1. Introduction
The proportional hazards model [
1] is a regression model widely used in survival data analysis, whose main characteristic is that the covariates act multiplicatively on the hazard function. However, this characteristic cannot be met when survival times are discrete (intrinsically discrete or grouped into intervals) since the hazard function is limited in the interval (0,1). According to [
2], the use of statistical methods that are specially designed for discrete times has many advantages. Indeed, [
3] illustrated through simulation studies and application to real data that it is inadvisable to use a continuous model to analyze discrete data.
Given this situation and the importance of correctly treating discrete data to effectively model discrete time-to-event survival data, since the aforementioned model would not always be the most suitable, the proportional odds hazard model has been used with some frequency in the literature for this purpose. This model is an alternative version proposed by [
1] to be used when the time-to-event data are discrete, with the covariates having a multiplicative effect on the odds hazard.
A comprehensive study of the model in which various link functions are considered is presented in [
2], and the semiparametric extensions that the model can take on in [
4]. Applications of this model are given in [
5,
6,
7,
8].
The popularization of this model is due, in part, to the fact that users do not invest effort in reporting the baseline hazard, which receives less attention in these studies. However, according to [
9], the behavior of the hazard function is of potential medical interest because it is directly related to the course of a disease. To estimate this hazard function informatively (i.e., smoothly), a parametric model may be appropriate. In this context, parametric models in which the response variable is discrete to inform the baseline hazard of the model efficiently become fundamental, and in recent years a large number of research articles dealing with discrete distributions arising from the discretization of distributions of continuous random variables in a survival analysis context have emerged among these are: discrete Weibull distribution (DW) in [
10,
11], discrete Weibull geometric in [
12], exponentiated discrete Weibull (EDW) in [
13], discrete Gumbel in [
14], discrete Burr in [
15] and discrete log-logistic in [
16].
This work aims to formulate the proportional odds hazard model considering the discrete Weibull and discrete log-logistic distributions as baseline distributions, as well as the estimation via maximum likelihood of the model’s parameters for right-censored data. The Weibull distribution was chosen due to its popularity in modeling survival data and the log-logistic distribution, allowing model data with non-monotonic hazards. The quality of the model’s fit was assessed using simulation studies. Finally, the proposed methodology was illustrated using a data set whose response variable is the number of unsuccessful sessions before pain relief or reduction in patients with low back pain [
17].
4. Simulation Study
This section describes a simulation study to evaluate the behavior of the maximum likelihood estimators of the POHM-DW and POHM-G models. The study was conducted using data simulated in the R software [
18], and the survival times of these models were generated using the inverse transformation method. For more details, see [
19].
The survival time samples were simulated, considering two covariates: a numerical covariate,
, with a standard normal distribution and a dichotomous covariate,
, generated from a Bernoulli distribution with a probability of success
, the various parameters used take into account the baseline hazard of a WD and geometric distribution (particular case of WD considering
), more specifically the parameters of the two scenarios are shown in
Table 1.
To assess the behavior of the parameter estimators, the histograms of the parameter estimates of the different scenarios resulting from 1000 Monte Carlo replications will be evaluated for different sample sizes, i.e., n = 30, 50, 100, 250 and 500.
The mean of the parameter estimates, the mean squared error (MSE), and the coverage probability (CP) are shown alongside the above graphs. To construct the confidence intervals for calculating the CP, a confidence level of 0.95 was used. In addition, for the parameters of the probability distributions (
q and
), which are limited in parametric space, it is interesting to transform them to make them unrestricted. The appropriate transformations were made to the following parameters to construct the confidence intervals, as described by [
13].
The results from 1000 Monte Carlo replication that refer to the estimator
q,
,
and
are shown in
Figure 1,
Figure 2,
Figure 3 and
Figure 4 respectively.
When evaluating the estimators in general, it can be seen that the mean estimates are approximately equal to the respective true parameter values, regardless of the scenario and sample size. For the estimators referring to the baseline distribution, it can be seen that the mean values of the parameter estimates are concentrated close to the true parameter values, and as the sample size increases, the mean estimates of the MSEs become closer to zero, and the coverage probabilities converge to the adopted confidence level of 0.95.
For the estimators related to the covariates, where is associated with the numerical variable and associated with the dichotomous variable, similar behavior can be observed between the two and, in turn, satisfactory performance concerning the estimates and distributions of the data, just like the estimators referring to the baseline distribution.
When evaluating the estimators for the scenarios, it can be seen that the first scenario is associated with a circumstance in which the discrete Weibull distribution is adopted as the baseline distribution and the second in which the geometric distribution is adopted ( = 1), it can be seen from the estimates and graphs presented that both baseline distributions are suitable for modeling discrete time-to-event data.
The entire evaluation up to this point has been carried out without censoring. Therefore, considering the same scenarios and sample sizes in
Table 2 shows the estimates (average of parameter estimates, mean square error (MSE) and coverage probability (CP)) considering censoring percentages of 5, 10 and 30%. These estimates are the result of 1000 Monte Carlo replications.
In the presence of censoring, it can be seen that the higher the percentage of censoring, the greater the deviations of the estimates from the true value of the parameter. This behavior is expected since the higher the percentage of censoring, the more the empirical distribution of the simulated data differs from the theoretical distribution used to generate the data. The probability of coverage, which has a confidence level of 0.95, reinforces this statement. Note that as the amount of censoring increases, the greater the differences between the CP and the confidence level stipulated for constructing the intervals.
Another pertinent aspect is that, even with this shift in the true value of the parameter, the distribution of the estimators, even in the presence of censoring, is similar to the estimators in the absence of censoring (see, for example,
Figure 5, which shows the estimator of
, considering 30% censoring, which has the lowest CP values among the estimators).
Therefore, it can be seen from the results of the estimates and histograms, regardless of the scenario, censoring percentage, or sample size, that the shape of the empirical distribution of the estimators suggests adherence to the normal distribution. Thus, this distribution can be used for interval parameter estimation. As a result, hypothesis tests approximated by a normal distribution to verify the significance of the covariate can also be used in applications.
5. Application
Chronic low back pain is a major public health problem, as it can affect the quality of life and daily activities. Low back pain is also responsible for high rates of absenteeism from work.
The data set used in this study comes from [
17], whose time-to-event is the number of unsuccessful sessions before the session that reduced or relieved the low back pain. Here,
represents the patient who would have had pain relief in the very first session.
Observations were considered censored when the patient’s follow-up was interrupted for some reason unrelated to the event of interest in the study or after 11 unsuccessful sessions.
Table 3 shows the number of patients who experienced a reduction or relief of low back pain and the number and percentage of censored patient observations per number of unsuccessful sessions.
In addition to the number of unsuccessful sessions, the data set includes information on the various characteristics of the 150 patients (6 covariates). The covariates age, body mass index (BMI), and duration of pain were originally quantitative and were categorized. The patients were divided into two age groups, one for individuals aged up to 50 and the other aged 50 or over; into two BMI groups, non-obese (BMI less than 30) and obese (BMI greater than or equal to 30); into two pain time groups, one with less than five years of pain and the other with five years or more of pain. This information is summarized in
Table 4.
The application data was then adjusted using POHM-G, POHM-DW and POHM-DLL. Initially, these multiple models were adjusted to check the significance of their covariates (
to
). The
p-value results of the multiple models are shown in
Table 5.
According to the results in
Table 5, the covariates treatment and medicines are significant (at a significance level of 5%) in all three models.
On the other hand, the other covariates are not significant and would not influence the relief or reduction of the patient’s back pain. The significance test was therefore carried out by adjusting only the significant covariates, and the results are shown in
Table 6.
The results in
Table 6 show that the covariates treatment and medicines influence the relief or reduction of patients’ low back pain. Therefore, taking these covariates into account, the study to verify the assumption of proportional odds hazard will be carried out using the methods presented in
Section 3.2.
The assumption of proportional odds hazard will be verified for the data set, observing this proportionality between the levels of the covariate treatment and the covariate medicines and for each of the levels of these two covariates, using the graph:
and the hypothesis test proposed in (
25).
Since five consecutive tests were carried out, the Bonferroni correction will be used to correct the probability of incorrectly rejecting the null hypothesis, and thus the significance level will be
. The results are shown in
Figure 6, assuming:
level of the covariate treatment (
: placebo;
: active) and
level of the covariate medicines (
: yes;
: no).
It is important to note that the number of tests to be carried out would be eight, that is, four levels of covariates combined two by two, totaling six tests plus the two levels within the covariates. However, one of the covariate levels (; ) has a limited number of observations (<10), making it inadequate to construct graphs and test hypotheses.
The test results shown in
Figure 6 show that the proportional odds hazard assumption was not rejected for 3 of the five levels of covariates considered in this study (given a significance level of 1%). The
graphs shown corroborate that the proportional odds hazard was not rejected in the hypothesis tests, as the points are close to the fitted regression line.
The fact that most of the two-by-two levels studied have proportional odds hazard indicates that the data under study have proportional odds hazard, which justifies using this methodology in this data set.
Thus, for the POHM-G, POHM-DW, and POHM-DLL models as a whole, considering the two significant covariates, the point and interval estimates of their parameters were calculated and are shown in
Table 7.
The estimates in
Table 7, provide an interpretation of the odds hazard for the different categories of the covariates under study. Taking the POHM-DW model and the treatment covariate as an example. Since
represents the ratio of the odds hazard of the different groups, constant over time, considering that the covariate medicines is constant. Assuming the group of patients with active treatment (
). In this context, the odds hazard for patients on active treatment is
times the odds hazard for patients on placebo treatment.
Therefore, the odds hazard of the patient having active treatment is 1.0448 times greater than the odds hazard of the patient having placebo treatment (). In this circumstance, the odds hazard for patients who do not use medication is 1.1282 times greater than the odds hazard for patients who do use medication.
The same interpretation can be made for the other models with different numerical values. However, the odds hazard remain higher for active treatment and patients not taking medication.
To assess the fit of the models to the data, the survival graphs of the Kaplan-Meier estimator (K-M) [
20] and the survival curves of the models under study were drawn for each of the covariate levels to analyze the set of graphs and interpret their overall fit (
Figure 7).
Figure 7 shows that the models fit the data well, with the survival estimates of these models always being close to the empirical estimates, with a positive highlight for the POHM-DLL and POHM-DW models, where the survival estimates are closer to the survival estimates of the Kaplan-Meier estimator.
In order to compare with pre-existing discrete models in the literature, regression models were fitted taking into account the DW (expressions (
5)–(
7)) and geometric distribution (DW with
) with the covariates associated in the parameter
q through a logit link function, i.e.,
These models will be referred to respectively as the discrete Weibull regression model (DWRM) and the geometric regression model (GRM).
In addition, we also consider the DLL (expressions (
8)–(
10)) with the covariates associated in the parameter
through a logarithmic link function, i.e.,
This model will be called the discrete log-logistic regression model (DLLRM).
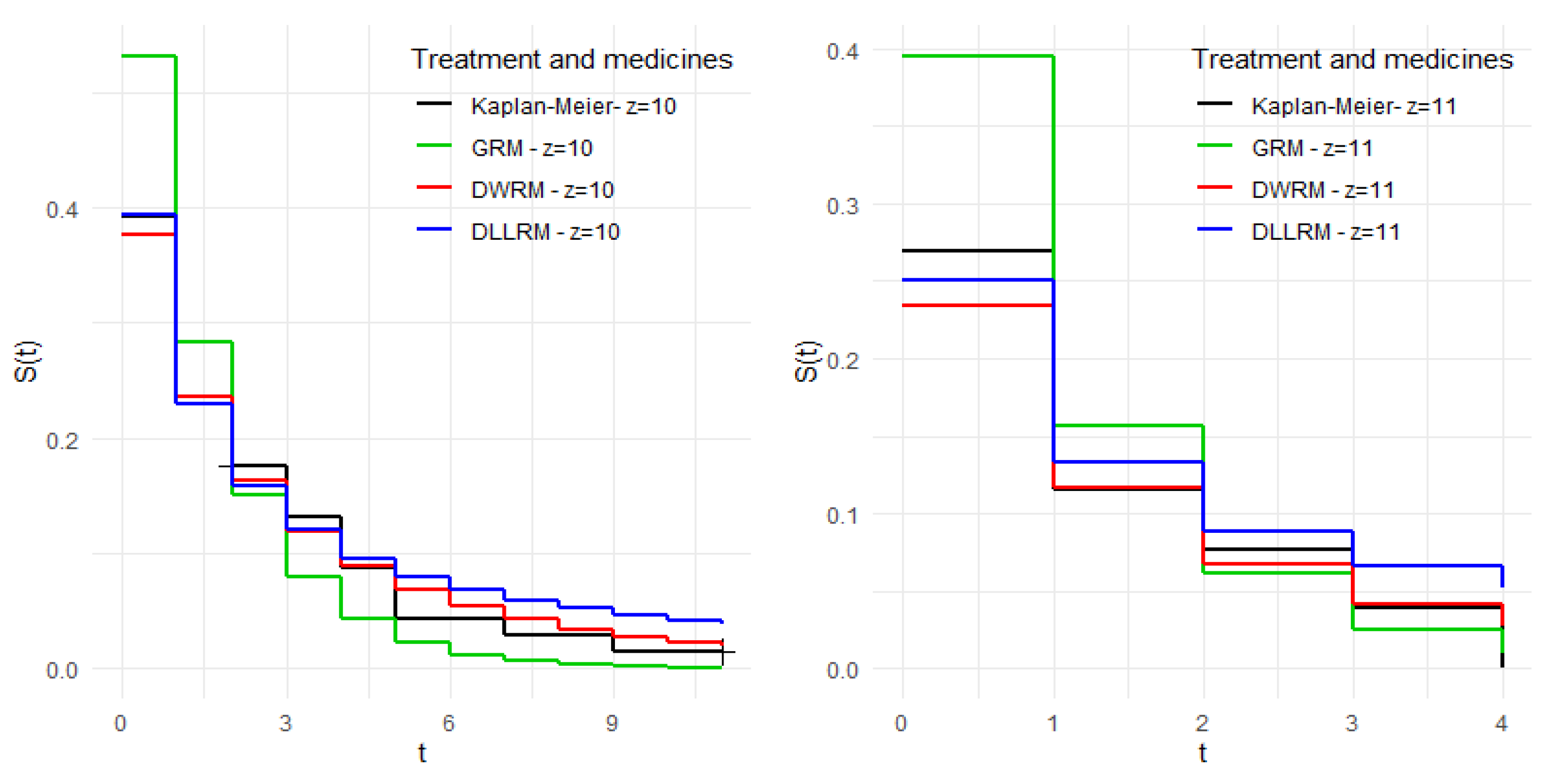
Note, through
Figure 8, that for levels
;
and
;
, the so-called traditional models behaved similarly to the model under study. However, for the other levels, the estimates of these models are more distant from the empirical estimates compared to the model under study, providing indications that the proportional odds hazard structure for discrete data provides a better fit to the data when compared to traditional discrete models.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}