our goal is mainly to give a theoretical message, which, despite its simple underlying idea, is not found in the literature. Even so, this does not exclude practical applications of the method in some rare situations. This depends on the circumstances rather than on the method itself. It may happen that a numerical model that one uses and relies on is available only as an executable, without the source code and without the knowledge of its theoretical background. Then, averaging based on perturbing its input parameters may be the only way to increase the precision, if necessary. This could possibly also apply to situations where knowledge is available, but re-programming (let us say in an arbitrary-precision language) is costly. Some quantities (such as the first derivative) are improved significantly by the averaging method (
Table 7), which may improve the practical application potential of averaging for such cases.
In this text, we have put the emphasis on the computing environment, and it indeed has an impact. These effects, complemented by other numerical effects, lead to various observations:
Many numbers in the result tables have substantial fluctuations, as observed when reproducing them. This is in spite of the large statistic that is used.
Distribution shapes vary: sometimes triangular (
Figure 1) and sometimes Gaussian (
Figure 5) or other.
Changing the computational environment may make numerical disturbances (dis)appear. An example is the regular peaky structure seen in the upper-right picture in
Figure 3.
The third derivative is, for some reason, surprisingly precise for the C6 case (C++, Windows).
We do not have an understanding of these effects. Acquiring it would entail tedious work studying low-level computer arithmetic. But, this is not necessary for our purposes: these effects exist, and the averaging approach is cross-platform valid thanks to its robust, statistical character.
Being persuaded that averaging is an existing numerical phenomenon that one can possibly profit from, there are many different directions in which one could investigate it further. One could, for example, search for rules to properly set the averaging parameters for higher-order derivatives, since somewhat disappointing numbers for
in
Table 7 can certainly be improved, as demonstrated in
Section 4.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}