1. Introduction
Binary outcome data are widespread in medical applications. We often encounter the observation of paired organs (e.g., eyes, ears, and arms) in medical clinical studies. If only one of the patients’ paired organs is diseased, one organ’s response outcomes are not cured or cured; we call this unilateral data. Previous researchers have achieved outstanding achievements on statistical inferences about the unilateral data [
1,
2,
3,
4]. If both patients’ paired organs are diseased, the treatment responses of paired organs are none, one, and both cured; this is called bilateral data. Generally, the paired organs of patients may be correlated. Unlike the unilateral case, correlation should be considered in bilateral data to avoid biased results. For such correlated paired data, researchers have proposed many probabilistic models, including Rosner’s model [
5], Dallal’s model [
6], and Donner’s model [
7]. Under the above models, various statistical methods have been proposed for testing the equality of proportions in bilateral data [
8,
9,
10,
11]. Among these models, Rosner’s model is the basis and has been widely studied [
12,
13,
14].
In practice, we usually obtain both data types described above. Due to certain factors, some patients have only one eye studied, while others provide information on both eyes. For example, Mandel et al. [
15] conducted a double-blind randomized clinical trial to treat acute otitis media (OME). In this trial, each child suffered either unilateral or bilateral tympanocentesis and was randomly assigned to receive treatment with Amoxicillin or Cefaclor. Under the same treatment method, we divided children into three groups by age. In the Amoxicillin treatment, 97 children of different ages were classified into three types: less than 2 years old, 2 to 5 years old, and 6 years old or older. After 14 days of treatment,
Table 1 shows that each child underwent no, unilateral or bilateral OME, and was assigned into three groups according to age: <2, 2–5, and ≥6 years. Pei et al. [
16] observed that the previous methods of studying unilateral or bilateral data are unsuitable for their combination. They proposed new asymptotical ways to test the equality of two proportions under such data. This topic is an emerging problem, and related research is less available [
17,
18,
19,
20]. Therefore, studying unilateral and bilateral data under Rosner’s model is imperative.
To compare the treatment of Amoxicillin in
Table 1, the common measures are risk difference (RD), relative risk ratio (RR), and odds ratio (OR). The RD is an essential and straightforward measure that reflects the underlying risk without treatment and the risk reduction associated with treatment. The relative risk of a treatment is the ratio of risks between the treatment and control groups. It is generally more meaningful to use relative effect measures for summarizing the evidence and absolute measures. The odds ratio aims to look at associations rather than differences. Please note that RR and OR are related; this paper compares the relative risk ratios under Rosner’s model.
Multiple groups can often occur in many different treatments or over time in medical trials [
21]. It is natural to compare several treatment groups with a control group. Mou and Li [
22] considered a homogeneity test of risk differences on many-to-one bilateral data in a study. Schaarschmidt et al. [
23] studied asymptotic simultaneous confidence intervals (SCIs) for many-to-one comparisons on binary proportion. Yang et al. [
24] proposed asymptotic SCI construction for many-to-one comparisons of proportion differences adjusting for multiplicity and correlation. To date, relatively few papers have studied unilateral and bilateral data. Most research on unilateral or bilateral data mainly focuses on homogeneity testing for risk differences in stratified data, and on the study of equality of multiple groups of proportions. When the cure rates are low, and the difference between groups is slight, using the relative risk ratio to judge is more appropriate. There is insufficient research into statistical inference on many-to-one procedures of combined unilateral and bilateral data. Under Rosner’s model, the paper aims to study homogeneity tests of many-to-one relative risk ratios in unilateral and bilateral data. The hypothesis proposed by Ma et al. [
17] is a particular case of this type. Moreover, the method proposed in this paper can also be applied to unilateral or bilateral data, and the corresponding test statistics are given. We arrange the rest of the work as follows. In
Section 2, we introduce the data structure and Rosner’s model, and estimate the unknown parameters by algorithms.
Section 3 constructs the likelihood ratio, score, and Wald-type statistics. In
Section 4, through Monte Carlo simulations, we compare the performance of these test statistics in terms of the empirical type-I error rates and power. We provide a real example to illustrate our proposed method in
Section 5 and conclude in
Section 6.
2. Data Structure and Probability Distribution
In an ophthalmologic study, let
be the number of patients with
l response(s) for bilateral data. For unilateral data, let
be the number of patients with
l response in the
ith group for
.
Table 2 shows the combined unilateral and bilateral data.
Let
be the total number of patients with bilateral data in the
ith group, and
be the total number of patients with exactly
response(s). For the unilateral case,
is the total number of patients with binary data in the
ith group, and
is the total number of patients with
response. We have
For the bilateral data, let
be a random variable representing the number of patients with
l response in the
ith group, which has a trinomial distribution. In addition,
is the corresponding probability. Define
,
,
and
. Then, the probability density of
is
for
. For the unilateral data, let
be a random variable that represents the number of patients with
l response in the
ith group and follows a binomial distribution, and
be the corresponding probability. We denote
,
,
and
. Then, the probability density of
is
for
.
Suppose
in bilateral data if the
kth
eye of the
jth individual
is cured in the
ith group and 0 otherwise. Define
if the eye of the
jth patient
has a response in the
ith group, and 0 otherwise for the unilateral patients. Under Rosner’s model, we propose a probability model of unilateral and bilateral data as
where
R is a constant. If
, the two organs of a patient are completely independent. They are completely dependent when
.
From the probabilities of Equation (
1), it is easy to derive
,
,
,
and
for
. Since
and
are independent random variables, the likelihood function is expressed by
where
. Thus, we have the log-likelihood as
where
is a constant.
Denote
and
. We aim to test whether the many-to-one relative risk ratios are identical and give the hypotheses as
Let
and
be the global maximum likelihood estimators (MLEs) of unknown parameters
and
R, respectively. Global MLEs are the solutions to the equations
where
Denote
and
. We simplify the first equation of (
2) as the following 4th-order polynomial equations
where
The
th update of
R is obtained by the Newton–Raphson algorithm
where
Remark 1. In the above algorithm, if , the global MLEs of and R correspond to the results of bilateral data in Ma et al. [14]. If , it is easy to obtain the global MLEs in unilateral data. Suppose that
under
, the log-likelihood is rewritten by
where
Let
,
and
be the constrained MLEs of
,
and
R under the null hypothesis
. We calculate the constrained MLEs of
and
R from
However, there is no close solution for Equation (
3) when
(see
Appendix A.1). Given initial values
,
and
, the Fisher scoring algorithm is introduced to obtain the
th updates of
and
R as follows
where
is a
Fisher information matrix (see
Appendix A.1), and
Remark 2. Under , if , we can obtain the constrained MLEs of Rosner’s model through Equation (4) in bilateral data. If , the constrained MLEs of and δ are directly given by 4. Monte Carlo Simulation Studies
In this section, we compare the performance of the statistics for the homogeneity test of risk ratios. In addition, we selected two evaluation indexes of type-I error rates (TIEs) and power. The fitting results of the homogeneity test are calculated when the significance level
. The TIE is the probability of rejecting the null hypothesis when it is true. Each parameter set is performed 10,000 times based on the null hypothesis. The empirical TIEs is calculated as the number rejecting the null hypothesis divided by 10,000 at a significance level
. According to Tang et al. [
12], a test is liberal if the empirical TIEs is larger than 0.06, conservative if the empirical TIE rate is less than 0.04, and robust otherwise at the significance level
.
First, we investigate the performance of TIEs under different parameter settings. Take the sample sizes , . Let for balanced designs and for unbalanced designs. Take , , and under the hypothesis . Then, we calculate the empirical TIEs of all proposed test statistics. For each scenario, 10,000 replicates are randomly generated under the null hypothesis .
Table 3,
Table 4 and
Table 5 show the empirical TIEs based on three statistics under all configurations for
and 5, respectively. The left side of the table shows the balanced design results. We provide the unbalanced design results on the right of each table. Let
,
is equivalent to
. This situation can be seen as the proportional homogeneity test proposed by Ma and Wang [
17]. In
Table 3, the likelihood ratio and score tests are robust for the balanced design and small sample size, while the Wald-type statistic is liberal. The Wald-type test tends to be robust when the sample size becomes larger. In the unbalanced design, let
, the Wald-type statistic is liberal when
and
. Take
, and the Wald-type test performs better. The result of the Wald-type statistic becomes more robust when the total sample sizes increase.
Table 4 displays that the Wald-type test is more liberal for the unbalanced design. The likelihood ratio and score tests are more robust than the Wald-type tests for the balanced design, especially for a small sample size. In
Table 5, the Wald-type test is worse for small sample sizes in unbalanced scenarios, similar to balanced ones.
In
Table 3,
Table 4 and
Table 5, the score test
and likelihood ratio test
are more robust than Wald-type test
in terms of the TIEs. The Wald-type statistic is liberal in small sample scenarios and becomes more liberal as the number of groups increases. There is no significant difference in the performance of the three statistics when the total sample sizes of the balanced and unbalanced groups are the same. As the values of
m or
n increase, we can observe that the Wald-type statistic tends to be robust. The TIEs of all three tests grow closer if the sample size increases.
The above results are obtained for given multiple parameter values. In practice, there are more possibilities for parameter values. To further compare these test statistics, we randomly choose 1000 sets of parameters
according to the constrained ranges of parameters for
and
under
. A total of 10,000 replicates are randomly generated for each configuration to calculate the type-I error rates.
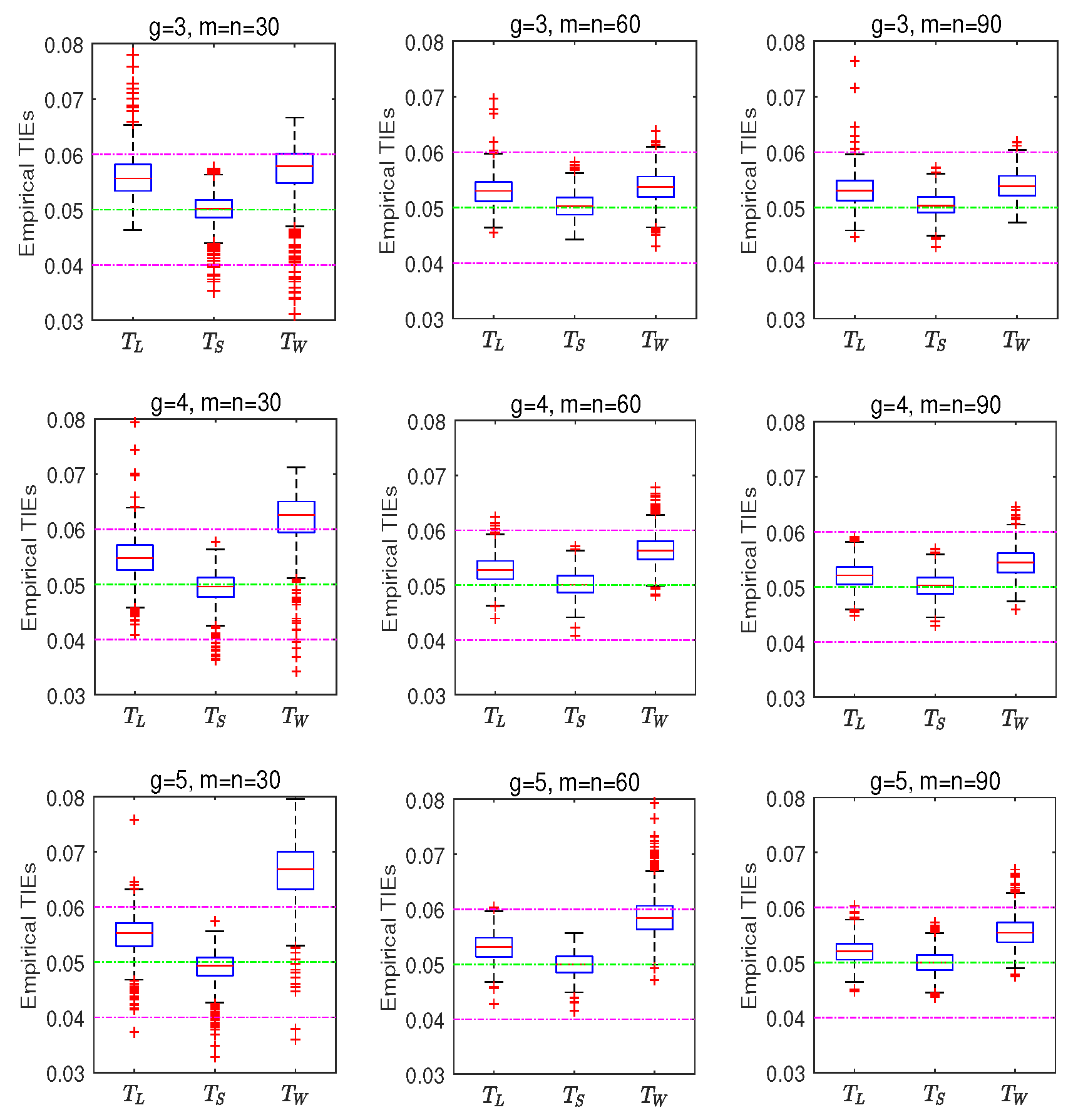
Figure 1 shows the box plots of the empirical TIEs. The results display that the three statistics become more robust under the same number of groups as the sample size increases. As the number of groups grows, the Wald-type test becomes more liberal while the likelihood ratio and score tests become more robust. Overall, the score test is more robust in the sense that the TIE of it is close to the significant level
regardless of sample size and the number of groups.
Next, we compare and summarize the performance of proposed test statistics in terms of power under different parameter settings. To be specific, we consider the balanced and unbalanced settings, respectively. In addition, we also take the same parameter
as we do for empirical type-I error rates. Under the hypothesis
, the parameter settings satisfy:
for
. Similarly, we randomly select 10,000 replicates from the alternative hypothesis for each parameter setting and calculate the empirical power by the number of rejections of the alternative hypothesis divided by 10,000. The simulated results are presented in
Table 6 and
Table 7, respectively. At the same number of groups, when we fix parameter
R, the empirical powers will become larger as
increases. However, given a fixed parameter
, the empirical powers do not change much as
R increases. In
Table 7, the powers obtained with sample size of
are greater than that obtained with
. The results show that these powers of the three test statistics are very close under the same parameter settings. The empirical power will increase with the sample size or the number of groups.
We further study the power of three statistics changes as the given parameters change. Under hypothesis
, let
,
and
for
.
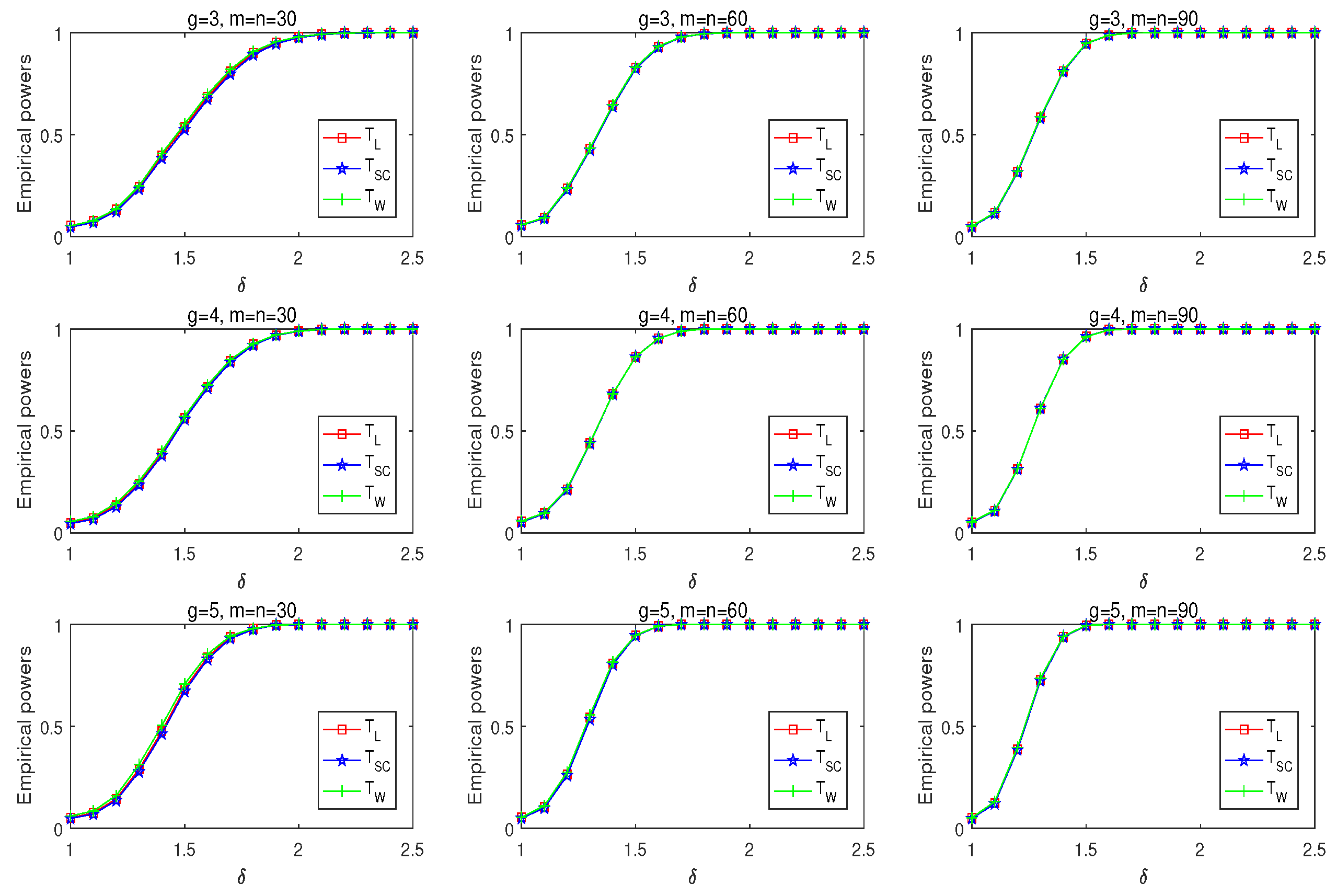
Figure 2 reveals the empirical powers of three tests for given parameters
. The performances of the three statistics are close in terms of powers. When
is around 1, the resulting power is around 0.05. This is because the difference between the null and alternative hypotheses is small. The increasing
leads to a significant power increase. The powers increase in the same number of groups as the sample size increases. The three statistics have good power performance when the number of groups increases.
According to the simulation results, the score statistic and LR test have satisfactory results in the TIEs. However, the score statistics are more robust than the other two for small sample-size scenarios. The powers of the three tests are very close. Thus, we recommend it for the homogeneity test about a many-to-one comparison of relative risk ratios.
5. A Real Example
In this section, we review the double-blinded randomized clinical trial of treating acute otitis media (OME) from Mandel et al. [
15] to illustrate the proposed methods. In
Table 1,
and
in the first group; for the second group,
and
;
and
in the third group. Under Rosner’s model, an interesting test is whether there is a significant difference in many-to-one risk ratios. Thus, give the hypotheses as
.
Let
, then we use the formula in this article to obtain global MLEs and constrained MLEs. Global and constrained MLEs are given in
Table 8. The results show a correlation between paired organs. The estimated relative risk ratios under
is 0.6709, and global relative risk ratios can be calculated as
in
Table 9. The values of
and
are 5.3330, 3.8502, and 7.4055. At significance level
, the values are bigger than the 95 percentile of the chi-square distribution with one degree of freedom, and
p values of statistics are less than 0.05. Therefore, it provides stronger evidence to reject the null hypothesis
. It means that there were significant differences in relative risk ratios between groups. We can find that if
is less than 1, then children who were less than two years old had the highest cure rates in Amoxicillin-treated. Mandel et al. [
15] find that children less than 2 years old had more OME. This is consistent with our results.
6. Conclusions
This paper introduces three statistics for testing the homogeneity of many-to-one relative risk ratios for bilateral and unilateral data under Rosner’s model. Then, we use a fourth-order polynomial and the Newton–Raphson algorithm to estimate the global maximum likelihood estimate. In addition, we obtain constrained MLEs under through the Fisher scoring method. Three statistics are proposed in bilateral and unilateral data. Moreover, we also offer global MLEs, constrained MLEs, and three statistics for unilateral and bilateral data, respectively. The Monte Carlo simulation was carried out with different parameter settings.
Based on the simulation results, the score test is more robust than the likelihood ratio and the Wald-type test regarding the TIEs and has sufficient power. The powers of the proposed three tests grow closer as the sample size becomes more significant. By comparison, the Wald-type test is better than the score test and the likelihood ratio test in terms of power. However, the Wald-type test has liberal type-I error rates under a small sample size. The results of the Wald-type test behave worse, especially when the number of groups is more extensive and the sample size is small. The score test performs well regardless of the number of groups and sample size. The score test is recommended for unilateral and bilateral data for the above reasons.
In future work, we will focus on other statistical problems of the many-to-one relative risk ratios for unilateral and bilateral data, such as confidence intervals.







{kind=link}
{kind=link}