Abstract
This paper introduces an innovative concentration inequality for Extended Negative Dependence (END) random variables, providing new insights into their almost complete convergence. We apply this inequality to analyze END variable sequences, particularly focusing on the first-order auto-regressive (AR(1)) model. This application highlights the dynamics and convergence properties of END variables, expanding the analytical tools available for their study. Our findings contribute to both the theoretical understanding and practical applications of END variables in fields such as finance and machine learning, where understanding variable dependencies is crucial.
Keywords:
dependency analysis; extended negative dependence (END); almost sure convergence; random variables dynamics; concentration inequality; auto-regressive (AR(1)) model MSC:
60E15; 60G50; 62J02; 62M10
1. Introduction
The exploration of dependence among random variables is fundamental in probability theory and spans various scientific disciplines. Particularly, Extended Negative Dependence (END) has emerged as a significant area of study, shedding light on systems where variables inversely influence each other. This paper builds upon the rich theoretical background established by seminal works to advance the understanding of END random variables, their convergence properties, and implications in statistical modeling and analysis.
Liu’s [1] pioneering work on precise large deviations for dependent variables with heavy tails marked a significant advancement in the field, providing a methodological foundation that has influenced subsequent studies. Understanding the behavior of dependent variables, especially those with heavy tails, is crucial as it impacts the reliability of statistical inferences in real-world applications, ranging from financial risk management to environmental statistics.
Building on this foundation, Shen et al. [2,3] introduced probability inequalities for END sequences and elucidated their convergence behaviors. These contributions are pivotal as they not only enhance the theoretical understanding of END variables but also offer practical tools for analyzing their collective dynamics. The study of convergence properties, as explored by Yan [4] and Wang et al. [5], further expands this knowledge base, offering nuanced insights into the statistical properties of END variables through the lens of complete convergence and moment convergence.
The theoretical underpinnings of END variable analysis also draw heavily from classic results in probability theory, such as those by Baum and Katz [6] on convergence rates in the law of large numbers. This theory provides a mathematical framework for assessing the convergence behavior of random variables, a critical aspect when dealing with END variables. Additionally, the work by Chen et al. [7] and Chow [8] on uniform asymptotics and moment complete convergence, respectively, extends the application of these theories to more complex and realistic models.
At the intersection of dependence structures and statistical modeling, the contributions of Ebrahimi and Ghosh [9] on multivariate negative dependence, and Wu and Min [10] on the asymptotic theory of unbounded negatively dependent variables, lay the groundwork for a nuanced understanding of END variables [11,12,13,14]. These studies highlight the complexity of dependence structures and their impact on the asymptotic behavior of statistical estimators and models. Exponential type inequality for unbounded Widely Orthant Dependent (WOD) random variables can be found in [15].
This paper not only synthesizes the aforementioned theoretical advancements but also aims to extend them by exploring new dimensions of END variables and their applications. Boucheron, Lugosi, and Massart’s [16] work on concentration inequalities and Vershynin’s [17] introduction to high-dimensional probability theory provide a modern context for our study. These perspectives are crucial for addressing the challenges posed by high-dimensional data in understanding the behavior of END random variables.
The concentration inequality plays a pivotal role in many limit theorem proofs by providing a measure of partial sum convergence crucial for complete convergence analysis. It was Liu [1] who initially proposed the concept of Extended Negative Dependence (END). Before delving further, let us review the definitions of Lower Negatively Extended Dependent and Upper Negatively Extended Dependent. As outlined by Liu, the Extended Negative Dependence structure surpasses the Negatively Orthant-Dependent (NOD) structure as it can reflect both negative and positive dependence structures to some extent. Liu also provided intriguing examples demonstrating that Extended Negative Dependence supports a wide range of dependency models. According to Joag-Dev and Proschan [18], random variables that are negatively associated (NA) must satisfy the property of negative orthant dependence (NOD). However, not all random variables satisfying NOD are necessarily negatively associated. Therefore, random variables that exhibit negative association are considered endogenous (END).
The potential scenarios where END errors might be relevant include situations with volatility clustering and asymmetric dependence observed in financial time series in financial data, negative dependence between observations due to resource constraints or competition in environmental data, and dependence structures arising from interactions between interconnected components in networked systems.
Therefore, it is crucial to examine the asymptotic characteristics of this expanded END category. Following the release of Ebrahimi and Ghosh’s work [9], researchers have extensively investigated the convergence properties of NOD random sequences using various approaches. A sequence of random variables is said to converge completely to a constant if, for each , the sum of the probabilities . As a consequence of the Borel–Cantelli lemma, almost surely. Therefore, the idea of complete convergence is more powerful than that of almost surely convergence. The first explanation of complete convergence came from Robbins and Hsu [11]. In general, Baum and Katz [6], Chow [8], Wang and others [3,5,7] can all be cited.
This paper aims to enhance the understanding of END variables. We begin by reviewing the literature on END variables, highlighting their defining characteristics and the theoretical advancements. We then introduce a novel concentration inequality tailored to END variables, detailing its derivation and potential applications. Following this, we explore the convergence properties of sequences of END variables, employing theoretical analysis and simulated data to illustrate the practical implications of our findings.
We apply our theoretical findings to linear models, with a particular focus on the first-order auto-regressive (AR(1)) model. This application not only demonstrates the utility of our contributions in a practical setting but also offers new insights into the behavior of END variables in statistical modeling. Through rigorous analysis, we aim to show how our research advances both the theoretical and practical understanding of END variables.
In this comprehensive exploration, our paper unfolds across seven distinctive sections. Section 1 introduces the theoretical foundation and motivation, providing a context for our study. Section 2, Preliminary Lemmas, establishes essential mathematical lemmas that underpin our subsequent analysis. The main theorems and their proofs are presented in Section 3, Main Results and Proofs, offering a deep dive into the theoretical framework, introducing the novel concentration inequality tailored to END random variables and establishing its foundational properties. In Section 4, we present the principal finding of almost complete convergence for sequences of Extended Negative Dependence random variables, leveraging the developed concentration inequality. Section 5 showcases the application of these results in the context of the AR(1) model. Section 6, Numerical Illustration, breathes life into the theoretical framework, showcasing its practical implications through a detailed numerical example. Finally, Section 7 concludes the paper, summarizing its contributions and outlining potential avenues for future research, and also reflecting on the broader significance of our study in the realms of extreme value theory and statistical analysis.
2. Initial Lemmas
The random variables are said to be Lower Extended Negative Dependence (LEND) if there exist some constant such that, for all , , we have
They are said to be Upper Extended Negative Dependence (UEND) if there exist some constant such that, for all , , we have
They are said to Extended Negative Dependence (END) if both (1) and (2) hold for each . Liu developed the notion of the Extended Negative Dependency random process. Clearly, when , the Extended Negative Dependence random process concept is reduced to the concept of negatively orthant-dependent (NOD) random process.
Lemma 1
([19]). For any integer n greater than or equal to 1, if the sequence consists of non-negative numbers and has a dominant coefficient M, then
Specifically, if are uniformly exponentially bounded with dominant coefficients M, then for each and ,
By Lemma 1, we can obtain the following corollary immediately.
Corollary 1.
Let be sequence of END random variables. Then, for each and
Lemma 2.
Let be a sequence of END random variables. And ; then,
Proof of Lemma 2.
Let be a sequence of END random variables, and let . We need to prove that
Recall the expression for the hyperbolic cosine function:
Applying this to the left-hand side, we obtain
By linearity of expectation, this becomes
Since are END random variables, we leverage properties of END sequences. END sequences satisfy certain inequalities that allow us to bound the expectation of sums involving these variables.
For END random variables, we know that negative dependence often leads to certain forms of decoupling inequalities. Specifically, for END random variables, we have
and similarly,
Thus, we have
By the assumption that the sequence is uniformly exponentially bounded, there exist constants , and for all i:
Therefore, combining the bounds for each :
for some constant M that depends on the product of the .
Given the bounds from the END property, we can conclude that
completing the proof with the correct handling of extended negative dependence. □
Lemma 3.
For all
Lemma 4.
Let be an Extended Negative Dependence random process, and for , , if holds for a series of positive numbers c, set and for all K, . Then, for any , we have
3. Main Results and Proofs
Theorem 1.
Let be END random variables for all if there exists a positive constant c such that , for and for all . Then, for any ξ, we have
Proof.
Using Markov’s inequality, along with Corollary 1 and Lemma 2,
By Lemma 4, we obtain
By taking , we obtain
Then,
□
4. Almost Complete Convergence
Corollary 2.
Consider a sequence of identically distributed END random processes. Let us assume that there is a positive number such that it is true for all n greater than or equal to . If there is a positive constant c such that the probability of the absolute value of being less than or equal to c is 1, for i greater than or equal to 1, then for any ξ, , we get
Theorem 2.
Consider the sequence of END random variables . It is given that the expected value , and the probability that the absolute value of is less than or equal to c is 1, for , where c is a positive constant. Now, let Δ be any value greater than 0.
Proof.
For any positive value of , we can deduce from Lemma 4 that
Let () be a positive constant that does not depend on n. Therefore, the proof is finished. □
Theorem 3.
Consider a sequence of identically distributed END random variables. Let us assume that there is a positive integer such that the probability of the absolute value of being less than or equal to c is equal to 1, for i greater than or equal to 1, for every n greater than or equal to , where c is a positive constant. For any positive value of Δ,
Proof.
According to Theorem 1, for any given value of greater than zero, there exists
where is a positive constant independent of n, . Therefore, we have successfully completed the proof. □
5. Application of Results in a Linear Model
The Autoregressive Model of Order 1 (AR(1))
We explore an autoregressive model of the first order AR(1), which is defined by
where is a sequence of END random variables with ,, and is a parameter with Hence (15) as follows:
The coefficient is determined by the least squares method, resulting in the estimator below.
Theorem 4.
Once the requirements of Theorem 1 are met, for each that is positive, we obtain
where
Proof.
From (18) it follows that
Thus, based on the probability characteristics and Holder’s inequality, it follows that for every ,
First, we begin by estimating the value of , followed by estimating the value of .
It is evident that
Applying Theorem 1, the expression on the right-hand side of Equation (20) is transformed.
Next, we establish an upper limit for the right-hand side of the equation of . For any , it follows that
By taking , then for any ,
□
Corollary 3.
Whenever the sequence completely converges to the parameter θ of the first-order autoregressive process, then we can conclude that
Proof.
By applying Theorem 3 and assuming that is finite and is finite, we may directly obtain the result stated in Corollary 3. □
6. Numerical Illustration
In this section, we provide a comprehensive numerical demonstration of concentration inequalities applied to a dataset generated from an autoregressive process with transformed residuals. Our main objective is to validate and visualize the concentration of the sum of transformed residuals around its expected value.
Concentration inequalities are vital tools in probability theory and statistical analysis, offering limits on the deviation of random variables from their expected values. This section explores the application of concentration inequalities to a dataset derived from an autoregressive process with transformed residuals, examining the implications of extreme value theory (EVT) on the distribution’s tails.
The methodology of this study involved generating a dataset that represents an autoregressive process AR(1) with residuals transformed into Extended Negative Dependence random variables (END) using the sine function, in Figure 1 and Figure 2 below.
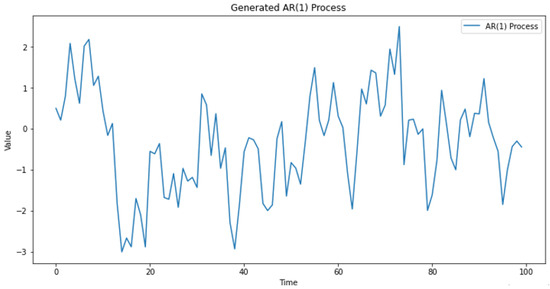
Figure 1.
Generated dataset representing an autoregressive process AR(1).
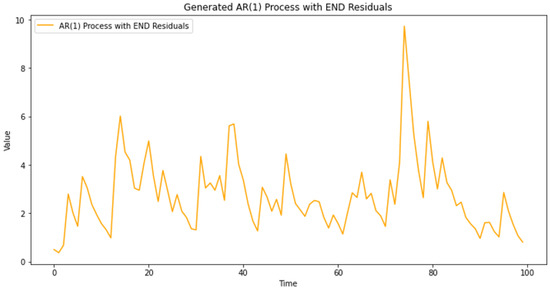
Figure 2.
Residuals.
When we proceed to verify END properties for the transformed residuals, we find that the condition, for all k, , is not satisfied. Therefore, we apply an additional transformation using a sine function, Figure 3 below.
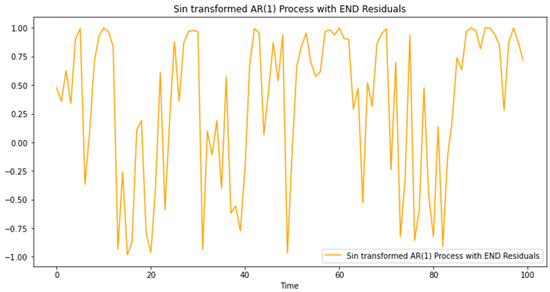
Figure 3.
Sinus transformation.
Before verifying the condition above for this final transformation, we ensure that the sine-transformed data remain Extended Negative Dependence random variables (ENDs) through moment conditions and the Q-Q plot in the Figure 4 below.
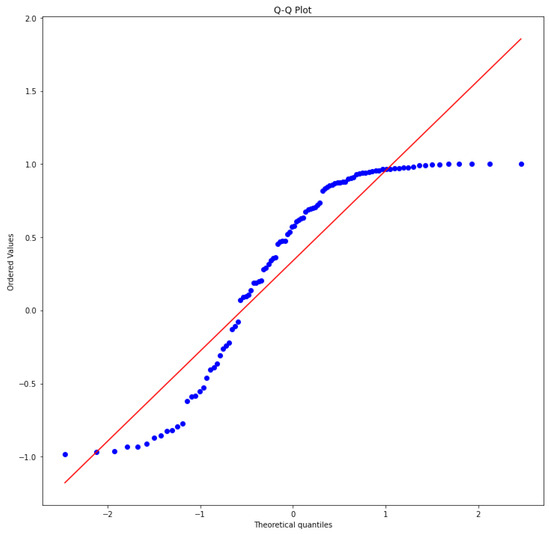
Figure 4.
Q-Q plot.
The points roughly follow a straight line from around −2.0 to 1.5 on the x-axis. This indicates that the data approximates a normal distribution.
Prior to delving into the concentration inequality, we rigorously confirm that the transformed residuals meet the conditions outlined by Theorem 1. Specifically, we validate that for all .
Ensuring the meticulous verification of these conditions is crucial for laying the foundation for the subsequent analysis of concentration inequalities.
With these conditions confirmed, we proceed to compute the theoretical bound for the concentration inequality. The bound is expressed as
where M, , and are constants determined based on the characteristics of the transformed residuals.
Subsequently, we compute the actual probability of the sum of transformed residuals deviating from its expected value for varying sample sizes. This involves calculating the cumulative sum of the transformed data (Sn) and comparing it with the expected cumulative sum (ESn).
The culmination of our numerical illustration is visualized through a line plot. This plot showcases the theoretical bound alongside the actual probability for different sample sizes, offering a visual comparison of the concentration behavior in Figure 5 below.
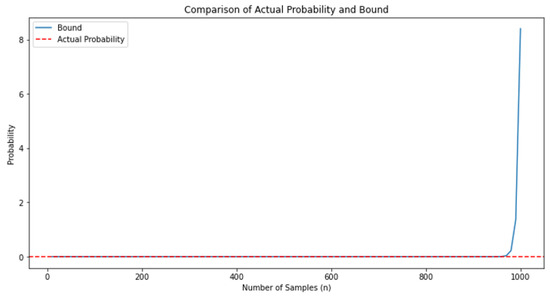
Figure 5.
Comparison of the concentration behavior.
The results obtained from the numerical illustration shed light on the concentration behavior of the sum of transformed residuals. The visual comparison of the theoretical bound and the actual probability reinforces the validity of the concentration inequality for the given dataset.
Furthermore, the verification of conditions ensures the applicability of Theorem 1 to the transformed residuals, affirming the foundational assumptions crucial for the subsequent analysis.
In conclusion, this section provides a comprehensive numerical illustration of concentration inequalities applied to transformed residuals from an autoregressive process. Through meticulous verification of conditions, calculation of theoretical bounds, and visual comparison with actual probabilities, we gain insights into the concentration behavior of the transformed data.
This analysis contributes to a deeper understanding of statistical properties in the context of EVT, particularly for non-random variables exhibiting extreme value behavior. The verified concentration inequalities provide a solid foundation for subsequent analyses and form a basis for further exploration into the tails of the distribution.
Through this illustration, we not only showcase the application of concentration inequalities but also emphasize the importance of thorough verification and visual representation in establishing the reliability of statistical results.
7. Conclusions
Our research investigates the complete convergence of Extended Negative Dependence (END) random variables and their applications in autoregressive AR(1) models. By employing exponential inequalities and specific inequalities for the likelihood of END variables, we demonstrate significant insights into their convergence properties. Our findings show that the proposed concentration inequalities effectively characterize the statistical behavior of END random variables.
The results from our theoretical analysis and numerical illustrations underscore the robustness of our approach. Specifically, the application of our methodology to AR(1) models reveals important dynamics and convergence properties of END variables, validating the practical significance of our theoretical contributions.
Moving forward, our methodology can be extended to other statistical models to further validate its applicability. Additionally, exploring higher-order moments and different tail behaviors in real-world datasets can enhance our understanding of extreme events and dependencies. This research lays a solid foundation for future studies, encouraging further collaboration and innovation in statistical analysis and extreme value theory.
Author Contributions
Authors Z.C.E., A.B., H.D., F.A. and Z.K. have made significant contributions to this manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by two funding sources: (1) Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R358), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia and (2) The Deanship of Research and Graduate Studies at King Khalid University, which provided a grant (RGP1/163/45) for a Small Group Research Project.
Data Availability Statement
Data used in this research study are within the paper.
Acknowledgments
The authors thank and extend their appreciation to the funders of this work: (1) Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP- 2024R358), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia; (2) The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through small under grant number group research RGP1/163/45.
Conflicts of Interest
There are no conflicts of interest to declare by the authors.
References
- Liu, L. Precise large deviations for dependent random variables with heavy tails. Stat. Probab. Lett. 2009, 79, 1290–1298. [Google Scholar] [CrossRef]
- Shen, A. Probability inequalities for END sequence and their applications. J. Inequalities Appl. 2011, 2011, 98. [Google Scholar] [CrossRef]
- Shen, A.; Zhang, Y.; Wang, W. Complete convergence and complete moment convergence for Extended Negative Dependence random variables. Filomat 2017, 31, 1381–1394. [Google Scholar] [CrossRef]
- Yan, J. Complete convergence and complete moment convergence for maximal weighted sums of Extended Negative Dependence random variables. Acta Math. Sin. Engl. Ser. 2018, 34, 1501–1516. [Google Scholar] [CrossRef]
- Wang, X.; Xu, C.; Hu, T.; Andrei, V.; Hu, S. On complete convergence for widely orthant dependent random variables and its applications in nonparametric regression models. TEST 2014, 23, 607–629. [Google Scholar] [CrossRef]
- Baum, L.E.; Katz, M. Convergence rates in the law of large numbers. Ams Am. Math. Soc. 1965, 120, 108–123. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, L.; Wang, Y. Uniform asymptotics for the finite-time ruin probabilities of two kinds of nonstandard bidimensional risk models. J. Math. Anal. Appl 2013, 401, 114–129. [Google Scholar] [CrossRef]
- Chow, Y.S. On the rate of moment complete convergence of sanple sums and extremes. Bull. Inst. Math. Acad. Sin. 1988, 16, 177–201. [Google Scholar]
- Ebrahimi, N.; Ghosh, M. Multivariate negative dependence. Commun. Stat. Theory Methods 1981, 10, 307–337. [Google Scholar]
- Wu, W.; Min, W. On the asymptotic theory of unbounded negatively dependent random variables. Stat. Sin. 2005, 15, 1141–1155. [Google Scholar]
- Robbins, H.; Hsu, L. Complete convergence and the law of large numbers. Proc. Natl. Acad. Sci. USA 1947, 33, 25–31. [Google Scholar]
- Tang, Q. Insensitivity to negative dependence of the asymptotic behavior of precise large deviations. Electron. J. Probab. 2006, 11, 107–120. [Google Scholar] [CrossRef]
- Yongfeng, W.; Mei, G. onvergence properties of the sums for sequences of END random variables. Korean Math. Soc. 2012, 49, 1097–1110. [Google Scholar]
- Yongming, L. On the rate of strong convergence for a recursive probability density estimator of END samples and its applications. J. Math. Inequal. 2017, 11, 335–343. [Google Scholar]
- Kaddour, Z.; Belguerna, A.; Benaissa, S. New tail probability type inequalities and complete convergence for wod random variables with application to linear model generated by wod errors. J. Sci. Arts 2022, 22, 309–318. [Google Scholar] [CrossRef]
- Boucheron, S.; Lugosi, G.; Massart, P. Concentration Inequalities: A Nonasymptotic Theory of Independence; Oxford University Press: Oxford, UK, 2013. [Google Scholar]
- Vershynin, R. High-Dimensional Probability: An Introduction with Applications in Data Science; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar]
- Joag-Dev, K.; Proschan, F. Negative Association of Random Variables, with Applications. Ann. Stat. 1983, 11, 286. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, A.; Ng, K.W. The Strong Law of Large Numbers for Extended Negatively Dependent Random Variables. J. Appl. Probab. 2010, 47, 908–922. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).