

A Game—Theoretic Model for a Stochastic Linear Quadratic Tracking Problem



{kind=link}
{kind=link}
Abstract
1. Introduction
2. The Problem
- (a)
- is a.s. continuous in every
- (b)
- for each is measurable, where is the algebra generated by the random variables
- (c)
- for all
- (d)
- (a)
- are continuous matrix-valued functions;
- (b)
- for all
- (a)
- We shall see that for the computation of the gain matrices of a Nash equilibrium strategy we need to know a priori the whole reference signal
- (b)
- When for all then (4) reduces toThe performance criterion (4) could be replaced by one of the form (7), when the decision-maker is interested only by the minimization of the deviation of the final value from the target The termwhich appears both in (4) and (7), must be viewed as a penalization of the control effort.
3. The Main Results
3.1. The Case with Only One Decision Maker
- (a)
- are continuous matrix-valued functions;
- (b)
- for all
- (i)
- the unique solution of the TVP (16) is defined on the whole interval Moreover, for all
- (ii)
- the TVPs (17) and (18) have unique solutions and
- (i)
- Follows immediately applying Corollary 5.2.3 from [9] applied in the case of TVP (16).
- (ii)
- The TVP (17) is associated with a linear nonhomogeneous differential equation with time-varying coefficients. Hence its solution is defined on the whole interval of a definition of its coefficients. According to it follows that the coefficients of the differential Equation (17a) are defined on the whole interval Hence, its solution is also defined on the whole interval The conclusion regarding the definition of the solution of TVP (18) on the interval is obtained in the same way.
3.2. The Case of Two Decision-Makers
- (a)
- the assumption (H1) is fulfilled;
- (b)
- the solutions and of the TVPs (30) and (31), respectively, are defined on the whole interval
4. Several Special Cases
4.1. The Case without Control-Dependent Noise of the Diffusion Part of the Controlled System
- (a)
- the assumption (H1) is fulfilled;
- (b)
- the solution of the TVP (35a)–(35c) is defined on the whole intervalWe set
4.2. The Case when the Performance Criterion (4) Is Replaced by Performance Criterion of Type (7)
5. A Numerical Experiment
- Step 1.
- The aim of this step is to compute the gains matrices and
- Step 2.
- The aim is to compute for . We have:
- (A).
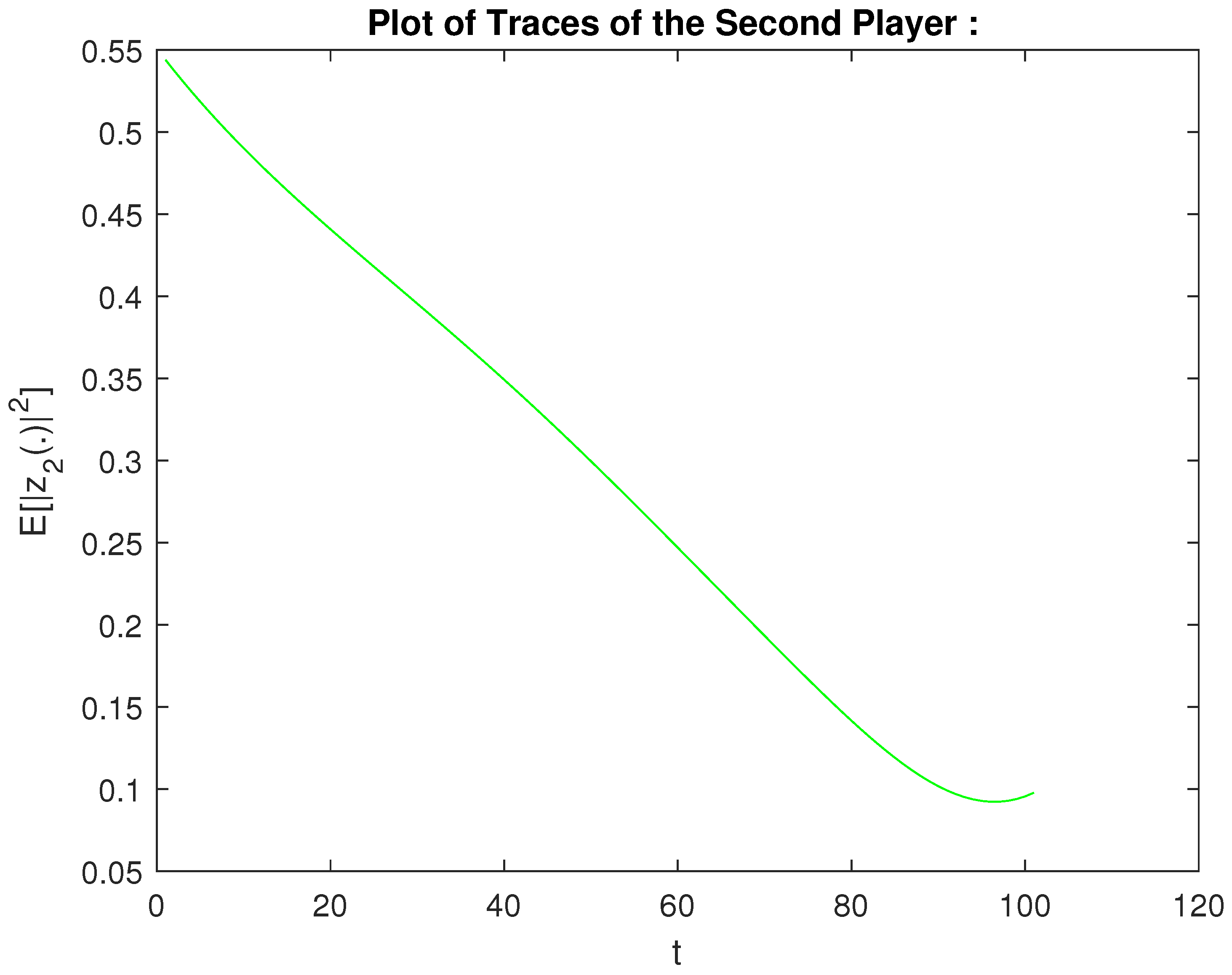
- The base variant using the above matrix coefficients. We have executed Step 1 and Step 2. The computed values for the signals of the players are given on Figure 1 and Figure 2 for the first player and the second player, respectively. Moreover, we have obtained the following values of for the players , i.e.,
- (B).
- We want to compute the output of the closed-loop system by using a control law (other than the optimal one) with . For this, we take and different from the optimal cases. We use the same matrix coefficients. After Step 1, we obtain the optimal values of and . Then, we compute the different values as follows ():The computations continue with Step 2 with . The computed values of areOne sees from (39) and (40) that the values of the obtained deviation from the target provided by the optimal control are better than the ones provided by another control.
6. Conclusions
- Direct extensions from this article can be considered as follows: the case when two or more players (with different cost functionals) are willing to cooperate or the case when for the tracking problem associated with a controlled system of type (1).
- Anther direction of future research can consider the case of a tracking problem with preview in the case when the controlled dynamical system is affected by state multiplicative and/or control multiplicative white noise perturbations. To our knowledge, this case was not yet considered in the existing literature. Some results in this direction have been reported, for example in [2,6,7], for the case of only one decision-maker and [29,30] for the case with more than one decision-maker.
Author Contributions
Funding
Conflicts of Interest
References
- Axelband, E. The structure of the optimal tracking problem for distributed-parameter systems. IEEE Trans. Autom. Control 1968, 13, 50–56. [Google Scholar] [CrossRef]
- Cohen, A.; Shaked, U. Linear discrete-time H∞-optimal tracking with preview. IEEE Trans. Autom. Control 1997, 42, 270–276. [Google Scholar] [CrossRef]
- Emami-Naeini, A.; Franklin, G. Deadbeat control and tracking of discrete-time systems. IEEE Trans. Autom. Control 1982, 27, 176–181. [Google Scholar] [CrossRef]
- Liu, D.; Liu, X. Optimal and minimum-energy optimal tracking of discrete linear time-varying systems. Automatica 1995, 31, 1407–1419. [Google Scholar] [CrossRef]
- Shaked, U.; de Souza, C.E. Continuous-time tracking problems in an H∞ setting: A game theory approach. IEEE Trans. Autom. Control 1995, 40, 841–852. [Google Scholar] [CrossRef]
- Gershon, E.; Shaked, U.; Yaesh, I. H∞ tracking of linear systems with stochastic uncertainties and preview. IFAC Proc. Vol. 2002, 35, 407–412. [Google Scholar] [CrossRef]
- Gershon, E.; Limebeer, D.J.N.; Shaked, U.; Yaesh, I. Stochastic H∞ tracking with preview for state-multiplicative systems. IEEE Trans. Autom. Control 2004, 49, 2061–2068. [Google Scholar] [CrossRef]
- Dragan, V.; Morozan, T. Discrete-time Riccati type equations and the tracking problem. ICIC Express Lett. 2008, 2, 109–116. [Google Scholar]
- Dragan, V.; Morozan, T.; Stoica, A.M. Mathematical Methods in Robust Control of Linear Stochastic Systems; Springer: New York, NY, USA, 2013. [Google Scholar]
- Han, C.; Wang, W. Optimal LQ tracking control for continuous-time systems with pointwise time-varying input delay. Int. J. Control. Autom. Syst. 2017, 15, 2243–2252. [Google Scholar] [CrossRef]
- Jin, N.; Liu, S.; Zhang, H. Tracking Problem for Itô Stochastic System with Input Delay. In Proceedings of the Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 1370–1374. [Google Scholar]
- Pindyck, R. An application of the linear quadratic tracking problem to economic stabilization policy. IEEE Trans. Autom. Control 1972, 17, 287–300. [Google Scholar] [CrossRef]
- Alba-Florest, R.; Barbieri, E. Real-time infinite horizon linear quadratic tracking controller for vibration quenching in flexible beams. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Taipei, Taiwa, 8–11 October 2006; pp. 38–43. [Google Scholar]
- Wang, Y.-L.; Yang, G.-H. Robust H∞ model reference tracking control for networked control systems with communication constraints. Int. J. Control. Autom. Syst. 2009, 7, 992–1000. [Google Scholar] [CrossRef]
- Ou, M.; Li, S.; Wang, C. Finite-time tracking control for multiple non-holonomic mobile robots based on visual servoing. Int. J. Control 2013, 86, 2175–2188. [Google Scholar] [CrossRef]
- Fu, Y.-M.; Lu, Y.; Zhang, T.; Zhang, M.-R.; Li, C.-J. Trajectory tracking problem for Markov jump systems with Itô stochastic disturbance and its application in orbit manoeuvring. IMA J. Math. Control. Inf. 2018, 35, 1201–1216. [Google Scholar] [CrossRef]
- Basar, T. Nash equilibria of risk-sensitive nonlinear stochastic differential games. J. Optim. Theory Appliations 1999, 100, 479–498. [Google Scholar] [CrossRef]
- Buckdahn, R.; Cardaliaguet, P.; Rainer, C. Nash equilibrium payoffs for nonzero-sum stochastic differential games. SIAM J. Control. Optim. 2004, 43, 624–642. [Google Scholar] [CrossRef]
- Sun, H.Y.; Li, M.; Zhang, W.H. Linear quadratic stochastic differential game: Infinite time case. ICIC Express Lett. 2010, 5, 1449–1454. [Google Scholar]
- Sun, H.; Yan, L.; Li, L. Linear quadratic stochastic differential games with Markov jumps and multiplicative noise: Infinite time case. Int. J. Innov. Comput. Inf. Control 2015, 11, 348–361. [Google Scholar]
- Nakura, G. Nash tracking game with preview by stare feedback for linear continuous-time systems. In Proceedings of the 50th ISCIE International Symposium on Stochastic Systems Theory and Its Applications, Kyoto, Japan, 1–2 November 2018; pp. 49–55. [Google Scholar]
- Fridman, A. Stochastic Differential Equations and Applications; Academic: New York, NY, USA, 1975; Volume I. [Google Scholar]
- Oksendal, B. Stoch. Differ. Equations; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Chung, K.L. Markov Chains with Stationary Transition Probabilities; Springer: Berlin/Heidelberg, Germany, 1967. [Google Scholar]
- Doob, J.L. Stochastic Processes; Wiley: New York, NY, USA, 1967. [Google Scholar]
- Boukas, E.R. Stochastic Switching Systems: Analysis and Design; Birkhäuser: Boston, MA, USA, 2005. [Google Scholar]
- Costa, O.L.V.; Fragoso, M.D.; Marques, R.P. Discrete-Time Markov Jump Linear Systems; Series: Probability and Its Applications; Springer: London, UK, 2005. [Google Scholar]
- Costa, O.L.V.; Fragoso, M.D.; Todorov, M.G. Continuous-Time Markov Jump Linear Systems; Series: Probability and Its Applications; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Nakura, G. Soft-Constrained Nash Tracking Game with Preview by State Feedback for Linear Continuous-Time Markovian Jump Systems. In Proceedings of the 2018 57th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Nara, Japan, 11–14 September 2018; pp. 450–455. [Google Scholar]
- Nakura, G. Nash Tracking Game with Preview by State Feedback for Linear Continuous-Time Markovian Jump Systems. In Proceedings of the 50th ISCIE International Symposium on Stochastic Systems Theory and Its Applications, Kyoto, Japan, 1–2 November 2018; pp. 56–63. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Drăgan, V.; Ivanov, I.G.; Popa, I.-L. A Game—Theoretic Model for a Stochastic Linear Quadratic Tracking Problem. Axioms 2023, 12, 76. https://doi.org/10.3390/axioms12010076
Drăgan V, Ivanov IG, Popa I-L. A Game—Theoretic Model for a Stochastic Linear Quadratic Tracking Problem. Axioms. 2023; 12(1):76. https://doi.org/10.3390/axioms12010076
Chicago/Turabian StyleDrăgan, Vasile, Ivan Ganchev Ivanov, and Ioan-Lucian Popa. 2023. "A Game—Theoretic Model for a Stochastic Linear Quadratic Tracking Problem" Axioms 12, no. 1: 76. https://doi.org/10.3390/axioms12010076
APA StyleDrăgan, V., Ivanov, I. G., & Popa, I.-L. (2023). A Game—Theoretic Model for a Stochastic Linear Quadratic Tracking Problem. Axioms, 12(1), 76. https://doi.org/10.3390/axioms12010076