
Small Area Estimation under Poisson–Dirichlet Process Mixture Models


Abstract
1. Introduction
2. Theoretical Background
2.1. Nested Error Regression Models
- Define a conditional on and , as well as estimator , for , independently;
- Define a conditional on and small area means , for , independently;
- The model parameters are given a prior distribution with a density .
2.2. Poisson–Dirichlet Process
3. Small Area Model with PDP Random Effects
- Define a conditional on , , , and ; estimator is given by , for , independently;
- Define a conditional on , , and ; the random effects are given by and , for , independently.
4. Estimation
4.1. Proposed Approach
4.1.1. Estimation of Regression Coefficients and Error Variance
4.1.2. Estimation of the Base Distribution and Two Parameters of the Poisson–Dirichlet Process
4.2. Algorithms
4.2.1. Selection of Initial Values
4.2.2. Full Conditional Distributions of the MCMC Algorithm
4.2.3. Sampling and Estimation
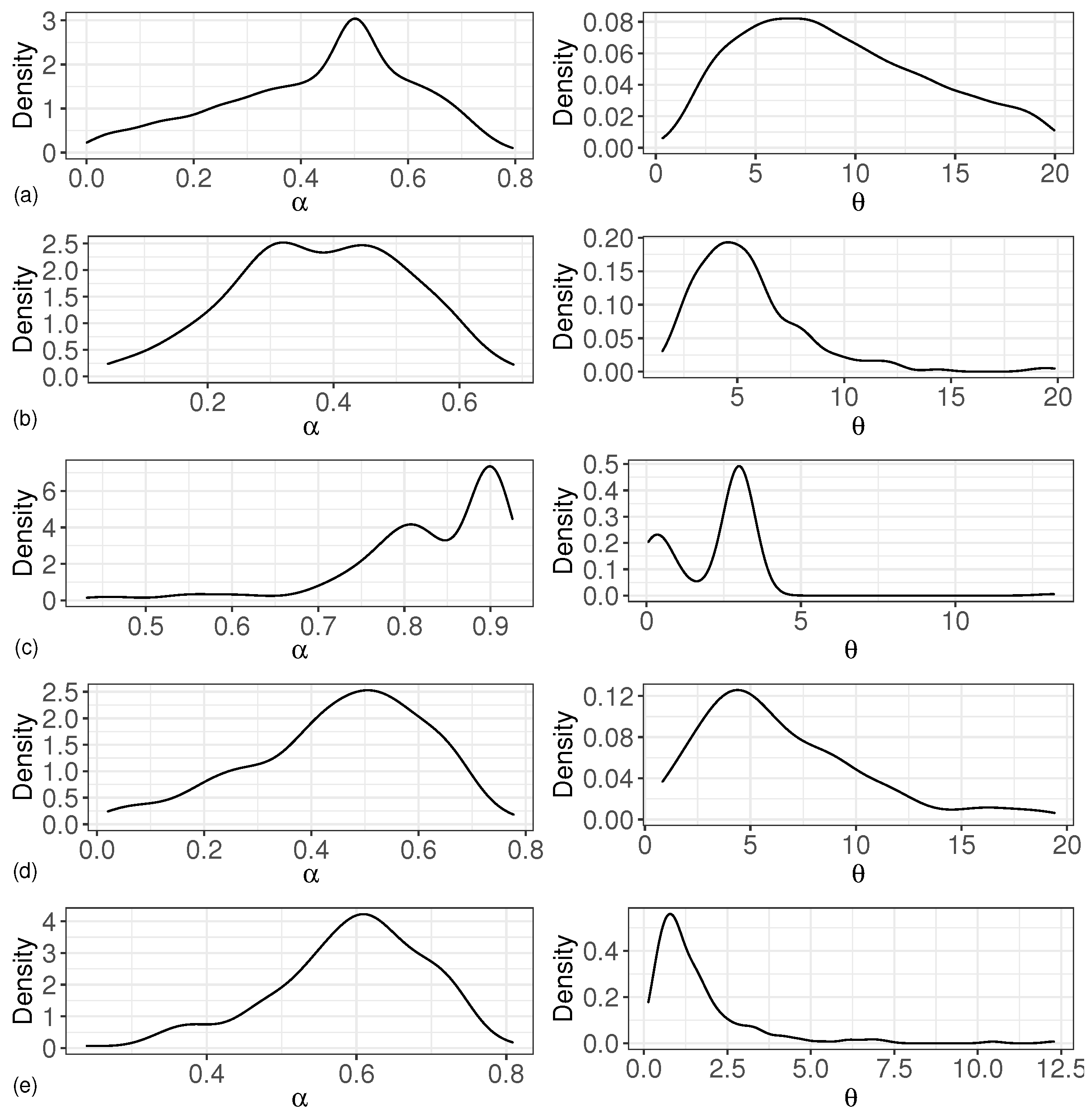
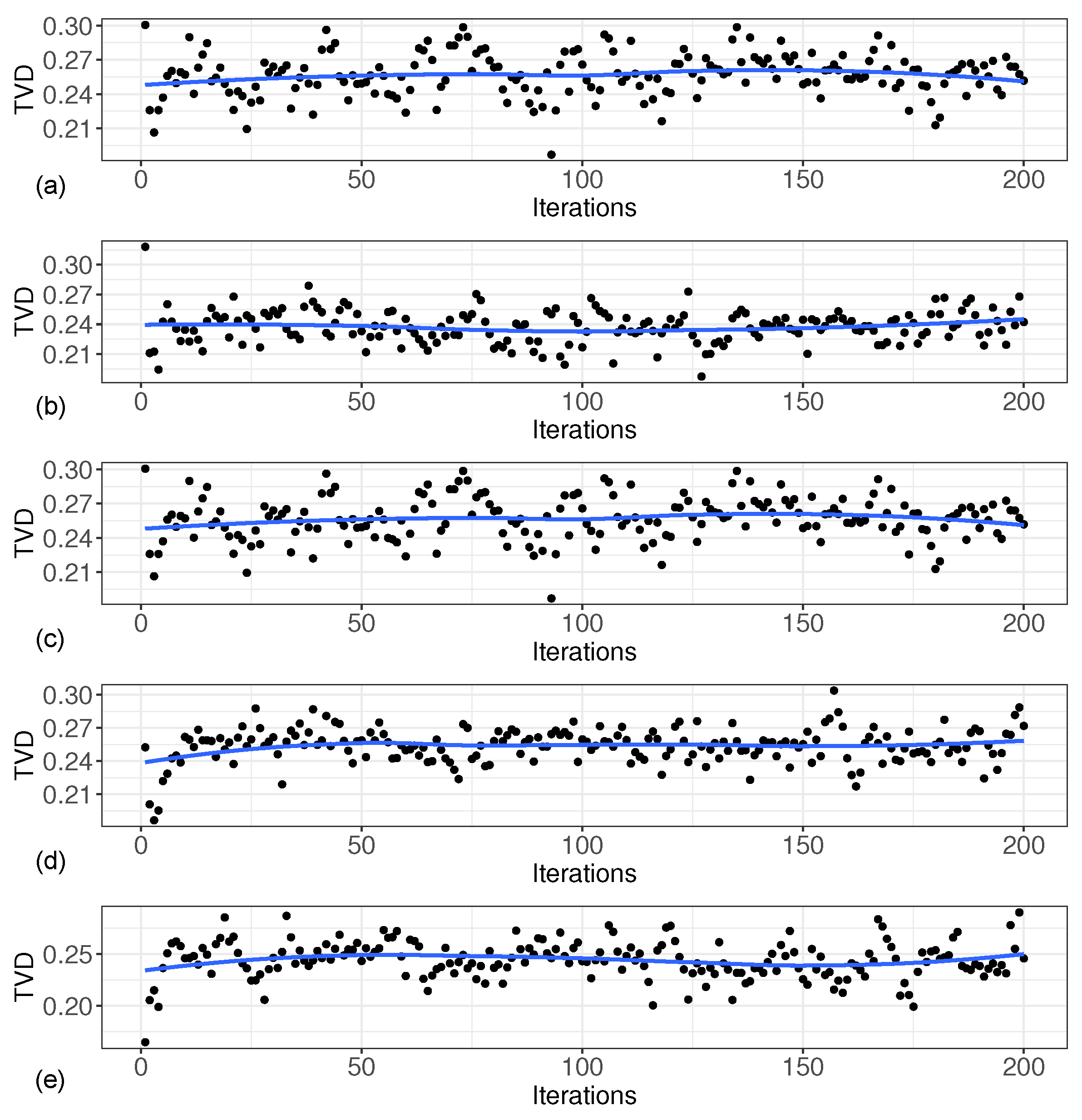
5. Simulation
5.1. Model Setup and Simulation Conditions
- Five choices of parameters are: , , , , or , and the base distribution is set to be , , or ;
- The error comes from a normal distribution ;
- The true value of the regression coefficient is set to ;
- The initial parameter values are set to be , , , , or when is , , , , or ;
- The initial random effects are set to ;
- The number of iterations for the MCMC algorithm is set to .
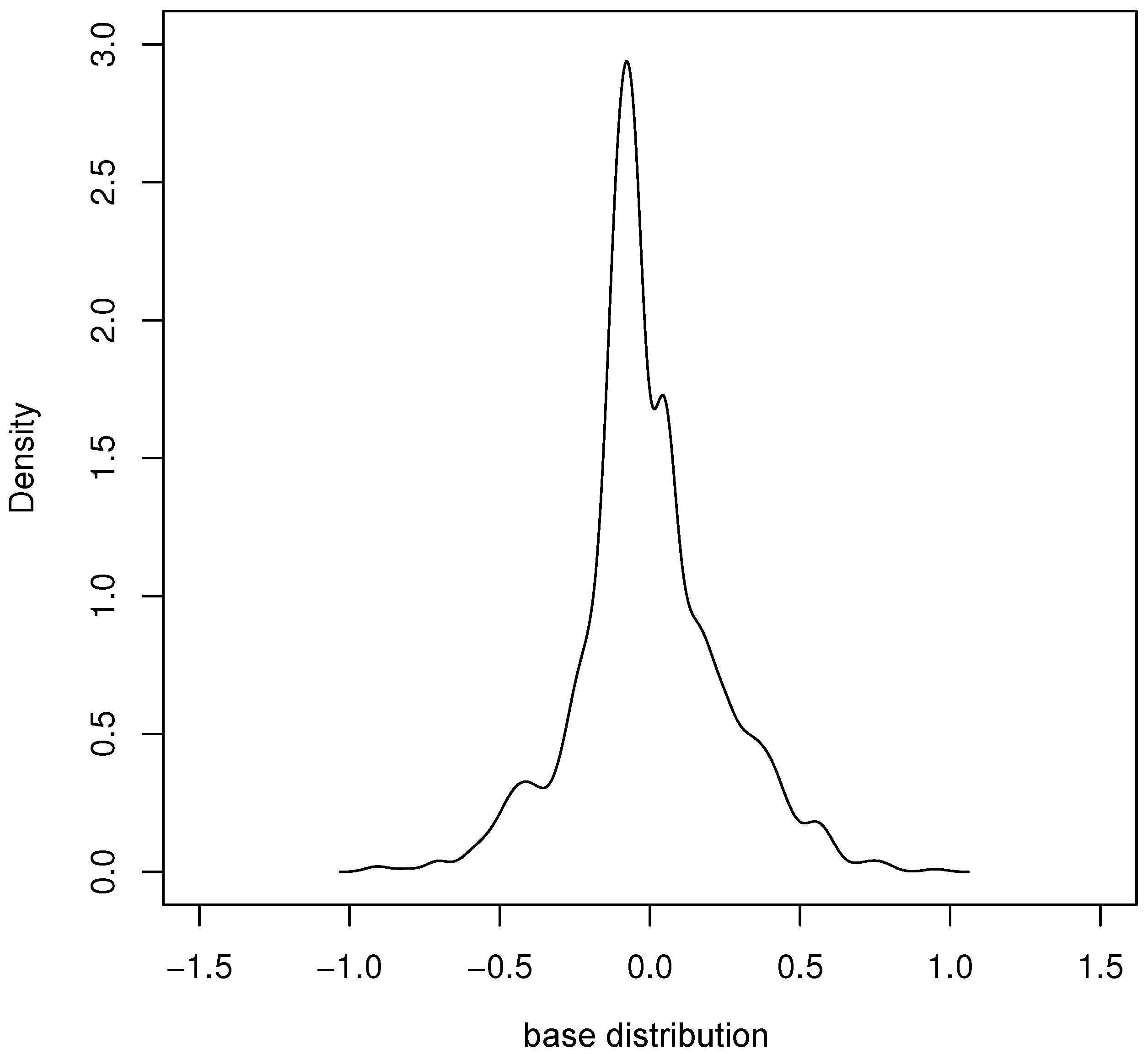
5.2. Simulation Results and Analysis
5.3. Simulated Normal Data
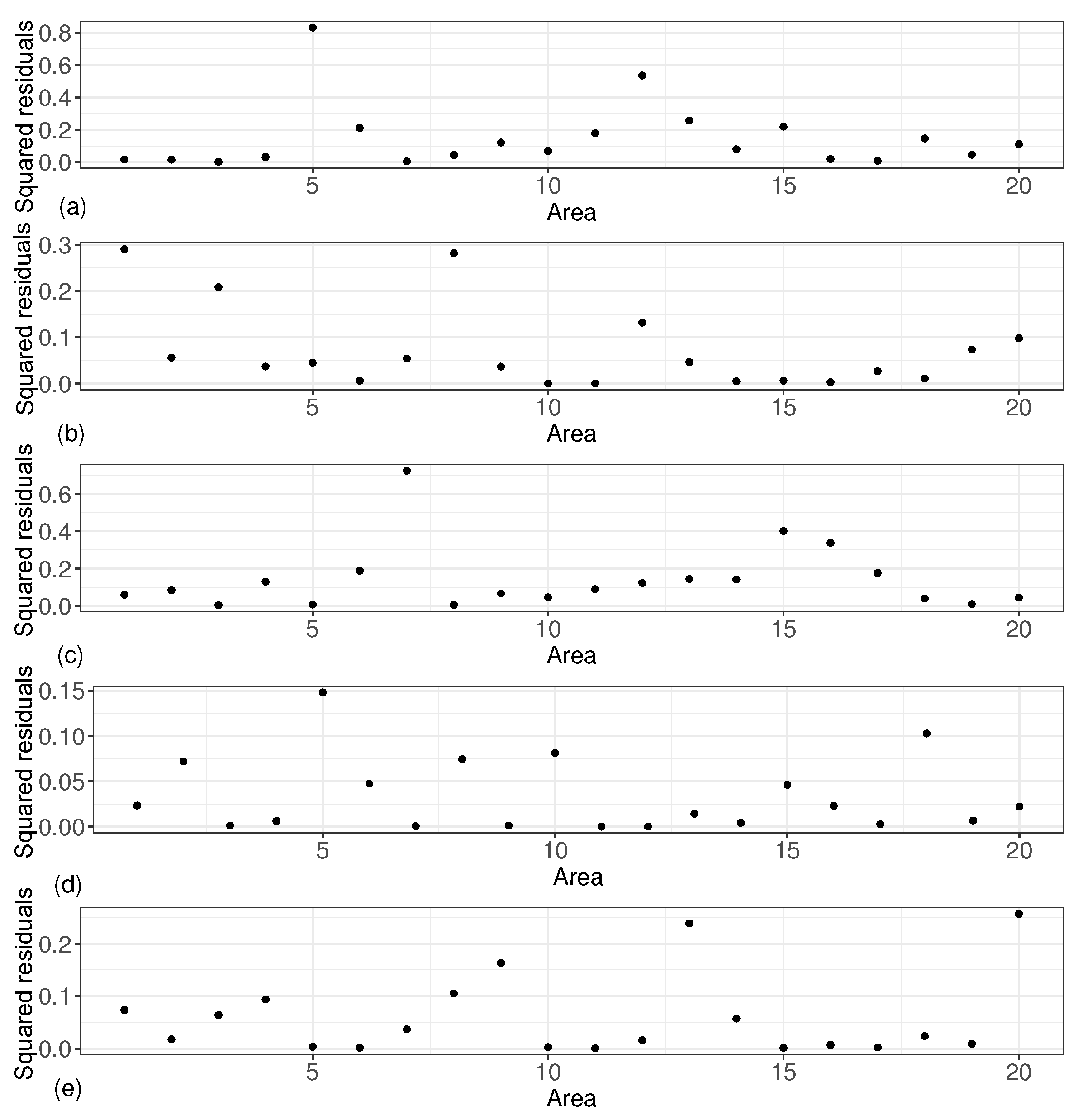
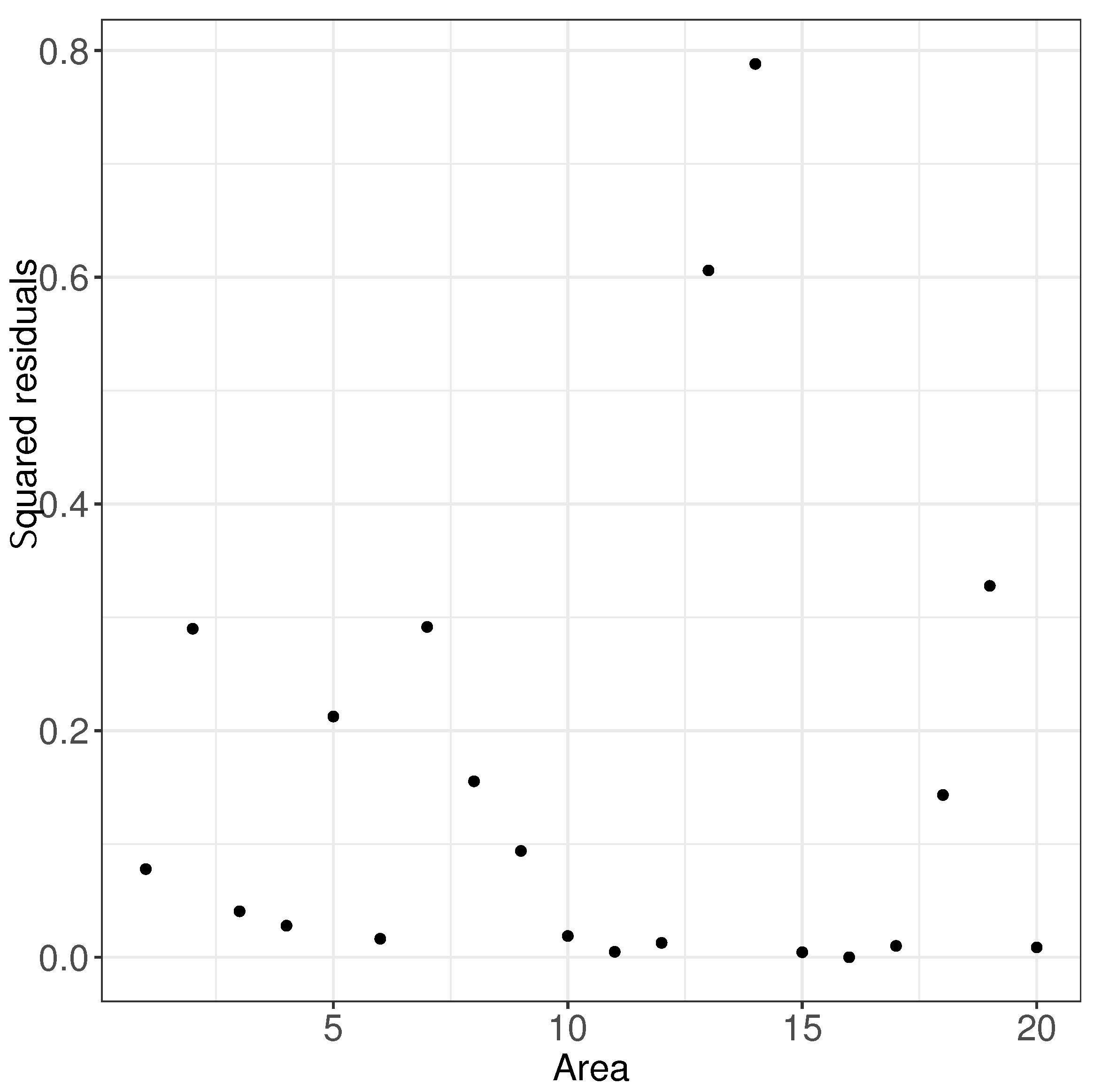
6. Application
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rao, J.N. Small Area Estimation; John Wiley & Sons: Hoboken, NJ, USA, 2005; Volume 331. [Google Scholar]
- Pfeffermann, D. New important developments in small area estimation. Stat. Sci. 2013, 28, 40–68. [Google Scholar] [CrossRef]
- Rao, J.N.; Molina, I. Small Area Estimation; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Fay, R.E., III; Herriot, R.A. Estimates of income for small places: An application of James-Stein procedures to census data. J. Am. Stat. Assoc. 1979, 74, 269–277. [Google Scholar] [CrossRef]
- Battese, G.E.; Harter, R.M.; Fuller, W.A. An error-components model for prediction of county crop areas using survey and satellite data. J. Am. Stat. Assoc. 1988, 83, 28–36. [Google Scholar] [CrossRef]
- Arima, S.; Bell, W.R.; Datta, G.S.; Franco, C.; Liseo, B. Multivariate Fay–Herriot Bayesian estimation of small area means under functional measurement error. J. R. Stat. Soc. Ser. A Stat. Soc. 2017, 180, 1191–1209. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, J. Small area mean estimation after effect clustering. J. Appl. Stat. 2020, 47, 602–623. [Google Scholar] [CrossRef] [PubMed]
- Datta, G.S.; Hall, P.; Mandal, A. Model selection by testing for the presence of small-area effects, and application to area-level data. J. Am. Stat. Assoc. 2011, 106, 362–374. [Google Scholar] [CrossRef]
- Sugasawa, S.; Kubokawa, T. Bayesian estimators in uncertain nested error regression models. J. Multivar. Anal. 2017, 153, 52–63. [Google Scholar] [CrossRef]
- Ferrante, M.R.; Pacei, S. Small domain estimation of business statistics by using multivariate skew normal models. J. R. Stat. Soc. Ser. A Stat. Soc. 2017, 180, 1057–1088. [Google Scholar] [CrossRef]
- Fabrizi, E.; Trivisano, C. Robust linear mixed models for small area estimation. J. Stat. Plan. Inference 2010, 140, 433–443. [Google Scholar] [CrossRef]
- Chakraborty, A.; Datta, G.S.; Mandal, A. A two-component normal mixture alternative to the Fay-Herriot model. Stat. Transit. New Ser. 2016, 17, 67–90. [Google Scholar]
- Diallo, M.S.; Rao, J. Small area estimation of complex parameters under unit-level models with skew-normal errors. Scand. J. Stat. 2018, 45, 1092–1116. [Google Scholar] [CrossRef]
- Tsujino, T.; Kubokawa, T. Empirical Bayes methods in nested error regression models with skew-normal errors. Jpn. J. Stat. Data Sci. 2019, 2, 375–403. [Google Scholar] [CrossRef]
- Opsomer, J.D.; Claeskens, G.; Ranalli, M.G.; Kauermann, G.; Breidt, F.J. Non-parametric small area estimation using penalized spline regression. J. R. Stat. Soc. Ser. B Stat. Methodol. 2008, 70, 265–286. [Google Scholar] [CrossRef]
- Polettini, S. A Generalised Semiparametric Bayesian Fay–Herriot Model for Small Area Estimation Shrinking Both Means and Variances. Bayesian Anal. 2016, 12, 729–752. [Google Scholar] [CrossRef]
- Pitman, J.; Yor, M. The two-parameter Poisson-Dirichlet distribution derived from a stable subordinator. Ann. Probab. 1997, 25, 855–900. [Google Scholar] [CrossRef]
- Al-Labadi, L.; Hamlili, M.; Ly, A. Bayesian Estimation of Variance-Based Information Measures and Their Application to Testing Uniformity. Axioms 2023, 12, 887. [Google Scholar] [CrossRef]
- Handa, K. The two-parameter Poisson–Dirichlet point process. Bernoulli 2009, 15, 1082–1116. [Google Scholar] [CrossRef]
- Favaro, S.; Lijoi, A.; Mena, R.H.; Prünster, I. Bayesian non-parametric inference for species variety with a two-parameter Poisson–Dirichlet process prior. J. R. Stat. Soc. Ser. B Stat. Methodol. 2009, 71, 993–1008. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis, 3rd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2013. [Google Scholar]
- Yang, L.; Wu, X. Estimation of Dirichlet process priors with monotone missing data. J. Nonparametr. Stat. 2013, 25, 787–807. [Google Scholar] [CrossRef]
- Qiu, X.; Yuan, L.; Zhou, X. MCMC sampling estimation of Poisson-Dirichlet process mixture models. Math. Probl. Eng. 2021, 2021, 6618548. [Google Scholar] [CrossRef]
- Carlton, M.A. Applications of the Two-Parameter Poisson-Dirichlet Distribution; University of California: Los Angeles, CA, USA, 1999. [Google Scholar]
- Neal, R.M. Markov chain sampling methods for Dirichlet process mixture models. J. Comput. Graph. Stat. 2000, 9, 249–265. [Google Scholar] [CrossRef]
- Molina, I.; Rao, J.N. Small area estimation of poverty indicators. Can. J. Stat. 2010, 38, 369–385. [Google Scholar] [CrossRef]
- Molina, I.; Marhuenda, Y. sae: An R Package for Small Area Estimation. R J. 2015, 7, 81–98. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Base Distribution | True Value | Bias | MSE | Confidence Interval |
|---|---|---|---|---|---|
| 0.5 | −0.06534407 | 0.03458486 | (0.427019, 0.442293) | ||
| 10 | −0.9001747 | 22.34711 | (8.874574, 9.325077) | ||
| 1 | 0.01457439 | 0.005534238 | (1.011374, 1.017774) | ||
| 2 | 0.03045286 | 0.01246042 | (2.025742, 2.035163) | ||
| 0.3 | 0.08081297 | 0.02533613 | (0.361643, 0.399983) | ||
| 5 | 0.4856122 | 7.561553 | (5.105321, 5.865904) | ||
| 1 | 0.01848704 | 0.002993466 | (1.011289, 1.025685) | ||
| 2 | 0.04352289 | 0.004664257 | (2.036166, 2.050880) | ||
| 0.9 | −0.07212803 | 0.01389355 | (0.814840, 0.840904) | ||
| 3 | −0.8307739 | 3.068224 | (1.915222, 2.423231) | ||
| 1 | 0.08176262 | 0.01210896 | (1.071468, 1.092058) | ||
| 2 | −0.08813282 | 0.01125358 | (1.903614, 1.920121) | ||
| 0.4 | 0.05213893 | 0.02911436 | (0.429428, 0.474850) | ||
| 7 | −0.5294164 | 15.58317 | (5.916658, 7.024509) | ||
| 1 | 0.06114231 | 0.006702937 | (1.053531, 1.068753) | ||
| 2 | 0.02870615 | 0.004429664 | (2.020312, 2.037100) | ||
| 0.5 | 0.09099937 | 0.01867303 | (0.576749, 0.605250) | ||
| 2 | −0.3801979 | 2.727176 | (1.395155, 1.844450) | ||
| 1 | −0.1348095 | 0.02203277 | (0.856507, 0.873875) | ||
| 2 | 0.3587933 | 0.1333754 | (2.349268, 2.368318) |
| Regression Coefficient | True Value | NER Model | NER Model with PDP Random Effects |
|---|---|---|---|
| 0.9607364 | 1.014574 | ||
| 1.017708 | 1.018487 | ||
| 1 | 1.001620 | 1.081763 | |
| 1.069568 | 1.061142 | ||
| 0.7113994 | 0.8651905 | ||
| 2.045244 | 2.030453 | ||
| 2.038286 | 2.043523 | ||
| 2 | 1.900959 | 1.911867 | |
| 2.044987 | 2.028706 | ||
| 2.4582498 | 2.358793 |
| Area | Sample Mean | Estimate |
|---|---|---|
| 1 | 2.089628 | 2.220492 |
| 2 | 1.793437 | 1.916604 |
| 3 | 1.692420 | 1.731447 |
| 4 | 2.428903 | 2.606485 |
| 5 | 1.550903 | 2.462545 |
| 6 | 2.068002 | 2.527393 |
| 7 | 2.412526 | 2.482989 |
| 8 | 1.717398 | 1.926363 |
| 9 | 2.042811 | 2.390698 |
| 10 | 2.094958 | 2.358032 |
| 11 | 2.218328 | 2.641435 |
| 12 | 1.865992 | 2.597315 |
| 13 | 1.725139 | 2.231473 |
| 14 | 2.020898 | 2.302906 |
| 15 | 1.630873 | 2.099237 |
| 16 | 2.129673 | 2.268741 |
| 17 | 1.834107 | 1.922384 |
| 18 | 2.570386 | 2.952974 |
| 19 | 2.006835 | 2.219573 |
| 20 | 1.733093 | 2.066331 |
| 0.6003261 | 5.124903 | 1.003003 | 2.411909 |
| Area | Sample Mean | Estimate |
|---|---|---|
| 1 | 2.6218905 | 2.342866 |
| 2 | 2.0078687 | 1.469475 |
| 3 | 0.9612582 | 1.162803 |
| 4 | 1.5513356 | 1.384326 |
| 5 | 2.2699821 | 1.809038 |
| 6 | 2.0796827 | 1.951780 |
| 7 | 3.0264584 | 2.486590 |
| 8 | 3.1521868 | 2.758094 |
| 9 | 1.2477416 | 1.554100 |
| 10 | 1.2796926 | 1.416766 |
| 11 | 2.5728659 | 2.642539 |
| 12 | 1.8507724 | 1.963746 |
| 13 | 2.8604333 | 2.081979 |
| 14 | 3.1778784 | 2.290092 |
| 15 | 1.7505182 | 1.817446 |
| 16 | 1.8190648 | 1.810704 |
| 17 | 1.0271540 | 1.127514 |
| 18 | 2.6706406 | 2.292215 |
| 19 | 2.5922461 | 2.019817 |
| 20 | 2.7200485 | 2.626496 |
| 0.875775 | 3.025505 | −0.007919 | −0.000048 | −0.000173 | −0.000169 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, X.; Ke, Q.; Zhou, X.; Liu, Y. Small Area Estimation under Poisson–Dirichlet Process Mixture Models. Axioms 2024, 13, 432. https://doi.org/10.3390/axioms13070432
Qiu X, Ke Q, Zhou X, Liu Y. Small Area Estimation under Poisson–Dirichlet Process Mixture Models. Axioms. 2024; 13(7):432. https://doi.org/10.3390/axioms13070432
Chicago/Turabian StyleQiu, Xiang, Qinchun Ke, Xueqin Zhou, and Yulu Liu. 2024. "Small Area Estimation under Poisson–Dirichlet Process Mixture Models" Axioms 13, no. 7: 432. https://doi.org/10.3390/axioms13070432
APA StyleQiu, X., Ke, Q., Zhou, X., & Liu, Y. (2024). Small Area Estimation under Poisson–Dirichlet Process Mixture Models. Axioms, 13(7), 432. https://doi.org/10.3390/axioms13070432