1. Introduction
Aggregation [
1,
2] is a process of merging several inputs to obtain a single representative output value. The mathematical operator carrying out this process is called an aggregation operator. Aggregation operators play an important role in many fields of science, including decision making [
3,
4,
5], image processing [
6,
7], pattern recognition [
8,
9] and machine learning [
10], where problems are related to the fusion of data or information. In a decision-making scenario, aggregation of information comprises all those situations where multiple opinions or different attributes are included and the intention is to make a potentially consistent decision with the primary information. For more details on the aggregation operators, the reader can turn to [
11,
12,
13].
Conventional aggregation operators mostly consider a fixed number of input arguments. However, in some applications, data cardinality changes can often occur—in hierarchical systems, for example—and each time a different aggregation operator needs to be used to aggregate the new collection of elements. The issue of aggregating dimensional data was analyzed in terms of the notion of the extended aggregation operator [
14,
15,
16,
17,
18,
19], and some well-known aggregation operators, such as the ordered weighted averaging operator and Quasilinear weighted mean, have already been extended to explore their applicability in aggregating data of various dimensions. However, the aforementioned aggregation operators emphasize the importance of each input, yet they are unable to capture interrelationships of any kind among the aggregated arguments. In this regard, Calvo et al. [
19] introduced the concept of an extended discrete Choquet integral to aggregate inputs of various dimensions under the same framework. In this article, we focus on developing and analyzing an extended version of the partitioned Bonferroni mean operator to aggregate multidimensional data under the same framework, along with modeling specific requirements in the partition structure interrelationship among criteria.
The PBM is one of the variants of the BM [
20] operator. The constructional interpretation of the BM operator provided by Yager [
21], who analyzed the BM as a combination of averaging and an “anding” operator, influenced the researchers to work on that, and as a result, sophisticated evolution of the BM operator and its several variants has been developed. Dutta and Guha [
22] introduced the PBM operator by modeling partitioned structure interrelationship patterns among the criteria. In recent years, the PBM operator has received a lot of attention from researchers in a variety of decision-making contexts [
23,
24,
25]. To handle the imprecision and vagueness in the data, the PBM operator has been applied to distinct, higher-order fuzzy sets such as the linguistic 2-tuple data [
22], the interval-valued fuzzy set [
26], intuitionistic fuzzy sets [
23], the Pythagorean uncertain linguistic set [
27] and the q-rung orthopair fuzzy [
28]. Added to that, in the literature, amalgamation of different aggregation operators with PBM has been accomplished. For instance, motivated by the ideal of the geometric mean and the PBM, Liu and Liu [
29] developed the partitioned geometric Bonferroni mean (PGBM) operator. Liu et al. [
30] integrated the Maclaurin symmetric mean operator into the PBM operator and proposed a new operator named the partitioned Maclaurin symmetric mean (PMSM) operator. However, the PBM operators for data of various dimensions have not been studied yet.
As influenced by the concept of the extended aggregation operator, Banerjee et al. [
31] analyzed the PBM operator for aggregating data of various dimensions by defining new partition sets with the changes of data cardinality and named it the
operator. The main advantage of the proposed operator over other existing variants of BM is its ability to aggregate multi-dimensional input arguments into one formulation with partitioned structure interrelationship patterns. However, there is a gap in the development and application of
:
Weight vector analysis associated with multi-dimensional was not done.
moreover, along with partitioned structure interrelationship to model genuine representation of the real situation, modelling specific requirements is also important which was missing in that paper.
This observation motivated us to develop a generalized multi-dimensional
with suitable replacements of different components to explicitly and deeply understand its aggregation mechanism. In order to assign weight vectors to the multi-dimensional
, we focus on the construction of a probabilistic triangle or triangle of weights [
14,
15,
18]. To implement those weighting triangles, we first ascertained under which conditions the proposed operator is monotonic. In this sense, we established the condition for weight vectors satisfied by the weighting triangle associated with our proposed multi-dimensional
. Further, the application of the proposed operator was explored in a hierarchical model. Hierarchical decomposition [
32,
33,
34] basically assists decision makers by providing a ranking of alternatives not only considering the whole set of criteria but also with respect to any intermediate higher-level point of view. Since in each level of the hierarchy, the number of criteria considered varies in dimensions, this model is intrinsically multi-dimensional. Moreover, the elementary criterion set of a hierarchical system can follow a partition structure interrelationship pattern where each class of the partition comprises the elementary sub-criteria belonging to the same criteria of the immediately upper level (more explanation is provided in
Section 5). These observations motivated us to synthesize the features of the hierarchical decomposition in the context of a multi-dimensional
operator.
With these incentives, in this contribution, we
introduce the concept of the generalized multi-dimensional (refer to it as the operator), and an in-depth analysis of the proposed operator is presented.
estimate the weight vector associated with the proposed operator.
handle a hierarchical attribute set where alternatives are evaluated based on the criteria which are not at the same level but structured into several levels using the proposed operator.
The rest of the paper is as follows: In
Section 2, we describe some basic concepts of the extended aggregation operator and partitioned Bonferroni mean (PBM) operator. In
Section 3, we present a generalized version of the multi-dimensional
(named as
) operator.
Section 4 provides the conditions of weight vectors satisfied by the weighting triangle associated with the proposed operators. The evolution of the proposed operator for handling the hierarchical structure of criteria is provided in
Section 5.
Section 6 explains the implementation of the proposed operators in the child’s home environment index assessment through a case-based example with a detailed analysis. Finally, in
Section 7, we conclude the discussion with some future work.
2. Preliminaries
Here we begin by recalling the concept of the extended aggregation operator first.
2.1. Brief Review of Extended Aggregation Operators
Suppose
represents the set of all finite ordered lists that can be constructed from
. In order to compare two ordered lists with different dimensions, the following binary relations on
can be considered.
Definition 1 ([
14])
. Suppose and are the two elements from . Then, the orderings on can be considered as- (i)
if and if for all .
- (ii)
if , for all , and if , then
.
- (iii)
if , for all , and if , then
.
Thus, the binary relations
are partial orderings on
. The first order is the standard partial order of Cartesian products of
related to the considered dimensions. As an extension of this order, two other partial orders (
-order and
-order) were introduced in [
14], which refine the
-order.
Now, we recall the definitions of the extended aggregation operator which was introduced in [
18,
19].
Definition 2 ([
19])
. A mapping is an extended aggregation operator on if for a fixed , the aggregation operator satisfies the monotonicity and boundary conditions and for all . However, with the help of the above definition, we have problems when comparing inputs with different numbers of arguments.
Definition 3 ([
18])
. A mapping is an extended aggregation operator on ifit is monotonic with respect to , and —i.e., for all .
is idempotent—i.e., for all and .
However, the above definition suffers from the false assumption of the idempotency condition. Following [
14], if we replace condition (ii) of the above definition by
for any
, then it will inevitably lead to idempotency of
. With this observation in this contribution, we present the definition of an extended aggregation operator which we refer to as regular extended aggregation operator as follows.
Definition 4. A mapping is a regular extended aggregation operator on if
it is monotonic with respect to , and —i.e., for all .
for any .
Observe that, for any
,
and thus
Hence, is an extended aggregation operator if and only if for each , the restriction is an n-ary aggregation operator. On the other hand, can be regular extended aggregation operator only if is an n-ary idempotent aggregation operator for each (but this condition is not sufficient). In this contribution, we are interested in regular extended aggregation operators.
Next, we recall the definition of the weighting triangle associated with the weighted extended aggregation operator that collects the weights of any weighting list , where .
Definition 5 ([
18])
. A weighting triangle is a collection of numbers ,
for ,
such that for each .
It can be represented as It can be denoted as .
Some well-known extended aggregation operators, for instance, the extended ordered weighted averaging (EOWA) operator [
35] and the extended quasi-linear weighted mean (EQLWM) operator [
18], are examples of idempotent extended aggregation operators which may not satisfy the
,
monotonicity conditions (i.e., may not be regular).
2.2. Partitioned Bonferroni Mean and Generalized Partitioned Bonferroni Mean Operator
As mentioned earlier, in this study our motivation was to employ the PBM operator for aggregating hierarchical data. Thus, in this section, we recall the definitions of the PBM operator and its several generalizations.
We are starting with the definition of BM. Suppose denotes the degree of satisfaction of the alternative X associated with the criterion set , where . Then, the BM operator can be defined as:
Definition 6 ([
21])
. For with , the Bonferroni mean operator is a mapping such that BM operator fundamentally captures the homogeneous interaction between all pairs of input arguments. However, in practice, the data may be related to each other in a different way.
With increasing complexity, sometimes some criteria are related to each other, and some criteria are not related to any other criteria. In that case, we can divide the criteria into two sets:
: set of criteria that are related to others;
: the set of criteria which are not related to any criteria such that
and
. Without loss of generality, assume that, first,
among the criterion set
is partitioned into
mutually disjoint partition sets
where
for all
and
. Clearly,
. We further assume that the criteria of each partition set
are interrelated, and there is no interrelationship among criteria of any two partition sets
and
whenever
and
. The remaining
criteria are not related to any other criteria. With this information in the background, the partitioned Bonferroni mean (PBM) [
26] operator of the collection of inputs
can be defined as follows:
Definition 7 ([
26])
. For with , the partitioned Bonferroni mean operator is a mapping such that
with the convention
and
= cardinality of
.
From the construction of the PBM operator, it is clear that the aggregated value computed by the PBM depends on the interrelationships among the inputs. The interpretation, modeling capability and relation of the PBM with the other existing aggregation operators can be found in [
22,
26]. Apart from that, one can easily verify that the PBM operator satisfies the idempotency, monotonicity and boundary conditions.
In [
36], authors expressed the PBM operator as a composite
n-ary aggregation operator by generalizing it in terms of other aggregation operators. The generalized PBM (
) is defined as follows:
Definition 8 ([
36])
. Let, , , , and for all ; are the different aggregation operators; and is the conjunctive aggregation operator having the inverse diagonal . Then, the generalized version of a composite n-ary operator , where the criterion set following the partitioned structure interrelationship pattern is given bywhere denotes the set of indices of the criteria from the partition set , . Here we consider the convention that the aggregation of no information is zero. Thus, if
, then this imposes on the aggregation operator
, and if
, then this imposes on the aggregation operator
. A detailed study in this regard can be found in the article [
36].
Now if every criterion is related to the rest of the criterion set and there exists no independent criterion (i.e.,
), then
reduces to the generalized BM (
) [
37] operator, as follows:
where
is the conjunctive aggregation operator having the inverse diagonal
.
and
for
are different aggregation operators, and
denotes the index of the criterion set
C.
3. Generalized Version of the Multi-Dimensional Extended-PBM Operator
In this section, we try to draft the generalized version of the multi-dimensional extended aggregation operator following a partitioned structure interrelationship pattern.
We start the process by changing the dimensions of input arguments from n to , i.e., we include one new criteria in the old criterion set C. Hence, the old criterion set is updated to . Suppose is the degree of satisfaction of the alternative X under the criteria , with the assumption that . With this assumption, we can define the -order between and ; i.e., we can say that , where is the new input set.
As we are updating the old criterion set C to , in that instance two cases are possible.
The new criterion may be not interrelated with any of the other criteria . In that case, the new partition structure is .
Alternatively, is interrelated with all the criteria of a particular partition set, for example, , and then the new partition structure is .
Following the similar background and notation used for the PBM operator and previously defined composite n-ary operator, we analyze both cases.
- Case I.
When the new criterion
is not interrelated with any of the other criteria
, then for the input arguments
, we obtain the aggregated value as
where
is the degree of satisfaction of the alternative
X under the criterion
.
Suppose all the different aggregation operators used to define the
operator possess the property of non-decreasing in each argument. Since
is the convex combination of
and
with the assumption that
, we can say
which implies
- Case II.
If
is interrelated with all the criteria of a particular partition set, say,
, then, partition set
is updated to
, and the construction of the rest of the partition sets will remain same. Suppose
and
are the collections of inputs associated with the
k-th partition set
; then we can modify the aggregation operator for the partition
with input arguments
as
Thus, a comprehensive composite
-ary aggregation operator satisfying the partitioned structure interrelationship pattern can be mathematically presented as
Since
, and from the assumption, we can say
; hence,
which implies
Thus, by analyzing case I and case II we can conclude that, for any two collections of input arguments
and
with varying numbers of components, if
, then,
By generalizing the above-defined statement for data of various dimensions, we can establish the property of monotonicity as:
Suppose, for any with , there exists some element in with where , so that and . Then, for any two collections of input arguments and with varying numbers of components, if and if all the different aggregation operators used to define the operator posses the property of not decreasing in each argument.
Similarly, the case when is considered can be discussed.
Simultaneously, the idempotency condition of operator for any fixed number of input argument can be easily proved, i.e., Following these two characterizations, we can conclude that the composite varying dimensional aggregation operator satisfying the partitioned structure interrelationship pattern belongs to the class of regular extended aggregation operators on .
Following that, we can introduce the formal definition of the operator as:
Definition 9. An extended aggregation operator is called a generalized multi-dimensional extended-PBM operator if , where and there are and such that for each , the restriction is a operator related to partition of so that for any and any with , there exists some element in with so that and .
Considering some particular operator for for all and , the operator can be transformed into one of these cases:
- I.
Let us fix
,
,
,
,
,
,
for all
and
. Then, our proposed
operator reduces to the
operator proposed by Banerjee et al. [
31].
- II.
If we fix , and , then our proposed operator converts to an extended-BM () operator.
Next, we present an example to illustrate the computational procedure of the proposed operator.
Example 1 (adopted from [
38])
. Suppose the dean of a high school wants to evaluate four students, A, B, C and D, based on three subjects: mathematics (Math), physics (Phys) and literature (Lit). The scores are given on a scale, as shown in Table 1. Usually, it is common to see that students who are good at mathematics are also good at physics, but the performance in literature does not depend on the performance in mathematics or physics. Considering the relationship among the subjects, we can partition the criterion set into: , independent criteria: .Let us fix , , , , , , for all and . For simplicity, assume , and here, .
Based on the provided background, the resulting is as follows: The of the scores of student A is: Similarly, we can calculate the of the scores for students B, C and D. The result is summarized in the following Table 1. Thus, by applying the operator, we obtain the final rank order of the students as . Next, we compute the overall scores of the four students using the Choquet integral [39]. Since students who are good at mathematics are in general good at physics, the dean does not want to overvalue students having good marks in both subjects. Let , and . The defined sub-additive capacities satisfy the dean’s preference when evaluating the four students (details can be found in [38]). Considering the capacity defined above, the Choquet integral of the scores of student A is: Similarly, we can calculate the Choquet integral of the scores for students B, C and D (results are summarized in Table 1). The final ranking order of the students is . Clearly, the aggregated value obtained by the Choquet integral differs from that found by the operator. By implementing the Choquet integral, we cannot distinguish between student C and D; however, the proposed operator is capable of doing so. In addition, in order to evaluate overall scores utilizing , the degrees of importance of the different interacting criteria subsets are not required.
However, the multi-dimensional aspect of the criterion set has not been addressed in the above example. We will address this issue extensively in Section 6. 4. Weight Determination for the Multi-Dimensional Extended-PBM Operator
Sometimes all the evaluation criteria are not equally important. Thus, to take into account the variability among them, we need to consider the weight vectors associated with the criterion set. In this section, we try to determine the condition of weight vectors satisfied by the weighting triangle associated with the weighted extended operators. That is, under which condition are the weighted operators regular extended aggregation operators? Or under which condition of weight vectors are extended operators monotonic with respect to -order and -order?
By assigning weight vectors, one can rewrite the definition of the extended-PBM operator as follows.
Definition 10 ([
31])
. An extended aggregation operator is called an weighted extended-PBM if where and there are , , such that for each the restriction is a operator related to partition of and defined aswhere for each , there exists a with , so that for any and any element in , , there are elements in with so that and . If all the criteria belong to the same class (i.e., ), then the operator in Definition 10 transforms to the weighted extended-BM () operator. The above-defined weighted extended-PBM operator on is idempotent, bounded and monotonic with respect to . However, it need not be regular, i.e., monotonic with respect to -order and -order.
In [
18], Calvo et al. established the condition for weight vectors to be satisfied by the weighting triangle
so that the extended aggregation operators (namely, EOWA and EQLWM) are monotonic with respect to
-order and
-order. With a view of their results and Definition 4, we may say an EOWA operator is a regular extended aggregation operator if and only if the weighting triangle
associated with EOWA satisfies
where
, and an EQLWM operator is a regular extended aggregation operator if and only if the weighting triangle
associated with EQLWM satisfies
.
Now, to find the weighting condition associated with the composite n-ary operator where the criterion set follows the partitioned structure interrelationship pattern, we first try to determine the condition for the n-ary operator, following a homogeneous relationship.
Theorem 1. A weighted, extended Bonferroni mean () operator is a regular extended aggregation operator if and only if for all and , the inequalityholds. Next, we define the condition of the weighting triangle for the operator.
Theorem 2. A weighted extended-PBM operator is a regular extended aggregation operator if and only if for all partitions with , the above inequality satisfying the homogeneous relationship holds.
Proof. The proof is similar to the proof of Theorem 1. □
In the literature [
18], there exist different ways to determine these weighting triangles. Next, we recall several methods that are capable of generating weighting triangles.
Generation of triangles by means of a quantifier:
Yager [
40,
41] first proposed the basics of all kinds of relative quantifier
Q, named the regular increasing monotone (RIM) quantifier, where
Q is a monotone non-decreasing operator
satisfying
and
. The weights generated by increasing quantifier
Q can be defined by
where
and
.
Generation of triangles by means of a negation operator:
One can obtain the weights of a weighting triangle through a negation
, i.e., a monotone non-increasing operator satisfying
and
, as follows:
where
and
.
There exists a duality relation between an increasing quantifier and a negation, i.e., . Thus, the weights generated by Q are just reversed to those generated by its dual N.
Generation of triangles by means of sequence:
Consider a sequence of non-negative real numbers
such that
and
for
. Then, one can define a weighting triangle in the following way:
where
and
. The weighting triangle related to the sequence is known as the Sierpinski carpet.
With these, all generated weighting triangles, one can easily determine which weight vector satisfies the conditions of Theorems 1 and 2.
Example 2. For example, consider the "normalized" triangle of Pascalwhich satisfies the above condition, where and …, for each , and let A be the operator defined by this triangle. Then, by Theorem 2, we can easily show that the above-defined operator is a regular extended aggregation operator. 5. Handling the Hierarchy of Criteria with a Multidimensional Extended-PBM Operator
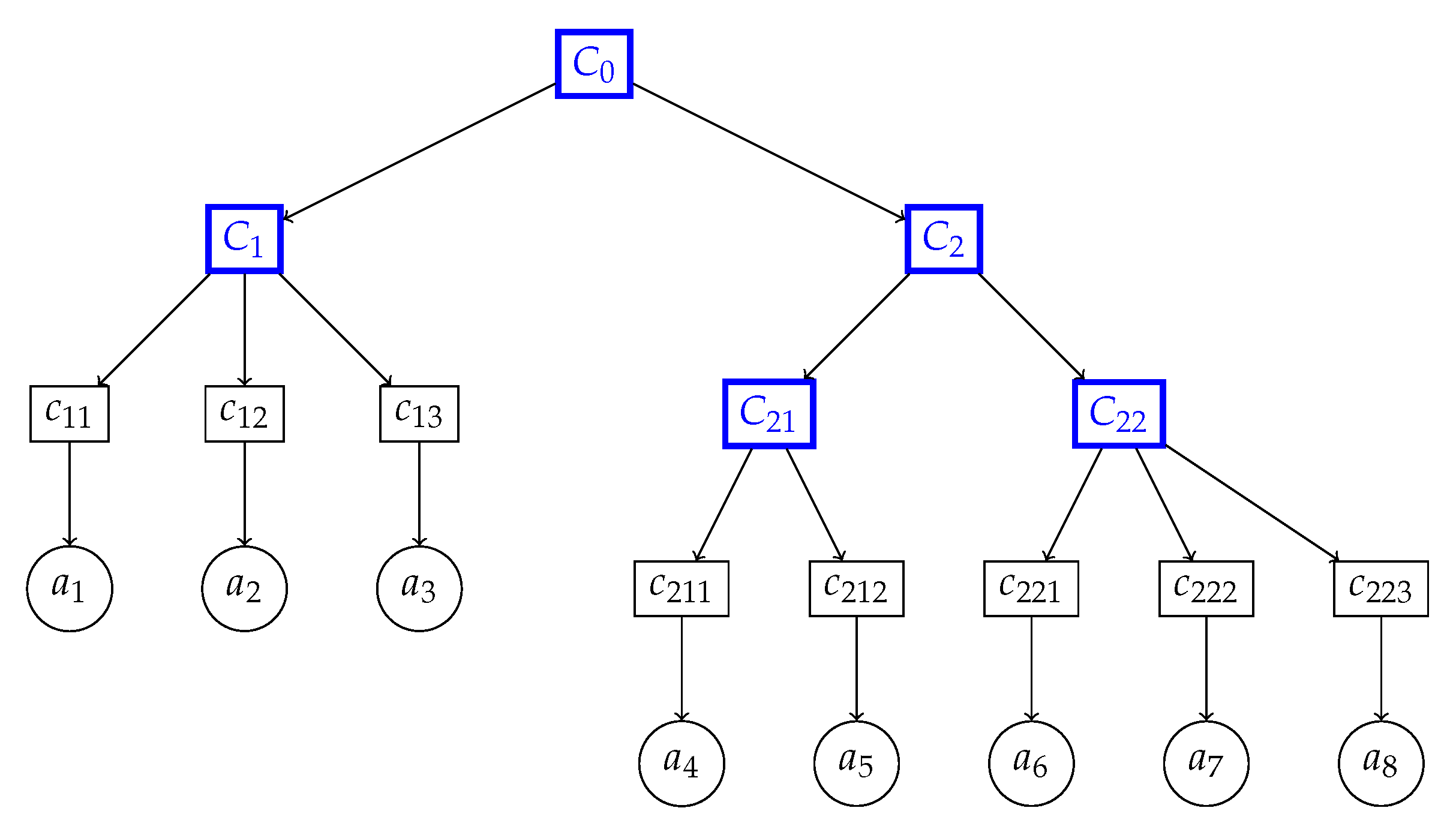
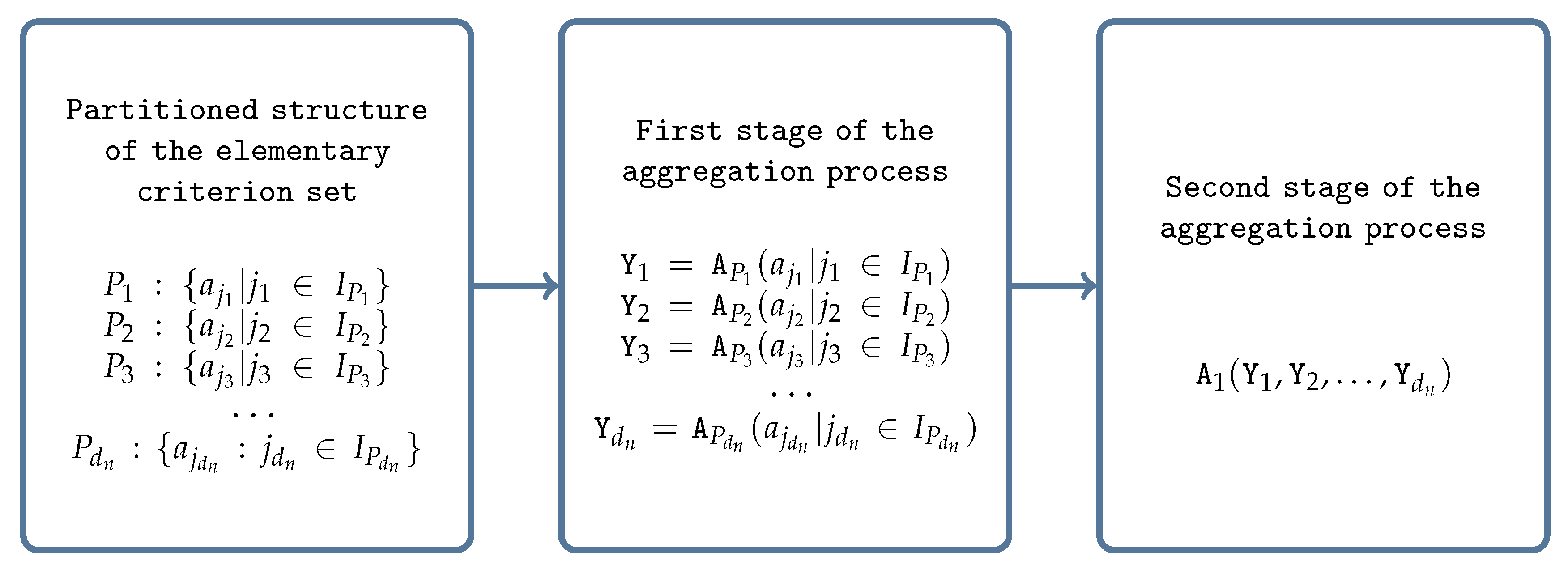
Hierarchical decomposition basically assists decision makers by providing a ranking of alternatives, not only considering the whole set of criteria, but also with respect to any intermediate higher-level point of view. The results at each level of the hierarchy can be considered a very useful tool in any decision-making process. In a hierarchical system, the output of each level is dependent on another in a sequential manner. Such a hierarchy structure of criteria starts with the root criterion at zero levels, which is referred to as a comprehensive objective, then a set of sub-criteria of the root criterion at level one and so on. The criteria at the lowest level of the hierarchy are termed elementary criteria. Here, we assume that the elementary criterion set follows a partition structure interrelationship pattern where each class of the partition comprises the elementary sub-criteria belonging to the same criteria of the immediately upper level. The framework of a hierarchical structure of criterion set is shown in
Figure 1.
indicates the main goal or root criterion.
is the set of all criteria comprising the elementary sub-criterion set and non-elementary criterion set, denoted by square boxes in
Figure 1, and
is the set of indices of all criteria belong to
representing a position of the criteria located at any level of the hierarchy.
is the set of all elementary sub-criteria located at the bottom of hierarchy, where is the index set of all elementary sub-criteria and .
The evaluation value/preference value for any alternative
X based on the elementary criteria in the hierarchical structure is denoted by circles in
Figure 1.
Then, the overall aggregated value for an alternative
X based on a set of non-elementary criteria can be defined as
where
denotes the aggregation operator for
and
is defined as:
This formulation can be viewed as an evaluation of the hierarchical structure of the criterion set using a composite
n-ary aggregation operator
. The flowchart of the proposed aggregation mechanism is illustrated in
Figure 2. If we replace the aggregation operator
with
, and aggregation operators
,
(
) and
with arithmetic mean, then
will be reduced to a PBM operator for a fixed number of inputs
n.
Further, if we want to estimate a partial result based on some criteria located at any intermediate level of the hierarchical structure, then we can utilize to aggregate only that preference information descending from that particular criterion or the set of criteria, and for rest, we follow the convention that the aggregation of no information is zero. Thus, the main advantage of the proposed operator is that it can model the hierarchical structure appropriately in the sense of not only evaluating the ultimate goal but also producing partial results by characterizing the situations with any possible partition. Hence, composite operator can be executed as a different dimensional aggregation operator based on the set of criteria by which the decision maker wants to evaluate the result. Additionally, can be considered as a general aggregation approach where inputs of various sizes can be compared.
Example 3. If we consider the hierarchical structure presented in Figure 1, we get the overall evaluation as: Thus, the proposed aggregation operator is more able to handle situations with any possible number of input arguments. Thus, it is more flexible in the sense that it can obtain results in a partial way, i.e., for a sub-criterion or a set of criteria at some intermediate level of the hierarchy.
In a complex decision-making problem, there may be a case where all the partitions are not equally important. In this context, depending on the aggregated value of each partition of the elementary criterion set, the decision maker can assign the weights. When we are aggregating for alternative
X against all root criteria
,
, suppose that
is the permutation of
such that
and
is the weight assigned to the
r-th largest element
in the tuple (
). Using this concept, we can get the aggregated value for alternative
X as
We note that, for input argument values in
, we have
. It is a standard aggregation operator, where for all
, we get
, and for all
, we get
. The monotonicity of the aggregation operator is straightforward. Now, for the case when
and
, we get back to Equation (
1). To aggregate the value through the OWA operator, we need the weight vector. Several methods have been proposed in the literature to determine the weight vector of the OWA operator [
42].
To understand the computational aspect of the proposed aggregation operator, we summarize the decision-making algorithm in a stepwise fashion as follows:
- Step 1:
Construct the hierarchical structure of the criterion set and identify the set of all elementary criteria located at the bottom of the hierarchy, and all non-elementary criteria up to the root criterion .
- Step 2:
Collect the decision maker’s assessments of the alternative X against the elementary criterion set and represent them by .
- Step 3:
Identify the partition structure interrelationship pattern among the criterion set based on the assumption that elementary sub-criteria belonging to the same criteria of the immediately upper level will form a partition.
- Step 4:
Assign the weight information of the criterion set by employing the concept of the weighting triangle defined in
Section 4.
- Step 5:
Utilize the proposed operator or the operator to find the overall performance of alternative X with respect to the whole set of elementary criteria or partial performance for any subset of elementary sub-criteria.
- Step 6:
Finally, compare the performances of alternative X based on different sub-criteria to find out which criteria need more attention to improve overall performance.
Now, to apply the newly proposed aggregation operators developed in the previous sections, in the following we present a real-life based application of assigning indexes to the quality of a child’s home environment.
6. An Illustrative Application
Applied behavior analysis (ABA) is a part of psychology that deals with behaviorism, but its major contribution is measuring behaviors that need to be modified by clearly observing them. Research suggests that ABA has been understood to be helpful in social, functional and educational contexts across all ages. Research with parents in the years 2009, 2010, 2011 and 2014 showed positive outcomes with this approach. Therefore, this approach was used in this work to see if it is effective even during the times of e-learning and e-adaptation. With the above view, we used the proposed hierarchical aggregation method in studying preteens’ (9–12 years) home environment index, since in this period it is possible to produce a major impact on the subsequent development of the personality. The quality of the home environment, educational style and parenting practices each play a significant role in influencing the child’s social, adaptive, coping and emotional skills during this development age. Additionally, this motivated us to analyze the home environment quality indexes. The development of indexes based on usual statistical techniques does not ensure an adequate representation, as in the case of a child’s home environment, the criterion set is hierarchically related, there being an interrelationship among them. Rojas et al. [
43] developed an approach to measuring the quality of the home environment of children who were between 15 and 30 months. In that particular article, the authors assumed that information possesses a prioritized hierarchical structure. However, in a hierarchical system, dependence among the criteria is a significant aspect that needs to be focused on. Additionally, till now, no conceptual model has been created to invent an exact plan for evaluation of the quality of the home environment by relating the selected indicators for this particular age group. Thus, in this section, we analyze the preteens’ home environment traits for a better understanding of this core component in child rearing, employing our newly proposed hierarchical extended-PBM operator, where the criterion set follows the partition structure interrelationship pattern.
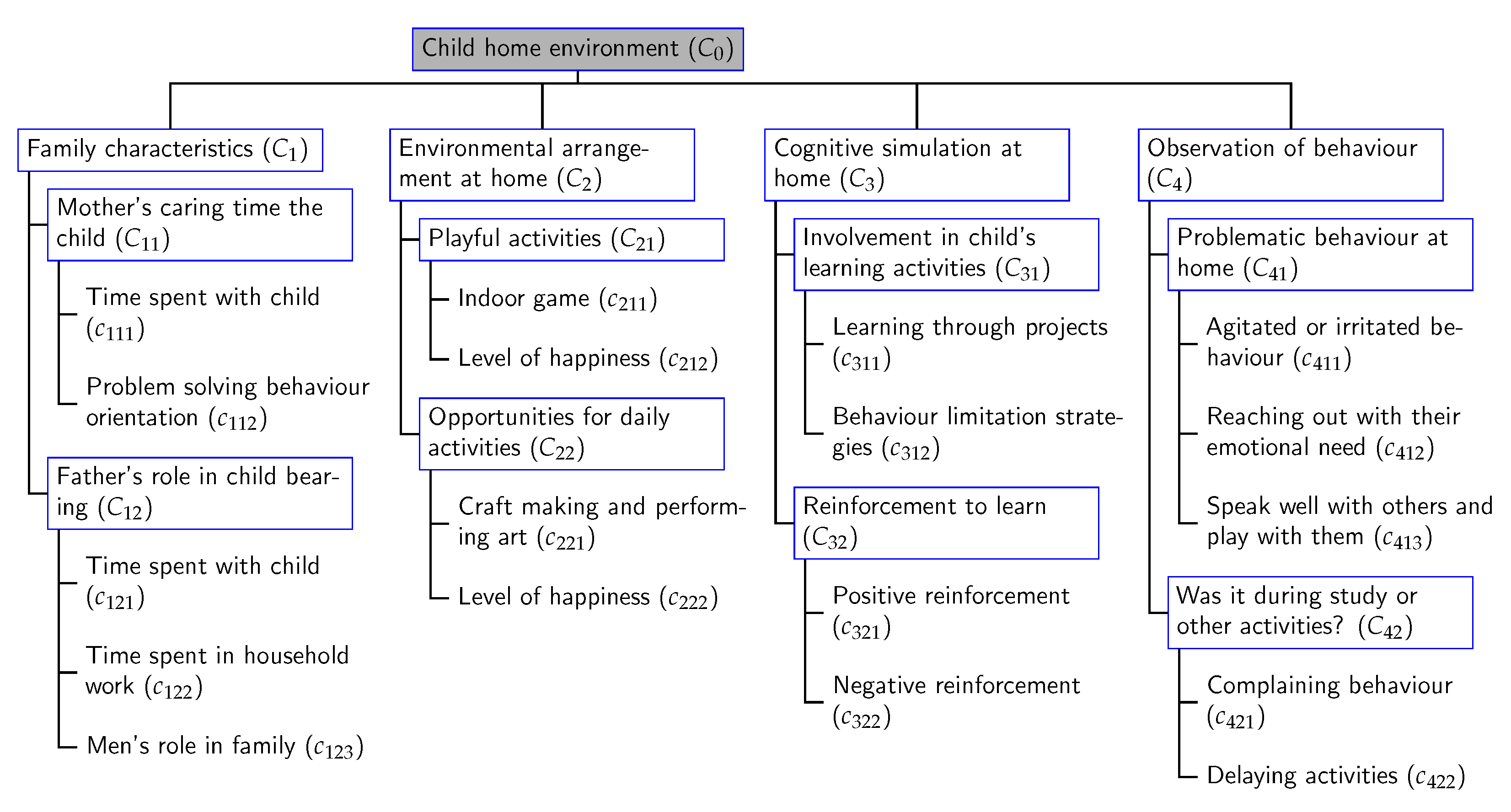
With the aid of an expert’s opinion, a 3-layer hierarchical structure of the criterion set associated with a child’s home environment and behavioral properties was constructed as shown in
Figure 3. Here, the entire criterion set is organized into four broad categorie—
: family characteristics,
: environmental arrangement at home,
: cognitive simulation at home,
: observation of behavior—which are further grouped into a number of sub-categories. This hierarchical decomposition basically assisted the decision makers to evaluate the respective home environment index of each participant by not only considering the whole set of criteria but also any intermediate point of view so that experts could analyze the child’s home environment with respect to the individual aspects as well to improve the overall impact.
Based on the structured hierarchical criterion set, a questionnaire was created, and subsequently, a set of data was collected via an online survey through the questionnaire given to the parents of children in the age group of 9–12 years, who agreed to participate in the study. The area of the survey was selected randomly with some degree of proportional allocation to obtain the desired correlation and comparative study of the impacts of environmental factors on behavioral patterns. In order to obtain the parents’ opinion on criteria related to the child’s home environment, a proper linguistic evaluation scale needed to be predefined. Then, to estimate a child’s home environment index utilizing our proposed hierarchical aggregation operator, we needed to transform the linguistic scale into a fuzzy scale [
43]. Considering the expert’s opinion, for each linguistic assessment, a fuzzy set can be built (see
Table 2), keeping in view the fact that the fuzzy values associated with each linguistic variable are ordered from the optimal case to the worst case for the child development. Finally, by aggregating parents’ responses using our proposed aggregation operator, one can obtain an index or set of sub-indexes for each child which will portray the quality of his or her home environment.
We present an example to illustrate the computational procedure of the index assigned to a specific child utilizing the proposed operator.
Example 4. In accordance with the hierarchical structure of the criterion set (Figure 3) associated with the child’s home environment, suppose for a specific child, by transforming the linguistic response gathered from the parent into fuzzy set, we obtain the input assessment as = (1, 0.8, 0.6, 0.4, 0.6, 1, 0.8, 1, 1, 1, 0.8, 0.6, 0.6, 0, 1, 1, 1, 1). As mentioned earlier, we have hypothesized that the elementary criterion set of the hierarchical structure follows a partition structure interrelationship pattern, where each class of the partition comprises elementary sub-criteria belonging to the same criteria of the immediately higher level. Based on (Figure 3), the criterion set is partitioned into 8 classes: , , , , , , , and . It has been assumed that every criterion contributes to the final result equally. Now, to aggregate the set of values in at the comprehensive level, we must use our proposed hierarchical- operator as:
To capture the dependency pattern of each partition set, we have used , , and finally, the arithmetic mean to obtain the final aggregated value. The primary difference between this proposed aggregation process and the classical one is that in this case the criterion set is assumed to possess a partition structure interrelationship pattern with varying dimensions.
The main advantage of utilizing the proposed operator, besides evaluating the index at a comprehensive level, we can analyze the child’s home environment with respect to the individual aspects of the main criteria or any particular sub-criteria as well. The above computation indicates that an aggregated value with respect to the sub-criterion is comparatively on the lower end. Hence, in order to improve a child’s overall home environment, the criterion “Father”s role in child bearing” needs to be focused on.
In the above example, it has been assumed that every criterion contributes to the final result equally. Thus, the weighting triangle associated with the aggregation operator is generated by the quantifier
, where the corresponding weights are
,
. It can be presented as
Now, depending on the weighting triangle, the evaluations of the index at the comprehensive level or sub-indices at any intermediate level will differ. Instead of a weighting triangle generated by the quantifier , if we implement a normalized Pascal weighting triangle, as provided in Example 2, to assign weights of the criterion set, then the overall evaluation of the quality of the home environment for the particular child will be . Accordingly, the index value with respect to the main criterion set will be .
Thus, depending on different weighting triangles associated with the operator, index evaluation will change.
6.1. Comparison with Other Mean Based Operators
Now, we compare our proposed method with some well-known aggregation operators, including BM, in the context of the home environment computation considered in Example 4. The aggregation results are shown in
Table 3.
From
Table 3, we can see that if we simply calculate the average of all responses (1, 0.8, 0.6, 0.4, 0.6, 1, 0.8, 1, 1, 1, 0.8, 0.6, 0.6, 0, 1, 1, 1, 1) using the extended arithmetic mean operator, then the particular interrelationship pattern among the set criteria is neglected. Even if we employ an extended-BM operator to aggregate the responses, it considers only a homogeneous relationship among the whole criterion set and is not able to capture the exact relationship of the criteria in the hierarchical system. On the other hand, if we employ an extended geometric mean operator, then since the response against one criterion is zero, it turns into the overall index evaluation based on the whole criterion set for the child as zero, which is an undesirable outcome. Additionally, it is not able to differentiate between the results of the comprehensive level with the results obtained for the criteria
, since both have acquired a zero index value. Thus, the hierarchical
operator has a certain advantage by modeling the partition structure interrelationship pattern among the criterion set more adequately than other mean-based aggregation operators.
Table 4 shows a comparison of the characteristics of the proposed aggregation operator with those of other extended aggregation operators.
6.2. Effects of the Parameters p and q
Here we try to analyze the influences of the parameters
p and
q on the overall evaluation of the home environment index. For different values of
p and
q, the obtained evaluations for the input
= (1, 0.8, 0.6, 0.4, 0.6, 1, 0.8, 1, 1, 1, 0.8, 0.6, 0.6, 0, 1, 1, 1, 1) (Example 4) are summarized in
Table 5.
With reference to
Table 5, we can state that the assigned index values, calculated from the input
, based on the entire criterion set or any intermediate level perspective, are insignificantly different from different variants of
p and
q. However, from the table, we can see, for all variation of
p and
q, the aggregated results obtained for criteria
are the meanest. Thus, those particular criteria need more attention to improve the overall evaluation. Most commonly, we use
for the simplicity of the calculation.
7. Conclusions
In this contribution, we have presented a composite aggregation operator called the generalized multi-dimensional extended partitioned Bonferroni mean (). In multi-dimensional aggregation, the proposed operator can help decision makers to acknowledge the significance of each criterion in the aggregation process. Further, we have established the condition of weight vectors satisfied by the weighting triangle associated with the operator. We have implemented this new concept to handle the hierarchical structure of a criterion set for evaluation of a child’s home environment, where the decision maker can evaluate the child’s home environment quality not only based on the whole set of criteria but also for any intermediate higher-level point of view. In the future, the operator can be further explored by taking specific prerequisites within each partition set.
We can summarize the main contributions of this study as follows:
We have proposed the operator, which can capture the partition structure interrelationship pattern within the data of various dimensions and can model specific relationships within each partition set in multi-dimensional data aggregation.
We have established the weighting condition associated with the proposed multi-dimensional aggregation operator.
We have extended the concept of the proposed operator for accommodating the hierarchical structure of the criterion set.
Proposed operators can be used to deal with multi-criteria group decision-making problems [
44] or two-sided matching decision-making problems [
45]. In the future, we will also try to model outer dependency relationship [
46] among the criteria of different layers of a hierarchical system. To do so, we could make an attempt to adapt the concept of a heterogeneous relationship [
47] to a hierarchical system of criterion set. We could study more interesting properties of the proposed operator when combined with other operators like the Choquet integral. In addition, we could extend our proposed operator to imprecise membership grades to handle real-life decision-making problems.







{kind=link}
{kind=link}
{kind=link}