
Moduli of Continuity in Metric Models and Extension of Livability Indices



Abstract
1. Introduction
2. Basic Definitions and Concepts
Composition Metrics and Modulus of Continuity
- (i).
- and
- (ii).
- when
- (iii).
- ϕ is a continuous function.
- (a)
- For any , the condition holds if and only if because is only null at 0. Since d is a metric, this holds if and only if , demonstrating that satisfies the identity of indiscernibles.
- (b)
- Given that for all , it is evident that , indicating the symmetry of .
- (c)
- Let with corresponding distances , and . If are distinct, then since d is a metric, leading to .
- A mapping is termed α-Hölder continuous if there exist constants and satisfying for allThese mappings qualify as ϕ-Lipschitz maps for . Specifically, if , then defining places ϕ within Φ, and f is ϕ-Lipschitz with . If , it can be demonstrated that f becomes a constant map, rendering it ϕ-Lipschitz for any .
- Consider equipped with its standard metric, and let . Subadditivity implies for ; hence, . Thus, every qualifies as a ϕ-Lipschitz function with . Examples of ϕ functions, in addition to those already mentioned, include , or .
3. Index Extension
3.1. Standard Indices and Approximation
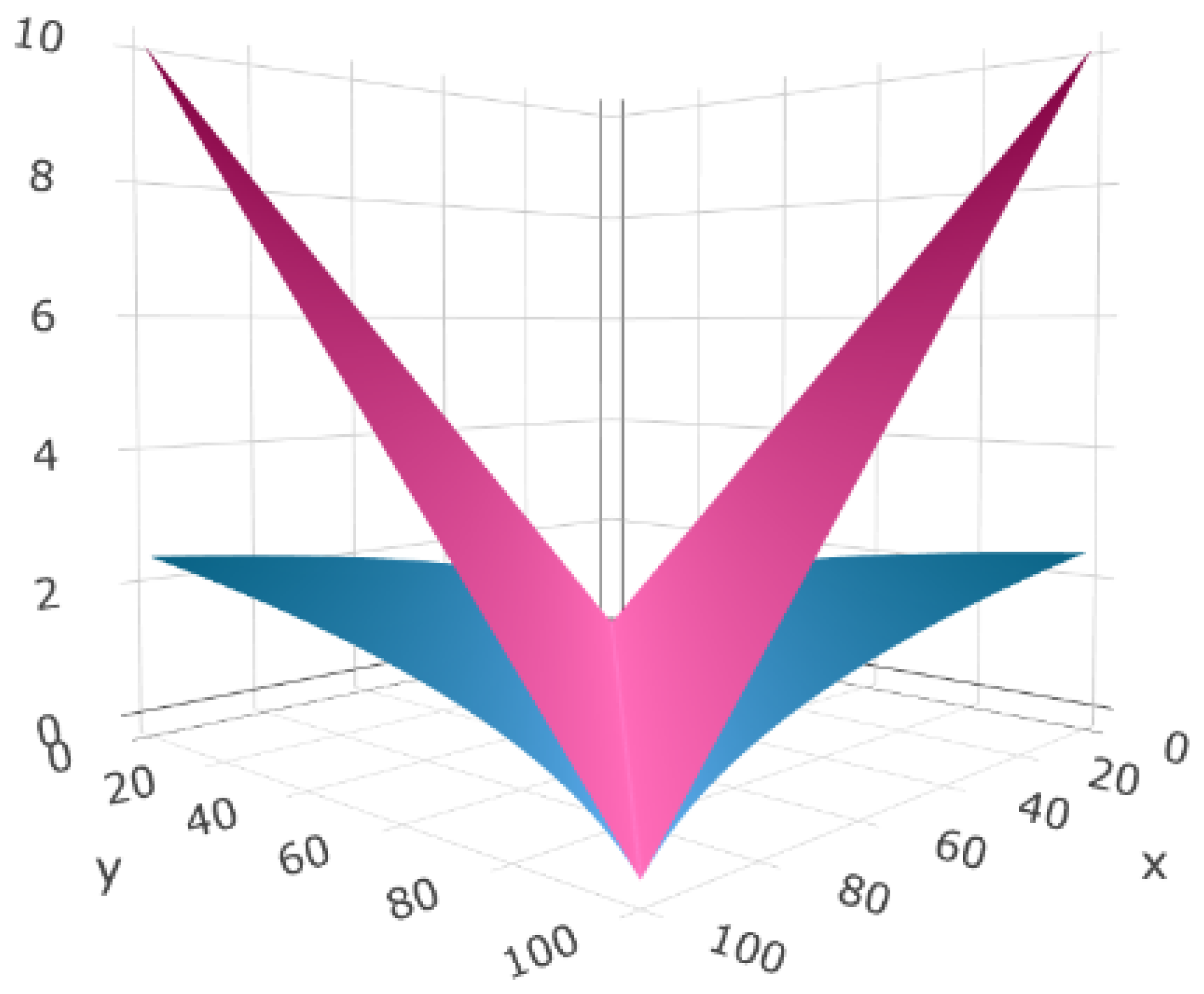
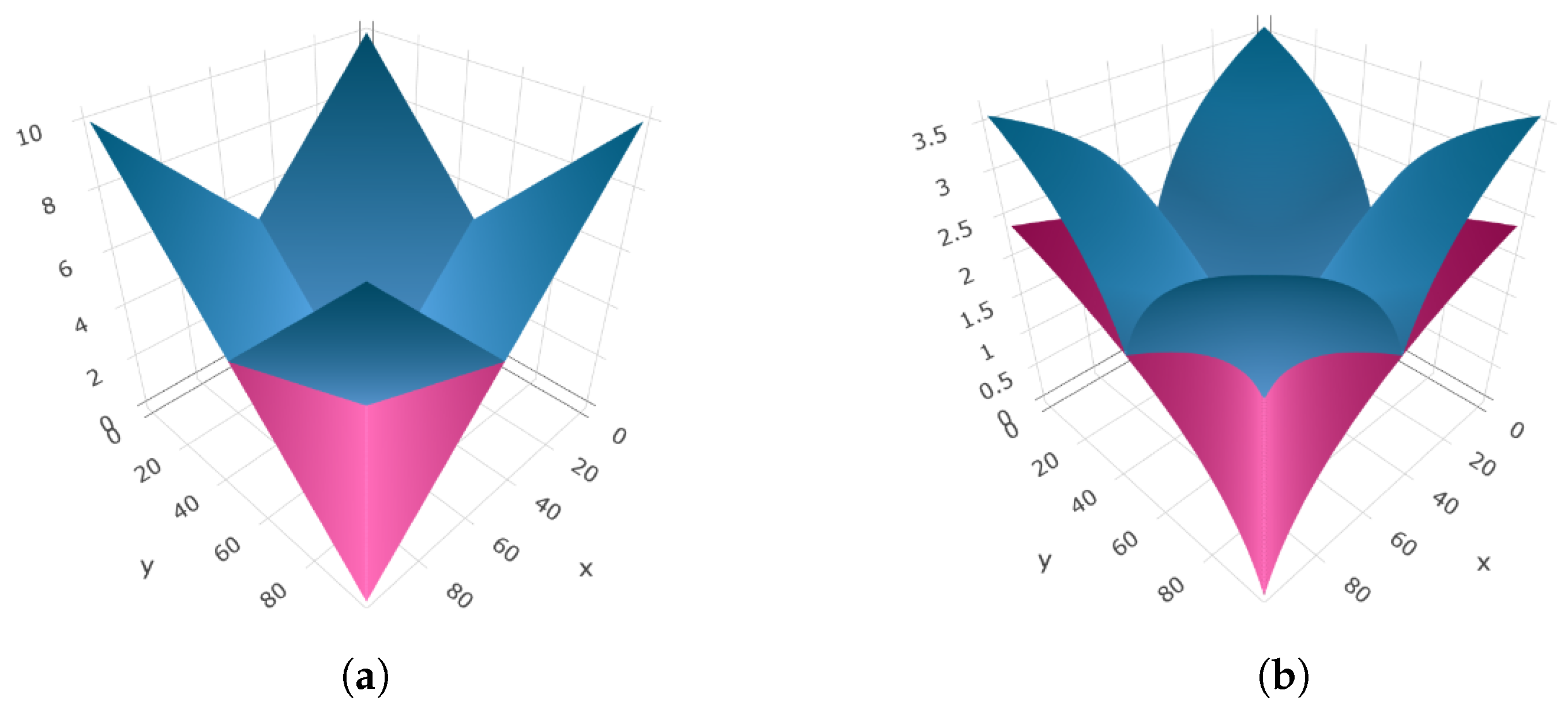
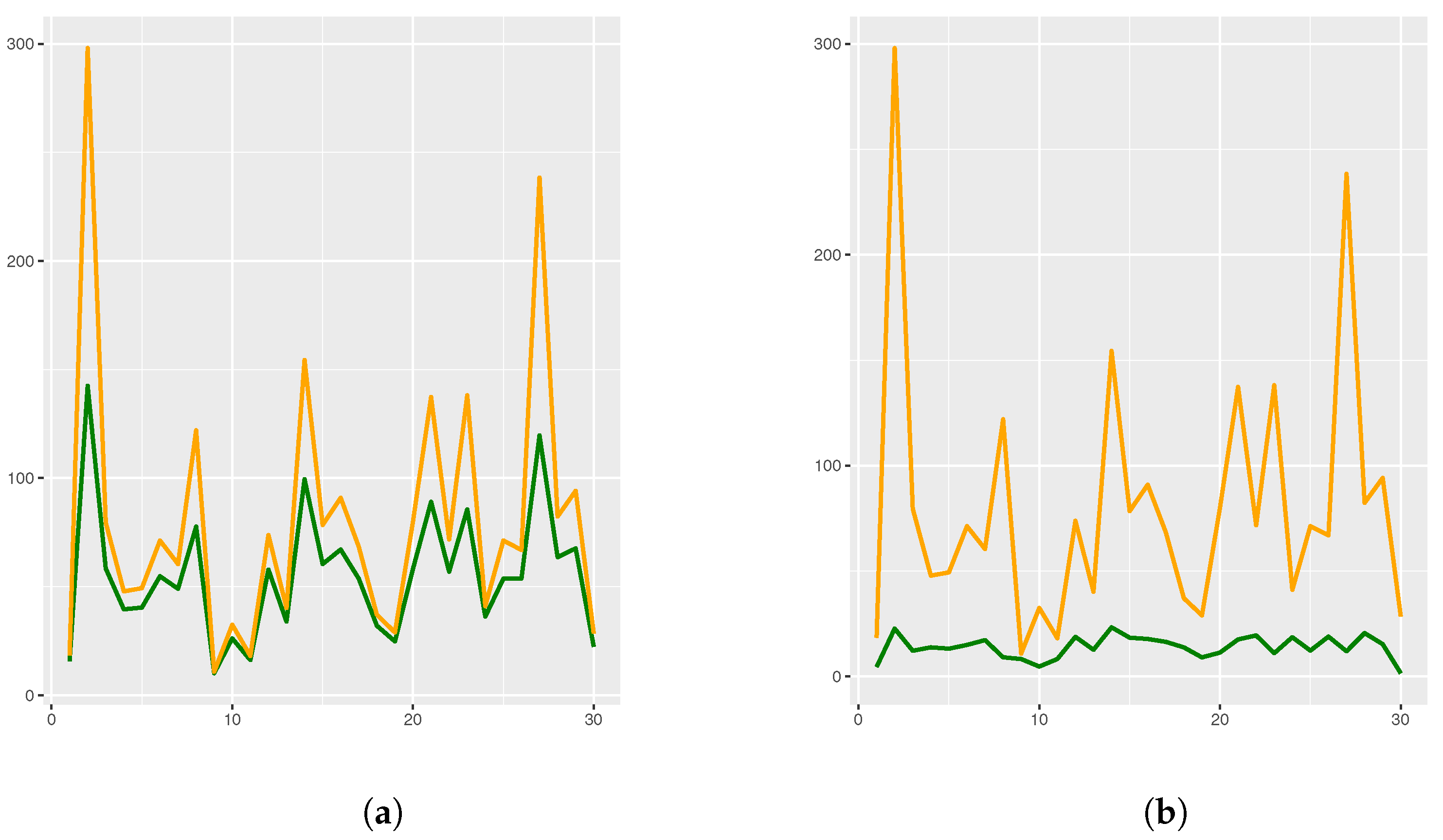
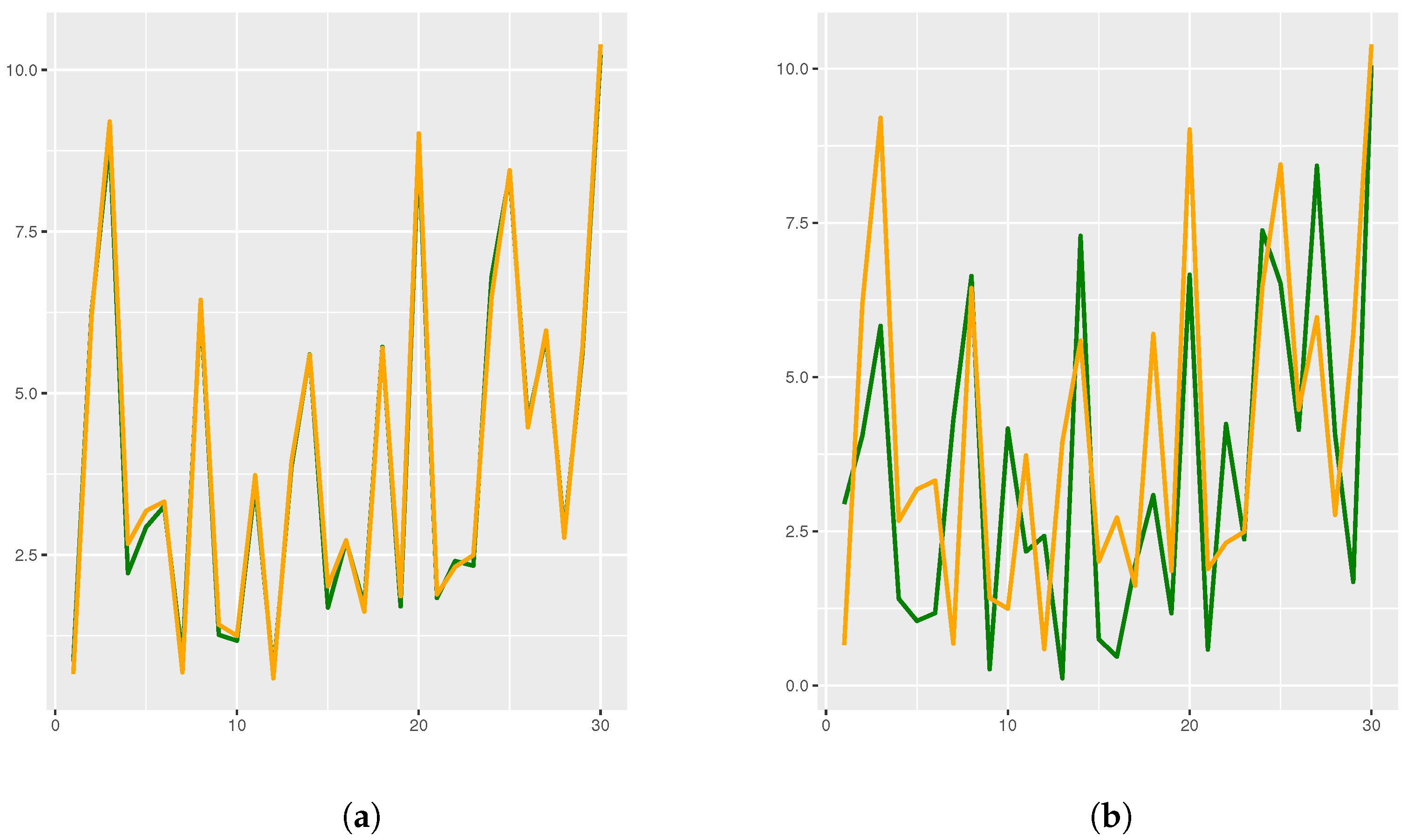
3.2. McShane and Whitney Formulas as Approximation Tools
4. Applications: The Livability Index for Cities
4.1. Methodology
4.2. Extension of a Livability Index
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Erdoğan, E.; Ferrer-Sapena, A.; Jiménez-Fernández, E.; Sánchez-Pérez, E.A. Index spaces and standard indices in metric modelling. Nonlinear Anal. Model. Control 2022, 27, 803–822. [Google Scholar] [CrossRef]
- Calabuig, J.; Falciani, H.; Sánchez-Pérez, E. Dreaming machine learning: Lipschitz extensions for reinforcement learning on financial markets. Neurocomputing 2020, 398, 172–184. [Google Scholar] [CrossRef]
- Mémoli, F.; Sapiro, G.; Thompson, P.M. Geometric surface and brain warping via geodesic minimizing Lipschitz extensions. In Proceedings of the 1st MICCAI Workshop on Mathematical Foundations of Computational Anatomy: Geometrical, Statistical and Registration Methods for Modeling Biological Shape Variability, Munich, Germany, 9 October 2006; pp. 58–67. [Google Scholar]
- Dacorogna, B.; Gangbo, W. Extension theorems for vector valued maps. J. Math. Pures Appl. 2006, 85, 313–344. [Google Scholar] [CrossRef][Green Version]
- Doboš, J.B. Functions whose composition with every metric is a metric. Math. Slovaca 1981, 31, 3–12. [Google Scholar]
- Wilson, W. On certain types of continuous transformations of metric spaces. Am. J. Math. 1935, 57, 62–68. [Google Scholar] [CrossRef]
- Valentine, F.A. On the extension of a vector function so as to preserve a Lipschitz condition. Bull. Am. Math. Soc. 1943, 49, 100–108. [Google Scholar] [CrossRef][Green Version]
- Deza, E.; Deza, M.M. Encyclopedia of Distances; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Cobzaş, Ş.; Miculescu, R.; Nicolae, A. Lipschitz Functions; Springer International Publishing: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- McShane, E.J. Extension of range of functions. Bull. Am. Math. Soc. 1934, 40, 837–842. [Google Scholar] [CrossRef]
- Whitney, H. Analytic extensions of differentiable functions defined in closed sets. In Hassler Whitney Collected Papers; Springer: Berlin/Heidelberg, Germany, 1992; pp. 228–254. [Google Scholar]
- Efimov, A. Modulus of Continuity, Encyclopaedia of Mathematics. 2001. Available online: https://encyclopediaofmath.org/wiki/Continuity (accessed on 22 October 2023).
- Juutinen, P. Absolutely minimizing Lipschitz extensions on a metric space. Ann. Acad. Sci. Fenn. Math. 2002, 27, 57–67. [Google Scholar]
- Ritchie, H.; Roser, M. Urbanization. Our World Data 2018. Available online: https://ourworldindata.org/urbanization? (accessed on 4 October 2023).
- Paul, A.; Sen, J. A critical review of liveability approaches and their dimensions. Geoforum 2020, 117, 90–92. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| City | Walk Score | Transit Score | Bike Score | I |
|---|---|---|---|---|
| New York | 88 | 88.6 | 69.3 | 63 |
| Los Angeles | 68.6 | 52.9 | 58.7 | 49 |
| Chicago | 77.2 | 65 | 72.2 | 57 |
| Toronto | 61 | 78.2 | 61 | ? |
| Houston | 47.5 | 36.2 | 48.6 | 48 |
| Montreal | 65.4 | 67 | 72.6 | ? |
| Function | Standard | McShane–Whitney | ||
|---|---|---|---|---|
| Lipschitz | -Lipschitz | Lipschitz | -Lipschitz | |
| Mean RMSE | 138.43 | 79.48 | 5.08 | 5.04 |
| Median RMSE | 140.49 | 81.25 | 5.12 | 5.05 |
| Standard deviation | 24.11 | 8.78 | 0.61 | 0.60 |
| Seconds per iteration | 1.039 × 10−3 | 3.316 × 10−1 | 1.513 × 10−3 | 3.330 × 10−1 |
| Function | Standard | McShane–Whitney | ||
|---|---|---|---|---|
| Lipschitz | -Lipschitz | Lipschitz | -Lipschitz | |
| Mean RMSE | 138.43 | 16.69 | 5.08 | 4.55 |
| Median RMSE | 140.49 | 16.50 | 5.12 | 4.47 |
| Standard deviation | 24.11 | 1.52 | 0.61 | 0.63 |
| Seconds per iteration | 1.039 × 10−3 | 3.000 × 10−1 | 1.513 × 10−3 | 3.013 × 10−1 |
| Standard | McShane–Whitney | Neural Net | Linear | |
|---|---|---|---|---|
| Mean RMSE | 16.69 | 4.55 | 4.40 | 13.80 |
| Median RMSE | 16.50 | 4.47 | 4.42 | 13.65 |
| Standard deviation | 1.52 | 0.63 | 0.46 | 3.25 |
| Seconds per iteration | 3.000 × 10−1 | 3.013 × 10−1 | 1.923 × 10−1 | 4.341 × 10−3 |
| Ranking | Standard | McShane–Whitney | Neural Net | Linear |
|---|---|---|---|---|
| 1 | Vancouver | Montreal | Vancouver | Vancouver |
| 2 | Toronto | Vancouver | Toronto | Toronto |
| 3 | Montreal | Longueuil | Montreal | Montreal |
| 4 | Burnaby | Toronto | Burnaby | Burnaby |
| 5 | Longueuil | Saskatoon | Longueuil | Longueuil |
| 6 | Mississauga | Winnipeg | Ottawa | Ottawa |
| 7 | Winnipeg | Burnaby | Winnipeg | Winnipeg |
| 8 | Ottawa | Mississauga | Mississauga | Surrey |
| 9 | Brampton | Ottawa | Brampton | Laval |
| 10 | Quebec | Brampton | Quebec | Mississauga |
| 11 | Surrey | Surrey | Laval | Kitchener |
| 12 | Laval | Quebec | Surrey | Brampton |
| 13 | Kitchener | Edmonton | Kitchener | Hamilton |
| 14 | Calgary | Kitchener | Calgary | Saskatoon |
| 15 | Saskatoon | Windsor | Gatineau | Calgary |
| 16 | Markham | Laval | Markham | Quebec |
| 17 | Hamilton | Hamilton | London | Windsor |
| 18 | Edmonton | Calgary | Hamilton | Edmonton |
| 19 | London | London | Edmonton | Vaughan |
| 20 | Gatineau | Gatineau | Windsor | Markham |
| 21 | Vaughan | Markham | Vaughan | London |
| 22 | Windsor | Vaughan | Saskatoon | Gatineau |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arnau, R.; Calabuig, J.M.; González, Á.; Sánchez Pérez, E.A. Moduli of Continuity in Metric Models and Extension of Livability Indices. Axioms 2024, 13, 192. https://doi.org/10.3390/axioms13030192
Arnau R, Calabuig JM, González Á, Sánchez Pérez EA. Moduli of Continuity in Metric Models and Extension of Livability Indices. Axioms. 2024; 13(3):192. https://doi.org/10.3390/axioms13030192
Chicago/Turabian StyleArnau, Roger, Jose M. Calabuig, Álvaro González, and Enrique A. Sánchez Pérez. 2024. "Moduli of Continuity in Metric Models and Extension of Livability Indices" Axioms 13, no. 3: 192. https://doi.org/10.3390/axioms13030192
APA StyleArnau, R., Calabuig, J. M., González, Á., & Sánchez Pérez, E. A. (2024). Moduli of Continuity in Metric Models and Extension of Livability Indices. Axioms, 13(3), 192. https://doi.org/10.3390/axioms13030192