Abstract
Environmental security is among the top priorities worldwide, and there are many difficulties in this area. The reason for this is a painful subject for society and healthcare systems. Multidimensional sensitivity analysis is fundamental in the process of validating the accuracy and reliability of large-scale computational models of air pollution. In this paper, we present an improved version of the well-known Sobol sequence, which shows a significant improvement over the best available existing sequences in the measurement of the sensitivity indices of the digital ecosystem under consideration. We performed a complicated comparison with the best available low-discrepancy sequences for multidimensional sensitivity analysis to study the model’s output with respect to variations in the input emissions of anthropogenic pollutants and to evaluate the rates of several chemical reactions. Our results, which are presented in this paper through a sensitivity analysis, will play an extremely important multi-sided role.
Keywords:
air pollution modeling; sensitivity analysis; multidimensional integrals; Monte Carlo methods; digital sequences MSC:
60J22; 62P12; 65C05; 68W20
1. Introduction
The purpose of our work is in the field of environmental security [1,2], since this is one of the key areas worldwide. By definition, a sensitivity analysis (SA) is an investigation of how much the uncertainty in the input data of a model is apportioned in the accuracy of the output results [3,4,5,6,7]; see Figure 1. Multidimensional SA [8,9,10,11,12] is a very challenging task when modeling, but it is often the key tool for studying a complex phenomenon [13,14,15,16,17].
Figure 1.
Methodology for performing sensitivity analysis.
The main problem in SA is the evaluation of the total sensitivity indices (SIs) [18,19,20,21]. The mathematical formulation for estimating the SIs is represented by a set of multidimensional integrals (MIs) [22,23,24,25]. The Monte Carlo (MC) and quasi-Monte Carlo (QMC) methods are the best tools for solving the MIs [22,26,27,28,29,30,31]. For a more clear explanation of the objectives in this paper, one should check [32,33,34].
The input data for SA were obtained with a large-scale model of the long-range transport of pollutants in the air—the Unified Danish Eulerian Model (UNI-DEM) [35,36,37,38,39]. UNI-DEM is also a basic tool and important tool for the creation of a digital twin, namely, Digital Air (see [40]).
By definition, the model can be introduced with a model function [41]:
The concept of the Sobol approach consists of the following representation of and a constant [41]:
The above description is noted as the ANOVA representation of if [41]:
The quantities
are called total and partial variances [41]. The same is true for the total variance:
The Sobol global SIs [6,41] are determined by:
Then, the total sensitivity index (TSI) of the input parameter is determined by [42]:
where is the jth-order SI for .
According to the definition in [43], when , the quantity is called the main effect of ; if , are called two-way interactions (second-order SIs); if , are called three-way interactions (third-order SIs), and so on. In this study, we are interested in the main effects and the two-way interactions.
The TSI of the output variance for an input parameter is represented as: ; see [18]. With this, we show that multidimensional SA using Sobol’s approach is turned into a problem of evaluating MIs [44].
In this paper, we aim to suggest implementations for the fast and accurate evaluation of the sensitivity indices. As mentioned earlier, the problem of SA is transformed into a multidimensional integration task that is approached by using novel quasi-Monte Carlo methods, which are compared with the best available algorithms in an application to large-scale modeling of atmospheric pollution. The methods are described in the next section, followed by a thorough analysis of the computational results.
2. Methods and Algorithms
Consider the following multidimensional problem:
where and .
In the simplest possible MC approach, “Crude”, we introduce the random variable , for which
and the random points are independent realizations of the random point with a probability density function and . The Crude MC approach for the integral I is defined as [22]:
Let for and let be the representation of in base .
Then, the discrepancy (star discrepancy) of the set is defined [22,24]:
where .
For the one-dimensional quasi-random number sequence, we introduce the radical inverse sequence [22,23]:
The van der Corput sequence [45] is obtained when . Now, the multidimensional quasi-random number sequence is defined as: where the bases are all relatively prime: , where denotes the ith prime.
Now, the Halton sequence [46,47] is defined as:
where , designates the i-th prime, and denotes the set of permutations on
The standard M-dimensional Hammersley sequence [48], which is based on N samples, is simply composed of a first component of successive fractions paired with one-dimensional van der Corput sequences by using the first primes as bases. More precisely, if are the first prime numbers, then the Hammersley sequence with N points in s dimensions is given by
The Faure sequence [49,50,51] is given by:
The Sobol sequence [52,53,54] is defined by:
where are the set of permutations on every subsequent points of the van der Corput sequence, defined by when .
In binary, for the Sobol sequence, we have that: , where is the set of directional numbers [55].
For the QMC algorithms, based on the Halton, Faure and Sobol sequences, it is known that the corresponding discrepancy is:
According to several important works [56,57,58,59], the convergence rate for the scrambling algorithms essentially improves the convergence rate for the unscrambled nets [56,57,58,59], which is . The scrambling itself is based on the randomization of a single digit at each iteration. Let
be quasi-random numbers in , and let
be the corresponding scrambled version of the point . Let every be rewritten in base b as
with K being the number of digits for scrambling. For the scrambled Halton sequence HaltonScr, we apply a permutation of the radical inverse coefficients, which is obtained by applying a reverse-radix operation to each of the possible coefficient values [60]. For the scrambled Sobol sequence SobolScr, we use a random linear scramble blended with a random digital shift [61].
Now, we will introduce a super-convergent modified Sobol sequence SobolBurkardt based on the INSOBL and GOSOBL routines in ACM TOMS Algorithm 647 and ACM TOMS Algorithm 659, as well as a Burkardt modification [52,53,54,55,62,63,64,65,66,67]. The original code can only compute the next element of the sequence. Our modification allows the user to specify the index of the desired element. The novelty is that this is the first time that the SobolBurkardt algorithm has been applied for a multidimensional sensitivity analysis of this important digital ecosystem.
3. Results and Discussion
In this section, the advanced stochastic algorithms described above (Crude, Sobol, Halton, SobolScr, HaltonScr, SobolBurkardt, Hammersley, and Faure) are applied to sensitivity studies with respect to emission levels (SSREL) and with respect to some chemical reaction rates (SSRCRR) of varying concentrations of UNI-DEM pollutants [68,69]. We use the following notations: EQ refers to the estimated quantity, RV refers to the reference value, RE refers to the relative error, and AE refers to the approximate evaluation.
For SSREL, we will investigate an SA of the model output (in terms of the mean monthly concentrations of several important pollutants—in our case, the pollutant is ammonia in Milan) with respect to a variation in the input emissions from anthropogenic pollutants, which consist of four components, :
The output of the model is the mean monthly concentration of the following three pollutants:
—ozone ();
—ammonia ();
—ammonium sulfate and ammonium nitrate ().
For SSEL, the results for the REs for the AE of the and when using Crude, Sobol, Halton, SobolScr, HaltonScr, SobolBurkardt, Hammersley, Faure are shown in Table 1, Table 2, Table 3, Table 4, Table 5 and Table 6, respectively. The quantity is represented by a four-dimensional integral, whereas the rest are represented by eight-dimensional integrals.

Table 1.
RE for the AE of .
Table 2.
RE for the AE of .
Table 3.
RV for the SIs.
Table 4.
RE for the SIs for .
Table 5.
RE for the SIs for .
Table 6.
RE for the SIs for .
In the case of SSRCRR, we will investigate the ozone concentrations in Genova according to the rates of variation of these chemical reactions, which are ## (time-dependent) and (time-independent) in the CBM-IV scheme [36]:
In the case of SSRCRR, the results for the REs for the AE of and when using Crude, Sobol, Halton, SobolScr, HaltonScr, SobolBurkardt, Hammersley, and Faure are shown in Table 7, Table 8, Table 9, Table 10, Table 11 and Table 12, respectively. As in the first case study, the quantity is represented by a six-dimensional integral, whereas the rest are represented by twelve-dimensional integrals.
Table 7.
RE for the AE of .
Table 8.
RE for the AE of .
Table 9.
RV for the SIs.
Table 10.
RE for the SIs for .
Table 11.
RE for the SIs for .
Table 12.
RE for the SIs for .
In the case of SSREL, one may observe the following. In Table 1, for the model function , the best algorithm for all numbers of samples is HaltonScr, followed by SobolBurkardt. For , for the total variance , the best algorithm is SobolBurkardt, followed by the Halton sequence—see the results in Table 2. However, for and , the Halton sequence produces slightly better results—see Table 2. The behavior of the algorithm can also be seen in Figure 2. The RVs for the first and total SIs are presented in Table 3. From Table 4, Table 5 and Table 6, one can conclude that for all first-order SIs and TSIs, the best algorithm is SobolBurkardt, followed by HaltonScr and the Halton sequence. It is important that the scrambling procedure improves the results of the Sobol and Halton sequences by at least one order for most of the cases—see the values for and in Table 6. In [42], it was pointed out that having the smallest possible SIs is the most important aspect of a model. In our case, these are and —see Table 3. For them, SobolBurkardt significantly improved upon the results of the other sequences, and one can also see that the Hammersley and Faure sequences performed better than the Crude algorithm, as expected.
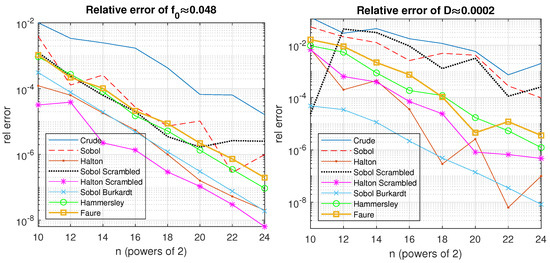
Figure 2.
RE for the AE of and .
The performance of the algorithms in the case of SSREL can be generalized in this way: The algorithm that we implemented, SobolBurkardt, held the smallest relative errors for all SIs; the scrambled Halton and original Halton sequences were the next, followed by the Hammersley, Faure, scrambled Sobol, and Sobol algorithms; the worst was the plain algorithm.
In the case of SSRCRR, the following observations could be made. In Table 7, for the model function , the best algorithm for all numbers of samples except , , and was HaltonScr; for , the best algorithm was SobolBurkardt, and in the other two cases, the best algorithm was the Hammersley sequence. The RVs of the first- and second-order SIs and TSIs are given in Table 9. For all numbers of samples except , for the total variance D, the best algorithm was SobolBurkardt—see the results in Table 8. However, for , the scrambled Halton sequence produced results that was one order better than our SobolBurkardt algorithm. The behavior of the algorithm can also be seen in Figure 3. For a low number of samples, , as shown in Table 10, the Halton sequence was better than our SobolBurkardt algorithm for and , and the scrambled Halton sequence was better than our algorithm for the total SIs , , and . As previously mentioned, having the smallest possible SIs is the most important aspect of a model. Here, these were , , and —see Table 9. For them, our SobolBurkardt implementation performed better than the other algorithms. However, for larger numbers of samples, as shown in Table 11 and Table 12, one can conclude that for all first-order SIs, second-order SIs, and TSIs, the best algorithm was SobolBurkardt, followed by the HaltonScr and scrambled Sobol sequence algorithms. It is important that the scrambling procedure significantly improved the results of the Sobol and Halton sequences for some of the cases—see the values for and in Table 12. For all of the cases, the Hammersley and Faure sequences performed better than the Crude algorithm, as expected.
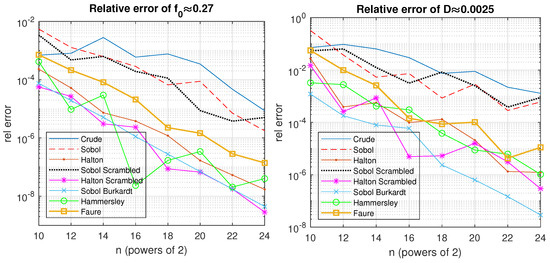
Figure 3.
RE for the AE of and .
The performance of the algorithms in the case of SSREL can be generalized in such a way: The SobolBurkardt algorithm that we implemented held the smallest REs for all SIs; the scrambled Halton and the original Halton sequence are the next, followed by the Hammersley, Faure, scrambled Sobol, and Sobol algorithms, and the worst was the Crude algorithm.
The overall conclusion is that the implemented SobolBurkardt algorithm was the best approach among the benchmarked algorithms, and the values of the relative errors showed its supremacy over the majority of the existing methods when applied to multidimensional air pollution sensitivity analysis.
4. Conclusions
Our paper treats a very important area of environmental safety. The computational accuracy and numerical efficiency in terms of the relative error for one of the best available stochastic methods for multidimensional integration were studied for the sensitivity of the Unified Danish Eulerian model’s output to find the variations in the rate constants of chosen chemical reactions and the variations in selected input emissions of anthropogenic pollutants. We implemented an improved Sobol sequence based on a Burkardt modification, which dramatically improved upon the results produced by other low-discrepancy sequences that have been used until now to perform multidimensional sensitivity analyses of this model. In addition, for the first time, we included the Faure and Hammersley sequences in our comparison; they have never before been compared with the Sobol and Halton sequences for this particular and very important large-scale air pollution model.
When compared with the results reported in recent studies, our results show significant improvements in terms of the accuracy and lower computational costs of the suggested algorithm. Our improvements when calculating the sensitivity indices of the model will significantly help provide a more accurate evaluation of agricultural losses. The most important effect of our results will be our contribution to the estimation of harmful emissions’ effects on human health.
There are many ways in which this investigation could be extended. Some of the straightforward ones include exploring other quasi-sequences with possibly better properties, scrambling and shifting the existing sequences, and creating new ones from suitable generation vectors or generation matrices.
Author Contributions
Conceptualization, V.T.; methodology, V.T.; software, V.T. and S.G.; validation, V.T. and S.G.; formal analysis, V.T.; investigation, V.T.; resources, V.T.; data curation, V.T. and S.G.; writing—original draft preparation, V.T. and S.G.; writing—review and editing, I.D., V.T. and S.G.; visualization, V.T. and S.G.; supervision, I.D. and V.T.; project administration, I.D. and V.T.; funding acquisition, I.D. All authors have read and agreed to the published version of the manuscript.
Funding
The development of stochastic methods was supported by the Bulgarian National Science Fund under Bilateral Project KP-06-Russia/17 “New Highly Efficient Stochastic Simulation Methods and Applications”. The Sobol global approach estimation was supported by the Bulgarian National Science Fund under Project KP-06-M32/2—17.12.2019 “Advanced Stochastic and Deterministic Approaches for Large-Scale Problems of Computational Mathematics”. The multidimensional sensitivity analysis was supported by the Bulgarian National Science Fund under Project KP-06-N52/5 “Efficient methods for modeling, optimization and decision making”. The optimization of the Sobol algorithm was supported by the Bulgarian National Science Fund under Project KP-06-N62/6 “Machine learning through physics-informed neural networks”. The experimental study was supported by the National Program “Young Scientists and Postdoctoral Researchers-2”—Bulgarian Academy of Sciences.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Havasi, Á.; Bartholy, J.; Faragó, I. Splitting method and its application in air pollution modeling. Idojárás 2001, 105, 39–58. [Google Scholar]
- Fidanova, S.; Zhivkov, P.; Roeva, O. InterCriteria Analysis Applied on Air Pollution Influence on Morbidity. Mathematics 2022, 10, 1195. [Google Scholar] [CrossRef]
- Ferretti, F.; Saltelli, A.; Tarantola, S. Trends in sensitivity analysis practice in the last decade journal. Sci. Total Environ. 2016, 568, 666–670. [Google Scholar] [CrossRef]
- Saltelli, A.; Chan, K.; Scott, M. Sensitivity Analysis; John Wiley & Sons Publishers: London, UK, 2000. [Google Scholar]
- Saltelli, A.; Tarantola, S.; Chan, K. A quantitative model-independent method for global sensitivity analysis of model output. Source. Technometrics Arch. 1999, 41, 39–56. [Google Scholar] [CrossRef]
- Saltelli, A.; Tarantola, S.; Campolongo, F.; Ratto, M. Sensitivity Analysis in Practice: A Guide to Assessing Scientific Models; Halsted Press: New York, NY, USA, 2004. [Google Scholar]
- Sandewall, E. Combining logic and differential equations for describing real-world system. In Proceedings of the First International Conference on Principles of Knowledge Representation and Reasoning, San Francisco, CA, USA, 1 December 1989; Brachmann, R.J., Levesque, H., Reiter, R., Eds.; Morgan Kaufmann Publishers Inc.: Los Altos, CA, USA, 1989; pp. 412–420. [Google Scholar]
- Parpia, S.; Morris, T.P.; Phillips, M.R.; Wykoff, C.C.; Steel, D.H.; Thabane, L.; Bhandari, M.; Chaudhary, V.; Retina Evidence Trials InterNational Alliance (R.E.T.I.N.A.) Study Group. Sensitivity analysis in clinical trials: Three criteria for a valid sensitivity analysis. Eye 2022, 36, 2073–2074. [Google Scholar] [CrossRef]
- Puy, A.; Beneventano, P.; Levin, S.A.; Lo Piano, S.; Portaluri, T.; Saltelli, A. Models with higher effective dimensions tend to produce more uncertain estimates. Sci. Adv. 2022, 8, eabn9450. [Google Scholar] [CrossRef]
- Razavi, S.; Jakeman, A.; Saltelli, A.; Prieur, C.; Iooss, B.; Borgonovo, E.; Plischke, E.; Piano, S.L.; Iwanaga, T.; Becker, W.; et al. The Future of Sensitivity Analysis: An essential discipline for systems modeling and policy support. Environ. Model. Softw. 2021, 137, 104954. [Google Scholar] [CrossRef]
- Puy, A.; Piano, S.L.; Saltelli, A. Is VARS more intuitive and efficient than Sobol’ indices? Environ. Model. Softw. 2021, 137, 104960. [Google Scholar] [CrossRef]
- Puy, A.; Piano, S.L.; Saltelli, A. A sensitivity analysis of the PAWN sensitivity index. Environ. Model. Softw. 2020, 127, 104679. [Google Scholar] [CrossRef]
- Cukier, R.; Fortuin, C.; Shuler, K.; Petschek, A.; Schaibly, J. Study of the sensitivity of coupled reaction systems to uncertainties in rate coefficients. I. Theory. J. Chem. Phys. 1973, 59, 3873–3878. [Google Scholar] [CrossRef]
- Zlatev, Z.; Dimov, I.T.; Georgiev, K. Modeling the long-range transport of air pollutants. IEEE Comput. Sci. Eng. 1994, 1, 45–52. [Google Scholar] [CrossRef]
- Jacques, J.; Lavergne, C.; Devictor, N. Sensitivity analysis in presence of modele uncertainty and correlated inputs. Reliab. Eng. Syst. Saf. 2006, 91, 1126–1134. [Google Scholar] [CrossRef]
- Rashid, M.; Saleem, N.; Bibi, R.; George, R. Solution of Integral Equations Using Some Multiple Fixed Point Results in Special Kinds of Distance Spaces. Mathematics 2022, 10, 4707. [Google Scholar] [CrossRef]
- Wang, M.; Ishtiaq, U.; Saleem, N.; Agwu, I.K. Approximating Common Solution of Minimization Problems Involving Asymptotically Quasi-Nonexpansive Multivalued Mappings. Symmetry 2022, 14, 2062. [Google Scholar] [CrossRef]
- Homma, T.; Saltelli, A. Importance measures in global sensitivity analysis of nonlinear models. Reliab. Eng. Syst. Saf. 1996, 52, 1–17. [Google Scholar] [CrossRef]
- Iooss, B.; Van Dorpe, F.; Devictor, N. Response surfaces and sensitivity analyses for an environmental model of dose calculations. Reliab. Eng. Syst. Saf. 2006, 91, 1241–1251. [Google Scholar] [CrossRef]
- Akgungor, A.; Yildiz, O. Sensitivity analysis of an accident prediction model by the fractional factorial method. Accid. Anal. Prev. 2007, 39, 63–68. [Google Scholar] [CrossRef]
- Helton, J.C. Uncertainty and sensitivity analysis techniques for use in performance assessment for radioactive waste disposal. Reliab. Eng. Syst. Saf. 1993, 42, 327–367. [Google Scholar] [CrossRef]
- Dimov, I.T. Monte Carlo Methods For Applied Scientists; World Scientific: Hackensack, NJ, USA; London, UK; Singapore, 2007. [Google Scholar]
- Caflisch, R.E. Monte Carlo and quasi-Monte Carlo methods. Acta Numer. 1998, 7, 1–49. [Google Scholar] [CrossRef]
- Kalos, M.A.; Whitlock, P.A. Monte Carlo Methods, Volume 1: Basics; Wiley: New York, NY, USA, 1986. [Google Scholar]
- Berntsen, J.; Espelid, T.; Genz, A. An adaptive algorithm for the approximate calculation of multiple integrals. ACM Trans. Math. Softw. 1991, 17, 437–451. [Google Scholar] [CrossRef]
- Sobol, I.M. Monte Carlo Numerical Methods; Nauka: Moscow, Russia, 1973. [Google Scholar]
- Niederreiter, H. Low-discrepancy and low-dispersion sequences. J. Number Theory 1988, 30, 51–70. [Google Scholar] [CrossRef]
- Sobol, I.M. Distribution of points in a cube and approximate evaluation of integrals. USSR Comput. Maths. Math. Phys. 1967, 7, 86–112. [Google Scholar] [CrossRef]
- Joe, S.; Kuo, F.Y. Constructing Sobol’ sequences with better two-dimensional projections. SIAM J. Sci. Comput. 2008, 30, 2635–2654. [Google Scholar] [CrossRef]
- Atanassov, E.; Durchova, M. Generating and testing the modified Halton sequences. Lect. Notes Comput. Sci. 2007, 2542, 91–98. [Google Scholar]
- Pencheva, V.; Georgiev, I.; Asenov, A. Evaluation of passenger waiting time in public transport by using the Monte Carlo method. In Proceedings of the Seventh International Conference on New Trends in the Applications of Differential Equations in Sciences, Sts. Constantin and Helena, Bulgatia, 1–4 September 2020; AIP Publishing LLC: Melville, NY, USA, 2021; Volume 2321, p. 030028. [Google Scholar]
- Kucherenko, S.; Song, S. Derivative-Based Global Sensitivity Measures and Their Link with Sobol’ Sensitivity Indices. In Monte Carlo and Quasi-Monte Carlo Methods; Cools, R., Nuyens, D., Eds.; Springer Proceedings in Mathematics & Statistics; Springer: Cham, Switzerland, 2016; Volume 163. [Google Scholar]
- Sobol, I.M.; Kucherenko, S.S. On Global Sensitivity Analysis of Quasi-Monte Carlo Algorithms; De Gruyter: Berlin, Germany, 2005; Volume 11, pp. 83–92. [Google Scholar]
- Kucherenko, S.; Rodriguez-Fernandez, M.; Pantelides, C.; Shah, N. Monte Carlo evaluation of derivative-based global sensitivity measures. Reliab. Eng. Syst. Saf. 2009, 94, 1135–1148. [Google Scholar] [CrossRef]
- The Danish Eulerian Model. Available online: http://www2.dmu.dk/AtmosphericEnvironment/DEM/ (accessed on 26 January 2023).
- Zlatev, Z. Computer Treatment of Large Air Pollution Models; KLUWER Academic Publishers: Dorsrecht, The Netherlands; Boston, MA, USA; London, UK, 1995. [Google Scholar]
- Zlatev, Z.; Dimov, I.T.; Georgiev, K. Three-dimensional version of the Danish Eulerian model. Z. Angew. Math. Mech. 1996, 76, 473–476. [Google Scholar]
- Zlatev, Z.; Dimov, I. Computational and Numerical Challengies in Environmental Modelling; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Dimov, I.; Zlatev, Z. Testing the sensitivity of air pollution levels to variations of some chemical rate constants. Notes Numer. Fluid Mech. 1997, 62, 167–175. [Google Scholar]
- Zlatev, Z.; Dimov, I. Using a digital twin to study the influence of climatic changes on high ozone levels in bulgaria and europe. Atmosphere 2022, 13, 932. [Google Scholar] [CrossRef]
- Sobol, I.M. Sensitivity estimates for nonlinear mathematical models. Math. Model. Comput. Exp. 1993, 4, 407–414. [Google Scholar]
- Archer, G.; Saltelli, A.; Sobol, I. Sensitivity measures, ANOVA-like techniques and the use of bootstrap. J. Stat. Comput. Simul. 1997, 58, 99–120. [Google Scholar] [CrossRef]
- Chan, K.; Saltelli, A.; Tarantola, S. Sensitivity analysis of model output: Variance-based methods make the difference. In Proceedings of the 1997 Winter Simulation Conference, Atlanta, GA, USA, 7–10 December 1997; pp. 261–268. [Google Scholar]
- Saltelli, A. Making best use of model valuations to compute sensitivity indices. Comput. Phys. Commun. 2002, 145, 280–297. [Google Scholar] [CrossRef]
- van der Corput, J.G. Verteilungsfunktionen (Erste Mitteilung). In Proceedings of the Koninklijke Akademie van Wetenschappen te Amsterdam (in German), Amsterdam, The Netherlands, 28 September 1935; Volume 38, pp. 813–821. [Google Scholar]
- Halton, J. On the efficiency of certain quasi-random sequences of points in evaluating multi-dimensional integrals. Numer. Math. 1960, 2, 84–90. [Google Scholar] [CrossRef]
- Halton, J.; Smith, G.B. Algorithm 247: Radical-inverse quasi-random point sequence. Commun. ACM 1964, 7, 701–702. [Google Scholar] [CrossRef]
- Hammersley, J.M.; Scomb, D.C. General principles of the Monte Carlo method. In Monte Carlo Methods; John Wiley & Sons: New York, NY, USA, 1964. [Google Scholar]
- Faure, H. Discrépance de suites associées à un système de numération (en dimension s). Acta Arith. 1982, 41, 337–351. [Google Scholar] [CrossRef]
- Niederreiter, H. Point sets and sequences with small discrepancy. Monatshefte Math. 1987, 104, 273–337. [Google Scholar] [CrossRef]
- Mullen, G.L.; Mahalanabis, A.; Niederreiter, H. Tables of (t, m, s)-net and (t, s)-sequence parameters. In Monte Carlo and Quasi-Monte Carlo Methods in Scientific Computing; Niederreiter, H., Shiue, P.J., Eds.; Volume 106 of Lecture Notes in Statistics; Springer: Berlin/Heidelberg, Germany, 1995; pp. 58–86. [Google Scholar]
- Bratley, P.; Fox, B. Algorithm 659: Implementing Sobol’s Quasirandom Sequence Generator. ACM Trans. Math. Softw. 1988, 14, 88–100. [Google Scholar] [CrossRef]
- Bratley, P.; Fox, B.; Niederreiter, H. Implementation and Tests of Low Discrepancy Sequences. ACM Trans. Model. Comput. Simul. 1992, 2, 195–213. [Google Scholar] [CrossRef]
- Antonov, I.; Saleev, V. An Economic Method of Computing LPτ-sequences. USSR Comput. Math. Phys. 1979, 19, 252–256. [Google Scholar] [CrossRef]
- Bratley, P.; Fox, B.; Schrage, L. A Guide to Simulation, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 1987; ISBN 0387964673. [Google Scholar]
- Ökten, G.; Göncüb, A. Generating low-discrepancy sequences from the normal distribution: Box–Muller or inverse transform? Math. Comput. Model. 2011, 53, 1268–1281. [Google Scholar] [CrossRef]
- Owen, A. Randomly Permuted (t, m, s)-Nets and (t, s)-Sequences. Monte Carlo and Quasi-Monte Carlo Methods in Scientific Computing; 106 in Lecture Notes in Statistics: 299–317; Springer: New York, NY, USA, 1995. [Google Scholar]
- Owen, A. Scrambled Net Variance for Integrals of Smooth Functions. Ann. Stat. 1997, 25, 1541–1562. [Google Scholar] [CrossRef]
- Owen, A. Variance and Discrepancy with Alternative Scramblings. ACM Trans. Model. Comput. Simul. 2002, 13, 1–16. [Google Scholar]
- Kocis, L.; Whiten, W.J. Computational investigations of low-discrepancy sequences. ACM Trans. Math. Softw. 1997, 23, 266–294. [Google Scholar] [CrossRef]
- Matousek, J. On the L2-discrepancy for anchored boxes. J. Complex. 1998, 14, 527–556. [Google Scholar] [CrossRef]
- Fox, B. Algorithm 647: Implementation and Relative Efficiency of Quasirandom Sequence Generators. ACM Trans. Math. Softw. 1986, 12, 362–376. [Google Scholar] [CrossRef]
- Niederreiter, H. Random Number Generation and Quasi-Monte Carlo Methods; SIAM: Philadelphia, PA, USA, 1992; Volume 13, ISBN 978-0-898712-95-7. [Google Scholar]
- Press, W.; Flannery, B.; Teukolsky, S.; Vetterling, W. Numerical Recipes in FORTRAN: The Art of Scientific Computing, 2nd ed.; Cambridge University Press: Cambridge, UK, 1992; ISBN 0-521-43064-X. [Google Scholar]
- Sobol, I. Uniformly Distributed Sequences with an Additional Uniform Property. USSR Comput. Math. Math. Phys. 1977, 16, 236–242. [Google Scholar] [CrossRef]
- Sobol, I.; Levitan, Y.L. The Production of Points Uniformly Distributed in a Multidimensional Cube; Preprint IPM Akademii Nauk SSSR, Number 40; Akademiia: Moscow, Russia, 1976. (In Russian) [Google Scholar]
- Joe, S.; Kuo, F. Remark on Algorithm 659: Implementing Sobol’s Quasirandom Sequence Generator. ACM Trans. Math. Softw. 2003, 29, 49–57. [Google Scholar] [CrossRef]
- Dimov, I.T.; Georgieva, R.; Ostromsky, T.; Zlatev, Z. Sensitivity Studies of Pollutant Concentrations Calculated by UNI-DEM with Respect to the Input Emissions. Cent. Eur. J. Math. Methods Large Scale Sci. Comput. 2013, 11, 1531–1545. [Google Scholar] [CrossRef]
- Dimov, I.T.; Georgieva, R.; Ostromsky, T.; Zlatev, Z. Variance-based Sensitivity Analysis of the Unified Danish Eulerian Model According to Variations of Chemical Rates. In Proceedings of the Numerical Analysis and Its Applications: 5th International Conference, NAA 2012, Lozenetz, Bulgaria, 15–20 June 2012; Dimov, I., Faragó, I., Vulkov, L., Eds.; Springer: Berlin, Germany, 2013; pp. 247–254. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).