
Conditional Tail Expectation and Premium Calculation under Asymmetric Loss



Abstract
1. Introduction
2. Premium Calculation Minimizing the CTE under Asymmetric Loss
- (i)
- Translativity: any increase in the liability by a deterministic amount c should result in the same increase in the capital. If the risk increases by a fixed amount c, then the premium also increases by that amount, i.e., for all random variables and each constant c.
- (ii)
- Monotonicity: if then , assuming that and exist, where is the usual stochastic order.
- (iii)
- Subadditivity: this reflects the idea that risk can be reduced by diversification, i.e., .
- (iv)
- Positive homogeneity or scale invariance: independence with respect to the monetary units used, i.e., for all random variables and any constant c. As , then using Proposition 1, is the optimal solution of the equations
- (v)
- No-rip off: if , then . , for all random variables. It is useless to keep more capital than the maximal loss value. If the random variable is unbounded then the premium is infinite.
- (vi)
- Constancy (or no unjustified loading): if , then . To deal with a loss of c, the insurer only needs to have a capital of the same amount at its disposal.
- (i)
- As , then using Proposition 1, is the optimal solution of the equations
- (ii)
- If , then for all and therefore for all . Thus .
- (iii)
- It is direct.
- (iv)
- This property is satisfied since the CTE is a coherent risk measure. To be named coherent, a risk measure must be positive homogeneous, translative, and subadditive (see [20]).
- (v)
- The result follows since
- (vi)
- The result is easily verified since
3. Analytical Expressions of the Premium for Composite Models
4. A Specific Model
5. Numerical Application
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Artzner, P.; Delbaen, F.; Eber, J.M.; Heath, D. Coherent measures of risk. Math. Financ. 1999, 9, 203–228. [Google Scholar] [CrossRef]
- Klugman, S.A.; Panjer, H.H.; Willmot, G.E. Loss Models. From Data to Decisions, 3rd ed.; John Wiley: Hoboken, NJ, USA, 2008. [Google Scholar]
- Furman, E.; Zitikis, R. Weighted premium calculation principles. Insur. Math. Econ. 2008, 42, 459–465. [Google Scholar] [CrossRef]
- Furman, E.; Zitikis, R. Weighted risk capital allocations. Insur. Math. Econ. 2008, 42, 263–269. [Google Scholar] [CrossRef]
- Heilmann, W.R. Decision theoretic foundations of credibility theory. Insur. Math. Econ. 1989, 8, 77–95. [Google Scholar] [CrossRef]
- Gómez-Déniz, E. A generalization of the credibility theory obtained by using the weighted balanced loss function. Insur. Math. Econ. 2008, 42, 850–854. [Google Scholar] [CrossRef]
- Gómez-Déniz, E.; Calderín-Ojeda, E. Credibility premiums for natural exponential family and general 0–1 loss function. Chil. J. Stat. 2015, 6, 3–17. [Google Scholar]
- Zellner, A. Bayesian and non-Bayesian estimation using balanced loss function. In Statistical Decision Theory and Related Topics; Gupta, S.S., Berger, J.O., Eds.; Springer: New York, NY, USA, 1994; pp. 371–390. [Google Scholar]
- Farsipour, N.S.; Asgharzadhe, A. Estimation of a normal mean relative to balanced loss functions. Stat. Pap. 2004, 45, 279–286. [Google Scholar] [CrossRef]
- Jafari, M.; Marchand, E.; Parsian, A. On estimation with weighted balanced-type loss function. Stat. Probab. Lett. 2006, 76, 773–780. [Google Scholar] [CrossRef]
- Hosomatsu, Y. Concepts, theory, and techniques. Asymmetric loss function and optimal policy under uncertainty: A simple proof. Manag. Sci. 1980, 26, 577–582. [Google Scholar]
- Rockafellar, R.; Uryasev, S. Conditional value at risk for general loss distributions. J. Bank. Financ. 2002, 26, 1443–1471. [Google Scholar] [CrossRef]
- Rockafellar, R.; Uryasev, S.; Zabaranking, M. Generalized deviations in risk analysis. Financ. Stoch. 2006, 10, 51–74. [Google Scholar] [CrossRef]
- Wang, S. Premium calculation by transforming the premium layer density. ASTIN Bull. 1996, 26, 71–92. [Google Scholar] [CrossRef]
- Heras, A.; Balbás, B.; Vilar, J.L. Conditional tail expectation and premium calculation. ASTIN Bull. 2012, 42, 325–342. [Google Scholar]
- Grün, B.; Miljkovic, T. Extending composite loss models using a general framework of advanced computational tools. Scand. Actuar. J. 2019, 8, 642–660. [Google Scholar] [CrossRef]
- Pigeon, M.; Denuit, M. Composite Lognormal–Pareto model with random threshold. Scand. Actuar. J. 2011, 3, 177–192. [Google Scholar] [CrossRef]
- Scollnik, D.P.M. On composite Lognormal-Pareto models. Scand. Actuar. J. 2007, 1, 20–33. [Google Scholar] [CrossRef]
- Sarabia, J.M.; Calderín-Ojeda, E. Analytical expressions of risk quantities for composite models. J. Risk Model Valid. 2018, 12, 75–101. [Google Scholar] [CrossRef]
- Kaas, R.; Goovaertes, M.; Dhaene, J.; Denuit, M. Modern Actuarial Risk Theory; Springer; Heidelberg Gmbh & Co. Kg.: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Cooray, K.; Ananda, M.M.A. Modeling actuarial data with a composite Lognormal–Pareto model. Scand. Actuar. J. 2005, 5, 321–334. [Google Scholar] [CrossRef]
- Scollnik, D.P.M.; Sun, C. Modeling with Weibull-Pareto models. N. Am. Actuar. J. 2012, 16, 260–272. [Google Scholar] [CrossRef]
- Calderín-Ojeda, E. On the Composite Weibull–Burr Model to describe claim data. Commun. Stat. Case Stud. Data Anal. Appl. 2015, 1, 59–69. [Google Scholar] [CrossRef]
- Calderín-Ojeda, E.; Kwok, C.F.K. Modeling claims data with composite Stoppa models. Scand. Actuar. J. 2016, 9, 817–836. [Google Scholar] [CrossRef]
- Acerbi, C.; Tasche, D. On the coherence of expected shortfall. J. Bank. Financ. 2002, 26, 1487–1503. [Google Scholar] [CrossRef]



{kind=link}
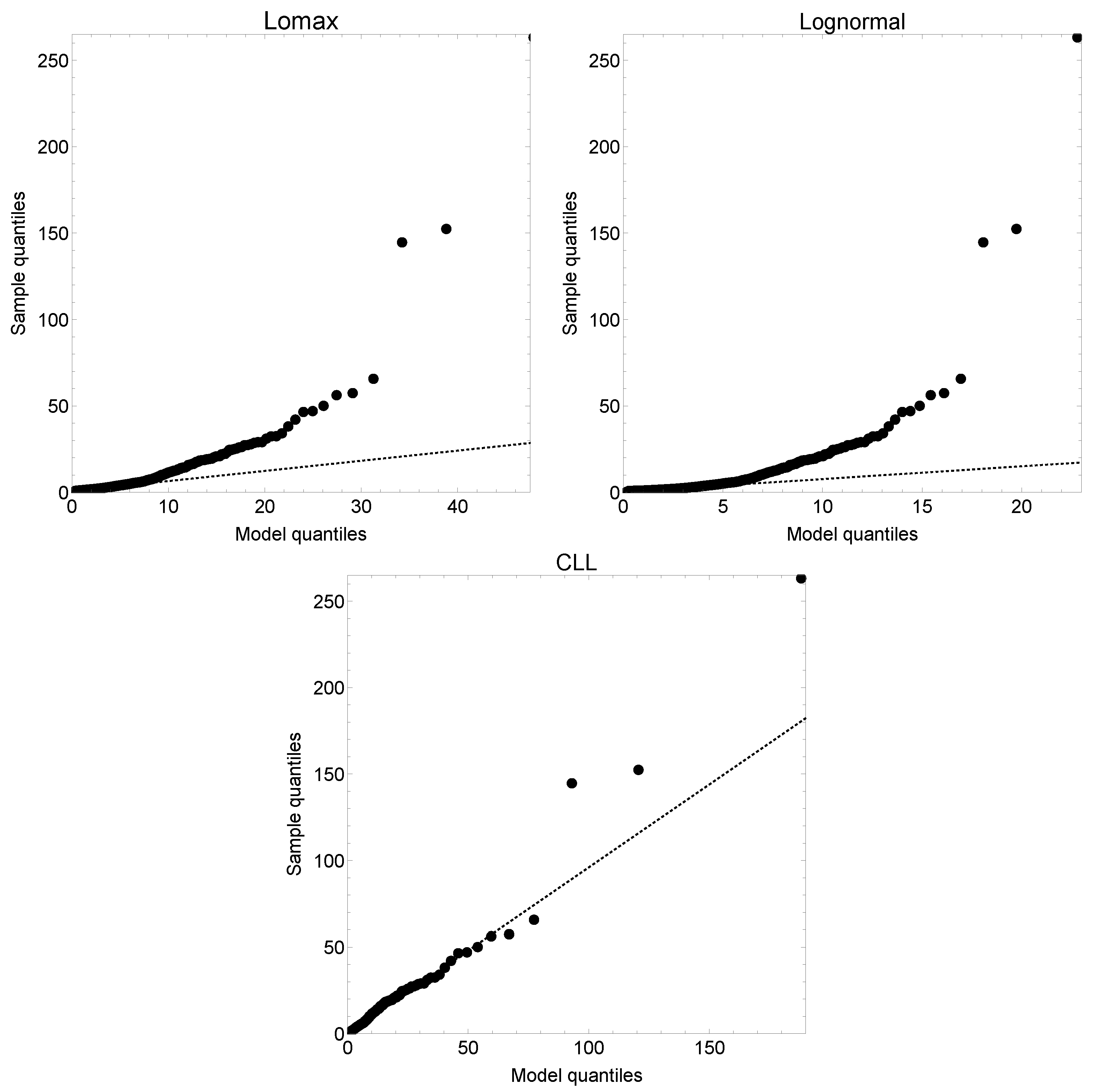{kind=link}
| Risk Level | ||||||
|---|---|---|---|---|---|---|
| Risk | Measure | 0.90 | 0.925 | 0.95 | 0.975 | 0.99 |
| Empirical | VaR | 5.080 | 5.989 | 8.454 | 14.395 | 24.970 |
| TVaR | 14.271 | 17.172 | 22.222 | 33.450 | 55.587 | |
| Model | 5.165 | 6.281 | 8.248 | 13.052 | 23.741 | |
| 14.971 | 18.068 | 23.524 | 36.848 | 66.492 | ||
| 3.333 | 3.951 | 5.043 | 7.723 | 13.707 | ||
| 2.515 | 3.152 | 4.270 | 6.988 | 13.015 | ||
| 3.478 | 4.290 | 5.718 | 9.198 | 16.927 | ||
| 3.938 | 4.684 | 6.001 | 9.229 | 16.428 | ||
| 3.165 | 3.928 | 5.267 | 8.527 | 15.765 | ||
| 7.210 | 8.759 | 11.485 | 18.136 | 32.922 | ||
| 4.211 | 5.017 | 6.440 | 9.923 | 17.688 | ||
| 3.476 | 4.297 | 5.738 | 9.251 | 17.051 | ||
| 9.150 | 11.092 | 14.510 | 22.851 | 41.398 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calderín-Ojeda, E.; Gómez-Déniz, E.; Vázquez-Polo, F.J. Conditional Tail Expectation and Premium Calculation under Asymmetric Loss. Axioms 2023, 12, 496. https://doi.org/10.3390/axioms12050496
Calderín-Ojeda E, Gómez-Déniz E, Vázquez-Polo FJ. Conditional Tail Expectation and Premium Calculation under Asymmetric Loss. Axioms. 2023; 12(5):496. https://doi.org/10.3390/axioms12050496
Chicago/Turabian StyleCalderín-Ojeda, Enrique, Emilio Gómez-Déniz, and Francisco J. Vázquez-Polo. 2023. "Conditional Tail Expectation and Premium Calculation under Asymmetric Loss" Axioms 12, no. 5: 496. https://doi.org/10.3390/axioms12050496
APA StyleCalderín-Ojeda, E., Gómez-Déniz, E., & Vázquez-Polo, F. J. (2023). Conditional Tail Expectation and Premium Calculation under Asymmetric Loss. Axioms, 12(5), 496. https://doi.org/10.3390/axioms12050496