1. Introduction
With the rapid development of the economy, environmental issues, including energy consumption and air pollution, are becoming increasingly serious and gradually attracting people’s attention. As a diffusion phenomenon, air pollution is the main concomitant of urbanization, which will lead to the increase of haze weather and increase the probability of people suffering from respiratory diseases, thus affecting people’s health and restricting the speed of economic development [
1].
PM2.5 is an important air pollutant. The higher the concentration of PM2.5 in the air, the more serious the air pollution becomes. Therefore, many countries and regions around the world have listed the prevention and control of PM2.5 pollution as the priority of environmental protection. PM2.5 refers to particulate matter with an aerodynamic equivalent diameter of 2.5 microns or less in the ambient air. Although PM2.5 in earth’s atmospheric composition of very few, it leads to the deterioration of visibility and air quality. PM2.5 is considered the most hazardous pollutant since it has small particle size, strong activity, easy to attach toxic and harmful substances (such as heavy metals, microorganisms, etc.), and stays in the air for a long time, flows far away, and affects a large range, so its harm for human health and atmospheric environmental quality is greater [
2]. PM2.5 and the substances it carries will enter the alveoli through the respiratory tract, and the insoluble part will be deposited in the lungs, and the rest will dissolve into the blood and reach various organs of the body through the blood circulation, causing harm to various systems of the human body, resulting in various diseases. The PM2.5 concentration is not only related to the direct emission of atmospheric pollutants, but also the chemical and physical reactions between atmospheric pollutants can form new pollutants, which further affects the PM2.5 concentration.
As a major air pollutant, the concentration of PM2.5 is directly affected by human activities and the surrounding environment, at the same time, it also reacts on human beings themselves. Based on global data, Zhou et al. scientifically quantified the impact of air pollutants on antibiotic resistance, clarified for the first time the driving impact of PM2.5 air pollution on global antibiotic resistance, and predicted the impact of PM2.5 on antibiotic resistance and the trend of premature human death [
3]. Although the mechanism of PM2.5 pollution is very complex, in general, it is mainly caused by natural factors and social and economic factors. The relative importance of these factors to PM2.5 pollution remains uncertain, which will not be conducive to the formulation of effective air pollution mitigation policies. Therefore, it is necessary to have an in-depth understanding of the influence mechanism of PM2.5.
The influencing factors of PM2.5 have been extensively studied in the literature. Zhu et al. took the air pollutants and meteorological factors with a lag of one day and two days as PM2.5 influence factors. Air pollutants include PM10, CO, NO
2, O
3, and SO
2. Meteorological factors include sunshine duration, mean/maximum/minimum pressure, mean/maximum/minimum temperature, mean/minimum relative humidity and mean/maximum/minimum wind speed [
4]. Taking PM2.5 as the dependent variable, Venkataraman used wavelet analysis and regression analysis to find out the significant factors of environmental variables and pollutants affecting PM2.5 concentration, and found that pollutants such as NO
2, NOx, SO
2 and benzene, as well as environmental factors such as ambient temperature, solar radiation and wind direction, had little effect on PM2.5 concentration [
5].
With regard to the forecasting of PM2.5 concentration, Zhang et al. used a time-series auto-regressive integrated moving average (abbreviated as “ARIMA”) model to predict PM2.5 concentration in Fuzhou. The results agree well with the measured data [
6]. Lv et al. established a nonlinear regression model to predict PM2.5 concentration in Beijing, Nanjing and Guangzhou respectively. The model includes nonlinear terms and linear terms, which has the advantage of showing the nonlinear relationship between PM2.5 concentration and meteorological factors [
7]. Sorek-Hamer et al. confirmed that the generalized additive model had achieved good results in forecasting PM2.5 concentration, and the relationship between explanatory variables and explained variables could be explained [
8]. Back propagation artificial neural networks (abbreviated “BP-ANN”) are a common machine learning method for predicting PM2.5 concentrations. Wang et al. used a hybrid model of principal component analysis and spatial backpropagation neural network to predict PM2.5 concentration at 1280 monitoring sites in China [
9]. In addition to BP-ANN, other machine learning models have also been widely used to predict PM2.5 concentration. Park et al. applied a convolutional neural network model to predict PM2.5 concentration [
10]. Perez and Gramsch used feedforward neural networks to build a PM2.5 concentration prediction model [
11].
Among the methods for predicting PM2.5 concentration, the generalized additive model shows obvious superiority. Song et al. used the generalized additive model to fit the statistical relationship between input variables and PM2.5 concentration to show that the GAM prediction results were better than the stepwise linear regression prediction results [
12]. Zou et al. predicted PM2.5 concentration and showed that the generalized additive model was superior to the typical land use regression model, which verified the reliability of the generalized additive model [
13].
In an extended study of GAM, Marra and Radice proposed to apply the two-stage instrumental variable method to GAM [
14]. Yu et al. constructed a generalized geographically additive model for processing spatial data randomly distributed over an irregular domain [
15].
The effects of various influencing factors on PM2.5 concentration have been often complex and nonlinear. There are more and more studies using nonlinear models to predict PM2.5 concentration, while there are still relatively few studies using generalized additive models to predict PM2.5 concentration. The PM2.5 concentration varies greatly among regions and cities, and the factors affecting PM2.5 concentration may be different. It is necessary to divide the cities into different regions and establish a generalized additive model to predict PM2.5 concentration, which has enriched the relevant research on PM2.5 concentration forecasting.
This paper is organized as follows:
Section 2 briefly introduces linear fuzzy information granule_dynamic time warping_hierarchical clustering algorithm (LFIG_DTW_HC algorithm) and generalized additive model. In
Section 3, a new PM2.5 concentration forecasting method based on LFIG_DTW_HC algorithm and generalized additive model is proposed. First, the LFIG_DTW_HC algorithm is used to divide the cities into 7 regions according to the air quality index of the cities, and the descriptive statistics of PM2.5 concentration in each region are carried out. Then, the input variables of the forecasting model are determined by the method of variable correlation and generalized additive model, and the influencing factors of regional PM2.5 concentration are analyzed.
Section 4 is the empirical analysis of regional and urban PM2.5 concentration forecasting. First, a generalized additive model is established to predict PM2.5 concentration in each region, and the forecasting result has been analyzed. Then, a generalized additive model is established by selecting cities from each region, and compared with the auto-regressive integrated moving average (ARIMA) model to analyze the forecasting effect of the two models.
Section 5 is the conclusion, summarizing the research content of this paper and looking forward to the future.
In summary, the innovation of this paper is as follows: the combination of LFIG_DTW_HC algorithm and generalized additive model. Due to the large difference in PM2.5 concentration among cities, and the influencing factors of PM2.5 concentration in different cities may vary to some extent, it is particularly important to research the forecasting of PM2.5 concentration in multiple places. However, when there are many places, sub-regional prediction of PM2.5 concentration is a better method. Moreover, the generalized additive model can overcome the shortcomings of the formal setting of regression model and the black box model of machine learning method, and it can effectively solve the problems of too many assumptions and inexplicable model while maintaining high forecasting accuracy. Therefore, in this paper, the LFIG_DTW_HC algorithm is used to cluster the urban air quality index data and divide the cities into several regions. Then, the main influencing factors of PM2.5 concentration in each region are determined based on the generalized additive model, and the input variables of the PM2.5 concentration forecasting model in each region are determined by combining the variable correlation with the generalized additive model. The relationship between input variables and output variables could be explained. By predicting PM2.5 concentration by region, the PM2.5 concentration can be predicted more accurately.
3. A Novel PM2.5 Concentration Forecasting Method
In this section, a novel PM2.5 concentration forecasting method is proposed based on LFIG_DTW_HC algorithm and generalized additive model.
Section 3.1 introduces a time series clustering method in detail, namely LFIG_DTW_HC algorithm.
Section 3.2 introduces the basic principle of generalized additive model.
Section 3.3 shows the theory and practice of the novel PM2.5 concentration forecasting method.
3.1. A Time Series Clustering Method
For two given LFIG time series LGS1 = and LGS2 = , we use the LFIG_DTW algorithm to calculate their distance. This means that LFIGs in LGS1 and lgs2 are matched with the shortest distance using recursion:
Recurrence relation:
where
is the LFIG distance between
and
and
is the sum of distance calculated from
to
. The minimum of W (m, n) is defined as the LFIG_DTW distance between the two given LFIG time series.
We have defined the distance between two time series above, when calculating the distance between each two time series in the time series data set, combining the distance calculation with the clustering process can simplify the whole process. First, each time series is segmented by the trend filtering. Then each subsequence is represented by LFIG to obtain the LFIG time series corresponding to each original time series. Record the LFIG time series. Next, the distance between each two LFIG time series is calculated to obtain the distance matrix. Finally, the matrix is used for hierarchical clustering and the clustering result is obtained. For the sake of representation, we will call this clustering method LFIG_DTW_HC.
3.2. A Model for Predicting PM2.5 Concentration
3.2.1. Basic Principle of Model
Generalized additive model is a nonparametric regression analysis method based on generalized linear model and additive model. Regression analysis is a common statistical method to reveal the relationship between response variables and explanatory variables. Therefore, the generalized additive model can be used to predict PM2.5 concentration and explain the relationship between response variables and explanatory variables in the model.
When there is a linear relationship between the response variables and explanatory variables, but the distribution of the response variable for other indexes of non-normal distribution, to establish the generalized linear model, define the connection function g (
) said explained variable and the relationship between the response variable, the formula of the generalized linear model expression is:
If the response variable follows the conditional normal distribution, but there is a nonlinear relationship between the response variable and the explanatory variable, non-parametric regression method can be used to fit the relationship between the variables, and an additive model can be established. The expression is as follows:
in Formula (6) is the smoothing function of variable, which is used to represent the relationship between variable and response variable.
However, when the distribution of response variables is non-normal distribution of other exponential families, and there is a complex nonlinear relationship between response variables and explanatory variables, GAM is a more appropriate regression method. The expression is as follows:
As can be seen from the Formula (7), GAM contains three parts: explanatory variables and response variables Y, connect function , smooth function .
The underlying assumption of GAM is that the functions of the explanatory variables are additive and that the components of GAM are smooth.
Connect function is determined by the distribution of the response variables, in the form of different distributions of the corresponding link function have differences. The connection function of the normal distribution is , the binomial distribution is , the gamma distribution is , and the poisson distribution is . Due to the existence of connection function, the relationship between explanatory variables and response variables can be set as nonlinear, which overcomes the limitation of multiple linear regression model and is more in line with the complex relationship between explanatory variables and response variables in the actual situation.
There are three main types of smoothing functions used in GAM: local regression, smoothing spline and regression spline.
The local regression obtains the smoothing function by fitting a weighted regression model within each nearest neighbor window. The steps to computing the smoothing function value of the target point X are as follows: First, determine the window width, which refers to the proportion of data contained in each symmetric sliding neighborhood. The smoothness can be determined by controlling the window width. The second step is to calculate the weight, which is a kernel function based on the idea of suppressing data points far from the target point. If the weight is represented by a quadratic function, then the weight
h is the width of the neighborhood. The third step is to establish a weighted regression model, and the weighted regression fitting value of the target point
x is the corresponding smoothing function value.
A smooth spline is a regularized regression of a natural spline, and the smooth function can be estimated by minimizing the penalty sum of squares . is the basis function at the phase node, and the node is at each observation point . is the sum of squared residuals of fitted observations, is a penalty term to improve the smoothness of the fitted curve, and the smoothing parameter controls the trade-off between goodness of fit and smoothness of the model.
The regression spline is a relatively practical smooth function. Common regression splines include B spline, P spline and thin plate spline. The regression spline can estimate the smoothness function by minimizing the sum of penalty squares, which is . A common method for the penalty term is to use a P-spline, which improves smoothness by directly penalizing the difference between neighboring coefficients, with the expression .
3.2.2. Model Diagnosis
- (1)
Concurvity
The change space explained by the smoothing function in GAM can be decomposed into two parts: the change space explained by other smoothing functions and the change space not explained by other smoothing functions. If is explained by the change of space parts of explain the change of space is more, the problem of concurvity can be thought of. The worst index, observed index and estimate index calculated according to the above thought can all evaluate the concurvity of GAM. If the index is greater than 0.5, it can be considered that the variables in the model have concurvity.
- (2)
Effective degree of freedom
As the smoothing parameter increases, the effective degree of freedom will decrease. After GAM is established, the effective degree of freedom is judged. If the effective degree of freedom of the variable smoothing function is close to 1, the parameter of the variable can be estimated; otherwise, the smoothing function is used for fitting.
3.3. The Theory and Practice of the Novel PM2.5 Concentration Forecasting Method
Due to the large difference in PM2.5 concentration among cities, the influencing factors of PM2.5 concentration in different cities may vary to some extent. The prediction of PM2.5 concentration in multiple cities is particularly important. However, when the number of cities is large, it is very complicated to establish a model for each city. So it is a good choice to cluster cities into different regions and predict by region. The innovation of the novel PM2.5 concentration forecasting method proposed in this paper lies in: the combination of LFIG_DTW_HC algorithm and generalized additive model. It can effectively solves this problem of excessive models, explains the relationship between input variables and output variables, and better predicts multi-city PM2.5 concentration while maintaining high prediction accuracy.
In order to evaluate the prediction effect of the novel PM2.5 concentration forecasting method, namely, the degree of fitting between the predicted value derived from the novel PM2.5 concentration forecasting method and the actual observed value, root mean square error (RMSE) and mean absolute error (MAE) and mean absolute scaled error (MASE) can be used to measure. The evaluation criterion of the three indicators are value as small as possible.
Therefore, a novel PM2.5 concentration forecasting method based on LFIG_DTW_HC algorithm and generalized additive model is proposed in this paper. Firstly, LFIG_DTW_HC algorithm is used to cluster cities. The original time series are transformed into granular time series, the clustering results are obtained by calculating the distance between them and applying hierarchical clustering method. Then, the main influencing factors of PM2.5 concentration in each region are determined and analyzed based on the generalized additive model. The input variables of the novel forecasting model in each region are determined by the method combining variable correlation with generalized additive model, the relationship between input variables and output variables could be explained. Finally, the predicted results are obtained by regional forecasting and urban forecasting. The framework of the novel forecasting method is shown in
Figure 1.
3.3.1. Descriptive Statistics of Regional PM2.5 Concentration
The causes of PM2.5 are complicated. It is mainly composed of primary particulate matter (particulate matter discharged directly into the air by emission sources) and secondary particulate matter (particulate matter generated by physical and chemical reactions with some components in the air). There are two main sources of particulate matter: one is natural sources, such as sea salt in the ocean and volcanic eruption; the second is man-made sources, including open burning activities, coal burning, motor vehicle exhaust, industrial waste gas, etc. Oxides such as sulfur and nitrogen in the air can be converted into PM2.5 through complex physicochemical reactions. Meteorological factors such as airflow and rainfall can achieve PM2.5 dilution and sedimentation, thus affecting PM2.5 concentration.
By sorting out and summarizing the influencing factors of PM2.5 concentration in the existing research results, the factors affecting PM2.5 concentration can be summarized into two aspects: one is micro variables such as meteorological and air pollutants; the other is macro variables such as population density, number of polluting enterprises and construction land area. Macro variables are mainly quarterly or annual data. This article predicts the average daily concentration of PM2.5, so using microscopic variables such as meteorological and air pollutants to forecast PM2.5 concentration.
Therefore, this article selects air pollutants and meteorological data from 1 January 2022 to 28 February 2023 in China for empirical study on PM2.5 concentration forecasting. The data from 1 January 2022 to 31 December 2022 are selected as the training set to conduct the fitting analysis of the model. Data from 1 January 2023 to 28 February 2023 are used as test sets for model prediction analysis.
In this study, the average daily concentration of PM2.5 is predicted based on the existing data of meteorological stations. Therefore, the air pollutant data are daily average concentrations including PM2.5, PM10, SO
2, NO
2, CO and O
3 (data available from:
http://www.tianqihoubao.com/ (accessed on 19 April 2023)). Because maximum, minimum, and average values are most representative of daily data, meteorological data include daily maximum pressure, daily minimum pressure, average pressure, daily maximum temperature, daily minimum temperature, average temperature, average relative humidity, daily cumulative precipitation and maximum wind speed (data available from:
https://rp5.ru/ (accessed on 19 April 2023)). As shown in
Table 1.
In this paper, 30 provincial capitals of China (mainland) are selected and grouped according to the air quality index by LFIG_DTW_HC algorithm. These cities are divided into seven regions, so that the air quality similarity in the same region is as large as possible, while the air quality difference in different regions is also as large as possible. The selected cities and regional distribution are shown in
Figure 2, they are summarized in
Table 2.
The box plot of PM2.5 concentration in each region for the period from 1 January 2022 to 31 December 2022 is shown in
Figure 3. The median PM2.5 concentration in the seven regions are no more than 35
, indicating that the number of days with good air quality have been more than half. The lower quartiles of 7 regions are all lower than 75
, namely the proportion of days with good or good air quality in each region are more than 75%. The maximum PM2.5 concentration in regions 1, 2, 5 and 6 are lower than 250
, there is no serious PM2.5 pollution weather, while other regions have serious pollution weather.
According to
Table 3, we can see that Region 3 has the highest average PM2.5 concentration, while region 2 has the lowest average. The average PM2.5 concentration in region 1, region 2, region 4, region 5 and region 6 are all lower than 35
, indicating that the air quality is excellent according to the air quality classification standard of PM2.5 average daily concentration, the air quality levels of each region are shown in
Figure 4.
As can be seen from
Table 3, the skewness of all regions is greater than 0, indicating that the distribution of PM2.5 concentration in each region is skewed to the right. The Kolmogorov-Smirnov test is conducted on the PM2.5 concentration data of 7 regions, and the
p-values are all less than 0.05, rejecting the null hypothesis. Therefore, it can be considered that the data of these 7 regions do not obey the normal distribution.
3.3.2. Analysis on Influencing Factors of Regional PM2.5 Concentration
There are 14 air pollutant and meteorological variables collected in this paper. There are complex relationships between each variable and PM2.5 concentration, and there is multicollinearity among some variables. If all variables are introduced into the forecasting model, which will lead to unreasonable practical significance of parameter estimators, or the significance test of some variables will lose significance. Therefore, variables need to be screened to determine the input variables of the forecasting model.
In GAM, the greater the variance explanatory degree of the variable, the stronger the influence of the variable on the response variable. In seven regions, univariate GAM is established separately for five air pollutant variables and nine meteorological variables that may affect PM2.5 concentration. Since the data in each region do not pass the normality test, the logarithmic connection function is selected and the spline smoothing function is used for fitting. Preliminary variable screening is conducted according to the variance interpretation rate obtained. The result is shown in
Table 4.
The input variables in the model can be determined according to the correlation between variables and the univariate GAM variance explanatory degree. First, the correlation coefficient between the two variables is calculated. For two variables whose absolute value of correlation coefficient is greater than 0.7, the variables with high variance interpretive degree are retained to avoid concurvity. Second, based on the reserved variables mentioned above, a preliminary multivariate GAM is established to perform a concurvity test on the smoothing function in the fitting model. If the results of two variables are greater than 0.5 in concurvity test, the variables with lower variance interpretive degree are removed. If the result is less than 0.5 in concurvity test, the concurvity of the fitting model can be considered to be within an acceptable range. Finally, the significance test of variables in the fitting model is conducted. If the fitting results show that some variables are not significant, the insignificant variables are removed. After the concurvity test and significance test of the smoothing term, the input variables of the model are determined.
As shown in
Table 5, the input variables of the PM2.5 concentration forecasting model in seven regions all include both air pollutants and meteorological factors. Among air pollutants, PM10 has a very important effect on PM2.5 concentration. Except region 1, the other regional PM2.5 concentration forecasting models all include PM10. The input variables in most regions also include O
3. Among meteorological factors, each region contains the barometric variables. The input variables in most regions include AH, AP and MINP. PM2.5 concentration forecasting models for region 1 and 3 include RAIN.
For each region, the smooth spline is used to fit the smoothing function for the determined input variables, and logarithmic connection function is also selected to establish GAM to forecast PM2.5 concentration in each region according to the training set. According to the fitting results, the effect of input variables in the forecasting model of each region on PM2.5 concentration is analyzed.
As shown in
Figure 5 and
Table 6. In region 1, AP positively affects PM2.5 concentration, and as AP increases, its influence on PM2.5 concentration gradually slows down. The relationship between PM2.5 concentration and MAXW, RAIN is complicated, which may change at some nodes, but in general, they all have the reverse effect. When AH is lower than 53%, it negatively affects PM2.5 concentration; which is lower than 90% and higher than 53%, it positively affects PM2.5 concentration; when it is higher than 90%, again into a reverse effect. In region 6, both PM10 and CO positively affect PM2.5 concentration, the influence gradually slows down as the concentration increases. The effect of MAXT and MINP on PM2.5 concentration will change with the increase of MAXT and MINP, not showing a single positive or negative trend.
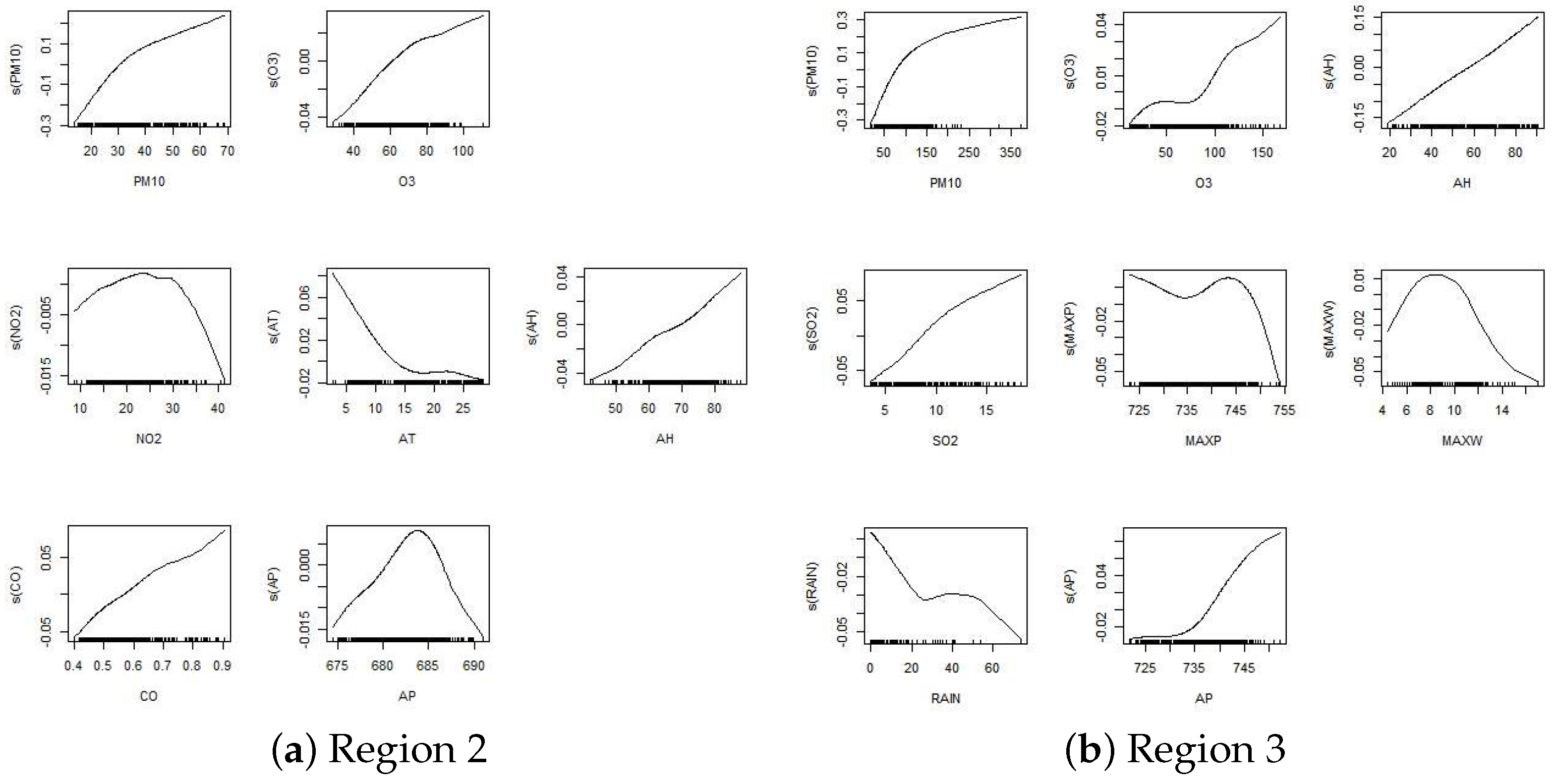
As shown in
Figure 6 and
Table 7. In region 2, PM10, O
3, AH and CO all positively affect PM2.5 concentration, while AT has a reverse impact. With the increase of AT, the effect on PM2.5 concentration gradually slows down. When the NO
2 concentration is lower than 26
, PM2.5 concentration rises with the increase of NO
2 concentration; when it is higher than 26
, it reduces with the increase of NO
2 concentration. AP’s influence on PM2.5 concentration in 684 hPa begins to change. With the increase of AP, PM2.5 concentration first increases and then decreases. In region 3, PM10, AP, AH, SO
2 and O
3 all positively affect PM2.5 concentration. When the MAXW is lower than 9 m/s, the PM2.5 concentration gradually rises with the increasing MAXW; when it is higher than 9 m/s, the PM2.5 concentration declines with the increasing MAXW. The effects of MAXP and RAIN on PM2.5 concentration are more complex, and will change continuously as they rise.
See
Figure 7 and
Table 8. In region 4, the PM2.5 concentration increases with the SO
2 concentration. When the concentration of PM10 exceeds 170
, its effect on PM2.5 concentration changes from positive to reverse. When AH exceeds 40%, its effect on PM2.5 concentration changes from reverse to positive. 70
is a turning point. With the increase of O
3 concentration, the effect on PM2.5 concentration with forward after reverse first. When MINP is lower than 730 hPa, it negatively affects on PM2.5 concentration; when MINP is higher than 730 hPa, it positively affects PM2.5 concentration. In region 5, PM10, AH and NO
2 all positively affect PM2.5 concentration. When the concentration of O
3 exceeds 110
, its effect on PM2.5 concentration changes from reverse to positive. The effect of MINP on the concentration of PM2.5 is relatively complex, rising as MINP changes constantly, but the overall trend is positive influence on first after the reverse effect. In region 7, PM10, MINP and AH all positively affect PM2.5 concentration, while AP inversely affects PM2.5 concentration. When MAXW exceeds 14 m/s, its effect on PM2.5 concentration changes from reverse to positive. When AT is lower than −9 °C, it positively affects on PM2.5 concentration; when it is between −9 °C and 20 °C, it negatively affects PM2.5 concentration; when it is higher than 20 °C, it becomes a positive effect again.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}