1. Introduction
Partial differential equations (PDEs) are ubiquitous and fundamental to understanding and modeling the complexities of natural phenomena. From mathematics to physics to economics and beyond, PDEs play a critical role in virtually all fields of engineering and science [
1,
2,
3]. Through their mathematical representation of physical phenomena, PDEs provide a powerful means of gaining insight into complex systems, enabling researchers and engineers to predict behavior and uncover hidden relationships. However, solving PDEs can be a daunting and challenging task. The complexity of these equations often requires sophisticated numerical methods that must balance accuracy and efficiency while solving high-dimensional PDEs. Despite these challenges, PDEs remain a cornerstone of modern science, enabling researchers to unlock discoveries and technological advancements across disciplines.
As numerical and computational techniques continue to rapidly develop, the study of PDEs has become increasingly vital. In recent years, advances in numerical methods and high-performance computing techniques have made it possible to solve complex PDEs more accurately and efficiently than ever before. These new tools can precisely solve specific problems across a broader range of equations while simultaneously computing data faster, reducing the time and cost of solving pending problems. Moreover, these new techniques have allowed researchers to gain deeper insights into the physical meaning behind PDEs, enabling them to revisit natural phenomena from fresh perspectives and explore those that prove challenging to explain by traditional methods. This has led to groundbreaking research discoveries and innovations in various fields of science and engineering.
Machine learning methods [
4,
5], particularly in the area of artificial neural networks (ANNs) [
6,
7], have piqued considerable interest in recent years due to their potential to solve differential equations. ANNs are well-known for their exceptional approximation capabilities and have emerged as a promising alternative to traditional algorithms [
8]. These methods have a significantly smaller memory footprint and generate numerical solutions that are both closed and continuous over the integration domain without requiring interpolation. ANNs have been applied to differential equations, including ordinary differential equations (ODEs) [
9,
10], PDEs [
11,
12], and stochastic differential equations (SDEs) [
13,
14], making them a valuable tool for researchers and engineers alike. Neural networks have become a powerful and versatile tool for solving differential equations due to their ability to learn intricate mappings from input–output data, further cementing their role as a critical component in the machine learning fields.
In recent years, the application of neural networks in solving differential equations has gained significant attention in the scientific community. One prominent model is the neural ordinary differential equations, which approximates the derivative of an unknown solution using neural networks, parameterizing the derivatives of the hidden states of the network with the help of the differential equation, thus creating a new type of neural network [
15]. Another approach is the deep Galerkin method [
16], which uses neural networks to approximate the solution of the differential equation in a bid to minimize error. Gorikhovskii et al. [
17] introduced a practical approach for solving ODEs using neural networks in the TensorFlow machine-learning framework. In addition, Huang et al. [
18] introduce an additive self-attention mechanism to the numerical solution of differential equations based on the dynamical system perspective of the residual neural network.
By utilizing neural network functions to approximate the solutions, neural networks have also been used to solve PDEs. The physics-informed neural network (PINN) method uses the underlying physics of the problem to incorporate constraints into the solution of the neural network, resulting in successful applications to various PDEs such as the Burgers and Poisson equations [
19]. Compared to traditional numerical methods, PINNs offer several advantages, including higher accuracy and more efficient computation. Berg et al. [
20] introduced a new deep learning-based approach to solve PDEs on complex geometries. They use a feed-forward neural network and an unconstrained gradient-based optimization method to predict PDE solutions. Furthermore, Another exciting development in the field of neural networks and PDEs is the use of convolutional neural networks (CNNs). Ruthotto et al. [
21] used a CNN to learn to solve elliptic PDEs and incorporated a residual block structure to improve network performance. Quan et al. [
22] presented an innovative approach to addressing the challenge of solving diffusion PDEs, by introducing a novel learning method built on the foundation of the extreme learning machine algorithm. By leveraging this advanced technique, the parameters of the neural network are precisely calculated by solving a linear system of equations. Furthermore, the loss function is ingeniously constructed from three crucial components: the PDE, initial conditions, and boundary conditions. Tang et al. [
23] demonstrate through numerical cases that the proposed depth adaptive sampling (DAS-PINNs) method can be used for solving PDEs. Overall, the advancements made in the domain of neural networks have revolutionized how we approach solving complex PDEs in unimaginable ways. These developments suggest that neural networks are a promising tool for solving complex PDEs and that there is great potential for further research and innovation in this area.
This paper proposes a novel approach for solving the Burgers–Huxley equation, which uses a neural network based on the Lie series in the Lie groups of differential equations, adding initial or boundary value terms to the loss function to approximate the solution of the equation by minimization. Slavova et al. [
24] constructed a cellular neural network model to study the Burgers–Huxley equation. Shagun et al. [
25] employed a feed-forward neural network to solve the Burgers-Huxley equation and investigated the impact of the number of training points on the accuracy of the solution. Kumar et al. [
26] proposed a deep learning algorithm based on the deep Galerkin method for solving the Burgers–Huxley equation, which outperformed traditional numerical methods. These studies demonstrate the potential of neural networks in solving differential equations. Nonetheless, it is simple to ignore the underlying nature of these equations, in other words, to fail to capture the nonlinear nature of the equations, which is essential to comprehend the behavior of complex systems. To address this issue, the aim of our proposed method is to approximate the solution of the differential equations by combining the Lie series in Lie groups of differential equations and the power of neural networks. Our proposed method accurately simulates the physical behavior of complicated systems, and the first part of the constructed solution has well captured the nonlinear nature of the equation while reducing the parameter cost of the subsequent neural network and by minimizing the loss function, making the solution converge quickly by introducing initial or boundary value terms required for exact approximation. This work demonstrates the effectiveness of combining neural networks with Lie series to solve differential equations and provides insights into the physical behavior of complex dynamical systems.
The essay is set up as follows. The basic framework and fundamental theory of neural network algorithms based on Lie series in Lie groups of differential equations are introduced in
Section 2. The specific steps for the Lie-series-based neural network method to solve the Burgers–Huxley equation are described in
Section 3. The method is also applied to the Burgers–Fisher equation and the Huxley equation. Summary and outlook are presented in
Section 4.
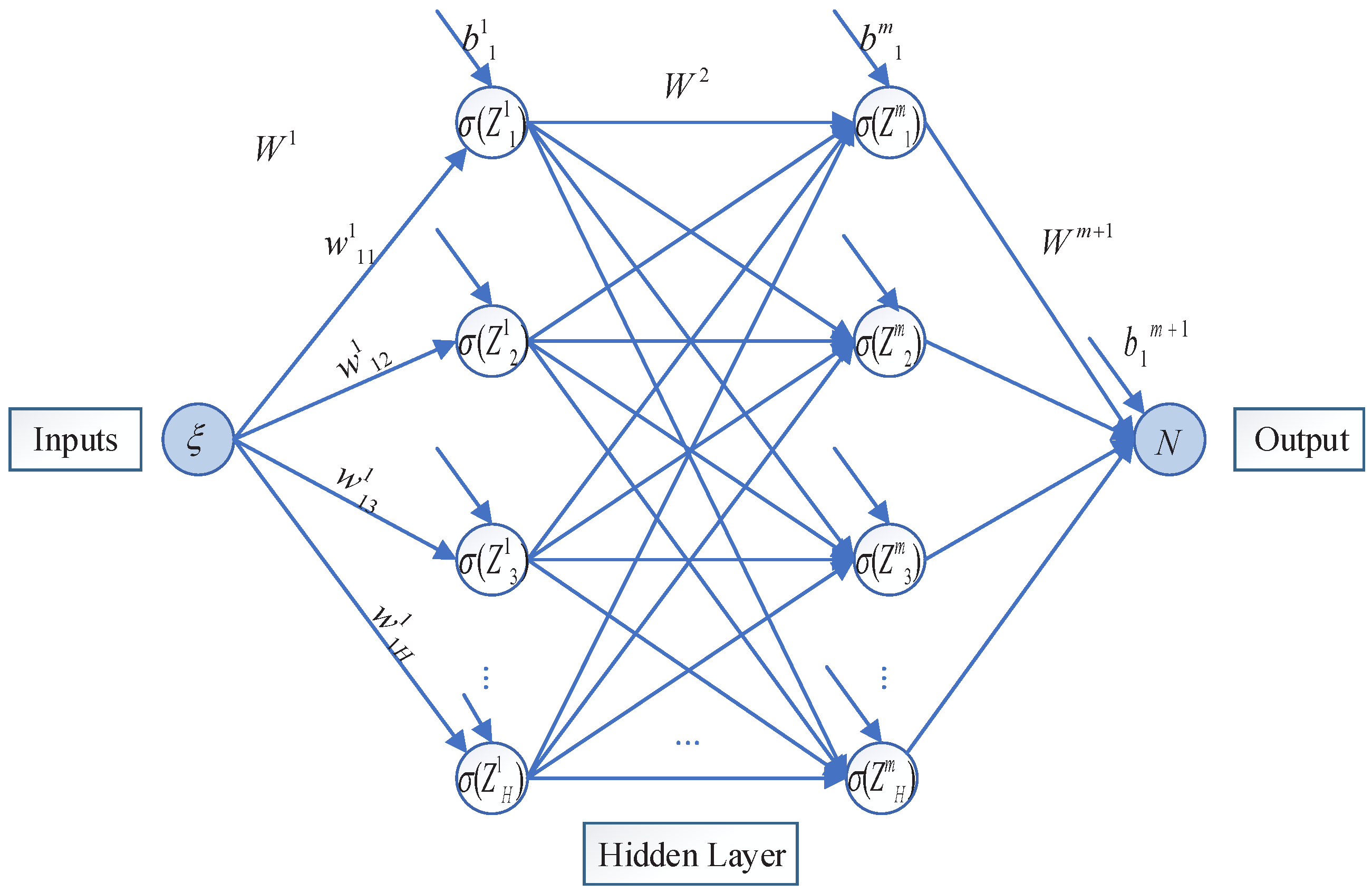
3. Lie-Series-Based Neural Network Algorithm for Solving Burgers Huxley Equation
The generalized Burgers–Huxley equation [
30] is a nonlinear PDE that describes the propagation of electrical impulses in excitable media, such as nerve and muscle cells. It is a widely used mathematical framework for modeling intricate dynamical phenomena and has been instrumental in advancing research across multiple domains including physics, biology, economics, and ecology. The equation takes the form
where
,
,
,
are constants and
is a positive constant.
When
,
,
,
,
, the Burgers–Huxley equation is as follows:
The exact solution of (
12) is
. Using the traveling wave transform
, problem (
12) is transformed into an ODE,
. Naturally, it is transformed into the form of the following system of ODEs
with
,
and initial values
,
.
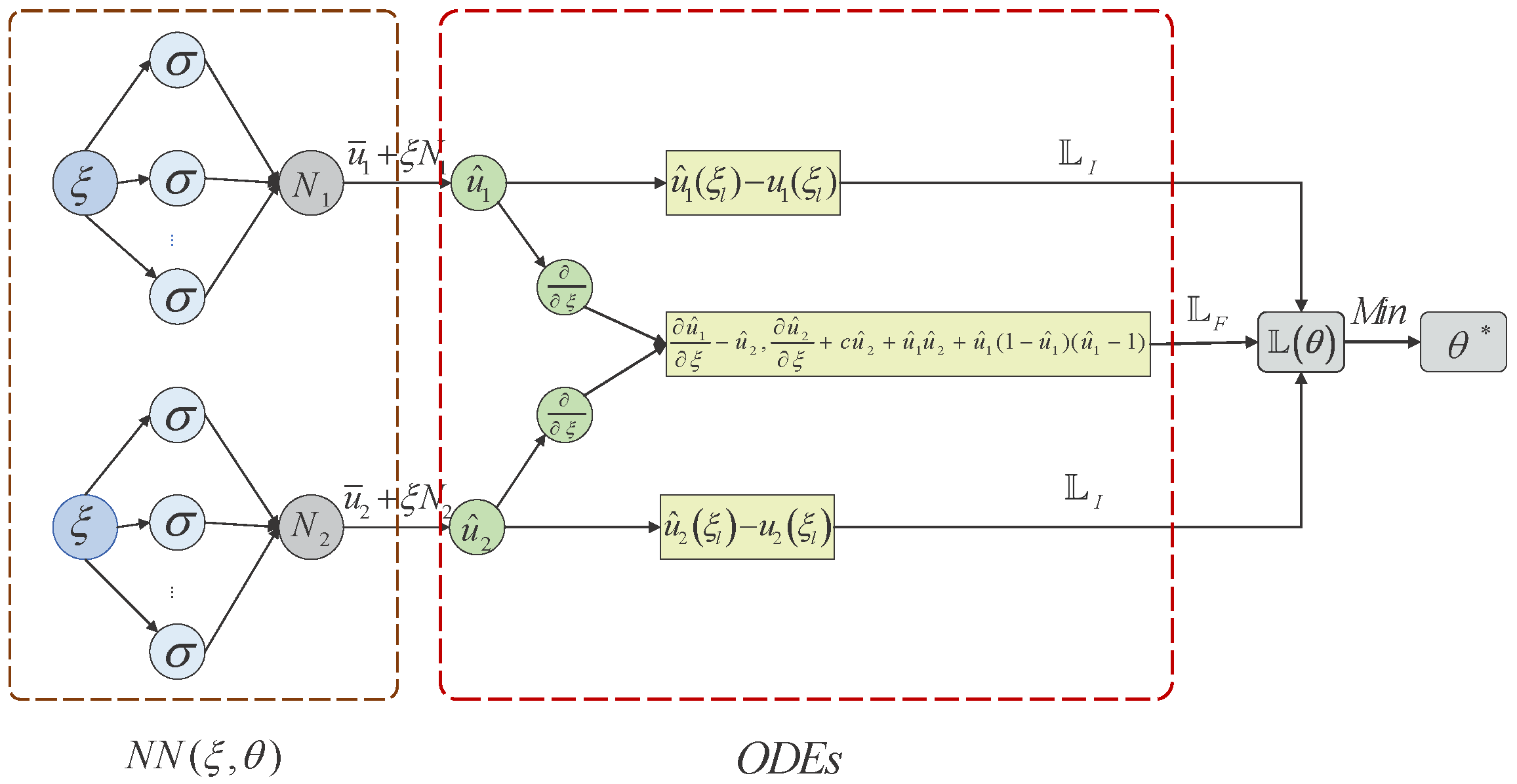
In this study, we address the problem of solving the Burgers–Huxley equation using a Lie-series-based neural network algorithm. The operator
of (
13) is chosen as
, and the solution of the corresponding initial value problem is
,
. The solution of this part has been able to capture the nonlinear nature of the equation within a certain range, as shown in
Figure 3. To minimize the loss function
, we employ two structurally identical neural networks and boundary value terms, each with 30 neurons in a single hidden layer, and the input
is 100 training points spaced equally in the interval
, making
as close as possible to the exact solution
of the equation. The generalization ability of the neural network was confirmed in 120 test points at equidistant intervals of
. The Lie-series-based neural network algorithm solves the Burgers–Huxley equation model as shown in
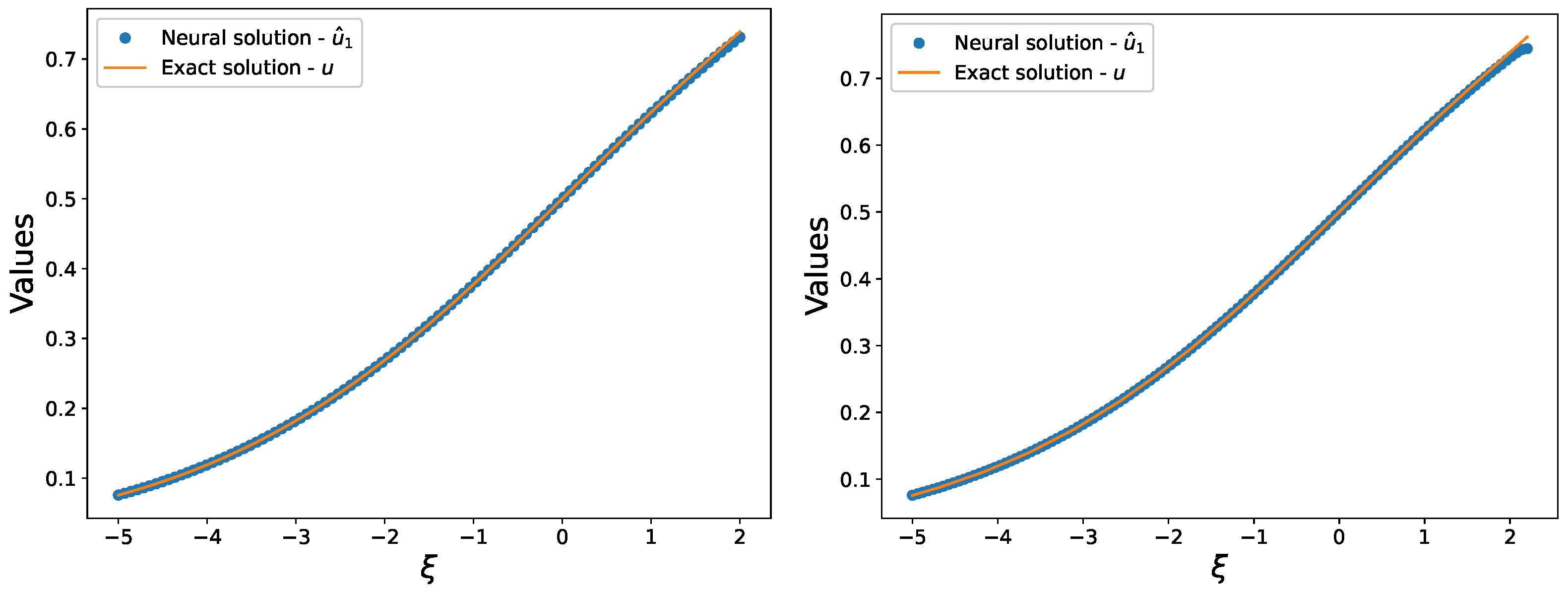
Figure 4. Furthermore, we demonstrate the ability of neural networks to fit the training and test sets in
Figure 5. By plotting the loss function
against the number of iterations in
Figure 6, where
, and
,
. Some 1100 iterations later,
.
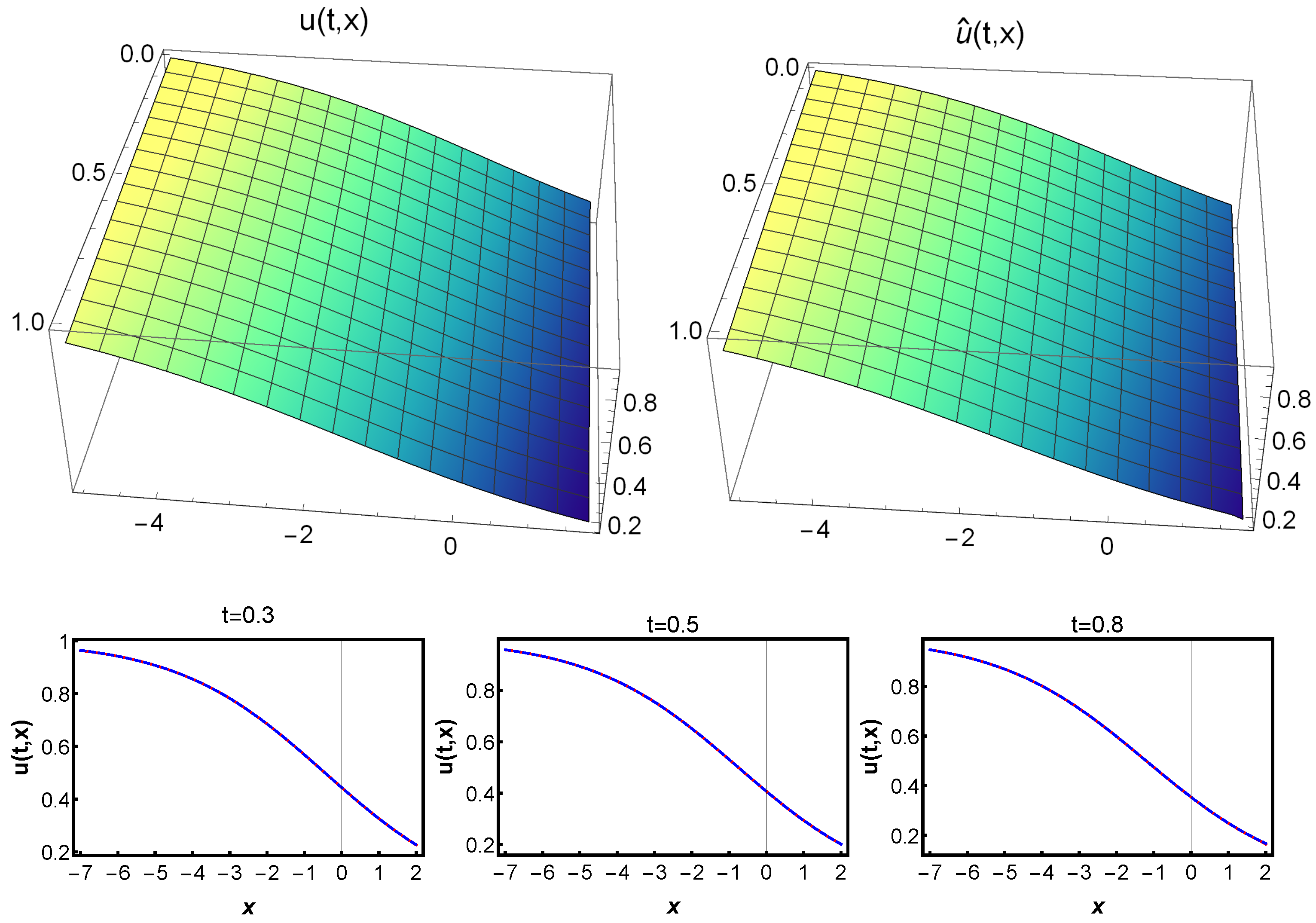
We compare the solution
containing the neural network training and the exact solution
in the interval
,
in the upper panel of
Figure 7. Additionally, the lower panel displays the behavior of the solution at
,
,
, demonstrating the solitary wave solution of the Burgers–Huxley equation. The contour plots for solution
and the exact solution
are shown in
Figure 8, further illustrating the accuracy of our proposed algorithm.
To verify the validity and generality of our proposed equation, the method was applied to two classical equations, the Burgers–Fisher, and the Huxley equations. For this purpose, we performed a thorough analysis and obtained strong results that proved the validity of our method. Specifically, when
,
,
,
,
, the Burgers–Fisher equation is as follows:
The exact solution of (
14) is
. Similarly, using the traveling wave transform
, problem (
14) is transformed into an ODE,
, with initial value
,
. Transformation of ODEs into the form of a system of differential equations,
where
,
, and initial values
,
. The operator
of (
15),
is chosen as
, the predicted solution
,
, where the structure of the neural network is a single hidden layer containing 30 neurons with inputs
of equidistant intervals of 100 training points and test points are 120 points of the interval
, and the training results are shown in
Figure 9. As shown in
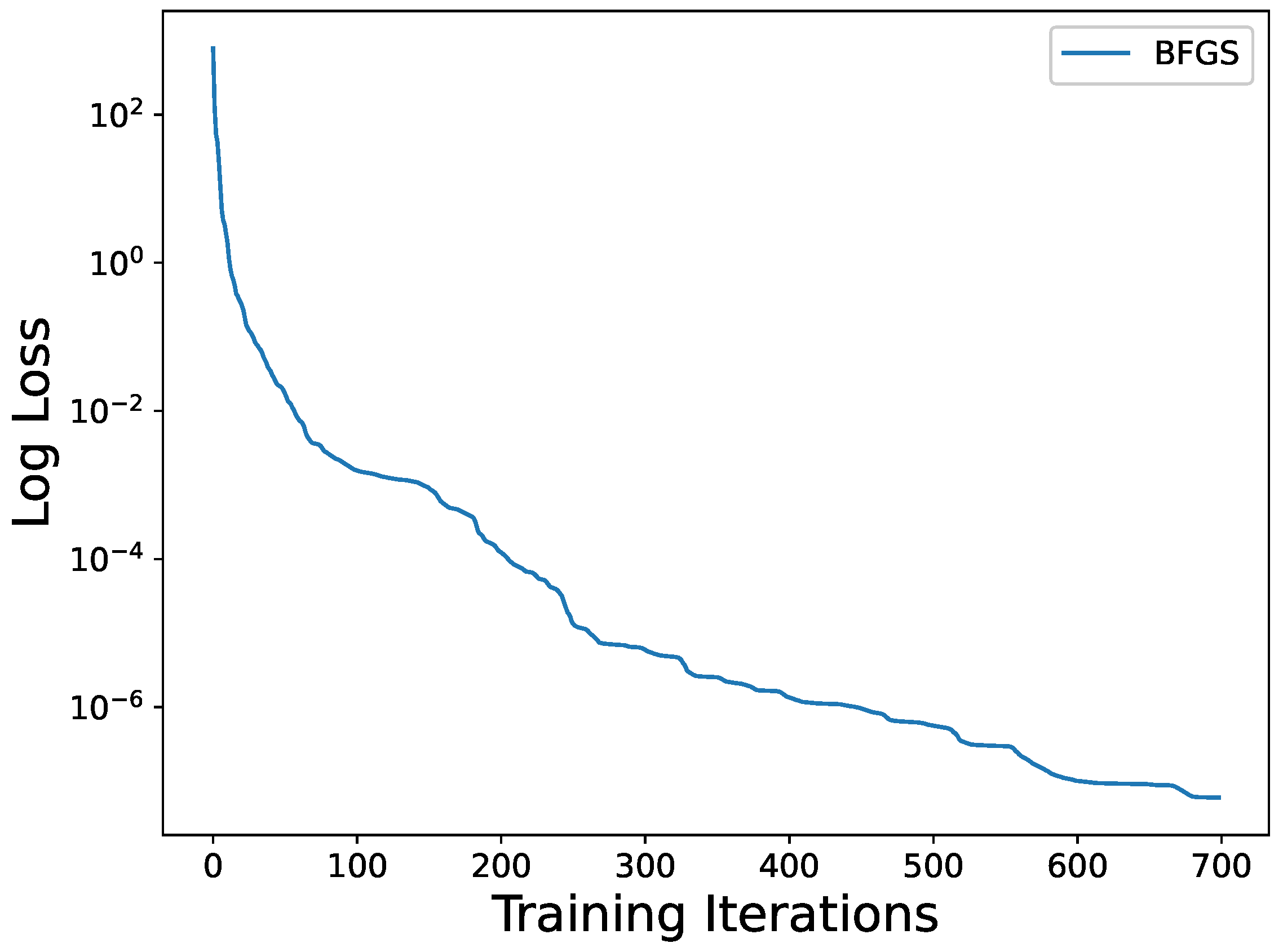
Figure 10, our method achieves an impressive performance with the loss function
reaches
in about 700 iterations. This exceptional result again illustrates that the solution of the
part of our proposed method captures the nonlinear nature of the solution, thereby reducing the computational cost associated with additional parameters which are evident from
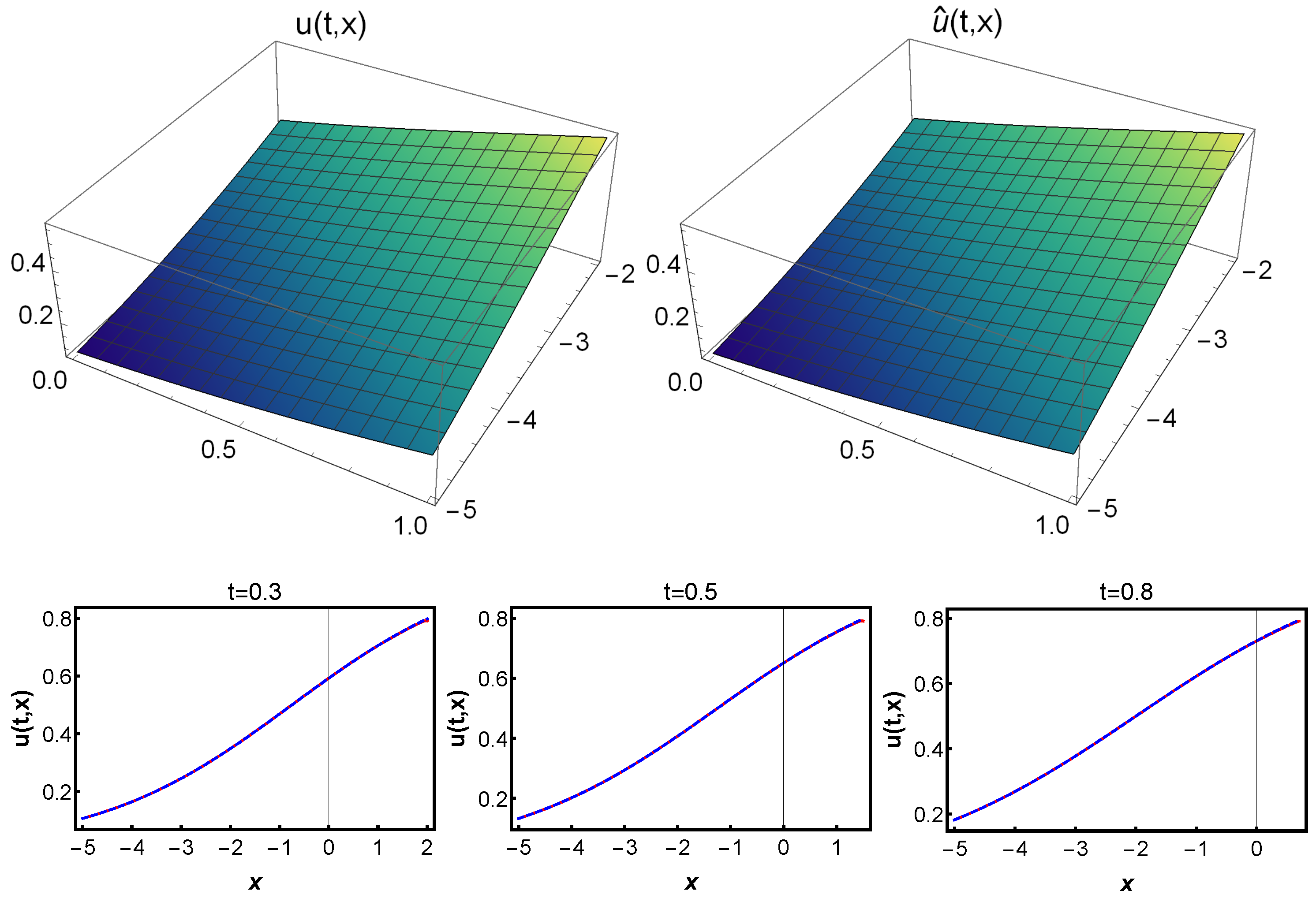
Figure 11. In addition, we provide a three-dimensional representation of the dynamics of the predicted solution
with the exact solution
in the interval
and
, as shown in
Figure 12.
We investigate the Huxley equation under the conditions where
,
,
,
,
. The equations are as follows:
The exact solution of (
16) is
. Similarly, using the traveling wave transform
, problem (
16) is transformed into an ODE,
. It is transformed into the following differential equation form
where initial values
,
, and
, it is clear that
,
. In the case of
, the system of differential equations
,
, the initial values are
and
, this time
,
.
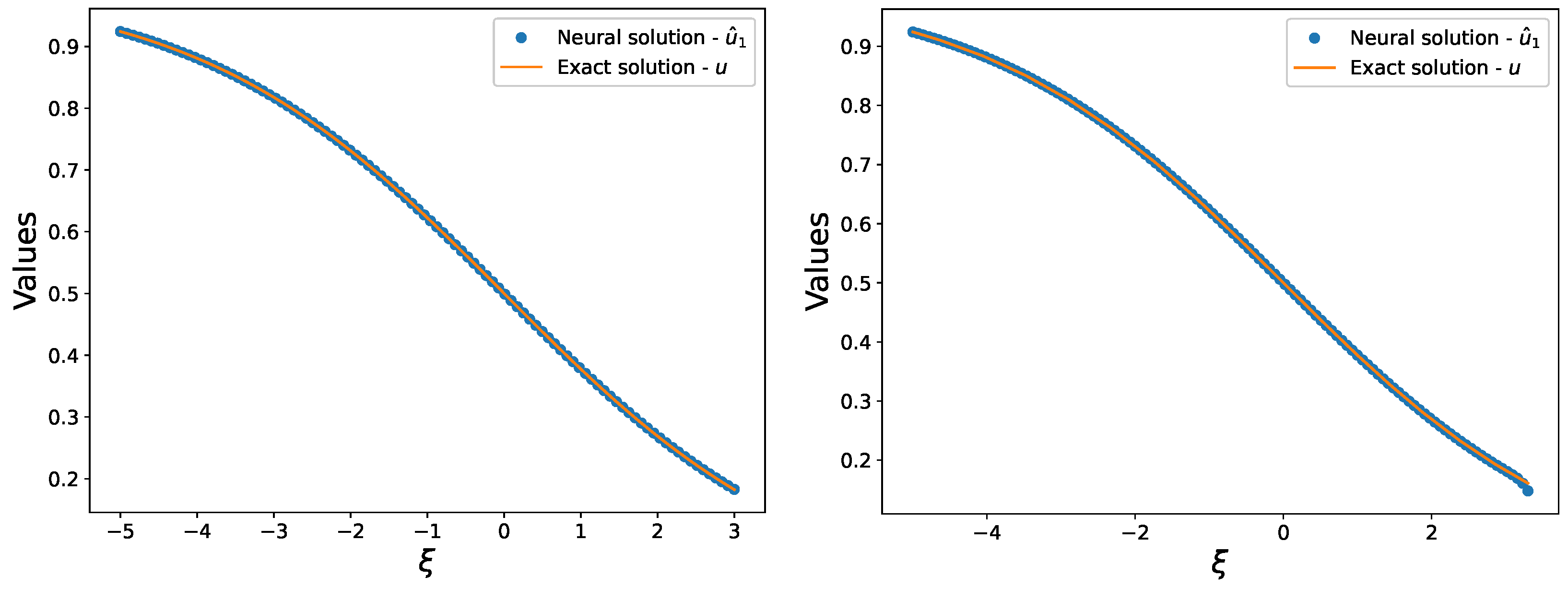
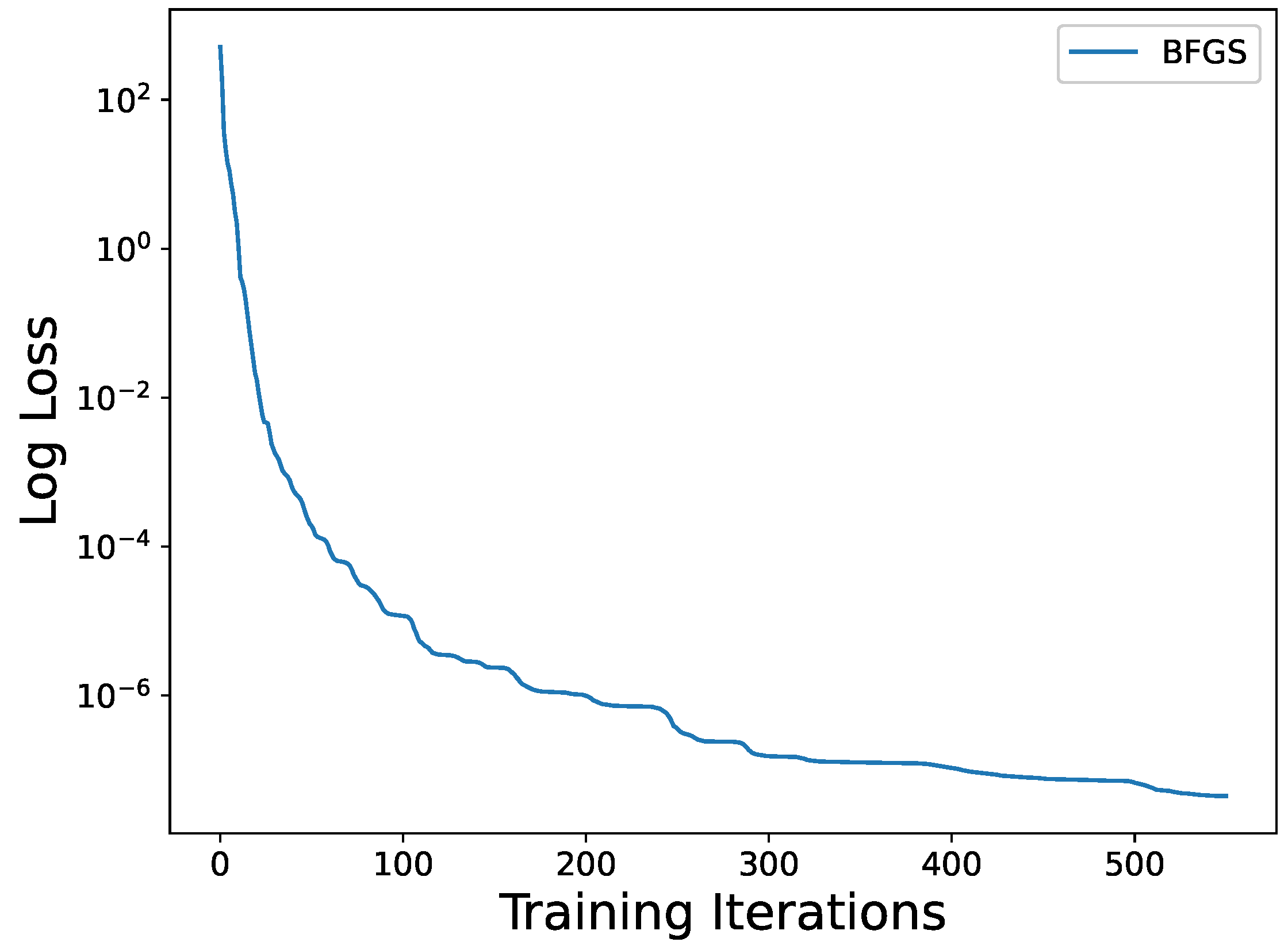
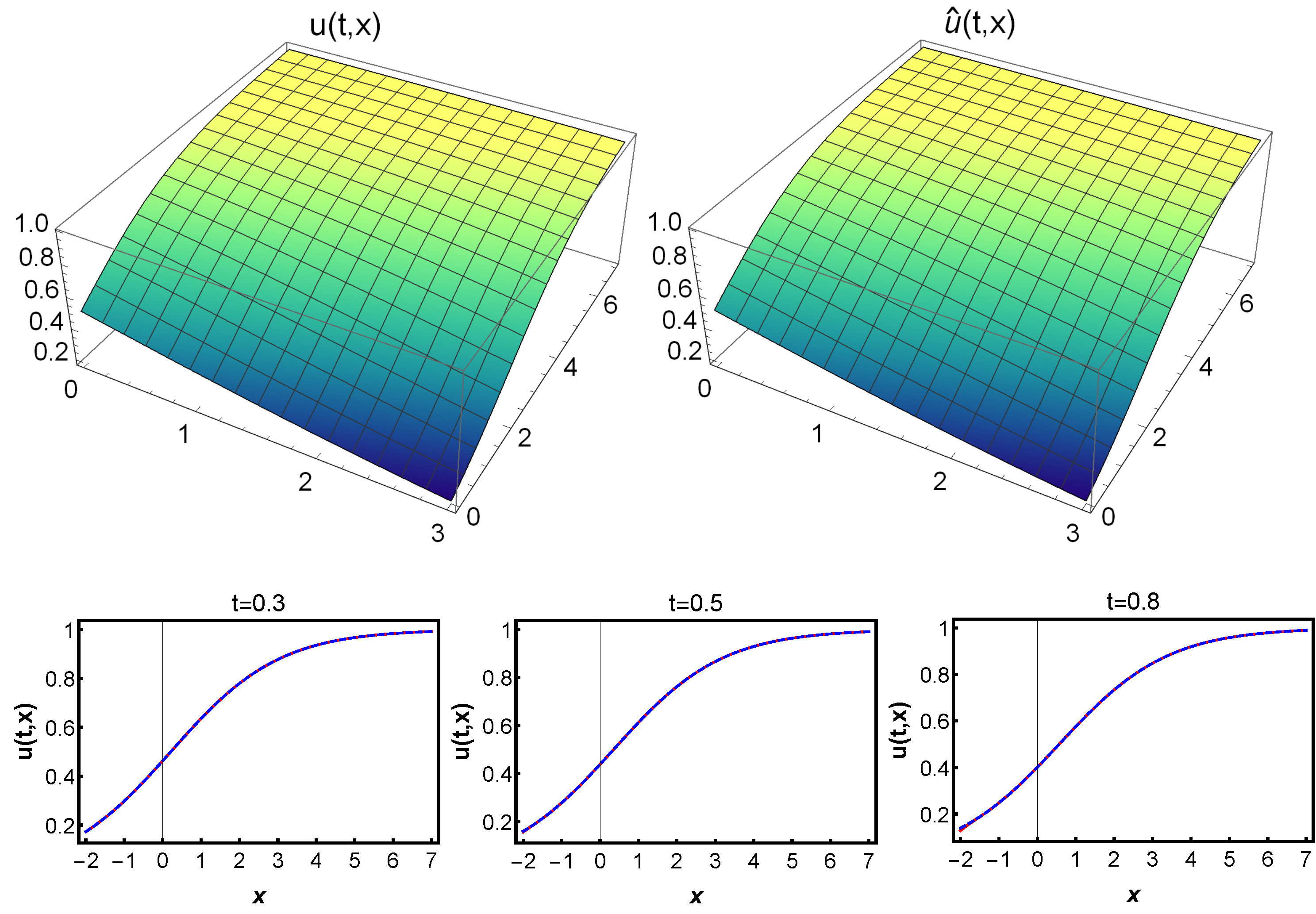
For predicting the solution
and
, the same neural network with two single hidden layers containing 30 neurons with the same structure is trained by optimization technique Broyden–Fletcher–Goldfarb–Shanno (BFGS) minimizes the Loss function
. The input
is the interval
equidistantly spaced by 100 points. The test set is the 150 points in the interval
. As shown in
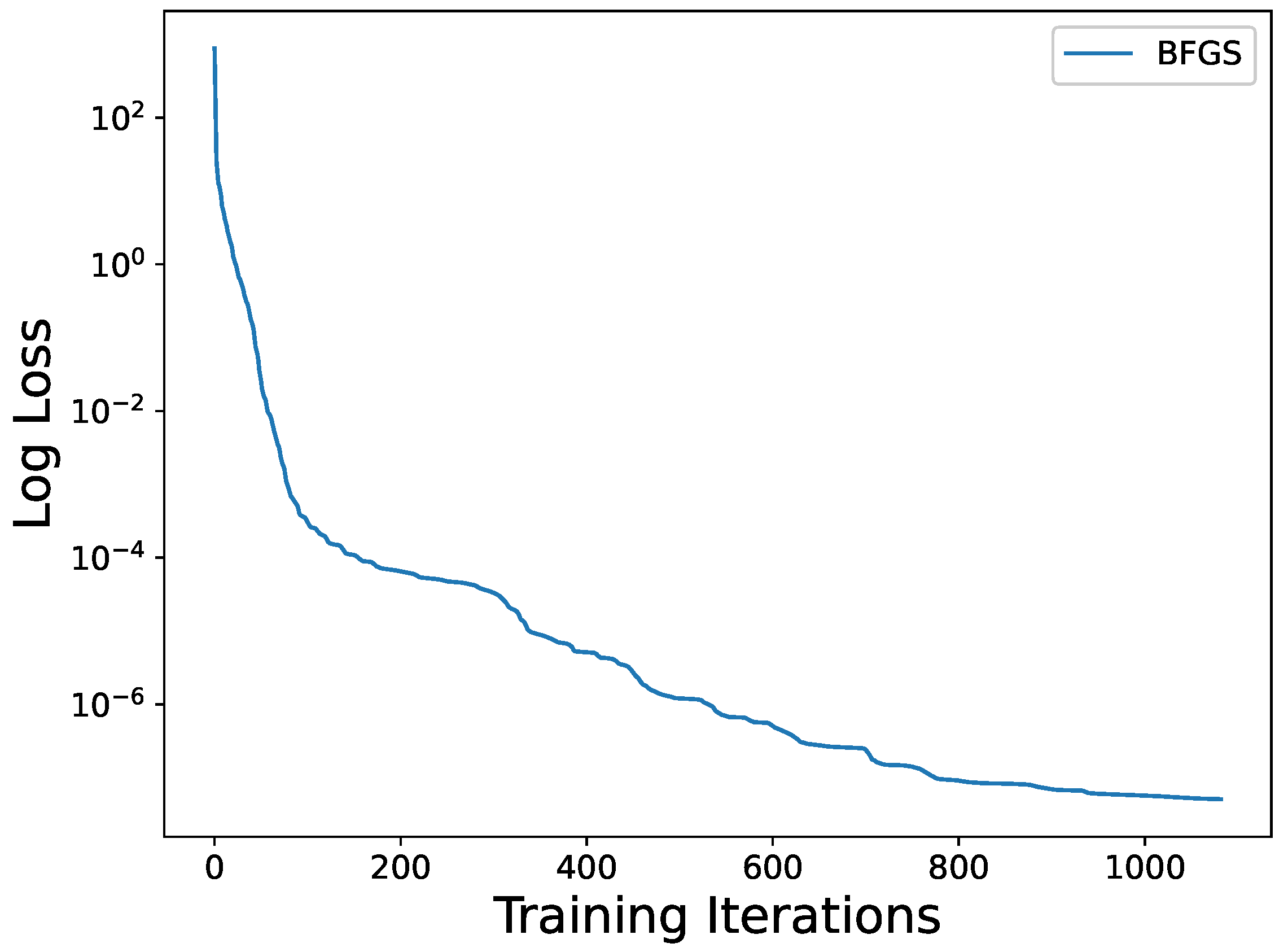
Figure 13, our proposed method produced excellent predictions for both the trained predicted and exact solutions. The variation of the loss function throughout the process is depicted in
Figure 14, and it can be observed that the loss function decreased remarkably during training.
Figure 15 shows the dynamics of
with the exact solution
, when
is substituted into
and the predicted solution
compared with the exact solution
at
. The contour plot in
Figure 16 provides a more visualization of the network solution
compared to the exact solution
.
4. Discussion and Conclusions
The exponential growth of information data has resulted in limited data becoming a significant issue in various fields, especially in data-driven applications. Addressing this challenge has become a critical area of research in recent times. To contribute towards finding solutions to this problem, this paper proposes a novel method for resolving the Burgers-Huxley equation using a neural network based on Lie series in Lie groups of differential equations, which is an emerging field with great potential in solving complex problems. To the best of our knowledge, this study represents the first time the Burgers-Huxley equation has been solved using a Lie-series-based neural network algorithm. In physics, engineering, and biology, the Burgers–Huxley equation is a well-known mathematical model that is frequently utilized. Our novel approach offers a unique perspective on solving this equation by adding boundary or initial value items to the loss function, which leads to more accurate predictions and a better understanding of the underlying system. This research opens up new avenues for further exploration of the Lie-series-based neural network algorithm, specifically regarding its applications to other complex models beyond the Burgers–Huxley equation.
In this study, we present a novel method for obtaining a differentiable closed analytical form to provide an effective foundation for further research. The proposed approach is straightforward to use and evaluate. To verify the effectiveness of the suggested method, we applied it to two classic models of the Burgers–Fisher and Huxley equations that have well-known exact solutions. The proposed algorithm exhibits remarkable potential in capturing the nonlinear nature of equations and accelerating the computation process of neural networks. The performance of our method is demonstrated in
Figure 3 and
Figure 11, which show how the proposed algorithm can capture the nonlinear behavior of the equations more effectively and speed up the computation of subsequent neural networks. To further evaluate the effectiveness of the proposed technique, we plotted the relationship between the loss function and the number of iterations in
Figure 6,
Figure 10 and
Figure 14. Our results indicate that under the influence of the Lie series in Lie groups of differential equations, our algorithm can converge quickly and achieve more precise solutions with fewer data. Moreover, the accuracy of the obtained solutions is significant, and the generalization ability of the neural network is demonstrated by its ability to maintain high accuracy even outside the training domain, as shown in
Figure 5,
Figure 9 and
Figure 13. We compared the performance of each neural network using small parameters (60 weight parameters and 31 bias parameters) with the exact solution to the problem. Our results highlight that the addition of the Lie series in Lie groups of differential equations algorithm remarkably enhances the ability of the neural network to solve a given equation.
Undoubtedly, the proposed method has several limitations that need to be carefully considered. Firstly, the method requires the transformation of PDEs into ODEs before applying the suggested algorithm. Although the results obtained after this transformation are preliminary, they provide useful insights for researchers. Additionally, an inverse transformation must be employed to produce the final solution , taking into account the range of values for various variables. The choice of the operator may also influence the outcomes. Secondly, the current study only addresses nonlinear diffusion issues of the type , and the suitability of the technique was assessed via the computation of the loss function. Therefore, the applicability of the method to other types of non-linear PDEs is yet to be investigated, and it might require further adjustments to accommodate such problems. Despite some inherent challenges, our work offers a promising strategy for solving complex mathematical models using neural network algorithms based on Lie series. The computational performance of the proposed algorithm is noteworthy, achieving high solution accuracy at a relatively low time and parameter cost. In light of these findings, it is worth considering the prospect of applying this algorithm to financial modeling, where accurate predictions can have a significant impact.
Moving forward, there is ample scope for extending and improving the proposed algorithm further. Future research could explore how to optimize the performance of the algorithm by addressing its limitations and weaknesses for nonlinear PDE problems. For example, choosing a different neural network framework, CNN or recurrent neural network, etc., may improve the efficiency and accuracy of the method. Additionally, expanding the method’s applicability beyond nonlinear diffusion issues may also yield valuable insights into other areas of mathematical modeling.
In summary, we believe that our work presents an exciting avenue for future research. By building upon our findings and addressing the limitations of the proposed algorithm, we can develop more sophisticated techniques for solving complex mathematical models in finance and other areas. Solving the above problems is the main goal of our next research work.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















