

A Schelling Extended Model in Networks—Characterization of Ghettos in Washington D.C.


Abstract
1. Introduction
2. Literature Review
2.1. The Schelling Model and Other Related Models from Sociophysics
2.2. Segregation (GIS)
2.3. Related Works
3. Methods and Model
3.1. Network
3.2. Dissatisfaction Index
3.3. System Dynamics
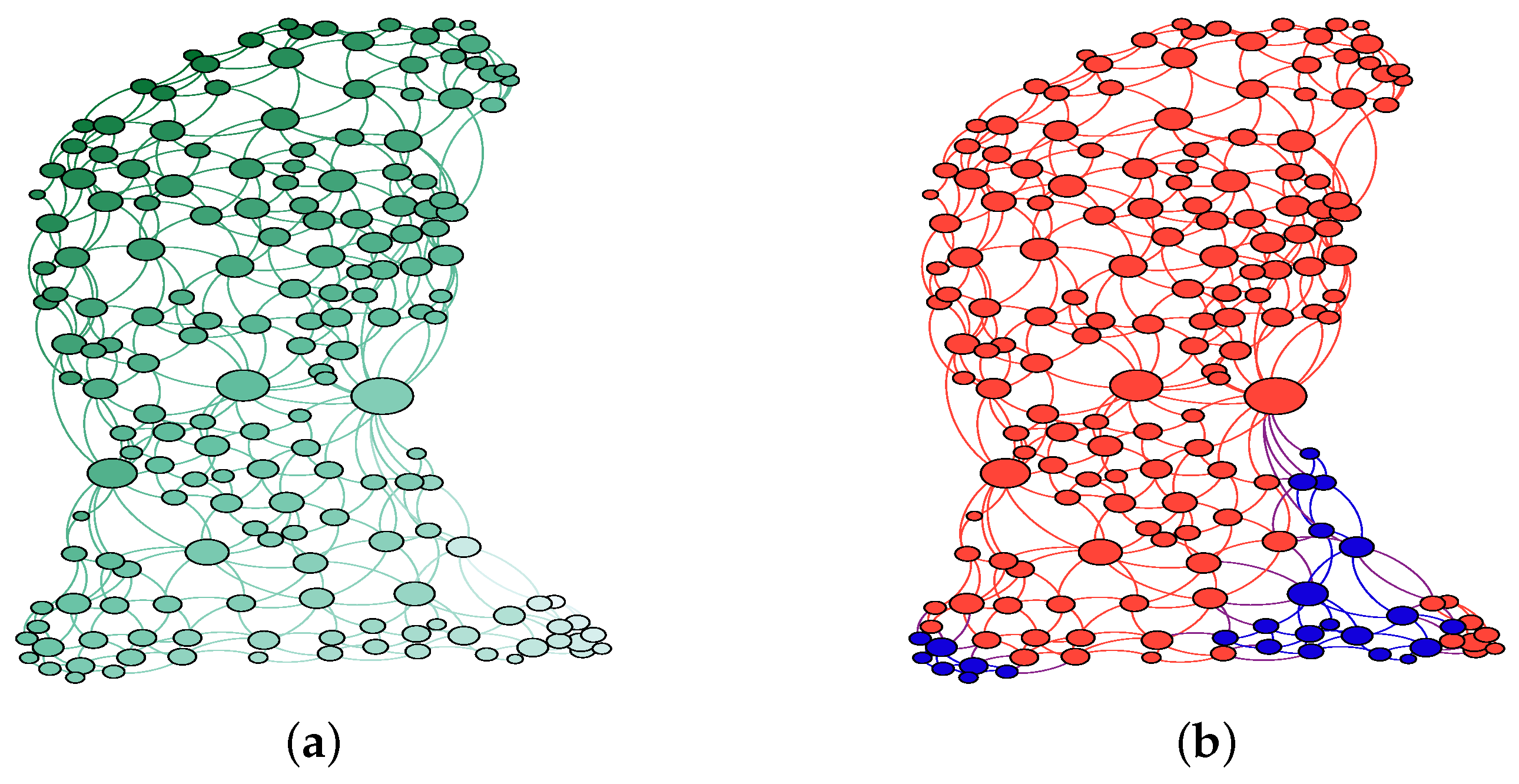
4. Results
4.1. Segregation in Washington D.C.
4.2. Model
4.3. Spatial Analysis and Machine Learning Results
4.4. Comparison
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BEG | Blume-Emery-Griffiths |
| EM | Expectation-Maximization |
| GIS | Geographic Information Systems |
| ML | Machine Learning |
| MAUP | Modifiable Areal Unit Problem |
| USA | United States of America |
| SA | Spatial Analysis |
| WPF | White People’s Fraction |
References
- Merriam Webster Dictionary. Available online: https://www.merriam-webster.com/ (accessed on 22 July 2022).
- Encyclopedia Britannica. Available online: https://www.britannica.com/topic/segregation-sociology (accessed on 22 July 2022).
- Schelling, T.C. Dynamic models of segregation. J. Math. Sociol. 1971, 2, 143–186. [Google Scholar] [CrossRef]
- Blume, M.; Emery, M.J.; Griffiths, R.B. Ising Model for the λ Transition and Phase Separation in He3 and He4 Mixtures. Phys. Rev. A 1971, 4, 1071–1077. [Google Scholar] [CrossRef]
- Ortega, D.; Rodríguez-Laguna, J.; Korutcheva, E. Avalanches in an extended Schelling model: An explanation of urban gentrification. Phys. A Stat. Mech. Appl. 2021, 573, 125943. [Google Scholar] [CrossRef]
- Vinković, D.; Kirman, A. A physical analogue of the Schelling model. Proc. Natl. Acad. Sci. USA 2006, 103, 19261–19265. [Google Scholar] [CrossRef]
- Dall’Asta, L.; Castellano, C.; Marsili, M. Statistical physics of the Schelling model of segregation. J. Stat. Mech. Theory Exp. 2008, 7, L07002. [Google Scholar] [CrossRef]
- Gauvin, L.; Nadal, J.-P.; Vannimenus, J. Schelling segregation in an open city: A kinetically constrained Blume-Emery-Griffiths spin-1 system. Phys. Rev. E 2010, 81, 066120. [Google Scholar] [CrossRef]
- Zhang, J. A dynamic model of residential segregation. J. Math. Sociol. 2004, 280, 147–170. [Google Scholar] [CrossRef]
- Fossett, M. Ethnic Preferences, Social Distance Dynamics, and Residential Segregation: Theoretical Explorations Using Simulation Analysis. J. Math. Sociol. 2006, 30, 185–273. [Google Scholar] [CrossRef]
- Jensen, P.; Matreux, T.; Cambe, J.; Larralde, H.; Bertin, E. Giant catalytic effect of altruists in Schelling’s segregation model. Phys. Rev. Lett. 2018, 120, 208301. [Google Scholar] [CrossRef]
- Flaig, J.; Houy, N. Altruism and fairness in Schelling’s segregation model. Phys. A Stat. Mech. Appl. 2019, 527, 121298. [Google Scholar] [CrossRef]
- Urselmans, L.; Phelps, S. A Schelling model with adaptive tolerance. PLoS ONE 2018, 3, e0193950. [Google Scholar] [CrossRef] [PubMed]
- Yao, J.; Wong, D.; Bailey, N.; Minton, J. Segregation Measures: A Methodological Review. Tijdschr. Econ. Soc. Geogr. 2018, 110, 235–250. [Google Scholar] [CrossRef]
- Massey, D.S.; Denton, N.A. The Dimensions of Residential Segregation. Soc. Forces 1988, 67, 281–315. [Google Scholar] [CrossRef]
- Duncan, O.D.; Duncan, B. A methodological analysis of segregation indexes. Am. Sociol. Rev. 1955, 20, 210–217. [Google Scholar] [CrossRef]
- O’sullivan, D.; Wong, D.W. A Surface based approach to measuring spatial segregation. Geogr. Anal. 2007, 39, 147–168. [Google Scholar] [CrossRef]
- Anselin, L. Local Indicators of Spatial Association—LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Farber, S.; O’kelly, M.; Miler, H.J.; Neutens, T. Measuring Segregation Using Patterns of Daily Travel Behavior: A Social Interaction Based Model of Exposure. J. Transp. Geogr. 2015, 49, 26–38. [Google Scholar] [CrossRef]
- Harris, R. Measuring the scales of segregation: Looking at the residential separation of White British and other schoolchildren in England using a multilevel index of dissimilarity. Trans. Inst. Br. Geogr. 2017, 42, 432–444. [Google Scholar] [CrossRef]
- Reitano, M.; Cerreta, M.; Poli, G. Evaluating Socio-Spatial Exclusion: Local Spatial Indices of Segregation and Isolation in Naples (Italy). In Proceedings of the ICCSA2020, Cagliari, Italy, 1–4 July 2020. [Google Scholar]
- Jelinski, D.E.; Wu, J. The modifiable areal unit problem and implications for landscape ecology. Landsc. Ecol. 1996, 11, 129–140. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Wong, D.W.S. The modifiable areal unit problem in multivariate statistical analysis. Environ. Plan A 1991, 23, 1025–1044. [Google Scholar] [CrossRef]
- Benenson, I.; Hatna, E.; Or, E. From Schelling to Spatially Explicit Modeling of Urban Ethnic and Economic Residential Dynamics. Sociol. Methods Res. 2009, 37, 463–497. [Google Scholar] [CrossRef]
- Fagiolo, G.; Valente, M.; Vriend, N.J. Segregation in networks. J. Econ. Behav. Organ. 2007, 64, 316–336. [Google Scholar] [CrossRef]
- Cortez, V.; Rica, S. Dynamics of the Schelling Social Segregation Model in Networks. Procedia Comput. Sci. 2015, 61, 60–65. [Google Scholar] [CrossRef][Green Version]
- Banos, A. Network effects in Schelling’s model of segregation: New evidences from agent-based simulation. Environ. Plann. B Plann. Des. 2010, 38, 393–405. [Google Scholar] [CrossRef]
- Crooks, A.; Malleson, M.; Manley, E.; Heppenstall, A. Agent-Based Modelling & Geographical Information Systems. A Practical Primer; SAGE: London, UK, 2019. [Google Scholar]
- Crooks, A.T. Constructing and implementing an agent-based model of residential segregation through vector GIS. Int. J. Geogr. Inf. Sci. 2009, 24, 661–675. [Google Scholar] [CrossRef]
- QGIS Development Team (2022). QGIS Geographic Information System. Open Source Geospatial Foundation Project. Available online: http://qgis.osgeo.org (accessed on 15 May 2022).
- Hagberg, A.; Swart, P.; Chult, D. Exploring Network Structure, Dynamics, and Function Using NetworkX. In Proceedings of the SciPy2008, Pasadena, CA, USA, 19–24 August 2008. [Google Scholar]
- Asch, C.M.; Musgrove, G.D. Chocolate City: A History of Race and Democracy in the Nation’s Capital; University of North Carolina Press: Chapel Hill, NC, USA, 2017. [Google Scholar]
- Area Vibes. Available online: https://www.areavibes.com/washington-dc/most-dangerous-neighborhoods/ (accessed on 24 July 2022).
- United States Census Bureau. Available online: https://www.census.gov (accessed on 20 June 2022).
- Walker, K.; Herman, M. Tidycensus: Load US Census Boundary and Attribute Data as ‘tidyverse’ and ‘sf’-Ready Data Frames R Package Version 1.2.1. 2022. Available online: https://CRAN.R-project.org/package=tidycensus (accessed on 20 April 2022).
- Anselin, L.; Ibnu, S.; Youngihn, K. GeoDa: An Introduction to Spatial Data Analysis. Geogr. Anal. 2006, 38, 5–22. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Y.; Zhang, Y.; Liu, Y.; Wang, B.; Zhang, G. Spatially Varying Relationships between Land Subsidence and Urbanization: A Case Study in Wuhan, China. Remote Sens. 2022, 14, 291. [Google Scholar] [CrossRef]
- Do, C.B.; Batzoglou, S. What is the expectation maximization algorithm? Nat. Biotechnol. 2008, 26, 897–899. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. SIGKDD Explor. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013; Available online: http://www.R-project.org/ (accessed on 20 May 2022).
- Hornik, K.; Buchta, C.; Zeileis, A. Open-Source Machine Learning: R Meets Weka. Comput. Stat. 2009, 24, 225–232. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 11, 81–106. [Google Scholar] [CrossRef]
- Wong, D. WorldMinds: Geographical Perspective on 100 Problems; Kluwer Publishers: Dordrecht, The Netherlands, 2004; pp. 571–575. [Google Scholar]
- Azariadis, C.; Stachurski, J. Handbook of Economic Growth; Elsevier: Amsterdam, The Netherlands, 2005; Chapter 5: Poverty Traps. [Google Scholar]
- Rothstein, R. The Color of Law; Liveright Publishing Corporation: New York, NY, USA, 2018. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ortega, D.; Korutcheva, E. A Schelling Extended Model in Networks—Characterization of Ghettos in Washington D.C. Axioms 2022, 11, 457. https://doi.org/10.3390/axioms11090457
Ortega D, Korutcheva E. A Schelling Extended Model in Networks—Characterization of Ghettos in Washington D.C. Axioms. 2022; 11(9):457. https://doi.org/10.3390/axioms11090457
Chicago/Turabian StyleOrtega, Diego, and Elka Korutcheva. 2022. "A Schelling Extended Model in Networks—Characterization of Ghettos in Washington D.C." Axioms 11, no. 9: 457. https://doi.org/10.3390/axioms11090457
APA StyleOrtega, D., & Korutcheva, E. (2022). A Schelling Extended Model in Networks—Characterization of Ghettos in Washington D.C. Axioms, 11(9), 457. https://doi.org/10.3390/axioms11090457