1. Introduction
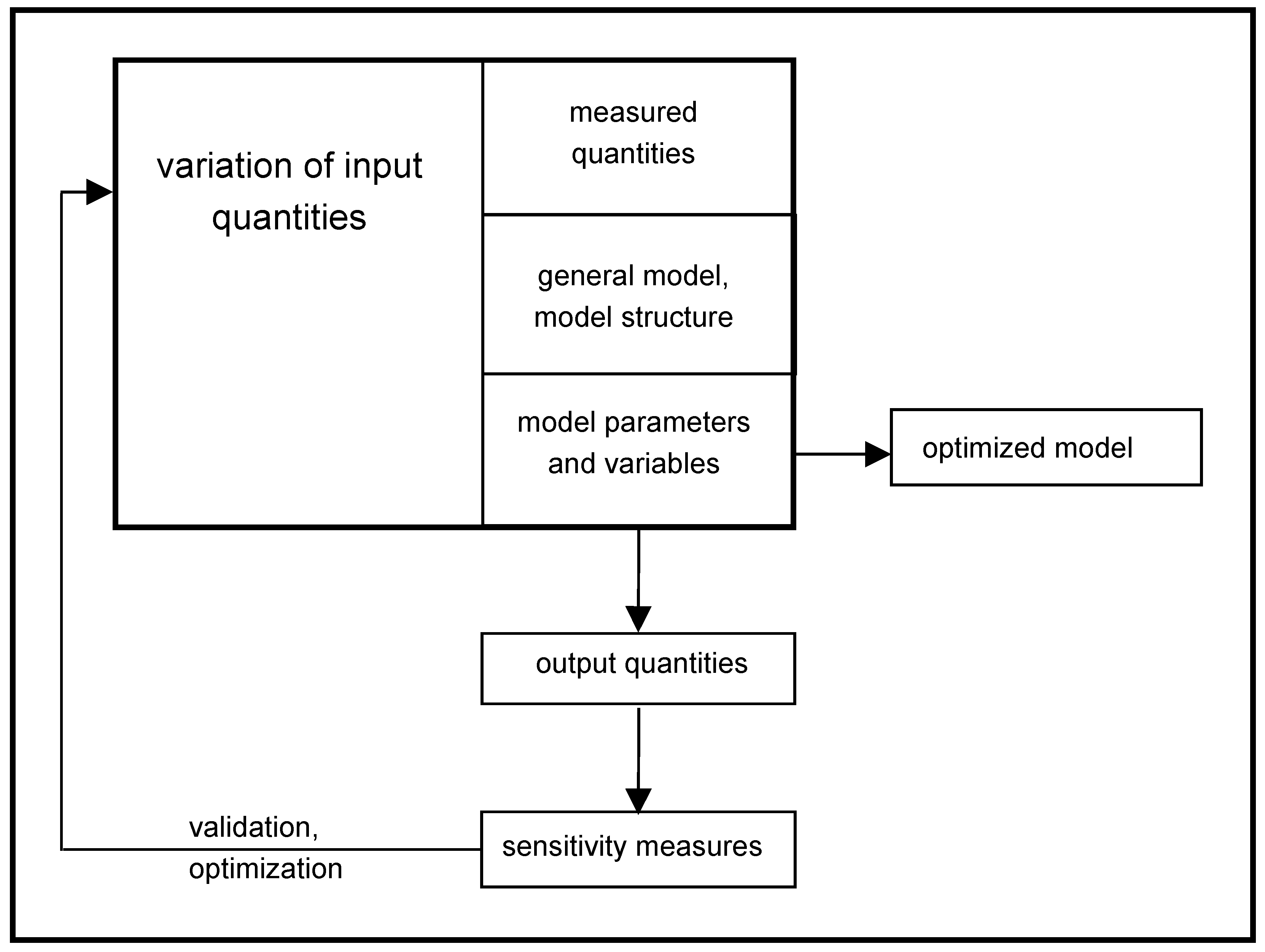
The purpose of our work is in the field of environmental security [
1,
2], since this is one of the key areas worldwide. By definition, a sensitivity analysis (SA) is an investigation of how much the uncertainty in the input data of a model is apportioned in the accuracy of the output results [
3,
4,
5,
6,
7]; see
Figure 1. Multidimensional SA [
8,
9,
10,
11,
12] is a very challenging task when modeling, but it is often the key tool for studying a complex phenomenon [
13,
14,
15,
16,
17].
The main problem in SA is the evaluation of the total sensitivity indices (SIs) [
18,
19,
20,
21]. The mathematical formulation for estimating the SIs is represented by a set of multidimensional integrals (MIs) [
22,
23,
24,
25]. The Monte Carlo (MC) and quasi-Monte Carlo (QMC) methods are the best tools for solving the MIs [
22,
26,
27,
28,
29,
30,
31]. For a more clear explanation of the objectives in this paper, one should check [
32,
33,
34].
The input data for SA were obtained with a large-scale model of the long-range transport of pollutants in the air—the
Unified
Danish
Eulerian
Model
(UNI-DEM) [
35,
36,
37,
38,
39]. UNI-DEM is also a basic tool and important tool for the creation of a digital twin, namely, Digital Air (see [
40]).
By definition, the model can be introduced with a model function [
41]:
The concept of the Sobol approach consists of the following representation of
and a constant
[
41]:
The above description is noted as the ANOVA representation of
if [
41]:
The quantities
are called total and partial variances [
41]. The same is true for the total variance:
The Sobol global SIs [
6,
41] are determined by:
Then, the
total
sensitivity
index (TSI) of the input parameter
is determined by [
42]:
where
is the
jth-order SI for
.
According to the definition in [
43], when
, the quantity
is called
the main effect of
; if
,
are called
two-way interactions (second-order SIs); if
,
are called
three-way interactions (third-order SIs), and so on. In this study, we are interested in the main effects and the two-way interactions.
The TSI of the output variance for an input parameter
is represented as:
; see [
18]. With this, we show that multidimensional SA using Sobol’s approach is turned into a problem of evaluating MIs [
44].
In this paper, we aim to suggest implementations for the fast and accurate evaluation of the sensitivity indices. As mentioned earlier, the problem of SA is transformed into a multidimensional integration task that is approached by using novel quasi-Monte Carlo methods, which are compared with the best available algorithms in an application to large-scale modeling of atmospheric pollution. The methods are described in the next section, followed by a thorough analysis of the computational results.
2. Methods and Algorithms
Consider the following multidimensional problem:
where
and
.
In the simplest possible MC approach, “Crude”, we introduce the random variable
, for which
and the random points
are independent realizations of the random point
with a probability density function
and
. The
Crude MC approach for the integral
I is defined as [
22]:
Let for and let be the representation of in base .
Then, the discrepancy (star discrepancy) of the set is defined [
22,
24]:
where
.
For the one-dimensional quasi-random number sequence, we introduce the radical inverse sequence [
22,
23]:
The
van der Corput sequence [
45] is obtained when
. Now, the multidimensional quasi-random number sequence is defined as:
where the bases
are all relatively prime:
, where
denotes the
ith prime.
Now, the
Halton sequence [
46,
47] is defined as:
where
,
designates the
i-th prime, and
denotes the set of permutations on
The standard
M-dimensional
Hammersley sequence [
48], which is based on
N samples, is simply composed of a first component of successive fractions
paired with
one-dimensional van der Corput sequences by using the first
primes as bases. More precisely, if
are the first
prime numbers, then the Hammersley sequence
with
N points in
s dimensions is given by
The
Faure sequence [
49,
50,
51] is given by:
The
Sobol sequence [
52,
53,
54] is defined by:
where
are the set of permutations on every
subsequent points of the van der Corput sequence, defined by
when
.
In binary, for the Sobol sequence, we have that:
, where
is the set of directional numbers [
55].
For the QMC algorithms, based on the
Halton,
Faure and
Sobol sequences, it is known that the corresponding discrepancy is:
According to several important works [
56,
57,
58,
59], the convergence rate for the scrambling algorithms essentially improves the convergence rate for the unscrambled nets [
56,
57,
58,
59], which is
. The scrambling itself is based on the randomization of a single digit at each iteration. Let
be quasi-random numbers in
, and let
be the corresponding scrambled version of the point
. Let every
be rewritten in base
b as
with
K being the number of digits for scrambling. For the scrambled Halton sequence
HaltonScr, we apply a permutation of the radical inverse coefficients, which is obtained by applying a reverse-radix operation to each of the possible coefficient values [
60]. For the scrambled Sobol sequence
SobolScr, we use a random linear scramble blended with a random digital shift [
61].
Now, we will introduce a super-convergent modified Sobol sequence
SobolBurkardt based on the INSOBL and GOSOBL routines in ACM TOMS Algorithm 647 and ACM TOMS Algorithm 659, as well as a Burkardt modification [
52,
53,
54,
55,
62,
63,
64,
65,
66,
67]. The original code can only compute the next element of the sequence. Our modification allows the user to specify the index of the desired element. The novelty is that this is the first time that the SobolBurkardt algorithm has been applied for a multidimensional sensitivity analysis of this important digital ecosystem.
3. Results and Discussion
In this section, the advanced stochastic algorithms described above (
Crude, Sobol, Halton, SobolScr, HaltonScr, SobolBurkardt, Hammersley, and
Faure) are applied to sensitivity studies with respect to emission levels (
SSREL) and with respect to some chemical reaction rates (
SSRCRR) of varying concentrations of UNI-DEM pollutants [
68,
69]. We use the following notations: EQ refers to the estimated quantity, RV refers to the reference value, RE refers to the relative error, and AE refers to the approximate evaluation.
For
SSREL, we will investigate an SA of the model output (in terms of the mean monthly concentrations of several important pollutants—in our case, the pollutant is ammonia in Milan) with respect to a variation in the input emissions from anthropogenic pollutants, which consist of four components,
:
The output of the model is the mean monthly concentration of the following three pollutants:
—ozone ();
—ammonia ();
—ammonium sulfate and ammonium nitrate ().
For
SSEL, the results for the REs for the AE of the
and
when using
Crude, Sobol, Halton, SobolScr, HaltonScr, SobolBurkardt, Hammersley, Faure are shown in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6, respectively. The quantity
is represented by a four-dimensional integral, whereas the rest are represented by eight-dimensional integrals.
In the case of
SSRCRR, we will investigate the ozone concentrations in Genova according to the rates of variation of these chemical reactions, which are ##
(time-dependent) and
(time-independent) in the CBM-IV scheme [
36]:
In the case of
SSRCRR, the results for the REs for the AE of
and
when using
Crude, Sobol, Halton, SobolScr, HaltonScr, SobolBurkardt, Hammersley, and
Faure are shown in
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12, respectively. As in the first case study, the quantity
is represented by a six-dimensional integral, whereas the rest are represented by twelve-dimensional integrals.
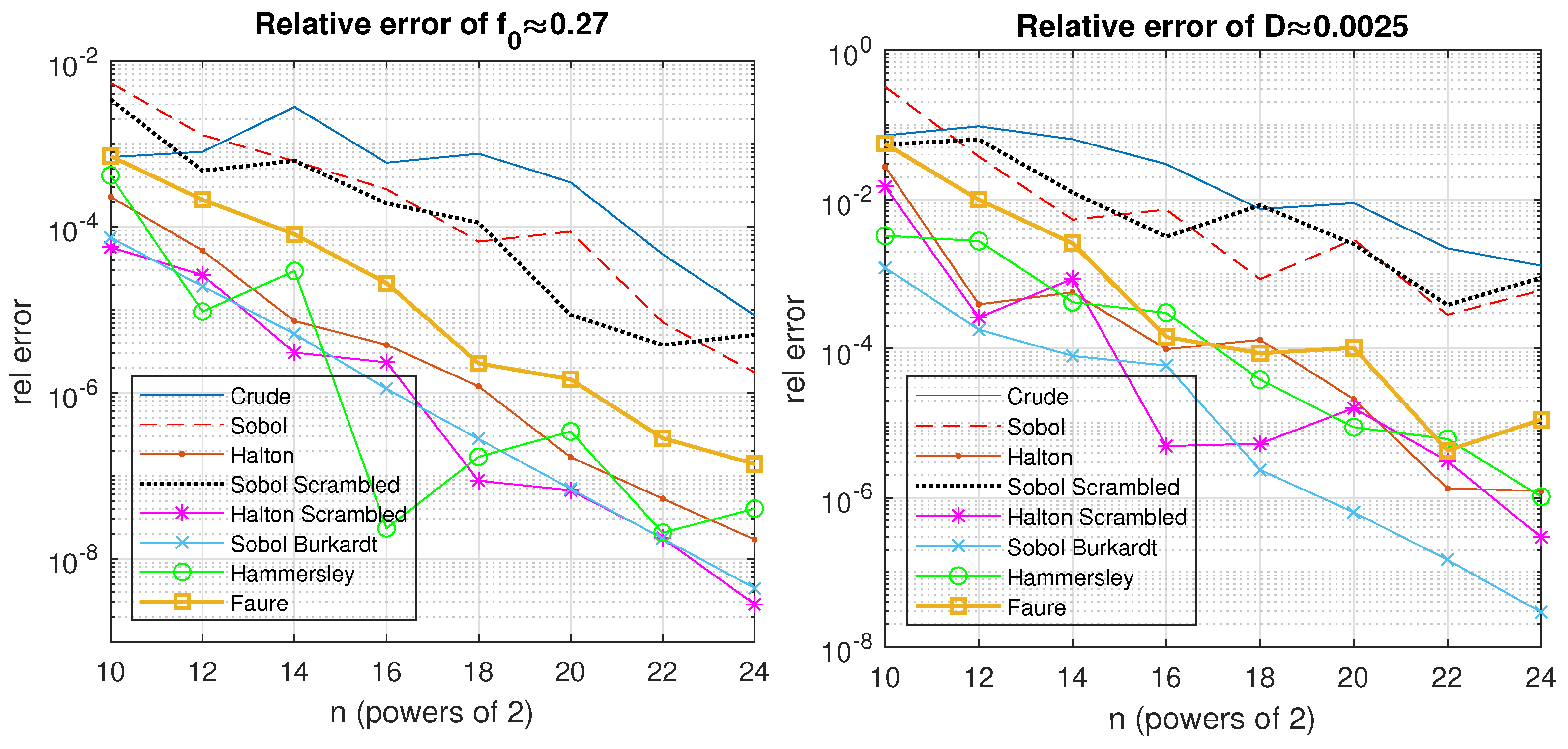
In the case of
SSREL, one may observe the following. In
Table 1, for the model function
, the best algorithm for all numbers of samples is HaltonScr, followed by SobolBurkardt. For
, for the total variance
, the best algorithm is SobolBurkardt, followed by the Halton sequence—see the results in
Table 2. However, for
and
, the Halton sequence produces slightly better results—see
Table 2. The behavior of the algorithm can also be seen in
Figure 2. The RVs for the first and total SIs are presented in
Table 3. From
Table 4,
Table 5 and
Table 6, one can conclude that for all first-order SIs and TSIs, the best algorithm is SobolBurkardt, followed by HaltonScr and the Halton sequence. It is important that the scrambling procedure improves the results of the Sobol and Halton sequences by at least one order for most of the cases—see the values for
and
in
Table 6. In [
42], it was pointed out that having the smallest possible SIs is the most important aspect of a model. In our case, these are
and
—see
Table 3. For them, SobolBurkardt significantly improved upon the results of the other sequences, and one can also see that the Hammersley and Faure sequences performed better than the Crude algorithm, as expected.
The performance of the algorithms in the case of SSREL can be generalized in this way: The algorithm that we implemented, SobolBurkardt, held the smallest relative errors for all SIs; the scrambled Halton and original Halton sequences were the next, followed by the Hammersley, Faure, scrambled Sobol, and Sobol algorithms; the worst was the plain algorithm.
In the case of
SSRCRR, the following observations could be made. In
Table 7, for the model function
, the best algorithm for all numbers of samples except
,
, and
was HaltonScr; for
, the best algorithm was SobolBurkardt, and in the other two cases, the best algorithm was the Hammersley sequence. The RVs of the first- and second-order SIs and TSIs are given in
Table 9. For all numbers of samples except
, for the total variance
D, the best algorithm was SobolBurkardt—see the results in
Table 8. However, for
, the scrambled Halton sequence produced results that was one order better than our SobolBurkardt algorithm. The behavior of the algorithm can also be seen in
Figure 3. For a low number of samples,
, as shown in
Table 10, the Halton sequence was better than our SobolBurkardt algorithm for
and
, and the scrambled Halton sequence was better than our algorithm for the total SIs
,
, and
. As previously mentioned, having the smallest possible SIs is the most important aspect of a model. Here, these were
,
, and
—see
Table 9. For them, our SobolBurkardt implementation performed better than the other algorithms. However, for larger numbers of samples, as shown in
Table 11 and
Table 12, one can conclude that for all first-order SIs, second-order SIs, and TSIs, the best algorithm was SobolBurkardt, followed by the HaltonScr and scrambled Sobol sequence algorithms. It is important that the scrambling procedure significantly improved the results of the Sobol and Halton sequences for some of the cases—see the values for
and
in
Table 12. For all of the cases, the Hammersley and Faure sequences performed better than the Crude algorithm, as expected.
The performance of the algorithms in the case of SSREL can be generalized in such a way: The SobolBurkardt algorithm that we implemented held the smallest REs for all SIs; the scrambled Halton and the original Halton sequence are the next, followed by the Hammersley, Faure, scrambled Sobol, and Sobol algorithms, and the worst was the Crude algorithm.
The overall conclusion is that the implemented SobolBurkardt algorithm was the best approach among the benchmarked algorithms, and the values of the relative errors showed its supremacy over the majority of the existing methods when applied to multidimensional air pollution sensitivity analysis.









{kind=link}
{kind=link}
{kind=link}