
ℤ2 × ℤ2 Equivariant Quantum Neural Networks: Benchmarking against Classical Neural Networks
 , , , , , , , , , and
, , , , , , , , , and
Abstract
1. Introduction
2. Dataset Description
- (i)
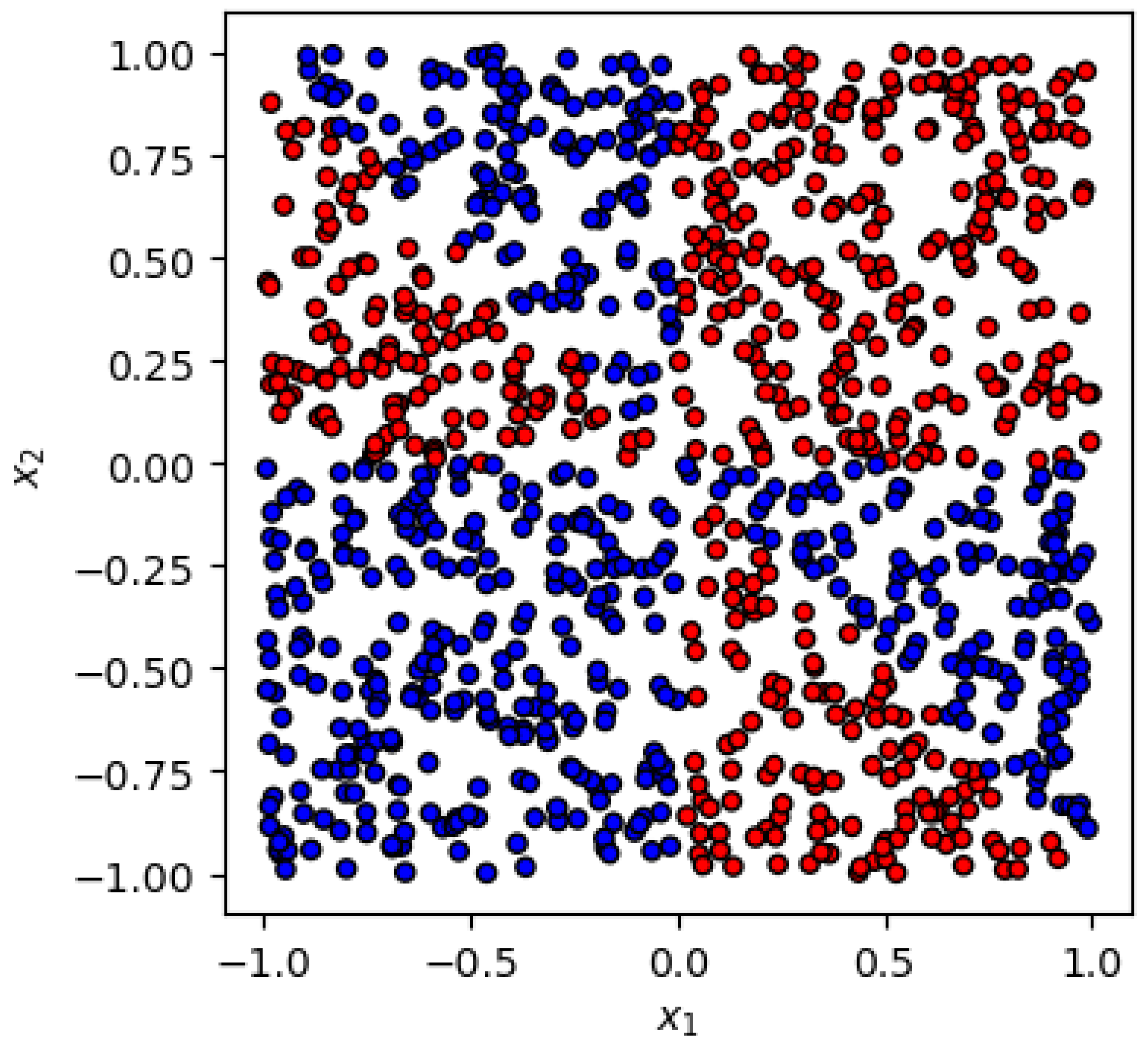
- Symmetric case:In the first example (Figure 1), the labels are generated by the functionwhere is the Heaviside step function and for definiteness we choose . The function (1) respects a symmetry, where the first is given by a reflection about the diagonalwhile the second corresponds to a reflection about the diagonalThis example was studied in Ref. [37] and we shall refer to it as the symmetric case since the y label is invariant.
- (ii)
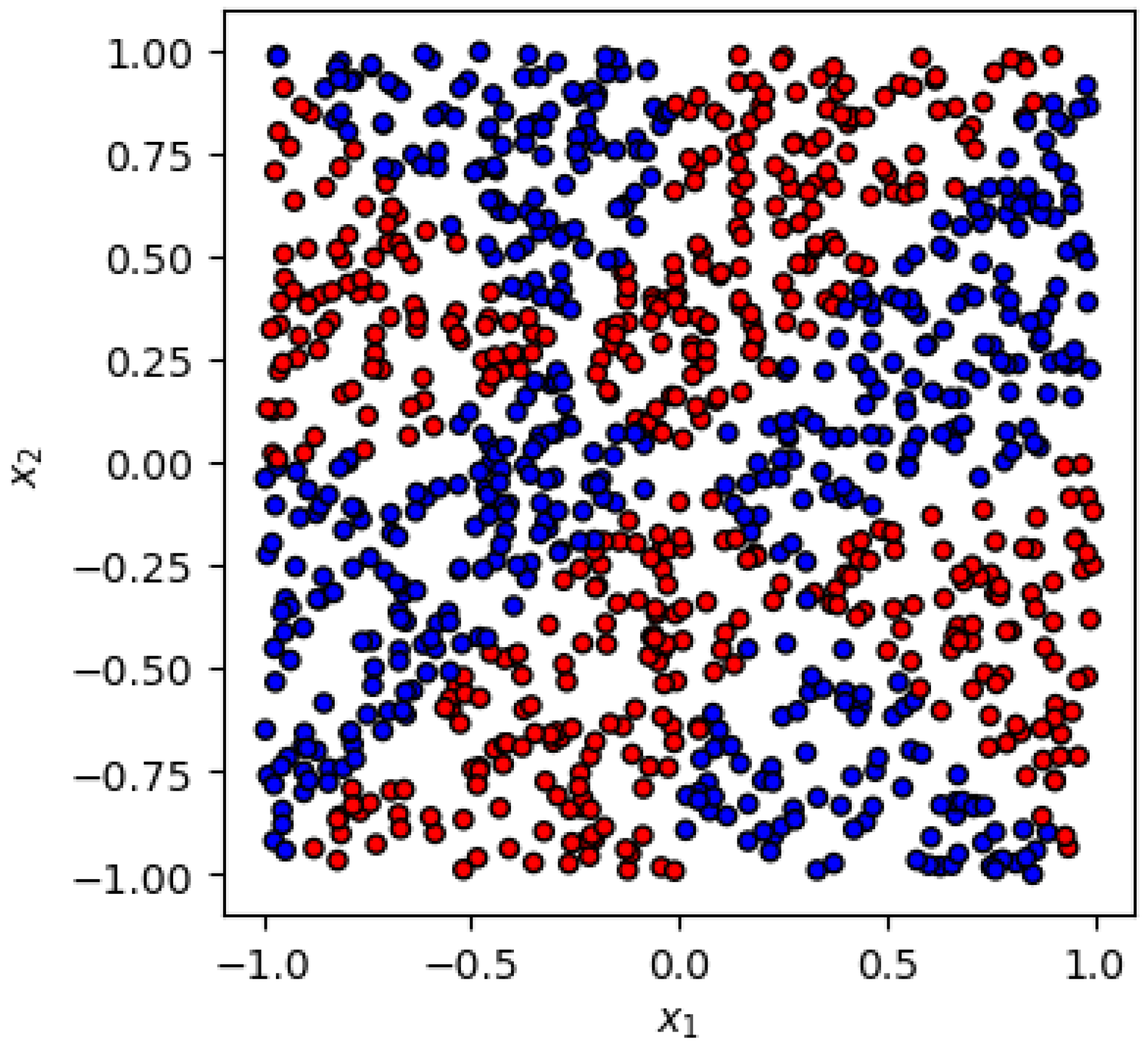
- Anti-symmetric case:The second example is illustrated in Figure 2. The labels are generated by the functionThe first is still realized as in (2). However, this time, the labels are flipped under a reflection along the diagonal:which is why we shall refer to this case as anti-symmetric.
- (iii)
- Fully anti-symmetric case:The last example is depicted in Figure 3. The labels are generated by the functionwhere is the Heaviside step function and for definiteness we choose . In this case, the labels are flipped under both reflections along the diagonal as well as the diagonal, which is why we shall refer to this case as fully anti-symmetric. As we will see later, it is straightforward to incorporate both symmetric and anti-symmetric properties in variational quantum circuits, while it is not obvious how to consider the anti-symmetric case in the classical neural networks.
3. Network Architectures
- (i)
- Deep Neural Networks:In our DNN, for the symmetric (anti-symmetric) case, we use one (two) hidden layer(s) with four neurons. For both types of classical networks, we use the softmax activation function, Adam optimizer, and a learning rate of . We use the binary cross-entropy for both the DNN and ENN.
- (ii)
- Equivariant Neural Networks:A given map between an input space X and an output space Y is said to be equivariant under a group G if it satisfies the following relation:where () is a representation of a group element acting on the input (output) space. In the special case when is the trivial representation, the map is called invariant under the group G, i.e., a symmetry transformation acting on the input data x does not change the output of the map. The goal of ENNs, or equivariant learning models in general, is to design a trainable map f which would always satisfy Equation (7). In tasks where the symmetry is known, such equivariant models are believed to have an advantage in terms of the number of parameters and training complexity. Several studies in high-energy physics have attempted to use classical equivariant neural networks [6,47,48,49,50]. Our ENN model utilizes four symmetric copies for each data point, which are fed into the input layer, followed by one equivariant layer with three (two) neurons and one dense layer with four (four) neurons in the symmetric (anti-symmetric) case.
- (iii)
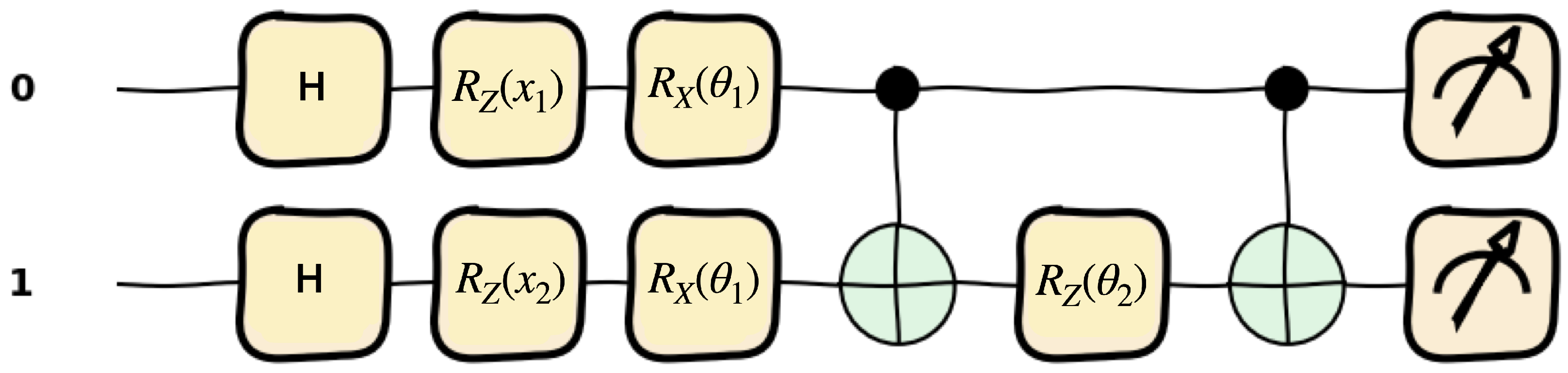
- Quantum Neural Networks:For the QNN, we utilize the one-qubit data-reuploading model [51], as shown in Figure 4, with depth four (eight) for the symmetric (anti-symmetric and fully anti-symmetric) case, using the angle embedding and three parameters at each depth. This choice leads to a similar number of parameters as in the classical networks. We use the Adam optimizer and the lossfor any choice of two orthogonal operators and (see Ref. [52] for more details.). In this paper, we usefor all three datasets considered in this paper.
- (iv)
- Equivariant Quantum Neural Networks.In EQNN models, symmetry transformations acting on the embedding space of input features are realized as finite-dimensional unitary transformations , . Consider the simplest case where one trainable operator acts on a state : . If for a symmetry transformation , the conditionis satisfied, then the operator U is equivariant, i.e., the equivariant gate should commute with the symmetry. In general, the operators on the two sides of Equation (10) do not necessarily have to be in the same representation but are often assumed so for simplicity. The output of a QNN is the measurement of the expectation value of the state with respect to some observable O. If the gates are equivariant and we apply some symmetry transformation , then this is equivalent to measuring the observable . Hence, if O commutes with the symmetry , the model as a whole would be invariant under , which is the case in our symmetric example. Otherwise the model is equivariant, as in our anti-symmetric example.
4. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| API | Application Processing Interface |
| AUC | Area Under the Curve |
| DNN | Deep Neural Network |
| ENN | Equivariant Neural Network |
| EQNN | Equivariant Quantum Neural Network |
| HEP | High-Energy Physics |
| LHC | Large Hadron Collider |
| MDPI | Multidisciplinary Digital Publishing Institute |
| ML | Machine Learning |
| NN | Neural Network |
| QML | Quantum Machine Learning |
| QNN | Quantum Neural Network |
| ROC | Receiver Operating Characteristic |
References
- Shanahan, P.; Terao, K.; Whiteson, D. Snowmass 2021 Computational Frontier CompF03 Topical Group Report: Machine Learning. arXiv 2022, arXiv:2209.07559. [Google Scholar]
- Feickert, M.; Nachman, B. A Living Review of Machine Learning for Particle Physics. arXiv 2021, arXiv:2102.02770. [Google Scholar]
- Cohen, T.; Welling, M. Group Equivariant Convolutional Networks. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; Balcan, M.F., Weinberger, K.Q., Eds.; Volume 48, pp. 2990–2999. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Pereira, F., Burges, C., Bottou, L., Weinberger, K., Eds.; Curran Associates, Inc.: Sydney, Australia, 2012; Volume 25. [Google Scholar]
- Jumper, J.M.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Zídek, A.; Potapenko, A.; et al. Highly accurate protein structure prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef]
- Bogatskiy, A.; Anderson, B.; Offermann, J.; Roussi, M.; Miller, D.; Kondor, R. Lorentz Group Equivariant Neural Network for Particle Physics. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; Volume 119, pp. 992–1002. [Google Scholar]
- Cohen, T.S.; Weiler, M.; Kicanaoglu, B.; Welling, M. Gauge Equivariant Convolutional Networks and the Icosahedral CNN. arXiv 2019, arXiv:1902.046152. [Google Scholar]
- Boyda, D.; Kanwar, G.; Racanière, S.; Rezende, D.J.; Albergo, M.S.; Cranmer, K.; Hackett, D.C.; Shanahan, P.E. Sampling using SU(N) gauge equivariant flows. Phys. Rev. D 2021, 103, 074504. [Google Scholar] [CrossRef]
- Favoni, M.; Ipp, A.; Müller, D.I.; Schuh, D. Lattice Gauge Equivariant Convolutional Neural Networks. Phys. Rev. Lett. 2022, 128, 032003. [Google Scholar] [CrossRef]
- Dolan, M.J.; Ore, A. Equivariant Energy Flow Networks for Jet Tagging. Phys. Rev. D 2021, 103, 074022. [Google Scholar] [CrossRef]
- Bulusu, S.; Favoni, M.; Ipp, A.; Müller, D.I.; Schuh, D. Generalization capabilities of translationally equivariant neural networks. Phys. Rev. D 2021, 104, 074504. [Google Scholar] [CrossRef]
- Preskill, J. Quantum Computing in the NISQ era and beyond. Quantum 2018, 2, 79. [Google Scholar] [CrossRef]
- Feynman, R.P. Simulating physics with computers. Int. J. Theor. Phys. 1982, 21, 467–488. [Google Scholar] [CrossRef]
- Georgescu, I.M.; Ashhab, S.; Nori, F. Quantum Simulation. Rev. Mod. Phys. 2014, 86, 153. [Google Scholar] [CrossRef]
- Ramírez-Uribe, S.; Rentería-Olivo, A.E.; Rodrigo, G.; Sborlini, G.F.R.; Vale Silva, L. Quantum algorithm for Feynman loop integrals. JHEP 2022, 5, 100. [Google Scholar] [CrossRef]
- Bepari, K.; Malik, S.; Spannowsky, M.; Williams, S. Quantum walk approach to simulating parton showers. Phys. Rev. D 2022, 106, 056002. [Google Scholar] [CrossRef]
- Li, T.; Guo, X.; Lai, W.K.; Liu, X.; Wang, E.; Xing, H.; Zhang, D.B.; Zhu, S.L. Partonic collinear structure by quantum computing. Phys. Rev. D 2022, 105, L111502. [Google Scholar] [CrossRef]
- Bepari, K.; Malik, S.; Spannowsky, M.; Williams, S. Towards a quantum computing algorithm for helicity amplitudes and parton showers. Phys. Rev. D 2021, 103, 076020. [Google Scholar] [CrossRef]
- Jordan, S.P.; Lee, K.S.M.; Preskill, J. Quantum Algorithms for Fermionic Quantum Field Theories. arXiv 2014, arXiv:1404.7115. [Google Scholar]
- Preskill, J. Simulating quantum field theory with a quantum computer. PoS 2018, LATTICE2018, 024. [Google Scholar] [CrossRef]
- Bauer, C.W.; de Jong, W.A.; Nachman, B.; Provasoli, D. Quantum Algorithm for High Energy Physics Simulations. Phys. Rev. Lett. 2021, 126, 062001. [Google Scholar] [CrossRef]
- Abel, S.; Chancellor, N.; Spannowsky, M. Quantum computing for quantum tunneling. Phys. Rev. D 2021, 103, 016008. [Google Scholar] [CrossRef]
- Abel, S.; Spannowsky, M. Quantum-Field-Theoretic Simulation Platform for Observing the Fate of the False Vacuum. PRX Quantum 2021, 2, 010349. [Google Scholar] [CrossRef]
- Davoudi, Z.; Linke, N.M.; Pagano, G. Toward simulating quantum field theories with controlled phonon-ion dynamics: A hybrid analog-digital approach. Phys. Rev. Res. 2021, 3, 043072. [Google Scholar] [CrossRef]
- Mott, A.; Job, J.; Vlimant, J.R.; Lidar, D.; Spiropulu, M. Solving a Higgs optimization problem with quantum annealing for machine learning. Nature 2017, 550, 375–379. [Google Scholar] [CrossRef]
- Blance, A.; Spannowsky, M. Unsupervised event classification with graphs on classical and photonic quantum computers. JHEP 2020, 21, 170. [Google Scholar] [CrossRef]
- Wu, S.L.; Chan, J.; Guan, W.; Sun, S.; Wang, A.; Zhou, C.; Livny, M.; Carminati, F.; Di Meglio, A.; Li, A.C.; et al. Application of quantum machine learning using the quantum variational classifier method to high energy physics analysis at the LHC on IBM quantum computer simulator and hardware with 10 qubits. J. Phys. G 2021, 48, 125003. [Google Scholar] [CrossRef]
- Blance, A.; Spannowsky, M. Quantum Machine Learning for Particle Physics using a Variational Quantum Classifier. JHEP 2021, 2, 212. [Google Scholar] [CrossRef]
- Abel, S.; Blance, A.; Spannowsky, M. Quantum optimization of complex systems with a quantum annealer. Phys. Rev. A 2022, 106, 042607. [Google Scholar] [CrossRef]
- Wu, S.L.; Sun, S.; Guan, W.; Zhou, C.; Chan, J.; Cheng, C.L.; Pham, T.; Qian, Y.; Wang, A.Z.; Zhang, R.; et al. Application of quantum machine learning using the quantum kernel algorithm on high energy physics analysis at the LHC. Phys. Rev. Res. 2021, 3, 033221. [Google Scholar] [CrossRef]
- Chen, S.Y.C.; Wei, T.C.; Zhang, C.; Yu, H.; Yoo, S. Hybrid Quantum-Classical Graph Convolutional Network. arXiv 2021, arXiv:2101.06189. [Google Scholar]
- Terashi, K.; Kaneda, M.; Kishimoto, T.; Saito, M.; Sawada, R.; Tanaka, J. Event Classification with Quantum Machine Learning in High-Energy Physics. Comput. Softw. Big Sci. 2021, 5, 2. [Google Scholar] [CrossRef]
- Araz, J.Y.; Spannowsky, M. Classical versus quantum: Comparing tensor-network-based quantum circuits on Large Hadron Collider data. Phys. Rev. A 2022, 106, 062423. [Google Scholar] [CrossRef]
- Ngairangbam, V.S.; Spannowsky, M.; Takeuchi, M. Anomaly detection in high-energy physics using a quantum autoencoder. Phys. Rev. D 2022, 105, 095004. [Google Scholar] [CrossRef]
- Chang, S.Y.; Grossi, M.; Saux, B.L.; Vallecorsa, S. Approximately Equivariant Quantum Neural Network for p4m Group Symmetries in Images. In Proceedings of the 2023 International Conference on Quantum Computing and Engineering, Bellevue, WA, USA, 17–22 September 2023. [Google Scholar]
- Nguyen, Q.T.; Schatzki, L.; Braccia, P.; Ragone, M.; Coles, P.J.; Sauvage, F.; Larocca, M.; Cerezo, M. Theory for Equivariant Quantum Neural Networks. arXiv 2022, arXiv:2210.08566. [Google Scholar]
- Meyer, J.J.; Mularski, M.; Gil-Fuster, E.; Mele, A.A.; Arzani, F.; Wilms, A.; Eisert, J. Exploiting Symmetry in Variational Quantum Machine Learning. PRX Quantum 2023, 4, 010328. [Google Scholar] [CrossRef]
- West, M.T.; Sevior, M.; Usman, M. Reflection equivariant quantum neural networks for enhanced image classification. Mach. Learn. Sci. Technol. 2023, 4, 035027. [Google Scholar] [CrossRef]
- Skolik, A.; Cattelan, M.; Yarkoni, S.; Bäck, T.; Dunjko, V. Equivariant quantum circuits for learning on weighted graphs. npj Quantum Inf. 2023, 9, 47. [Google Scholar] [CrossRef]
- Kim, I.W. Algebraic Singularity Method for Mass Measurement with Missing Energy. Phys. Rev. Lett. 2010, 104, 081601. [Google Scholar] [CrossRef] [PubMed]
- Franceschini, R.; Kim, D.; Kong, K.; Matchev, K.T.; Park, M.; Shyamsundar, P. Kinematic Variables and Feature Engineering for Particle Phenomenology. Rev. Mod. Phys. 2022, 95, 045004. [Google Scholar] [CrossRef]
- Kersting, N. On Measuring Split-SUSY Gaugino Masses at the LHC. Eur. Phys. J. C 2009, 63, 23–32. [Google Scholar] [CrossRef]
- Bisset, M.; Lu, R.; Kersting, N. Improving SUSY Spectrum Determinations at the LHC with Wedgebox Technique. JHEP 2011, 5, 095. [Google Scholar] [CrossRef]
- Burns, M.; Matchev, K.T.; Park, M. Using kinematic boundary lines for particle mass measurements and disambiguation in SUSY-like events with missing energy. JHEP 2009, 5, 094. [Google Scholar] [CrossRef]
- Debnath, D.; Gainer, J.S.; Kim, D.; Matchev, K.T. Edge Detecting New Physics the Voronoi Way. EPL 2016, 114, 41001. [Google Scholar] [CrossRef][Green Version]
- Debnath, D.; Gainer, J.S.; Kilic, C.; Kim, D.; Matchev, K.T.; Yang, Y.P. Detecting kinematic boundary surfaces in phase space: Particle mass measurements in SUSY-like events. JHEP 2017, 6, 092. [Google Scholar] [CrossRef]
- Bogatskiy, A.; Hoffman, T.; Miller, D.W.; Offermann, J.T. PELICAN: Permutation Equivariant and Lorentz Invariant or Covariant Aggregator Network for Particle Physics. arXiv 2022, arXiv:2211.00454. [Google Scholar]
- Hao, Z.; Kansal, R.; Duarte, J.; Chernyavskaya, N. Lorentz group equivariant autoencoders. Eur. Phys. J. C 2023, 83, 485. [Google Scholar] [CrossRef] [PubMed]
- Buhmann, E.; Kasieczka, G.; Thaler, J. EPiC-GAN: Equivariant point cloud generation for particle jets. SciPost Phys. 2023, 15, 130. [Google Scholar] [CrossRef]
- Batatia, I.; Geiger, M.; Munoz, J.; Smidt, T.; Silberman, L.; Ortner, C. A General Framework for Equivariant Neural Networks on Reductive Lie Groups. arXiv 2023, arXiv:2306.00091. [Google Scholar]
- Pérez-Salinas, A.; Cervera-Lierta, A.; Gil-Fuster, E.; Latorre, J.I. Data re-uploading for a universal quantum classifier. Quantum 2020, 4, 226. [Google Scholar] [CrossRef]
- Ahmed, S. Data-Reuploading Classifier. Available online: https://pennylane.ai/qml/demos/tutorial_data_reuploading_classifier (accessed on 7 March 2024).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| \ | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 |
|---|---|---|---|---|---|---|---|---|---|
| 105 | 0.764 | 0.855 | 0.879 | 0.963 | 0.973 | 0.981 | 0.981 | 0.982 | 0.988 |
| 85 | 0.669 | 0.743 | 0.804 | 0.953 | 0.951 | 0.978 | 0.986 | 0.946 | 0.981 |
| 67 | 0.587 | 0.722 | 0.695 | 0.946 | 0.886 | 0.9632 | 0.975 | 0.944 | 0.980 |
| 51 | 0.624 | 0.655 | 0.856 | 0.926 | 0.908 | 0.876 | 0.846 | 0.974 | 0.986 |
| 37 | 0.596 | 0.696 | 0.639 | 0.782 | 0.747 | 0.816 | 0.849 | 0.922 | 0.952 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Z.; Comajoan Cara, M.; Dahale, G.R.; Forestano, R.T.; Gleyzer, S.; Justice, D.; Kong, K.; Magorsch, T.; Matchev, K.T.; Matcheva, K.; et al. ℤ2 × ℤ2 Equivariant Quantum Neural Networks: Benchmarking against Classical Neural Networks. Axioms 2024, 13, 188. https://doi.org/10.3390/axioms13030188
Dong Z, Comajoan Cara M, Dahale GR, Forestano RT, Gleyzer S, Justice D, Kong K, Magorsch T, Matchev KT, Matcheva K, et al. ℤ2 × ℤ2 Equivariant Quantum Neural Networks: Benchmarking against Classical Neural Networks. Axioms. 2024; 13(3):188. https://doi.org/10.3390/axioms13030188
Chicago/Turabian StyleDong, Zhongtian, Marçal Comajoan Cara, Gopal Ramesh Dahale, Roy T. Forestano, Sergei Gleyzer, Daniel Justice, Kyoungchul Kong, Tom Magorsch, Konstantin T. Matchev, Katia Matcheva, and et al. 2024. "ℤ2 × ℤ2 Equivariant Quantum Neural Networks: Benchmarking against Classical Neural Networks" Axioms 13, no. 3: 188. https://doi.org/10.3390/axioms13030188
APA StyleDong, Z., Comajoan Cara, M., Dahale, G. R., Forestano, R. T., Gleyzer, S., Justice, D., Kong, K., Magorsch, T., Matchev, K. T., Matcheva, K., & Unlu, E. B. (2024). ℤ2 × ℤ2 Equivariant Quantum Neural Networks: Benchmarking against Classical Neural Networks. Axioms, 13(3), 188. https://doi.org/10.3390/axioms13030188