Abstract
Probabilistic interval ordering, as a helpful tool for expressing positive and negative information, can effectively address multi-attribute decision-making (MADM) problems in reality. However, when dealing with a significant number of decision-makers and decision attributes, the priority relationships between different attributes and their relative importance are often neglected, resulting in deviations in decision outcomes. Therefore, this paper combines probability interval ordering, the prioritized aggregation (PA) operator, and the Gauss–Legendre algorithm to address the MADM problem with prioritized attributes. First, considering the significance of interval priority ordering and the distribution characteristics of attribute priority, the paper introduces probability interval ordering elements that incorporate attribute priority, and it proposes the probabilistic interval ordering prioritized averaging (PIOPA) operator. Then, the probabilistic interval ordering Gauss–Legendre prioritized averaging operator (PIOGPA) is defined based on the Gauss–Legendre algorithm, and various excellent properties of this operator are explored. This operator considers the priority relationships between attributes and their importance level, making it more capable of handling uncertainty. Finally, a new MADM method is constructed based on the PIOGPA operator using probability intervals and employs the arithmetic–geometric mean (AGM) algorithm to compute the weight of each attribute. The feasibility and soundness of the proposed method are confirmed through a numerical example and comparative analysis. The MADM method introduced in this paper assigns higher weights to higher-priority attributes to establish fixed attribute weights, and it reduces the impact of other attributes on decision-making results. It also utilizes the Gauss AGM algorithm to streamline the computational complexity and enhance the decision-making effectiveness.
Keywords:
interval ordering; probabilistic interval ordering sets; prioritized aggregation operator; information aggregation; multi-attribute decision making MSC:
03E72; 90B50; 91B06
1. Introduction
Today, the Internet has greatly facilitated information sharing, while big data has enhanced the precision of this sharing. As enterprises in the supply chain have become more interconnected, small and medium-sized enterprises (SMEs) have assumed increasingly significant roles in the regular functioning and advancement of the supply chain. Due to their relatively small scale, SMEs often encounter challenges related to financing difficulties and financing risks. Typically, participants in the supply chain financing process include small and medium-sized enterprises, financial institutions, such as banks, and core guarantee enterprises. Direct financing between SMEs and investment institutions is a significant financing approach. The rapid development of the supply chain provides banks with a favorable opportunity, and the expansion of supply chain financial services can drive the innovation and growth of commercial banks. Although direct financing can optimize the credit structure of commercial banks and create new opportunities for business development, corporate financing risk and bank loan risk remain unavoidable. To effectively mitigate credit risk, commercial banks must conduct comprehensive assessments of SMEs and identify target customers, including credit history, asset scale, repayment ability, and other relevant factors. These criteria are the important ones for judging whether the enterprise can repay the loan on time. Therefore, it is necessary for banks to evaluate and select SMEs before making loan decisions.
MADM is a decision-making problem in which the evaluation values of finite schemes under different attributes are aggregated, and then the schemes are sorted, and the best scheme is selected on this basis. It is an essential part of modern decision-making science, and the main problem of MADM focuses on evaluation and selection. Today, many MADM methods have been developed, such as the analytical hierarchy process (AHP) [1], the technique for order preference by similarity to an ideal solution (TOPSIS) [2], elimination et choice translating reality (ELECTRE) [3], and vlsekriterijumska optimizacija i kompromisno resenje (VIKOR) [4]. These decision-making models can be divided into two categories: the first type consists of decision-making methods based on value or utility function, and the second type consists of decision-making methods based on priority ranking. MADM usually consists of the following three steps: establishing an evaluation index system, determining attribute weights, and using specific methods to rank alternatives. In recent decades, the theory and method of MADM have been widely used in engineering, economy, technology, and culture fields, such as project evaluation [5], location selection [6], investment decisions [7], and so on. However, due to the complexity and uncertainty of evaluation information and the fuzziness of human thinking, evaluators are more inclined to use fuzzy information than exact quantitative information when dealing with decision-making problems. Therefore, it is of great academic and practical significance to study MADM in various fuzzy environments [8,9,10,11].
With the increasing fuzziness of information and complexity of decision-making conditions, evaluators began to use fuzzy information instead of precise mathematical models for assessment. Since the appearance of fuzzy sets (FS) [12], scholars have conducted extensive research on FS theory and obtained abundant research results. Various types of fuzzy sets and their extensions have been developed and successfully applied to MADM problems, including intuitionistic fuzzy sets (IFS) [13], hesitant fuzzy sets (HFS) [14], q-rung orthopair fuzzy sets (q-ROFS) [15,16,17], Pythagorean fuzzy sets (PFS) [18], and so on. These enumerated fuzzy sets are single-valued. In many decision-making problems in real life, single values have certain limitations and uncertainties in information expression. Thus, the related concept of interval value has been proposed, allowing the evaluator to express quantitative evaluations with a set of values in the interval [19]. Sun et al. [10] explored a weighted ranking method of dominance rough sets for an interval ordered information system. Then, the probability was introduced based on interval-valued fuzzy sets (IVFSs) [20] to manage the problem of multiple membership degrees, and various new theories and methods were developed. Su et al. [21] proposed several entropy measures for probabilistic hesitant fuzzy information. Krishankumar et al. [22] proposed a new concept of the interval-valued probabilistic hesitant fuzzy set (IVPHFS) and presented the simple interval-valued probabilistic hesitant fuzzy weighted geometry (SIVPHFWG) operator. Mandal and Ranadive [23] investigated interval-valued fuzzy probabilistic rough sets (IVF-PRSs) based on multiple interval-valued fuzzy preference relations and consistency matrices. Li and Zhan [24] explored interval-valued probabilistic rough fuzzy sets and their applications.
When dealing with MADM problems, aggregation operators are often used to fuse the decision information of different experts for each alternative under different attributes. The most common aggregation operators include various weighted averaging operators [25,26], Bonferroni mean (BM) operators [27], Heronian mean (HM) operators [28], Einstein integration operators [29,30], and so on. These operators have been studied and extensively applied in different fuzzy environments. In practice, however, there is often a priority relationship between different attributes. Among the existing operators, the prioritized averaging (PA) operator proposed by Yager [31] has excellent advantages in reflecting the priority relationships of operators. Prioritization provides consistency in the evaluation process and ensures that decisions are made according to the overall goals of the organization or individual, resulting in more rational decision outcomes. Therefore, PA operators have significant advantages in managing biased and extreme data and have attracted the attention of many scholars. Based on the PA operator, Gao [32] introduced Pythagorean fuzzy Hamacher prioritized aggregation operators. Wei and Tang [33] proposed some generalized prioritized aggregation operators. Yu et al. [34] extended the PA operator to the intuitionistic fuzzy environment and developed a series of intuitionistic fuzzy prioritized aggregation operators. He et al. [35] developed the probabilistic interval preference ordering weighted averaging (PIPOWA) operator, which was used in a group decision-making process. Khan et al. [36] proposed several Pythagorean fuzzy prioritized aggregation operators and applied them to MADM problems. Pérez-Arellano et al. [37] introduced a prioritized induced probabilistic (PIP) operator. Ruan et al. [38] defined a new Fermatean hesitant fuzzy prioritized Heronian mean operator (FHFPHM) and applied it to solving MADM problems.
In MADM problems, interval ordering can provide a sorting interval for each scheme, representing the sorting interval of the scheme regarding a particular attribute. Therefore, interval ordering can transform uncertain evaluation information into quantifiable interval evaluation information and improve the scientificity and rationality of decision-making results. The earliest interval ordering was a set of integer intervals, and it has been widely used in various situations, such as interval optimization [39], pattern recognition [40], and project scheduling [41]. Gonzalez-Pachon et al. [42] used the interval goal programming model to aggregate preference ranking information to obtain the ranking results of the schemes. Zapata et al. [43] extended the ordering of Allen’s algebra to intervals in an arbitrary partially ordered set. Pouzet and Zaguia [44] described ordered groups such that the ordering is a semiorder, and they introduced threshold groups generalizing totally ordered groups. Ghosh et al. [45] introduced and analyzed the concepts of fixed ordering structure and variable ordering structure on intervals. Nguyen et al. [46] employed an ordered weighted averaging (OWA) operator to determine the similarity between users and clusters. Verma et al. [47] subsequently introduced the generalized Pythagorean fuzzy probabilistic ordered weighted cosine similarity (GPFPOWCS) operator. Huang et al. [48] initiated an IFN comparison method with probability conversion as the foundation.
Subsequently, some scholars studied the probabilistic interval ordering problem, which considers possible probabilistic information. As a valuable tool for expressing positive and negative information, probabilistic interval ordering can effectively solve the MADM problem in real life. Probabilistic interval ordering is constructed based on the interval ranking. It considers the opinions of multiple evaluation subjects comprehensively and obtains more comprehensive information by summarizing the ranking intervals given by different evaluation subjects. Gao et al. [49] proposed a probabilistic interval decision-making method based on priority. Nie et al. [50] suggested a group decision-making support model utilizing consistency recovery strategies grounded in probabilistic linguistic term sets (PLTS). Liu et al. [51] expanded the PLTS to encompass the belief function theory. Qiu et al. [52] compared different types of interval numbers, defined the binary order relationships of interval numbers, integrated the characteristic information of interval numbers using the probability density function, and constructed a probabilistic credibility model of the interval number order relationship. Al Hantoobi et al. [53] introduced the concept of the probabilistic interval neutrosophic hesitant fuzzy set (PINHFS). Song et al. [54] investigated the MADM problems with dual hesitant fuzzy information. He et al. [35] defined the concept of probabilistic interval preference ordering elements (PIPOEs) and developed some aggregation operators and distance measures for PIPOEs. Based on probabilistic interval-valued intuitionistic hesitant fuzzy sets (PIVIHFSs) [55], Luo and Liu [56] constructed a MADM model based on a probabilistic interval-valued intuitionistic hesitant fuzzy Maclaurin symmetric mean operator.
In the literature on probabilistic interval decision-making, scholars have often ignored the critical elements associated with one or more subsequent decisions after various decision-makers have voted and scored. Typically, attributes have varying degrees of importance, and critical attributes should have higher grading requirements than general ones. Furthermore, many existing methods often ignore the significance of interval ordering and attribute prioritization, resulting in inaccurate decision-making results. As a result, given that attributes frequently have a distinct priority interaction, this paper aggregates the significance of interval preference ordering with the characteristics of attribute priority distribution. It introduces a probabilistic parameter to represent the interval importance and proposes the PIOPA operator. Next, accounting for the complexity and uncertainty of decision problems and the priority relationship among different attributes, this paper further defines the PIOGPA operator by incorporating the Gauss–Legendre algorithm [57], and it explores some notable properties of the operator. Last, a MADM model based on the PIOGPA operator is constructed and applied to assess investment decisions for commercial banks, confirming the model’s scientific validity and effectiveness.
The PIOGPA operator proposed in this paper effectively manages extreme or biased data, offering enhanced applicability and flexibility. Unlike previous methods, this paper reduces the influence of extreme values on the algorithm’s mean and offers a more accurate representation of the overall data distribution. Additionally, the AGM algorithm addresses the limitation of geometric mean values, which cannot handle zero and non-negative data values. It also avoids significant reductions in results when addressing highly dispersed data. In practice, the importance of attributes often varies over time due to changing environmental factors. The presented PIOGPA operator is well suited for decision-making in uncertain environments since it allows for the adjustment of attribute importance in response to changing conditions. When the environment evolves, the PIOGPA operator can promptly adapt by reevaluating critical attributes and determining new attribute weights. This adaptability ensures that the most appropriate decision options are obtained for the current environment, making the PIOGPA operator flexible and highly applicable.
In summary, the PIOGPA operator offers several advantages over other existing aggregation operators, as outlined below:
- (1)
- The PIOGPA operator introduces the probability parameter and priority and can reflect the importance degrees and priority relationships of attributes;
- (2)
- The PIOGPA operator is more flexible and robust. It considers the priority between different attributes and can manage the influence of extreme data or biased data and obtain more reasonable decision results;
- (3)
- The PIOGPA operator is more applicable in addressing uncertain problems. It can adjust the critical attributes in time and determine the new critical attribute weight.
The paper is organized as follows: Section 2 provides the basic definitions and methods related to probabilistic interval ordering. Section 3 presents the PIOPA operator and PIOGPA operator and discusses related properties. A MADM method based on the PIOGPA operator is developed in Section 4. In Section 5, a numerical example of the MADM method is proposed, and the feasibility and rationality of the method are verified. Section 6 summarizes this paper with some remarks.
2. Basic Concepts
In this section, some basic concepts of interval ordering and probabilistic interval ordering sets are illustrated, and definitions of the PA operator and PIPOWA operator are given.
Definition 1
([10]). Let be a set of positive integers. Then, the interval ordering can be expressed as:
Among these values, , and , where and represent the minimum value and maximum value of interval ordering set , respectively. The interval ordering can be denoted as . When , the interval ordering becomes a definite ordering .
Definition 2
([35]). Let be a set of positive integers. Then, the probabilistic interval ordering set is given as:
where , and represents a collection of PIPOEs that consists of some positive integer intervals, encompassing sorting ordering information denoted as , and the probabilities associated with various sorting possibilities. signifies the probability that the expert group assigns the scheme’s corresponding attribute ranking among all schemes within this interval. It can be expressed as with , where and denote, respectively, the minimum and maximum values of the interval set.
Definition 3
([35]). Let and be the expected and scoring values of the PIPOE , respectively, then and can be defined as:
where represents the number of ordering elements, and and are the minimum and maximum values of the intervals in , respectively. The sorting value in indicates the ranking order of the scheme. The smaller that the sorting value is, the higher that the ranking order of the scheme is. To further compare the pros and cons of two different schemes within the PIPOEs , the possibility degree formula is defined as:
Definition 4
([35]). Let and be the scores of two different schemes in the probabilistic interval ordering set; then:
- (1)
- when , ;
- (2)
- when , ;
- (3)
- when , .
Definition 5
([31]). Given a set of attributes , each attribute contains a set of probabilistic interval orderings with the importance ranking , and then the attributes are called prioritized attributes. The prioritized averaging operator (PA) is defined as:
where , , , is the score function of .
Definition 6
([35]). Given a set of attributes , each attribute contains a set of probabilistic interval orderings . For convenience, is used to represent the . In traditional MADM models, the weight of each attribute follows the assumption of uniform distribution of attribute values. Then, the PIPOWA operator can be expressed as:
where , , and is the score function of .
When , the PIPOWA operator degenerates into the probabilistic interval preference ordering averaging operator (PIPOA):
3. Probabilistic Interval Ordering Averaging Operator with Attribute Priority
Although some scholars have studied the aggregation of interval ordering information, most existing probabilistic interval ordering averaging operators have assumed that different attributes are independent and have failed to consider the correlation between attributes in the decision-making process. Furthermore, decision-makers usually have different risk preferences and concerns in practice. Thus, decision-makers should consider the priority relationship between attributes when making decisions. To address this issue, this paper introduces the PA operator to consider the priority relationship between different attributes. Considering the complexity of the decision condition, the PIOPA operator, based on the accuracy of the probabilistic interval ordering operator, is proposed, and its properties and algorithms are discussed. This operator can solve the decision preference problem faced by decision-makers and improve the rationality and effectiveness of decision results.
Definition 7.
Given a set of attributes , each attribute contains a set of probabilistic interval orderings with the importance ranking . Let be a set of probabilistic interval orderings with a particular priority relationship between different attributes. Then, the PIOPA operator is defined as:
where , and ; is the score function of .
Considering the influence of decision-makers’ risk preference and environment complexity and uncertainty on decision results, as well as the operation rules of PIOPA operator, this paper compares the attribute ranking of different schemes by experts to determine the optimal solution. To overcome the complexity of traditional weight interval processing methods in data processing, this paper creatively introduces the Gauss–Legendre algorithm and further develops the PIOGPA for probabilistic interval ordering.
The AGM algorithm is an iterative algorithm that leverages a specific elliptic integral constructed through the algebraic relationship between Jacobi elliptic functions. This algorithm can approximate many mathematical constants effectively. It can be used to calculate elliptic integral constants with second-order convergence. Compared with traditional methods with first-order convergence, this approach can double the number of digits of convergence accuracy in a single iteration. As a result, the AGM algorithm reduces the computational complexity and enhances the correctness and effectiveness of decision-making results.
Definition 8.
Given a set of attributes , each attribute contains a set of probabilistic interval orderings with the importance ranking . Let be a set of probabilistic interval orderings with a particular priority relationship between different attributes. Then, the PIOGPA operator can be denoted as:
where
can be denoted as:
Theorem 1.
Let be a set of probabilistic interval orderings; then, the result obtained after the aggregation of the PIOGPA operator is still a probabilistic interval ordering Gauss–Legendre prioritized averaging element.
where , , , is the score function of .
Proof of Theorem 1.
This theorem can be proved by mathematical induction.
When ,
Suppose that, when , Theorem 1 is true.
Then, when , we have
Therefore, Theorem 1 holds for . □
Property 1.
(Idempotency) Let be a set of probabilistic interval orderings. If , then
Property 2.
(Boundedness) Let be a set of probabilistic interval orderings, then
where and .
Property 3.
(Permutation Invariance) Let be a set of probabilistic interval orderings; then
where is any permutation of .
4. MADM Method Based on the PIOGPA Operator
Based on the PIOGPA operator, a probabilistic interval MADM method considering consistency and attribute priority information is proposed in this section. Figure 1 describes how to use the consistency algorithm to remove abnormal data and modify the probabilistic interval ordering set; then, it gives the concrete MADM steps on this basis.
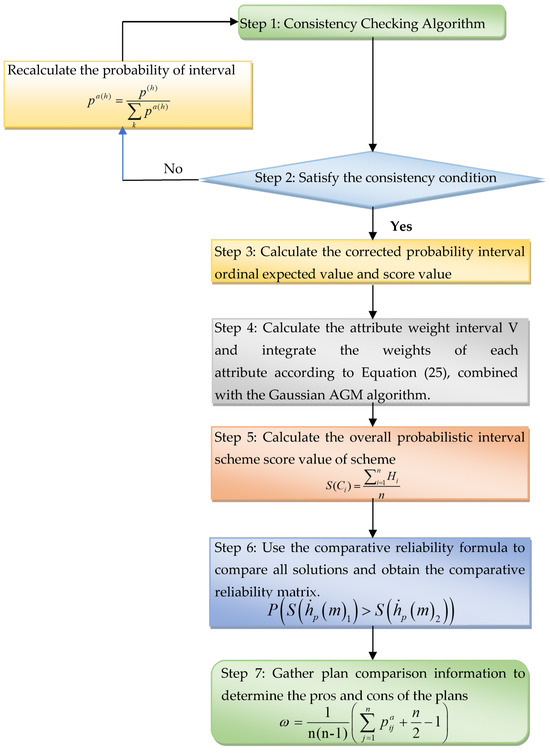
Figure 1.
Flow chart of the MADM method based on the PIOGPA operator.
Assume that is a set of alternatives, and is a collection of attributes with the priority relationship . Multiple experts evaluate each alternative with respect attribute . Considering differences in experts’ knowledge backgrounds, research fields, risk preferences, and environmental conditions, this paper aims to obtain a reasonable result in group decision-making.
Therefore, this paper summarizes the experts’ scoring interval ordering for each attributes , removes the abnormal data, and modifies the probabilistic interval to generate a new probabilistic interval ordering set denoted as with . The modified probabilistic interval ordering set and the PIOGPA operator are used to calculate the weights of each attribute and the scoring weight interval for each alternative , respectively. Finally, the optimal scheme is determined by comparing the scoring weight interval of each scheme. The specific calculation steps are as follows:
4.1. Consistency Algorithm
In the normal distribution , variables are distributed on both sides of according to a certain trend, where reflects the concentrated distribution position of variables, and reflects the degree of dispersion of variables. The smaller that the value of is, the stronger that the concentration of data is. In this paper, the following steps are used to eliminate abnormal evaluation data, correct the interval ordering set probability, and optimize the initial data to obtain a new probabilistic interval ordering set.
Step 1. Obtain the initial information of the probabilistic interval ordering set.
Step 2. Compute the location parameter and data dispersion parameter for a normal distribution within with .
Step 3. In the normal distribution, the intervals , , represent the minimum probability of the outcome being 68.3%, 95.4%, and 99.7%, respectively. To maximize the inclusion of data within the specified range and remove unreasonable data with excessive deviations, this paper uses the interval as the appropriate criterion for judgment. Here, and can be expressed as:
Step 4. Utilize the comparative degree formula to compare the and in the probabilistic interval ordering:
- (1)
- when , , is better than ;
- (2)
- when , , is as good as ;
- (3)
- when , , is not as good as .
Step 5. If and , it implies a 99.73% probability that the interval meets the condition, and is retained. Conversely, if or , it means that fails to meet the requirements; then, we recalculate the probability of each interval:
Return to Step 1 and recalculate the scores of the PIPOEs until all the data in the set meet the requirements.
4.2. MADM Steps Based on the PIOGPA Operator
After the experts provide their priority information for all alternatives and relevant attributes , all the information is summarized in . The specific calculation steps are as follows:
Step 1. Use consistency testing to remove the data deviating from the centralized position and modify the probabilistic interval and probability to obtain a new probabilistic interval ordering set and modified . Then, calculate the expected range of each alternative under different attributes and the score of attributes, respectively, according to Equations (24) and (25).
Step 2. The M1 model in reference [35] is cited to determine the importance of attributes under expert scoring standards. Based on the obtained attribute weight results, the priority ordering of attributes is determined in this paper. Then, Equation (27) is used to calculate the attribute weight interval V, and the weights of each attribute are integrated according to Equation (26), combined with the Gaussian AGM algorithm.
Step 3. Calculate the adjusted and use Equation (28) to obtain under the PIOPA operator:
Subsequently, use Equation (29) to calculate the overall probabilistic interval scores of each scheme:
Step 4. Compare the scores of different alternatives according to the comparison rules in Equation (30), where represents . Then, a possibility matrix is constructed, where , and . The prioritized weight of the alternative obtained from is denoted as the following formulas:
Step 5. The alternatives are ranked according to the prioritized weight . The larger that is, the worse that the solution is; the smaller that , the better that the solution is.
5. Case Study
5.1. Case Analysis
China has declared to end the measures undertaken due to three-year-long epidemic of novel coronavirus pneumonia, which was renamed novel coronavirus infection by the end of 2022. Despite the impact of the epidemic, the gross domestic product (GDP) of China continued to grow over the past three years, and the macroeconomic situation has improved. However, from a microperspective, many small and medium-sized enterprises (SMEs) are facing challenges and difficulties due to the epidemic. The government recognized that fostering a healthy and stable business environment requires not only the prosperity of large enterprises but also the vitality of all SMEs in the market. In 2022, the Institute of Economics of the Chinese Academy of Social Sciences conducted a systematic review of China’s economy and made predictions for its development in 2023. The future development strategy must effectively combine the expansion of domestic demand with supply-side structural reforms.
Suppose that a commercial bank plans to provide loans to SMEs in need of financing in a large supply chain network to take advantage of new investment opportunities To ensure that investment decisions meet the bank’s expectations regarding investment risk and profitability criteria, the bank invites 100 experts in the field of supply chain finance to evaluate the candidates. After a simple screening and evaluation by the experts, six enterprises with excellent conditions in all aspects are selected and denoted as . According to the expertise and experience of the experts, the bank determines four important evaluation indicators: business operation status (), market demand (), supply chain status (), and corporate reputation (). Then, the experts comprehensively rank the six enterprises according to these four indicators, and they obtain the probabilistic interval priority sets, as shown in Table 1. In addition, they adjust the initial priority sequence to achieve an acceptable level of consistency and apply the proposed group decision scheme to assess the strengths and weaknesses of the six production enterprises. This process enables the bank to select the most suitable production enterprises to provide loans. The specific steps are as follows:

Table 1.
The probabilistic interval ordering sets.
Step 1. The consistency testing algorithm is used to eliminate the intervals that do not meet the conditions of PIPOE, and the probabilities of each interval are recalculated according to Equation (23) to obtain the revised set of probability intervals, as shown in Table 2.
Table 2.
The modified probabilistic interval ordering sets.
Step 2. According to the M1 model in the literature [35], the importance of attributes is sorted as follows:
To determine the attribute prioritized weight, calculate the weight interval for each attribute based on Equation (27) and the weight information for each attribute using Equation (26). The results are shown as:
Step 3. Utilize the PIOGPA operator to aggregate the information from the probabilistic interval ordering set and obtain the score of each enterprise based on Equation (29).
Step 4. Compare the scores of different schemes and construct the possibility degree matrix using the possibility degree based on Equation (30).
Next, obtain the priority vector by Equation (31), and the results are presented in Figure 2:
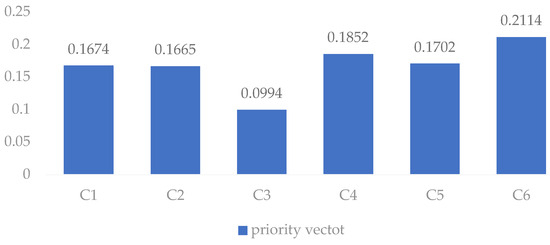
Figure 2.
The priority vector for each company in the case analysis.
Step 5. The enterprises are ranked as follows according to the priority vector:
The larger that is, the worse that the scheme is. The smaller that is, the better that the scheme is. Therefore, the best enterprise is .
5.2. Comparative Analysis
To further verify the scientificity and validity of the decision-making method proposed in this paper, this section compares and analyzes the results of the interval hesitant fuzzy ordering averaging (IHFOA) operator, the interval hesitant fuzzy ordering prioritized averaging (IHFOPA) operator, the interval hesitant fuzzy ordering Gauss–Legendre prioritized averaging (IHFOGPA) operator, the probabilistic interval preference ordering averaging (PIPOA) operator, and probabilistic interval preference ordering weighted averaging (PIPOWA) operator, as described in [20,35,54,56]. The comparison results are presented in Table 3 and Figure 3.
Table 3.
Comparative analysis of different integration operators.
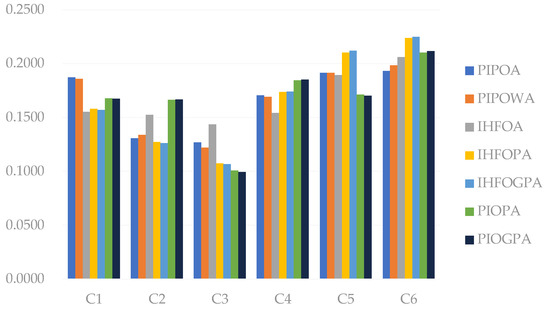
Figure 3.
Comparative analysis of different integration operators.
In the comparative analysis, the PIPOA and PIPOWA operators adopt the probabilistic interval preference ordering algorithm. The difference is that the PIPOA operator does not consider the influence of attribute weight information, while the PIPOWA operator aggregates attribute weight information in the decision-making process. The results obtained by the two methods are the same: enterprise is the best, and is the worst. The PIPOA, PIPOWA, IHFOPA, IHFGOPA, PIOPA, and PIOGPA operators all consider the complete attribute information for all attributes. Although the ranking results of the five methods are not exactly consistent, the results show that enterprise is the best, and enterprise is the worst. The specific analysis that leads to different sorting results is as follows.
The PIOGPA operator presented in this paper is based on the probabilistic interval ordering. It uses the AGM algorithm of mutual support and the influence of the data to consolidate the priority weight intervals of attributes into the attribute priority weights, thus constructing the appropriate attribute weight scheme. By examining the correlations between different attributes, the attribute weights for each scheme are refined. This approach improves the problem that the arithmetic averaging operators might yield excessively low attribute weights, and geometric averaging operators might lead to excessively high attribute weights and strengthen the data relationships. The overall coordination is more flexible and efficient in solving practical problems. The results of the proposed PIOPA and PIOGPA operators are consistent: . Compared with the PIOPA operator, the PIOGPA operator employs the Gaussian AGM algorithm to reduce the complexity of the calculations, while the PIOPA operator utilizes the unprocessed weight interval . Thus, the calculation of the PIOPA operator involves double interval superposition, resulting in a more complete and difficult calculation. On the other hand, the PIOGPA uses the AGM algorithm to consolidate the weight intervals, allowing only the maximum and minimum values to be used to determine the sorting interval. This approach, based on the PIOGPA operator, greatly reduces the complexity of the calculations. However, several methods in the literature [21,36,55,57] fail to effectively address the issue of data overestimation or underestimation, leading to varying ranking results for the schemes. The calculations of the IHFOA, IHFOPA, and IHFOGPA operators rely on hesitant fuzzy intervals. When information is evenly distributed, basic information can be distorted, making it difficult to obtain completely objective results. Based on the principle of probabilistic interval ordering, this paper redefines the operation associated with probabilistic interval ordering and demonstrates that the operator satisfies idempotency, boundedness, and permutation invariance. From the perspective of effectively using decision information, the PIOGPA operator not only can consider the subjective preferences and objective information of decision makers but also can accurately reflect the priority relationships between attributes, making the decision results more real. From the perspective of decision-making algorithms, the PIOGPA operator is simpler. It can avoid redundant data traversal, reduce operation complexity, and obtain more reasonable and effective aggregation results.
In summary, the PIOPA operator in this paper is derived from the PA operator and PIPOWA operator. The PIOPA operator can consider important relationships between attributes during the decision-making process, making it suitable for more complex decision-making environments. The presented PIOGPA operator considers the normal distribution of interval numbers and overcomes the assumption of the uniform distribution of attribute values in traditional MADM models. Furthermore, it considers the priority relationships of attributes. The attribute weight is determined by assigning greater importance to top-ranked attributes, thereby mitigating the influence of other attributes on the decision-making results. Most importantly, the Gaussian AGM algorithm is used to optimize the calculation steps, reducing the calculation complexity by converging the attribute weight intervals and enhancing the accuracy and effectiveness of decision outcomes.
6. Conclusions
Commercial banks are increasingly focusing on investment decisions regarding supply chain finance. In the complex and changing market environment, selecting high-quality companies that meet specific standards becomes a multi-attribute group decision-making problem. To address this challenge, a novel MADM method based on the PIOGPA operator is presented. First, the PIPOA operator, combining probabilistic interval ordering with the PA operator, is proposed. However, the PIPOA operator tends to cause some operational complexity in the selection process. Then, based on the PIPOA operator, this paper employs the Gauss–Legendre algorithm to develop the PIOGPA operator, which considers the priority relationships between attributes and their importance and is more suitable for dealing with uncertain decision-making problems, and some basic properties of the PIOGPA operator are discussed. Furthermore, this paper presents a new MADM method of probabilistic interval ordering based on the PIOGPA operator and uses the AGM algorithm to calculate the attribute weights. Finally, the feasibility and rationality of the proposed method are verified by the numerical example and comparative analysis. The results show that this method is suitable for solving practical decision-making problems and has a broad application prospect.
For MADM problems, the current research mainly focuses on aggregating values under different attributes by constructing various weight operators. However, weight determination is challenging in the decision-making process. Some scholars have used subjective methods to determine weights. They have usually verified the feasibility of the method through examples and have rarely discussed the sensitivity of different weights to the decision results. Some scholars have adopted objective empowerment approaches, including the optimization weighting methods and entropy weighting methods, but the weight calculation process may be complicated. The MADM method proposed in this paper is based on the PA operator and probabilistic interval ordering operators. It calculates the positive and negative information about attributes, satisfying the comparison of positives and negatives through priority relationships. This method effectively avoids the direct aggregation of attributes and does not require manual determination of attribute weights, thereby obtaining more objective decision-making results. The presented method can be widely used in many fields. When the fields involve multiple attributes, and the values of these attributes are uncertain, a probability interval ranking information system can be constructed for MADM evaluation using ranking evaluation. For example, when evaluating an investment plan, it is impossible to make a decision based on only one index due to the diversity of evaluation indicators, so the probabilistic interval ordering system can be used for evaluation. Then, this method can transform attributes according to different environmental states and generate data consistent with a fuzzy information system for decision-making.
This paper has several limitations. First, there is limited discussion of the properties of comparing and ranking methods of probabilistic interval ordering. Second, the applicability of constructing a function for addressing non-sequential problems is limited to ranking evaluation problems, and it is difficult to apply to other evaluation problems. In addition, this paper fails to test larger data sets, and enterprise development against the background of big data should be further considered as the analysis object. In the future, more probabilistic interval operators could be proposed, and their application fields should be broadened to deal with fuzziness, including medical, financial, autonomous driving, and other fields. Furthermore, with the evolution of the Internet of Things, the processing of multimodal data, such as text, image, and sound, requires improving fuzzy decision theories and techniques to enhance the comprehensiveness and accuracy of fuzzy decision-making. In the future, the research in the fuzzy decision-making field will face a rapid increase in the amount of data, and more efficient algorithms and techniques are needed to effectively solve large-scale decision problems. The integration of fuzzy decision-making methods with deep learning technology is likely to enhance the learning and innovation ability of future decision-making models.
Author Contributions
Conceptualization, C.R., S.G. and X.C.; methodology, C.R. and S.G.; software, C.R. and S.G.; validation, C.R., S.G. and X.C.; formal analysis, S.G.; data curation, X.C.; writing—original draft preparation, S.G.; writing—review and editing, X.C.; visualization, C.R. and X.C.; supervision, C.R., S.G. and X.C.; project administration, C.R.; funding acquisition, C.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Guangdong Provincial Philosophy and Social Science Planning Project (No. GD23XGL012) and the Innovative Team Project of Guangdong Universities (No. 2019WCXTD008).
Data Availability Statement
The data in this research were obtained originally.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, P.; Liu, Q.; Kang, B. An improved OWA-Fuzzy AHP decision model for multi-attribute decision making problem. J. Intell. Fuzzy Syst. 2021, 40, 9655–9668. [Google Scholar] [CrossRef]
- Zeng, S.; Chen, S.M.; Fan, K.Y. Interval-valued intuitionistic fuzzy multiple attribute decision making based on nonlinear programming methodology and TOPSIS method. Inform. Sci. 2020, 506, 424–442. [Google Scholar] [CrossRef]
- Ferreira, L.; Borenstein, D.; Santi, E. Hybrid fuzzy MADM ranking procedure for better alternative discrimination. Eng. Appl. Artif. Intell. 2016, 50, 71–82. [Google Scholar] [CrossRef]
- Mishra, A.R.; Chen, S.M.; Rani, P. Multiattribute decision making based on Fermatean hesitant fuzzy sets and modified VIKOR method. Inform. Sci. 2022, 607, 1532–1549. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Y.; Wang, H. Competency model for international engineering project manager through MADM method: The Chinese context. Expert Syst. Appl. 2023, 212, 118675. [Google Scholar] [CrossRef]
- Lei, F.; Cai, Q.; Wei, G.; Mo, Z.; Guo, Y. Probabilistic double hierarchy linguistic MADM for location selection of new energy electric vehicle charging stations based on the MSM operators. J. Intell. Fuzzy Syst. 2023, 44, 1–22. [Google Scholar] [CrossRef]
- Shahabi, R.S.; Basiri, M.H.; Qarahasanlou, A.N.; Mottahedi, A.; Dehghani, F. Fuzzy MADM-based model for prioritization of investment risk in Iran’s mining projects. Int. J. Fuzzy Syst. 2022, 24, 3189–3207. [Google Scholar] [CrossRef]
- Senapati, T.; Mesiar, R.; Simic, V.; Iampan, A.; Chinram, R.; Ali, R. Analysis of interval-valued intuitionistic fuzzy aczel–alsina geometric aggregation operators and their application to multiple attribute decision-making. Axioms 2022, 11, 258. [Google Scholar] [CrossRef]
- Dou, W. MADM framework based on the triangular Pythagorean fuzzy sets and applications to college public English teaching quality evaluation. J. Intell. Fuzzy Syst. 2023, 45, 4395–4414. [Google Scholar] [CrossRef]
- Sun, M.; Liang, Y.Y.; Pang, T.J. A weighted ranking method of dominance rough sets for interval ordered information systems. J. Chi. Comput. Syst. 2018, 39, 676–680. [Google Scholar]
- Ning, B.; Wei, G.; Lin, R.; Guo, Y. A novel MADM technique based on extended power generalized Maclaurin symmetric mean operators under probabilistic dual hesitant fuzzy setting and its application to sustainable suppliers selection. Expert Syst. Appl. 2022, 204, 117419. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inform. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Atanassov, K.T.; Stoev, S. Intuitionistic fuzzy sets. Fuzzy Sets. Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Torra, V. Hesitant fuzzy sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Khan, M.R.; Wang, H.; Ullah, K.; Karamti, H. Construction Material Selection by Using Multi-Attribute Decision Making Based on q-Rung Orthopair Fuzzy Aczel–Alsina Aggregation Operators. Appl. Sci. 2022, 12, 8537. [Google Scholar] [CrossRef]
- Khan, M.R.; Ullah, K.; Karamti, H.; Khan, Q.; Mahmood, T. Multi-attribute group decision-making based on q-rung orthopair fuzzy Aczel–Alsina power aggregation operators. Eng. Appl. Artif. Intell. 2023, 126, 106629. [Google Scholar] [CrossRef]
- Feng, F.; Zhang, C.; Akram, M.; Zhang, J. Multiple attribute decision making based on probabilistic generalized orthopair fuzzy sets. Granul. Comput. 2023, 8, 863–891. [Google Scholar] [CrossRef]
- Garg, H. Linguistic Pythagorean fuzzy sets and its applications in multiattribute decision-making process. Int. J. Intell. Syst. 2018, 33, 1234–1263. [Google Scholar] [CrossRef]
- Gorzałczany, M.B. A method of inference in approximate reasoning based on interval-valued fuzzy sets. Fuzzy Sets. Syst. 1987, 21, 1–17. [Google Scholar] [CrossRef]
- Ruan, C.; Chen, X. Probabilistic Interval-Valued Fermatean Hesitant Fuzzy Set and Its Application to Multi-Attribute Decision-Making. Axioms 2023, 12, 979. [Google Scholar] [CrossRef]
- Su, Z.; Xu, Z.; Zhao, H.; Hao, Z.; Chen, B. Entropy measures for probabilistic hesitant fuzzy information. IEEE Access 2019, 7, 65714–65727. [Google Scholar] [CrossRef]
- Krishankumar, R.; Ravichandran, K.S.; Kar, S.; Gupta, P.; Mehlawat, M.K. Interval-valued probabilistic hesitant fuzzy set for multi-criteria group decision-making. Soft Comput. 2019, 23, 10853–10879. [Google Scholar] [CrossRef]
- Mandal, P.; Ranadive, A.S. Multi-granulation interval-valued fuzzy probabilistic rough sets and their corresponding three-way decisions based on interval-valued fuzzy preference relations. Granul. Comput. 2019, 4, 89–108. [Google Scholar] [CrossRef]
- Li, W.; Zhan, T. Multi-Granularity Probabilistic Rough Fuzzy Sets for Interval-Valued Fuzzy Decision Systems. Int. J. Fuzzy Syst. 2023, 1–13. [Google Scholar] [CrossRef]
- Senapati, T.; Yager, R.R. Fermatean fuzzy weighted averaging/geometric operators and its application in multi-criteria decision-making methods. Eng. Appl. Artif. Intell. 2019, 85, 112–121. [Google Scholar] [CrossRef]
- Wei, G. Pythagorean fuzzy interaction aggregation operators and their application to multiple attribute decision making. J. Intell. Fuzzy Sys. 2017, 33, 2119–2132. [Google Scholar] [CrossRef]
- Ruan, C.Y.; Chen, X.J.; Zeng, S.Z.; Shahbaz, A.; Bander, A. Fermatean Fuzzy Power Bonferroni Aggregation Operators and Their Applications to Multi-Attribute Decision Making. Soft Comput. 2023. accepted. [Google Scholar]
- Deb, N.; Sarkar, A.; Biswas, A. Development of Archimedean power Heronian mean operators for aggregating linguistic q-rung orthopair fuzzy information and its application to financial strategy making. Soft Comput. 2023, 27, 11985–12020. [Google Scholar] [CrossRef]
- Rahman, K.; Abdullah, S.; Ahmed, R.; Ullah, M. Pythagorean fuzzy Einstein weighted geometric aggregation operator and their application to multiple attribute group decision making. J. Intell. Fuzzy Syst. 2017, 33, 635–647. [Google Scholar] [CrossRef]
- Rani, P.; Mishra, A.R. Fermatean fuzzy Einstein aggregation operators-based MULTIMOORA method for electric vehicle charging station selection. Expert Syst. Appl. 2021, 182, 115267. [Google Scholar] [CrossRef]
- Yager, R.R. Prioritized aggregation operators. Int. J. Approx. Reason. 2008, 48, 263–274. [Google Scholar] [CrossRef]
- Gao, H. Pythagorean fuzzy Hamacher prioritized aggregation operators in multiple attribute decision making. J. Intell. Fuzzy Syst. 2018, 35, 2229–2245. [Google Scholar] [CrossRef]
- Wei, C.; Tang, X. Generalized prioritized aggregation operators. Int. J. Intell. Syst. 2012, 27, 578–589. [Google Scholar] [CrossRef]
- Yu, D. Multi-Criteria Decision Making Based on Generalized Prioritized Aggregation Operators under Intuitionistic Fuzzy Environment. Int. J. Fuzzy Syst. 2013, 15, 47–54. [Google Scholar]
- He, Y.; Xu, Z.; Jiang, W. Probabilistic interval reference ordering sets in multi-criteria group decision making. Int. J. Uncertain. Fuzz. Knowl. Based Syst. 2017, 25, 189–212. [Google Scholar] [CrossRef]
- Khan, M.S.A.; Abdullah, S.; Ali, A.; Amin, F. Pythagorean fuzzy prioritized aggregation operators and their application to multi-attribute group decision making. Granul. Comput. 2019, 4, 249–263. [Google Scholar] [CrossRef]
- Pérez-Arellano, L.A.; León-Castro, E.; Avilés-Ochoa, E.; Merigó, J.M. Prioritized induced probabilistic operator and its application in group decision making. Int. J. Mach. Learn. Cyb. 2019, 10, 451–462. [Google Scholar] [CrossRef]
- Ruan, C.Y.; Chen, X.J.; Han, L.N. Fermatean Hesitant Fuzzy Prioritized Heronian Mean Operator and Its Application in Multi-Attribute Decision Making. Comput. Mater. Con. 2023, 75, 3204–3222. [Google Scholar] [CrossRef]
- Costa, T.M.; Chalco-Cano, Y.; Osuna-Gómez, R.; Lodwick, W.A. Interval order relationships based on automorphisms and their application to interval optimization. Inform. Sci. 2022, 615, 731–742. [Google Scholar] [CrossRef]
- Hesamian, G. Measuring similarity and ordering based on interval type-2 fuzzy numbers. IEEE Trans. Fuzzy Syst. 2016, 25, 788–798. [Google Scholar] [CrossRef]
- Moukrim, A.; Quilliot, A.; Toussaint, H. An effective branch-and-price algorithm for the preemptive resource constrained project scheduling problem based on minimal interval order enumeration. Eur. J. Oper. Res. 2015, 244, 360–368. [Google Scholar] [CrossRef]
- González-Pachón, J.; Romero, C. Aggregation of partial ordinal rankings: An interval goal programming approach. Comput. Oper. Res. 2001, 28, 827–834. [Google Scholar] [CrossRef]
- Zapata, F.; Kreinovich, V.; Joslyn, C.; Hogan, E. Orders on intervals over partially ordered sets: Extending Allen’s algebra and interval graph results. Soft Comput. 2013, 17, 1379–1391. [Google Scholar] [CrossRef][Green Version]
- Pouzet, M.; Zaguia, I. Interval orders, semiorders and ordered groups. J. Math. Psychol. 2019, 89, 51–66. [Google Scholar] [CrossRef]
- Ghosh, D.; Debnath, A.K.; Pedrycz, W. A variable and a fixed ordering of intervals and their application in optimization with interval-valued functions. Int. J. Approx. Reason. 2020, 121, 187–205. [Google Scholar] [CrossRef]
- Nguyen, J.; Armisen, A.; Sánchez-Hernández, G.; Casabayó, M.; Agell, N. An OWA-based hierarchical clustering approach to understanding users’ lifestyles. Know. Based Syst. 2020, 190, 105308. [Google Scholar] [CrossRef]
- Verma, R.; Mittal, A. Multiple attribute group decision-making based on novel probabilistic ordered weighted cosine similarity operators with Pythagorean fuzzy information. Granul. Comput. 2023, 8, 111–129. [Google Scholar] [CrossRef]
- Huang, Z.; Weng, S.; Lv, Y.; Liu, H. Ranking Method of Intuitionistic Fuzzy Numbers and Multiple Attribute Decision Making Based on the Probabilistic Dominance Relationship. Symmetry 2023, 15, 1001. [Google Scholar] [CrossRef]
- Gao, F.J.; Wang, H.Y. Probabilistic interval decision-making based on priority. Stat. Decis. 2012, 04, 85–87. [Google Scholar]
- Nie, R.; Wang, J. Prospect theory-based consistency recovery strategies with multiplicative probabilistic linguistic preference relations in managing group decision making. Arabian J. Sci. Eng. 2020, 45, 2113–2130. [Google Scholar] [CrossRef]
- Liu, R.; Fei, L.; Mi, J. A Multi-Attribute Decision-Making Method Using Belief-Based Probabilistic Linguistic Term Sets and Its Application in Emergency Decision-Making. Comput. Model. Eng. Sci. 2023, 136, 2039–2067. [Google Scholar] [CrossRef]
- Qiu, D.S.; He, C.; Zhu, X.M. Interval number ranking method based on probability credibility. Control. Decis. 2012, 27, 1894–1898. [Google Scholar]
- Hantoobi, A.; Sendeyah. A Decision Modelling Approach for Security Modules of Delegation Methods in Mobile Cloud Computing using Probabilistic Interval Neutrosophic Hesitant Fuzzy Set; The British University in Dubai (BUiD): Dubai, United Arab Emirates, 2023. [Google Scholar]
- Song, J.; Ni, Z.W.; Wu, W.Y.; Jin, F.F.; Li, P. Multi-attribute decision making method based on probability dual hesitant fuzzy information correlation coefficient under unknown attribute weight information. Pattern Recogn. Artif. Intell. 2022, 35, 306–322. [Google Scholar]
- Xie, G.; Wang, K.; Wu, X.; Wang, J.; Li, T.; Peng, Y.; Zhang, H. A hybrid multi-stage decision-making method with probabilistic interval-valued hesitant fuzzy set for 3D printed composite material selection. Eng. Appl. Artif. Intell. 2023, 123, 106483. [Google Scholar] [CrossRef]
- Luo, S.H.; Fang, T.; Liu, J. Probabilistic interval-valued intuitionistic hesitant fuzzy Maclaurin symmetric averaging operator and decision method. Control. Decis. 2021, 36, 1249–1258. [Google Scholar]
- Fermé, E.; Hansson, S.O. AGM 25 years: Twenty-five years of research in belief change. J. Philos. Logic. 2011, 40, 295–331. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).