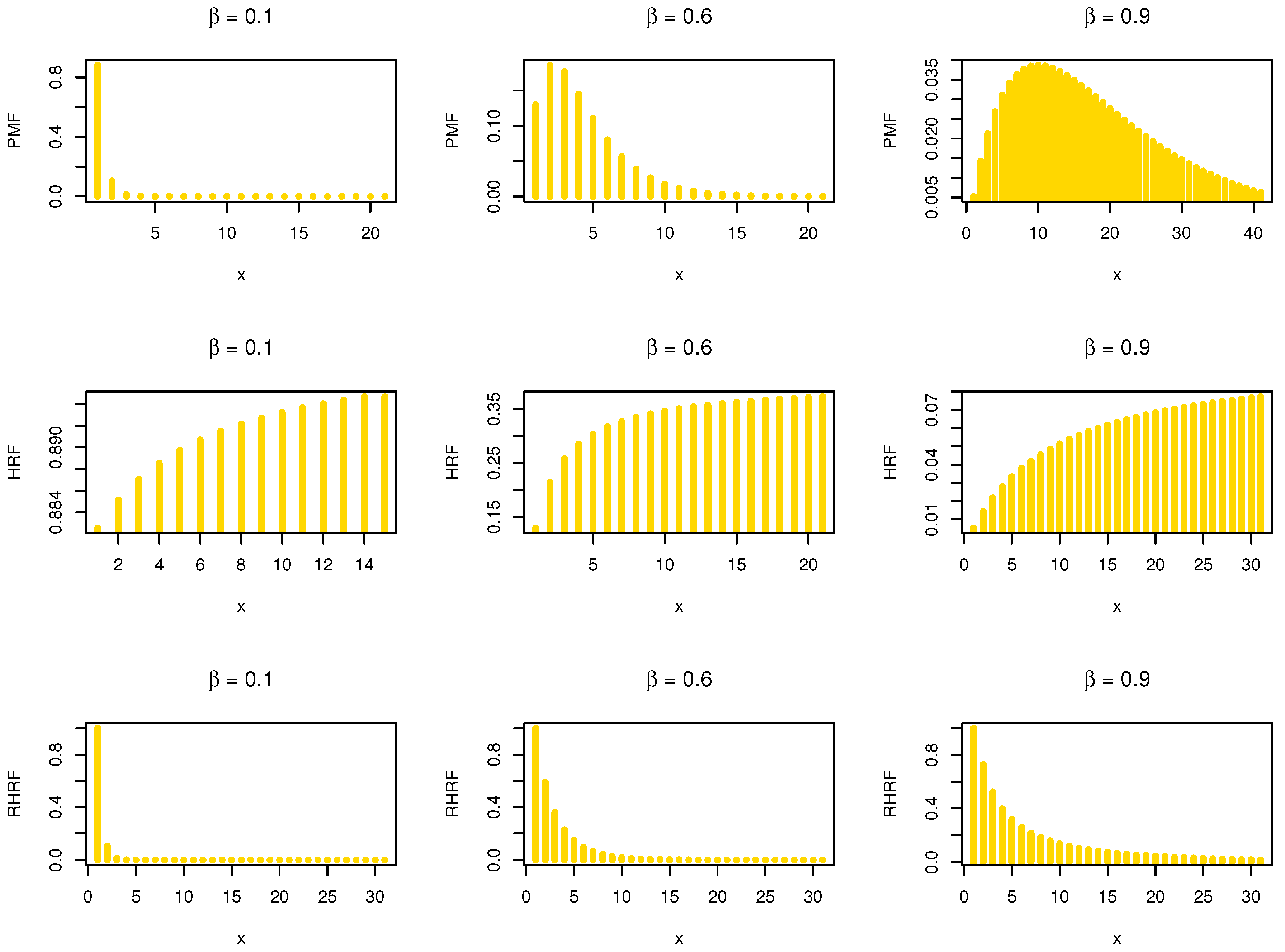
Figure 1.
The PMF, HRF and RHRF plots of the NDsLE model.
Figure 1.
The PMF, HRF and RHRF plots of the NDsLE model.
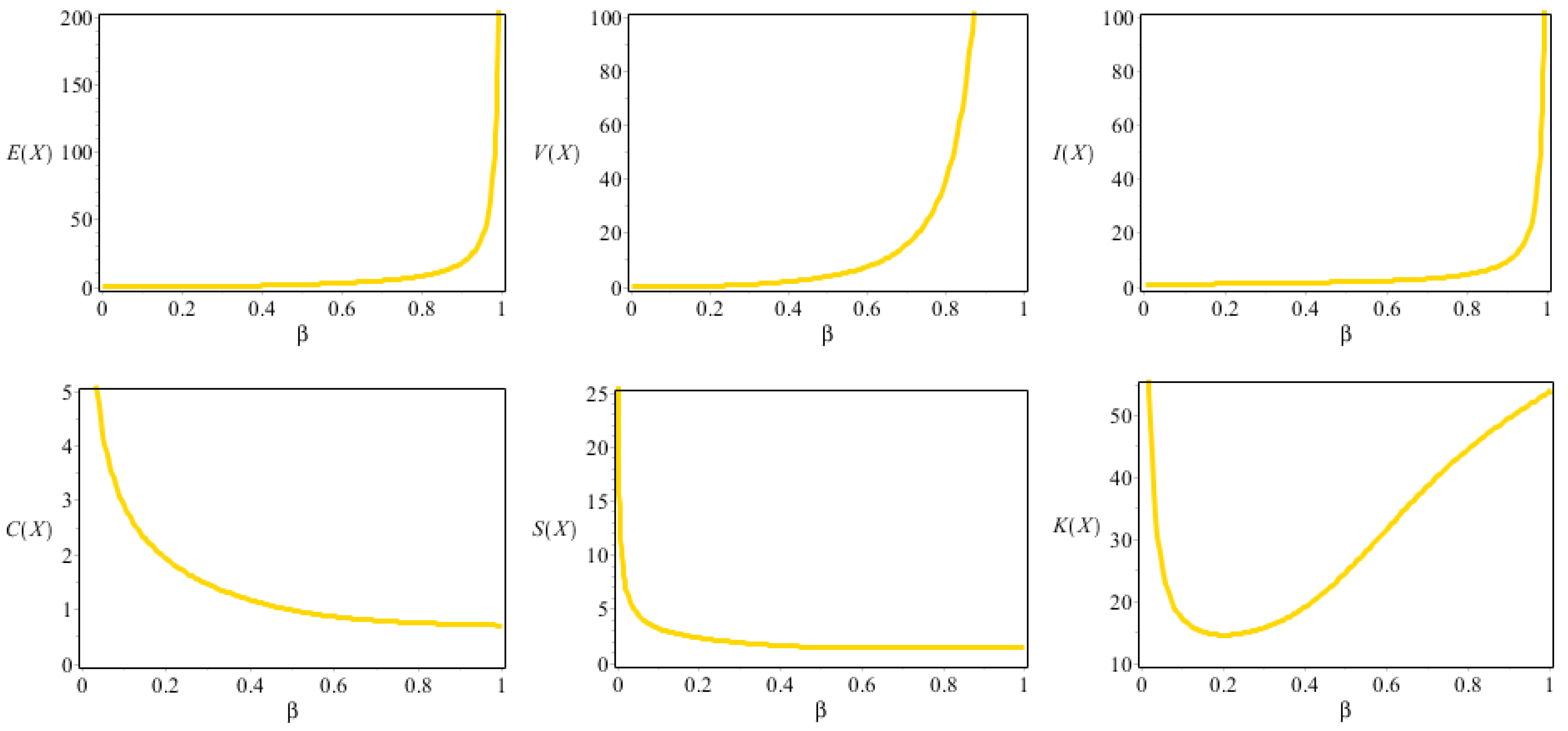
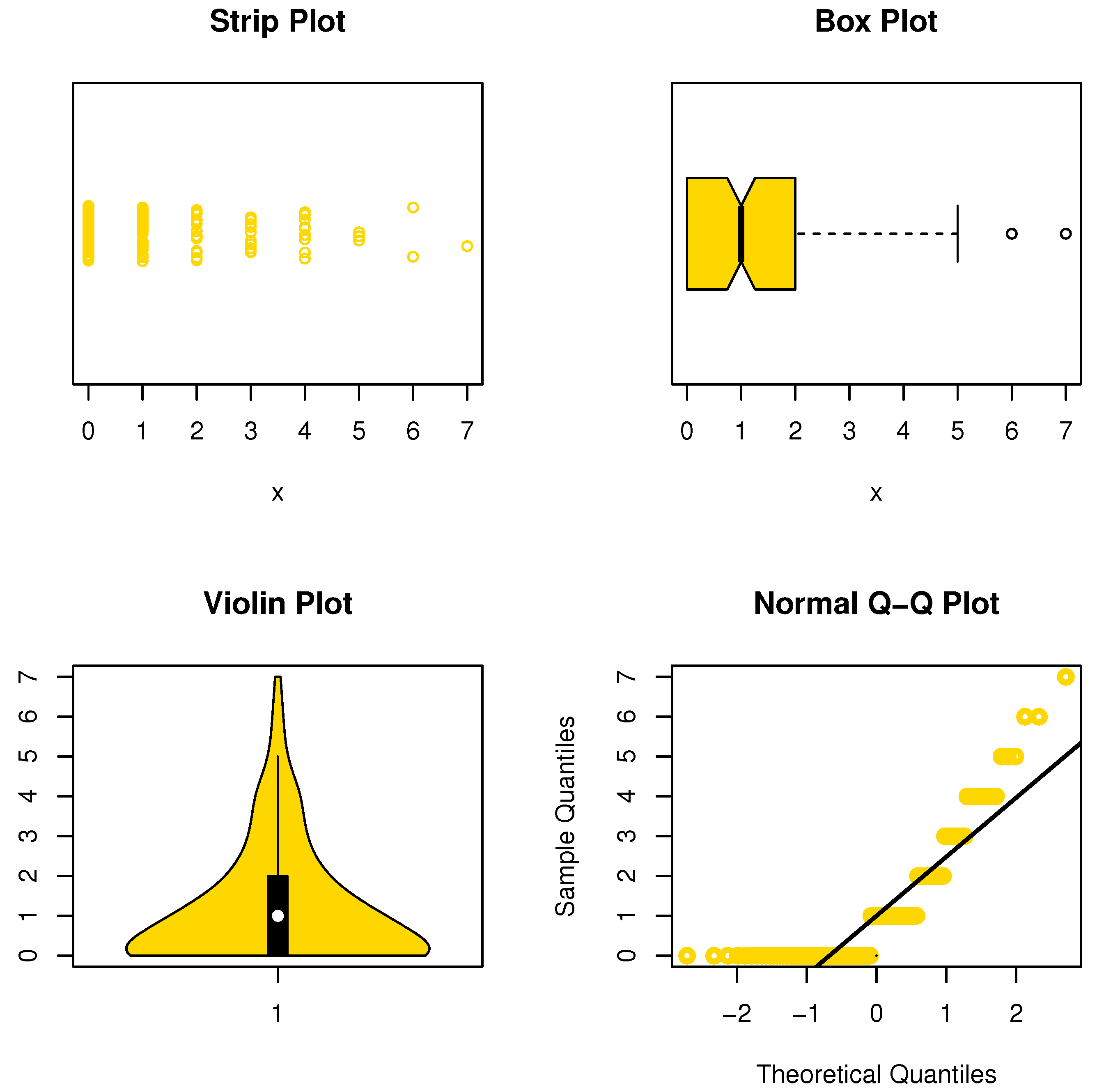
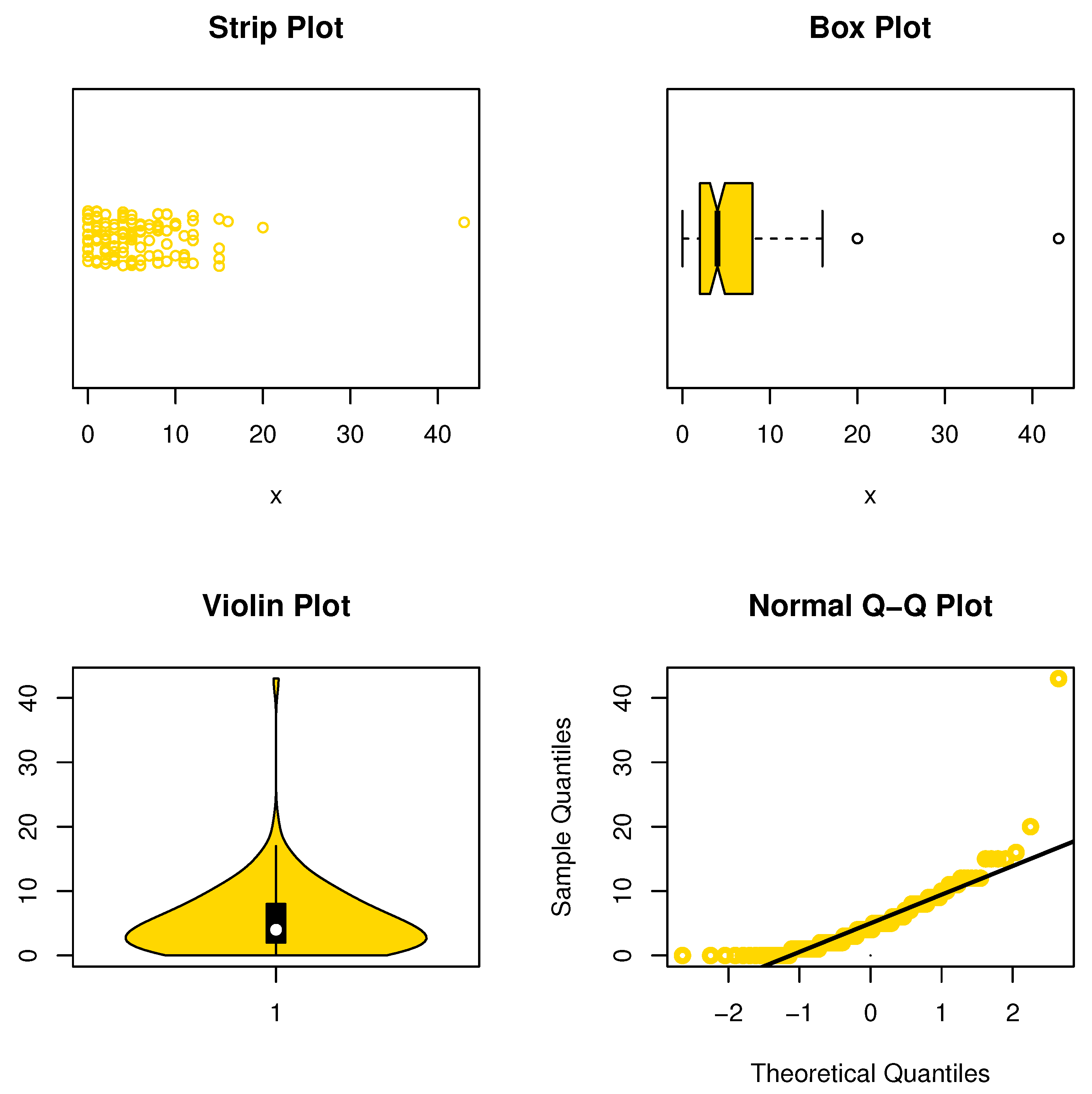
Figure 2.
Some DS plots for the NDsLE model.
Figure 2.
Some DS plots for the NDsLE model.
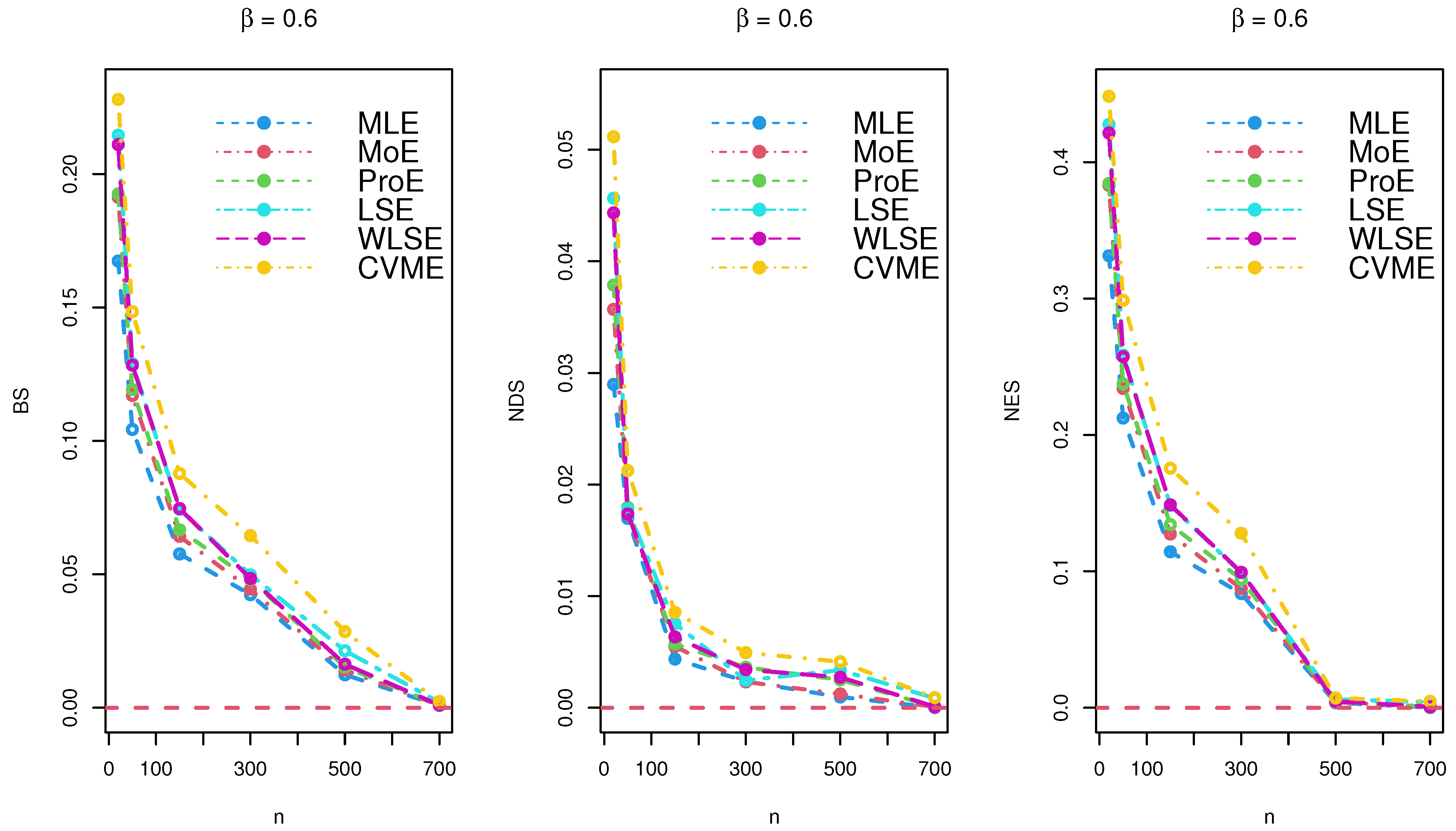
Figure 3.
Simulation results for under various estimation techniques.
Figure 3.
Simulation results for under various estimation techniques.
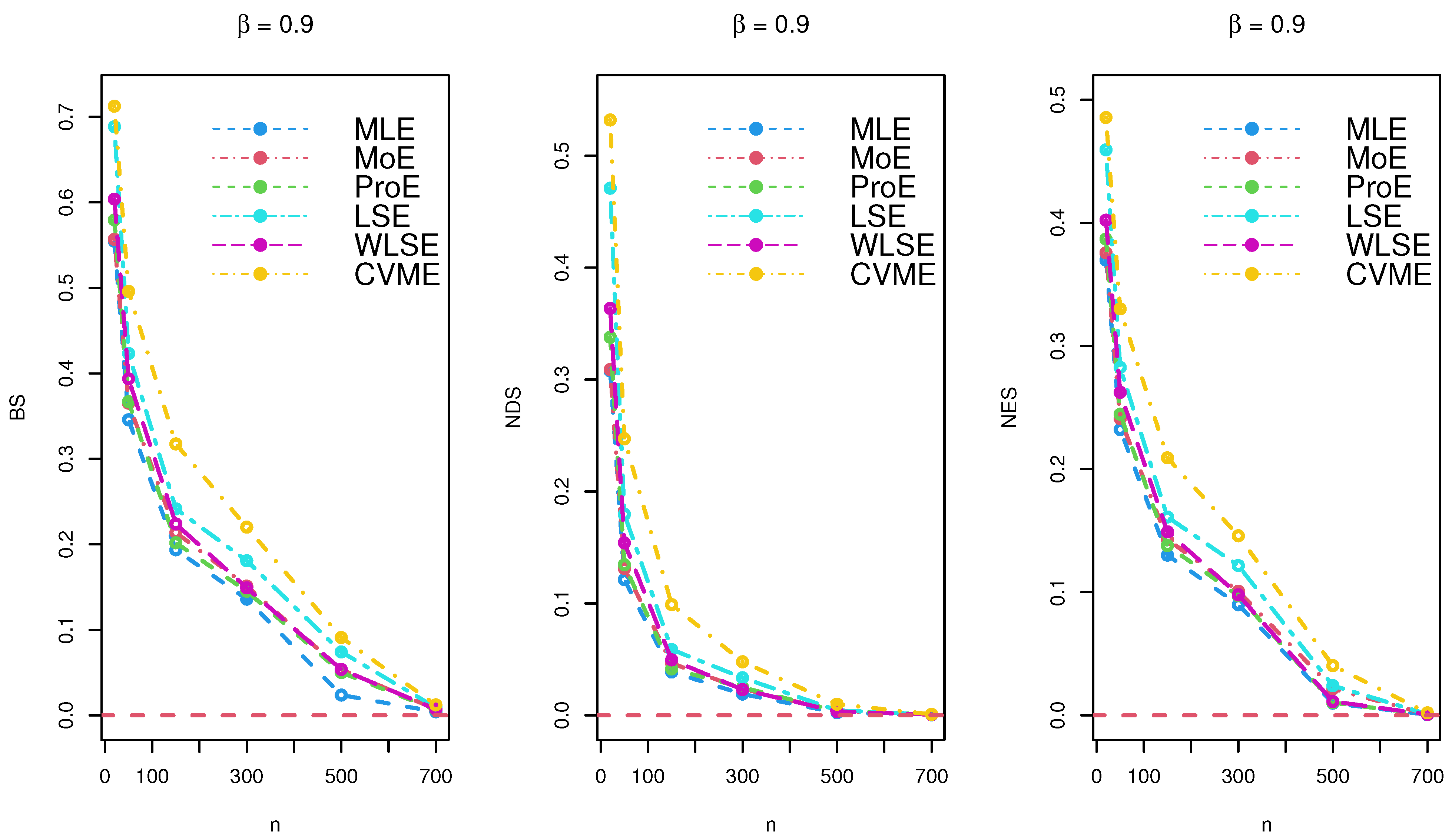
Figure 4.
Simulation results for under various estimation techniques.
Figure 4.
Simulation results for under various estimation techniques.
Figure 5.
Simulation results for under various estimation techniques.
Figure 5.
Simulation results for under various estimation techniques.
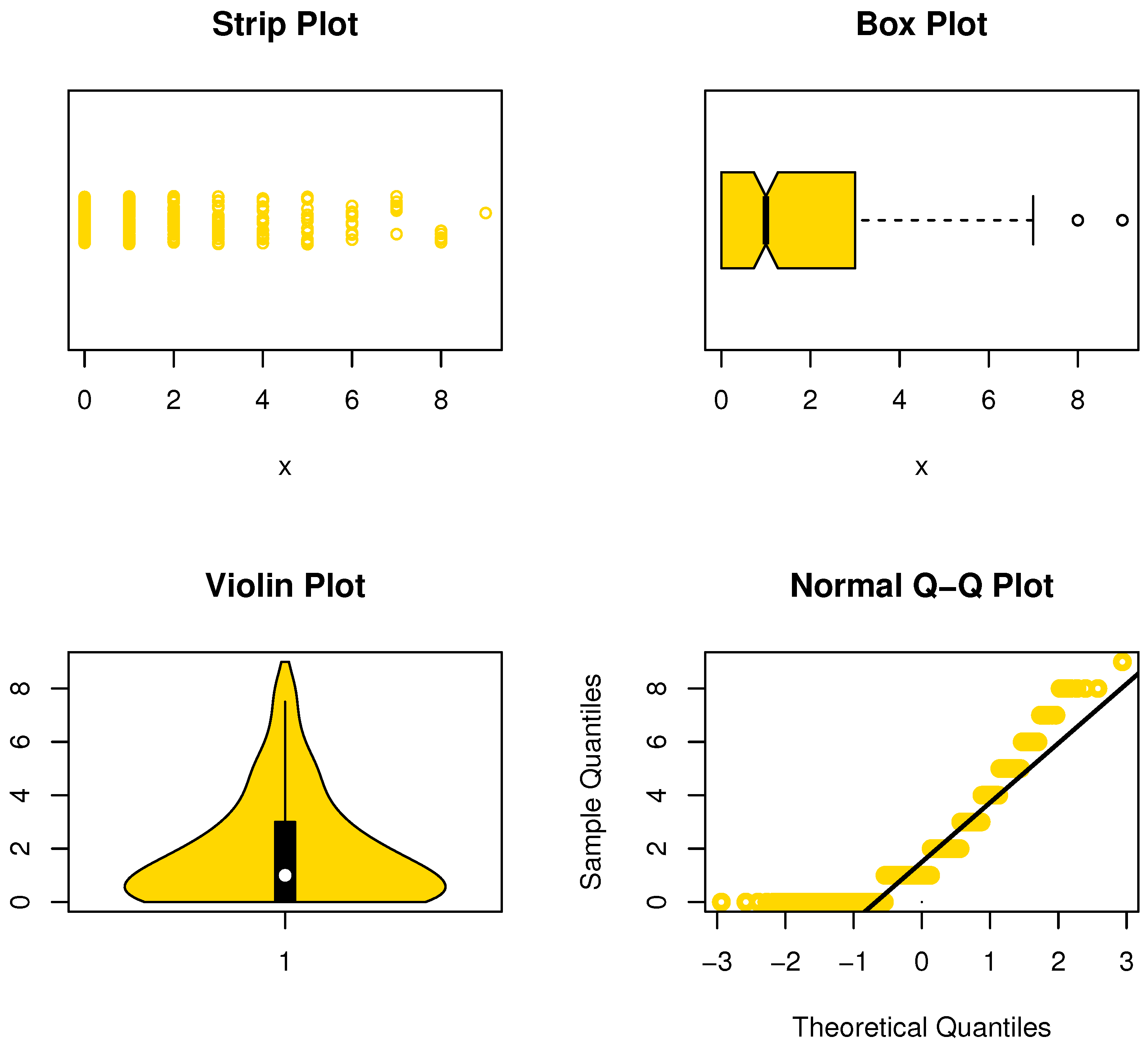
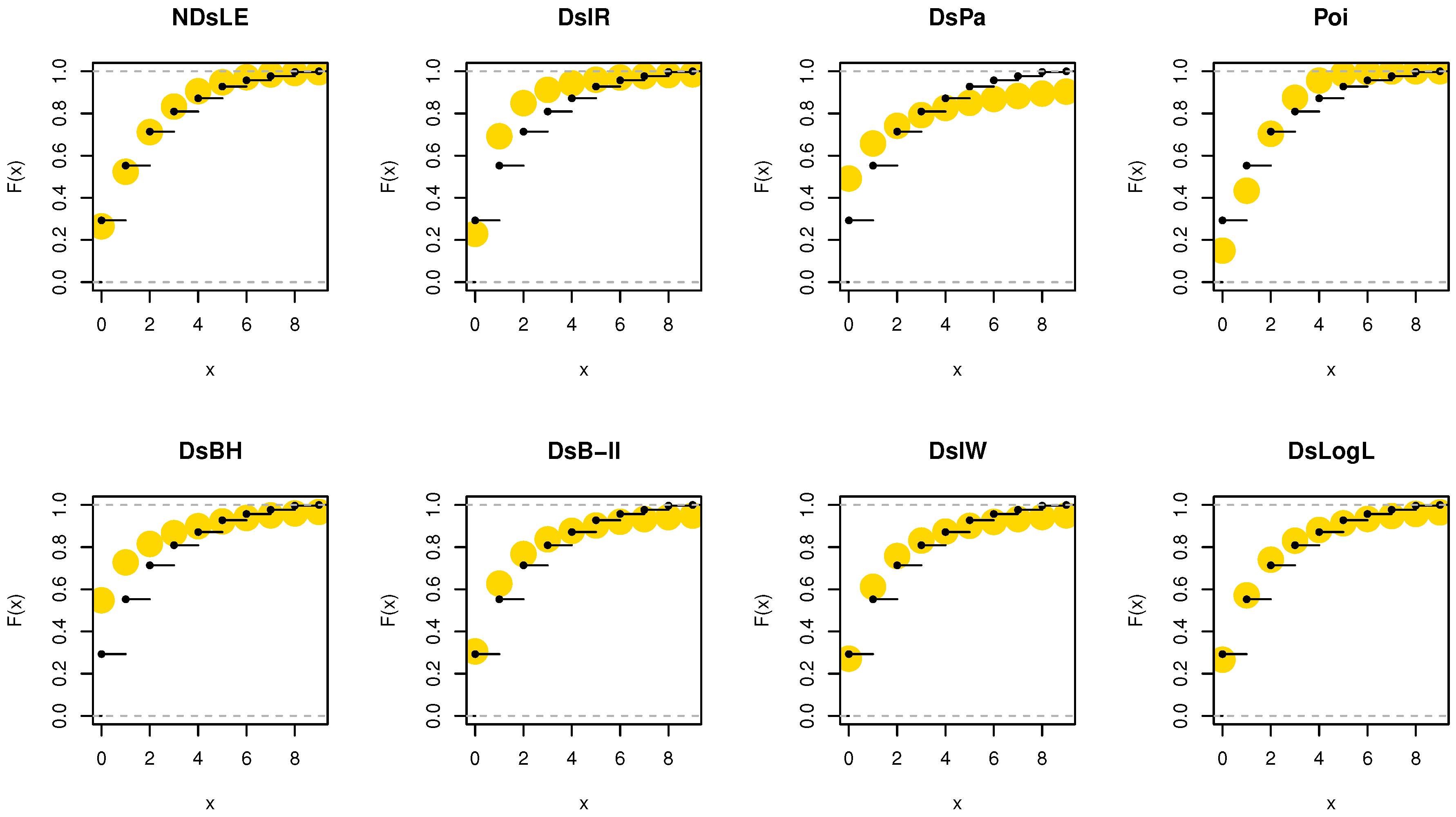
Figure 6.
Nonparametric plots for data set I.
Figure 6.
Nonparametric plots for data set I.
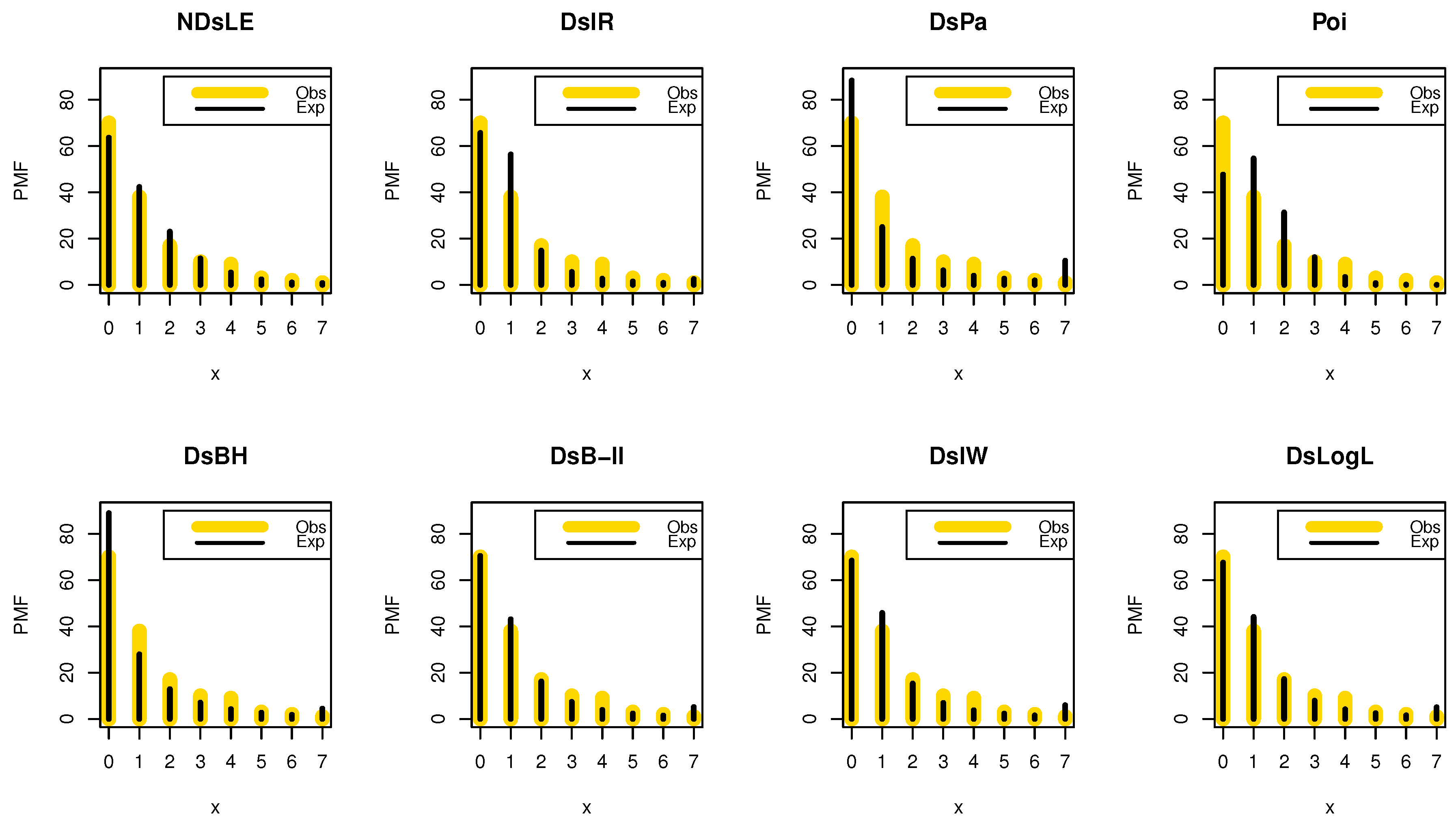
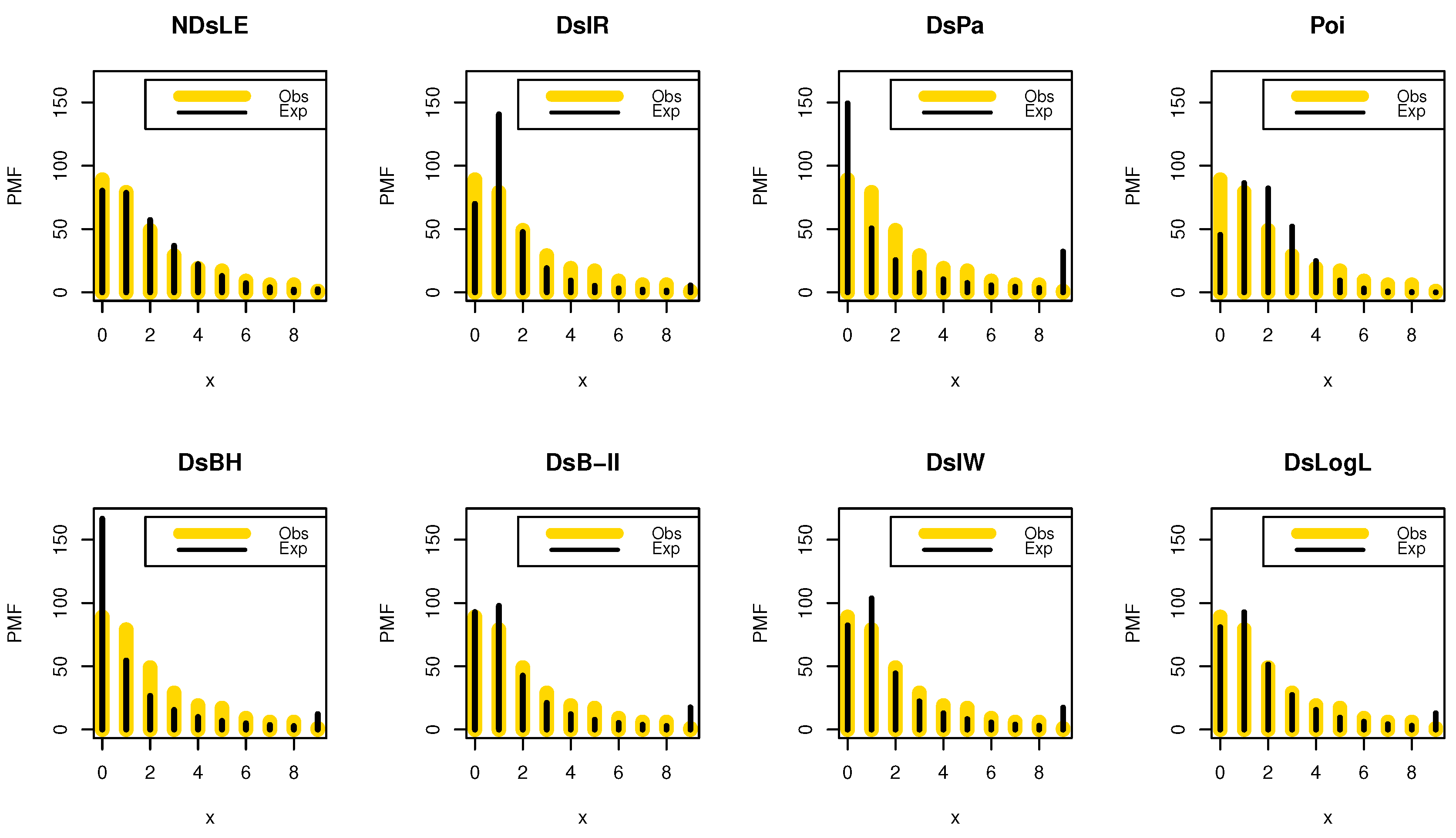
Figure 7.
The empirical PMFs plots for data set I.
Figure 7.
The empirical PMFs plots for data set I.
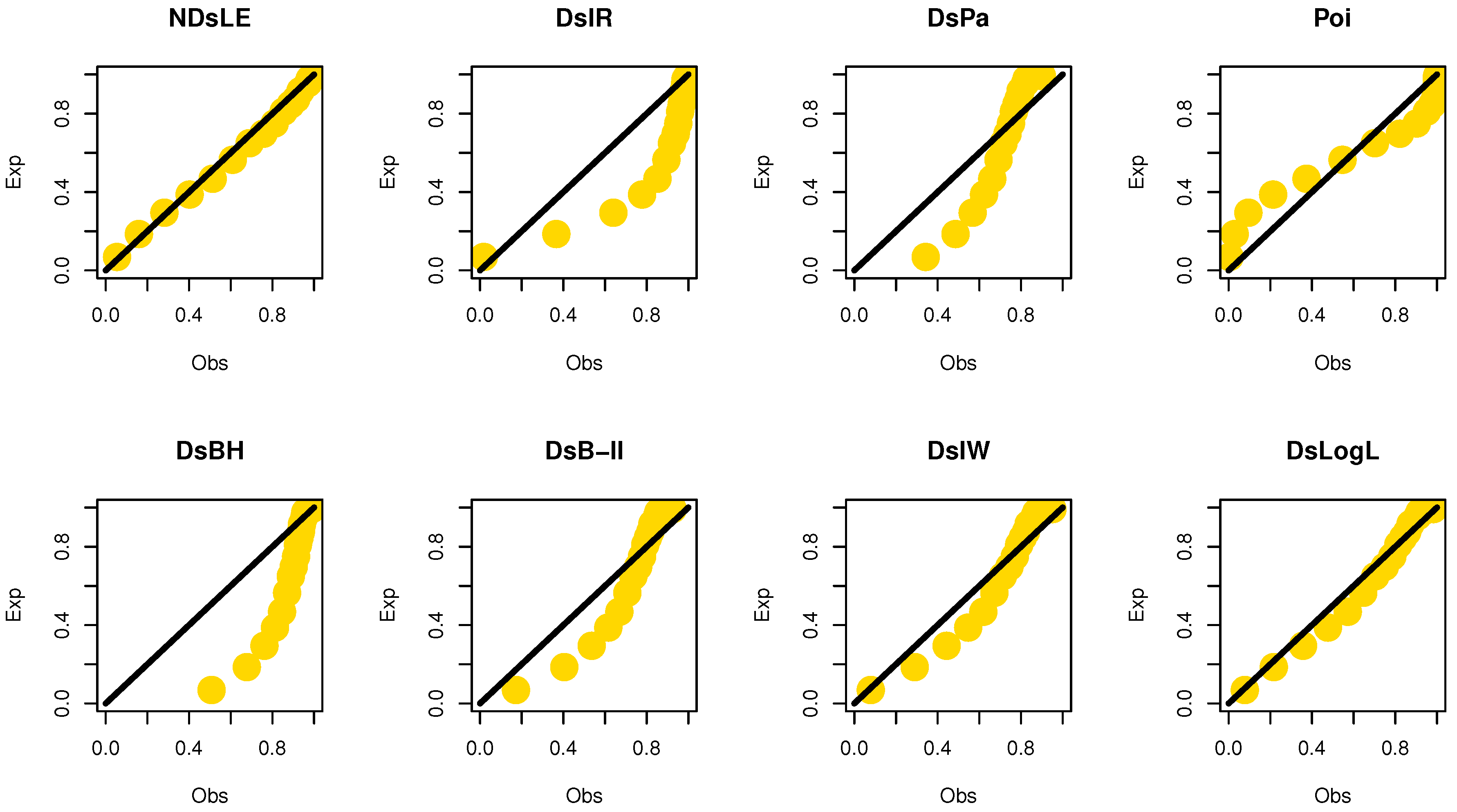
Figure 8.
The empirical PPs plots for data set I.
Figure 8.
The empirical PPs plots for data set I.
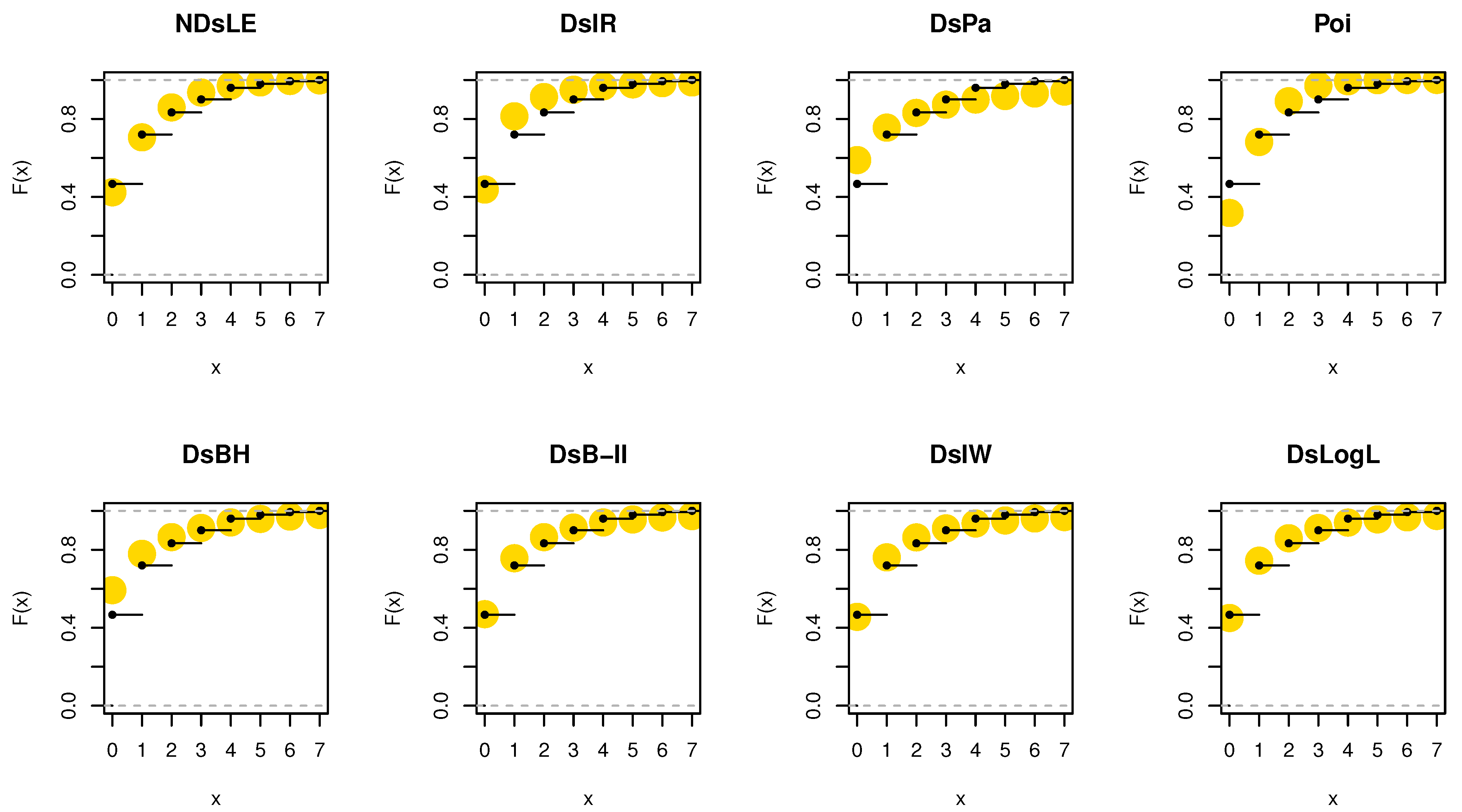
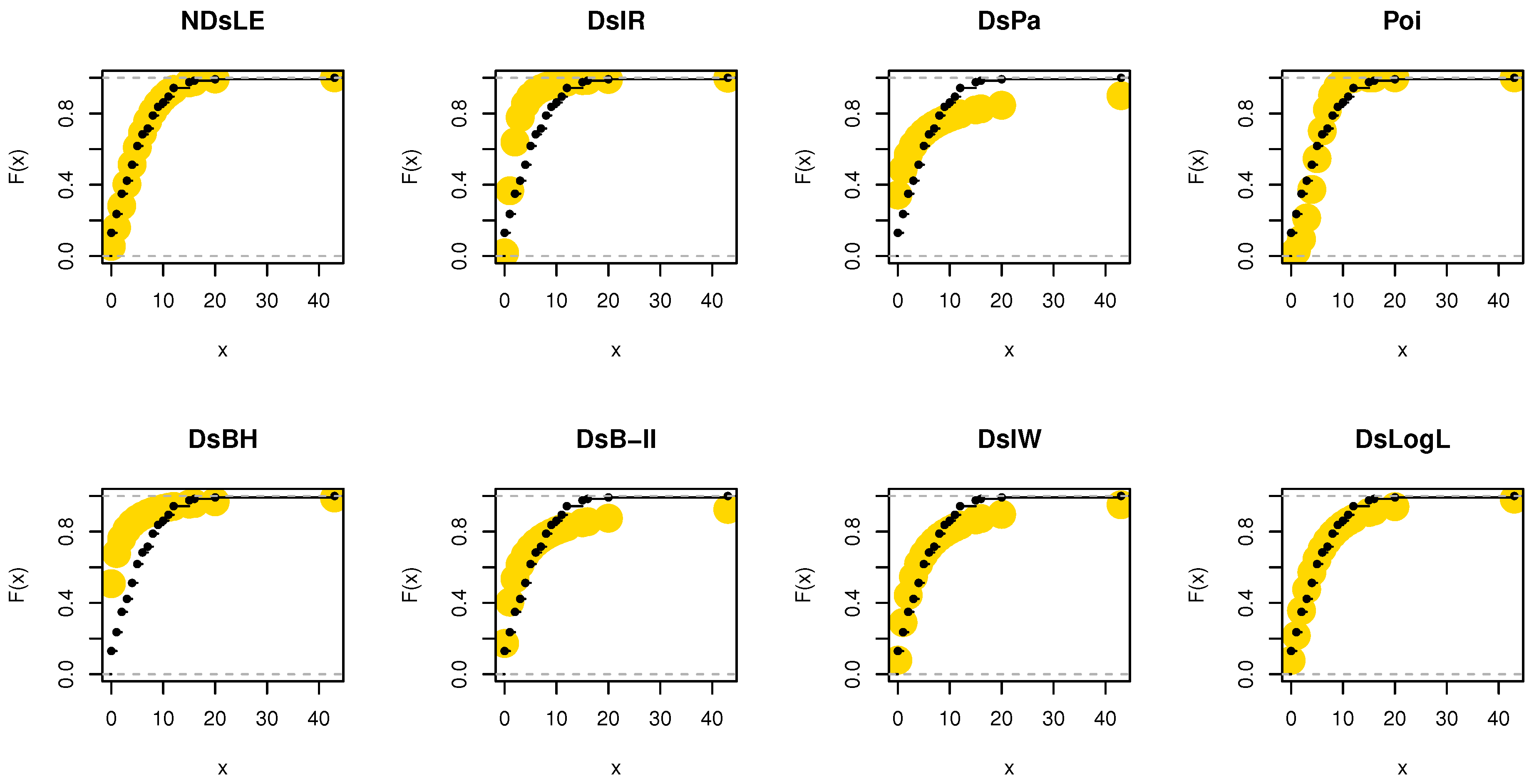
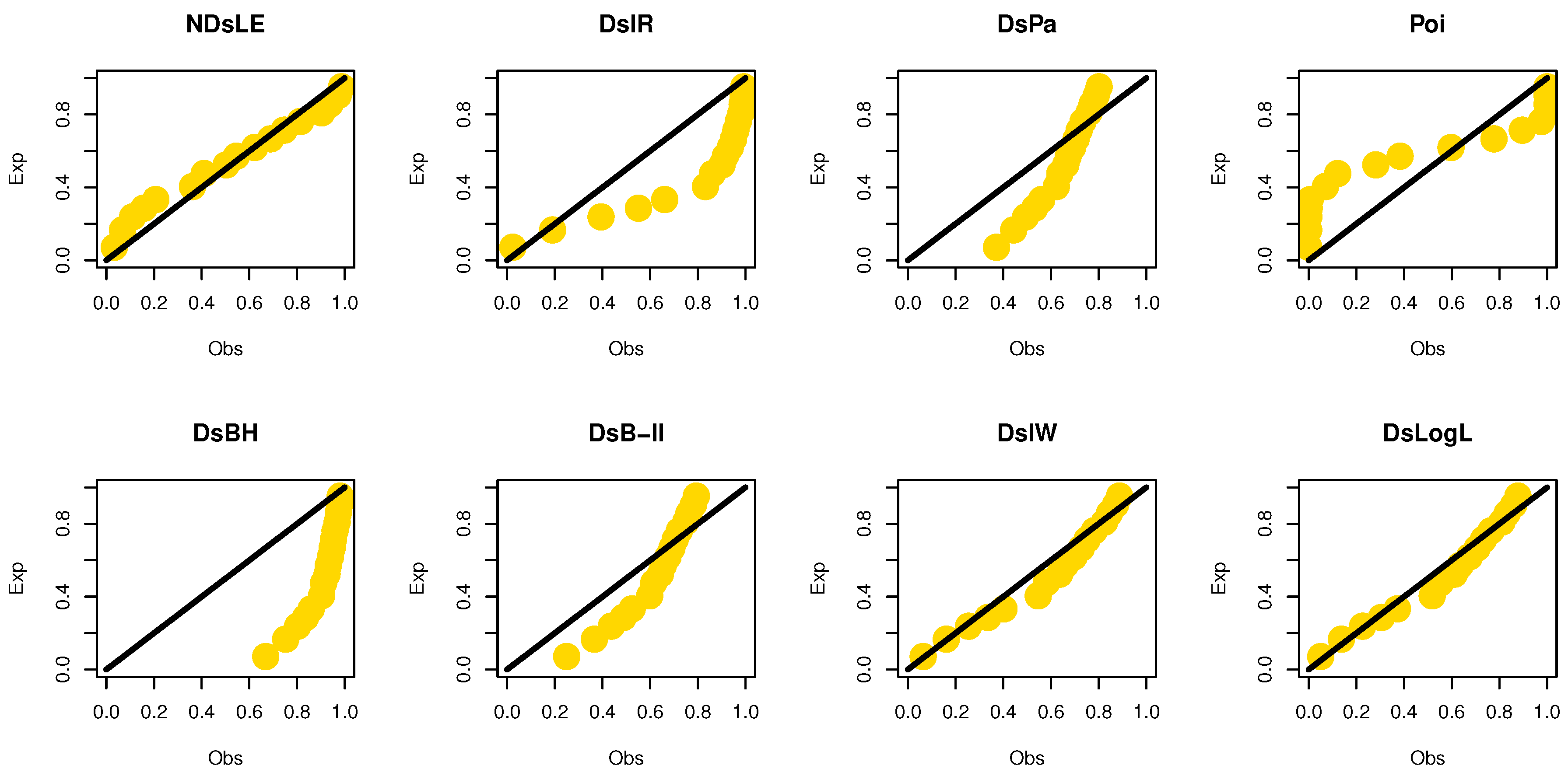
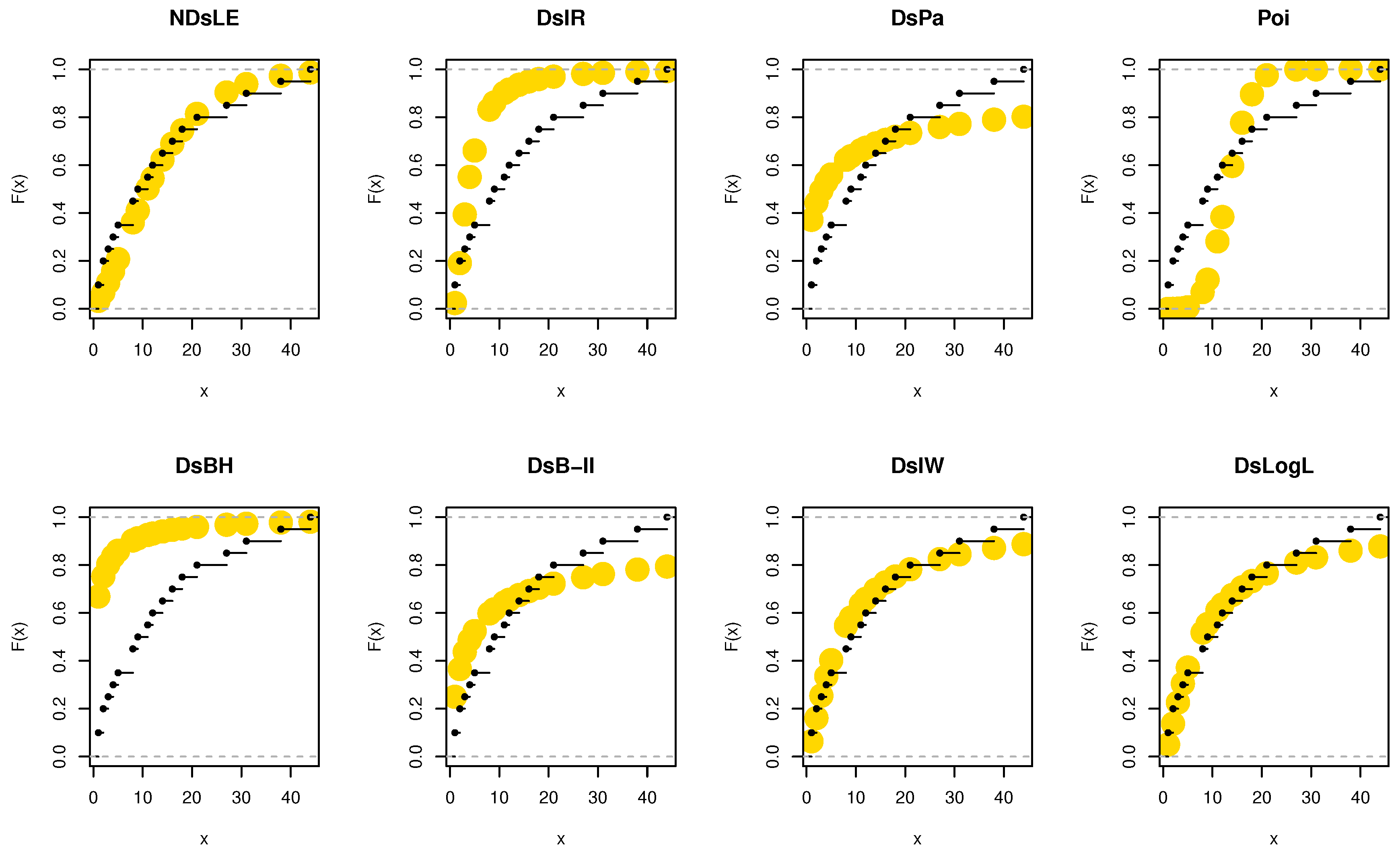
Figure 9.
The empirical CDFs plots for data set I.
Figure 9.
The empirical CDFs plots for data set I.
Figure 10.
Nonparametric plots for data set II.
Figure 10.
Nonparametric plots for data set II.
Figure 11.
The empirical PPs plots for data set II.
Figure 11.
The empirical PPs plots for data set II.
Figure 12.
The empirical CDFs plots for data set II.
Figure 12.
The empirical CDFs plots for data set II.
Figure 13.
Nonparametric plots for data set III.
Figure 13.
Nonparametric plots for data set III.
Figure 14.
The empirical PMFs plots for data set III.
Figure 14.
The empirical PMFs plots for data set III.
Figure 15.
The empirical PPs plots for data set III.
Figure 15.
The empirical PPs plots for data set III.
Figure 16.
The empirical CDFs plots for data set III.
Figure 16.
The empirical CDFs plots for data set III.
Figure 17.
Nonparametric plots for data set IV.
Figure 17.
Nonparametric plots for data set IV.
Figure 18.
The empirical PPs plots for data set IV.
Figure 18.
The empirical PPs plots for data set IV.
Figure 19.
The empirical CDFs plots for data set IV.
Figure 19.
The empirical CDFs plots for data set IV.
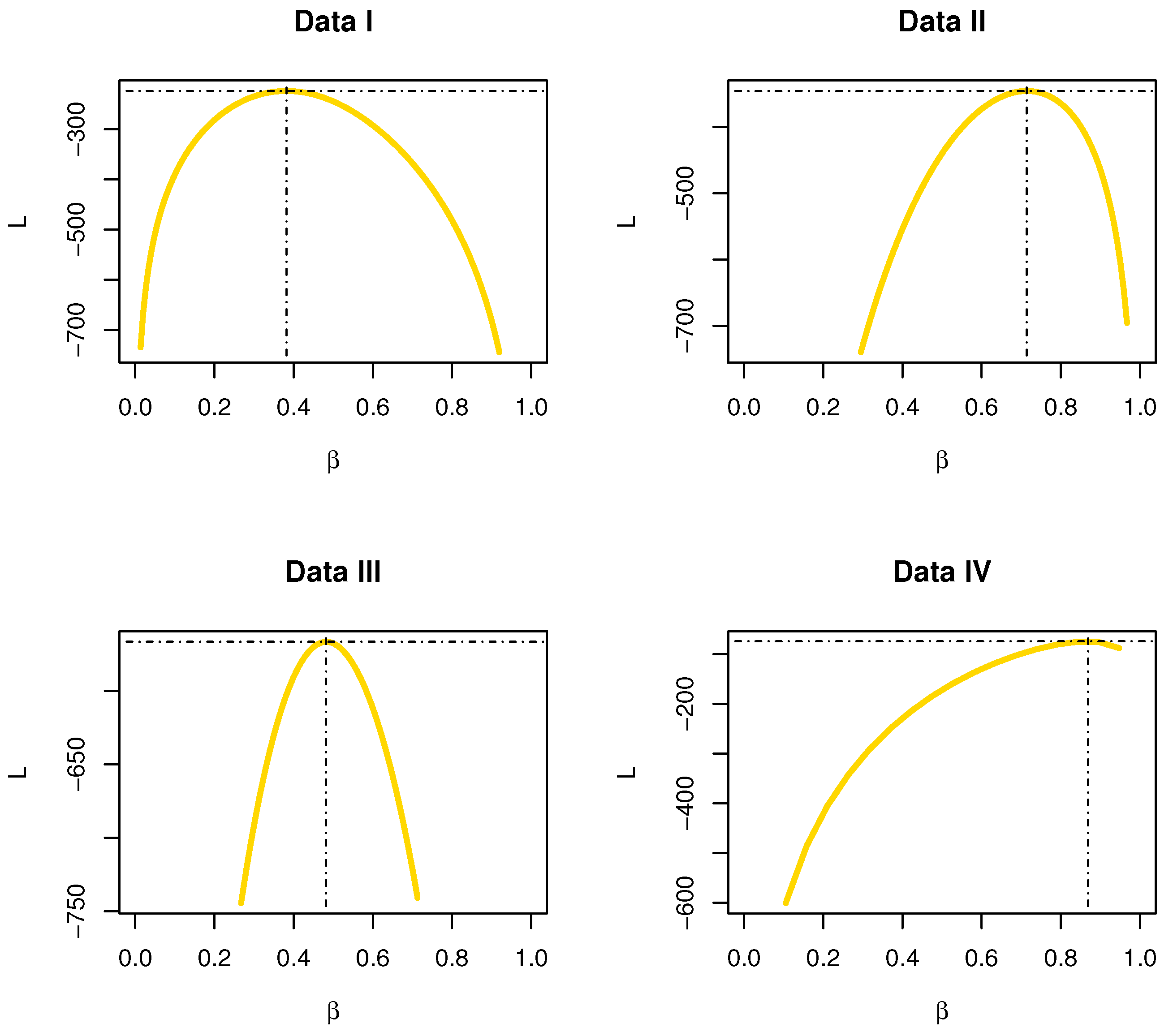
Figure 20.
The profiles of L functions for data sets I, II, III and IV.
Figure 20.
The profiles of L functions for data sets I, II, III and IV.
Table 1.
Some DS for the NDsLE model under various values of .
Table 1.
Some DS for the NDsLE model under various values of .
| | | | | | |
|---|
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
Table 2.
The performance of different estimators.
Table 2.
The performance of different estimators.
| p | Criteria | MLE | MoE | ProE | LSE | WLSE | CVME |
|---|
|
| 20 | | 0.13725150 | 0.13901581 | 0.14074285 | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 50 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 150 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 300 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 500 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 700 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
Table 3.
The performance of different estimators.
Table 3.
The performance of different estimators.
| p | Criteria | MLE | MoE | ProE | LSE | WLSE | CVME |
|---|
|
| 20 | | 0.16739517 | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 50 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 150 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 300 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 500 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 700 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
Table 4.
The performance of different estimators.
Table 4.
The performance of different estimators.
| p | Criteria | MLE | MoE | ProE | LSE | WLSE | CVME |
|---|
|
| 20 | | 0.55453838 | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 50 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 150 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 300 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 500 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
| 700 | | | | | | | |
| | NDS | | | | | | |
| | NES | | | | | | |
Table 5.
The CMs of the NDsLE model.
Table 5.
The CMs of the NDsLE model.
| Distribution | Abbreviation | Author(s) |
|---|
| Discrete inverse Rayleigh | DsIR | Hussain and Ahmad [15] |
| Discrete Pareto | DsPa | Krishna and Pundir [2] |
| Poisson | Poi | Poisson [16] |
| Discrete Burr-Hatke | DsBH | El-Morshedy et al. [17] |
| Discrete Burr type II | DsB-II | Para and Jan [8] |
| Discrete inverse Weibull | DsIW | Jazi et al. [18] |
| Discrete log-logistic | DsLog-L | Para and Jan [19] |
Table 6.
The MLEs, Std-er, C.I, and GOF measures for data set I.
Table 6.
The MLEs, Std-er, C.I, and GOF measures for data set I.
| No. | | EF |
|---|
| X | OF | NDsLE | DsIR | DsPa | Poi | DsBH | DsB-II | DsIW | DsLogL |
|---|
| 70 | | | | | | | | |
| 38 | | | | | | | | |
| 17 | | | | | | | | |
| 10 | | | | | | | | |
| 9 | | | | | | | | |
| 3 | | | | | | | | |
| 2 | | | | | | | | |
| 1 | | | | | | | | |
| Total | | | | | | | | | |
| MLE for | | | | | | | | |
| Std-er | | | | | | | | |
| 95% C.I | | | | | | | | | |
| MLE for | − | − | − | − | − | | | |
| Std-er | − | − | − | − | − | | | |
| 95% C.I | | | | | | | | | |
| | | | | | | | |
| A | | | | | | | | |
| CA | | | | | | | | |
| B | | | | | | | | |
| H | | | | | | | | |
| | | | | | | | |
| DV | 3 | 3 | 4 | 2 | 4 | 2 | 3 | 2 |
| PV | | ≤0.001 | ≤0.001 | ≤0.001 | | | | |
Table 7.
CVE for data set I.
Table 7.
CVE for data set I.
| No. | | EF |
|---|
| X | OF | MLE | MoE | ProE | LSE | WLSE | CVME |
|---|
| 70 | | | | | | |
| 38 | | | | | | |
| 17 | | | | | | |
| 10 | | | | | | |
| 9 | | | | | | |
| 3 | | | | | | |
| 2 | | | | | | |
| 1 | | | | | | |
| Total | | | | | | | |
| | | | | | |
| | | | | | |
| DF | 3 | 3 | 3 | 5 | 4 | 5 |
| PV | | | | <0.001 | <0.001 | <0.001 |
Table 8.
Descriptive statistics for data set I.
Table 8.
Descriptive statistics for data set I.
| | | | | | |
|---|
| Data | | | | | |
| MLE | | | | | |
| MoE | | | | | |
| ProE | | | | | |
| LSE | | | | | |
| WLSE | | | | | |
| CVME | | | | | |
Table 9.
The MLEs, Std-er, C.I, and GOF measures for data set II.
Table 9.
The MLEs, Std-er, C.I, and GOF measures for data set II.
| | NDsLE | DsIR | DsPa | Poi | DsBH | DsB-II | DsIW | DsLogL |
|---|
| MLE for | | | | | | | | |
| Std-er | | | | | | | | |
| 95% C.I | | | | | | | | | |
| MLE for | − | − | − | − | − | | | |
| Std-er | − | − | − | − | − | | | |
| 95% C.I | | | | | | | | | |
| | | | | | | | |
| A | | | | | | | | |
| CA | | | | | | | | |
| B | | | | | | | | |
| H | | | | | | | | |
| K–S | 0.089 | | | | | | | |
| PV | 0.281 | | | ≤0.001 | | ≤0.0010 | ≤0.0010 | |
Table 10.
CVE for data set II.
Table 10.
CVE for data set II.
| | MLE | MoE | ProE | LSE | WLSE | CVME |
|---|
| | | | | | |
| K–S | | | | | | |
| PV | | | ≤0.001 | | | |
Table 11.
Descriptive statistics for data set II.
Table 11.
Descriptive statistics for data set II.
| | | | | | |
|---|
| Data | | | | | |
| MLE | | | | | |
| MoE | | | | | |
| ProE | | | | | |
| LSE | | | | | |
| WLSE | | | | | |
| CVME | | | | | |
Table 12.
The MLEs, Std-er, C.I, and GOF measures for data set III.
Table 12.
The MLEs, Std-er, C.I, and GOF measures for data set III.
| No. | | EF |
|---|
| X | OF | NDsLE | DsIR | DsPa | Poi | DsBH | DsB-II | DsIW | DsLogL |
|---|
| 89 | | | | | | | | |
| 79 | | | | | | | | |
| 49 | | | | | | | | |
| 29 | | | | | | | | |
| 19 | | | | | | | | |
| 17 | | | | | | | | |
| 9 | | | | | | | | |
| 6 | | | | | | | | |
| 6 | | | | | | | | |
| 1 | | | | | | | | |
| Total | | | | | | | | | |
| MLE for | | | | | | | | |
| Std-er | | | | | | | | |
| 95% C.I | | | | | | | | | |
| MLE for | − | − | − | − | − | | | |
| Std-er | − | − | − | − | − | | | |
| 95% C.I | | | | | | | | | |
| | | | | | | | |
| A | | | | | | | | |
| CA | | | | | | | | |
| B | | | | | | | | |
| H | | | | | | | | |
| | | | | | | | |
| DV | 6 | 6 | 7 | 4 | 6 | 6 | 6 | 6 |
| PV | | ≤0.001 | ≤0.001 | ≤0.001 | ≤0.001 | ≤0.001 | ≤0.001 | ≤0.001 |
Table 13.
CVE for data set III.
Table 13.
CVE for data set III.
| No. | | EF |
|---|
| X | OF | MLE | MoE | ProE | LSE | WLSE | CVME |
|---|
| 89 | | | | | | |
| 79 | | | | | | |
| 49 | | | | | | |
| 29 | | | | | | |
| 19 | | | | | | |
| 17 | | | | | | |
| 9 | | | | | | |
| 6 | | | | | | |
| 6 | | | | | | |
| 1 | | | | | | |
| Total | | | | | | | |
| | | | | | |
| | | | | | |
| DV | 6 | 6 | 6 | 7 | 7 | 7 |
| PV | | | | ≤0.001 | | ≤0.001 |
Table 14.
Descriptive statistics for data set III.
Table 14.
Descriptive statistics for data set III.
| | | | | | |
|---|
| Data | | | | | |
| MLE | | | | | |
| MoE | | | | | |
| ProE | | | | | |
| LSE | | | | | |
| WLSE | | | | | |
| CVME | | | | | |
Table 15.
The MLEs, Std-er, C.I, and GOF measures for data set IV.
Table 15.
The MLEs, Std-er, C.I, and GOF measures for data set IV.
| | NDsLE | DsIR | DsPa | Poi | DsBH | DsB-II | DsIW | DsLogL |
|---|
| MLE for | | | | | | | | |
| Std-er | | | | | | | | |
| 95% C.I | | | | | | | | | |
| MLE for | − | − | − | − | − | | | |
| Std-er | − | − | − | − | − | | | |
| 95% C.I | | | | | | | | | |
| | | | | | | | |
| A | | | | | | | | |
| CA | | | | | | | | |
| B | | | | | | | | |
| H | | | | | | | | |
| K–S | | | | | | | | |
| PV | | <0.001 | | | <0.001 | | | |
Table 16.
CVE for data set IV.
Table 16.
CVE for data set IV.
| | MLE | MoE | ProE | LSE | WLSE | CVM |
|---|
| | | | | | |
| K–S | | | | | | |
| PV | | | | | | |
Table 17.
Descriptive statistics for data set IV.
Table 17.
Descriptive statistics for data set IV.
| | | | | | |
|---|
| Data | | | | | |
| MLE | | | | | |
| MoE | | | | | |
| ProE | | | | | |
| LSE | | | | | |
| WLSE | | | | | |
| CVME | | | | | |
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
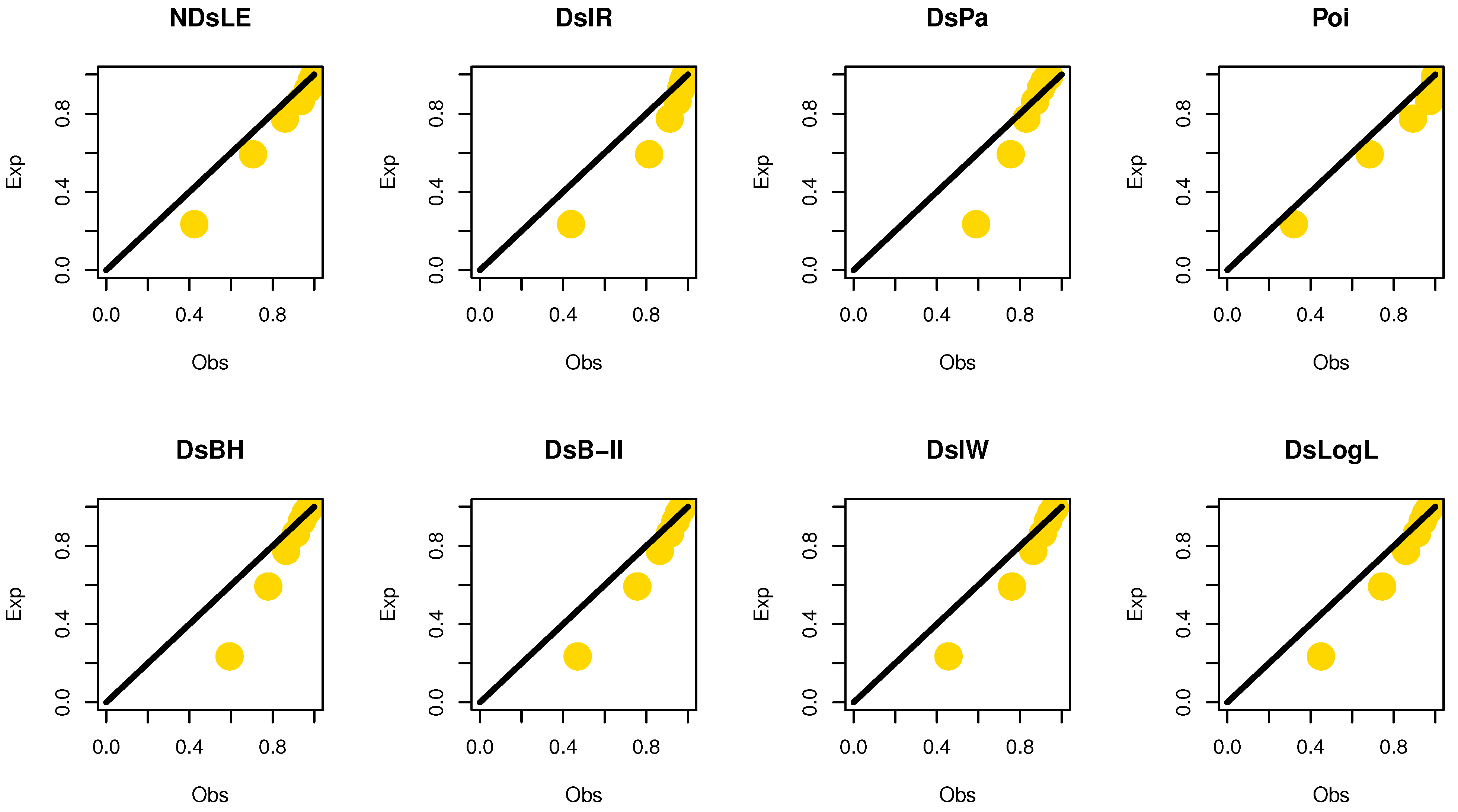{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
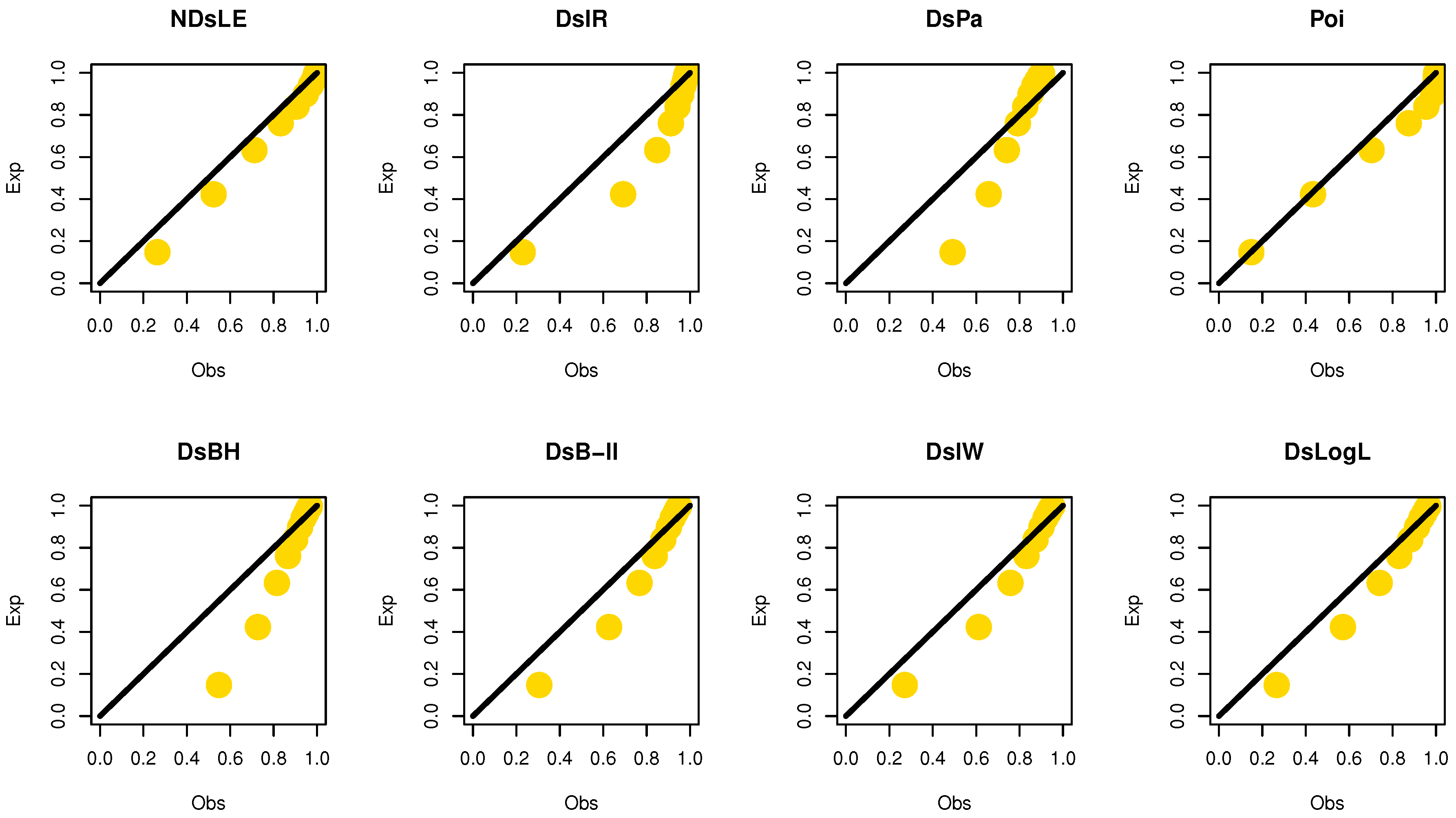{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}