1. Introduction
Matrix equations are often used in mathematics and engineering applications, such as control theory, signal processing and computational mathematics [
1,
2,
3,
4]. For example, the forward and backward periodic Sylvester matrix equations (PSMEs) with the following forms
and
are an indispensable part of pole assignment and the design of state observers for linear discrete periodic systems [
5]. Thus, studying the computational methods of matrix equations has become an important subject in the field of computational mathematics and control. For matrix equations, computing their exact solutions is very meaningful for many practical problems. However, in many applications, such as stability analysis of control systems, it is usually not necessary to calculate the exact solution, as the approximate solution is sufficient. Therefore, the research of iterative solutions to matrix equations has attracted many researchers [
6,
7,
8,
9,
10,
11,
12].
One of the important ways to study the approximate solutions of matrix equations is to establish iterative methods. In recent years, many researchers have proposed a great deal of iterative methods to solve different kinds of Sylvester matrix equations. For the generalized coupled Sylvester matrix equations
where
,
and
, Ding and Chen [
13] applied the hierarchical identification principle and introduced the block matrix inner product to propose the GI algorithm. Based on the idea of the GI algorithm, some researchers established many improved versions of the GI algorithm and investigated their convergence properties [
14,
15]. To improve the convergence rate of the GI algorithm, Zhang [
16] proposed the residual norm steepest descent (RNSD), conjugate gradient normal equation (CGNE) and biconjugate gradient stabilized (Bi-CGSTAB) algorithms to solve the matrix in Equation (
1). Subsequently, Zhang [
17] constructed the full-column rank, full-row rank and reduced-rank gradient-based algorithms, with the main idea of them being to construct an objective function and use the gradient search. Afterward, Zhang and Yin [
18] developed the conjugate gradient least squares (CGLS) algorithm for Equation (
1), which can be convergent within the finite iteration steps in the absence of round off errors.
The generalized coupled Sylvester-conjugate matrix equations have the following form:
where
,
and
. The matrix in Equation (
2) can be regarded as the generalization of Equation (
1) in the complex field. For the matrix in Equation (
2), Wu et al. [
19] extended the GI algorithm to solve it and derived the sufficient condition for the convergence of the GI algorithm. Due to the fact that the sufficient condition in [
19] is somewhat conservative, Huang and Ma [
20] established the sufficient and necessary conditions for convergence of the GI algorithm based on the properties of the real representation of a complex matrix and the vec operator. Also, they made use of different definitions of the real representation to derive another sufficient and necessary condition for the convergence of the GI algorithm. In [
21], Huang and Ma introduced
l relaxation factors into the GI algorithm and proposed two relaxed gradient-based iterative (RGI) algorithms. They proved that the RGI algorithms are convergent under suitable restrictions in light of the real representation of a complex matrix and the vec operator. Quite recently, Wang et al. [
22] developed a cyclic gradient-based iterative (CGI) algorithm by introducing a modular operator, which is different from previous iterative methods. The most remarkable advantage of the CGI algorithm is that less information is used in each iteration update, which helps save memory and improve efficiency.
In addition, the generalized, coupled Sylvester-transpose matrix equations
where
,
and
are related to fault detection, observer design and so forth. Due to the important role of the generalized, coupled Sylvester-transpose matrix equations in several applied problems, numerous methods have been developed to solve them. For example, Song et al. [
23] constructed the GI algorithm for the matrix in Equation (
3) by using the principle of hierarchical identification. According to the rank of the related matrices of the matrix in Equation (
3), Huang and Ma [
24] developed three relaxed gradient-based iterative (RGI) algorithms recently by minimizing the objective functions.
In [
25], Beik et al. considered the following matrix equations:
where
and
,
are the known matrices with suitable dimensions in a complex number field,
is a group of unknown matrices and
represents the conjugate transpose of the matrix
. The matrix in Equation (
4) is quite general and includes several kinds of Sylvester matrix equations, and it can be viewed as a general form of the aforementioned matrices in Equations (
1)–(
3). By using the hierarchical identification principle, the authors in [
25] put forward the GI algorithm over a group of reflexive (anti-reflexive) matrices.
Inspired by the above work, this paper focuses on solving the iterative solution of the generalized coupled conjugate and transpose Sylvester matrix equations:
where
and
are the known matrices and
for
are the unknown matrices that need to be determined. When
, Wang et al. [
26] presented the relaxed gradient iterative (RGI) algorithm for Equation (
5), which has four system parameters. Note that the matrices in Equations (
1)–(
3) are special cases of the matrix in Equation (
5), and thus the results obtained in this work contain the existing ones in [
20,
23,
24,
27]. Owing to the fact that the convergence speed of the GI algorithm is slow in many cases, it is quite meaningful to further improve the numerical performance of the GI algorithm for the matrix in Equation (
5). According to [
21,
24,
26,
28,
29], it can be seen that the relaxation technique can ameliorate the numerical behaviors of the existing GI-like algorithms. Then, this motivated us to apply the weighted relaxation technique to the GI algorithm. By using different step size factors and the weighted technique, we construct the weighted, relaxed gradient-based iterative (WRGI) algorithm for solving the matrix in Equation (
5). The WRGI algorithm contains s relaxation factors. When all relaxation factors are equal, the WRGI algorithm will reduce to the GI one proposed in [
25]. In [
25], the optimal convergence factor of the GI algorithm was not derived. Compared with the GI algorithm in [
25], the WRGI algorithm proposed in this paper can own a higher computational efficiency, and its convergence properties are analyzed in detail, including the convergence conditions, optimal parameters and corresponding optimal convergence factor. The proposed WRGI algorithm has a faster convergence rate than the GI one by adjusting the values of the relaxation factors so it is more conducive to solving matrix equations in control theory, signal processing and computational mathematics, among other applications. The main contributions of this paper are given below:
The rest of this paper is organized as follows. In
Section 2, some definitions and previous results are given, and the GI algorithm that has been proposed before is reviewed. In
Section 3, we first design a new algorithm referred to as the WRGI algorithm to solve the matrix in Equation (
5). Then, we prove that the WRGI algorithm is convergent for any started matrices under proper conditions, and we explicitly give the optimal step factor such that the convergence rate of the WRGI algorithm is maximized.
Section 4 gives two numerical examples to demonstrate the effectiveness and advantages of the proposed WRGI algorithm. Finally, we give some concluding remarks to end this paper in
Section 5.
2. Preliminaries
In this section, as a matter of convenience to discuss the main results of this paper, we describe the following notations which will be used throughout this paper. Let be the set of all complex matrices. For a given matrix , some related notations are the following:
denotes the conjugate of the matrix A;
stands for the transpose of the matrix A;
represents the conjugate transpose of the matrix A;
denotes the inverse of the matrix A;
denotes the Frobenius norm of the matrix A;
denotes the spectrum norm of the matrix A;
indicates the maximum singular value of the matrix A;
indicates the minimum singular value of the matrix A;
stands for the spectral radius of the matrix A;
stands for the spectrum of the matrix A;
stands for the rank of the matrix A.
Moreover, some useful definitions and lemmas are given below:
Definition 1 ([
30])
. For two matrices and , the Kronecker product of the matrices E and F is defined as follows: Definition 2 ([
27])
. Let be the n-dimensional column vector whose ith element of is one, and other elements are zero. Then, the vec permutation matrix can be defined as follows: Definition 3 ([
30])
. Let , with being the ith column of A. The vector-stretching function of A is defined as follows: Lemma 1 ([
20])
. Let be a matrix equation, with the matrices C and D being full-column rank and full-row rank, respectively. Then, the iterative solution produced by the GI iteration processconverges to the exact solution of for any initial matrix if and only ifIn addition, the optimal step size is Lemma 2 ([
30])
. Let , and . Then, we have the following:- (i)
- (ii)
Lemma 3 ([
19])
. Let . If , then Next, we introduce two definitions of the real representation of a complex matrix. For
,
A can be uniquely expressed as
, where
. We define the operators
and
as follows:
It can be seen from Equation (
11) that the sizes of
and
are two times that of
A. Then, by combining Equation (
11) with the definition of the Frobenius norm, we can obtain
Aside from that, for the identity matrix
with the matrix order
n, we define the following matrices:
The properties of the real representation of several complex matrices are given by the following lemma:
Lemma 4 ([
21])
. Let and . Then, the following statements hold:- (1)
- (2)
If is nonsingular, then .
- (3)
.
- (4)
If , then it holds that and .
The lemma below gives the norm relationship between the block matrices and its submatrices:
Lemma 5 ([
31])
. Let B be a block-partitioned matrix withand be a matrix with a proper size. Then, it holds thatIf , or if B is a vector, then we have The following result gives the norm inequality for the p norms of the block matrix and its submatrices, which is essential for analyzing the convergence of the WRGI algorithm:
Lemma 6 ([
21])
. Let be a partitioned matrix with the form in Equation (13), and let the orders of the matrices be compatible. Then, for any deduced q norm, we have 3. The Weighted, Relaxed Gradient-Based Iterative (WRGI) Algorithm and Its Convergence Analysis
In this section, we first propose the weighted, relaxed gradient-based iterative (WRGI) algorithm to solve the matrix in Equation (
5) based on the hierarchical identification principle. Then, we discuss the convergence properties of the WRGI algorithm, which include the convergence conditions, optimal step size and the corresponding optimal convergence factor of the WRGI algorithm.
First, we define the following intermediate matrices for
by applying the hierarchical identification principle:
For the sake of the following discussions, we define
Then, Equations (
14)–(
17) can be written as
Therefore, the matrix in Equation (
5) can be decomposed into the following matrix equations
for
. By applying Lemma 1 to Equations (
22)–(
25), we can construct the recursive forms as follows
for
, where
is a step size factor.
For convenience, we define the following notations:
Substituting Equations (
18)–(
21) into Equations (
26)–(
29), respectively, and then using
and
to replace
for
gives
By taking the average of
and
in the above equations, one can obtain the following iterative algorithm:
Then, we construct the calculation forms of
by introducing the suitable relaxation parameters and using the balanced strategies
with
being the weighted relaxation factors.
Remark 1. We apply Lemma 1 to Equations (22)–(25) and then use the same step size factor μ to establish the iterative sequences in Equations (26)–(29), which is conducive to deducing the convergence conditions of the proposed algorithm. It is noteworthy that we also can use different step size factors in Equations (26)–(29) and design a new algorithm, but it may be difficult to derive the convergence conditions of the new algorithm this way. Using different step size factors to construct iterative sequences and proposing a new algorithm will be the direction and focus in our future work. Based on the above discussions, we obtain the following weighted, relaxed gradient-based iterative (WRGI) algorithm (Algorithm 1) to solve the generalized coupled conjugate and transpose Sylvester matrix equations.
| Algorithm 1: The weighted, relaxed gradient-based iterative (WRGI) algorithm |
Step 1: Given the matrices and , two constants and and the relaxation parameters , choose the initial matrices , and set ; Step 2: If , then stop; otherwise, go to Step 3; Step 3: Compute using
Step 4: Set and return to Step 2. |
In the following, we will discuss the convergence properties of the WRGI algorithm by applying the properties of the real representation of a complex matrix and the Kronecker product of the matrices. For convenience, we introduce the following notations. Let
and
where
Theorem 1. The matrix in Equation (5) has a unique solution if and only if (that is, R is of a full-column rank) and . The unique solution is given byand the corresponding homogeneous matrix equationshave a unique solution , whereand R is defined by Equation (31). Proof. Applying the real representation of the complex matrix to Equation (
5) leads to
By using the Kronecker products of the matrices and the vector-stretching operator in the above equations, we have
where
, which can be equivalently transformed into the following linear system:
Therefore, Equation (
33) has a unique solution if and only if
R has a full-column rank and
. In this case, the unique solution in Equation (
32) for the matrix in Equation (
5) can be obtained. The conclusions follow immediately. □
Based on the properties of the matrix norms and Algorithm 1, we establish the sufficient condition for the convergence of the proposed WRGI algorithm in the following theorem:
Theorem 2. Suppose that the matrix in Equation (5) has a unique solution . Then, the iterative sequences generated by Algorithm 1 converge to for any initial matrices if μ satisfies Proof. Define the error matrices
and
It follows from Algorithm 1 that
and
Taking the Frobenius norm in Equation (
36) and using the properties of the norm leads to
It is not difficult to verify that
and
are real. Then, under Lemma 3, it holds that
and
With the relations in Equations (
38) and (
39), it follows from Equation (
37) that
By making use of the relation in Equation (
12), as well as Lemmas 2 and 4, we have
where
V is defined by Equation (
30) and
By applying the properties of the 2-norms of the matrices and vectors, we obtain that
That aside, in light of the relation in Equation (
12), we deduce that
Substituting Equation (
43) into Equation (
42) leads to
By combining Equations (
40) and (
44) and changing the order of addition, we derive
If the parameter
is chosen to satisfy
then
and therefore
According to the convergence theorem of series, we have
. Having in mind that the matrix in Equation (
5) has a unique solution, then it follows from the definition of
in Equation (
34) that
The proof is completed. □
In the sequel, by applying the properties of the real representation of a complex matrix and the vector-stretching operator, we study the necessary and sufficient condition for the convergence of the WRGI algorithm. This result can be stated as in Theorem 3:
Theorem 3. Suppose that the matrix in Equation (5) has a unique solution . Then, the iterative sequences generated by Algorithm 1 converge to for any initial matrices if and only if Proof. For convenience, we define
From Equation (
36) and the definition in Equation (
34) for
in Theorem 2, it can be obtained that
Then, by combining the real representation with Equation (
47) and applying Lemma 4, we obtain
By taking the vector-stretching operator on both sides of Equation (
48) and using Lemma 2, we have
for
. This gives the following result:
where
and
R is defined by Equation (
31).
Equation (
50) implies that the sufficient and necessary condition for the convergent of Algorithm 1 (the WRGI algorithm) is
Since
is a symmetric matrix, it holds that
where
. Then,
is equivalent to
It follows from Equation (
52) that
After simple computations, we derive
which completes the proof. □
Remark 2. When the relaxation parameters of the WRGI algorithm are , then the condition in Equation (46) reduces to the following condition: Based on Theorem 3, we will study the optimal step size and the corresponding optimal convergence factor of the WRGI algorithm in the following theorem:
Theorem 4. Assume that the conditions of Theorem 2 are valid. Then, it holds thatwhere In addition, the optimal convergence factor is Under this situation, the convergence rate is maximized, and we have Proof. Due to the fact that
is symmetric, it follows that
In light of Equations (
50) and (
56), one has
where
Combining the relations in Equations (
12) and (
57) results in
where
Having in mind that
, then it follows from Equation (
58) that
It can be seen from Equation (
59) that the smaller the
, the faster the convergence rate of the WRGI algorithm. Direct calculations give that
is minimized if and only if
from which one can deduce that
If
, then we have
Substituting Equation (
61) into Equation (
59) yields Equation (
55). The proof is completed. □
Although the convergence conditions of the WRGI algorithm are given in Theorems 2 and 3, the Kronecker product and the real representations of the system matrices are involved in computing and . This may bring about a high dimensionality problem and lead to high computing consumption. To overcome this drawback, we will give a sufficient condition for the convergence of the proposed WRGI algorithm below.
Corollary 1. Suppose that the matrix in Equation (5) has a unique solution . Then, the iterative sequences generated by Algorithm 1 converge to for the arbitrary initial matrices if Proof. According to Lemmas 4–6 and the fact that
, we have
Substituting Equation (
62) into the relation in Equation (
46) gives the conclusion of this corollary. □
4. Numerical Experiments
In this section, two numerical examples are provided to verify the effectiveness and advantage of the proposed WRGI algorithm for solving the matrix in Equation (
5) in terms of the number of iterations (IT) and the computing times in seconds (CPU). All the computations were performed in MATLAB R2018b on a personal computer with an AMD Ryzen 7 5800H, where the CPU was 3.20 GHz and the memory was 16.0 GB.
Example 1 ([
32])
. Consider the generalized coupled conjugate and transpose Sylvester matrix equationswith the following coefficient matrices:It can be verified that the unique solution of this matrix equation is
We take the initial iterative matrices
and set
to be the termination condition with a constant
, where
Here, the prescribed maximum iterative number is = 20,000, and represents the kth iteration solution.
It follows from Remark 2 that the WRGI algorithm reduces to the GI one [
25] as
. In this case, according to Theorem 4, the optimal convergence factor is
. However, the optimal convergence factor
calculated by Theorem 4 may not minimize the IT of the GI algorithm, and the reason for this is that there are errors in the calculation process. Thus, the parameter
adopted in the GI algorithm is the experimentally found optimal one, which minimizes the IT of the GI algorithm. After experimental debugging, the experimental optimal parameters of the GI algorithm are
and
when
and
, respectively. Aside from that, we can obtain that the optimal parameter of the WRGI algorithm is
in terms of Theorem 4. Owing to the existence of computation errors, the parameter
in the WRGI algorithm is adopted to be the experimentally found one as demonstrated above. Through experimental debugging, the experimental optimal parameters of the WRGI algorithm are
and
when
and
, respectively. Under these circumstances, the relaxation factors are taken to be
,
and
.
Table 1 lists the numerical results of the GI and the WRGI algorithms. As observed earlier in the comparisons of the GI and the WRGI algorithms in
Table 1, the two tested algorithms were convergent for all cases, and the IT of them increased gradually with the decreases in the value of
. Additionally, it can be seen from
Table 1 that the proposed WRGI algorithm performed better than the GI one with respect to the IT and CPU times. This implies that by applying the weighted relaxation technique, the WRGI algorithm can own better numerical behaviors than the GI one.
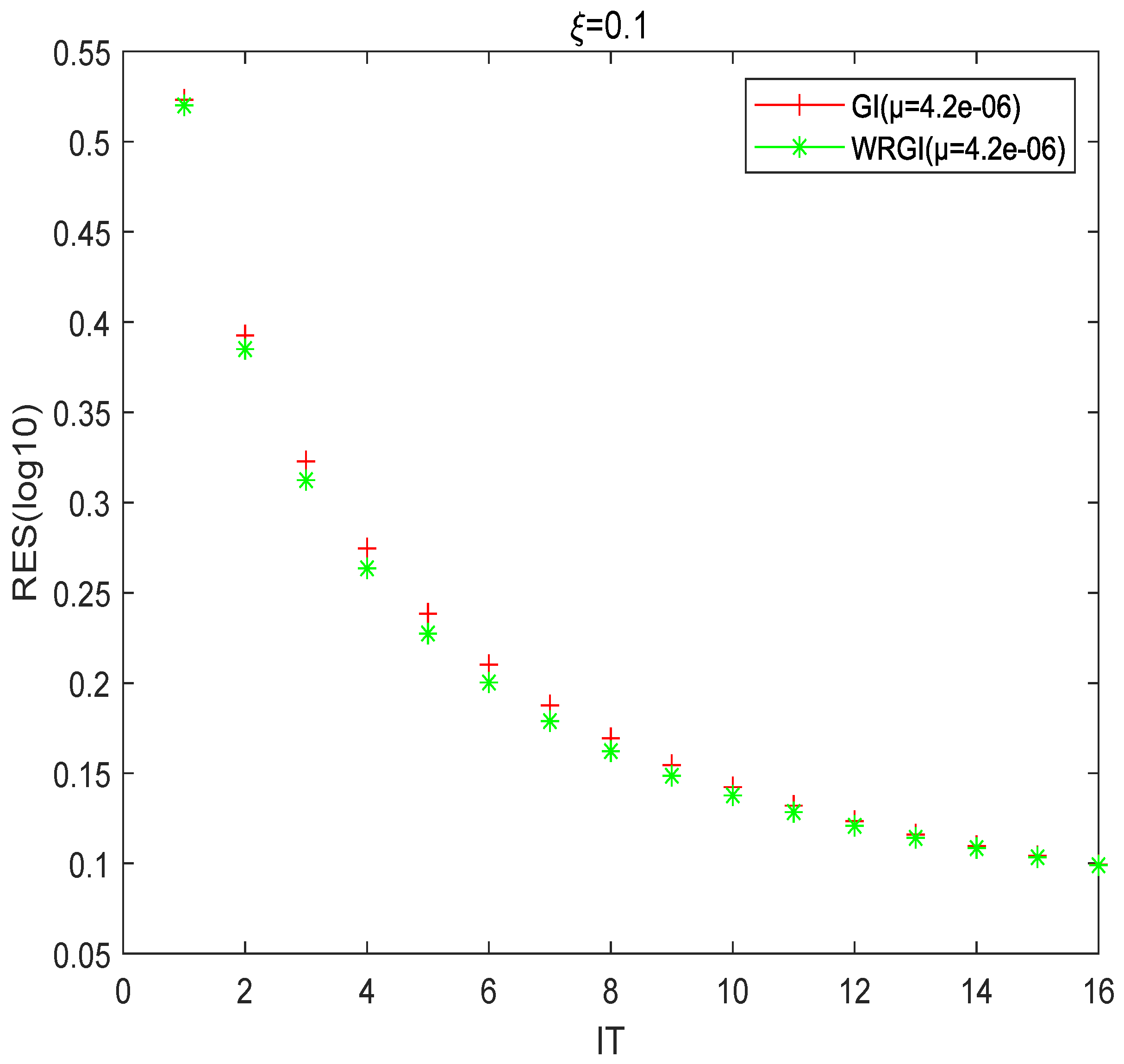
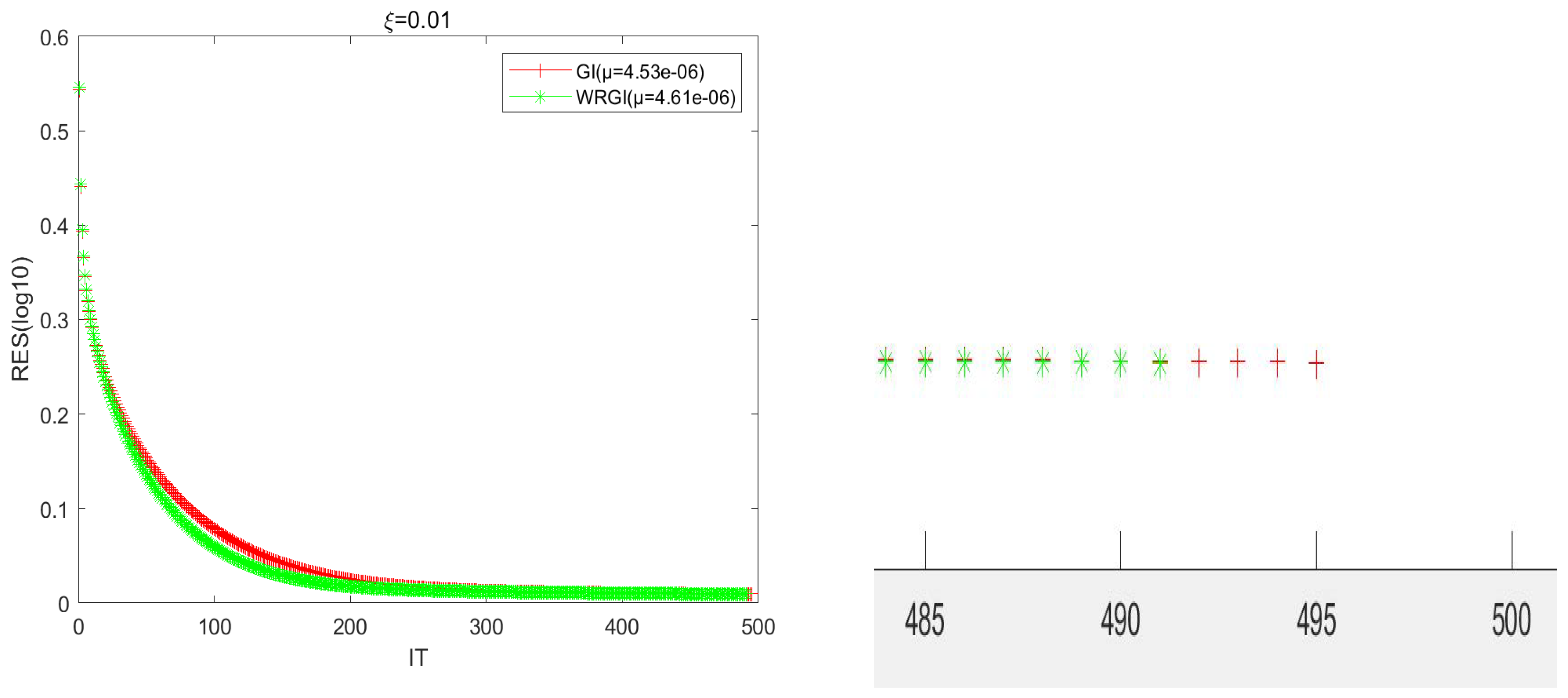
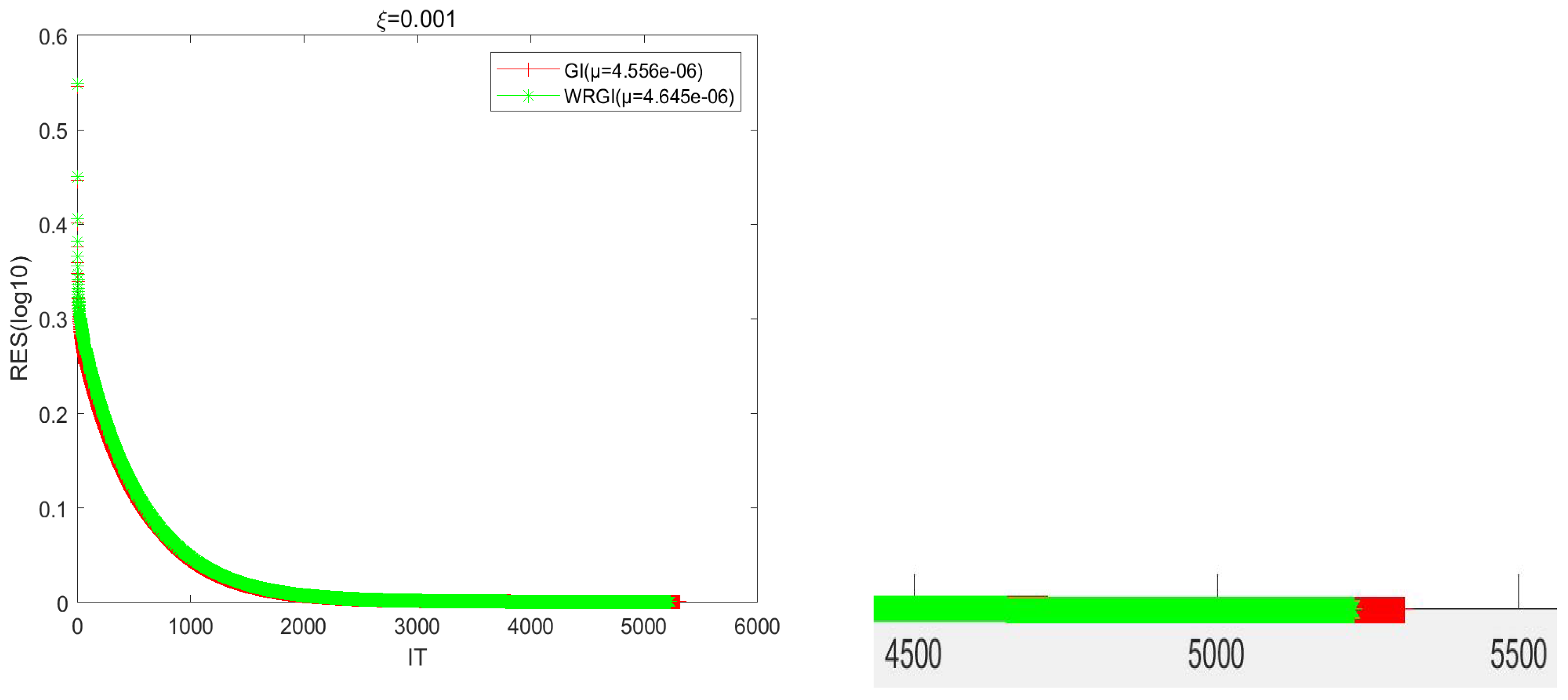
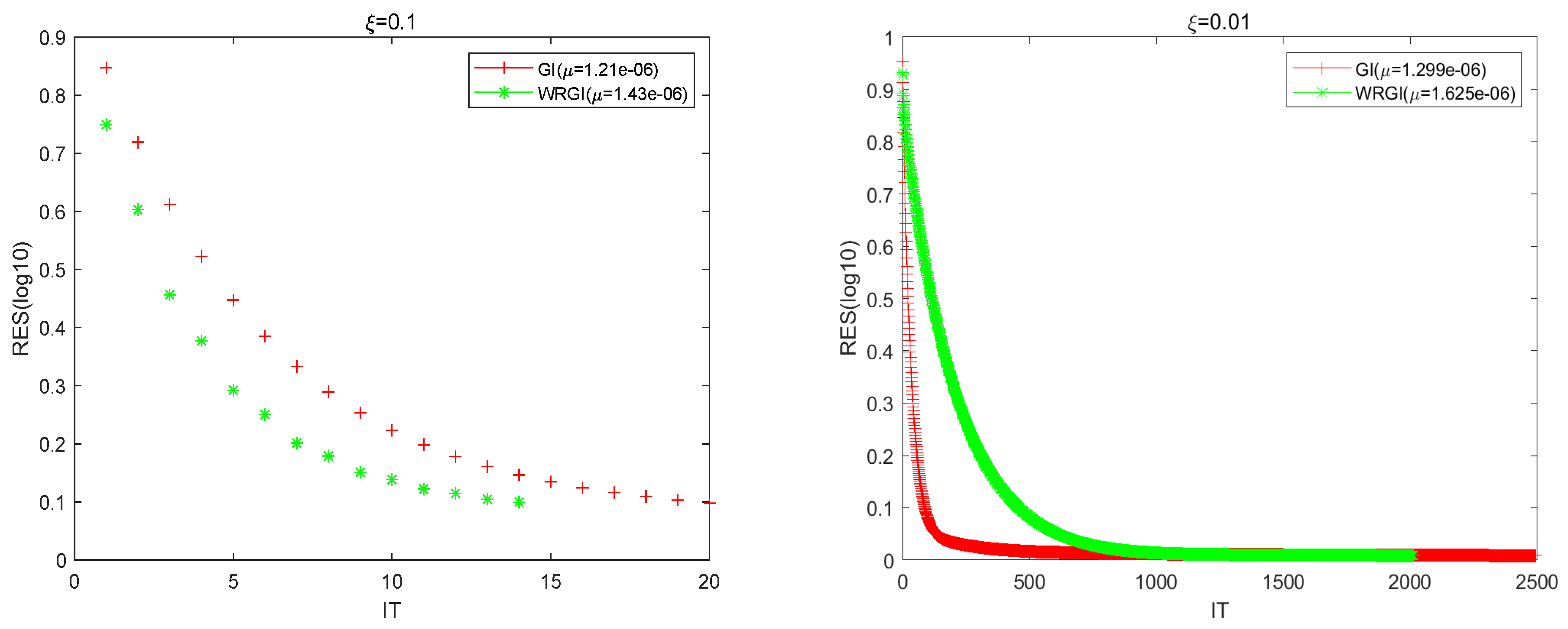
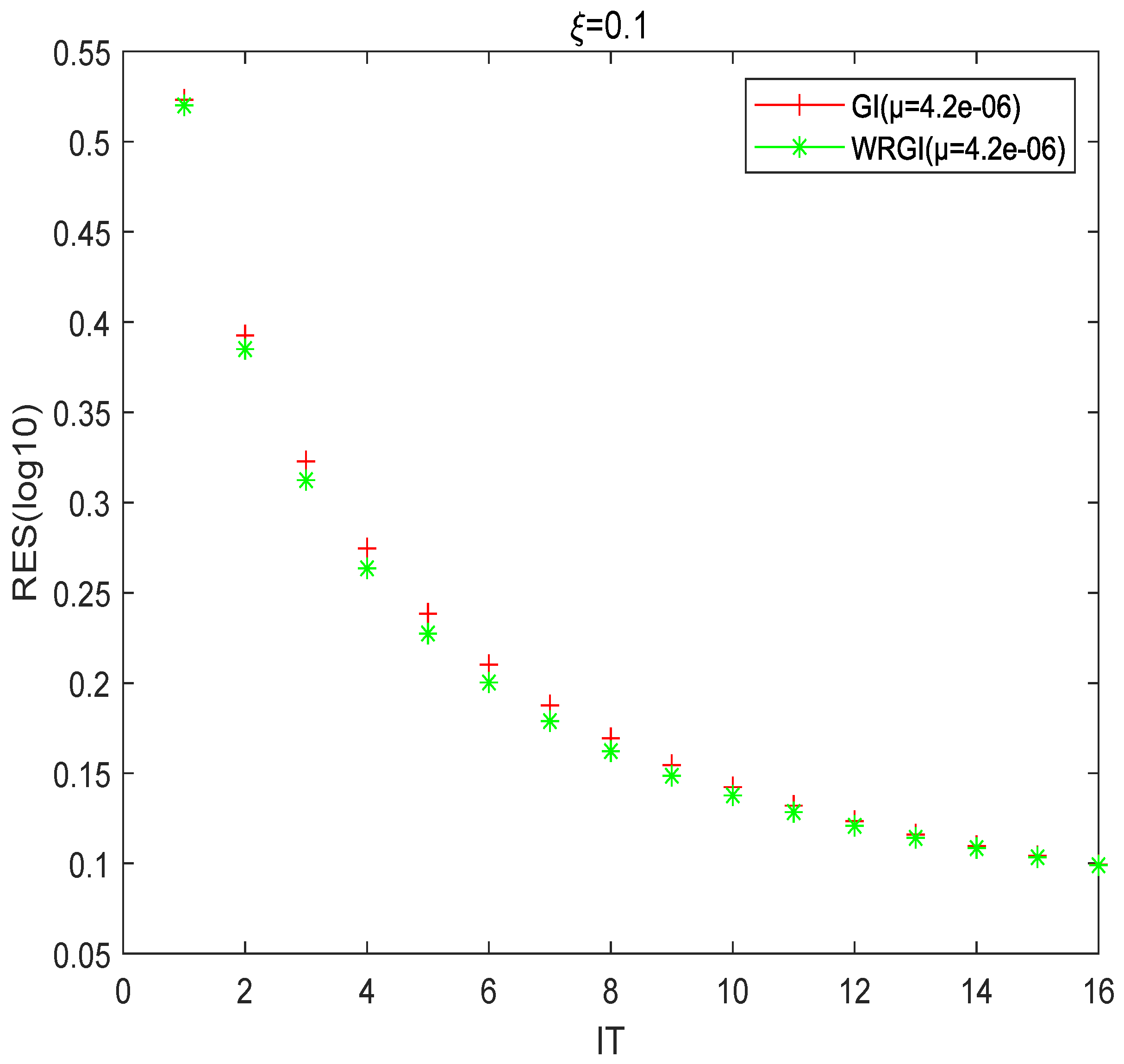
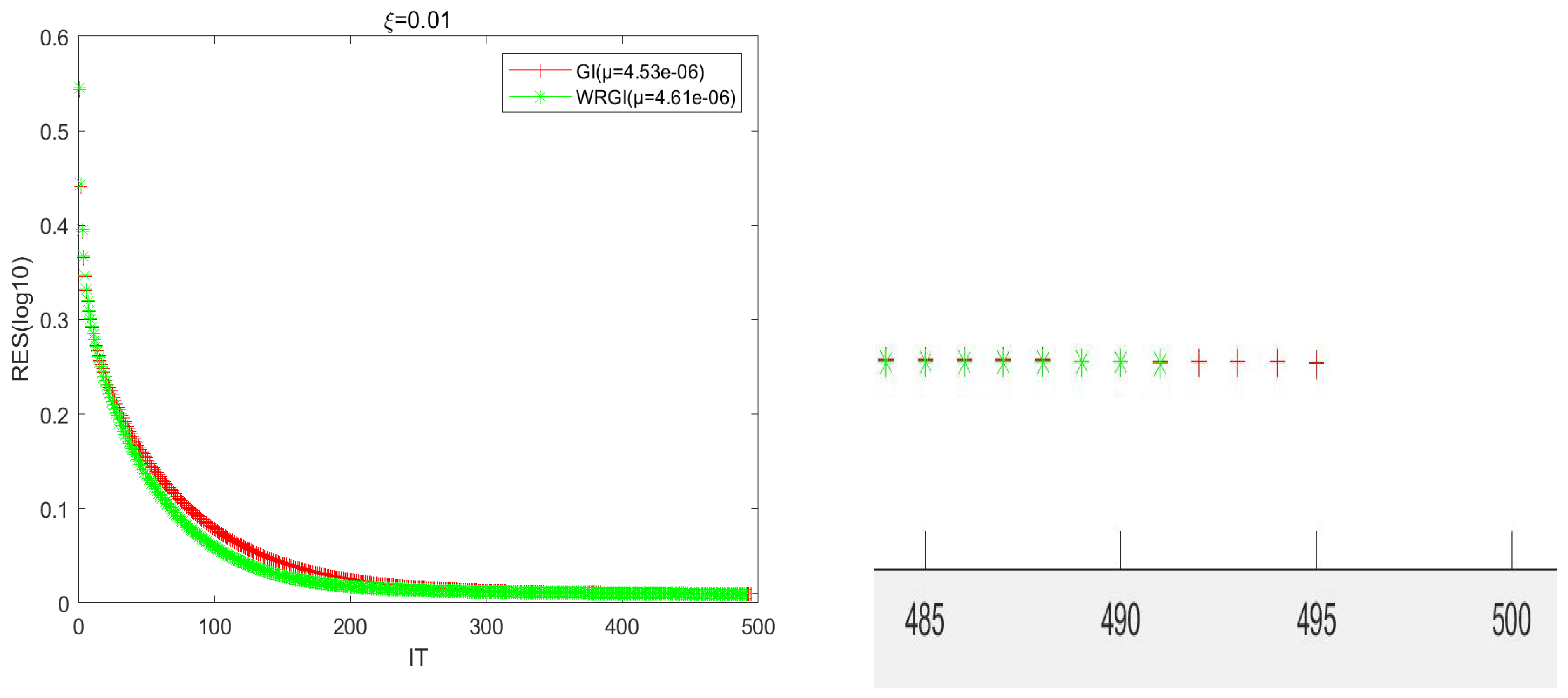
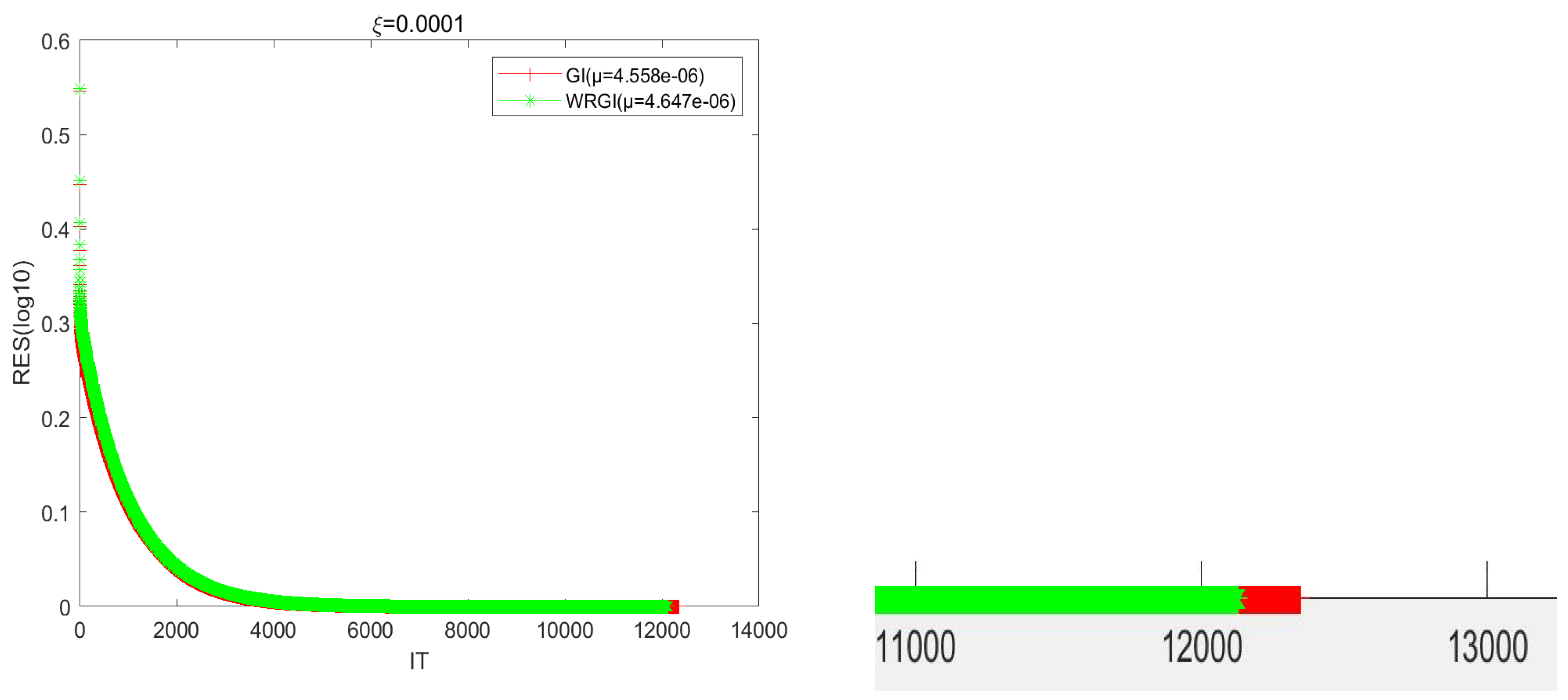
To better validate the advantage of the WRGI algorithm,
Figure 1,
Figure 2,
Figure 3 and
Figure 4 describe the convergence curves of the GI and WRGI algorithms for four different values of
. These curves reflect that the WRGI algorithm is convergent and its convergence speed is faster than the GI one, except for the case of
. Additionally, the advantage of the WRGI algorithm becomes more pronounced as the value of
decreases. This is consistent with the results in
Table 1.
Example 2. We consider the generalized coupled conjugate and transpose Sylvester matrix equationswith the coefficient matricesThe unique solution for these matrix equations is In this example, we chose
as the initial matrices and took
as the termination condition with a positive number ξ, where
and
and the prescribed maximum iterative number was
= 20,000, while
denotes the kth iteration solution.
When , the WRGI algorithm degenerates into the GI one, and the optimal convergence factor calculated by Theorem 4 is . When or , the optimal parameter of the WRGI algorithm is in light of Theorem 4. Due to the existence of computation errors, as in Example 1, the parameters used in the GI and WRGI algorithms for Example 2 are the experimentally found optimal ones which minimize the IT of the tested algorithms. Through experimental debugging, the experimental optimal parameters of the GI algorithm were and for and , respectively. And when and , the experimental optimal parameters of the WRGI algorithm were and for and , respectively.
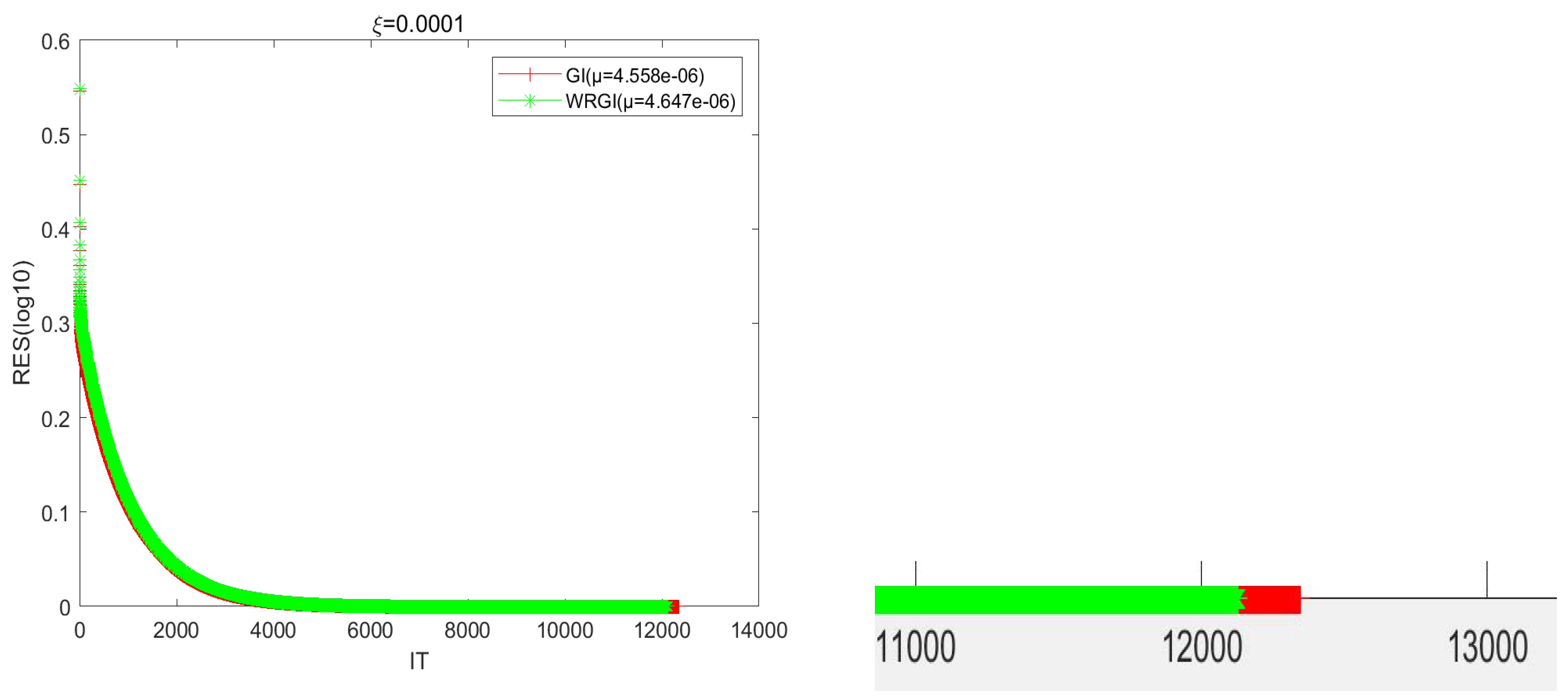
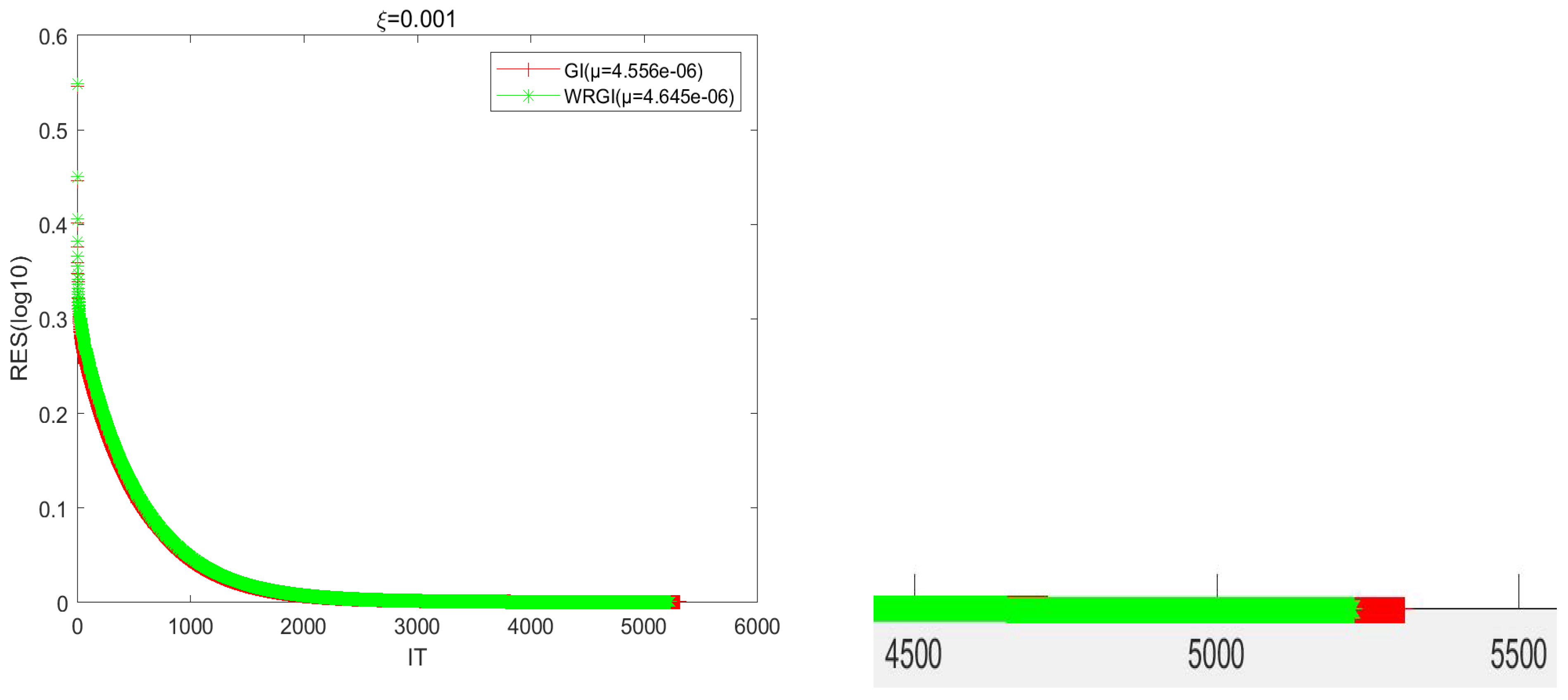
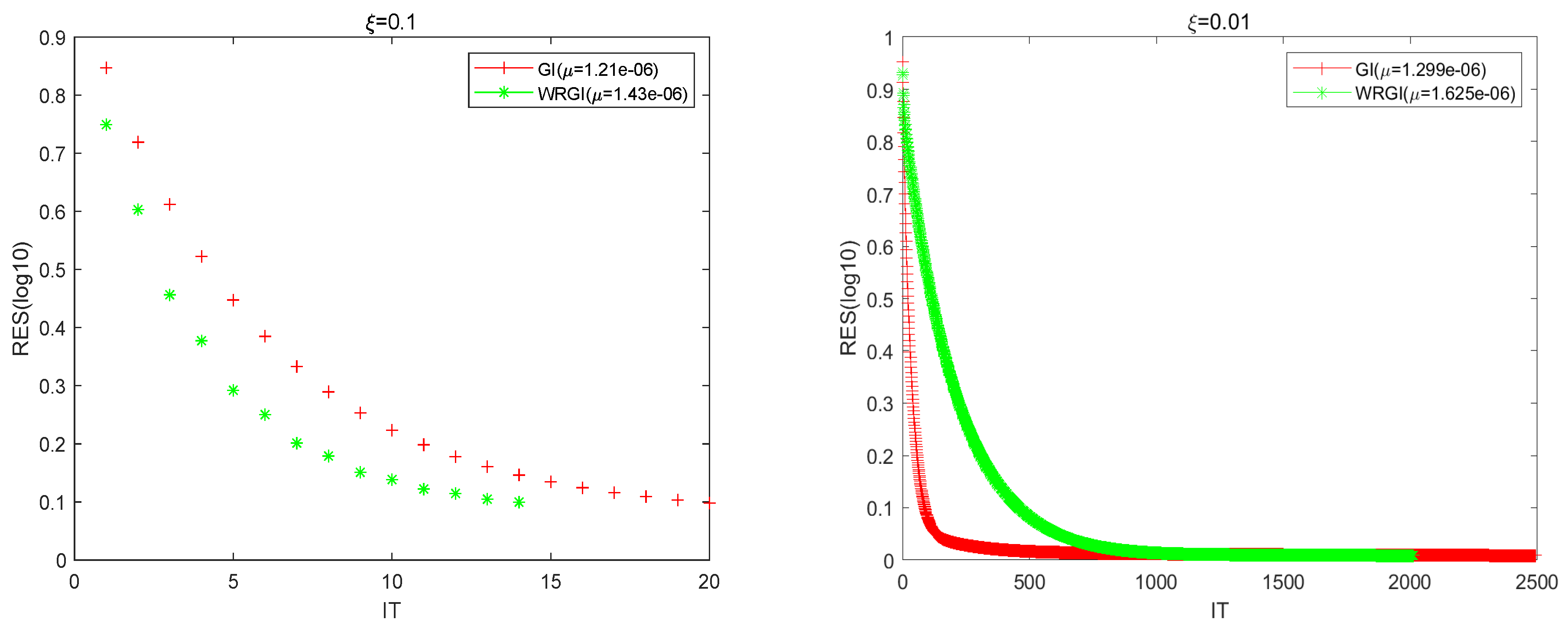
In
Table 2, we compare the numerical results of the GI and WRGI algorithms to solve the generalized coupled conjugate and transpose Sylvester matrix equations in Example 2 with respect to two different values of ξ. Since the IT of the algorithms exceeded the maximum number of iterations when
and
, we did not list the corresponding numerical results here. From the numerical results listed in
Table 2, we can conclude that when the value of ξ decreases, the IT and CPU times of the tested algorithms increase. The changing scope of the IT of the proposed WRGI algorithm was smaller than that for the GI one. In addition, the WRGI algorithm outperformed the GI one from the point of view of computing efficiency, and the advantage of the WRGI algorithm became more pronounced as ξ became small.
Figure 5 describes the convergence curves of the GI and WRGI algorithms for Example 2 with
and
, respectively. It follows from
Figure 5 that the error curves of the WRGI algorithm decreased faster than those for the GI one, which means that the proposed WRGI algorithm is superior to the GI one in terms of IT.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}