1. Introduction
In reliability experiments or clinical trials, the failure times of experimental objects are frequently unavailable. Censoring strategies are commonly used to save money while also limiting the amount of time spent on experiments. The two most popular censorship mechanisms, called; Type-I (or time) and Type-II (or failure) censoring strategies. These plans have been studied in detail by Bain and Engelhardt [
1]. Two mixtures of Type-I and Type-II techniques, called hybrid Type-I hybrid (T1H) and Type-II hybrid (T2H), are introduced by Epstein [
2] and Childs et al. [
3], respectively. Although a vast amount of literature is available on the given schemes, they do not allow for the withdrawal of live test items at other times than when the test ends. So, these plans do not have the flexibility to allow subjects to be removed, and they will not be beneficial to use. Therefore, to overcome this drawback, Type-I and Type-II progressive as well as Type-I progressive hybrid (T1PH) and Type-II progressive hybrid (T2PH) censored mechanisms are discussed in detail by an excellent monograph presented by Balakrishnan and Cramer [
4]. Unfortunately, although T2PH has become very common in reliability tests, it can take a long duration to stop the test, and thus inference procedures may be unworkable or ineffective. To address the disadvantages, Ng et al. [
5] proposed adaptive-T2PH to benefit from reducing the total test duration and enhancing grading efficiency.
Despite both T2PH and adaptive-T2PH censoring strategies ensure a certain amount of failures, their disadvantage is that it may take quite some time to detect the required
m failures and end the test. As a result, Lee et al. [
6] proposed a generalized-T2PH technique in which the study is certain to stop at a fixed time. They stated that the study carried out based on the generalized-T2PH plan could save overall time on testing and cost. We briefly explain this strategy as: Suppose
n subjects are put on an experiment at time 0, the size of censored sample
, the progressive design
and
(where
) must be prefixed. Let (
) be the length of the observed failures before (
). However, as soon as the first failure (say
) occurs,
(of
) are randomly drawn from the experiment; next when second failure (say
) occurs,
(of
) are randomly drawn, and so on. Then, at time
, the testing stopped. Clearly,
represents the greatest time for which the researcher is ready to continue the examination.
The main feature of this process is that it might occur when the participant has planned to use the testing facility for two time limitations by changing the values of some of the progressive units during the experiment. However, if
, end the test at
(Case-I); If
, end the test at
(Case-II); otherwise, stop the test at
(Case-III). Practically, the experimenter collects one of the following data groups:
Let
represent order statistics collected from a generalized-T2PH censoring, which come from a continuous population with probability density function (PDF) (symbolized by
) and cumulative distribution function (CDF) (symbolized by
). Then, the joint PDF of
can be expressed as
where
is a vector of interested parameters.
Table 1 provides the notations
,
,
,
and
of the generalized-T2PH censoring. Further, from (
1), various censoring techniques are reported in
Table 2. Several research investigations have been conducted on the statistical estimate of unknown parameter(s) and/or reliability indices in various lifespan models using generalized-T2PH data; e.g., see Ashour and Elshahhat [
7], Ateya and Mohammed [
8], Seo [
9], Cho and Lee [
10], Nagy et al. [
11], Wang et al. [
12], Elshahhat et al. [
13], later Alotaibi et al. [
14], among others.
The Rayleigh model is a particular kind of the Weibull lifetime model, which was initially suggested by Rayleigh while researching acoustics difficulties. Because it just has one parameter, its practical uses are restricted and un-flexible. Therefore, Ghitany et al. [
15] proposed a novel general group of inverse exponentiated distributions in which the two-parameter inverted exponentiated Rayleigh (IER) distribution is a particular member and its failure rate is non-monotonic if the failure rates of testing elements are not monotonous and show a pattern of change. However, suppose
Y is a nonnegative random variable of a test item that follows the IER distribution, denoted by
, where
,
is the shape and
is the scale parameters, respectively. Thus, its PDF, CDF, and hazard rate function (HRF), (symbolized by
), are given respectively by
and its reliability (or survival) function (RF) given by
.
In literature, using different sampling scenarios, several authors have done significant work on the theories and applications of the IER model, for example, Rastogi and Tripathi [
16] analyzed hybrid Type-I; independently, Kayal et al. [
17] as well as Maurya et al. [
18] analyzed progressive Type-II; independently, Gao and Gui [
19] as well as Maurya et al. [
20] analyzed progressive first-failure; Gao and Gui [
21] discussed the pivotal inference from progressive Type-II; Panahi and Moradi [
22] analyzed an adaptive Type II progressive hybrid; recently Fan and Gui [
23] analyzed joint progressively Type-II censoring mechanisms.
Table 2.
Six special cases from generalized-T2PH censoring.
Table 2.
Six special cases from generalized-T2PH censoring.
| Plan | Author(s) | Setting |
|---|
| T1PH | Kundu and Joarder [24] | |
| T2PH | Childs et al. [25] | |
| T1H | Epstein [2] | , and |
| T2H | Childs et al. [3] | , and |
| Type-I | Bain and Engelhardt [1] | , , and |
| Type-II | Bain and Engelhardt [1] | , , and |
Although a great deal of work has been done on the IER lifetime model, to the best of our experience, no effort has been achieved to discuss the IER’s model parameters and(or) reliability time features when the sample is a generalized-T2PH censored strategy. To fill up this issue, using the proposed censoring plan, the main contribution of the present study is three-fold:
Maximum likelihood estimators (MLEs) along with their approximate confidence intervals (ACIs) of , , and are obtained.
Bayes’ estimators under independent gamma assumptions of , , and are created relative to the squared-error (SE) and general-entropy (GE) losses.
Bayes estimators cannot be estimated in explicit form, so Markov-chain Monte-Carlo (MCMC) approximation techniques are recommended to compute the acquired Bayes MCMC estimates and the associated highest posterior density (HPD) intervals.
Numerical solutions for the offered estimators of
,
,
and
are done by installing two useful packages, namely: ‘
’ (proposed by Plummer et al. [
26]) and ‘
’ (proposed by Henningsen and Toomet [
27]) on the
4.2.2 programming platform.
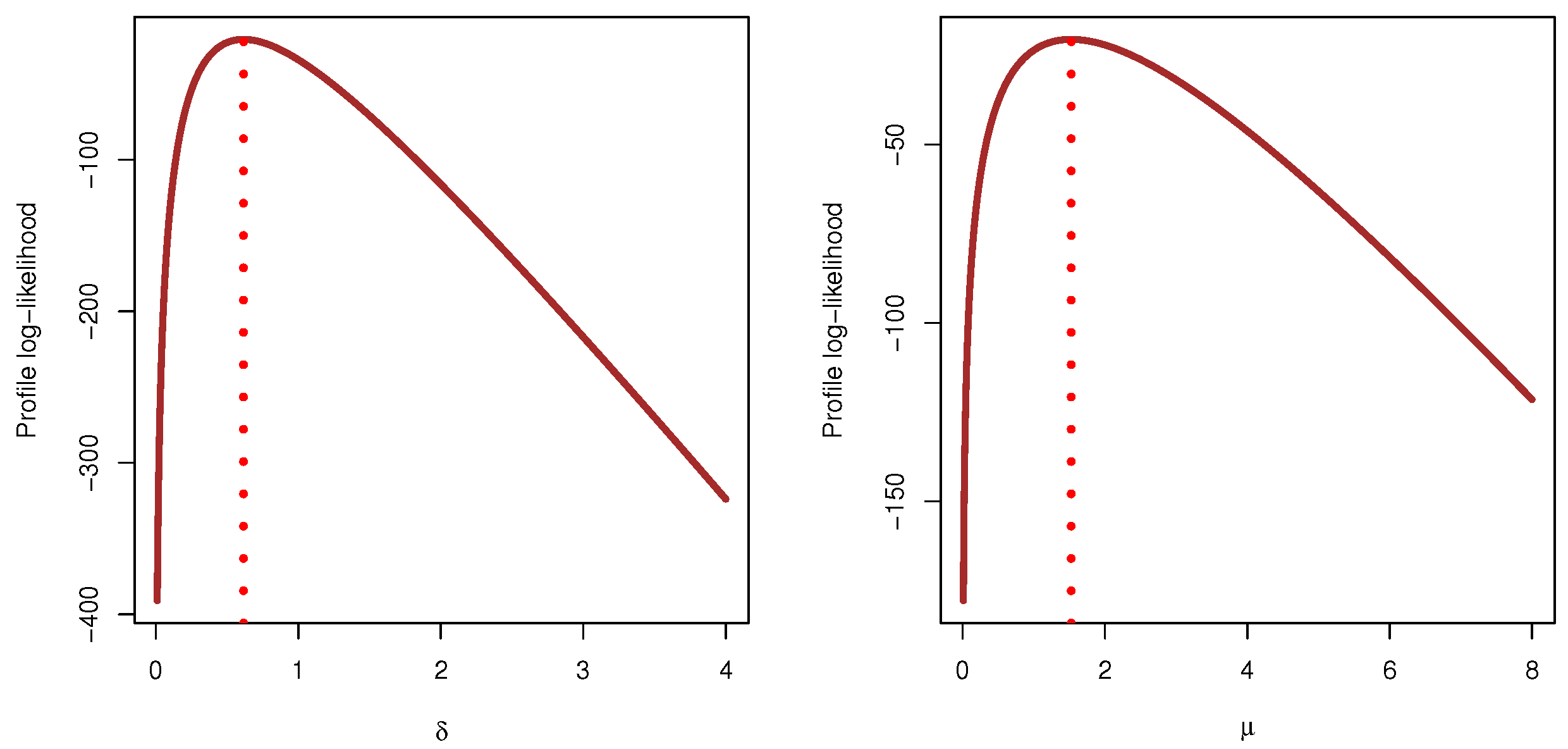
Extensive Monte Carlo comparisons, on the basis of four accuracy criteria, namely: (i) root mean squared-errors; (ii) mean relative absolute-biases; (iii) average confidence lengths; and (iv) coverage percentages, the behavior of the acquired estimators of , , and is discussed.
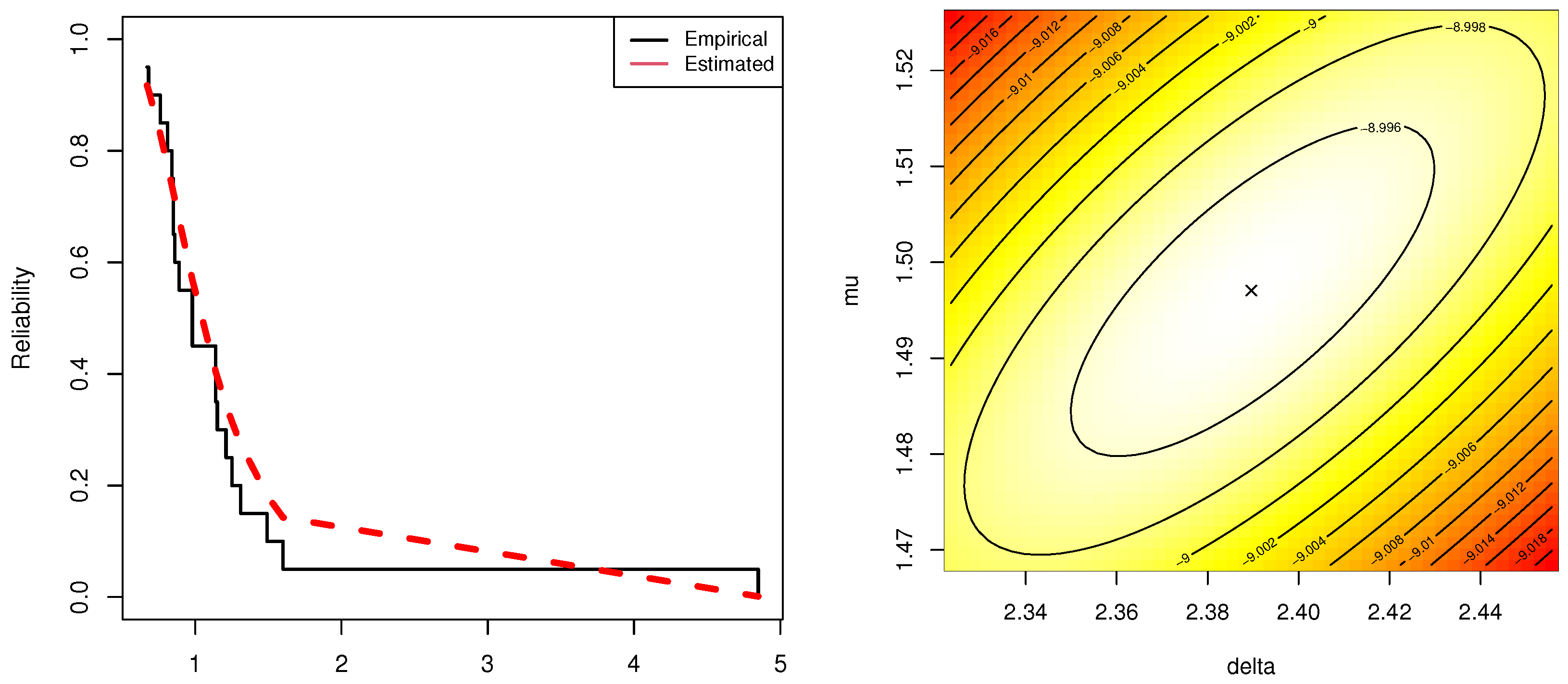
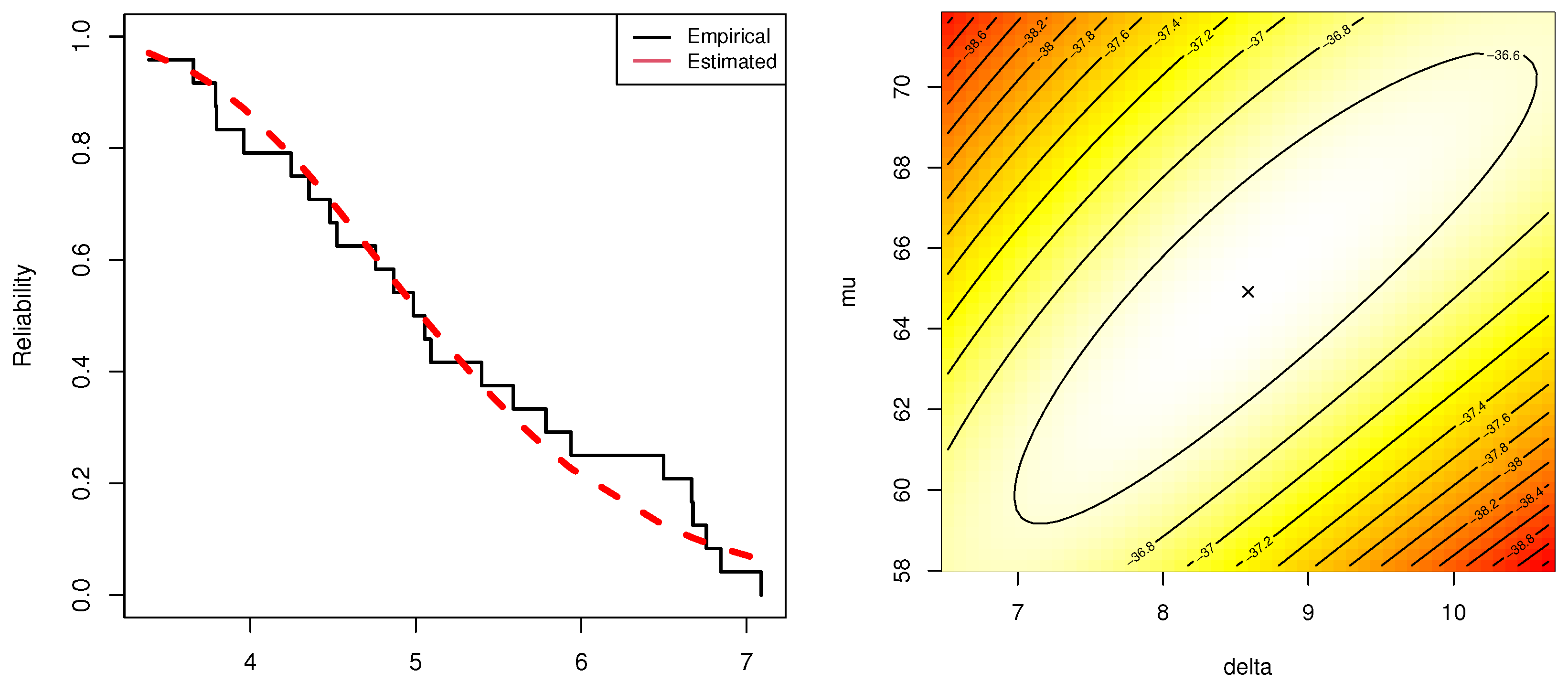
To benefit from the practicality and flexibility of the IER model in data analysis, from the engineering and chemistry areas, we analyzed different real data sets that reflect failure times of mechanical components and cumin essential oil.
The rest of the work is classified as follows:
Section 2 investigates both maximum likelihood and Bayesian inferences. Monte Carlo simulations are reported in
Section 3. In
Section 4, two real applications are explored. Lastly,
Section 5 provides some concluding remarks and recommendations of the study.
3. Monte Carlo Simulations
To know the associated performance of the offered estimators, investigated in the proceeding sections, of , , and , several comparisons via Monte Carlo simulations are performed. So, for specified choices of (threshold time points), n (number of experimental subjects), m (effective sample items) and (removal design), we replicated generalized-T2PH 1000 times from using the following steps:
- Step 1.
Set the actual values of and .
- Step 2.
For given values of
n,
m,
,
and
, following Balakrishnan and Cramer [
4], generate a traditional progressive Type-II sample with size
m units.
- Step 3.
Obtain the values of at .
- Step 4.
Determine the generalized-T2PH case as:
- a.
Case-I: If , set end the experiment at . Then, replace by those items collected from a truncated distribution with size .
- b.
Case-II: If , end the experiment at .
- c.
Case-III: If , end the experiment at .
Taking
, the true values of
and
are 0.9305 and 0.5310, respectively. Several failure percentages (FPs) (of each
n) such as
(=50, 80)% are considered. Further, for each group of
, three progressive mechanisms
are also used namely:
where
means that 0 is repeated
times.
When the desired generalized-T2PH samples obtained, via
4.2.2 software, the MLEs along their 95% ACIs of
,
,
and
are estimated via ‘
’ package. By running the MCMC sampler 12,000 times, when
2000, the Bayes’ inferences are obtained through the ‘
’ package introduced by Plummer et al. [
26]. To see how the gamma priors behave in Bayesian analysis, two informative sets called Prior-I and -II of
are used as
and
, respectively.
In our calculations, for
, the average estimates (Av.Es) of
,
,
or
(say
) are given by
where
is the estimate of
at
ith sample,
,
,
and
.
The comparison of the acquired point estimates of is made based on the following metrics:
- (i)
Root mean squared-errors (RMSE):
- (ii)
Mean absolute biases (MAB):
On the other hand, the comparison of the acquired interval estimates of is made based on the following metrics:
- (i)
Average confidence length (ACL):
where
denotes (lower-limit,upper-limit) of
ACI/HPD intervals of
.
- (ii)
Mean absolute biases (MAB):
where
denotes the indicator function.
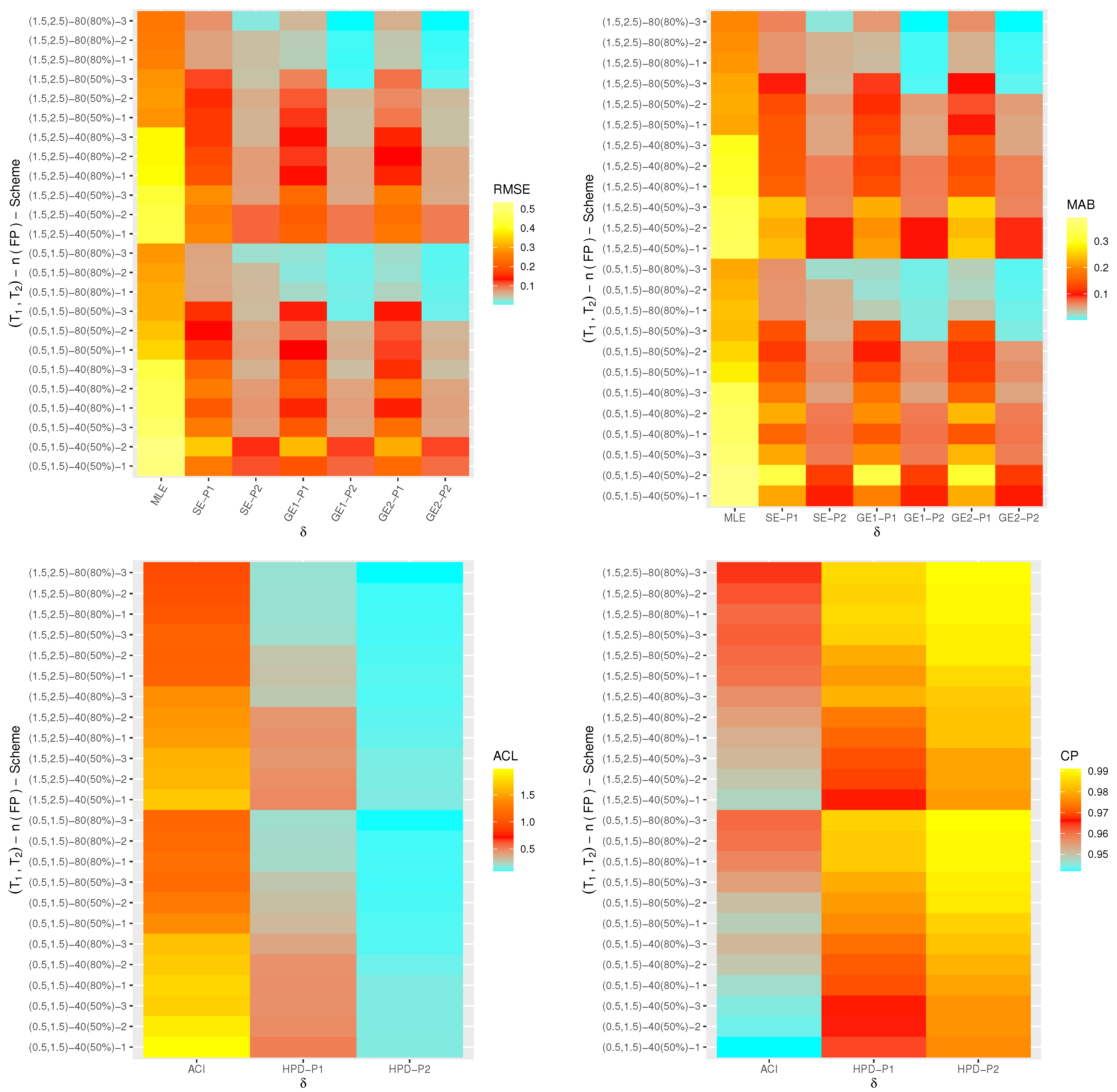
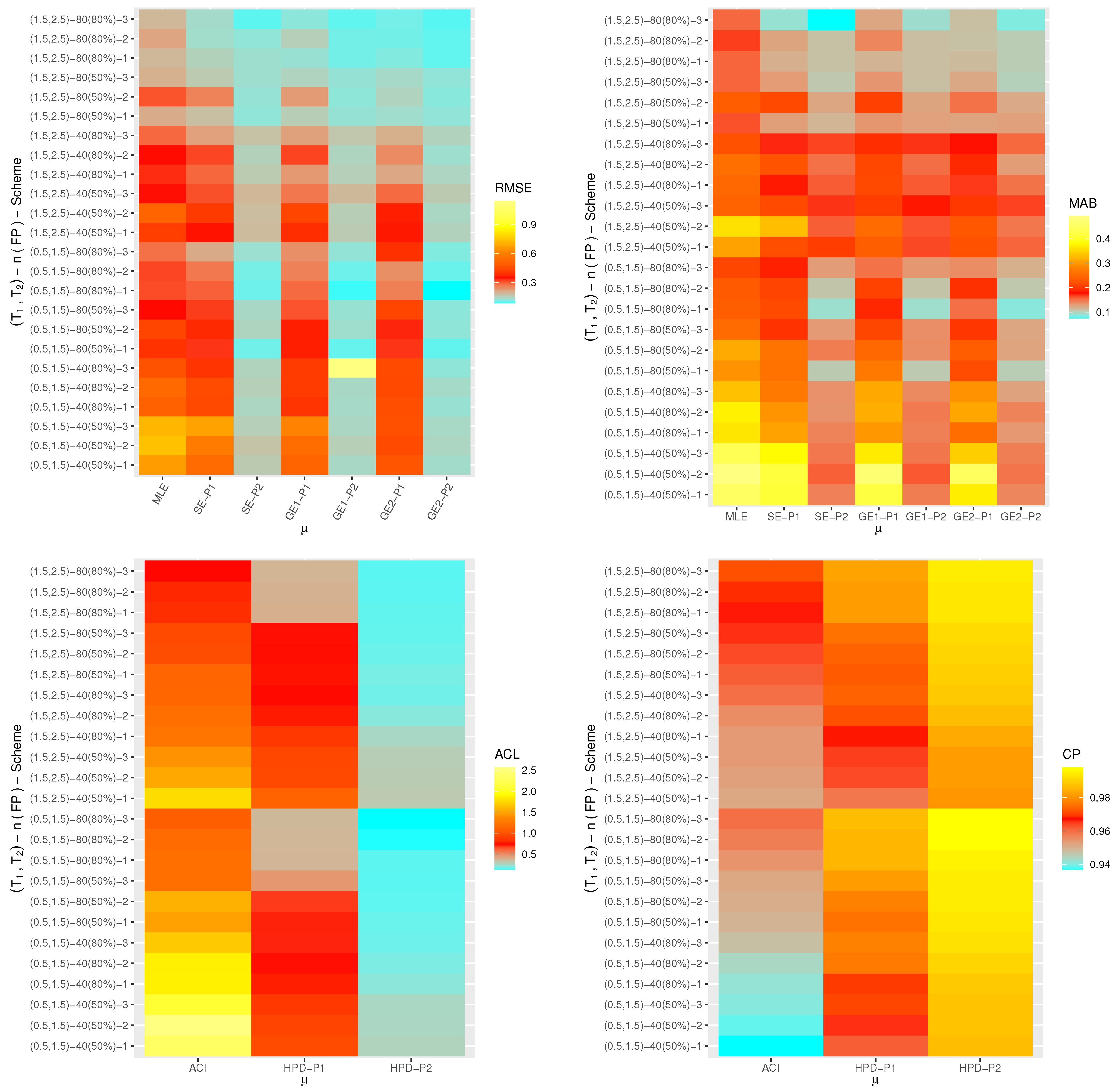
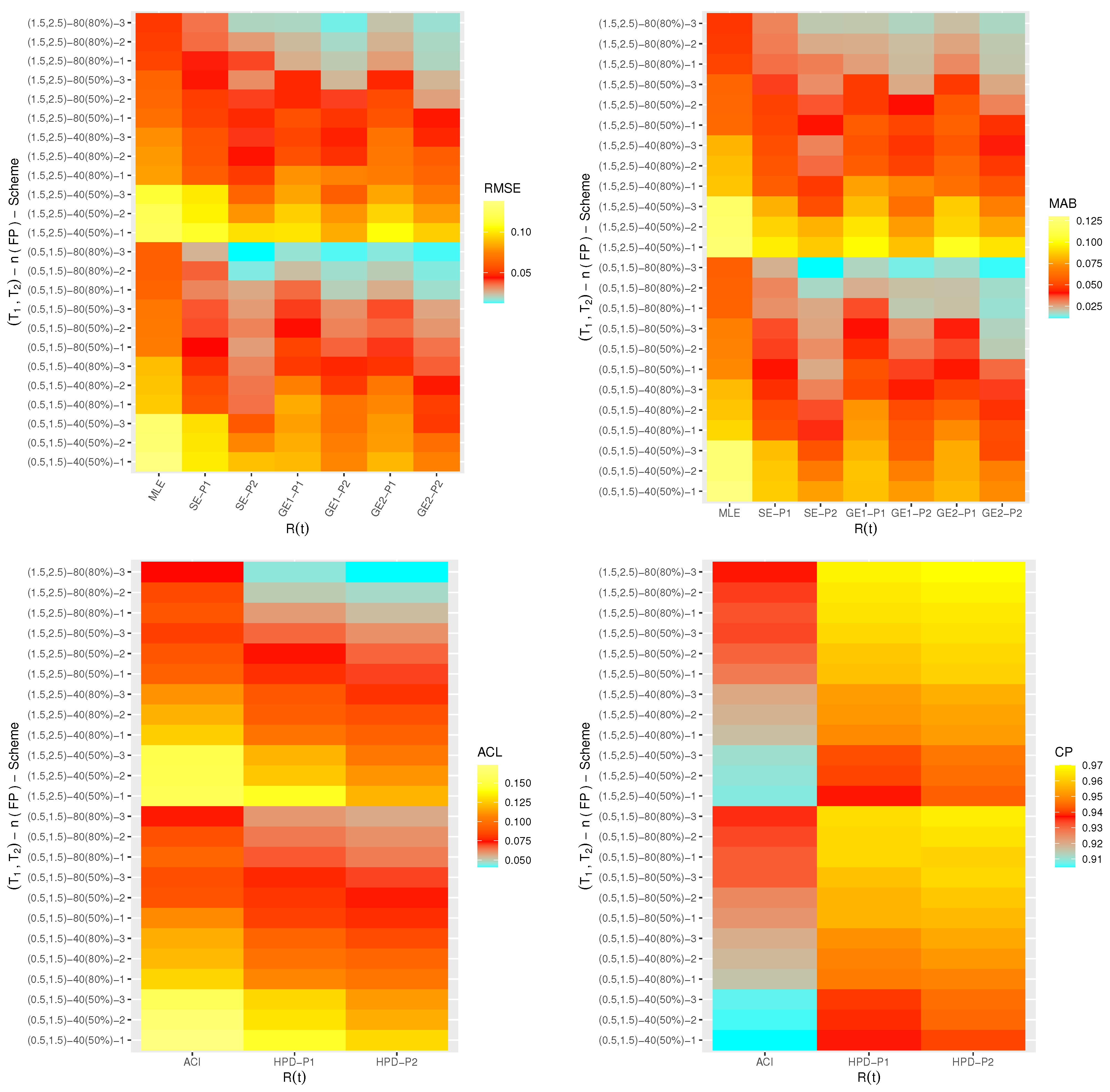
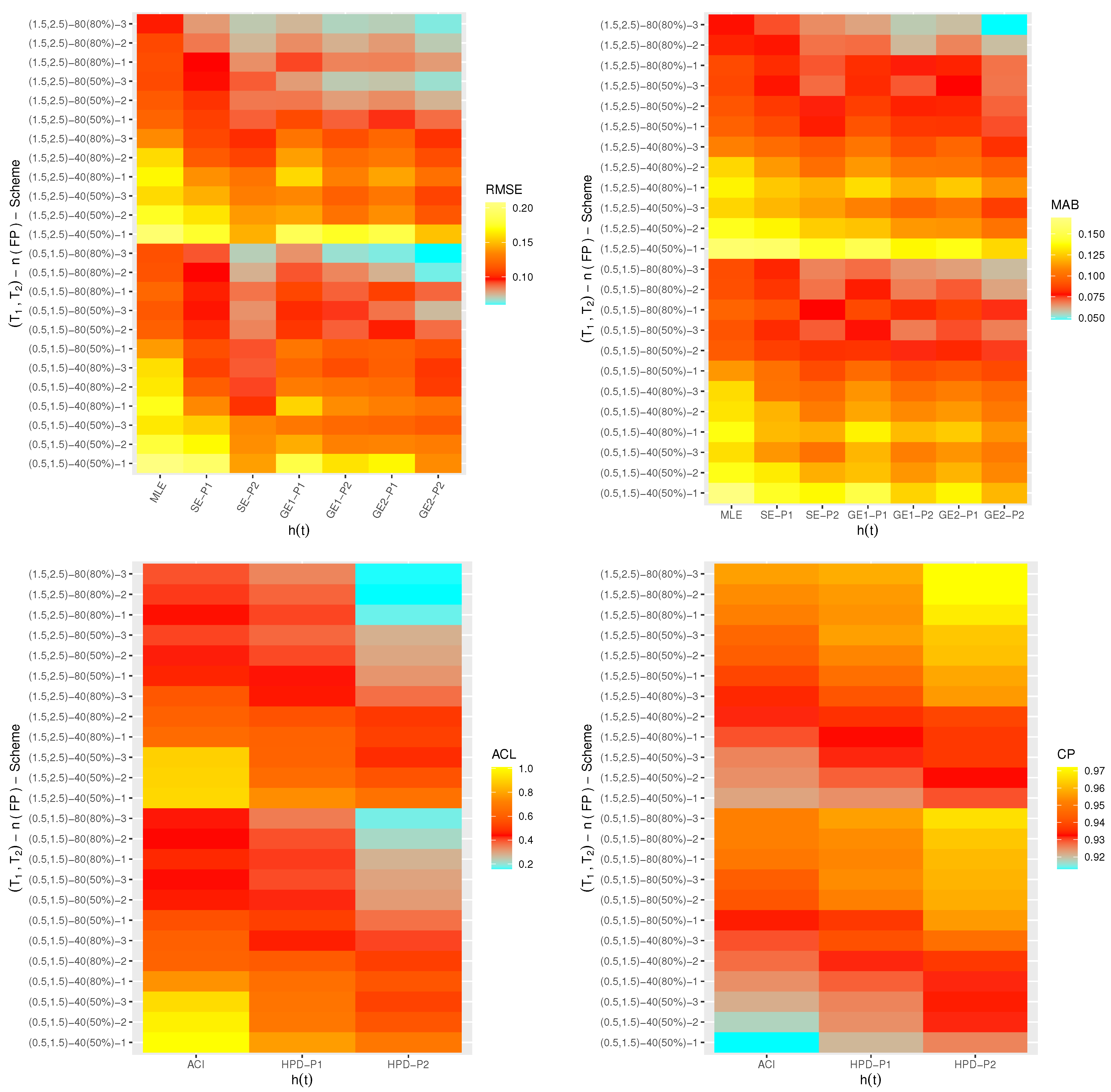
One of the best data visualization tools in
4.2.2 software is known as a heat-map. Therefore, in this study, the simulated RMSEs, MABs, ACLs and CPs of
,
,
and
are plotted with heat-map and shown in
Figure 4,
Figure 5,
Figure 6 and
Figure 7, respectively. Also, the numerical results of
,
,
and
are also available in a
Supplementary File. Some abbreviations of the proposed methods, for Prior-I (say P1) as an example, have been used such as: “SE-P1” refers to the Bayes estimates under SE loss; “GE1-P1” refers to the Bayes estimates under GE loss (for
); “GE2-P1” refers to the Bayes estimates under GE loss (for
) and “HPD-P1” refers to the HPD intervals.
From
Figure 4,
Figure 5,
Figure 6 and
Figure 7, in terms of the smallest RMSE, MAB and ACL values as well as the highest CP values, the following notes are drawn:
A general observation in this study is that the acquired estimates of , , or have good behavior.
Due to gamma informations, the Bayes point estimates (or their HPD credible interval estimates) of , , or behave satisfactory compared to the frequentist estimates.
Comparing the variance values associated with priors I and II, it can be seen that the variance of Prior-II is lower than the other, thus the Bayes calculations from this prior provide good estimates.
As n(or m) increases, both point and interval estimates of all unknown quantities perform sufficiently. A similar note is also obtained at decreases.
As increase, the RMSEs, MABs and ACLs of , , and decrease except for those associated with in the case of MCMC estimates. Opposite behavior of , , and is also reached in the case of estimated CP values.
Comparing the proposed censoring mechanisms, all calculated point/interval estimates of , , or are more efficient using Scheme 3 than others.
As a summary, to estimate the IER parameters , , or in presence of data generated from Type-II generalized progressively hybrid censored sampling, the Bayes’ paradigm via M-H algorithm is recommended.
5. Conclusions
This article discusses the examination of a generalized progressive Type-II hybrid censored test where the lifespans of the testing products have an inverted exponentiated Rayleigh model. Besides the issue of estimating model parameters, the present study has also taken into account the estimating issues of reliability and failure functions of the proposed model. The likelihood approach has been used to get acquire both point and asymptotic estimates of the objective parameters. From a Bayes’ point of view, both symmetric and asymmetric Bayes estimates, based on asymmetric and symmetric loss functions, of the unknown parameters have been developed using a hybrid Monte-Carlo Markov-Chain algorithm. Also, two-sided highest posterior interval estimators of the same parameters have also been cerated. Through valuable simulation experiments, the efficiency of various estimating strategies has been established. Numerical evaluations show that the acquired Bayes points and credible estimates behave satisfactorily. Two packages, namely ‘’ and ‘’, have been installed to evaluate the suggested theoretical results. Two applications, based on real data sets from various fields, namely engineering and chemistry, have been examined to demonstrate the utility of the suggested model in real-world applications. As a summary, in the presence of a sample produced through the proposed censoring, the Bayes framework is advised for estimating the model parameters of life of the inverted exponentiated Rayleigh model. In the future, it would be interesting to examine the inferential concerns of the same model utilized for other statistical challenges, such as accelerating life tests, competing risks, etc.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











