
Logarithmic SAT Solution with Membrane Computing


Abstract
:1. Introduction
2. Background
2.1. The SAT Problem
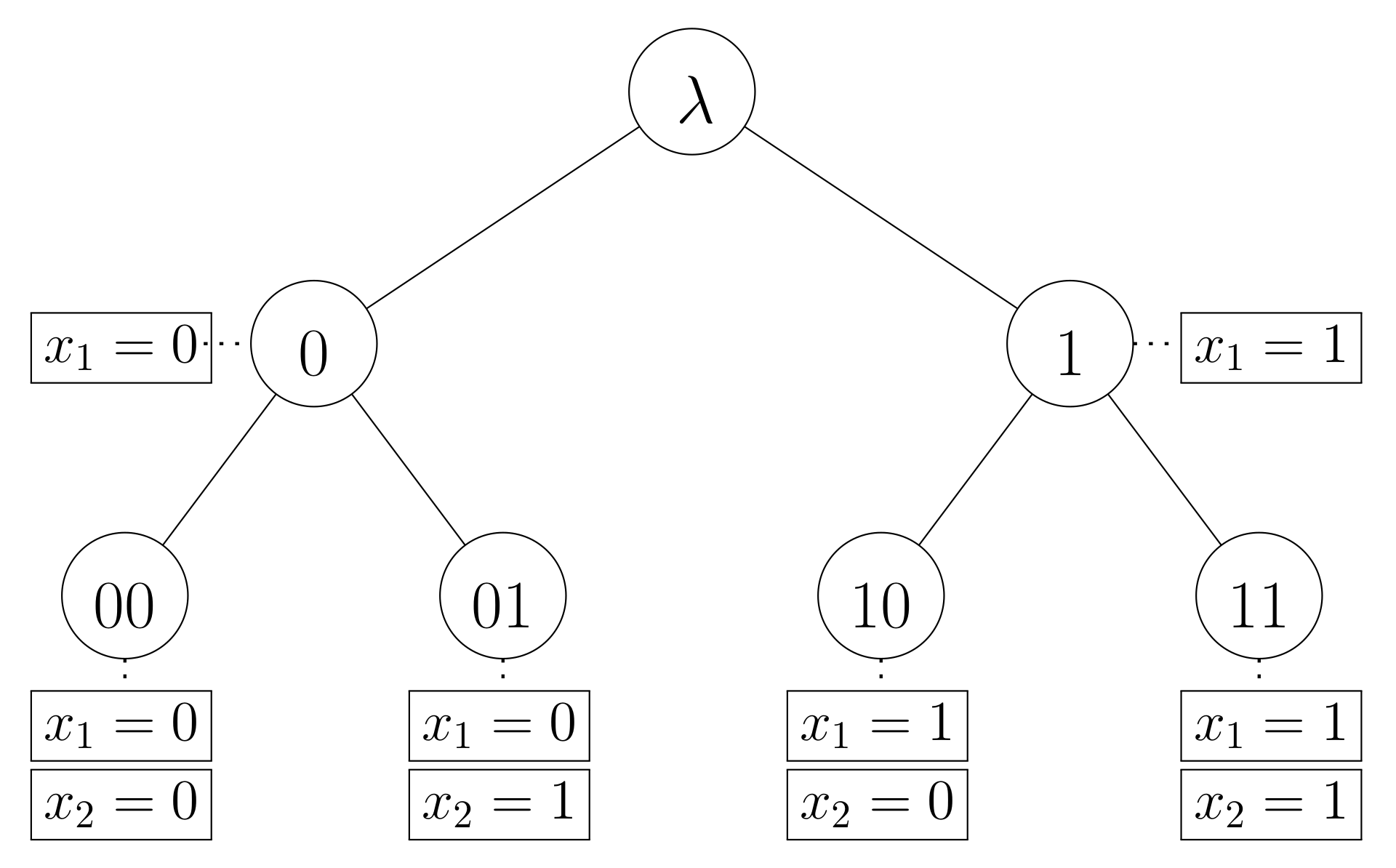
| . |
| . |
| Branch | SectionAllocations | Subset |
| 00 | ||
| 01 | { 2 } | |
| 10 | { 1 } | |
| 11 | { 1, 2 } |
2.2. cP Systems
| Listing 1. Simplified syntax for single-cell cP systems. Lhs = left-hand-side, rhs = right-hand-side, var-X = X may contain variables. Braces ({,}) and brackets ([,]) are meta-syntactic constructs followed by repetition bounds; here, braces generate multisets, whereas brackets generate sequences. |
| <top-cell> ::= <state> <objects> <state> ::= <atom> <objects> ::= {<atom> | <sub-cell>} <sub-cell> ::= <functor> ’(’<objects> [’;’ <objects>] ’)’ <functor> ::= <atom> ................................................................................................................................................ <rule> ::= <lhs> <rhs> [’|’ <promoters>] <mode> ::= ’1’ | ’+’ <lhs> ::= <state> <var-objects> <rhs> ::= <state> <var-objects> <state> ::= <atom> <promoters> ::= <var-objects> <var-objects> ::= {<variable> | <atom> | <var-sub-cell>} <var-sub-cell> ::= <functor> ’(’<var-objects> [’;’ <var-objects>] ’)’ <functor> ::= <atom> |
- Its lhs state must match the current top-cell state.
- Its rhs state must match the already committed next state, if any, as further detailed below, in the section on weak priority order.
- The rule must be completely instantiated, i.e., all its variables must be replaced by ground objects, ensuring that its lhs and promoter var-objects match extant top-cell objects.
- Commits to the next state.
- Consumes (deletes) extant top-cell objects matching its lhs. Promoters must also match extant top-cell objects, but are not consumed by the rule.
- Creates new objects as indicated by its instantiated rhs. Newly created objects are temporary unavailable and become available after the end of the current step only, as in traditional P systems.
2.3. Examples
- Matching deterministically instantiates one single unifier: .
- Matching fails.
- Matching deterministically instantiates one single set of unifiers: .
- Matching non-deterministically instantiates one of the following four sets of unifiers: ; ; ; .
3. The Logarithmic cP SAT Solution
3.1. Building Trees
| Listing 2. Ruleset for building complete binary trees of size n. | |
| (1) (2) (3) (4) (5) (6) (7) (8) | |
| k | h | branches–as bit strings | branches–as cP encodings |
| 0 | 1 | 0; 1 | |
| 1 | 2 | 00; 01; 10; 11 | |
| 2 | 4 | 0000; 0001; …; 1111 |
3.2. Decorating Trees with Variable Allocations
| Listing 3. Ruleset for decorating trees. | |
| (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) | |
3.3. Formula Evaluations
| Listing 4. Ruleset for formula evaluations (continuing from Ruleset 3). | |
| (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) | |
| Branch | Allocations | Eval. literals | Eval. clauses | Eval. formula |
| 00 | 0, 1 | 0 | ||
| 01 | 1, 1 | 1 | ||
| 10 | 1, 1 | 1 | ||
| 11 | 1, 0 | 0 |
3.4. Other NP-Complete Problems
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Traces for Sections “Decorating Trees with Variable Allocations” and “Ruleset Evaluations”
- Enter state , with immutable objects (not further listed unless actually useful):
- Step , rule (1): Create initial height 1 tree objects, t and a.
- Enter state , with:
- Step , rules (3-4): Enter the loop, duplicate tree objects t and a, as and .
- Enter state , with:
- Step , rules (5-7): Create double height tree by the Cartesian product of t and .
- Enter state , with:
- Step , rules (8-11): Create , allocation attributes for .
- Enter state , with:
- Step , rules (12–14): Double the height and rename temporary tree objects and as t and a.
- Enter state , with:
- Step , rule (2): Take loop exit.
- Enter state (end of ruleset 3, and start of 4), with:
- Step , rule (15): Multiply formula literals, making copies for each branch.
- Enter state , with:
- Step , rule (16): Evaluate literals.
- Enter state , with:
- Step , rules (17–19): Disjunctions between literals.
- Enter state , with:
- Step , rules (20–22): Conjunctions between clauses.
- Enter state , with:
- Step , rules (23–25): Disjunction between branches and final decision.
- -
- Intermediate snapshot after rules (23–24):
- Enter state (end, with success), with:
Appendix B. Pseudocode for Section “Building Trees”
| Listing A1. Pseudocode for the ruleset of Listing 2. | |
| : ; : ifthen gotoelse : null null : ; null goto : | // initial tree height and branches // altwhiledo … // copy current branches // concatenate all branch pairs // next tree // next height // end |
Appendix C. Pseudocode for Section “Decorating Trees with Variable Allocations”
| Listing A2. Pseudocode for the ruleset of Listing 3. | |
| : ; : ifthen gotoelse : null null : null null : ; null ; null goto : | // initial tree height and branches // initial branch variable allocations // altwhiledo … // copy current branches // copy allocations and shift indices by h // concatenate all branch pairs // lift from A // lift from // next tree // next allocations // next height // end (of this phase) |
Appendix D. Pseudocode for Section “Ruleset Evaluations”
| Listing A3. Pseudocode for the ruleset of Listing 4. | |
| : // attach literal copies to each branch in T : // evaluate literals for branch t and clause k null : // evaluate each clause for branch t, using disjunctions between literals null : // evaluate formula for branch t, using conjunctions between clauses null : // the decision is yes, if there is at least one branch evaluating true ifthen 1 else 0 null : | // F is (normally) a set // take F’ as a multiset! // take F″ as a set // take F‴ as a set // end |
References
- Sipser, M. Introduction to the Theory of Computation; Cengage Learning: Boston, MA, USA, 2012. [Google Scholar]
- Baker, B.S. Approximation algorithms for NP-complete problems on planar graphs. J. ACM (JACM) 1994, 41, 153–180. [Google Scholar] [CrossRef]
- Downey, R.G.; Fellows, M.R. Fixed-parameter tractability and completeness I: Basic results. SIAM J. Comput. 1995, 24, 873–921. [Google Scholar] [CrossRef] [Green Version]
- Henderson, A.; Nicolescu, R.; Dinneen, M.J. Sublinear P System Solutions to NP-Complete Problems; CDMTCS Report 559; University of Auckland: Auckland, New Zealand, 2022; Available online: https://www.cs.auckland.ac.nz/research/groups/CDMTCS/researchreports/download.php?selected-id=831 (accessed on 14 January 2022).
- Manca, V. DNA and membrane algorithms for SAT. Fundam. Inform. 2002, 49, 205–221. [Google Scholar]
- Nagy, B. On efficient algorithms for SAT. In International Conference on Membrane Computing; Csuhaj-Varjú, E., Gheorghe, M., Rozenberg, G., Salomaa, A., Vaszil, G., Eds.; LNCS 7762; Springer: Berlin/Heidelberg, Germany, 2012; pp. 295–310. [Google Scholar]
- Pan, L.; Alhazov, A. Solving HPP and SAT by P systems with active membranes and separation rules. Acta Inform. 2006, 43, 131–145. [Google Scholar] [CrossRef]
- Song, B.; Pérez-Jiménez, M.J.; Pan, L. An efficient time-free solution to SAT problem by P systems with proteins on membranes. J. Comput. Syst. Sci. 2016, 82, 1090–1099. [Google Scholar] [CrossRef]
- Song, B.; Zhang, C.; Pan, L. Tissue-like P systems with evolutional symport/antiport rules. Inf. Sci. 2017, 378, 177–193. [Google Scholar] [CrossRef]
- Păun, G. Computing with membranes. J. Comput. Syst. Sci. 2000, 61, 108–143. [Google Scholar] [CrossRef] [Green Version]
- Păun, G. P systems with active membranes: Attacking NP-Complete problems. J. Autom. Lang. Comb. 2001, 6, 75–90. [Google Scholar] [CrossRef]
- Martín-Vide, C.; Păun, G.; Pazos, J.; Rodríguez-Patón, A. Tissue P systems. Theor. Comput. Sci. 2003, 296, 295–326. [Google Scholar] [CrossRef] [Green Version]
- Ionescu, M.; Păun, G.; Yokomori, T. Spiking neural P systems. Fundam. Inform. 2006, 71, 279–308. [Google Scholar]
- Nicolescu, R.; Henderson, A. An Introduction to cP Systems. In Enjoying Natural Computing: Essays Dedicated to Mario de Jesús Pérez-Jiménez on the Occasion of His 70th Birthday; Graciani, C., Riscos-Núñez, A., Păun, G., Rozenberg, G., Salomaa, A., Eds.; LNCS 11270; Springer: Berlin/Heidelberg, Germany, 2018; pp. 204–227. [Google Scholar]
- Henderson, A.; Nicolescu, R. Actor-Like cP Systems. In Membrane Computing; Hinze, T., Rozenberg, G., Salomaa, A., Zandron, C., Eds.; LNCS 11399; Springer: Berlin/Heidelberg, Germany, 2019; pp. 160–187. [Google Scholar]
- Henderson, A.; Nicolescu, R.; Dinneen, M.J. Solving a PSPACE-complete problem with cP systems. J. Membr. Comput. 2020, 2, 311–322. [Google Scholar] [CrossRef]
- Ishdorj, T.O.; Leporati, A.; Pan, L.; Zeng, X.; Zhang, X. Deterministic solutions to QSAT and Q3SAT by spiking neural P systems with pre-computed resources. Theor. Comput. Sci. 2010, 411, 2345–2358. [Google Scholar] [CrossRef] [Green Version]
- Leporati, A.; Manzoni, L.; Mauri, G.; Porreca, A.E.; Zandron, C. Solving QSAT in sublinear depth. In Membrane Computing; Hinze, T., Rozenberg, G., Salomaa, A., Zandron, C., Eds.; LNCS 11399; Springer: Berlin/Heidelberg, Germany, 2019; pp. 188–201. [Google Scholar]
- Gutiérrez-Naranjo, M.A.; Pérez-Jiménez, M.J.; Romero-Campero, F.J. A Linear Solution for QSAT with Membrane Creation. In Membrane Computing; Freund, R., Păun, G., Rozenberg, G., Salomaa, A., Eds.; LNCS 3850; Springer: Berlin/Heidelberg, Germany, 2006; pp. 241–252. [Google Scholar]
- Alhazov, A.; Pérez-Jiménez, M.J. Uniform solution of QSAT using polarizationless active membranes. In International Conference on Machines, Computations, and Universality; Durand-Lose, J., Margenstern, M., Eds.; LNCS 4664; Springer: Berlin/Heidelberg, Germany, 2007; pp. 122–133. [Google Scholar]
- Leporati, A.; Manzoni, L.; Mauri, G.; Porreca, A.; Zandron, C. Characterizing PSPACE with shallow non-confluent P systems. J. Membr. Comput. 2019, 1, 75–84. [Google Scholar] [CrossRef] [Green Version]
- Leporati, A.; Mauri, G.; Zandron, C.; Păun, G.; Pérez-Jiménez, M. Uniform solutions to SAT and Subset Sum by spiking neural P systems. Nat. Comput. 2009, 8, 681–702. [Google Scholar] [CrossRef]
- Stamm-Wilbrandt, H. Programming in Propositional Logic or Reductions: Back to the Roots (Satisfiability); Sekretariat für Forschungsberichte, Inst. für Informatik III, University of Bonn: Bonn, Germany, 1993. [Google Scholar]

{kind=link}
| Paper | P System Variant | #Templates | #Rules | Runtime | Preprocessing |
|---|---|---|---|---|---|
| [7] 2006 | with active membranes | 27 | |||
| [8] 2016 | with proteins on membranes | 22 | |||
| [9] 2017 | tissue-like | 29 | |||
| [4] 2021 | cP system | 19 | 19 | NA | |
| † 2021 | cP system | 25 | 25 | NA |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nicolescu, R.; Dinneen, M.J.; Cooper, J.; Henderson, A.; Liu, Y. Logarithmic SAT Solution with Membrane Computing. Axioms 2022, 11, 66. https://doi.org/10.3390/axioms11020066
Nicolescu R, Dinneen MJ, Cooper J, Henderson A, Liu Y. Logarithmic SAT Solution with Membrane Computing. Axioms. 2022; 11(2):66. https://doi.org/10.3390/axioms11020066
Chicago/Turabian StyleNicolescu, Radu, Michael J. Dinneen, James Cooper, Alec Henderson, and Yezhou Liu. 2022. "Logarithmic SAT Solution with Membrane Computing" Axioms 11, no. 2: 66. https://doi.org/10.3390/axioms11020066
APA StyleNicolescu, R., Dinneen, M. J., Cooper, J., Henderson, A., & Liu, Y. (2022). Logarithmic SAT Solution with Membrane Computing. Axioms, 11(2), 66. https://doi.org/10.3390/axioms11020066