1. Introduction
Stochastic gradient descent (SGD) is a widely used optimization method, particularly in deep learning, that updates model parameters using mini-batches of data rather than the entire dataset, as in traditional gradient descent. This approach allows for more frequent updates, leading to faster convergence and helping the optimization process escape local minima due to its inherent noise. Because of its ability to efficiently handle large datasets and leverage parallel or distributed systems, SGD has become a go-to approach for training large-scale neural networks in modern machine learning applications. Its scalability and robustness in handling high-dimensional data make it an indispensable tool for achieving state-of-the-art results in various problem domains, such as image classification, object detection, and automatic machine translation [
1,
2,
3,
4].
The effectiveness of SGD in optimizing deep neural networks heavily depends on the selection of an appropriate step size, or learning rate. The learning rate controls how much the model parameters are adjusted at each iteration, and its value significantly impacts the convergence behavior of SGD. Too large a step size can cause the algorithm to overshoot the optimal point, leading to instability or divergence, while too small a step size can result in slow convergence or becoming trapped in local minima [
5]. To address these challenges, researchers have proposed a variety of strategies for selecting and adapting the step size [
6,
7,
8]. These strategies aim to balance stability and convergence speed throughout the optimization process. One commonly used approach is a constant step size, i.e.,
, as proposed in [
6]. It has been shown that SGD achieves a convergence complexity of
for non-convex functions, making it a reliable choice for many practical applications. Another widely studied method is the decaying step size, first introduced by Goffin [
9]. This approach includes variants such as
,
,
, and
step sizes, where the step size decreases gradually as training progresses [
7,
8,
10]. The decay mechanism allows for larger updates during the early stages of training when rapid exploration of the optimization landscape is desirable, and smaller updates in later stages to fine-tune the model parameters. Such adaptive adjustment reduces the likelihood of overshooting while improving convergence precision [
11]. Wang et al. [
8] introduced a weighted decay method using a learning rate proportional to the step size
, achieving an improved convergence rate of
for smooth non-convex functions. This approach effectively balances exploration and fine-tuning during optimization. Moreover, Ref. [
10] introduced a refinement to the step size
, proposing the expression
. This adjustment was made to prevent the step size from diminishing too rapidly, thus enhancing the accuracy of the SGD algorithm in classification tasks.
In addition to fixed and decaying step size strategies, dynamic schedules and adaptive methods have become increasingly popular. Techniques like step size annealing, which gradually reduces the step size over time, allow models to explore the parameter space more effectively during early training and fine-tune parameters in later stages [
12]. Adaptive optimizers, including Adam [
13], RMSProp [
14], and AdaGrad [
15], dynamically adjust the step size based on gradient information, enhancing stability and convergence. Similarly, the SGD with Armijo rule (SGD + Armijo) determines the optimal step sizes using the Armijo condition, ensuring a sufficient decrease in the objective function at each iteration [
16,
17].
The technique of warm restarts in SGD aims to boost training efficiency by periodically resetting the learning rate [
7]. This strategy effectively combines the benefits of high step sizes, which help the model escape local optima, with low step sizes, which are useful for fine-tuning the model as training progresses. One notable method that utilizes this idea is SGDR (stochastic gradient descent with warm restarts), proposed by Loshchilov and Hutter [
7]. By resetting the step size at specific intervals, SGDR helps overcome slow convergence issues often encountered with static step sizes, enabling faster convergence and better generalization. Integrating decay step size strategies with techniques such as warm restarts and cyclical step sizes has been shown to significantly enhance convergence rates. These methods enable models to adaptively modulate the step size across various training stages, promoting efficient exploration during initial phases and facilitating precise adjustments as training approaches completion. This dynamic adjustment ultimately leads to improved model performance [
7]. Compared to traditional SGD, which uses a fixed learning rate, the SGDR has been shown to require significantly less training time, often cutting the time needed by up to 50% [
18]. Variations of this method, such as cyclic learning rates and alternative restart strategies, have also demonstrated improvements in optimization performance [
10,
19,
20].
The
step size in SGD is widely used to optimize machine learning models, particularly in tasks like FashionMNIST. As the step size decreases gradually, it helps fine-tune model parameters and prevents overshooting the optimal solution. This approach ensures more precise adjustments as training progresses, which can be especially beneficial in the later optimization stages [
6,
9]. However, a key limitation of the
method is that the step size diminishes too quickly after only a few iterations, leading to slow convergence.
The Polyak–Łojasiewicz (PL) inequality provides a crucial framework for analyzing the convergence behavior of SGD methods in non-convex optimization. For a function
that satisfies the PL condition, the inequality ensures that the gradient norm serves as a direct measure of the gap to the global minimum [
6,
21]. In the context of stochastic optimization, the presence of noise significantly influences the choice of step size decay strategies. Specifically, when the PL condition is satisfied, the noise introduces challenges that require appropriate adjustments in the step size. The PL condition facilitates faster convergence rates by allowing the use of time-varying step sizes, which adapt to the noise level encountered during the optimization process. In this setting, the convergence rate is typically improved when using time-dependent step sizes, such as
, where
is the PL constant, as demonstrated by previous works [
6,
22].
Contribution
In this paper, we propose a novel sine step size for the SGD with warm restarts. Our main contributions can be summarized as follows:
We propose a new step size for SGD to enhance convergence efficiency. Unlike the rapidly decaying step size, the new proposed step size maintains a larger learning rate for longer, allowing for better exploration early on and more precise fine-tuning in later stages. The sine-based step size gradually decays to zero, ensuring stable and faster convergence while avoiding the slowdowns associated with traditional decay methods.
We establish an convergence rate for SGD under the proposed step size strategy for smooth, non-convex functions that satisfy the PL condition.
We establish a convergence rate of for smooth non-convex functions without the PL condition. Notably, this convergence rate outperforms existing methods and achieves the best-known rate of convergence for smooth non-convex functions.
We evaluate the performance of our proposed new step size against eight other step size strategies, including the constant step size,
,
, Adam, SGD + Armijo, PyTorch’s ReduceLROnPlateau scheduler, and the stagewise step size method [
20]. The results of performing SGD on well-known datasets like FashionMNIST, CIFAR10, and CIFAR100 show that the new step size outperforms the others, achieving a
improvement in test accuracy on the CIFAR100 dataset.
This paper is structured as follows:
Section 2 introduces the new sine step size and discusses its properties.
Section 3 analyzes the convergence rates of the proposed step size on smooth non-convex functions with and without PL conditions.
Section 4 presents and discusses the numerical results obtained using the new decay step size. Finally, in
Section 5, we summarize our findings and conclude the study.
In this paper, we use the following notation: the Euclidean norm of a vector is denoted by , the non-negative orthant and the positive orthant of are represented by and , respectively. Additionally, we use the notation to indicate that there exists a positive constant such that for all .
2. Problem Formulation and Methodology
In this paper, we consider the following optimization problem:
where
represents the loss function of the variable
for the
i-th training sample, and
n is the total number of training samples. This form of optimization is particularly common in machine learning tasks involving large datasets, such as classification and regression problems, where the objective is to minimize the empirical risk or expected loss over a set of training data points. The SGD method, which updates
x iteratively based on a subset of the data, is widely used for this purpose:
where
denotes a randomly chosen mini-batch of training samples, and
is the learning rate or step size at iteration
k. This method allows for efficient updates by estimating the gradient over only a small, randomly selected subset of the data, thus reducing the computational cost compared to computing the full gradient over all training samples at every iteration. As a result, SGD has become a cornerstone of optimization algorithms for large-scale machine learning problems, with applications ranging from deep learning to large-scale regression models [
23,
24]. Moreover, variants of SGD, such as mini-batch SGD, Adam, and others, further improve convergence speed and stability by adjusting the step size and utilizing additional optimization techniques [
13,
15].
To analyze the performance and ensure the convergence of the SGD method in solving the problem (
1), we assume the following conditions, which are commonly adopted in the optimization literature [
20]:
- A1:
f is an
L-smooth function, meaning that for all
, the following inequality holds:
This assumption ensures that the gradient of
f is Lipschitz continuous, with
L representing the Lipschitz constant. This condition is fundamental for the analysis of optimization algorithms as it guarantees that the function’s gradient does not change too rapidly, which is essential for the stability and convergence of gradient-based methods.
- A2:
The function
f satisfies the
-PL condition, i.e., for some constant
, the following inequality holds for all
:
where
denotes the optimal solution.
- A3:
For each iteration
, we assume that the expected squared norm of the difference between the stochastic gradient
and the true gradient
is bounded by a constant
, i.e.,
This assumption captures the noise inherent in the stochastic gradient estimation process, with
controlling the variance of the gradient estimates. By bounding the discrepancy between the true and stochastic gradients, this assumption ensures that the noise does not significantly hinder the optimization process, allowing for more reliable convergence behavior.
2.1. New Step Size
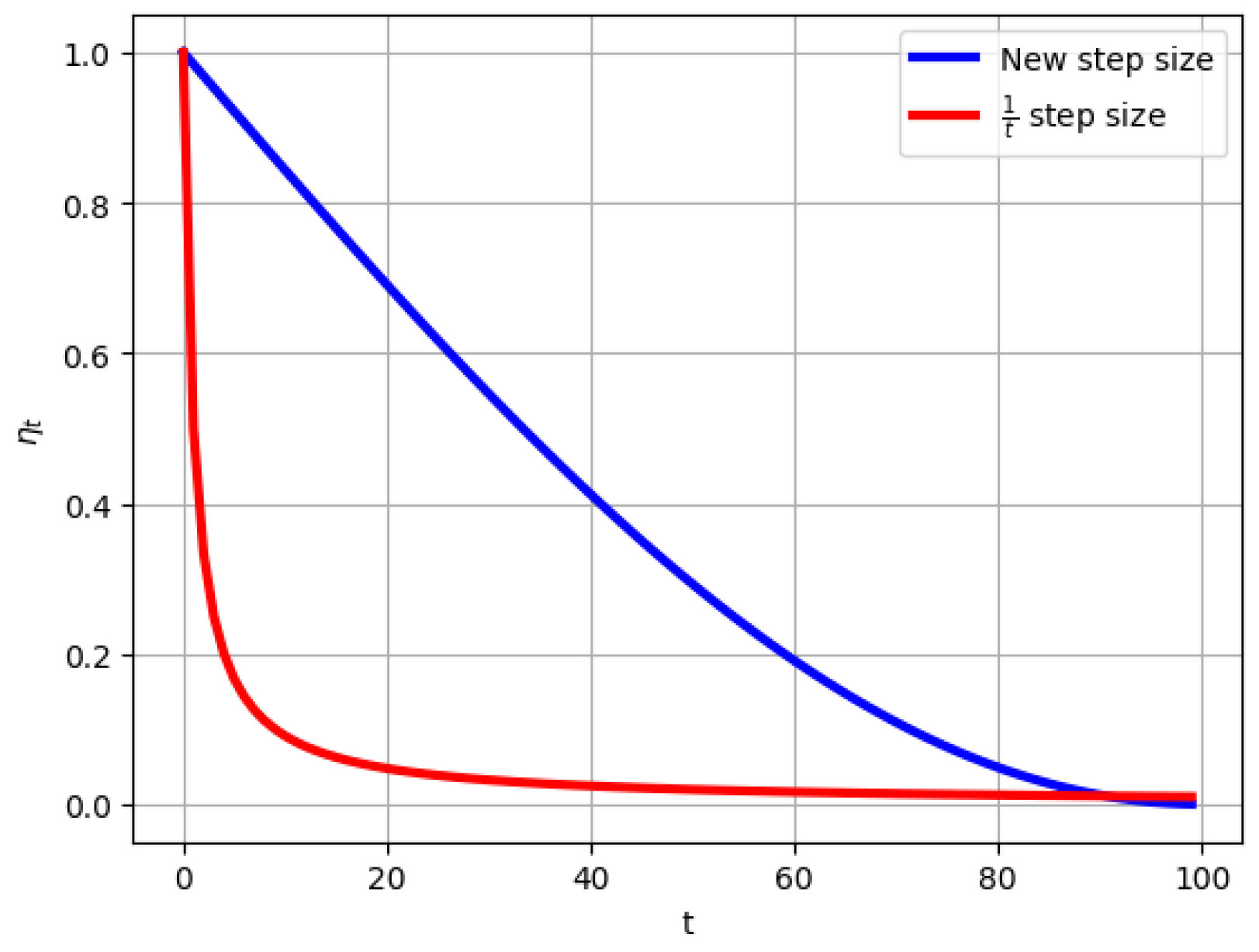
While the step size is widely recognized for its theoretical efficiency in SGD, it has a notable drawback; that is, the step size decreases rapidly after only a few iterations. As a result, the updates to the model parameters become progressively smaller, which significantly slows down the convergence process, particularly in the later stages of optimization. This inefficiency has motivated the development of alternative step size strategies to address the limitations of the step size .
To overcome this issue, we propose a trigonometric step size that ensures a more gradual and smooth decay compared to the steep reduction in the step size
. The new step size is defined as
where
is the initial step size, and
T represents the total number of iterations. This formulation maintains a relatively larger step size during the initial iterations, enabling efficient exploration of the optimization landscape. As training progresses, the step size gradually decreases, allowing for more precise parameter adjustments near the optimal solution. The new trigonometric step size given by (
3) provides two key advantages over the step size
:
Unlike the rapid reduction in the step size , the proposed step size decreases smoothly over iterations, improving the balance between exploration and exploitation.
The smoother decay prevents updates from becoming too small in the later stages, ensuring steady and reliable progress toward convergence.
Figure 1 demonstrates the behavior of the new trigonometric step size compared to the step size
, highlighting its smoother and more controlled transition over iterations. This property makes it a promising alternative for improving the efficiency and stability of SGD in various optimization tasks.
2.2. Warm-Restart Stochastic Gradient Descent (SGD)
Warm-restart SGD is an extension of the traditional SGD algorithm that periodically resets the learning rate during optimization. By introducing periodic “restarts” in the learning rate schedule, the method allows the algorithm to escape suboptimal local minima and explore new regions of the solution space, making it particularly effective for non-convex optimization problems [
7]. The approach involves starting each cycle with a high learning rate to promote exploration, followed by a gradual reduction to focus on exploitation and fine-tuning. This periodicity and adaptability enable the algorithm to balance exploration and exploitation dynamically, improving its performance across diverse optimization tasks.
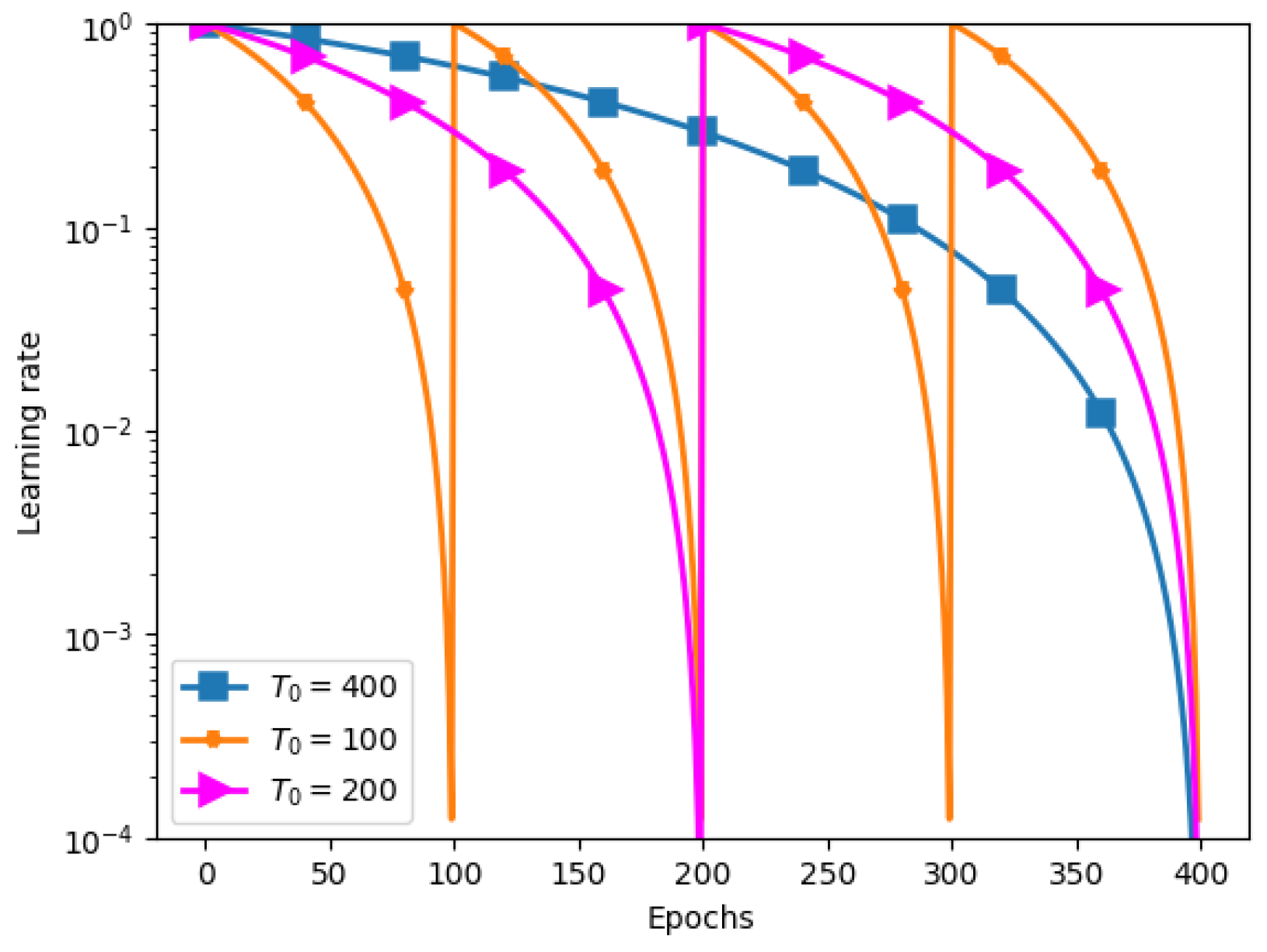
The new trigonometric step size, defined by (
3), is inherently periodic, making it especially suitable for warm-restart SGD. Its smooth and gradual decay aligns naturally with the cyclical learning rate schedule of warm restarts. At the start of each cycle, the higher values of the step size encourage substantial updates, facilitating effective exploration of new solution regions. As the cycle progresses, the step size decreases smoothly, ensuring consistent and meaningful updates that drive steady convergence. Unlike abrupt decay schedules, the sine-based step size avoids excessively small updates late in the optimization process, maintaining efficiency and stability. By integrating the periodic nature of the trigonometric step size with the warm-restart framework, this approach enhances the algorithm’s adaptability and accelerates convergence, particularly in complex, non-convex optimization landscapes.
Figure 2 illustrates the performance of the warm-restart strategy combined with the proposed trigonometric step size for various values of the total number of iterations,
T, set to 100, 200, and 400. As shown, the step size undergoes a smoother decay compared to traditional strategies, where the gradual reduction in the learning rate allows for larger updates during the earlier stages of training. With different values of
T, the figure highlights how the new step size maintains sufficient exploration in the initial phase and provides controlled exploitation in the latter stages, contributing to faster convergence and more efficient optimization. The effect of varying
T demonstrates how the decay rate adapts, offering more flexibility in fine-tuning the learning process for different training durations.
2.3. Algorithm
In our proposed approach, as outlined in Algorithm 1, we maintain a uniform number of inner iterations for each outer cycle, ensuring consistency in the algorithm’s performance across all stages. Specifically, the condition
indicates that the number of iterations within each epoch is kept constant, simplifying the analysis and comparison of different outer cycles. The algorithm begins by setting the initial parameters, including the initial value for the step size
, the initial point
, the total number of inner iterations
T, and the number of outer cycles
l. In addition, the algorithm is structured into two nested loops. The outer loop iterates through the specified number of epochs
l, while the inner loop executes the SGD updates within each epoch, using the proposed sine step size. The step size used for each inner iteration, i.e.,
t, is defined by
At the end of each inner loop, the updated point
is passed to the next outer iteration as the starting point
, ensuring continuity between epochs. Once all outer iterations are complete, the algorithm returns the final optimized point
.
![Axioms 13 00857 i001]()
3. Convergence
This section is dedicated to a theoretical analysis establishing the convergence properties of the SGD algorithm under the proposed step size. The analysis addresses smooth non-convex objective functions, with particular attention given to scenarios both satisfying and not satisfying the Polyak–Łojasiewicz (PL) condition. To facilitate this analysis, we introduce several key lemmas that play a critical role in establishing the convergence properties of the SGD algorithm with the new sine step size.
3.1. Convergence Without the PL Condition
We demonstrate that the SGD algorithm, utilizing the proposed step size for smooth non-convex functions, attains a convergence rate of , matching the best-known theoretical rate. The next lemma provides both an upper and lower bound for the function , when .
Lemma 1. For all , we have:
;
.
Lemma 2. For the step size given by (3), we have The next lemma provides an upper bound for .
Lemma 3. For the step size given by (3), we have The next lemma provides an upper bound for the expected gradient, which depends on the change in the objective function and the step size in SGD, under the condition that f is L-smooth and .
Lemma 4 (Lemma 7.1 in [
8])
. Assuming that f is an L-smooth function and that Assumption A3 holds, if , then the SGD algorithm guarantees the following results: The next theorem establishes an convergence rate of the SGD based on the new step size for smooth non-convex functions without the PL condition.
Theorem 1. Under Assumptions A1 and A3, the SGD algorithm with the new step sizes guarantees that where is a random iterate drawn from the sequence , with corresponding probabilities . The probabilities are defined as . Proof. Using the fact that
is randomly selected from the sequence
with a probability
and applying Jensen’s inequality, we obtain
We obtain the first and second inequalities by applying Jensen’s inequality and utilizing Lemma 4. Furthermore, considering the fact that
and Lemmas 2 and 3, we obtain
Setting
, we can conclude that
□
3.2. Convergence Results with PL Condition
The PL condition is a weaker form of strong convexity often used in the analysis of optimization algorithms. This property allows SGD to achieve efficient convergence, even for non-convex loss functions. Here, we present the convergence results for SGD with the new step size under the PL condition for smooth non-convex functions. Our analysis shows that the proposed sine step size achieves a convergence rate of . We begin by presenting several lemmas that are crucial for proving this convergence rate.
Lemma 5 (Lemma 2 in [
20])
. Suppose , , are non-negative for all , and . Then, we have The next lemma establishes an upper bound on the difference between the expected objective function value after T iterations and the optimal value for SGD, where the step size , and f is an L-smooth function that satisfies the PL condition.
Lemma 6. Assuming that f is an L-smooth function that satisfies the PL condition and that the step size satisfies for all t, the following result holds: Proof. From Lemma 4 we have
Equation (
5) can be written as
By utilizing the PL condition, i.e.,
, we conclude that
We now define
. As a result, from (
6) we derive
Utilizing Lemma 5 along with the definition of
, the following inequality can be established:
Using the fact that
and leveraging the property
, Equation (
7) can be reformulated as
□
Lemma 7. Let be non-negative numbers. Then, we have Proof. We define the function
, where
. It is clear that the function
is increasing on the interval
and decreasing for
. Therefore, the summation
can be bounded by partitioning the sum around
. Specifically, we decompose
S as follows:
An upper bound for
can be written as
Moreover, we have
Therefore, we can conclude that
Using the fact that
, we obtain
□
In order to use Lemma 6, it is essential to derive a lower bound for and an upper bound for . The subsequent lemma establishes these bounds.
Lemma 8. For the new proposed step size, as defined in (3), the following bounds hold: - I.
.
- II.
Proof. To prove item (I), we apply the definition of
and use Lemma 1. Therefore, we have
To prove item (II), we use Equation (
8), which leads to the following conclusion:
where the last inequality is obtained by using Lemma 7. □
By combining the results from Lemmas 2, 6 and 8, we can establish the convergence rate for smooth non-convex functions under the PL condition.
Theorem 2. Consider the SGD algorithm with the new proposed step size. Under Assumptions A1–A3, and for a given number of iterations T with the initial step size , the algorithm delivers the following guarantees: Proof. From Lemma 6, we have
Using Lemmas 2 and 8, we can rewrite (
10) as
Setting
, we conclude that
□
Based on Theorem 2, we can conclude that the SGD algorithm with the newly proposed step size, for a smooth non-convex function satisfying the PL condition, achieves a convergence rate of .
4. Numerical Results
In this section, we assess the performance of the proposed algorithm on image classification tasks by comparing its effectiveness against state-of-the-art methods across three widely used datasets: FashionMNIST, CIFAR10, and CIFAR100 [
2].
The FashionMNIST dataset consists of 50,000 grayscale images for training and 10,000 examples for testing, each with dimensions of pixels. For this dataset, we utilize a convolutional neural network (CNN) model. The architecture comprises two convolutional layers with kernel sizes of and padding of 2, followed by two max-pooling layers with kernel sizes of . The model also includes two fully connected layers, each with 1024 hidden nodes, employing the rectified linear unit (ReLU) activation function. To prevent overfitting, dropout with a rate of is applied to the hidden layers of the network. For performance evaluation, we use the cross-entropy loss function and measure accuracy as the primary evaluation metric for comparing the performance of the different algorithms.
The CIFAR10 dataset comprises 60,000 color images of size
, which are divided into 10 classes with 6000 images each. The dataset is split into 50,000 training images and 10,000 test images. To evaluate algorithm performance on this dataset, a 20-layer residual neural network (ResNet) architecture, as introduced in [
25], is employed. The ResNet model employs cross-entropy as the loss function.
The CIFAR100 dataset shares similarities with CIFAR10, with the key difference being that it consists of 100 classes, each containing 600 distinct natural images. For each class, there are 500 training images and 100 testing images. To enhance the training process, randomly cropped and flipped images are utilized. The deep learning model employed is a DenseNet-BC model that consists of 100 layers, with a growth rate of 12 [
26].
We conducted a performance comparison between our proposed method and state-of-the-art methods that have been previously fine-tuned in a study in [
20]. In our own numerical studies, we adopted the same hyperparameter values as used in that research. To mitigate the impact of stochasticity, the experiments are repeated five times using random seeds.
4.1. Methods
In our study, we examined SGD with various step sizes as follows:
We give the following names to these step sizes: the SGD constant step size, the
step size, the
step size, and the new step size. The parameter
t represents the iteration number of the inner loop, and each outer iteration consists of iterations for training on mini-batches. We wanted to compare the performance of the new step size with other optimization methods, namely, Adam, SGD + Armijo, PyTorch’s ReduceLROnPlateau scheduler, and the stagewise step size method. It is worth noting that the term “stagewise” in our context refers to the Stagewise—2 Milestone and Stagewise—3 Milestone methods, as defined in [
20]. Since we utilized Nesterov momentum in all our SGD variants, the performance of multistage accelerated algorithms, as discussed in [
27], is essentially covered by the stagewise step decay. For consistency, all our experiments followed the settings proposed in [
20].
4.2. Parameters
To determine the optimal value for the hyperparameter for each dataset, we employed a two-stage grid search approach. In the first stage, we conducted a coarse search using the grid to identify a promising interval for that yielded the best validation performance. In the second stage, we further refined the search within the identified interval by dividing it into 10 equally spaced values and evaluating the accuracy at each point. This fine-tuning process allowed us to determine the optimal for each dataset based on the resulting performance. The procedure was applied individually to each dataset, ensuring that the hyperparameters were specifically tailored to the characteristics of each dataset.
To benchmark the effectiveness of our proposed method, we compared it against state-of-the-art approaches. The hyperparameters used for these methods were obtained from a prior study [
20], and we adopted the same values in our experiments for consistency. These hyperparameters are summarized in
Table 1. The momentum parameter was fixed at 0.9 across all methods and datasets. Moreover, the symbol − indicates that the respective step size does not require or utilize the specified parameter. For weight decay, we used values of
for FashionMNIST and CIFAR10, and
for CIFAR100, consistent across all methods. Additionally, a batch size of 128 was used for all experiments. The parameter
was defined as the ratio of the number of training samples to the batch size.
4.3. Results and Discussion
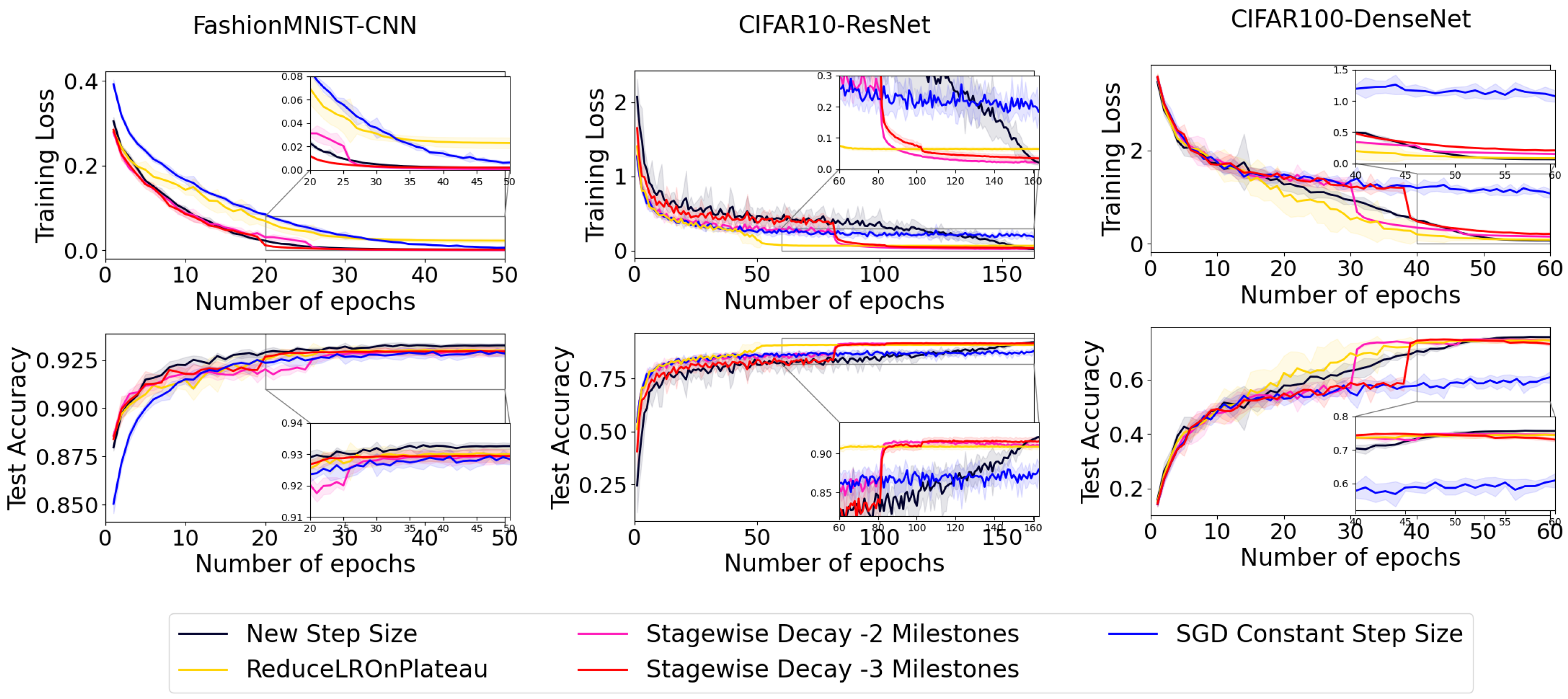
We divide the methods into two groups and present the results in distinct figures for better clarity. In
Figure 3 and
Figure 4, we observe that the new proposed step size shows significant improvements on the FashionMNIST dataset. After the 40th epoch, it achieves a training loss close to zero, comparable to the well-known methods SGD + Armijo and Stagewise—3 Milestone. Additionally, the test accuracy of the new proposed step size surpasses all other methods in this dataset.
In the CIFAR10 dataset, the new step size achieves superior accuracy compared to other step sizes. Specifically, it enhances the accuracy of Stagewise—2 Milestone by
in test accuracy, as shown in
Figure 3 and
Figure 4. Similarly, in the CIFAR100 dataset, this new step size outperforms others in terms of accuracy, improving the accuracy of Stagewise—1 Milestone by
in test accuracy, as evidenced in
Figure 3 and
Figure 4.
Overall, the newly proposed step size demonstrates the best performance among the methods evaluated for both the CIFAR10 and CIFAR100 datasets, as clearly indicated in
Figure 3 and
Figure 4.
Table 2 demonstrates the average of the final test accuracy obtained by five runs starting from different random seeds on the FashionMNIST, CIFAR10, and CIFAR100 datasets. The bolded values in the table represent the highest accuracy achieved for each dataset among all different step sizes. Based on the information presented in
Table 2, it can be inferred that the new proposed step size leads to a
,
, and
improvement in test accuracy compared to the previously studied best method on the FashionMNIST, CIFAR10, and CIFAR100 datasets, respectively.
4.4. Limitations
The proposed step size has demonstrated notable performance improvements when applied to the DenseNet-BC model for classification tasks. However, a significant limitation arises when attempting to extend this approach to more complex neural network architectures, such as EfficientNet. These models, which require the updating of a larger number of weight parameters, introduce substantial computational complexity. Moreover, the current system is constrained by limited GPU and hardware resources, which restricts the ability to efficiently explore hyperparameter configurations for these advanced architectures. This makes it challenging to fully leverage the potential of the proposed step size in more complex models.
5. Conclusions
In this paper, we introduced a novel sine step size aimed at enhancing the efficiency of the stochastic gradient descent (SGD) algorithm, particularly for optimizing smooth non-convex functions. We derived a theoretical convergence rate for SGD based on the newly proposed step size for smooth non-convex functions, both with and without the PL condition. By testing the approach on image classification tasks using the FashionMNIST, CIFAR10, and CIFAR100 datasets, we observed significant improvements in accuracy, with gains of , , and , respectively. These findings highlight the potential of the sine step size in advancing optimization techniques for deep learning, paving the way for further exploration and application in complex machine learning tasks.
For future work, testing the sine step size on more complex neural network architectures like recurrent neural networks (RNNs) and transformers could provide further insights into its effectiveness across a wider range of tasks. Exploring its impact on large-scale datasets and different domains, such as natural language processing or reinforcement learning, could also enhance its applicability. Finally, theoretical advancements in convergence analysis for different types of functions, including convex and strongly convex problems, could refine its usage in diverse optimization scenarios.






{kind=link}
{kind=link}
{kind=link}
{kind=link}